
端到端的Exactly Once| Kafka的事务和幂等性| Flink的Exactly Once
1. Kafka的事务和 Exactly Once
Kafka 中的事务,它解决的问题是,确保在一个事务中发送的多条消息,要么都成功,要么都失败。注意,这里面的多条消息不一定要在同一个主题和分区中,可以是发往多个主题和
分区的消息。Kafka 的这种事务机制,单独来使用的场景不多。更多的情况下被用来配合 Kafka 的幂等机制来实现 Kafka 的 Exactly Once 语义。这里面的 Exactly Once,和我们通
常理解的消息队列的服务水平中的 Exactly Once 是不一样的。
通常理解消息队列的服务水平中的 Exactly Once,它指的是,消息从生产者发送到 Broker,然后消费者再从 Broker 拉取消息,然后进行消费。这个过程中,确保每一条消息恰好传输一次,不重不丢。包括 Kafka 在内的几个常见的开源消息队列,都只能做到 At Least Once,也就是至少一次,保证消息不丢,但有可能会重复。做不到 Exactly Once。

那 Kafka 中的 Exactly Once 又是解决的什么问题呢?它解决的是,在流计算中,用 Kafka 作为数据源,并且将计算结果保存到 Kafka 这种场景下,数据从 Kafka 的某个主题中消费,在计算集群中计算,再把计算结果保存在 Kafka 的其他主题中。这样的过程中,保证每条消息都被恰好计算一次,确保计算结果正确。

比如,我们把所有订单消息保存在一个 Kafka 的主题 Order 中,在 Flink 集群中运行一个计算任务,统计每分钟的订单收入,然后把结果保存在另一个 Kafka 的主题 Income 里面。要保证计算结果准确,就要确保,无论是 Kafka 集群还是 Flink 集群中任何节点发生故障,每条消息都只能被计算一次,不能重复计算,否则计算结果就错了。这里面有一个很重要的限制条件,就是数据必须来自 Kafka 并且计算结果都必须保存到 Kafka 中,才可以享受到 Kafka 的 Excactly Once 机制。
可以看到,Kafka 的 Exactly Once 机制,是为了解决在“读数据 - 计算 - 保存结果”这样的计算过程中数据不重不丢,而不是我们通常理解的使用消息队列进行消息生产消费过程中的 Exactly Once。
Kafka 的事务是如何实现的
基于两阶段提交来实现的,但是实现的过程更加复杂。
首先说一下,参与 Kafka 事务的几个角色,或者说是模块。为了解决分布式事务问题,Kafka 引入了事务协调者这个角色,负责在服务端协调整个事务。这个协调者并不是一个独立的
进程,而是 Broker 进程的一部分,协调者和分区一样通过选举来保证自身的可用性。
和 RocketMQ 类似,Kafka 集群中也有一个特殊的用于记录事务日志的主题,这个事务日志主题的实现和普通的主题是一样的,里面记录的数据就是类似于“开启事务”“提交事务”这样
的事务日志。日志主题同样也包含了很多的分区。在 Kafka 集群中,可以存在多个协调者,每个协调者负责管理和使用事务日志中的几个分区。这样设计,其实就是为了能并行执行
多个事务,提升性能。
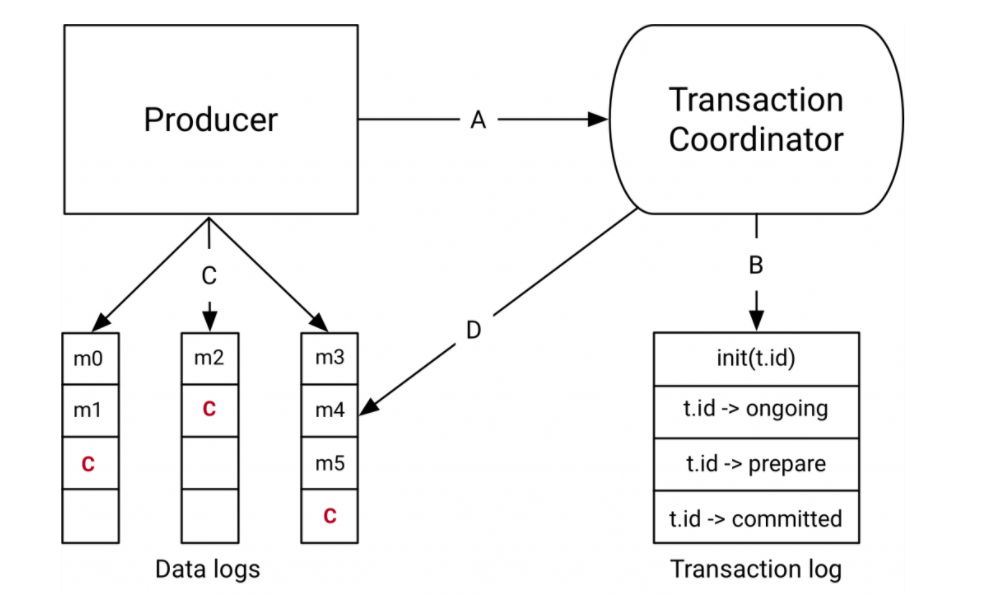
Kafka 事务的实现流程
首先,当我们开启事务的时候,生产者会给协调者发一个请求来开启事务,协调者在事务日志中记录下事务 ID。
然后,生产者在发送消息之前,还要给协调者发送请求,告知发送的消息属于哪个主题和分区,这个信息也会被协调者记录在事务日志中。
接下来,生产者就可以像发送普通消息一样来发送事务消息,这里和 RocketMQ 不同的是,RocketMQ 选择把未提交的事务消息保存在特殊的队列中,而 Kafka 在处理未提交的事务
消息时,和普通消息是一样的,直接发给Broker,保存在这些消息对应的分区中,Kafka 会在客户端的消费者中,暂时过滤未提交的事务消息。
消息发送完成后,生产者给协调者发送提交或回滚事务的请求,由协调者来开始两阶段提交,完成事务。第一阶段,协调者把事务的状态设置为“预提交”,并写入事务日志。到这里,
实际上事务已经成功了,无论接下来发生什么情况,事务最终都会被提交。
之后便开始第二阶段,协调者在事务相关的所有分区中,都会写一条“事务结束”的特殊消息,当 Kafka 的消费者,也就是客户端,读到这个事务结束的特殊消息之后,它就可以把之
前暂时过滤的那些未提交的事务消息,放行给业务代码进行消费了。最后,协调者记录最后一条事务日志,标识这个事务已经结束了。
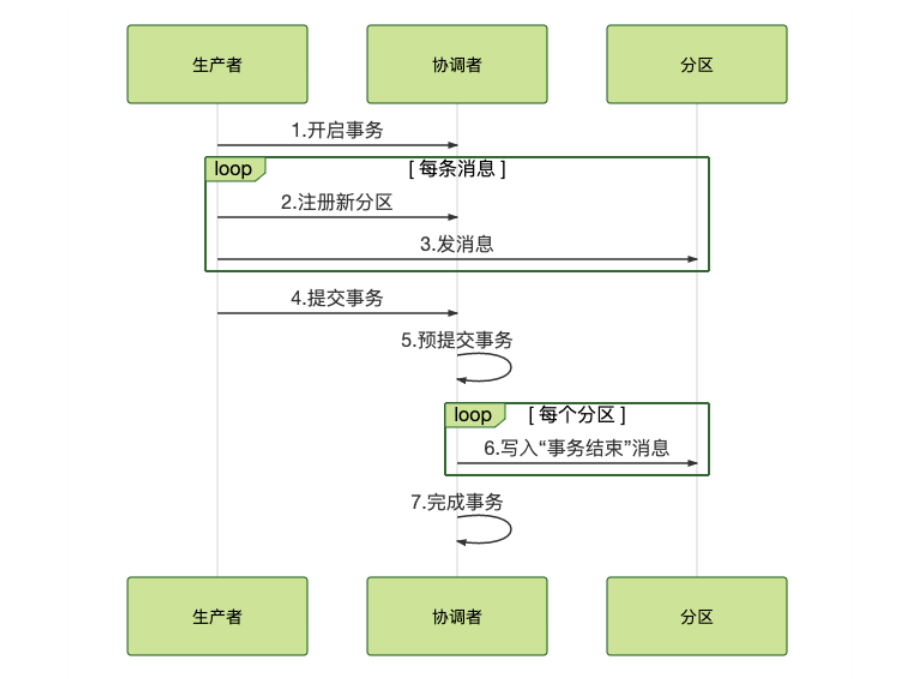
总结一下 Kafka 这个两阶段的流程,准备阶段,生产者发消息给协调者开启事务,然后消息发送到每个分区上。提交阶段,生产者发消息给协调者提交事务,协调者给每个分区发一
条“事务结束”的消息,完成分布式事务提交。
基于两阶段提交来实现的事务,都利用了特殊的主题中的队列和分区来记录事务日志。
对处于事务中的消息的处理方式, Kafka 直接把消息放到对应的业务分区中,配合客户端过滤来暂时屏蔽进行中的事务消息。
Kafka 的事务则是用于实现它的 Exactly Once 机制,应用于实时计算的场景中。
其实kafka的Exactly Once模式,是kafka的consumer通过PID去实现了一个幂等操作,原理上来说是和at last once我们业务自己通过其他唯一ID实现幂等是一样的效果,并不是正真的
只传输到客户端一次,而是重复传输实现了幂等。
事务结束消息就是一条特殊的消息,和普通消息一样保存在分区中。同普通消息一样,事务结束消息只要不被删除,就会一直存在。
大量未提交消息对客户端内存影响不大,因为Kafka客户端有一个固定大小的buffer用来保存拉取的消息。
只要你遵循:先执行消费业务逻辑,再提交,这样的原则。即使客户端重启或者Rebalance,也不会丢消息。
“消息发送完成后,生产者给协调者发送提交或回滚事务的请求,由协调者来开始两阶段提交,完成事务。第一阶段,协调者把事务的状态设置为“预提交”,并写入事务日志。到这里,实际上事务已经成功了,无论接下来发生什么情况,事务最终都会被提交。”假如协调者执行完第一阶段之后还没有执行第二阶段,这时候机器宕机或者进程被KILL掉了,重启之后还是会继续执行第二阶段。
2. 在流计算中使用Kafka链接计算任务
大部分流计算平台都会采用存储计算分离的设计,将计算任务的状态保存在 HDFS 等分布式存储系统中。每个子任务将状态分离出去之后,就变成了无状态的节点,如果某一个计算
节点发生宕机,使用集群中任意一个节点都可以替代故障节点。
但是,对流计算来说,这里面还有一个问题没解决,就是在集群中流动的数据并没有被持久化,所以它们就有可能由于节点故障而丢失,怎么解决这个问题呢?办法也比较简单粗暴,
就是直接重启整个计算任务,并且从数据源头向前回溯一些数据。计算任务重启之后,会重新分配计算节点,顺便就完成了故障迁移。
回溯数据源,可以保证数据不丢失,这和消息队列中,通过重发未成功的消息来保证数据不丢的方法是类似的。所以,它们面临同样的问题:可能会出现重复的消息。消息队列可以通
过在消费端做幂等来克服这个问题,但是对于流计算任务来说,这个问题就很棘手了。
对于接收计算结果的下游系统,它可能会收到重复的计算结果,这还不是最糟糕的。像一些统计类的计算任务,就会有比较大的影响,比如计算IP 地址在统计周期内被访问了 5 次,产生了 5 条访问日志,正确的结果应该是 5 次。如果日志被重复统计,那结果就会多于 5 次,重复的数据导致统计结果出现了错误。怎么解决这个问题呢?
Kafka 支持 Exactly Once 语义,它的这个特性就是为了解决这个问题而生的。如何使用 Kafka 配合 Flink,解决数据重复的问题,实现端到端的 Exactly Once 语义。
Flink 是如何保证 Exactly Once 语义的
我们所说的端到端 Exactly Once,这里面的“端到端”指的是,数据从 Kafka 的 A 主题消费,发送给 Flink 的计算集群进行计算,计算结果再发给 Kafka 的 B 主题。在这整个过程
中,无论是 Kafka 集群的节点还是 Flink 集群的节点发生故障,都不会影响计算结果,每条消息只会被计算一次,不能多也不能少。
在理解端到端 Exactly Once 的实现原理之前,需要先了解一下,Flink 集群本身是如何保证 Exactly Once 语义的。为什么 Flink 也需要保证 Exactly Once 呢?Flink 集群本身也是一个
分布式系统,它首先需要保证数据在 Flink 集群内部只被计算一次,只有在这个基础上,才谈得到端到端的 Exactly Once。
Flink 通过 CheckPoint 机制来定期保存计算任务的快照,这个快照中主要包含两个重要的数据:
- 整个计算任务的状态。这个状态主要是计算任务中,每个子任务在计算过程中需要保存的临时状态数据。
- 数据源的位置信息。这个信息记录了在数据源的这个流中已经计算了哪些数据。如果数据源是 Kafka 的主题,这个位置信息就是 Kafka 主题中的消费位置。
有了 CheckPoint,当计算任务失败重启的时候,可以从最近的一个 CheckPoint 恢复计算任务。具体的做法是,每个子任务先从 CheckPoint 中读取并恢复自己的状态,然后整个计算任务从 CheckPoint 中记录的数据源位置开始消费数据,只要这个恢复位置和 CheckPoint 中每个子任务的状态是完全对应的,或者说,每个子任务的状态恰好是:“刚刚处理完恢复位置之前的那条数据,还没有开始处理恢复位置对应的这条数据”,这个时刻保存的状态,就可以做到严丝合缝地恢复计算任务,每一条数据既不会丢失也不会重复。
因为每个子任务分布在不同的节点上,并且数据是一直在子任务中流动的,所以确保 CheckPoint 中记录的恢复位置和每个子任务的状态完全对应并不是一件容易的事儿,Flink 是怎
么实现的呢? Flink 通过在数据流中插入一个 Barrier(屏障)来确保 CheckPoint 中的位置和状态完全对应。下面这张图来自Flink 官网的说明文档。
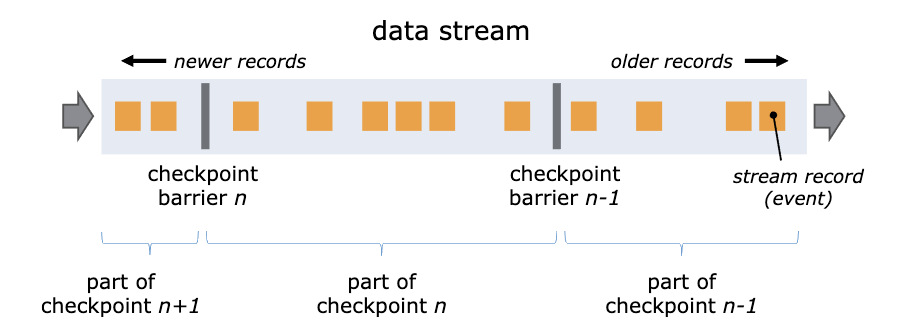
你可以把 Barrier 理解为一条特殊的数据。Barrier 由 Flink 生成,并在数据进入计算集群时被插入到数据流中。这样,无限的数据流就被很多的 Barrier 分隔成很多段。Barrier 在流经
每个计算节点的时候,就会触发这个节点在 CheckPoint 中保存本节点的状态,如果这个节点是数据源节点,还会保存数据源的位置。
当一个 Barrier 流过所有计算节点,流出计算集群后,一个 CheckPoint 也就保存完成了。由于每个节点都是在 Barrier 流过的时候保存的状态,这时的状态恰好就是 Barrier 所在位置
(也就是 CheckPoint 数据源位置)对应的状态,这样就完美解决了状态与恢复位置对应的问题。
Flink 通过 CheckPoint 机制实现了集群内计算任务的 Exactly Once 语义,但是仍然实现不了在输入和输出两端数据不丢不重。比如,Flink 在把一条计算结果发给 Kafka 并收到来自
Kafka 的“发送成功”响应之后,才会继续处理下一条数据。如果这个时候重启计算任务,Flink 集群内的数据都可以完美地恢复到上一个 CheckPoint,但是已经发给 Kafka 的消息却没
办法撤回,还是会出现数据重复的问题。所以,我们需要配合 Kafka 的 Exactly Once 机制,才能实现端到端的 Exactly Once。
Kafka 如何配合 Flink 实现端到端 Exactly Once?
Kafka 的 Exactly Once 语义是通过它的事务和生产幂等两个特性来共同实现的。Kafka 事务的实现原理,它可以保证一个事务内的所有消息,要么都成功投递,要么都不投递。
生产幂等这个特性可以保证,在生产者给 Kafka Broker 发送消息这个过程中,消息不会重复发送。这个实现原理与“检测消息丢失”的方法是类似的,都是通过连续递增的序号进行检
测。Kafka 的生产者给每个消息增加都附加一个连续递增的序号,Broker 端会检测这个序号的连续性,如果序号重复了,Broker 会拒绝这个重复消息。
Kafka 的这两个机制,配合 Flink 就可以来实现端到端的 Exactly Once 了。
简单地说就是,每个 Flink 的 CheckPoint 对应一个 Kafka 事务。Flink 在创建一个 CheckPoint 的时候,同时开启一个 Kafka 的事务,完成 CheckPoint 同时提交 Kafka 的事务。当计
算任务重启的时候,在 Flink 中计算任务会恢复到上一个 CheckPoint,这个 CheckPoint 正好对应 Kafka 上一个成功提交的事务。未完成的 CheckPoint 和未提交的事务中的消息都会
被丢弃,这样就实现了端到端的 Exactly Once。但是,怎么才能保证“完成 CheckPoint 同时提交 Kafka 的事务”呢?或者说,如何来保证“完成 CheckPoint”和“提交 Kafka 事务”这两个
操作,要么都成功,要么都失败呢?这不就是一个典型的分布式事务问题嘛!
所以,Flink 基于两阶段提交这个常用的分布式事务算法,实现了一分布式事务的控制器来解决这个问题。如果你对具体的实现原理感兴趣,可以看一下 Flink 官网文档中的这篇文章。
Exactly Once 版本的 Web 请求的统计
“统计 Web 请求的次数”的 Flink Job 改造一下,让这个 Job 具备 Exactly Once 特性。这个实时统计任务接收 NGINX 的 access.log,每 5 秒钟按照 IP 地址统计 Web 请求的次数。假
设我们已经有一个实时发送 access.log 的日志服务来发送日志,日志的内容只包含访问时间和 IP 地址,这个日志服务就是我们流计算任务的数据源。
改造之后,我们需要把数据的来源替换成 Kafka 的 ip_count_source 主题,计算结果也要保存到 Kafka 的主题 ip_count_sink 中。
整个系统的数据流向就变成下图这样:

日志服务将日志数据发送到 Kafka 的主题 ip_count_source,计算任务消费这个主题的数据作为数据源,计算结果会被写入到 Kafka 的主题 ip_count_sink 中。
Flink 提供了 Kafka Connector 模块,可以作为数据源从 Kafka 中消费数据,也可以作为 Kafka 的 Producer,将计算结果发送给 Kafka,并且,这个 Kafka Connector 已经实现了
Exactly Once 语义,我们在使用的时候只要做适当的配置就可以了。
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.AbstractDeserializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.runtime.state.StateBackend;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import java.io.File;
import java.nio.charset.StandardCharsets;
import java.text.ParseException;
import java.text.SimpleDateFormat
public class ExactlyOnceIpCount {
public static void main(String[] args) throws Exception {
// 设置输入和输出
FlinkKafkaConsumer011<IpAndCount> sourceConsumer = setupSource();
FlinkKafkaProducer011<String> sinkProducer = setupSink();
// 设置运行时环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); // 按照EventTime来统计
env.enableCheckpointing(5000); // 每5秒保存一次CheckPoint
// 设置CheckPoint
CheckpointConfig config = env.getCheckpointConfig();
config.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 设置CheckPoint模式为EXACTLY_ONCE
config.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 取消任务时保留CheckPoint
config.setPreferCheckpointForRecovery(true); // 启动时从CheckPoint恢复任务
// 设置CheckPoint的StateBackend,在这里CheckPoint保存在本地临时目录中。
// 只适合单节点做实验,在生产环境应该使用分布式文件系统,例如HDFS。
File tmpDirFile = new File(System.getProperty("java.io.tmpdir"));
env.setStateBackend((StateBackend) new FsStateBackend(tmpDirFile.toURI().toURL().toString()));
// 设置故障恢复策略:任务失败的时候自动每隔10秒重启,一共尝试重启3次
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
10000 // delay
));
// 定义输入:从Kafka中获取数据
DataStream<IpAndCount> input = env.addSource(sourceConsumer);
// 计算:每5秒钟按照ip对count求和
DataStream<IpAndCount> output = input
.keyBy(IpAndCount::getIp) // 按照ip地址统计
.window(TumblingEventTimeWindows.of(Time.seconds(5))) // 每5秒钟统计一次
.allowedLateness(Time.seconds(5))
.sum("count"); // 对count字段求和
// 输出到kafka topic
output.map(IpAndCount::toString).addSink(sinkProducer);
// execute program
env.execute("Exactly-once IpCount");
}
private static FlinkKafkaProducer011<String> setupSink() {
// 设置Kafka Producer属性
Properties producerProperties = new Properties();
producerProperties.put("bootstrap.servers", "localhost:9092");
// 事务超时时间设置为1分钟
producerProperties.put("transaction.timeout.ms", "60000");
// 创建 FlinkKafkaProducer,指定语义为EXACTLY_ONCE
return new FlinkKafkaProducer011<>(
"ip_count_sink",
new KeyedSerializationSchemaWrapper<>(new SimpleStringSchema()),
producerProperties,
FlinkKafkaProducer011.Semantic.EXACTLY_ONCE);
}
private static FlinkKafkaConsumer011<IpAndCount> setupSource() {
// 设置Kafka Consumer属性
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "IpCount");
// 创建 FlinkKafkaConsumer
FlinkKafkaConsumer011<IpAndCount> sourceConsumer =
new FlinkKafkaConsumer011<>("ip_count_source",
new AbstractDeserializationSchema<IpAndCount>() {
// 自定义反序列化消息的方法:将非结构化的以空格分隔的文本直接转成结构化数据IpAndCount
@Override
public IpAndCount deserialize(byte[] bytes) {
String str = new String(bytes, StandardCharsets.UTF_8);
String [] splt = str.split("\\s");
try {
return new IpAndCount(new SimpleDateFormat("yyyy-MM-dd_HH:mm:ss").parse(splt[0]),splt[1], 1L);
} catch (ParseException e) {
throw new RuntimeException(e);
}
}
}, properties);
// 告诉Flink时间从哪个字段中获取
sourceConsumer.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<IpAndCount>() {
@Override
public long extractAscendingTimestamp(IpAndCount ipAndCount) {
return ipAndCount.getDate().getTime();
}
});
return sourceConsumer;
}
}
定义数据源、定义计算逻辑和定义输入这三大步骤。下面主要来说不同之处,这些不同的地方也就是如何配置 Exactly Once 特性的关键点。
首先,我们需要开启并配置好 CheckPoint。在这段代码中,我们开启了 CheckPoint,设置每 5 秒钟创建一个 CheckPoint。然后,还需要定义保存 CheckPoint 的 StateBackend,也
就是告诉 Flink 把 CheckPoint 保存在哪儿。在生产环境中,CheckPoint 应该保存到 HDFS 这样的分布式文件系统中。这个例子中,为了方便运行调试,直接把 CheckPoint 保存到
本地的临时目录中。之后,我们还需要将 Job 配置成自动重启,这样当节点发生故障时,Flink 会自动重启 Job 并从最近一次 CheckPoint 开始恢复。
我们在定义输出创建 FlinkKafkaProducer 的时候,需要指定 Exactly Once 语义,这样 Flink 才会开启 Kafka 的事务,代码如下:
private static FlinkKafkaProducer011<String> setupSink() {
// 设置Kafka Producer属性
Properties producerProperties = new Properties();
producerProperties.put("bootstrap.servers", "localhost:9092");
// 事务超时时间设置为1分钟
producerProperties.put("transaction.timeout.ms", "60000");
// 创建 FlinkKafkaProducer,指定语义为EXACTLY_ONCE
return new FlinkKafkaProducer011<>(
"ip_count_sink",
new KeyedSerializationSchemaWrapper<>(new SimpleStringSchema()),
producerProperties,
FlinkKafkaProducer011.Semantic.EXACTLY_ONCE);
}
在从 Kafka 主题 ip_count_sink 中消费计算结果的时候,需要配置 Consumer 属性:isolation.level=read_committed,也就是只消费已提交事务的消息。因为默认情况下,Kafka 的
Consumer 是可以消费到未提交事务的消息的。
小结
端到端 Exactly Once 语义,可以保证在分布式系统中,每条数据不多不少只被处理一次。在流计算中,因为数据重复会导致计算结果错误,所以 Exactly Once 在流计算场景中尤其重
要。Kafka 和 Flink 都提供了保证 Exactly Once 的特性,配合使用可以实现端到端的 Exactly Once 语义。
在 Flink 中,如果节点出现故障,可以自动重启计算任务,重新分配计算节点来保证系统的可用性。配合 CheckPoint 机制,可以保证重启后任务的状态恢复到最后一次 CheckPoint,
然后从 CheckPoint 中记录的恢复位置继续读取数据进行计算。Flink 通过一个巧妙的 Barrier 使 CheckPoint 中恢复位置和各节点状态完全对应。
Kafka 的 Exactly Once 语义是通过它的事务和生产幂等两个特性来共同实现的。在配合 Flink 的时候,每个 Flink 的 CheckPoint 对应一个 Kafka 事务,只要保证 CheckPoint 和 Kafka
事务同步提交就可以实现端到端的 Exactly Once,Flink 通过“二阶段提交”这个分布式事务的经典算法来保证 CheckPoint 和 Kafka 事务状态的一致性。
可以看到,Flink 配合 Kafka 来实现端到端的 Exactly Once 语义,整个实现过程比较复杂,但是,这个复杂的大问题是由一个一个小问题组成的,每个小问题的原理都是很简单的。比
如:Kafka 如何实现的生产幂等?Flink 如何通过存储计算分离解决子任务状态恢复的?
每一个小问题它面临的场景是什么样的,以及如何解决问题的方法。而不要拘泥于,Kafka 或者 Flink 的某个参数怎么配这些细节问题。这些问题可以等到你在生产中真正需要使用的
时候,再去读文档,“现学现卖”都来得及。
思考
在消息队列的消费端,一定要“先执行消费业务逻辑,再确认消费”,这样才能保证不丢数据。在 FlinkKafkaConsumer 在从数据源主题 ip_count_sink 消费数据之后,如何来确认消费的。如果消费位置管理不好,一样会导致消息丢失或者重复,查阅资料看一下 FlinkKafkaConsumer 是如何来确认消费的。
https://www.infoq.cn/article/58bzvIbT2fqyW*cXzGlG
Kafka Stream目前来说,相关的生态还不够成熟,可以了解一下,但不建议在生产系统中使用。
它和flink最大的区别是,它是一个库,运行在你的应用程序进程内,而不是一个流计算框架。
1、spark官方文档说,如果保存到checkpoint和把offset 提交到kafka,必须保证输出是幂等的,光使用事务是不行的;
2、那么如果无法保证输出是幂等的,是否只能把offset 保存在第三方的数据库(比如redis)中,但是这样做是否是不可以设置checkpoints ?否则spark依然会从checkpoint中读取,和从数据库中读取会造成冲突呢?
3、但不设置checkpoint,spark如何恢复现场呢?在提交命令时加入--supervise,好像yarn的模式不支持?即使使用supervise重启,没有checkpoint,也无法恢复现场吧?
A1:是这样的,所以Kafka的Exactly Once特性中是有事务和生产幂等(相当于流计算输出幂等)二个功能组成的。
A2:这个方法不太可行,因为你很难做到完美的故障恢复。
A3:具体操作细节层面的问题,建议你以官方的文档为准。
理论上是可以的,但是实际上hdfs没有原生事务支持,实现起来比较困难。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号