
随笔分类 - 机器学习
摘要: ref :https://zhuanlan.zhihu.com/p/10747333168 1、GPU准备 1、查看GPU类型 GeForce RTX 3060 2、查看算力 https://en.wikipedia.org/wiki/CUDA#GPUs_supported 算力8.6 3、确定CU
阅读全文
ref :https://zhuanlan.zhihu.com/p/10747333168 1、GPU准备 1、查看GPU类型 GeForce RTX 3060 2、查看算力 https://en.wikipedia.org/wiki/CUDA#GPUs_supported 算力8.6 3、确定CU
阅读全文
ref :https://zhuanlan.zhihu.com/p/10747333168 1、GPU准备 1、查看GPU类型 GeForce RTX 3060 2、查看算力 https://en.wikipedia.org/wiki/CUDA#GPUs_supported 算力8.6 3、确定CU
阅读全文
摘要: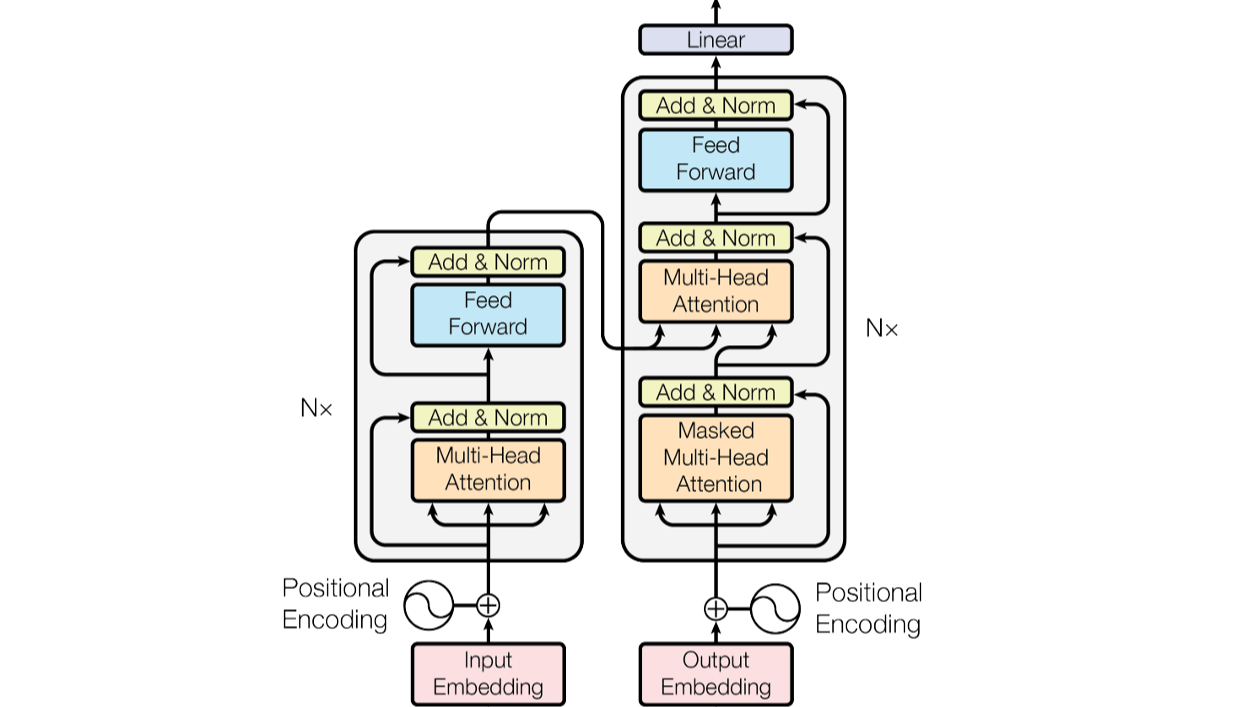 只有理解了,才能在超越经验的情况下,生成出合理的内容 编解码 encoder-decoder结构 什么是“码”? 剥离形式的表示(各种语言的不同),剩下的语义关系(上下文语义) “码”的要求:1、数字化 2、语义关系的距离 分词器和one-hot编码在2不足 需要找到一个纬度高,但是又没那么高的空间
阅读全文
只有理解了,才能在超越经验的情况下,生成出合理的内容 编解码 encoder-decoder结构 什么是“码”? 剥离形式的表示(各种语言的不同),剩下的语义关系(上下文语义) “码”的要求:1、数字化 2、语义关系的距离 分词器和one-hot编码在2不足 需要找到一个纬度高,但是又没那么高的空间
阅读全文
只有理解了,才能在超越经验的情况下,生成出合理的内容 编解码 encoder-decoder结构 什么是“码”? 剥离形式的表示(各种语言的不同),剩下的语义关系(上下文语义) “码”的要求:1、数字化 2、语义关系的距离 分词器和one-hot编码在2不足 需要找到一个纬度高,但是又没那么高的空间
阅读全文
摘要:RNN 简化后网络结构 LSTM 引入长期记忆链c 同时保持短期记忆链s和长期记忆链c,相互更新 与论文图的对应 GRU
阅读全文
摘要:WSL安装anaconda 1、按照CSDN(最终失败) 按照csdn中,直接在linux环境中下载镜像 wget https://repo.anaconda.com/archive/Anaconda3-2023.07-1-Linux-x86_64.sh 下载完成后输入 bash /tmp/Anac
阅读全文
摘要:正则化 L1正则化和L2正则化是机器学习中用于防止模型过拟合的技术,它们通过向损失函数添加额外的项来实现对模型复杂度的惩罚。 L1 正则化 (Lasso Regularization) L1正则化通过在损失函数中添加一个与权重系数的绝对值成比例的项来实现。这个额外的项迫使某些权重系数降为零,从而实现
阅读全文
摘要:1、Keras深度学习框架中的理解方式 矩阵向量点积 output = relu(dot(W, input) + b) input的每个元素为三维的特征向量的特征, W矩阵: 行:存储节点权重数组 列数表示节点数量 所以result[1]和result[0]运算互不干扰,能够并行加速 上述数学角度运
阅读全文
摘要:任务描述 如果你是某新闻单位工作人员(这里假设source=新华社),为了防止其他媒体抄袭你的文章,做一个抄袭自动检测分析的工具: 一、定义可能抄袭的文章来源 二、与原文对比定位抄袭的地方 数据预处理 本次实验涉及的数据预处理 - 数据清洗,针对content字段为空的情况,进行dropna - 分
阅读全文
摘要:训练数据生成 每个x向量维度为3,y标签使用one-hot编码进行3分类。 生成的数据如下: 构建BP神经网络模型 初始化权重和偏置矩阵如下: 训练神经网络 绘制梯度下降损失函数曲线图 附(如果采用梯度下降更新权重,即权重值发生少量变化后,基于损失值的变化更新权重的方法如下:
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号