
推荐系统架构| YouTube推荐系统
YouTube推荐系统
Deep Neural Networks for YouTube Recommendations, 2016https://dl.acm.org/citation.cfm?doid=2959100.2959190
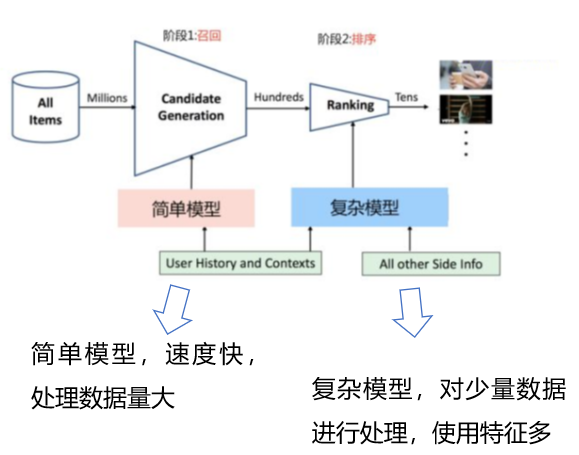
推荐系统分为召回(候选集生成)和排序两个阶段
- 召回阶段,基于用户画像及场景数据从海量的视频库(百万级别)中将相关度最高的资源检索出来,作为候选集 (100w -> 1000)
- 召回阶段可以通过“粗糙”的方式召回候选item
- 排序阶段,基于更加精细的特征对候选集(百级别)进行排序,最终呈现给用户的是很少的一部分数据。
- Ranking阶段,采用更精细的特征计算user-item之间的排序score,作为最终输出推荐结果的依据
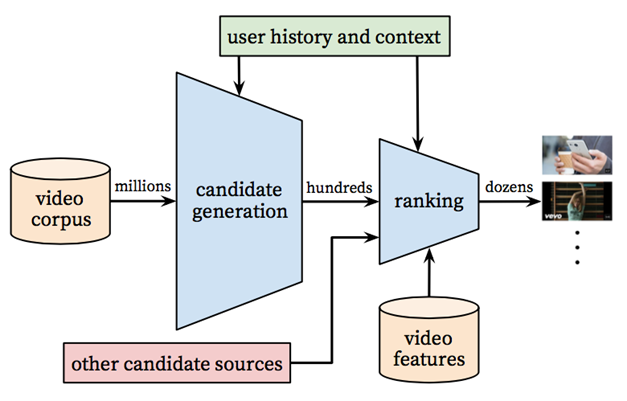
在YouTube推荐系统中使用DNN
越来越多的机器学习问题solution,转移到Deep learning上来解决
采用经典的两阶段法:
- 召回阶段 => deep candidate generation model
- 排序阶段 => deep ranking model
系统实际部署在基于Tensorflow的Google Brain上,模型有接近10亿级参数,训练样本千亿级别
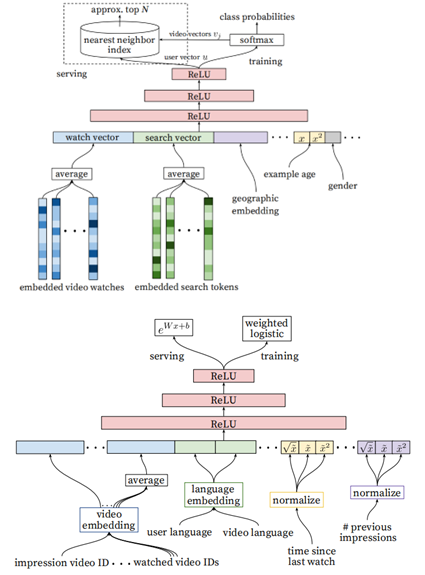
召回阶段的DNN模型:
- 把推荐问题看成一个“超大规模多分类”问题
即在时刻t,为用户U(上下文信息C)在视频库V中精准的预测出视频i的类别(每个具体的视频视为一个类别,i即为一个类别):
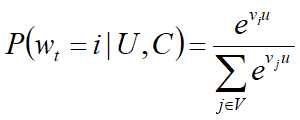
-
- U为<用户,上下文>的高维embedding向量
- vj每个候选视频的embedding向量
DNN的任务就是在用户信息,上下文信息为输入条件的情况下,学习用户的embedding向量u,通过一个softmax分类器,u能够有效的从视频语料库中识别视频的类别(也就是推荐的结果)
由于数据稀疏性问题,训练数据的正负样本选取采用用户隐式反馈数据,即完成了观看的事件作为样本。
比如训练数据为(u1,c1,5) => 用户u1在上下文c1的情况下观看了类别为5的视频
- 使用DNN的一个关键优点是,DNN的输入可以方便的处理离散和连续变量
- 输入是用户浏览历史、搜索历史、人口统计学信息和其余上下文信息concat生成的输入向量
- 模型架构中间是三个隐层的DNN结构
- 输出分线上和离线训练两个部分。
- 将用户观看历史和搜索历史通过embedding的方式映射成为一个稠密的向量,同时用户场景信息以及用户画像信息(比如年龄,性别等离散特征)也被归一化到[0,1]作为DNN的输入
ANN(近似邻居的查找),采用LSH算法;
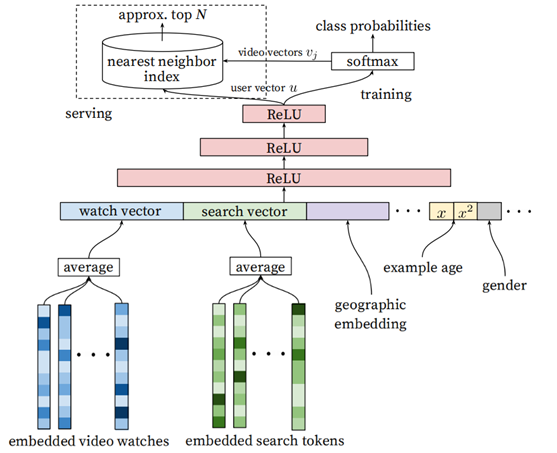
Training 阶段输出层为softmax层,
Serving 阶段直接用user Embedding和video Embedding计算dot-product表示分数,取topk作为候选结果。最重要问题是在性能。因此使用类似局部敏感哈希LSH(近似最近邻方法)
主要特征的处理:
- embedded video watches => watch vector,用户的历史观看是一个稀疏的,变长的视频id序列,采用类似于word2vec的做法,每个视频都会被embedding到固定维度的向量中。最终通过加权平均(可根据重要性和时间进行加权)得到固定维度的watch vector
- embedded search tokens => Search vector,和watch vector生成方式类似
- 用户画像特征:如地理位置,设备,性别,年龄,登录状态等连续或离散特征都被归一化为[0,1], 和watch vector以及search vector做拼接(concatenate)
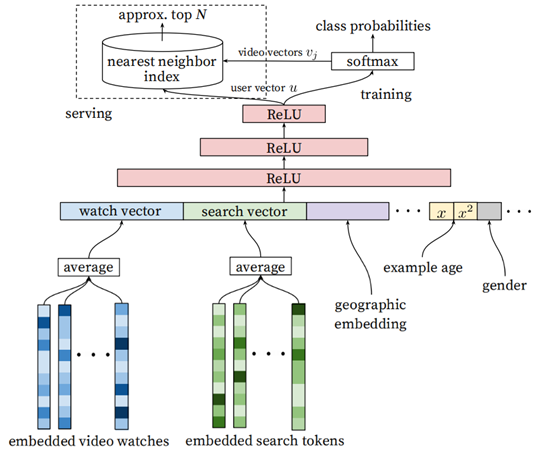
把历史搜索的query分词后的token的embedding向量进行加权平均,可以反映用户的整体的搜索历史情况
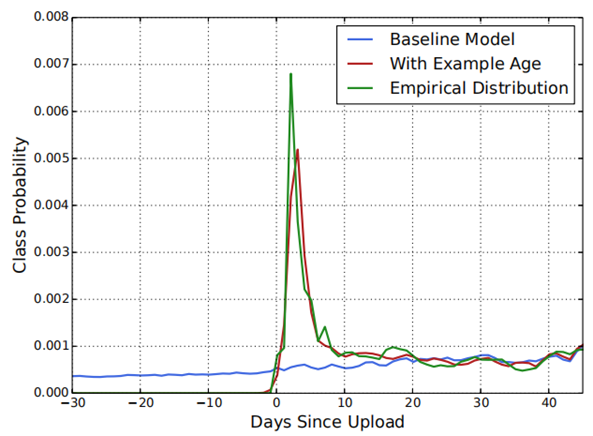
推荐系统中的example age(样本年龄):
- 用户更倾向于推荐尽管相关度不高但是新鲜fresh的视频。
- Example age特征表示视频被上传之后的时间。
- 每一秒中,YouTube都有大量视频被上传,推荐这些最新视频对于YouTube来说是极其重要的。
- 推荐系统往往是利用用户过去的行为来预测未来,那么对于历史行为,推荐系统通常是能够学习到一种隐式的基准的。但是对于视频的流行度分布,往往是高度不稳定的。
- 将example age作为一个特征拼接到DNN的输入向量。训练时,时间窗口越靠后,该值越接近于0或者为一个小负数。加入了example age特征后,模型效果和观测到的实际数据更加逼近
正负样本和上下文选择:
- 在有监督学习问题中,label选择非常关键,因为label决定了你做什么,决定了你的上限,而feature和model都是在逼近label
- 使用更广泛的数据源,训练样本要用youtube上的所有视频观看记录,而不只是系统推荐的视频观看记录。否则,面对新视频的时候很难推荐,并且推荐器会过度偏向exploitation
- 为每个用户生产固定数量的训练样本,在损失函数中所有用户的权重一样 => 防止一部分非常活跃的用户主导损失函数值
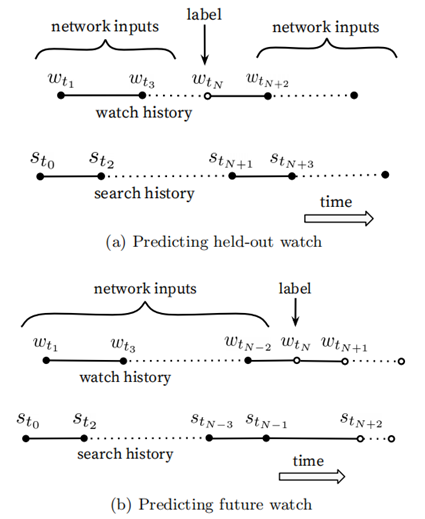
样本和上下文选择中的不对称的共同浏览问题(asymmetric co-watch):
- 用户在浏览视频时候,往往都是序列式的,通常会先看一些比较流行的,然后才是观看一些小众的视频。剧集系列通常也是顺序地观看
- 图(a)是held-out方式,利用上下文信息预估中间的一个视频 (前后的视频的都看了,看它俩中间的视频)
- 图(b)是predicting next watch的方式,则是利用上文信息,预估下一次浏览的视频。(前面看完,就看下一个)
- 发现预测用户的下一个观看视频的效果要好得多,而不是预测随机推出的视频。
- 论文发现图(b)的方式在线上A/B test中表现更佳。而实际上,传统的协同过滤类的算法,都是隐含的采用图(a)的held-out方式,忽略了不对称的浏览模式。
- 方法:从用户的历史视频观看记录中随机拿出来一个作为正样本,然后只用这个视频之前的历史观看记录作为输入(图b)。
负采样 Negative Sampling
- 数据处理过程有时候比算法更重要(算法使用可能半天能搞定,但是数据处理/样本处理需要半个月)
- 采用负采样,也就是随机从全量item中抽取用户没有点击过的item作为label=0的item后,效果明显提升
- 在当次展现的情况下,虽然用户只点击了click的item,其他item没有点击,但是很多用户在后续浏览的时候未click的item也在其他非列表页的地方进行click,如果将该item标记为label=0,可能是误标记
- 论文中提到,推荐列表展示的item极有可能为热门item,虽然该item该用户未点击,但是我们不能降低热门item的权重(通过label=0的方式),实际数据也证明了这一点
- 推荐列表页中展示的item是算法模型计算出来的 => 用户最有可能会点击的item
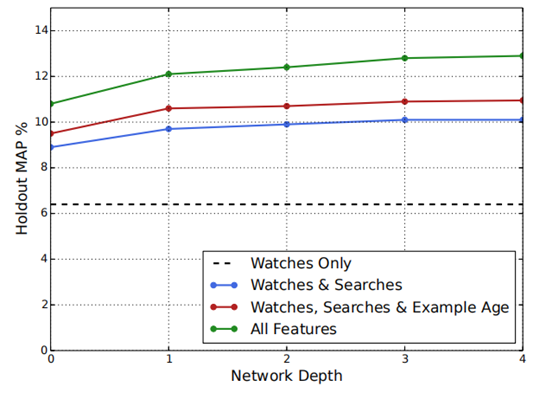
不同网络深度和特征的实验:
所有的视频和search token都embedded到256维的向量中,开始input层直接全连接到256维的softmax层,依次增加网络深度

随着网络深度加大,预测准确率在提升,但增加第4层之后,MAP(Mean Average Precision)已经变化不大了
增加了观看历史之外的特征,对预测准确率提升很明显
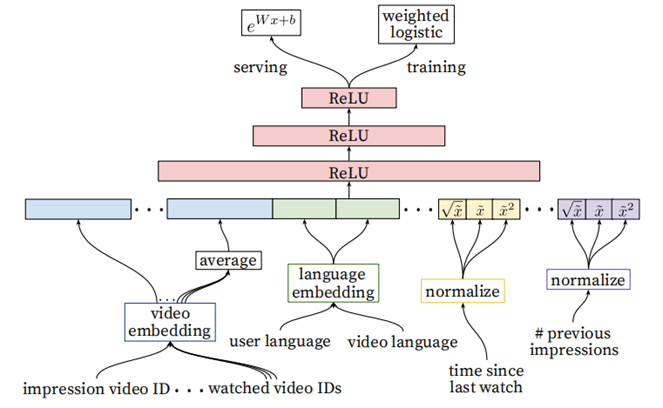
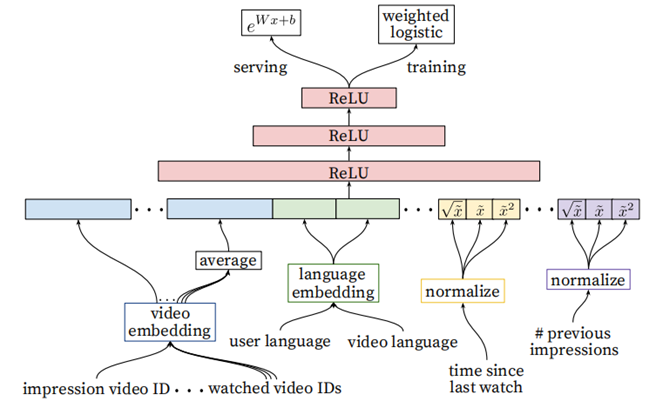
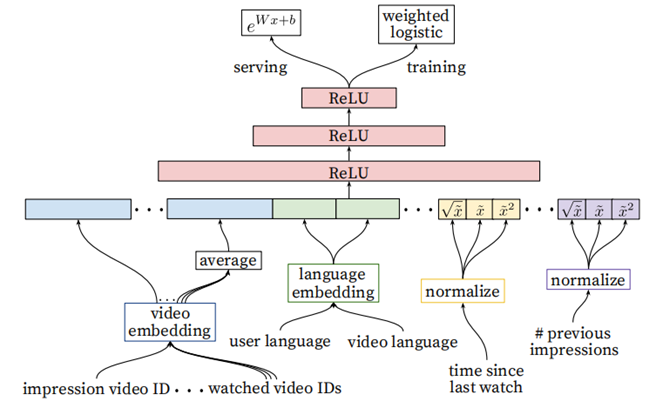
YouTube的排序阶段
- 用于精准的预估用户对视频的喜好程度。针对数百个item,需要更多feature来描述item,以及用户与视频(user-item)的关系。比如用户可能很喜欢某个视频,但如果推荐结果采用的“缩略图”选择不当,用户也许不会点击,等等
- Ranking阶段可以将不同来源的候选项进行有效的ensemble(召回阶段的候选集来源很多,没办法直接比较score)
- Ranking阶段的模型和召回阶段的基本相似,不同在于Training最后一层是Weighted LR,Serving时激励函数使用的
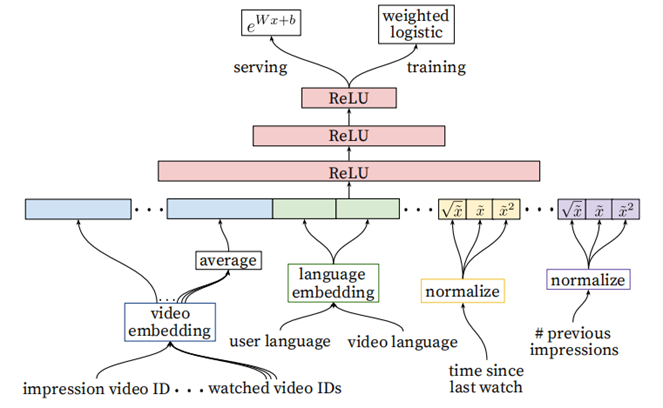
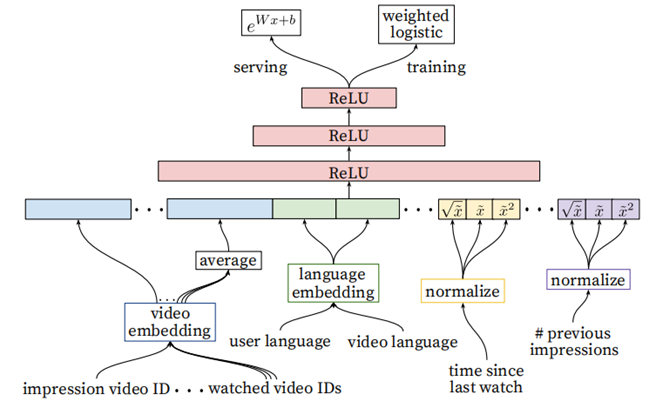
相比召回阶段,引入了更多的feature(当前要计算的video的embedding,用户观看过的最后N个视频embedding的average,用户语言的embedding和当前视频语言的embedding,自上次观看同channel
视频的时间,该视频已经被曝光给该用户的次数)
排序阶段的建模(对观看时间)
- CTR指标对于视频搜索具有一定的欺骗性,所以论文提出采用期望观看时间作为评估指标
- 观看时长不是只有0,1两种标签,所以YouTube采用了Weighted Logistic Regression来模拟这个输出
- 划分样本空间时,正样本为点击,输出值即阅读时长值;负样本为无点击视频,输出值则统一采用1,即采用单位权值,不进行加权
- 在正常的逻辑回归中,几率odds计算,表示样本为正例概率与负例概率的比例
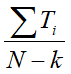
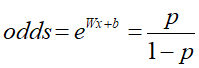
关于odds
odds,代表胜率
- 比如成功的概率p=0.8 ,那么失败的概率q = 1-0.8 = 0.2
- 成功的胜率为:odds(success) = p/q = 0.8/0.2 =4
- 失败的胜率为:odds(failure) = q/p = 0.2/0.8 =0.25
- 针对逻辑回归 Logistic Regression也叫Logit Regression,逻辑回归的输入是一个线性组合(与线性回归一样),但输出是概率
-
- 即为logit函数的定义
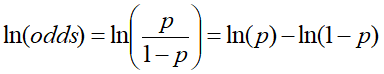
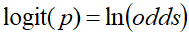
logit(p) 的图像,定义域是[0, 1], 值域是R;
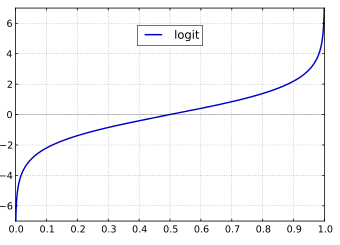
转换成定义域为R,值域为[0, 1],对logit 求反函数,用z 表示p
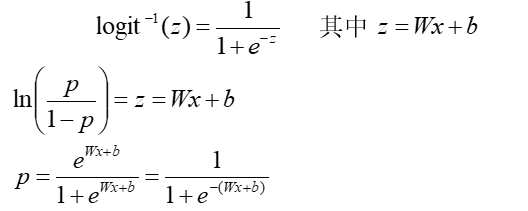
排序阶段的建模(对观看时间):
- 正样本用观看时间赋予权值,负样本赋予单位权值(即不加权)
- 每个展示impression的观看时长的期望为
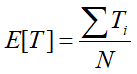
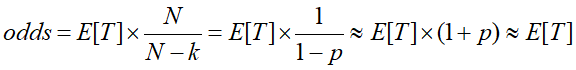
- p = k/ N
- N代表样本总数,k代表正样本数量,Ti是第i正样本的观看时长。k比N小,因此公式中的odds可以转换成E[T](1+P),其中P是点击率,点击率一般很小,所以odds接近于E[T],即期望观看时长。因此在线上serving阶段,YouTube采用 作为激励函数 => 近似的估计期望的观看时长。
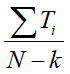
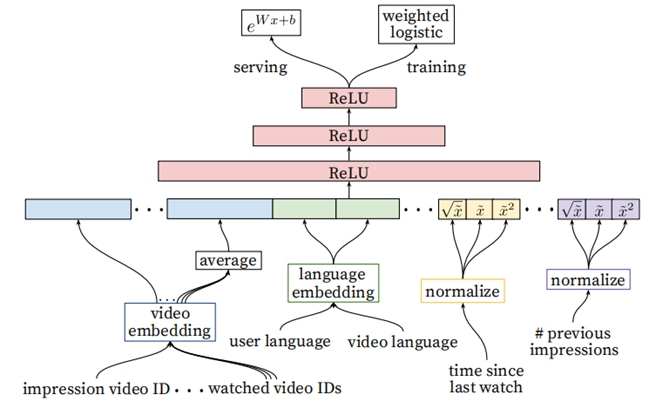
排序阶段中的特征工程(Feature Engineering):
- 尽管DNN能够减轻人工特征工程的负担,但是依然需要花费精力将用户及视频数据转化为有效的特征(参考Facebook提出的GBDT+LR模型)
- 难点在于对用户行为序列建模,并关联视频打分机制
- 用户对于某Channel的历史行为很重要,比如浏览该频道的次数,最近一次浏览该频道距离现在的时间
- 把召回阶段的信息传播到Ranking阶段同样能提升效果,比如推荐来源和所在来源的分数
排序阶段中的分类特征Embedding(Embedding Categorical Features):
- 采用embedding的方式映射稀疏离散特征为密集向量,YouTube为每一个类别特征维度生成一个独立的embedding空间
- 对于相同域的特征可以共享embedding,好处在于加速迭代,降低内存开销
排序阶段中的连续特征归一化(Normalizing Continuous Features):
- 神经网络对于输入数据的规模和分布非常敏感,而决策树模型(GBDT,RF)对于各个特征的缩放是不受什么影响
- 连续特征进行归一化对于收敛很重要
- 设计一种积分函数将特征映射为一个服从[0,1)分布的变量。一个符合f分布的特征x,等价转化成
- 除了输入归一化 ,还输入 的平方根和平方,特征的子线性和超线性,会让网络有更强的表达能力(输入连续特征的幂值,被证明是能提高离线精度的)
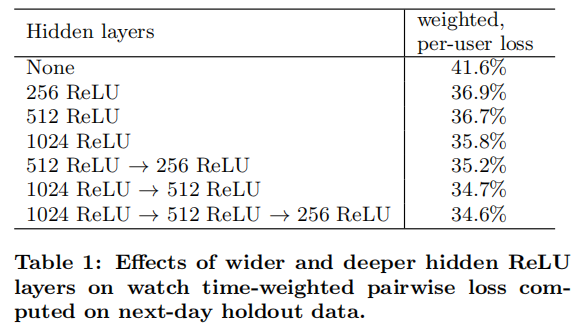
Hideden Layers实验:
- 在单个页面上,对展示给用户的正例和负例的这两个impression进行打分,如果对负例打分高于正例打分的话,那么我们认为对于正例预测的观看时间属于错误预测的观看时间
- YouTube定义了模型评估指标weighted,per-user loss,即错误预测的观看时间占比总的观看时间的比例。
- 对每个用户的错误预测loss求和即可获得该用户的loss
- 实验证明,YouTube采用的Tower塔式模型效果最好,即第一层1024,第二层512,第三层256
-
Summary
召回阶段完成快速筛选(几百万=>几百个),排序阶段完成精排(几百个=>十几个)
基于DNN模型完成召回,排序阶段,自动学习item的embedding特征
DNN的任务是基于用户信息和上下文环境,来学习用户的embedding向量,模拟矩阵分解的过程,DNN最后一层的输出近似作为用户的特征
特征embedding:
- 将用户观看过的视频id列表做embedding,取embedding向量的平均值,作为watch vector
- 把用户搜索过的视频id列表做embedding,取embedding向量的平均值,作为search vector
- 用户的人口统计学属性做embedding,作为geographic embedding
- 一些非多值类的特征如性别,还有数值类特征直接做DNN的输入
- 一些数值类特征,对其进行变换。如对example age进行平方,平方根操作,作为新的特征。
- 把推荐问题转换成多分类问题,采用Negative Sampling提升模型效果(随机从全量样本中抽取用户没有点击过的item作为label=0,因为推荐列表页中展示的item是算法模型计算出来的 => 用户最有可能会点击的item)
- 在召回阶段,采用的近似最近邻查找 => 提升效率
- Youtube的用户对新视频有偏好,引入Example Age(视频上传时间特征) => 与经验分布更Match
- 不对称的共同浏览问题,采用predicting next watch的方式,利用上文信息,预估下一次浏览的视频 => 从用户的历史视频观看记录中随机拿出来一个作为正样本,然后只用这个视频之前的历史观看记录作为输入
- 对每个用户提取等数量的训练样本 => 防止一部分非常活跃的用户主导损失函数值
- 针对某些特征,比如#previous impressions,进行平方和平方根处理,引入3个特征对DNN进行输入 => 简单有效的特征工程,引入了特征的非线性
- 在优化目标上,没有采用经典的CTR,或者Play Rate,而是采用了每次曝光预期播放时间作为优化目标
Thinking1:Wide & Deep的模型结构是怎样的,为什么能通过具备记忆和泛化能力(memorization and generalization)
Thinking2:在CTR预估中,使用FM与DNN结合的方式,有哪些结合的方式,代表模型有哪些?
Thinking3:为什么YouTube采用期望观看时间作为评估指标
Action1:使用Wide&Deep模型对movielens进行评分预测
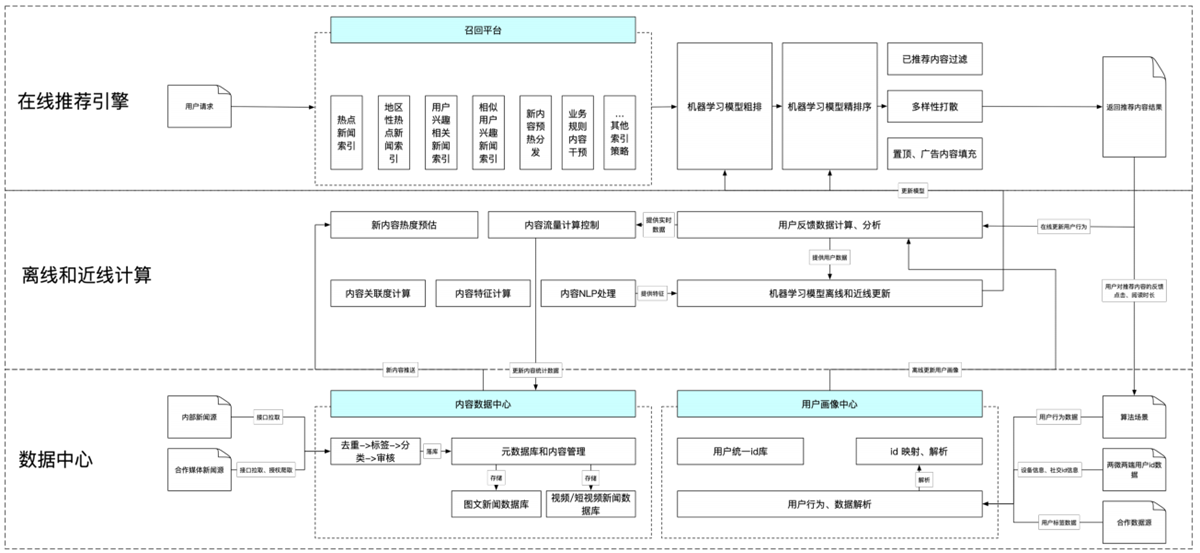
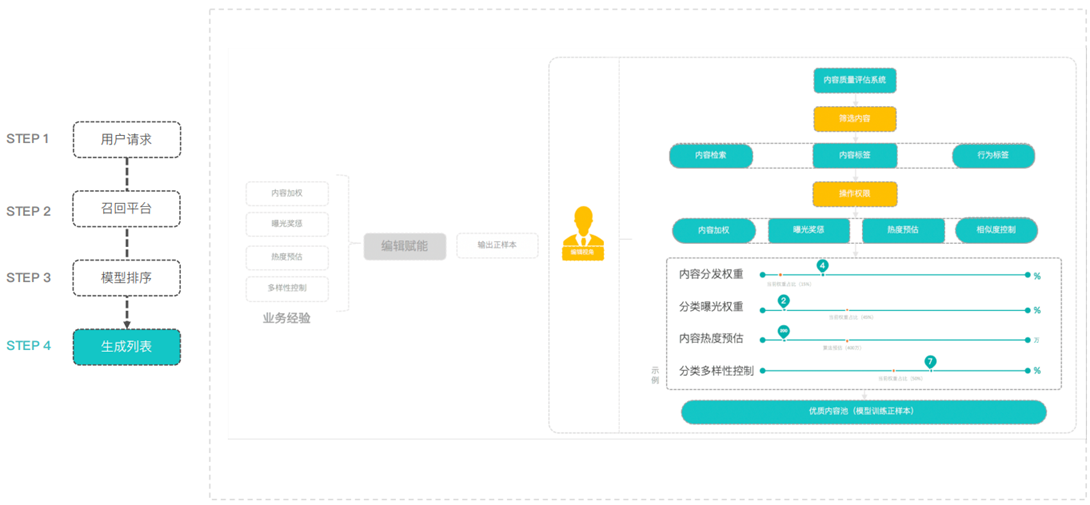
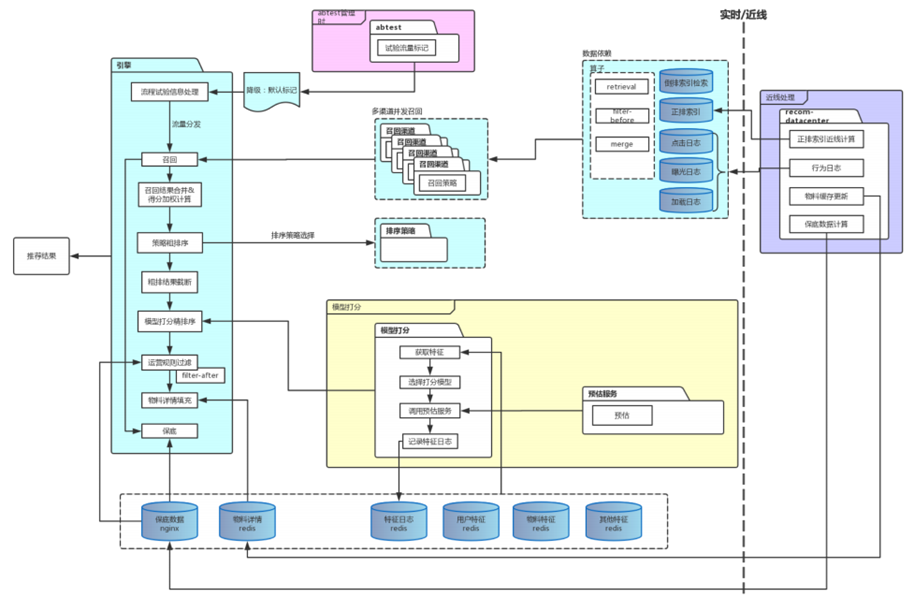
2. 推荐系统的架构
推荐系统的架构
在线部分,召回阶段将100万的item=>1000,item太多还可以进行粗排。排序阶段使用相对复杂的模型对较少的item进行排序。在呈现给用户前,还会集合一些业务策略(去掉用户已读,商业化广告)
近线部分,实时收集用户行为反馈,并选择训练实例,抽取特征=>更新在线推荐模型
离线部分,整理离线训练数据 => 周期性更新推荐模型


 浙公网安备 33010602011771号
浙公网安备 33010602011771号