JavaScript中的正则表达式
1、相关概念
正则表达式:是指由一些特殊的特定字符以特定形式组合在一起,进行字符串的匹配、查找、规则验证等。
正则表达式由原子、元字符、模式匹配符组成。
(1)原子:表示想要匹配的字符。
a、使用普通字符充当原子a-z、A-Z、0-9;
b、使用特殊的转义字符充当原子;
\d 匹配0-9之间任意一个数字
\D 匹配0-9之间之外的任意一个数字
\s 匹配任意一个空白符(空白符包括回车符\r、换行符\n、制表符\t)
\S 匹配空白符之外的任意一个字符
\w 匹配字母、数字、下划线中任意一个字符
\W 匹配除了字母、数字、下划线之外的任意一个字符
c、使用特殊的元字符充当原子;
. 匹配除了换行符之外的任意一个字符
(2)元字符:用于描述位置、数量等信息。
? * + [ ] ( ) { } ^ | & . \ \b \B
a、{ } 描述原子数量
{m} 描述其前原子恰好出现m次
{m,} 描述其前原子至少出现m次
{m,.n} 描述其前原子至少出现m次,最多出现n次
b、[ ] 原子列表,匹配列表中的任意一个字符
c、[^ ] 排除原子列表,即除了原子列表之外的任意一个字符
d、^ 字符串起始位置
e、$ 字符串结束位置
f、* 描述其前原子出现0次、1次或多次;同时*具有贪婪模式,只要符合条件就选取最多的
g、+ 描述其前原子出现1次或多次,具有贪婪模式
h、?描述其前原子出现0次或1次
i、| 或者关系
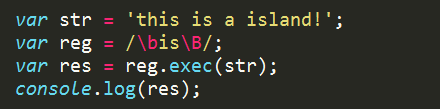
j、 \b \B 描述字符是否为单词的边界
\b 表示是单词的边界
\B表示不是单词的边界
注意:英文中使用空格来分割单词
k、模式单元 () 会看做一个整体,将匹配到的数据返回到结果数组中
贪婪模式: .+ 和 .* 获取最多的符合条件的数据
拒绝贪婪模式: .+? 和 .*?

模式匹配单元(),默认匹配的结果进行存储,同时能够使用特定的方式进行调用

若使用模式单元,但是不想存储结果,使用(?:),表示当前的模式单元不进行存储

(3)模式匹配符
g 表示全局模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止
i 表示不区分大小写模式,即在确定匹配项时忽略大小写
m 表示多行模式,即在到达一行文本末尾时还会继续查找下一行中是否存在与模式匹配的项
注意:模式匹配符可以组合使用。
2、正则表达式定义的2种方式
(1)使用new RegExp()构造函数实例化获取对象
(2)使用字面量双斜杠/ /形式快速定义正则表达式
RegExp实例属性:
(1)global 布尔值,表示是否设置了g标志
(2)ignoreCase 布尔值,表示是否设置了i标志
(3)multiline 布尔值,表示是否设置了m标志
(4)source 正则表达式的字符串表示,按照字面量形式而非传入构造函数中的字符串模式返回
(5)lastIndex 整数,表示开始搜索下一个匹配项的字符位置,从0算起
3、例子
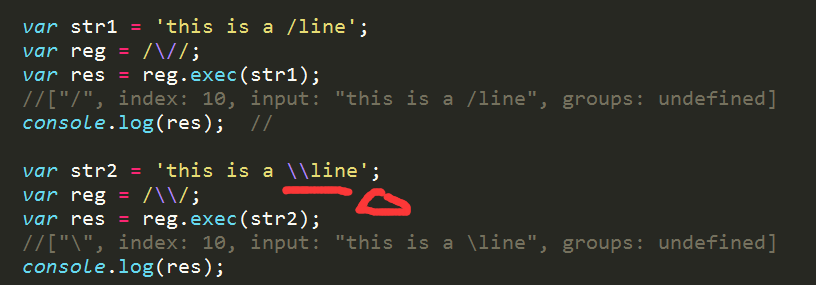
example1 斜线、反斜线
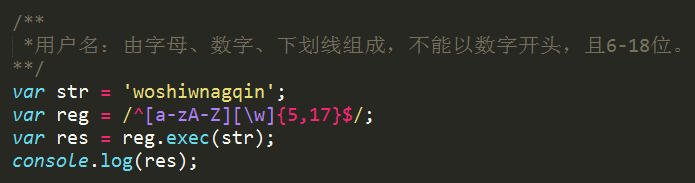
example2 用户名匹配
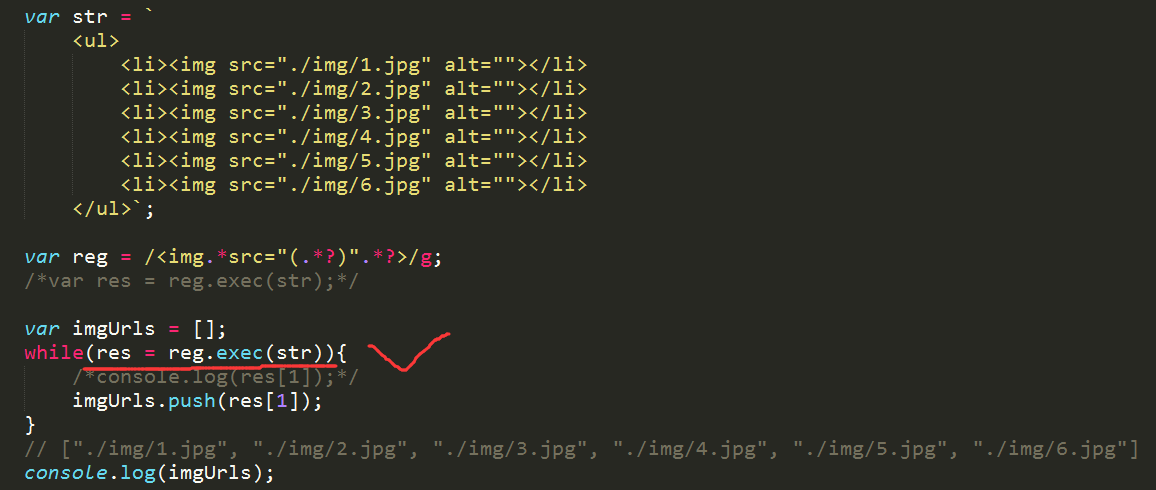
example3 使用正则表达式获取所有图片的地址
example4 replace()替换敏感词汇

example5 正则表达式匹配一个IP地址

example6 正则表达式匹配一个邮箱

example 正则表达式匹配中文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号