

爬虫进阶-爬虫爬取百度图片(二)
 爬虫进阶-爬虫爬取百度图片
爬虫进阶-爬虫爬取百度图片
一、开发环境
开发环境:python 3.9和sublime_text
二、第三方库
requests
os
(time)
三、步骤
步骤1:导入requests模块
步骤2:添加headers,url
步骤3:查看百度图片时,浏览器用到Ajax请求,所以url是变化的,每30张一请求,就用遍历
步骤4:get请求url,包括url、headers、请求数据。
步骤5:创建新文件夹接收响应
四、代码
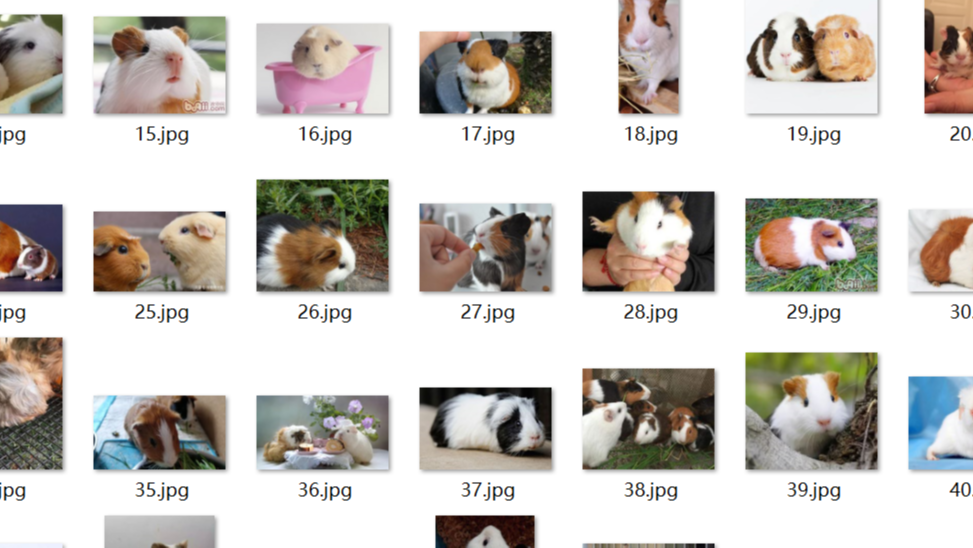
上一篇文章的代码只能爬取Ajax没请求之前的默认30张,现在根据自己的需要想爬多少张爬多少张。
可以自己输入,想要什么图片要什么图片,想爬多少张爬多少张。
如果想自定义,如下:
keyword=input("你想要什么图片:") num=input("你想要30*(x-1)张图片,x为:")
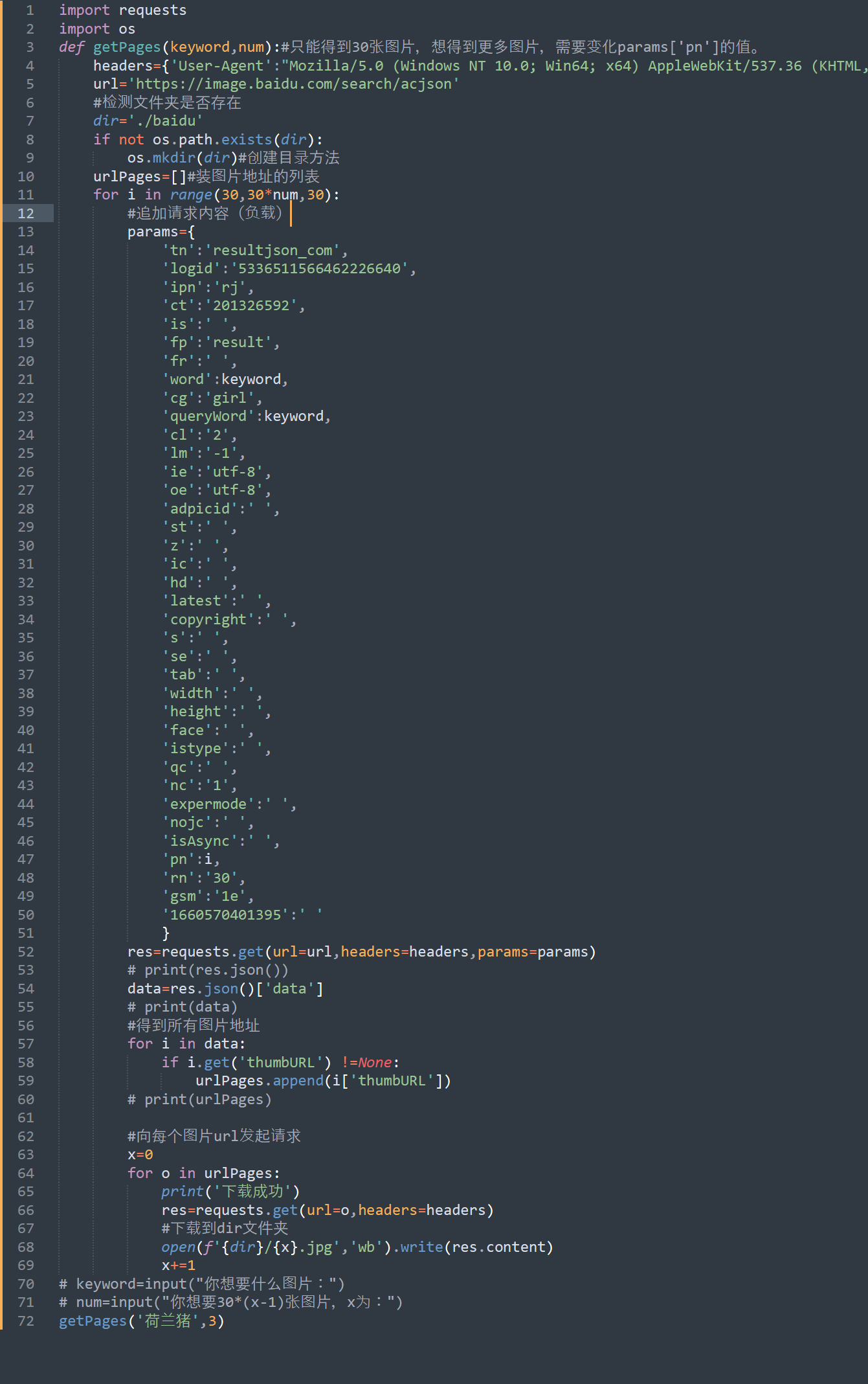
完整代码:(注意看注释)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号