
第一次作业-绪论及深度学习概论
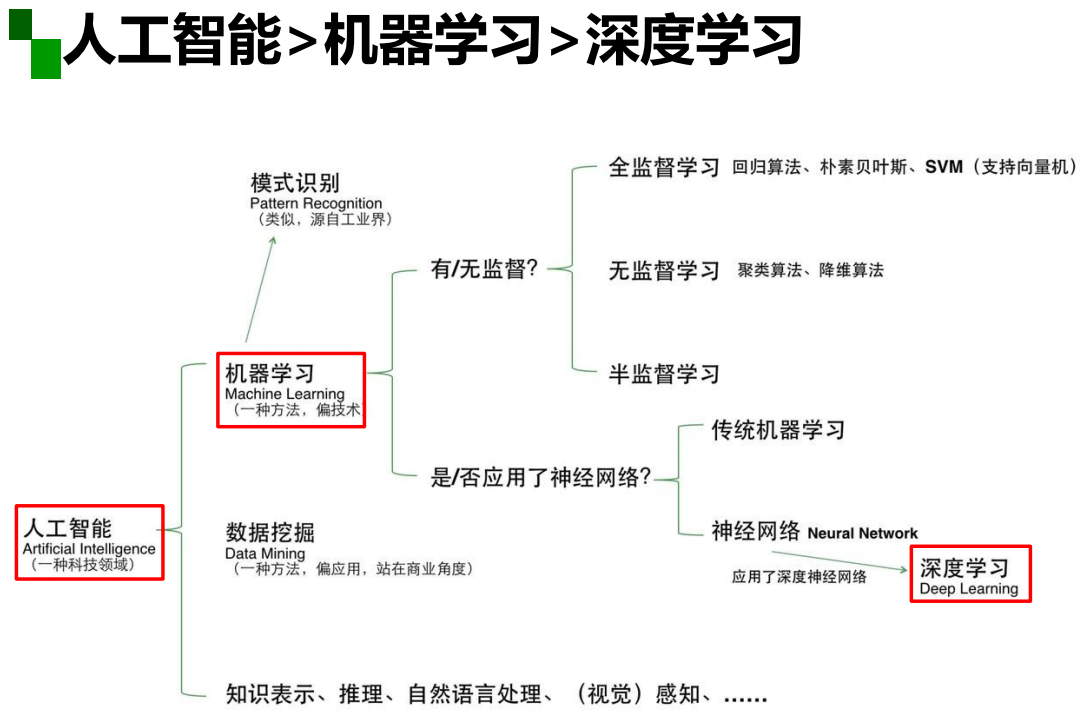
人工智能:使一部机器像人一样进行感知、认知、决策、执行的人工程序或系统。
机器学习:从数据中自动提取知识。
机器学习三要素:模型、策略、算法
深度学习三要素:算法、算力、数据
一、模型
1.分类

(1)数据标记:监督学习模型与无监督学习模型
无监督学习从数据中学习模式,适用于描述数据
监督学习从数据中学习标记分界面(输入-输出的映射函数),适用于预测数据标记
半监督学习:部分数据标记已知,监督学习和无监督学习的混合
强化学习:数据标记未知,但知道与输出目标相关的反馈,决策类问题
(2)数据分布:参数模型与非参数模型
参数模型:对数据进行假设,待求解的数据模式/映射可以用一组有限且固定数目的参数进行刻画
例:线性回归、逻辑回归、感知机、k均值聚类
非参数模型:不对数据分布进行假设,数据的所有统计特征都来源于数据本身
例:k近邻模型、SVM、决策树、随机森林
tips:
-
非参≠无参,“参数”指数据分布的参数,而不是模型的参数。非参数模型的时空复杂度一般比参数模型大得多
-
参数模型的模型参数固定,非参数模型是自适应数据的,模型参数随样本的变化而变化
(3)建模模型:判别模型与生成模型
生成模型:对输入X和输出Y的联合分布P(X, Y)建模
例:朴素贝叶斯、隐马尔科夫、马尔科夫随机场
优点:
- 提供更多信息(建模边缘分布->采样生成样本)
- 样本量大时,更快收敛到真实分布
- 支持复杂训练情况(无监督训练、存在隐变量时)
缺点:
- 数据需求大
- 预测类问题准确率通常不如判别模型
判别模型:对已知输入X的条件下输出Y的条件分布P(Y|X)建模
例:SVM、逻辑回归、条件随机场、决策树
二、深度学习的不能
- 算法输出不稳定,容易被“攻击”
- 模型复杂度高,难以纠错和调试
- 模型层级复合程度高,参数不透明
- 端到端训练方式对数据依赖性强,模型增量性差
- 专注直观感知类问题,对开放性问题推理能力无能为力
- 人类只是无法有效引入进行监督,机器偏见难以避免
学习心得:
了解了人工智能、机器学习、深度学习的关系。人工智能是一个大的概念,机器学习是其中的一个方面,而深度学习又是机器学习的一个方面。
了解了深度学习的发展历史以及它的“能”与“不能”。深度学习的三要素是算法、算力、数据。它依赖于大数据,由于数据的偏颇会造成机器偏见。
在深度学习中,有一个很重要的概念是神经网络。神经网络中有两个重要的概念:单层感知器和多层感知器。单层感知器是是首个可以学习的人工神经网络,但是解决不了非线性问题,于是就由单层感知器的线性任务组合推进到了多层感知器来实现相关非线性问题。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号