
七. 文本分类| 情感分析系统项目
情感分析系统
情感分析任务
情感分析是一个经典的文本分析任务,在工业界有着非常广泛的应用。从任务的角度来讲,它的输入为一段文本,输出为某一个特定的情感分类如正面、负面或者中性。 任务本身属于文本分类任务,所
以需要使用分类算法。
情感分析的一个经典的应用场景为舆情监控。比如一个公司推出了一款产品,然后想去分析市场用户对此产品的意见,这时候可以先基于爬虫技术来获取网上的用户评论,然后再利用分类算法来自动把
评论分为正面或者负面,最终再通过整合来获取最后的结果。
另外一种应用场景为量化投资。在量化投资里,我们一般使用模型对未来的股市做预测,然后再进行买卖的决策。其中一个重要的策略是舆情,就是实时去了解股民对目前市场的情绪,然后再根据整体
舆情的走势来进行对未来股票的买卖决策。
文本分析流程
分词(分为每个单词), 特征提取(文本转化为向量的形式)
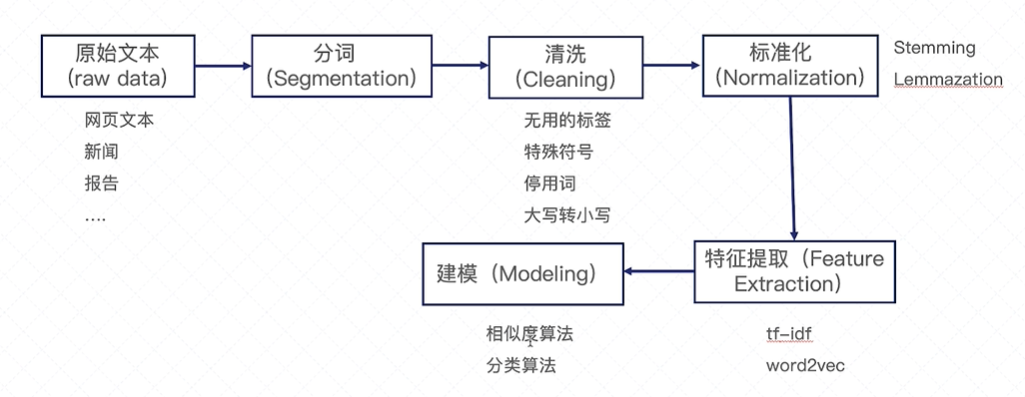
1. 文本预处理技术
分词、词的过滤、Stemming等操作。
文本分词
分词是最基本的第一步。无论对于英文文本,还是中文文本都离不开分词。英文的分词相对比较简单,因为一般的英文写法里通过空格来隔开不同单词的。
但对于中文,我们不得不采用一些算法去做分词。

常用的分词工具
上面列出了几个常用的分词工具,其中最常用的还是Jieba(结巴)分词,又快又有效。结巴分词的使用法非常简单,下面一个简单的代码示例。
# encoding=utf-8
import jieba
# 基于jieba的分词 参考: https://github.com/fxsjy/jieba
seg_list = jieba.cut("完善政策体系工作体系制度体系,以更有力的举措汇聚更强大的力量", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list))
# 在jieba中加入"住着"关键词
jieba.add_word("住着")
seg_list = jieba.cut("村路宽敞路灯亮堂,村子整洁鲜花苗木遍布,看着舒心住着舒服", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list))
------>
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\kris\AppData\Local\Temp\jieba.cache
Default Mode: 完善/ 政策/ 体系/ 工作/ 体系/ 制度/ 体系/ ,/ 以/ 更/ 有力/ 的/ 举措/ 汇聚/ 更/ 强大/ 的/ 力量
Default Mode: 村路/ 宽敞/ 路灯/ 亮堂/ ,/ 村子/ 整洁/ 鲜花/ 苗木/ 遍布/ ,/ 看着/ 舒心/ 住着/ 舒服
Loading model cost 0.653 seconds.
Prefix dict has been built successfully.
一般情况下,我们还是要定义属于自己的专有名词的。如果我们考虑的是医疗领域,则需要把医疗领域我们比较关注的词先加入到词库里,再通过结巴工具做分词,毕竟很多的专有词汇并不存在于结巴
的词库里。大部分情况下只需要使用工具去分词就可以了,没必要自己造轮子。但有一些特殊情况,比如这些开源工具的效果很一般,或者它们缺少某些方面的考虑,则可能需要自己写一个分词工具。
实际上,自己写一个分词工具也不难,可以基于HMM, CRF等方法来构造分词器。
单词的过滤
接下来,我们一般做单词的过滤或者字符的过滤。比如把一些出现次数特别多的单词过滤掉也叫作停用词的过滤,或者把那些出现次数特别少的单词过滤掉,或者把一些特殊符号比如#@过滤掉。
对于文本的应用,我们通常先把停用词、出现频率很低的词汇过滤掉;这其实类似于特征筛选的过程。
去掉停用词, 在英文里,比如“the”、“an”、“their”这些都可以作为停用词来处理。但是,也需要考虑自己的应用场景。
什么叫停用词呢? 其实很容易理解: 就是那些出现特别频繁,但对于一个句子贡献不是特别大的单词。比如”的“, ”他“可以认为是停用词。去掉停用词的方法也超级简单,就是提前设计好停用词库,然后
做文本分析时把这些停用词忽略掉就可以了。
停用词库的构建可以有三种方法:
- 第一、手动去设置停用词库,把所有的停用词写入一个文件。这个过程比较耗费时间,但对于非常垂直类的应用还是最有效的。
- 第二、从网上搜索停用词库,一般来讲网络上可以找到大部分语言的停用词库,这些都是别人已经整理好的,所以基本都是通用的。但有些时候确实由于应用本身的特点,这些停用词库可能还满足不了需求。所以,这时候需要适当地加入一些人工方式来整理的单词。
- 第三、从第三方工具中导入停用词库,比如NLTK这些工具已经集成了不同语言的停用词库,所以使用的时候直接调用就可以了。
# 方法1: 自己建立一个停用词词典
stop_words = ["the", "an", "is", "there"]
# 在使用时: 假设 word_list包含了文本里的单词
word_list = ["we", "are", "the", "students"]
filtered_words = [word for word in word_list if word not in stop_words]
print (filtered_words)
# 方法2:直接利用别人已经构建好的停用词库
from nltk.corpus import stopwords
cachedStopWords = stopwords.words("english")
print(cachedStopWords)
-------->>
['we', 'are', 'students']
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
过滤出现频率低的单词
出现频率特别低的词汇对分析作用不大,所以一般也会去掉。把停用词、出现频率低的词过滤之后,即可以得到一个词典库。
除了停用词,我们也通常会去掉出现次数特别少的单词,毕竟这些单词的频次太低,对整个训练来说起到的作用也不大。那如何去制定什么样的单词才叫作出现次数少的呢?
这里其实没有一个标准答案,还是需要去了解一下每个单词出现的次数,从而再去判断这个阈值。一般来讲,比如一个单词出现少于10次或者20次,我们可以归类为是可以去掉的单词。 但这个也取决于
手里的语料库大小。如果语料库本身总共只包含了不到一千个单词,那这个阈值显然有点高了。对于特殊符号,我们也需要做一些处理。特殊符号其实就是我们觉得不太有用的符号。比如一个文章里出
现的@#&,这些可以认为是特殊符号,进而可以去掉。
假如我们解决文本分类问题, 那文本中出现的数字如何处理比较合适?
把所有的数表示成一个特殊单词比如#num#
首先,数字本身是有意义的,至少说明这个是一个“数字“, 但具体是什么数字其实很难把它表示出来。为什么呢? 因为数字不像单词有一个完整的可以提前定义好的库。数字本身是无穷多的,我们没有办法把所
有的都列出来。而且具体是什么数对于理解文本来说意义没有那么大。基于这些理由,我们通常把出现的所有的数表示成一个统一的特殊符号比如"#NUM",这样至少我们的模型知道这是一个数字。
词的标准化操作
对于英文文本,我们通常会做单词标准化的操作,也就是把类似含义的单词统一表示成一种形式。这里有两种常用的方法,分别是stemming和lemmazation。


这些标准化的操作一般应用于英文等语言上,但对于中文用的不多,也是因为中文本身的特点不像英文那样有一种固定的格式比如单数或者复数。做完这些预处理工作之后,我们就可以开始对文本本身
做处理了,也就是把文本表示成向量的形式,之后再把它放入模型当中。那如何把文本表示成向量呢?
2. 文本表示与tf-idf
如何把文本信息表示成向量的形式,这里包括对单词的表示,也包括对句子的表示。

单词的表示了解完了,接下来就要考虑如何表示一个句子了。 这里有几种常用的方法,分别是boolean表示、 count表示以及 tf-idf的表示。
booblean表示法,true为1,false为0
都是七维的向量

这样的表示方法使得向量非常地稀疏,只有一个位置是1,剩下的全是0,而且向量的长度等于词库的长度,也就是我们的词库有多大,每一个单词向量的长度就有多大。这种方式虽然很简单,但明显
也有个缺点,就是不考虑一个单词出现的次数。出现次数越多,有可能对句子的贡献也会越大。我们希望把这部分信息也考虑进去。
count表示法
单词出现的个数

tf-idf 的表示
下面句子的表示是否有问题 ?

这种表示法 出现次数多的单词未必是最重要的。
其实上面的表示法是有些问题的,因为出现次数越多代表不了它就越重要,有可能反倒是更不重要。
所以呢, 我们希望把一个单词的重要性也考虑进去, 而不仅仅考虑单词出现的次数。这个新的方法叫作tf-idf表示法。

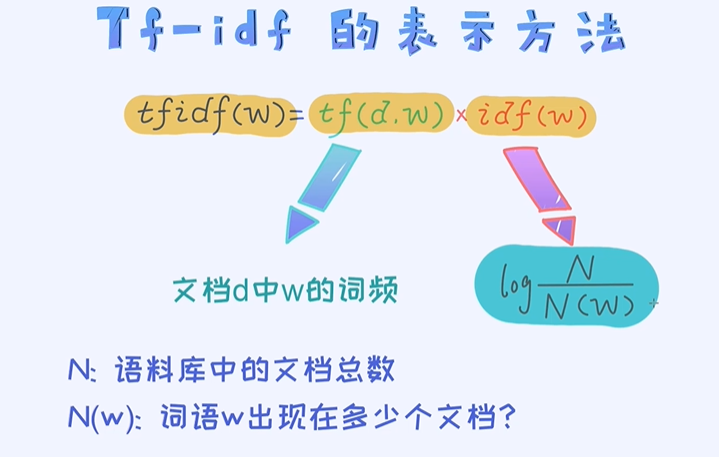
tf - idf 表示法
tf(d, w) 是单词w在文档d中出现了多少次;
idf(w) 是单词的重要性,单词出现次数越小权重越大,log起到一个平滑的作用,不想其中某个变得特别大;分子为整个文档的个数,分母为这个单词在几个文档里出现了;

文本相似度比较
在文本分析领域,还有一个工作特别重要,就是计算两个文本之间的相似度。计算相似度是理解文本语义来说也是很重要的技术,因为一旦我们理解了某一个单词或者句子,我们可以通过相似度计算方
法来寻找跟这个语义类似的单词或者文本。计算文本相似度有很多种方法,这里我们重点来讲解两个方法:计算欧式距离的方法和计算余弦相似度的方法。它们都可以用来评估文本的相似度,但前者是基
于距离的计算,后者是基于相似度的计算。需要注意的一点是: 距离越大相似度越小。
欧氏距离一定是正数,因为有个开根号;距离越大相似度越小;距离越小相似度越大;

余弦相似度
余弦相似度考虑了向量的方向,夹角越小相似度越大,余弦相似度的核心就是计算两个向量的夹角;
cos sin(x, y) 值越大它俩的相似度越大;

欧式距离简单且有效,但实际上用得其实并太多。目前来看,用的最多的方法仍然是余弦相似度的计算方法。
3. 分布式表示与Word2Vec
词独热编码表示的缺点,以及词向量相关的技术。


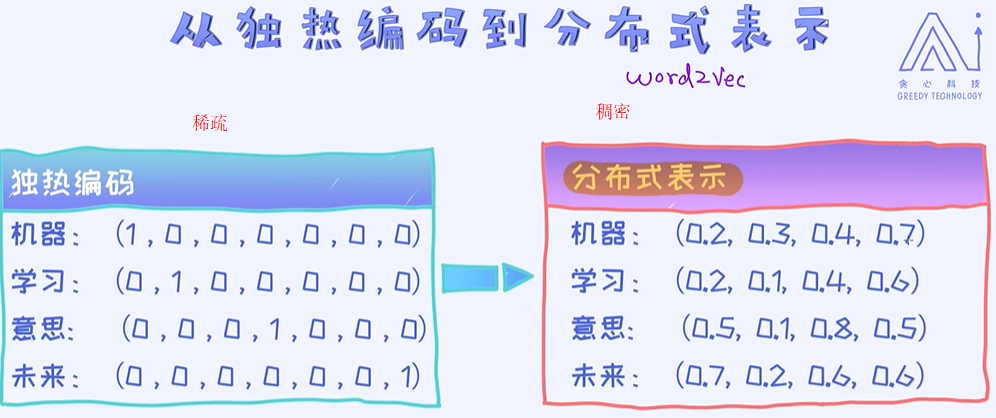
在独热编码下,我们有没有可能计算出两个单词之间的语义相似度?
在独热编码的前提下是没有办法计算出俩俩单词之间的相似度的,我们必须要借助于另外一种单词的表示法。

从独热编码到词向量
在独热编码的情况下是没有办法实现语义相似度评估的。不管使用欧式距离、余弦相似度还是其他的计算方法都没有办法比较出两个单词之间的相似度。所以,这就意味着我们必须要改变单词的表示方
法,也就是除了独热编码的形式,需要探索其他的方法论。幸运的是,确实存在这样的一个方法论叫作分布式表示法(Distributional Representation),也叫word2vec ;
使用分布式表示,利用余弦相似度计算语义相似度;

词向量在二维空间中的可视化
可以把学出来的词向量可视化在二维空间里。当然,可视化之前我们需要做降维处理的。对于词向量的降维,最经典的方法叫做T-SNE, 具体可以查一下网上的资料。 sklearn里也集成了此方法。
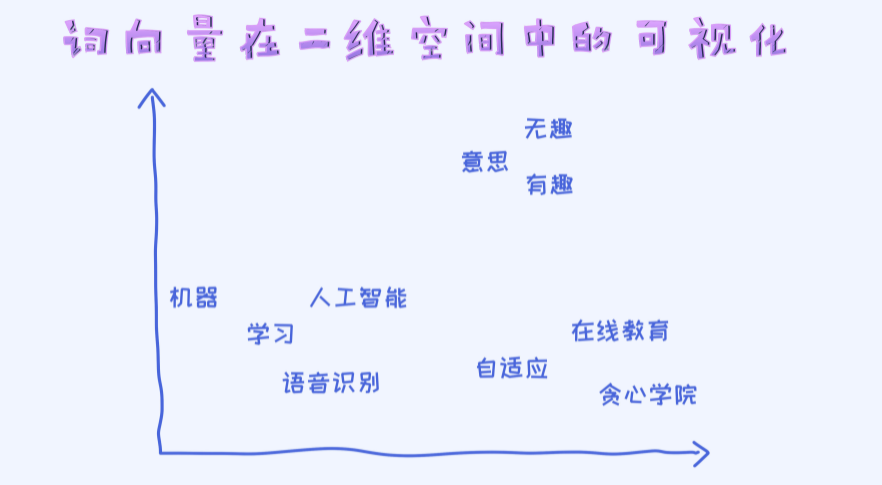
当我们把词向量可视化之后即可以发现很多拥有类似含义的单词都聚在一起。 比如”人工智能”和“学习”, “有趣”和“无趣”等。从这个角度,我们也可以理解为词向量确实能用来表示语义的相似度。
词向量的学习
如何学习每一个单词的分布式表示(词向量) ?
词向量的训练
具体训练词向量的方法很多,各有各的优缺点。在这里,我们就把它当作是一个黑盒子就可以了。而且网上有大量已经训练好的词向量,我们可以直接把它拿过来用。
训练词向量模型的有NNLM、CBow/SkipGram、Glaove、MF、Gaussian Ebedding、ELuo、Berf、XLNef等
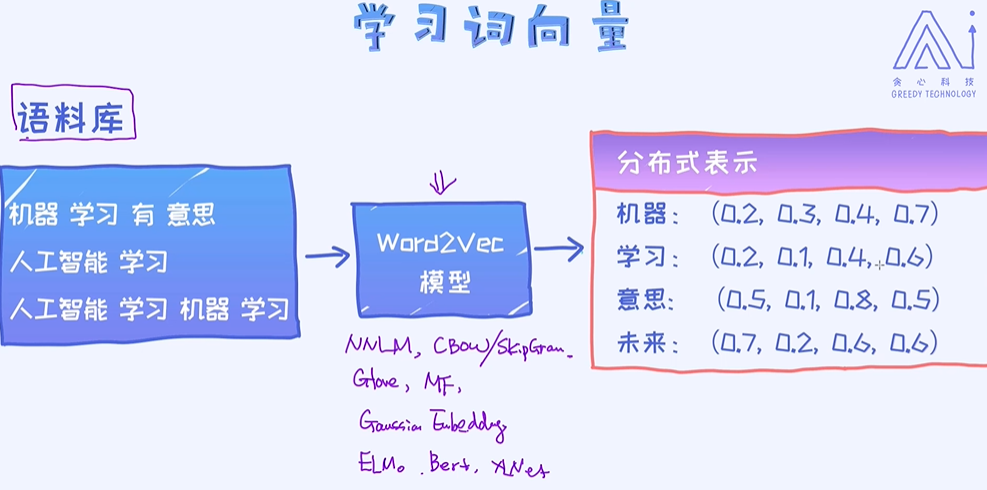
从词向量到句子向量
理解了如何通过词向量来表示一个单词之后,接着我们来看一下如何表示一个句子? 这里给出最为简单的方法,就是平均法,也叫作average pooling。
把每个维度相加,比如0.2+0.2+0.7=1.1,除以3得到句子向量 ;

简单来讲,给定单词的向量,我们通过平均法则即可得出包含若干个单词的句子向量, 接着再使用句子向量去做分类模型。
另外,词向量和分布式表示法有一个很重要的区别,我把它叫作容量上的差异。
比较两种表示法的容量
- Q: 100维的独热表示法最多可以表达多少个不同的单词?
- Q: 100维的分布式表示法最多可以表达多少个不同的单词?
假如我们用100维来表示单词,则在独热编码的情况下我们最多能表示100个不同的单词。 但是在分布式表示法的情况下可以表示无穷多个单词。从这里也可以看出两个表示方法在容量上的差异。
4. 项目案例
本项目的目标是基于用户提供的评论,通过算法自动去判断其评论是正面的还是负面的情感。比如给定一个用户的评论:
- 评论1: “我特别喜欢这个电器,我已经用了3个月,一点问题都没有!”
- 评论2: “我从这家淘宝店卖的东西不到一周就开始坏掉了,强烈建议不要买,真实浪费钱”
对于这两个评论,第一个明显是正面的,第二个是负面的。 我们希望搭建一个AI算法能够自动帮我们识别出评论是正面还是负面。
情感分析是文本处理领域经典的问题。整个系统一般会包括几个模块:
- 1.数据的抓取: 通过爬虫的技术去网络抓取相关文本数据
- 2.数据的清洗/预处理:在本文中一般需要去掉无用的信息,比如各种标签(HTML标签),标点符号,停用词等等
- 3.把文本信息转换成向量: 这也成为特征工程,文本本身是不能作为模型的输入,只有数字(比如向量)才能成为模型的输入。所以进入模型之前,任何的信号都需要转换成模型可识别的数字信号(数字,向量,矩阵,张量...)
- 4.选择合适的模型以及合适的评估方法。 对于情感分析来说,这是二分类问题(或者三分类:正面,负面,中性),所以需要采用分类算法比如逻辑回归,朴素贝叶斯,神经网络,SVM等等。另外,我们需要选择合适的评估方法,比如对于一个应用,我们是关注准确率呢,还是关注召回率呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号