数据库
数据库
一,MySql常用函数
聚合函数
- count()
- min()
- max()
- sum()
- avg()
数值型函数
主要是对数值型进行处理
- ceiling(x):向上取整
- floor(x):向下取整
- round(x):四舍五入
- truncate(x,y):返回数字x截断为y位小数的结果
- PI:圆周率
- rand:返回0~1的随机数
- abs:绝对值
- mod(x,y):x%y,取余
字符串型函数
- length(s):字符串长度
- concat(s1,s2,s3):合并字符串
- lower(s):字母转小写
- upper(s):字母转大写
- left(s,len):左边取len位
- right(s,len):右边取len位
- trim:去掉左右的空格
- replace(s,s1,s2):替换s中为s1,替换为s2
- substring:截取
- reverse:反转
日期和时间函数
date,time,datetime,timestamp,year
- curdate 和 current_date ,返回当前系统的日期
- curtime 和 current_time ,返回当前系统的时间
- now 和 sysdate ,返回当前系统的日期和时间
时间戳和日期转换函数
- UNIX_TIMESTAMP 获取unix系统时间毫秒数
- FROM_UNIXTIME 将时间戳转换为时间格式
根据日期获取年月日
- YEAR()
- MONTH()
- DAY()
- MONTHNAME():英文月份
- DATEIFF(D1,D):两个时间间隔
- DATE_FORMAT(D,'%W %M %D %Y' ):日期格式转换
加密函数
MD5(str)
-- 把传入的参数的字符串按照md5算法进行加密,得到一个32位的16进制的字符串
select MD5('123456');
md5算法是不可逆的。
流程控制函数
可以进行条件判断,用来实现SQL语句的逻辑。
-- if(test,t,f):如果test是真,则返回t,否则返回f
-- ifnull(arg1,arg2):如果arg1不是空,返回arg1,否则返回arg2
-- nullif(arg1,arg2):如果arg1=arg2返回null,否则返回arg1
select IF(2 > 1,'a','b');
select IFNULL(sal,0);
select NULLIF(age,0);
对一系列的值进行判断:
-- 输出学生的各科的成绩,以及评级,60以下D,60-70是C,71-80是B,80以上是A
SELECT
*,
CASE
WHEN score < 60THEN'D'WHEN score >= 60
AND score < 70THEN'C'WHEN score >= 70
AND score < 80 THEN 'B' WHEN score >= 80 THEN
'A'
ENDAS'评级'
FROM
mystudent;-- 行转列
SELECT
user_name,
max( CASE course WHEN '数学' THEN score ELSE 0 END ) '数学',
max( CASE course WHEN '语文' THEN score ELSE 0 END ) '语文',
max( CASE course WHEN'英语'THEN score ELSE0END ) '英语'
FROM
mystudent
GROUP BY
user_name二,数据库设计
三范式
第一范式确保数据的原子性
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
第一范式
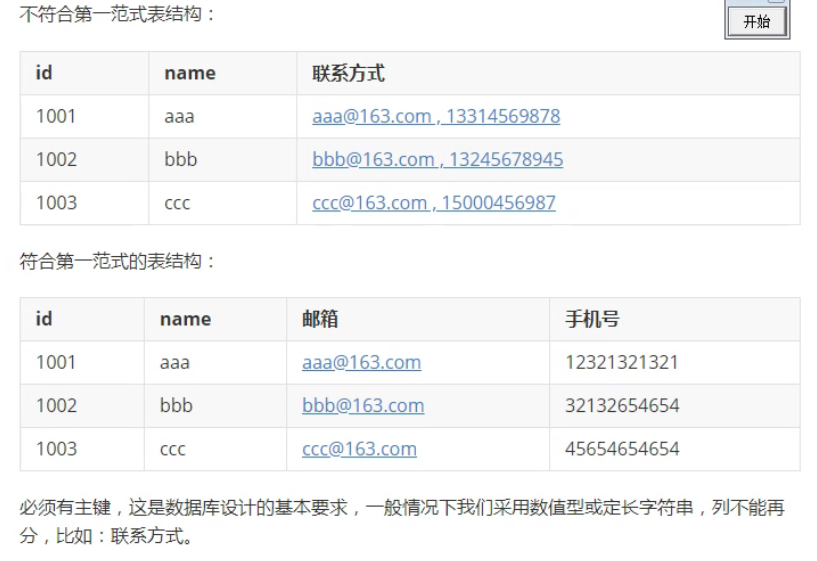
不符合第一范式表结构:
| id | name | 联系方式 |
| ---- | ---- | ------------------------------------------------------------ |
| 1001 | aaa | [aaa@163.com , 13314569878](mailto:aaa@163.com , 13314569878) |
| 1002 | bbb | [bbb@163.com , 13245678945](mailto:bbb@163.com , 13245678945) |
| 1003 | ccc | [ccc@163.com , 15000456987](mailto:ccc@163.com , 15000456987) |
符合第一范式的表结构:
| id | name | 邮箱 | 手机号 |
| ---- | ---- | --------------------------------- | ----------- |
| 1001 | aaa | aaa@163.com | 12321321321 |
| 1002 | bbb | [bbb@163.com](mailto:bbb@163.com) | 32132654654 |
| 1003 | ccc | [ccc@163.com](mailto:ccc@163.com) | 45654654654 |
必须有主键,这是数据库设计的基本要求,一般情况下我们采用数值型或定长字符串,列不能再分,比如:联系方式。
关于第一范式,保证每一行的数据是唯一,每个表必须有主键
第二范式
建立在第一范式的基础上,要求所有非主键字段完全依赖于主键,不能产生部分依赖。
| 学号 | 性别 | 姓名 | 课程编号 | 课程名称 | 教室 | 成绩 |
| ---- | ---- | ---- | -------- | -------- | ---- | ---- |
| 1001 | 男 | a | 2001 | java | 301 | 89 |
| 1002 | 女 | b | 2002 | mysql | 302 | 90 |
| 1003 | 男 | c | 2003 | html | 303 | 91 |
| 1004 | 男 | d | 2004 | python | 304 | 52 |
| 1005 | 女 | e | 2005 | c++ | 305 | 67 |
| 1006 | 男 | f | 2006 | c# | 306 | 84 |
解决方案
学生表:学号是主键
| 学号 | 性别 | 姓名 |
| ---- | ---- | ---- |
| 1001 | 男 | a |
| 1002 | 女 | b |
| 1003 | 男 | c |
| 1004 | 男 | d |
| 1005 | 女 | e |
| 1006 | 男 | f |
课程表:课程编号是主键
| 课程编号 | 课程名称 | 教室 |
| -------- | -------- | ---- |
| 2001 | java | 301 |
| 2002 | mysql | 302 |
| 2003 | html | 303 |
| 2004 | python | 304 |
| 2005 | c++ | 305 |
| 2006 | c# | 306 |
成绩表:学号和课程编号为联合主键
| 学号 | 课程编号 | 成绩 |
| ---- | -------- | ---- |
| 1001 | 2001 | 89 |
| 1002 | 2002 | 90 |
| 1003 | 2003 | 91 |
| 1004 | 2004 | 52 |
| 1005 | 2005 | 67 |
| 1006 | 2006 | 84 |
第三范式
建立在第二范式基础上,非主键字段不能传递依赖于主键字段。
不满足第三范式:
| 学号 | 姓名 | 课程编号 | 课程名称 |
| ---- | ---- | -------- | -------- |
| 1001 | a | 2001 | java |
| 1002 | b | 2002 | mysql |
| 1003 | c | 2003 | html |
| 1004 | d | 2004 | python |
| 1005 | e | 2005 | c++ |
| 1006 | f | 2006 | c# |
解决方案:
学生表:学号是主键
| 学号 | 姓名 | 课程编号 |
| ---- | ---- | -------- |
| 1001 | a | 2001 |
| 1002 | b | 2002 |
| 1003 | c | 2003 |
| 1004 | d | 2004 |
| 1005 | e | 2005 |
| 1006 | f | 2006 |
课程表:课程编号是主键
| 课程编号 | 课程名称 |
| -------- | -------- |
| 2001 | java |
| 2002 | mysql |
| 2003 | html |
| 2004 | python |
| 2005 | c++ |
| 2006 | c# |
常见的表关系
一对一
学生信息表分为基本信息表和信息信息表。
- 分为两张表,共享主键。
- 分两张表,用外键连接。
一对多
两张表,外键在多的一方。
- 分两张表存储,在多的一方加外键
- 这个外键字段引用是一的一方的主键
多对多
- 分三张表存储,在学生表存储学生信息,在课程表存储课程信息。
- 在成绩表中存储学生和课程的对应关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号