HashMap详解
1. 简介
(1)HashMap是基于hash表实现的,以k-v键值对方式存储数据,k-v封装在Node结点中
(2)key不允许重复,但可以为null,value可以重复,也可以为null。当get()方法返回null时,可以表示表中没有该键值,也可以表示该键值在表中对应的数据为null,所有不能用get()方法判断表中是否存在该键,可以使用containsKey()方法来判断
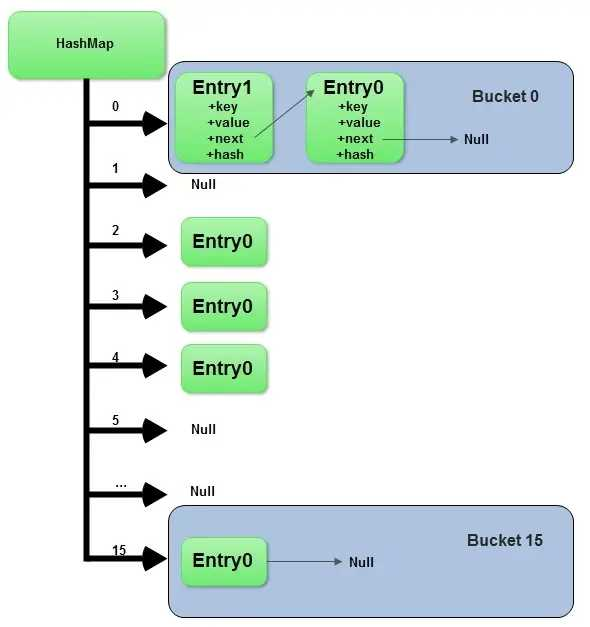
(3)HashMap底层结构为数组+链表+红黑树,数组table里面存储的是Node类型数据,Node实现了Map.entry接口,Node结点里面包括hash、key、value和next,相同hash值的数据会加在Node后面形成链表,当链表达到一定规模之后会树化形成红黑树
(4)HashMap结构图
2. put()实现原理
(1)将k-v封装到Node结点中
(2)调用k的hashCode()方法得到对应的hashCode值,再将hashCode值右移16位与之前的hashCode值做异或处理,得到最终的hash值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
(3)将hash值转化为数组下标:i = (n - 1) & hash
(4)通过数组下标寻找对应的数组位置,如果对应位置为空,则直接插入Node,如果对应位置不为空,则通过equals方法循环对链表中Node结点的k作比较,若返回true,则表示为同一个k,直接将v值替换,若返回false,则表示为不同的k,则将新的结点添加至链表末尾
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; //如果table表为空或者大小为0,则进行第一次扩容,大小为16
if ((p = tab[i = (n - 1) & hash]) == null) //将hash值转化为数组下标
tab[i] = newNode(hash, key, value, null); //如果数组下标对应table表中的位置为空,则创建一个新的Node用于保存k-v,并插入到该位置
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p; //如果hash相同,而且,准备加入的key与p所指Node的key值为同一个对象或者两者equals返回true,则不加入
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //判断p是不是一颗红黑树,如果是,则调用putTreeVal()方法进行添加
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null); //如果一直比较到链表末尾,则添加在链表末尾
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); //如果满足树化条件,则树化为红黑树
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break; //如果出现hash相同且equals返回true的情况,则直接break,退出循环
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value; //新的value值覆盖旧的value值
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount; //加入的结点数+1
if (++size > threshold)
resize(); //扩容
afterNodeInsertion(evict);
return null;
}
3. 扩容机制
(1)HashMap初始化table数组大小为16,装载因子为0.75,阈值为12
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
(2)如果数组大小达到12,则会进行第一次扩容,扩容后大小为32
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; //新数组大小为旧数组大小的2倍(用<<1实现)
}
(3)如果链表长度到达TREEIFY_THRESHOLD(默认为8),而且table数组长度到达MIN_TREEIFY_CAPACITY(默认为64),则会树化为红黑树,否则函数进行数组扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();

 浙公网安备 33010602011771号
浙公网安备 33010602011771号