

| 这个作业属于哪个课程 | 信安1912-软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 熟悉个人开发流程 |
正文
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 90 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 150 | 180 |
| Development | 开发 | 420 | 460 |
| · Analysis | · 需求分析 (包括学习新技术) | 150 | 90 |
| · Design Spec | · 生成设计文档 | 60 | 25 |
| · Design Review | · 设计复审 | 60 | 75 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 15 |
| · Design | · 具体设计 | 20 | 15 |
| · Coding | · 具体编码 | 150 | 150 |
| · Code Review | · 代码复审 | 30 | 45 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 120 | 180 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 60 |
| --- | · 合计 | 1340 | 1655 |
计算模块接口的设计与实现过程
jieba.cut
jieba是优秀的第三方中文词库,中文分词指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。实现中使用了jieba的精确模式,适合文本分析。
算法:
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)。
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合。
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
- 基于 TF-IDF 算法的关键词抽取
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 为待提取的文本
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight 为是否一并返回关键词权重值,默认值为 False
allowPOS 仅包括指定词性的词,默认值为空,即不筛选
jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
例:
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
效果:
【精确模式】: 我/ 来到/ 北京/ 清华大学、
Gensim 相似度查询(Similarity Queries)
使用similarities.Similarity类。该类的操作只需要固定大小的内存,因为将索引切分为多个文件(称为碎片)存储到硬盘上了。对九个语料库文档按照与该输入的关联性逆向排序,与现代搜索引擎不同,仅集中关注一个单一方面的可能的相似性——文本(单词)的语义关联性。没有超链接,没有随机行走静态排列,只是在关键词布尔匹配的基础上进行了语义扩展。
doc = "Human computer interaction"
vec_bow = dictionary.doc2bow(doc.lower().split())
vec_lsi = lsi[vec_bow] # convert the query to LSI space
print(vec_lsi)
[(0, -0.461821), (1, 0.070028)]
re.match
匹配字符串,过滤换行符和标点符号。
正则表达式:a-zA-Z0-9\u4e00-\u9fa5
re.match(u"[a-zA-Z0-9\u4e00-\u9fa5]", tags)
效果:对执行了分词后的数据,只保留英文a-zA-z、数字0-9和中文\u4e00-\u9fa5。
计算模块接口部分的性能改进
使用pycharm的profile插件对代码进行性能分析,找出瓶颈所在。测试结果由两部分构成,Statistcs(性能统计)和Call Graph(调用关系图)。
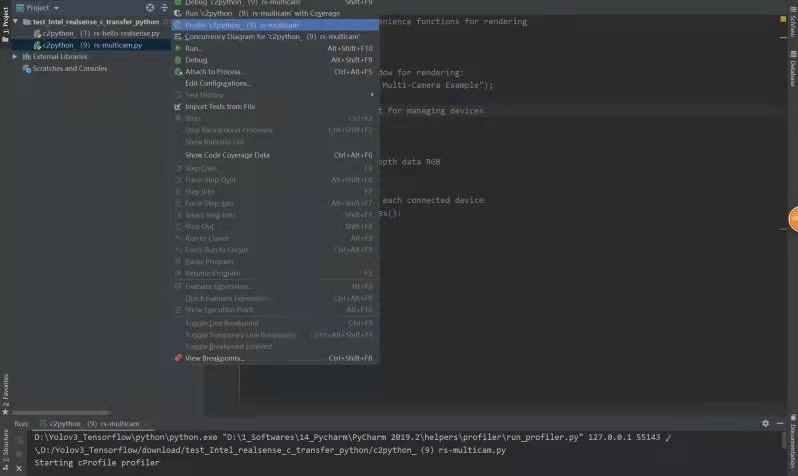

程序中消耗最大的函数:

有个函数循环了多次,花了很多时间,去掉函数后运行时间减少了几秒。
很多时候只需要某几个字段,全查取并非必要。改进了正则表达式,先匹配过滤后再使用结巴分词进行处理。
def part(string):
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]")
string = pattern.sub("", string)
result = jieba.lcut(string)
return result
计算模块部分单元测试展示
单元测试中使用了unittest框架,unittest是python自带的一个单元测试框架,类似于java的junit,基本结构是类似的。基本用法如下:
1.用import unittest导入unittest模块
2.定义一个继承自unittest.TestCase的测试用例类,如class xxx(unittest.TestCase):
3.定义setUp和tearDown,这两个方法与junit相同,即如果定义了则会在每个测试case执行前先执行setUp方法,执行完毕后执行tearDown方法。
4.定义测试用例,名字以test开头,unittest会自动将test开头的方法放入测试用例集中。
5.一个测试用例应该只测试一个方面,测试目的和测试内容应很明确。主要是调用assertEqual、assertRaises等断言方法判断程序执行结果和预期值是否相符。
6.调用unittest.main()启动测试
7.如果测试未通过,则会显示e,并给出具体的错误(此处为程序问题导致)。如果测试失败则显示为f,测试通过为.,如有多个testcase,则结果依次显示。
部分代码
from main import main_test
class test(unittest.TestCase):
def test_something(self):
self.assertEqual(main_test(),0.99)
测试结果
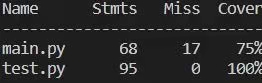
覆盖率
计算模块部分异常处理说明
python强大的库可以覆盖许多功能,在处理异常时,可以使用os.path.exists()方法检验文件,若文件不存在,则终止程序。
if not os.path.exists(path1) :
print("论文原文文件不存在!")
exit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号