动力节点Kafka
What is Kafka?


-
超过80%的财富100强公司信任并使用Kafka
-
Apache Kafka是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序;
谁在使用Kafka?

- 制造业:10个中有10个
- 银行:10个中有7个;
- 保险:10个中有10个;
- 电信:10个中有8个;

以上是每个行业使用Kafka的前十大公司的数量快照;
- 10/10最大的保险公司
- 10/10最大的制造公司
- 10/10最大的信息技术和服务公司
- 8/10最大的电信公司
- 8/10最大的运输公司
- 7/10最大的零售公司
- 7/10最大的银行和金融公司
- 6/10最大的能源和公用事业组织
Kafka的起源
- kafka最初由LinkedIn(领英:全球最大的面向职场人士的社交网站)设计开发的,是为了解决LinkedIn的数据管道问题,用于LinkedIn网站的活动流数据和运营数据处理工具;
- 活动流数据:页面访问量、被查看页面内容方面的信息以及搜索情况等内容;
- 运营数据:服务器的性能数据(CPU、IO使用率、请求时间、服务日志等数据);
- 刚开始LinkedIn采用的是ActiveMQ来进行数据交换,大约在2010年前后,那时的ActiveMQ还远远无法满足LinkedIn对数据交换传输的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了解决这个问题,LinkedIn决定研发自己的消息传递系统,当时LinkedIn的首席架构师 jay kreps 便开始组织团队进行消息传递系统的研发;
Kafka名字的由来
- 由于Kafka的架构师 jay kreps 非常喜欢franz kafka (弗兰茨·卡夫卡)(是奥匈帝国一位使用德语的小说家和短篇犹太人故事家,被评论家们认为是20世纪作家中最具影响力的一位),并且觉得Kafka这个名字很酷,因此把这一款消息传递系统取名为Kafka;
- 大师门取名字也是根据自己的喜好来取名,在我们看来有可能感觉很随意!
Kafka的发展历程
- 2010年底,Kafka在Github上开源,初始版本为0.7.0;
- 2011年7月,因为备受关注,被纳入Apache孵化器项目;
- 2012年10月,Kafka从Apache孵化器项目毕业,成为Apache顶级项目;
- 2014年,jay kreps离开LinkedIn,成立confluent公司,此后LinkedIn和confluent成为kafka的核心代码贡献组织,致力于Kafka的版本迭代升级和推广应用;
Kafka版本迭代演进
- Kafka前期项目版本似乎有点凌乱,Kafka在1.x之前的版本,是采用4位版本号;
- 比如:0.8.2.2、0.9.0.1、0.10.0.0...等等;
- 在1.x之后,kafka 采用 Major.Minor.Patch 三位版本号;
- Major表示大版本,通常是一些重大改变,因此彼此之间功能可能会不兼容;
- Minor表示小版本,通常是一些新功能的增加;
- Patch表示修订版,主要为修复一些重点Bug而发布的版本;
- 比如:Kafka 2.1.3,大版本就是2,小版本是1,Patch版本为3,是为修复Bug发布的第3个版本;
- Kafka总共发布了8个大版本,分别是0.7.x、0.8.x、0.9.x、0.10.x、0.11.x、1.x、2.x 及3.x 版本,截止目前,最新版本是Kafka 3.7.0,也是最新稳定版本;
Kafka运行环境前置要求
- Kafka是由Scala语言编写而成,Scala运行在Java虚拟机上,并兼容现有的Java程序,因此部署Kakfa的时候,需要先安装JDK环境;

Kafka源码: https://github.com/apache/kafka
Scala官网:https://www.scala-lang.org/
本地环境必须安装了Java 8+;(Java8、Java11、Java17、Java21都可以);
JDK长期支持版:https://www.oracle.com/java/technologies/java-se-support-roadmap.html
Kafka运行环境JDK安装
-
下载JDK:https://www.oracle.com/java/technologies/downloads/#java17
-
上传压缩包到虚拟机/root/soft/下,解压缩:
tar -zxvf jdk-17_linux-x64_bin.tar.gz -C /usr/local -
配置JDK环境变量:vim /etc/profile
export JAVA_HOME=/usr/local/jdk-17.0.7 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/ -
生效命令:
java --version 生效命令: source /etc/profile
Kafka的下载和安装
-
获取Kafka
- 下载最新版本的Kafka:https://kafka.apache.org/downloads
-
安装Kafka
tar -xzf kafka_2.13-3.7.0.tgz -C /usr/local/cd /usr/local/kafka_2.13-3.7.0
启动运行Kafka
-
启动Kafka环境
- 注意:本地环境必须安装了Java 8+;
- Apache Kafka可以使用ZooKeeper或KRaft启动;但只能使用其中一种方式,不能同时使用;
- KRaft:Apache Kafka的内置共识机制,用于取代 Apache ZooKeeper;
-
Kafka启动使用内置Zookeeper
-
1、启动zookeeper:
- 进入bin目录
cd /usr/local/kafka_2.13-3.7.0/bin- 后台启动zookeeper
./zookeeper-server-start.sh ../config/zookeeper.properties &- 通过如下命令查看是否启动成功
查看进程号: ps -ef | grep zookeeper 通过进程号查看占用端口: netstat -nlpt 通过进程好发现占用两端口:2181、一个不固定的端口 -
2、后台启动kafka:
./kafka-server-start.sh ../config/server.properties &通过如下命令查看是否启动成功
查看进程号: ps -ef | grep Kafka 通过进程号查看占用端口: netstat -nlpt 两端口:9092、一个不固定的端口 -
3、关闭Kafka:
./kafka-server-stop.sh ../config/server.properties -
4、关闭zookeeper:
./zookeeper-server-stop.sh ../config/zookeeper.properties
-
Zookeeper的下载和安装
-
获取Zookeeper
-
下载最新版本的Zookeeper:https://zookeeper.apache.org/
-
安装Zookeeper
tar -xzf apache-zookeeper-3.9.2-bin.tar.gz -C /usr/local/ cd /usr/local/apache-zookeeper-3.9.2-bin
Zookeeper的配置和启动
-
配置Zookeeper
cd /usr/local/apache-zookeeper-3.9.2-bin/conf cp zoo_sample.cfg zoo.cfgzoo.cfg 不需要修改,直接使用即可;
-
启动Zookeeper
-
启动:
进入bin目录下: cd /usr/local/apache-zookeeper-3.9.2-bin/bin 启动: ./zkServer.sh start 查看是否启动: 查看进程号: ps -ef | grep zookeeper 通过进程号查看占用端口: netstat -nlpt 占用3个端口:2181 8080 还有一个变化的 -
关闭:
./zkServer.sh stop -
Zookeeper启动默认会占用8080端口,修改配置文件,添加如下配置:
进入配置目录: cd /usr/local/apache-zookeeper-3.9.2-bin/conf 编辑: vim zoo.cfg 在最下面加上以下2行: #admin.serverPort默认占用8080端口 admin.serverPort=9089
-
使用独立的Zookeeper启动Kafka
-
启动Zookeeper:
进入Zookeeper的bin目录下: cd /usr/local/apache-zookeeper-3.9.2-bin/bin 启动: ./zkServer.sh start -
启动Kafka:
进入Kafka的bin目录下: cd /usr/local/kafka_2.13-3.7.0/bin 启动Kafka: ./kafka-server-start.sh ../config/server.properties & 查看是否正常启动: 查看进程号: ps -ef | grep zookeeper ps -ef | grep kafka 通过进程号查看占用端口: netstat -nlpt 关闭kafka: ./kafka-server-stop.sh ../config/server.properties 关闭zookeeper: cd /usr/local/apache-zookeeper-3.9.2-bin/bin ./zkServer.sh stop
使用KRaft启动运行Kafka
-
Kafka启动使用KRaft
-
1、生成Cluster UUID(集群UUID):
进入Kafka的bin目录下: cd /usr/local/kafka_2.13-3.7.0/bin 通过这个命令查看这个命令如何使用: ./kafka-storage.sh -h info 获取该节点上Kafka日志目录的信息。 format 格式化该节点上的Kafka日志目录。 random-uuid 打印一个随机UUID。 生成Cluster UUID(集群UUID),每次执行生成不重复的UUID: ./kafka-storage.sh random-uuid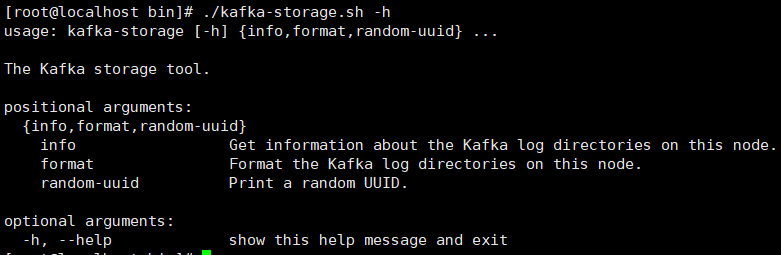
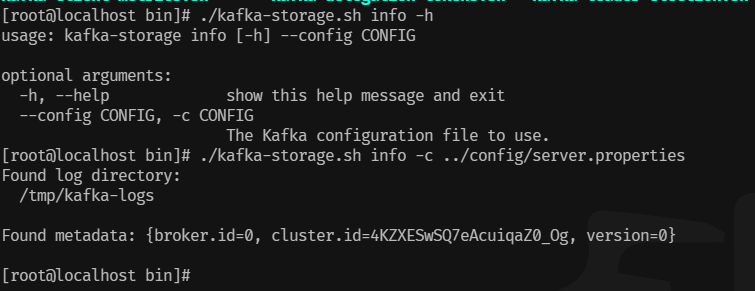
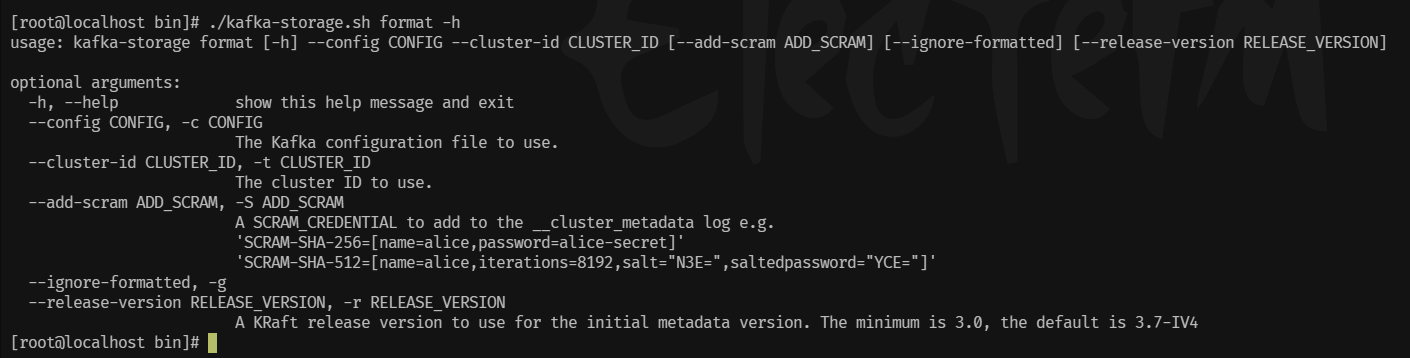
-
2、格式化日志目录(注意配置文件是kraft目录下的):
./kafka-storage.sh format -t Vej9AIzrTG2fHUAcq8WnCA -c ../config/kraft/server.properties -
3、启动Kafka,注意,配置文件是kraft目录里面的server.properties:
./kafka-server-start.sh ../config/kraft/server.properties & 可以看到开启了3个端口:9092,9093,一个不固定的端口 -
4、关闭Kafka:
./kafka-server-stop.sh ../config/kraft/server.properties -
5、实验格式化日志目录命令的uuid是否可以自己指定:
指定为abc123,报错RuntimeException: ./kafka-storage.sh format -t abc123 -c ../config/kraft/server.properties 根据错误提示查看文件里面的内容,可以看到uuid已经在上一步指定了: cat /tmp/kraft-combined-logs/meta.properties 进入文件夹: cd /tmp/kraft-combined-logs 删除里面的文件: rm -rf * 再次进入kafka的bin目录: cd /usr/local/kafka_2.13-3.7.0/bin 再次执行不报错: ./kafka-storage.sh format -t abc123 -c ../config/kraft/server.properties 再次查看集群ID: ./kafka-storage.sh info -c ../config/kraft/server.properties
-
使用Docker启动运行Kafka
-
Docker的卸载与安装:
-
安装前查看系统是否已经安装了Docker:
yum list installed | grep docker -
卸载Docker,根据上一步查询出来的名字进行指定,直到上一步命令执行没有结果(-y 自动确认):
yum remove docker.x86_64 -y yum remove docker-client.x86_64 -y yum remove docker-common.x86_64 -y -
安装Docker:
yum install docker -y 安装完毕后查看版本: docker -v注:这种方式安装的Docker版本比较旧;(查看版本:docker -v)
-
安装最新版的Docker:
再次卸载上面安装的docker 先安装yun-utils,如果已经安装过了,会提示Nothing to do: yum install yum-utils -y (如果需要卸载重装可以先执行:yum remove yum-utils -y)设置docker的镜像仓库: yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo 上面那个官网镜像目前执行不行了,从CSDN拿了一个阿里云镜像: yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo安装docker: yum install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -y -
查看是否安装成功:
查看docker版本:
docker --version(docker version,docker -v) -
Docker启动:
启动:systemctl start docker 或者 service docker start 停止:systemctl stop docker 或者 service docker stop 重启:systemctl restart docker 或者 service docker restart 检查Docker进程的运行状态:systemctl status docker 或者 service docker status 查看docker进程:ps -ef | grep docker 查看docker系统信息:docker info 查看所有的帮助信息:docker --help 查看某个commond命令的帮助信息:docker commond --help -
使用Docker镜像启动
-
拉取Kafka镜像:
docker pull apache/kafka:3.7.0 解决拉取不来kafka镜像问题: vim /etc/docker/daemon.json { "registry-mirrors": [ "https://docker.mirrors.sjtug.sjtu.edu.cn", "https://docker.m.daocloud.io", "https://noohub.ru", "https://huecker.io", "https://dockerhub.timeweb.cloud", "https://registry.cn-hangzhou.aliyuncs.com" ] } systemctl daemon-reload systemctl restart docker -
启动Kafka容器:
docker run -p 9092:9092 apache/kafka:3.7.0 -
新开一个窗口2查看已安装的镜像:
docker images -
删除镜像的命令:
docker rmi apache/kafka:3.7.0 -
查看Kafka是否启动成功
docker ps ps -ef | grep kafka
-
-
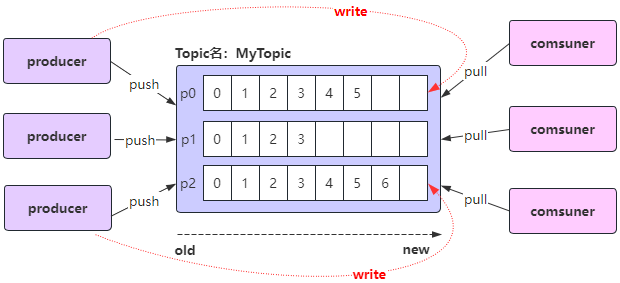
Kafka操作主题和事件
- 创建主题Topic
使用Kafka之前,第一件事情是必须创建一个主题(Topic)
- 主题(Topic)类似于文件系统中的文件夹;
- 主题(Topic)用于存储事件(Events)
- 事件(Events)也称为记录或消息,比如支付交易、手机地理位置更新、运输订单、物联网设备或医疗设备的传感器测量数据等等都是事件(Events);
- 事件(Events)被组织和存储在主题(Topic)中
- 简单来说,主题(Topic)类似于文件系统中的文件夹,事件(Events)是该文件夹中的文件;
创建主题使用:kafka-topics.sh 脚本
1、不带任何参数会告知该脚本如何使用:
cd /usr/local/kafka_2.13-3.7.0/bin/
./kafka-topics.sh
2、创建主题:
创建一个名字为quickstart-events的主题:
./kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
./kafka-topics.sh --create --topic hello --bootstrap-server localhost:9092

3、列出所有的主题:
./kafka-topics.sh --list --bootstrap-server localhost:9092

4、删除主题:
删除名字为hello的主题:
./kafka-topics.sh --delete --topic hello --bootstrap-server localhost:9092

5、显示主题详细信息:
显示quickstart-events主题的详细信息:
./kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092

6、修改主题信息:
修改quickstart-events主题的分区数为5:
./kafka-topics.sh --alter --topic quickstart-events --partitions 5 --bootstrap-server localhost:9092
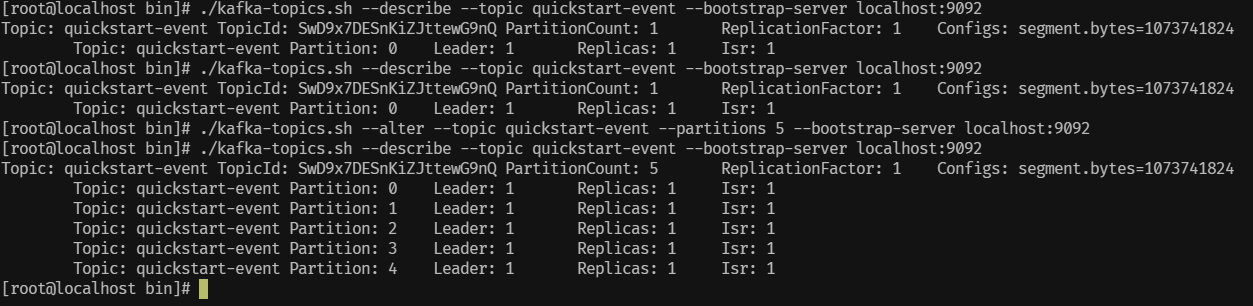
- 在主题(Topic)中写入一些事件(Events)
Kafka客户端通过网络与Kafka Brokers进行通信,可以写(或读)主题Topic中的事件Events;
Kafka Brokers一旦收到事件Event,就会将事件Event以持久和容错的方式存储起来,可以永久地存储;
通过 kafka-console-producer.sh 脚本工具写入事件Events;
不带任何参数会告知该脚本如何使用:
./kafka-console-producer.sh
发送消息:
./kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
每一次换行是一个事件Event;使用Ctrl+C退出,停止发送事件Event到主题Topic;

- 从主题(Topic)中读取事件(Events)
使用kafka-console-consumer.sh消费者客户端读取之前写入的事件Event:
不带任何参数会告知该脚本如何使用:
./kafka-console-consumer.sh
./kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
--from-beginning 表示从kafka最早的消息开始消费,
使用Ctrl+C停止消费者客户端;
事件Events是持久存储在Kafka中的,所以它们可以被任意多次读取;

不添加--from-beginning,可以读取新消息:
./kafka-console-consumer.sh --topic quickstart-events --bootstrap-server localhost:9092
再开一个窗口3发消息:
./kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092

窗口2可以看到有读取到123:

Idea插件连接Kafka
-
查看docker中Kafka是否启动,未启动则启动Kafka容器:
docker ps docker run -p 9092:9092 apache/kafka:3.7.0 -
安装外部连接工具
在idea的插件市场中搜索Kafka,并安装,如搜索不到,可能是idea的版本过低,此处使用2023.3.6版本
-
外部连接工具连接Kafka;
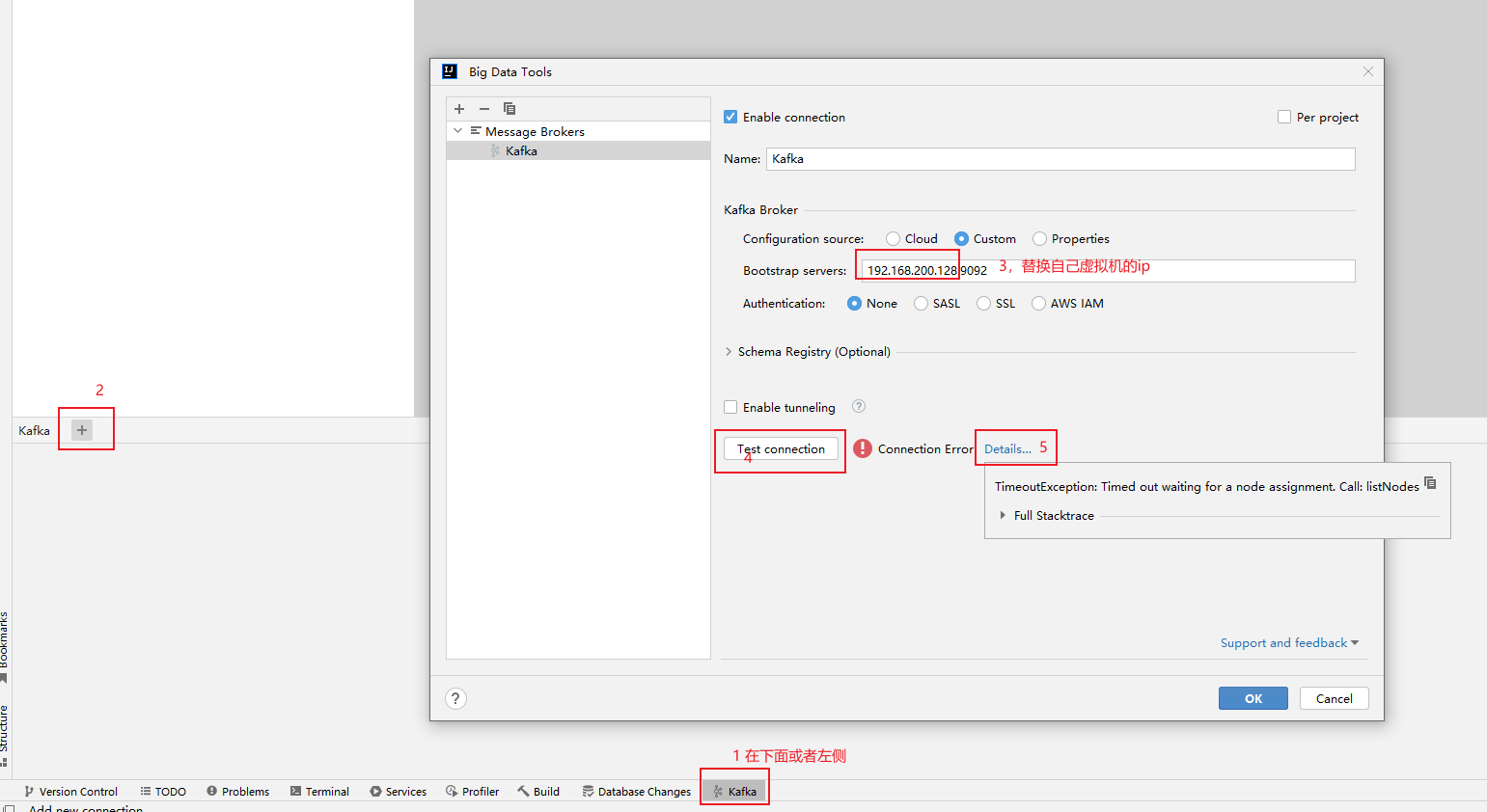
- 外部环境无法连接Kafka?
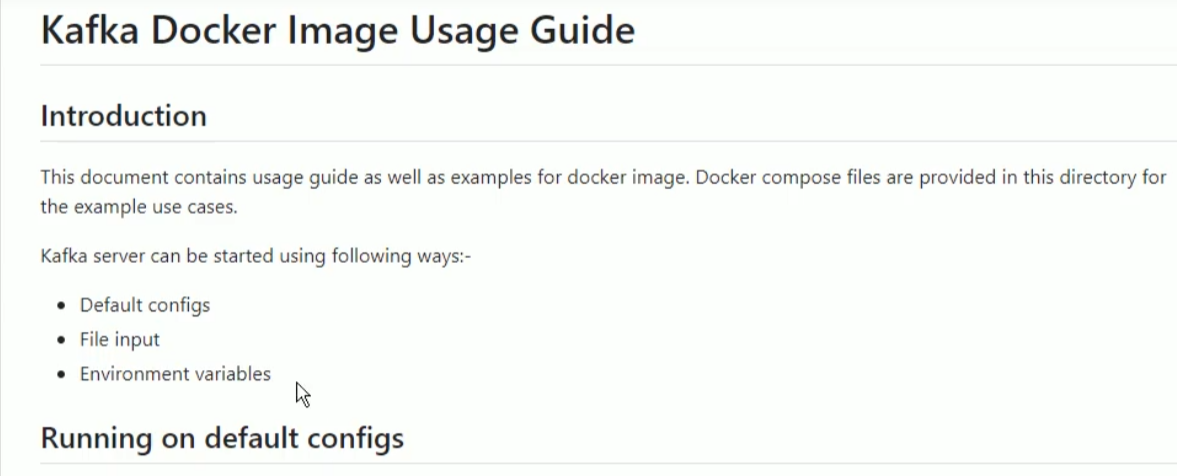
我们使用的是官方容器镜像,找到官方镜像文档;https://hub.docker.com/
文档:https://github.com/apache/kafka/blob/trunk/docker/examples/README.md
Docker容器的Kafka有三种配置启动方式:
- 默认配置:使用Kafka容器的默认配置,外部是连不上的;
- 文件输入:提供一个本地kafka属性配置文件,替换docker容器中的默认配置文件;
- 环境变量:通过env变量定义Kafka属性,覆盖默认配置中定义对应该属性的值;
文件输入:提供一个本地kafka属性配置文件,替换docker容器中的默认配置文件;
查看docker是否启动:
docker ps
未启动则启动:
docker run -p 9092:9092 apache/kafka:3.7.0
进入docker容器,容器id通过docker ps命令拿到(CONTAINER ID):
docker exec -it 容器id /bin/bash
新开一个窗口3在/opt/kafka下创建一个docker文件夹:
cd /opt
mkdir kafka
cd kafka
mkdir docker
窗口3中把docker容器中的文件复制到linux中:
docker cp bf17abcf35f0:/etc/kafka/docker/server.properties /opt/kafka/docker
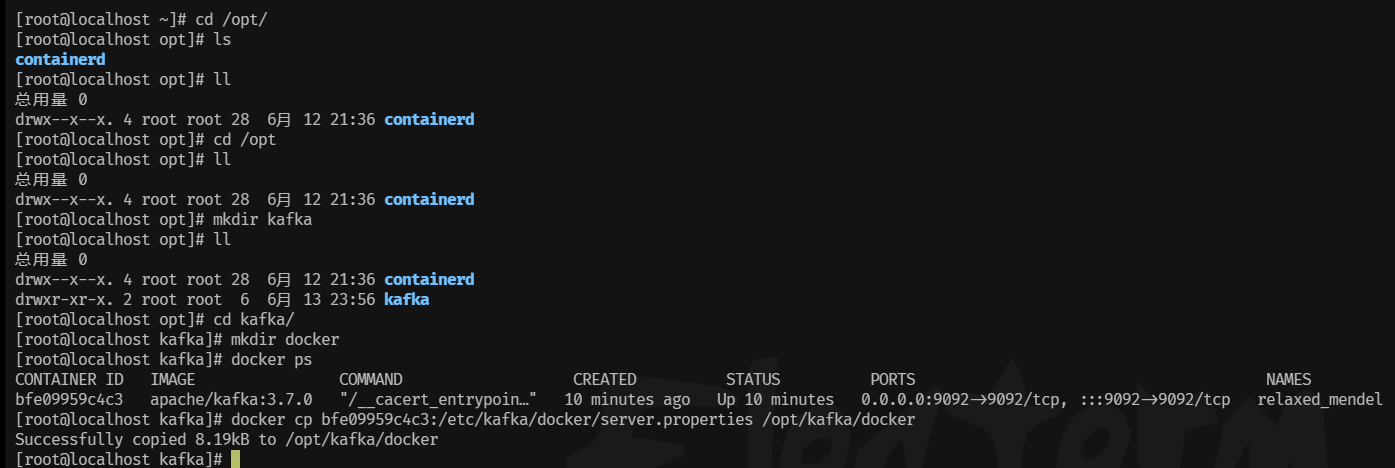
编辑配置文件:
cd /opt/kafka/docker
vim server.properties
更新截图处:
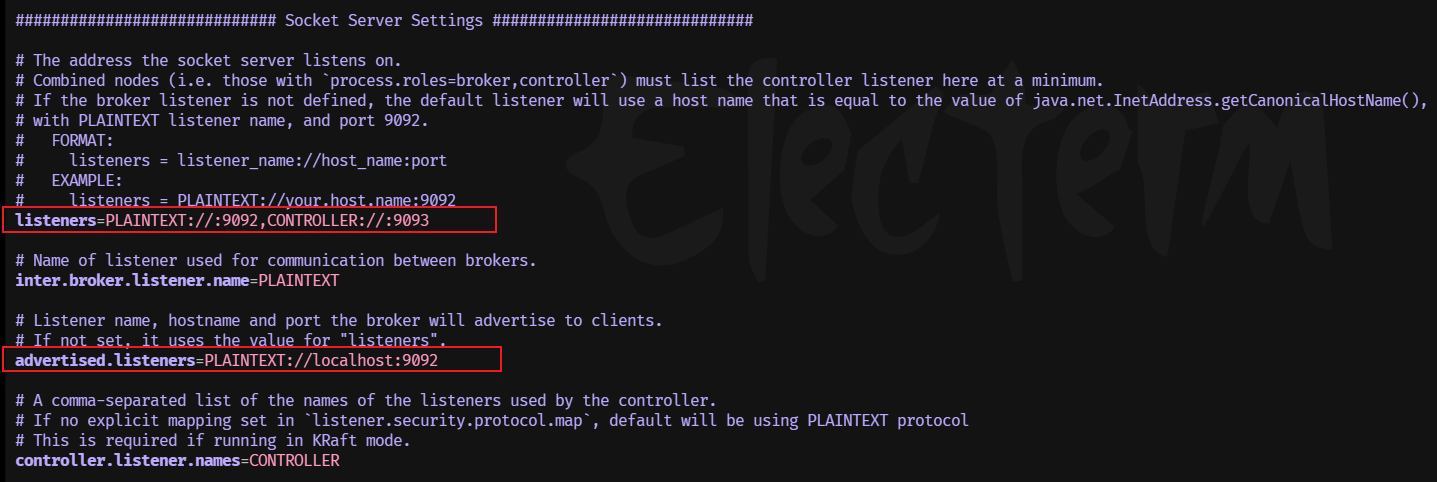
listeners=PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093
# ip替换自己的虚拟机IP
advertised.listeners=PLAINTEXT://192.168.200.128:9092
- advertise的含义表示宣称的、公布的,Kafka服务对外开放的IP和端口;
文件映射重新启动docker:
在原启动docker的窗口ctrl+c停止,重新执行下面命令:
docker run --volume /opt/kafka/docker:/mnt/shared/config -p 9092:9092 apache/kafka:3.7.0
idea连接正常:
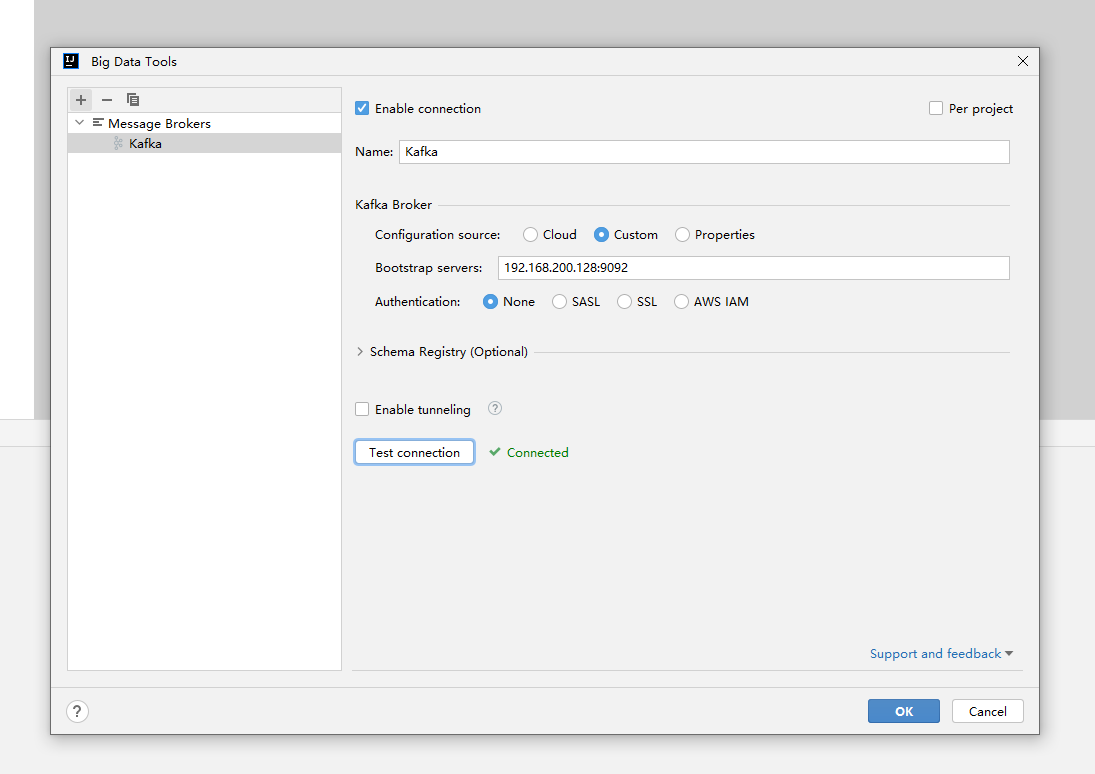
在新启动的再次创建主题:
cd /usr/local/kafka_2.13-3.7.0/bin/
./kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
./kafka-topics.sh --create --topic quickstart-events2 --bootstrap-server localhost:9092


Kafka图形界面连接工具
Kafka图形界面连接工具:
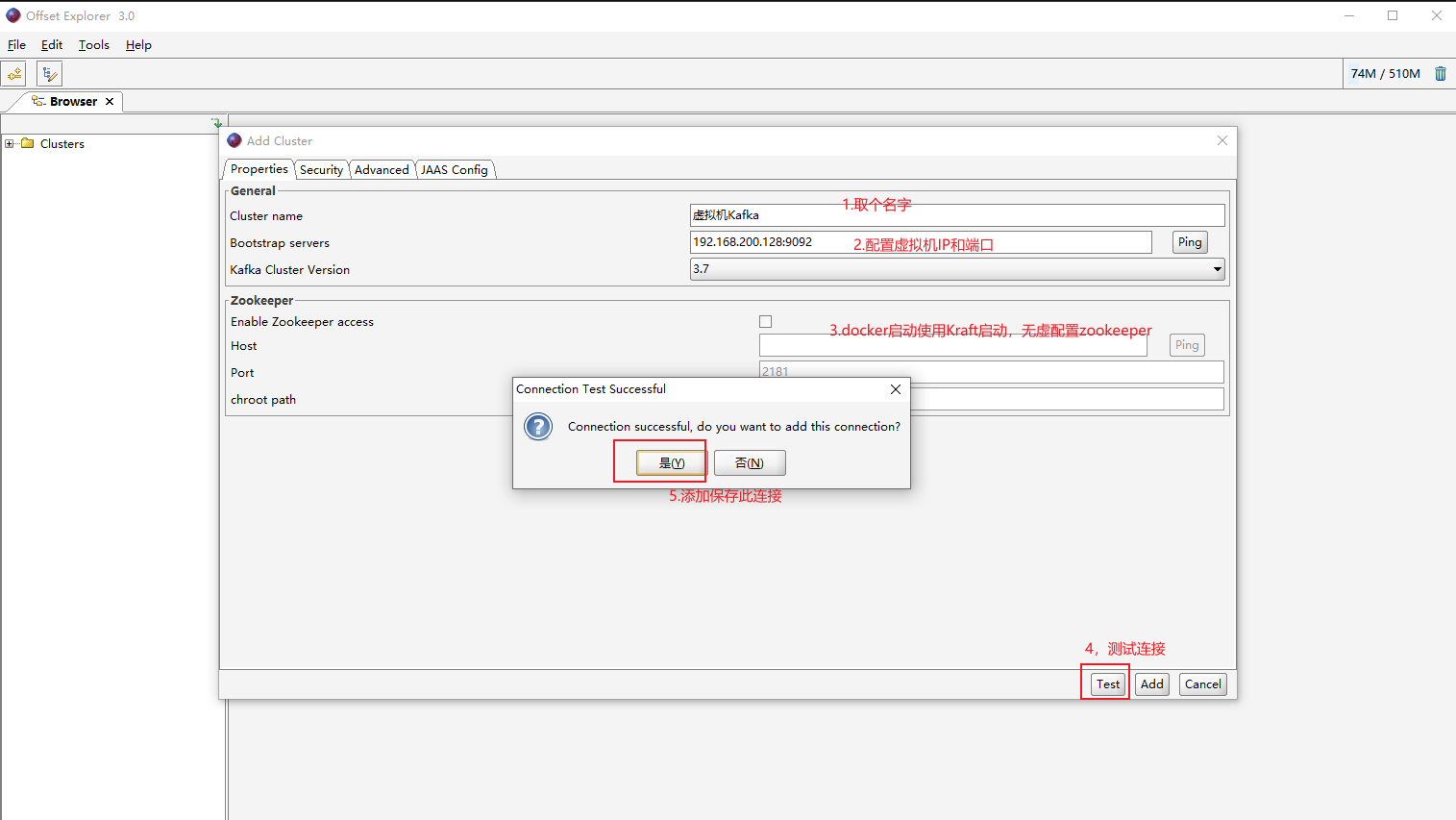
- Offset Explorer (以前叫 Kafka Tool),官网:https://www.kafkatool.com/
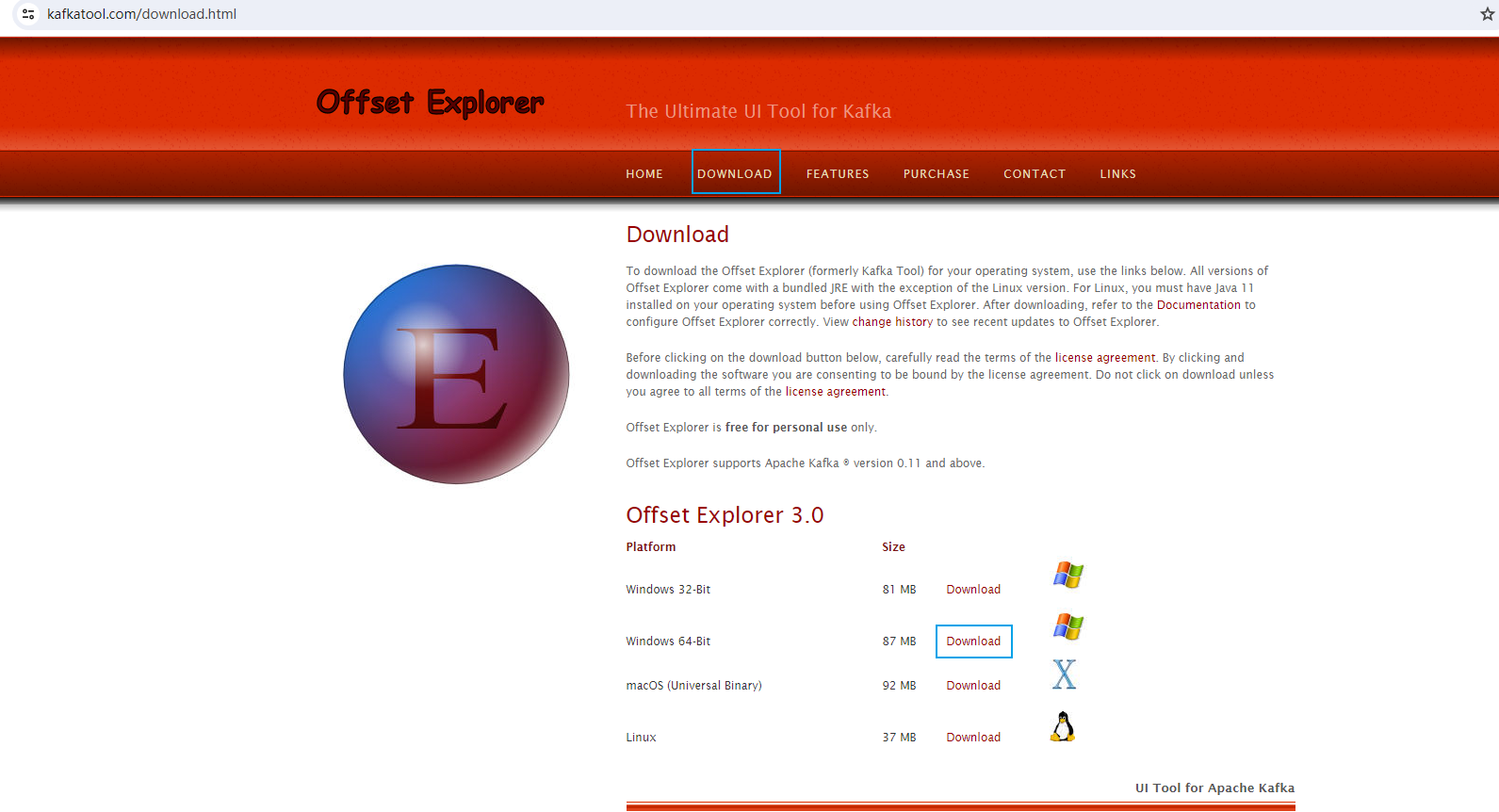
下载后直接安装到指定目录下即可;
-
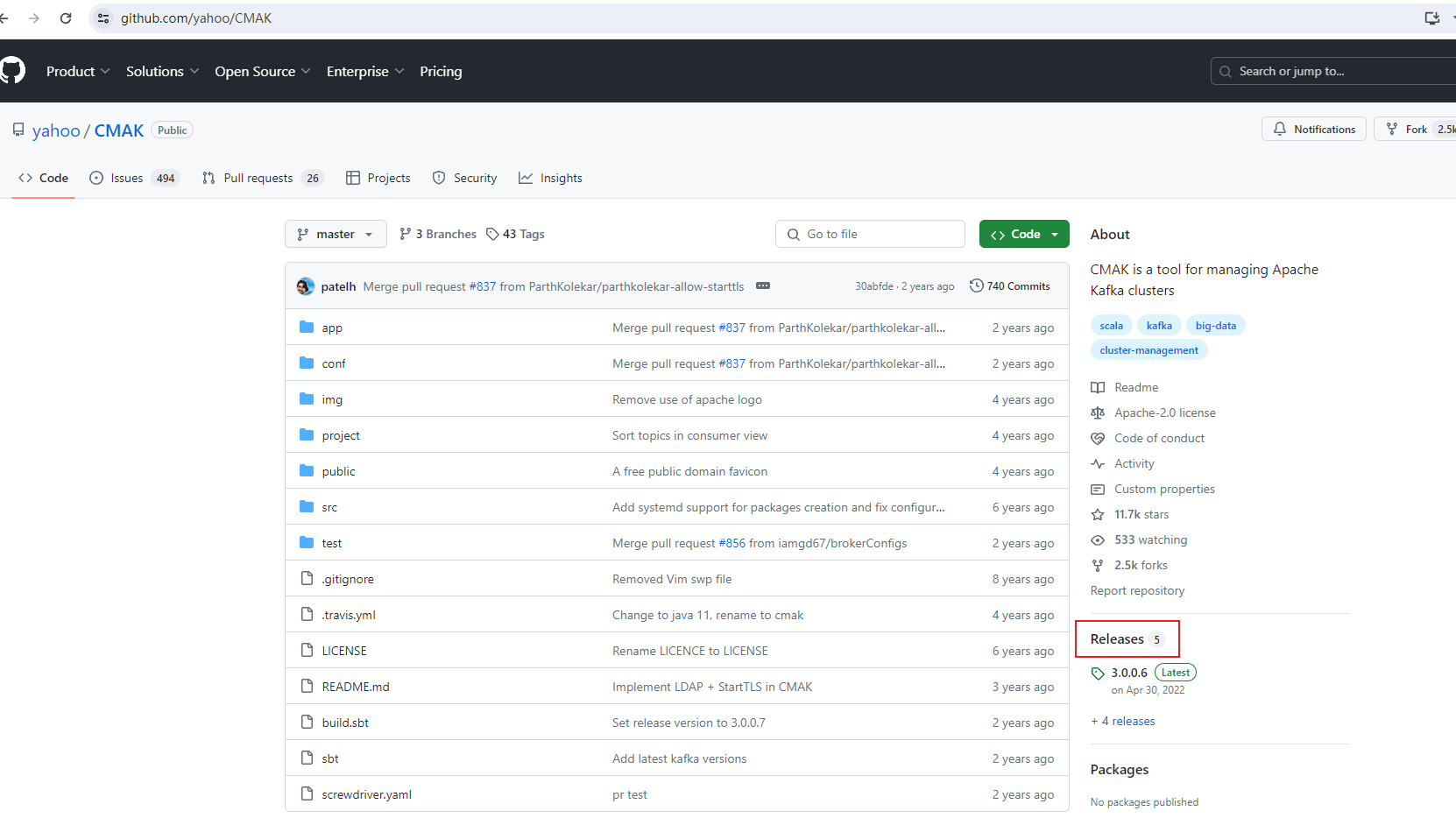
CMAK(以前叫 Kafka Manager) 官网:https://github.com/yahoo/CMAK
-
一个web后台管理系统,可以管理kafka;
-
项目地址: https://github.com/yahoo/CMAK
-
注意该管控台运行需要JDK11版本的支持;
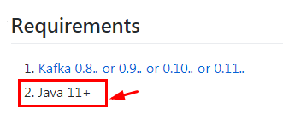
-
下载:https://github.com/yahoo/CMAK/releases
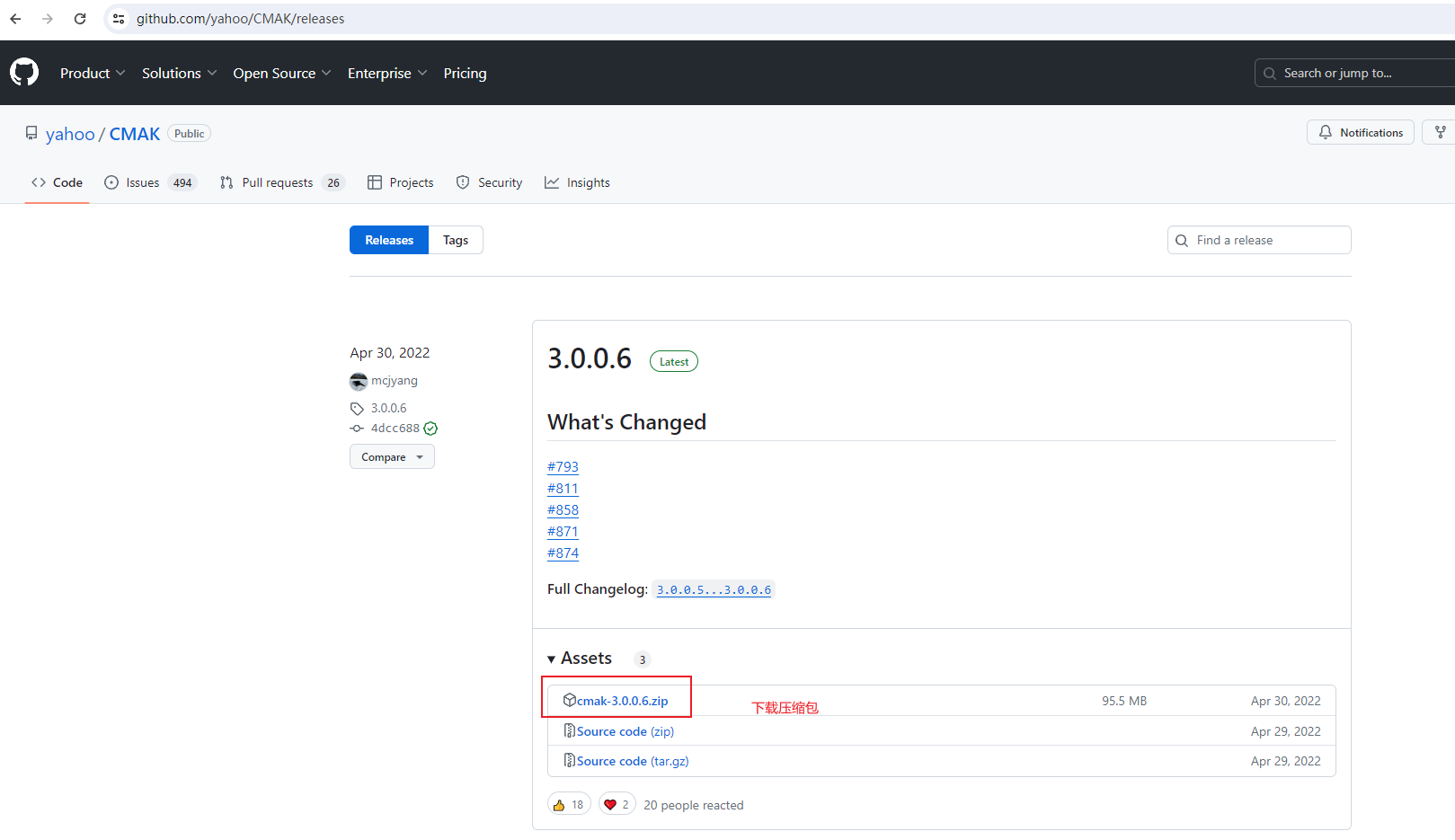
-
下载下来是一个zip压缩包,上传到linux的/root/soft文件夹下,直接 unzip解压:unzip cmak-3.0.0.6.zip
unzip cmak-3.0.0.6.zip
-
解压后即完成了安装
ll mv cmak-3.0.0.6 /usr/local/ ll /usr/local/cmak-3.0.0.6
-
基于zookeeper方式启动kafka才可以使用该web管理后台,否则不行;
-
CMAK配置:
修改conf目录下的application.conf配置文件:
vim /usr/local/cmak-3.0.0.6/conf/application.conf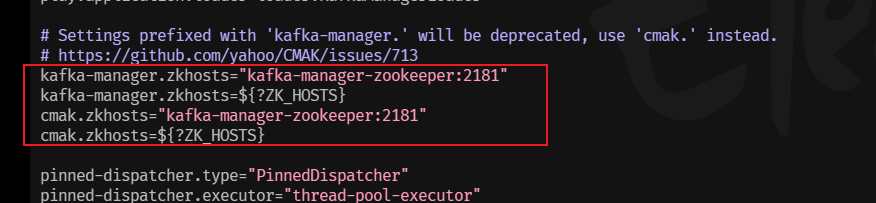
改成如下:
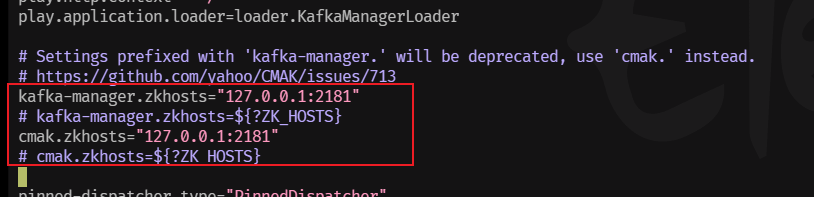
也可以使用真实IP:
kafka-manager.zkhosts="192.168.200.128:2181" cmak.zkhosts="192.168.200.128:2181"-
CMAK启动:
将jdk11的压缩包上传到虚拟机/root/soft
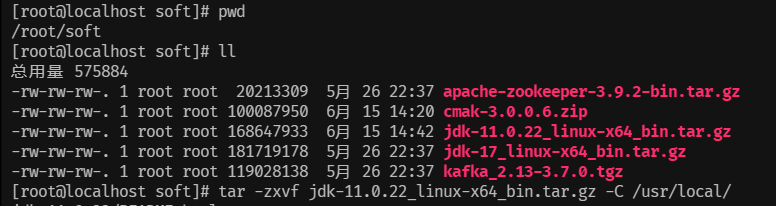
tar -zxvf jdk-11.0.22_linux-x64_bin.tar.gz -C /usr/local/关闭docker启动的Kafka
切换到bin目录下执行:
使用zookeeper方式启动Kafka: cd /usr/local/kafka_2.13-3.7.0/bin ./zookeeper-server-start.sh ../config/zookeeper.properties & ./kafka-server-start.sh ../config/server.properties & cd /usr/local/cmak-3.0.0.6/bin ./cmak -Dconfig.file=../conf/application.conf -java-home /usr/local/jdk-11.0.22其中-Dconfig.file是指定配置文件,-java-home是指定jdk11所在位置,如果机器上已经是jdk11,则不需要指定;
-
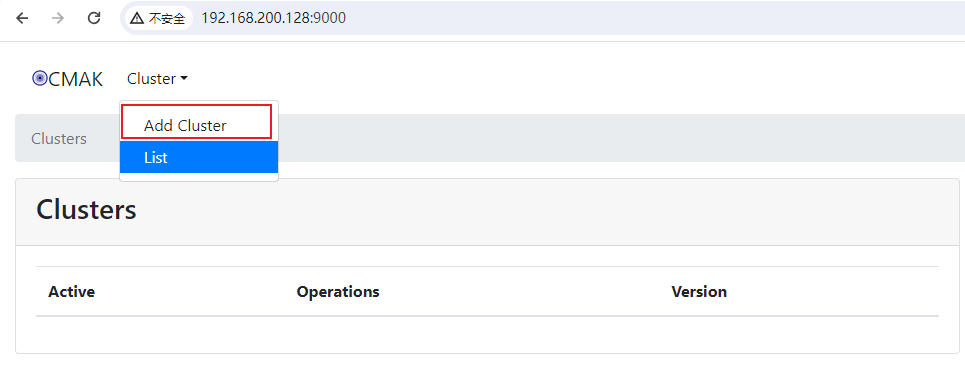
CMAK访问
启动之后CMAK默认端口为9000,访问:http://192.168.200.128:9000/
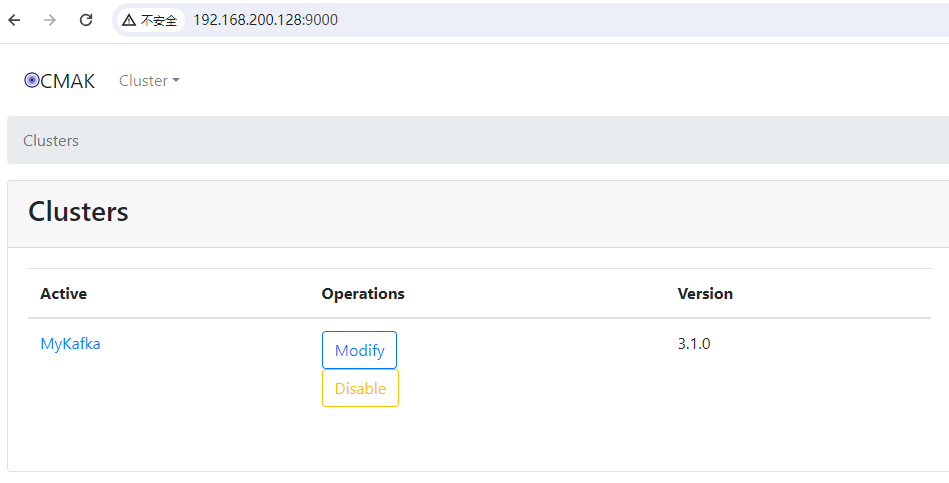
-
-
-
-
EFAK(以前叫 kafka-eagle) 官网:https://www.kafka-eagle.org/
EFAK一款优秀的开源免费的Kafka集群监控工具;(国人开发并开源)
官网:https://www.kafka-eagle.org/
Github:https://github.com/smartloli/EFAK
EFAK下载与安装:
下载:https://github.com/smartloli/kafka-eagle-bin/archive/v3.0.1.tar.gz
安装,需要解压两次:
解压得到一个文件夹: tar -zxvf kafka-eagle-bin-3.0.1.tar.gz 进入解压后的文件夹: cd kafka-eagle-bin-3.0.1 看到一个解压文件,再次解压: tar -zxvf efak-web-3.0.1-bin.tar.gz 得到web文件,移动到/usr/local下: mv efak-web-3.0.1 /usr/local 进入软件包,将刚刚解压的文件夹删除 cd /root/soft rm -rf kafka-eagle-bin-3.0.1 进入安装好的文件下: cd /usr/local/efak-web-3.0.1EFAK(以前叫 kafka-eagle)(EFAK: Eagle For Apache Kafka)Eagle:鹰
-
EFAK配置
-
安装数据库,需要MySQL,并创建数据库ke;
-
修改配置文件$KE_HOME/conf/system-config.properties
-
EFAK也是需要zookeeper方式启动Kafka才能使用;
-
主要修改Zookeeper配置和MySQL数据库配置;

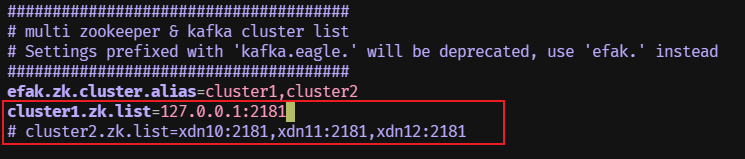
MySQL改成自己的账号密码:


cd /usr/local/efak-web-3.0.1/conf vim system-config.properties cluster1.zk.list=127.0.0.1:2181 efak.driver=com.mysql.cj.jdbc.Driver efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull efak.username=root efak.password=abc123
-
-
在/etc/profile文件中配置环境变量KE_HOME,在profile文件的最后添加:
vim /etc/profile export KE_HOME=/usr/local/efak-web-3.0.1 export PATH=$KE_HOME/bin:$PATH执行source让环境变量配置生效:
source /etc/profile -
启动EFAK
-
确保kafka采用zookeeper方式启动;
-
在EFAK安装目录的bin目录下执行:
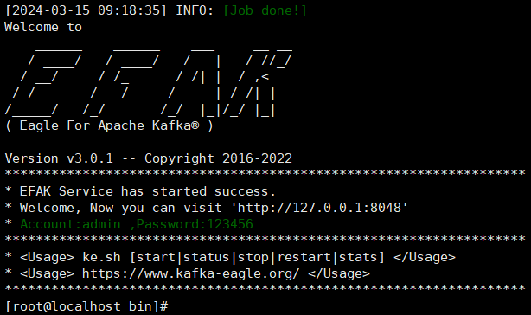
cd /usr/local/efak-web-3.0.1/bin/ ./ke.sh start (命令使用:ke.sh [start|status|stop|restart|stats])
-
-
访问EFAK
登录账号:admin , 密码:123456
-
-
Spring Boot集成Kafka开发
-
创建一个空工程kafka并创建第一个项目spring-boot-01-kafka-base
使用SpringBoot脚手架Spring Initializr创建SpringBoot项目;
-
配依赖,pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.3</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.bjpowernode</groupId> <artifactId>spring-boot-01-kafka-base</artifactId> <version>0.0.1-SNAPSHOT</version> <name>spring-boot-01-kafka-base</name> <description>spring-boot-01-kafka-base</description> <properties> <java.version>17</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <scope>runtime</scope> <optional>true</optional> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka-test</artifactId> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build> </project> -
配文件,将application.properties改成application.yaml
spring: application: # 应用名称 name: spring-boot-01-kafka-base kafka: # kafka连接地址 bootstrap-servers: 192.168.200.129:9092 # 配置生产者(有24个配置) # producer: # 配置消费者(有24个配置) # consumer: -
创建事件生产类
package com.bjpowernode.producer; import jakarta.annotation.Resource; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.stereotype.Component; @Component public class EventProducer { // 加入了spring-kafka依赖+.yml配置。springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean @Resource private KafkaTemplate<String,String> kafkaTemplate; public void sendEvent() { kafkaTemplate.send("hello-topic", "hello kafka"); } } -
创建测试类,并执行,发现报错,这是因为kafka未配置无法外部访问
package com.bjpowernode; import com.bjpowernode.producer.EventProducer; import jakarta.annotation.Resource; import org.junit.jupiter.api.Test; import org.springframework.boot.test.context.SpringBootTest; @SpringBootTest class KafkaBaseApplicationTests { @Resource private EventProducer eventProducer; @Test void test01() { eventProducer.sendEvent(); } } -
虚拟机启动Kafka,使用Zookeeper的方式启动,同时为了让外部能够访问,修改配置
cd /usr/local/kafka_2.13-3.7.0/config vim server.properties listeners=PLAINTEXT://0.0.0.0:9092 advertised.listeners=PLAINTEXT://192.168.200.129:9092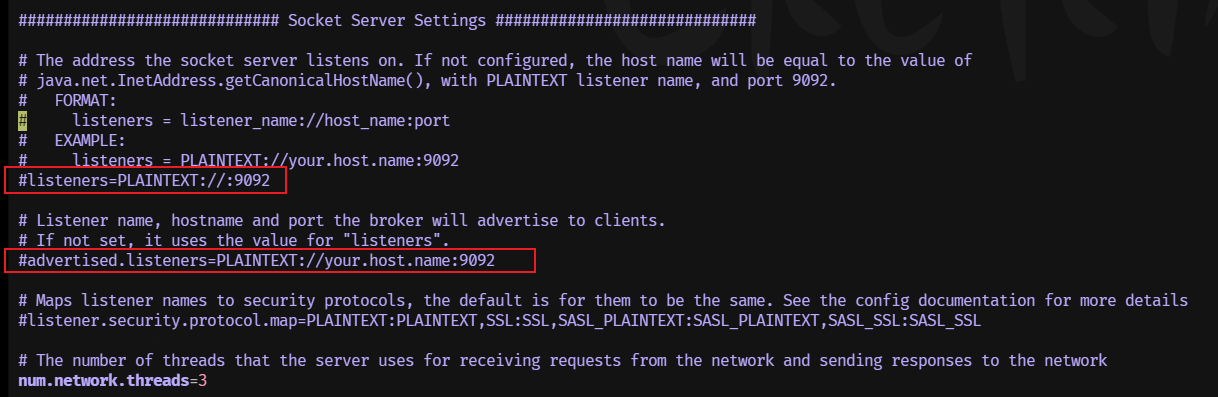
修改成下图:
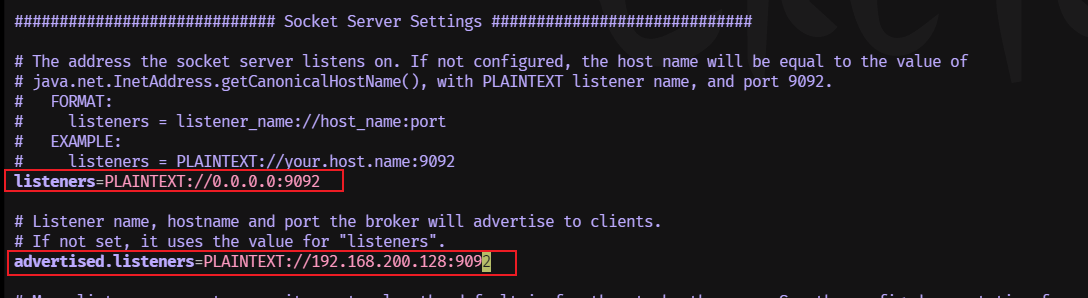
配置修改好后,启动
cd /usr/local/kafka_2.13-3.7.0/bin ./zookeeper-server-start.sh ../config/zookeeper.properties & ./kafka-server-start.sh ../config/server.properties & -
再次执行:
-
可以看到这次发送成功,我们创建消费者类去进行消费:
package com.bjpowernode.consumer; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.stereotype.Component; @Component public class EventConsumer { @KafkaListener public void onEvent(String event) { System.out.println("读取到的事件:" + event); } } -
启动main方法,我们发现topic上面的那条消息没有消费,这是因为默认是从最新的消息开始消费。再次调用测试方法发送一条消息。我们发现消费到了这条消息。如果我们想消费之前发送的消息,我们可以通过一下2种方法做到,我们先了解一下概念后,在介绍者2种方法。
-
kafka的所有配置都在这个类上:KafkaProperties.java,按Alt+7我们可以看到里面有生产者和消费者类
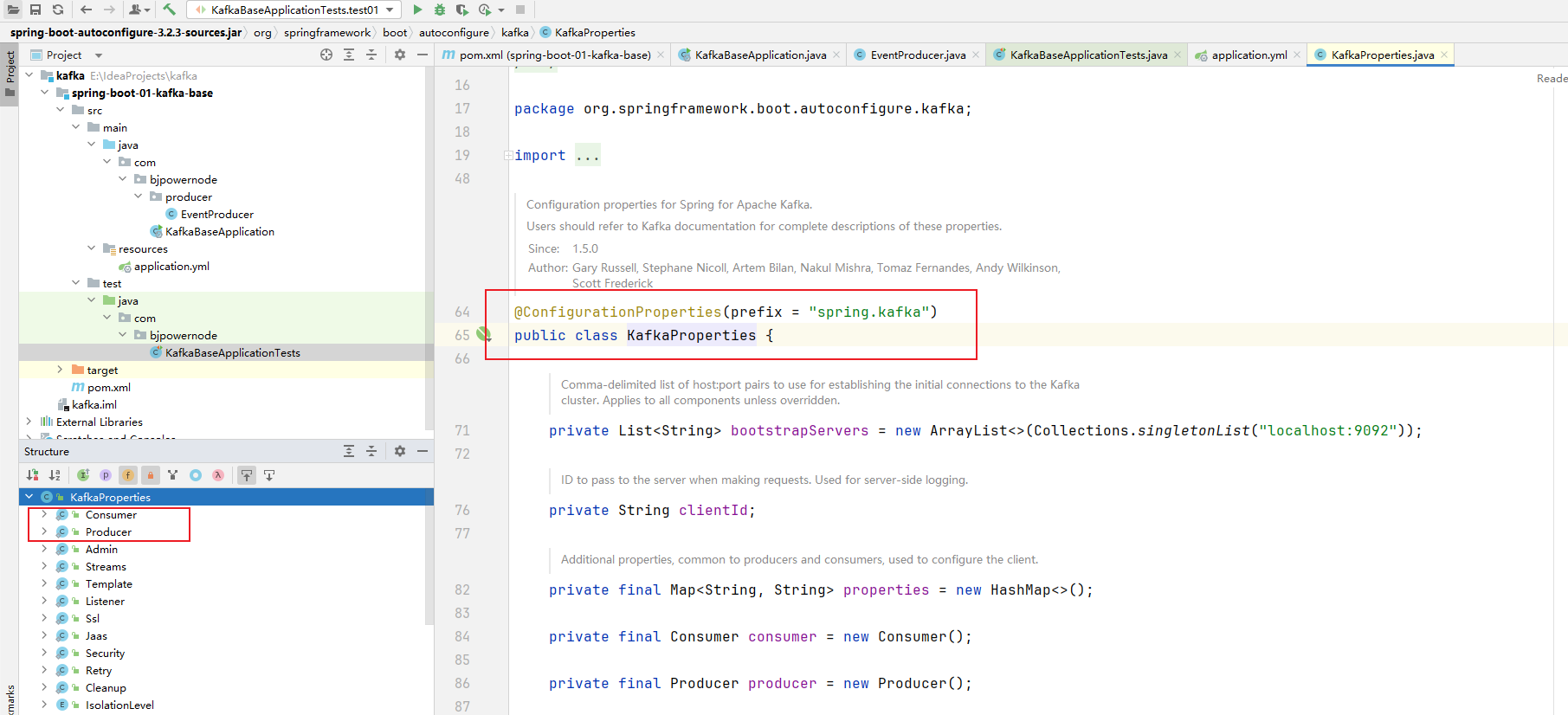
生产者配置类:打开结构并点击左边字段:
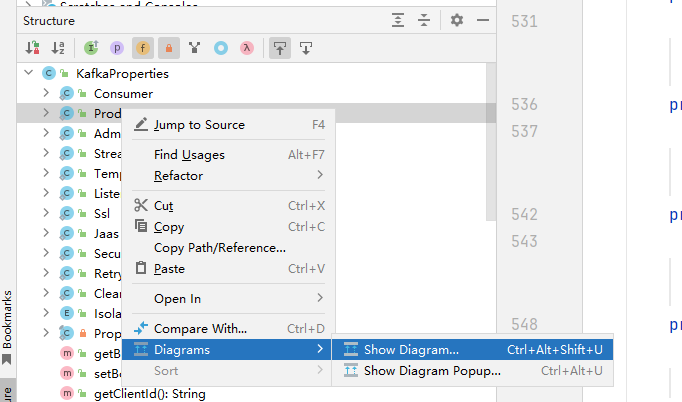
可以看到生产者和消费者有哪些字段:
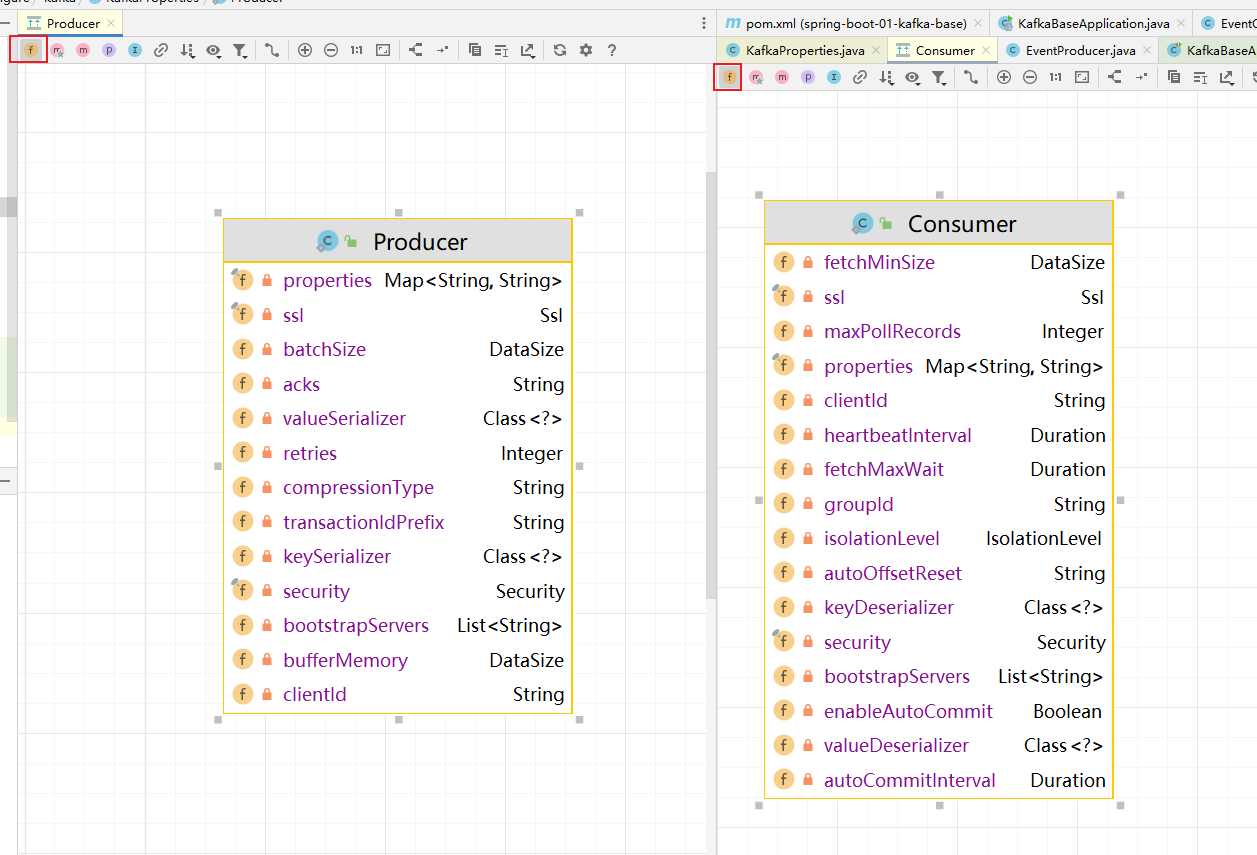
- kafka的几个概念:
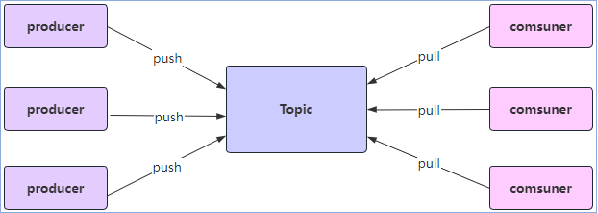
1、Kafka中,每个topic可以有一个或多个partition;
2、当创建topic时,如果不指定该topic的partition数量,那么默认就是1个partition;
3、offset是标识每个分区中消息的唯一位置,从0开始;
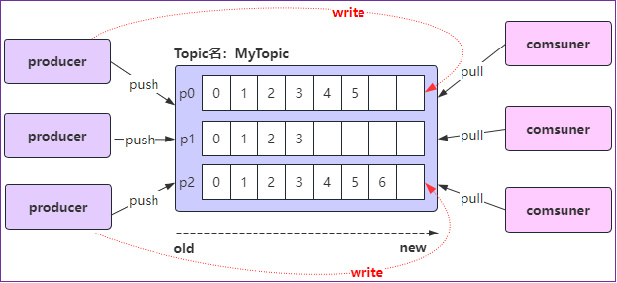
1、生产者Producer
2、消费者Consumer
3、主题Topic
4、分区Partition
5、偏移量Offset
默认情况下,当启动一个新的消费者组时,它会从每个分区的最新偏移量(即该分区中最后一条消息的下一个位置)开始消费。如果希望从第一条消息开始消费,需要将消费者的auto.offset.reset设置为earliest;
注意: 如果之前已经用相同的消费者组ID消费过该主题,并且Kafka已经保存了该消费者组的偏移量,那么即使你设置了auto.offset.reset=earliest,该设置也不会生效,
因为Kafka只会在找不到偏移量时使用这个配置。在这种情况下,你需要手动重置偏移量或使用一个新的消费者组ID;
-
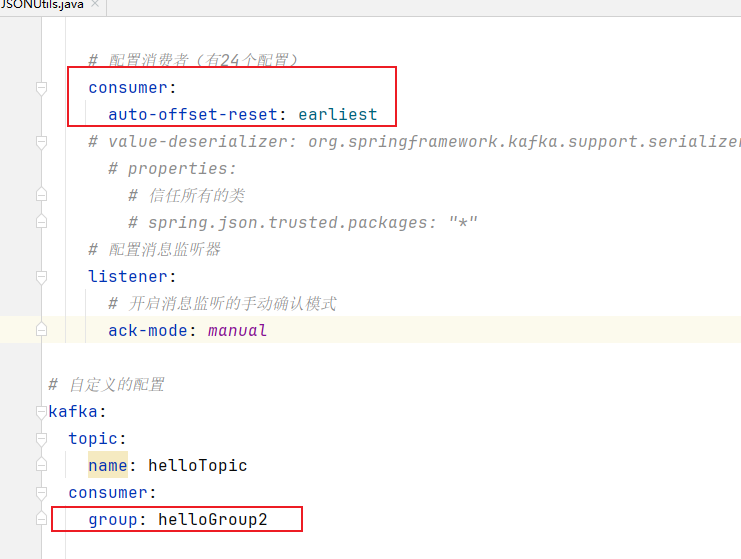
消息消费时偏移量策略的配置:
spring: kafka: # 配置消费者(有24个配置) consumer: auto-offset-reset: earliest配置以上配置后我们重启main方法,发现没有从第一条消费,这是因为该消费者ID已经消费过该主题,kafka已经保存了该消费组的偏移量。
将消费组groupId改成hello-group-02后,再次启动main方法,2条消息都读到了,同样的,再次启动main方法,就不会再读到了。
package com.bjpowernode.consumer; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.stereotype.Component; @Component public class EventConsumer { // @KafkaListener(topics = {"hello-topic"},groupId = "hello-group") @KafkaListener(topics = {"hello-topic"},groupId = "hello-group-02") public void onEvent(String event) { System.out.println("读取到的事件:" + event); } } -
手动重置偏移量:
重置偏移量到最早的位置: ./kafka-consumer-groups.sh --bootstrap-server <your-kafka-bootstrap-servers> --group <your-consumer-group> --topic <your-topic> --reset-offsets --to-earliest --execute 改成我们本地真实执行的命令: ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group hello-group-02 --topic hello-topic --reset-offsets --to-earliest --execute 执行我们发现如果报这个错: Error: Assignments can only be reset if the group 'hello-group-02' is inactive, but the current state is Stable. 表示我们服务为关闭。关闭服务再执行,我们发现执行成功,重新启动服务,再次消费2条数据。当然,再次启动服务不会再消费了。 重置偏移量到最后的位置: ./kafka-consumer-groups.sh --bootstrap-server <your-kafka-bootstrap-servers> --group <your-consumer-group> --topic <your-topic> --reset-offsets --to-latest --execute -
消息消费时偏移量策略的配置:
spring: kafka: consumer: auto-offset-reset: earliest取值:earliest、latest、none、exception
- earliest:自动将偏移量重置为最早的偏移量;
- latest:自动将偏移量重置为最新偏移量;
- none:如果没有为消费者组找到以前的偏移量,则向消费者抛出异常;
- exception:向消费者抛出异常;(spring-kafka不支持)
spring-kafka生产者发送消息
- spring-kafka生产者发送消息:(生产者客户端向kafka的主题topic中写入事件)
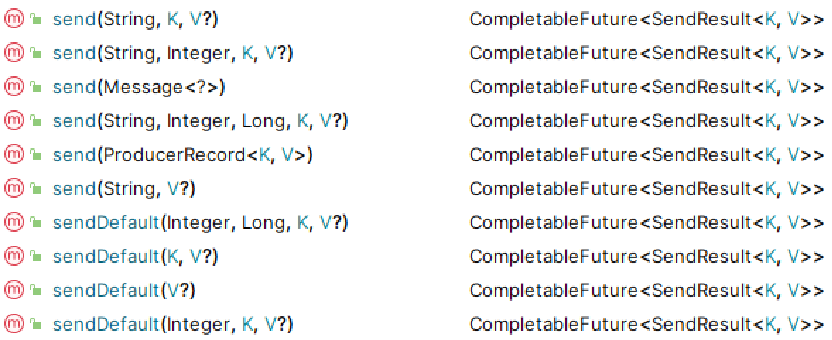
kafkaTemplate.send(...) 和 kafkaTemplate.sendDefault(...) 的区别?
主要区别是发送消息到Kafka时是否每次都需要指定主题topic;
-
kafkaTemplate.send(...) 该方法需要明确地指定要发送消息的目标主题topic;
-
kafkaTemplate.sendDefault() 该方法不需要指定要发送消息的目标主题topic;
-
kafkaTemplate.send(...) 方法适用于需要根据业务逻辑或外部输入动态确定消息目标topic的场景;
-
kafkaTemplate.sendDefault() 方法适用于总是需要将消息发送到特定默认topic的场景;
-
kafkaTemplate.sendDefault() 是一个便捷方法,它使用配置中指定的默认主题topic来发送消息,如果应用中所有消息都发送到同一个主题时采用该方法非常方便,可以减少代码的重复或满足特定的业务需求;
接下来我们在EventProducer类中使用一下这些方法:
public void sendEvent2() {
// 通过构建器模式创建Message对象
Message<String> message = MessageBuilder.withPayload("hello kafka")
.setHeader(KafkaHeaders.TOPIC, "test-topic").build();
kafkaTemplate.send(message);
}
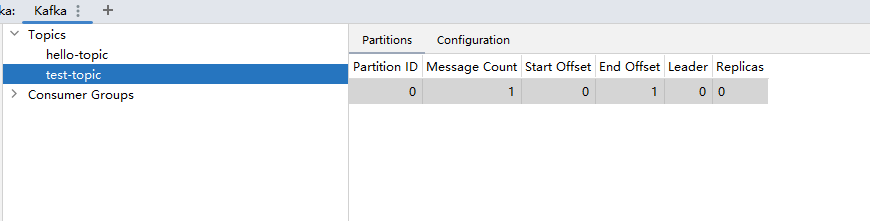
测试类中增加测试方法并执行:
@Test
void test02() {
eventProducer.sendEvent2();
}
kafka插件中看到test-topic主题已经存在了,并且有一条消息:
消费者类:
public void sendEvent3() {
Headers headers = new RecordHeaders();
headers.add("phone", "13709090909".getBytes(StandardCharsets.UTF_8));
headers.add("orderId", "OD158932723742".getBytes(StandardCharsets.UTF_8));
// 给kafka发送消息可以指定key和value,这里与kafkaTemplate保持一致,key和value都是String类型
// 这里我们用参数最多的
// String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers
ProducerRecord<String, String> record = new ProducerRecord<>(
"test-topic-02",
0,
System.currentTimeMillis(),
"k1",
"hello kafka",
headers
);
kafkaTemplate.send(record);
}
测试类并执行,可以看到创建了test-topic-02,里面有有一条消息:
@Test
void test03() {
eventProducer.sendEvent3();
}

消费者类:
public void sendEvent4() {
// String topic, Integer partition, Long timestamp, K key, V data
kafkaTemplate.send("test-topic-02", 0, System.currentTimeMillis(), "k2", "hello kafka");
}
测试类并执行,可以看到在test-topic-02,里面有2条消息了:
@Test
void test04() {
eventProducer.sendEvent4();
}

消费者类:
public void sendEvent5() {
// Integer partition, Long timestamp, K key, V data
kafkaTemplate.sendDefault(0, System.currentTimeMillis(), "k3", "hello kafka");
}
测试类:
@Test
void test05() {
eventProducer.sendEvent5();
}
由于没有指定topic,调用会报Topic cannot be null.
我们需要在yaml配置文件指定默认topic:
spring:
application:
# 应用名称
name: spring-boot-01-kafka-base
kafka:
# kafka连接地址
bootstrap-servers: 192.168.200.129:9092
# 配置生产者(有24个配置)
# producer:
# 配置消费者(有24个配置)
consumer:
auto-offset-reset: latest
# 配置模板默认的主题topic名称
template:
default-topic: default-topic
再次测试,我们发现有了

spring-kafka获取生产者消息发送结果
-
.send()方法和.sendDefault()方法都返回CompletableFuture<SendResult<K, V>>;
-
CompletableFuture 是Java 8中引入的一个类,用于异步编程,它表示一个异步计算的结果,这个特性使得调用者不必等待操作完成就能继续执行其他任务,从而提高了应用程序的响应速度和吞吐量;
-
因为调用 kafkaTemplate.send() 方法发送消息时,Kafka可能需要一些时间来处理该消息(例如:网络延迟、消息序列化、Kafka集群的负载等),如果 send() 方法是同步的,那么发送消息可能会阻塞调用线程,直到消息发送成功或发生错误,这会导致应用程序的性能下降,尤其是在高并发场景下;
-
使用 CompletableFuture,.send() 方法可以立即返回一个表示异步操作结果的未来对象,而不是等待操作完成,这样,调用线程可以继续执行其他任务,而不必等待消息发送完成。当消息发送完成时(无论是成功还是失败),CompletableFuture会相应地更新其状态,并允许我们通过回调、阻塞等方式来获取操作结果;
在生产者类增加发送消息,并接收返回值
public void sendEvent6() {
// Integer partition, Long timestamp, K key, V data
CompletableFuture<SendResult<String, String>> completableFuture =
kafkaTemplate.sendDefault(0, System.currentTimeMillis(), "k3", "hello kafka");
// 怎么拿结果,通过CompletableFuture这个类拿结果
try {
// 1.阻塞等待的方式拿结果:
SendResult<String, String> sendResult = completableFuture.get();
// 如果这个对象不为空,表示kafka服务器确认已经接收到了消息
if (sendResult.getRecordMetadata() != null) {
System.out.println("sendResult.getRecordMetadata().toString() = " + sendResult.getRecordMetadata().toString());
}
System.out.println("sendResult.getProducerRecord() = " + sendResult.getProducerRecord());
} catch (Exception e) {
throw new RuntimeException(e);
}
}
测试方法:
@Test
void test06() {
eventProducer.sendEvent6();
}
日志打印如下:

topic上也增加了一条消息:

非阻塞方式获取生产者消息发送结果:
public void sendEvent7() {
// Integer partition, Long timestamp, K key, V data
CompletableFuture<SendResult<String, String>> completableFuture =
kafkaTemplate.sendDefault(0, System.currentTimeMillis(), "k3", "hello kafka");
// 2.非阻塞等待的方式拿结果:
completableFuture.thenAccept(new Consumer<SendResult<String, String>>() {
@Override
public void accept(SendResult<String, String> sendResult) {
// 如果这个对象不为空,表示kafka服务器确认已经接收到了消息
if (sendResult.getRecordMetadata() != null) {
System.out.println("sendResult.getRecordMetadata().toString() = " + sendResult.getRecordMetadata().toString());
}
System.out.println("sendResult.getProducerRecord() = " + sendResult.getProducerRecord());
}
}).exceptionally(new Function<Throwable, Void>() {
@Override
public Void apply(Throwable throwable) {
throwable.printStackTrace();
return null;
}
});
}
测试方法:
@Test
void test07() {
eventProducer.sendEvent7();
}
- 方式一:调用CompletableFuture的get()方法,同步阻塞等待发送结果;
- 方式二:使用 thenAccept(), thenApply(), thenRun() 等方法来注册回调函数,回调函数将在 CompletableFuture 完成时被执行;
spring-kafka生产者发送对象消息
-
创建User类:
package com.bjpowernode.modole; import lombok.*; import java.util.Date; @Data @Builder @AllArgsConstructor @NoArgsConstructor public class User { private int id; private String phone; private Date birthDay; } -
发送消息方法:
public void sendEvent8() { User user = User.builder().id(111).phone("").birthDay(new Date()).build(); // 分区设为null,让spring-kafka决定发送到哪个分区 kafkaTemplate2.sendDefault(null, System.currentTimeMillis(), "k3", user); } -
测试方法:
@Test void test08() { eventProducer.sendEvent8(); } -
执行测试方法我们发现报错序列化异常:
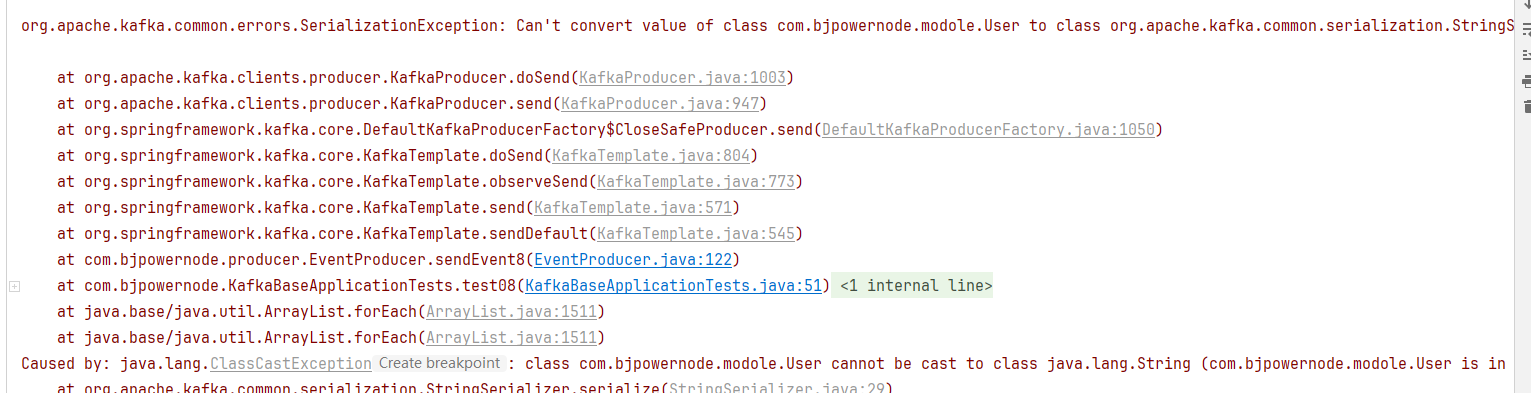
-
默认使用的是字符串序列化,无法将user对象转换成字符串,需要我们指定生产者的值序列化方式:
spring: application: # 应用名称 name: spring-boot-01-kafka-base kafka: # kafka连接地址 bootstrap-servers: 192.168.200.129:9092 # 配置生产者(有24个配置) producer: # value默认是StringSerializer.class序列化 value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # key也默认是StringSerializer.class序列化 # key-serializer: org.apache.kafka.common.serialization.StringSerializer # 配置消费者(有24个配置) consumer: auto-offset-reset: latest # 配置模板默认的主题topic名称 template: default-topic: default-topicJsonS依赖jackson实现,需要有该包依赖:
<dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency> -
再次发送消息,发送成功。
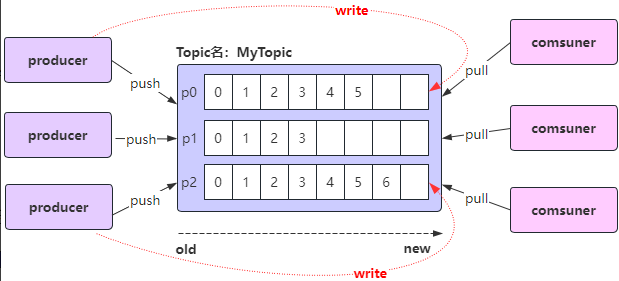
Kafka的核心概念:Replica副本
Replica:副本,为实现备份功能,保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且 Kafka仍然能够继续工作,Kafka提供了副本机制,一个topic的每个分区都有1个或多个副本;
Replica副本分为Leader Replica和Follower Replica:
- Leader:每个分区多个副本中的“主”副本,生产者发送数据以及消费者消费数据,都是来自leader副本;
- Follower:每个分区多个副本中的“从”副本,实时从leader副本中同步数据,保持和leader副本数据的同步,leader副本发生故障时,某个follower副本会成为新的leader副本;
设置副本个数不能为0,也不能大于节点个数,否则将不能创建Topic;
指定topic的分区和副本
方式一:通过Kafka提供的命令行工具在创建topic时指定分区和副本;
./kafka-topics.sh --create --topic myTopic --partitions 3 --replication-factor 1 --bootstrap-server 127.0.0.1:9092
方式二:执行代码时指定分区和副本;
kafkaTemplate.send("topic", message);
直接使用send()方法发送消息时,kafka会帮我们自动完成topic的创建工作,但这种情况下创建的topic默认只有
个分区,分区有1个副本,也就是有它自己本身的副本,没有额外的副本备份;
我们可以在项目中新建一个配置类专门用来初始化topic;
添加一个配置类:
package com.bjpowernode.config;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaConfig {
@Bean
public NewTopic newTopic() {
return new NewTopic("heTopic", 5, (short) 1);
}
}
执行mian方法后topic创建成功:
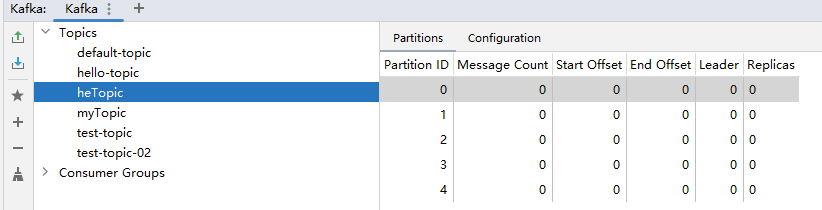
一台机器副本数只能设为1,超过报错。第一次启动创建topic,项目关闭后再次启动,不会有问题,往里面发送一条消息,再次启动,信息会不会丢?
public void sendEvent9() {
User user = User.builder().id(111).phone("").birthDay(new Date()).build();
// 分区设为null,让spring-kafka决定发送到哪个分区
kafkaTemplate2.send("heTopic", null, System.currentTimeMillis(), "k9", user);
}
测试类添加测试方法并执行:
@Test
void test09() {
eventProducer.sendEvent9();
}
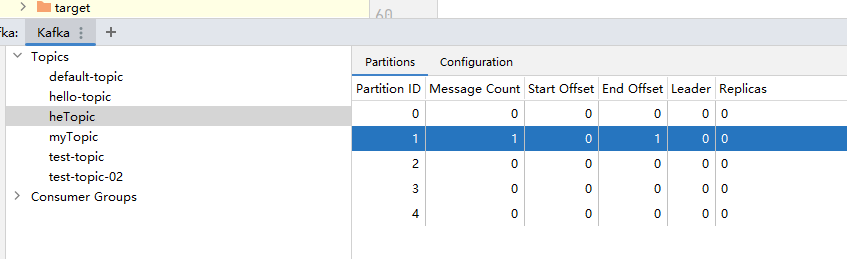
重新启动项目消息还在,topic存在不会创建,只有不存在才创建:
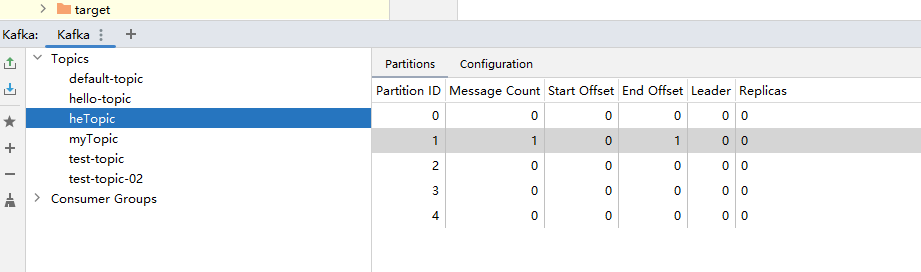
在KafkaConfig.java中增加更新topic,并重新启动项目
// 对topic进行更新
@Bean
public NewTopic updateNewTopic() {
return new NewTopic("heTopic", 9, (short) 1);
}
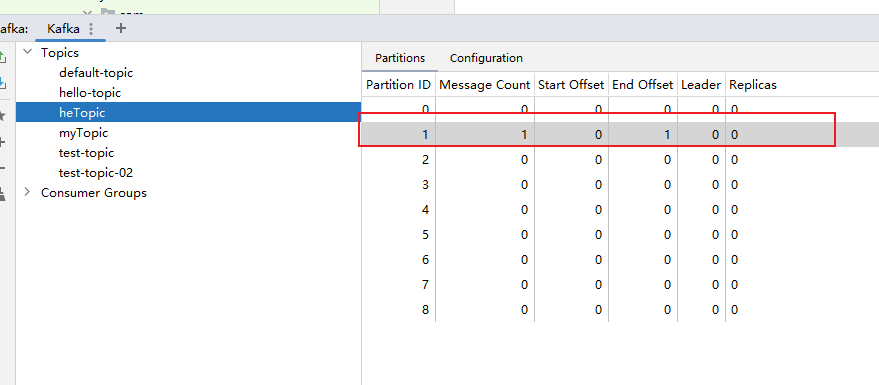
分区数更新为9,原来的数据还是存在。
将分区数改成7,再次重新启动项目,分区数还是9,没有帮我们缩小为7
生产者发送消息的分区策略
生产者写入消息到topic,Kafka将依据不同的策略将数据分配到不同的分区中;
指定分区,则直接发送到指定分区
public void sendEvent9() {
User user = User.builder().id(111).phone("").birthDay(new Date()).build();
// 指定分区数
kafkaTemplate2.send("heTopic", 2, System.currentTimeMillis(), "k9", user);
// 分区设为null,让spring-kafka决定发送到哪个分区,有key,则哈希key值,再取余分区数
kafkaTemplate2.send("heTopic", null, System.currentTimeMillis(), "k9", user);
// key设置为null,随机数哈希值,再取余分区数
kafkaTemplate2.send("heTopic", user);
}
分区改为null,则使用默认分配策略
-
默认分配策略:org.apache.kafka.clients.producer.internals.BuiltInPartitioner
有key:Utils.toPositive(Utils.murmur2(serializedKey)) % numPartitions;
key拿到hash值,取余分区数
没有key:是使用随机数 % numPartitions
随机数取余分区数

-
轮询分配策略:RoundRobinPartitioner (接口:Partitioner)
实现方式一,通过配置分配策略实现轮询策略:
spring: application: # 应用名称 name: spring-boot-01-kafka-base kafka: # kafka连接地址 bootstrap-servers: 192.168.200.129:9092 # 配置生产者(有24个配置) producer: # value默认是StringSerializer.class序列化 value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # key也默认是StringSerializer.class序列化 # key-serializer: org.apache.kafka.common.serialization.StringSerializer properties: # 配置分区轮询分配策略 partitioner.class: org.apache.kafka.clients.producer.RoundRobinPartitioner # 配置消费者(有24个配置) consumer: auto-offset-reset: latest # 配置模板默认的主题topic名称 template: default-topic: default-topic新增发送消息方法,测试方法循环调用5次:
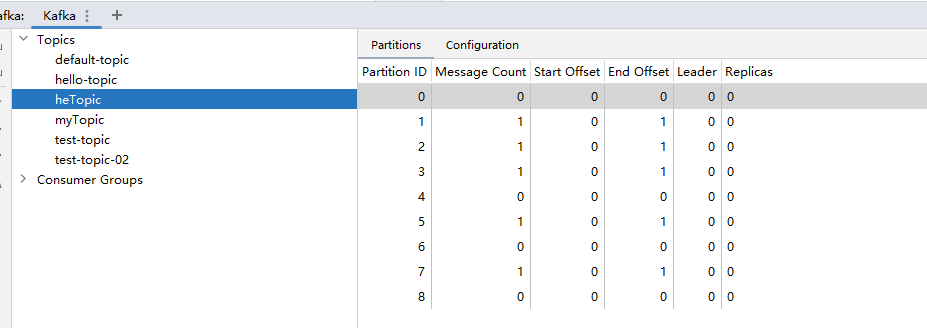
public void sendEvent10() { User user = User.builder().id(1208).phone("13709090909").birthDay(new Date()).build(); //分区是null,让kafka自己去决定把消息发到哪个分区 kafkaTemplate2.send("heTopic", user); }测试类:
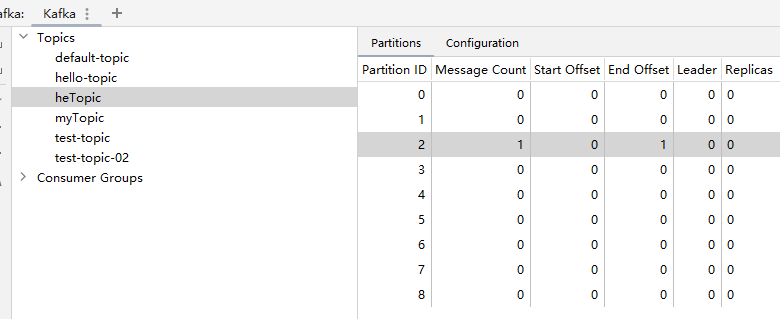
@Test void test10() { for (int i = 0; i < 5; i++) { eventProducer.sendEvent10(); } }删除heTopic,并运行测试方法,我们可以看到并不是一个很标准的轮询。
方式二:通过代码进行设置一个新的kafkaTemplate覆盖默认生成的
在KafkaConfig增加如下代码:
@Value("${spring.kafka.bootstrap-servers}") private String bootstrapServers; @Value("${spring.kafka.producer.value-serializer}") private String valueSerializer; @Value("${spring.kafka.producer.key-serializer}") private String keySerializer; /** * 生产者相关配置 * * @return */ public Map<String, Object> producerConfigs() { HashMap<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, keySerializer); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, valueSerializer); // 设置分区策略为轮询策略 props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class); return props; } public ProducerFactory<String, ?> producerFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs()); } @Bean public KafkaTemplate<String, ?> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); }application.yaml全部配置如下:
spring: application: # 应用名称 name: spring-boot-01-kafka-base kafka: # kafka连接地址 bootstrap-servers: 192.168.200.129:9092 # 配置生产者(有24个配置) producer: # value默认是StringSerializer.class序列化 value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # key也默认是StringSerializer.class序列化 key-serializer: org.apache.kafka.common.serialization.StringSerializer # properties: # partitioner.class: org.apache.kafka.clients.producer.RoundRobinPartitioner # 配置消费者(有24个配置) consumer: auto-offset-reset: latest # 配置模板默认的主题topic名称 template: default-topic: default-topic删除heTopic并启动测试方法:结果与方式一的一样。
-
自定义分配策略:我们自己定义;
写一个自定义分配策略类CustomerPartitioner.java:
package com.bjpowernode.config; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import org.apache.kafka.common.PartitionInfo; import org.apache.kafka.common.utils.Utils; import java.util.List; import java.util.Map; import java.util.concurrent.atomic.AtomicInteger; public class CustomerPartitioner implements Partitioner { private AtomicInteger nextPartition = new AtomicInteger(0); @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if (key == null) { // 使用轮询方式选择分区 int next = nextPartition.getAndIncrement(); if (next >= numPartitions) { nextPartition.compareAndSet(next, 0); } System.out.println("分区值:" + next); return next; } else { // 如果key不为null,则使用默认的分区策略 return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } } @Override public void close() { } @Override public void configure(Map<String, ?> configs) { } }修改配置类的分区策略我们自定义的分区策略
public Map<String, Object> producerConfigs() { HashMap<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, keySerializer); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, valueSerializer); // 设置分区策略为轮询策略 // props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class); // 设置分区策略为自定义策略,有key,则按默认策略。没有key,则轮询 props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomerPartitioner.class); return props; }再次执行测试方法后,消息分步如下,我们发现每隔一个存在一个,这是因为获取分区数在源码中调用了2次,实际生效的是调用的第2次。
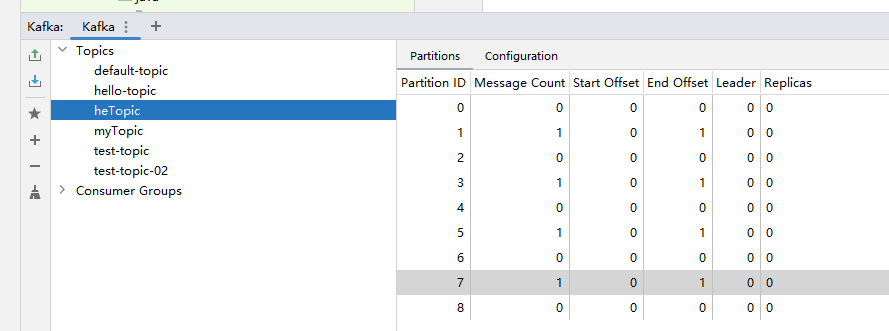
生产者发送消息拦截器
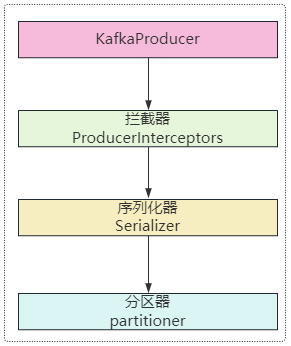
拦截生产者发送的消息
自定义拦截器拦截消息的发送;
实现ProducerInterceptor<K, V>接口;
创建拦截器类CustomerProducerInterceptor.java:
package com.bjpowernode.config;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
public class CustomerProducerInterceptor implements ProducerInterceptor<String, Object> {
/**
* 发送消息时,会先调用该方法,对消息进行拦截,可以在拦截中对消息做一些处理,记录日志等等操作.....
*
* @param record the record from client or the record returned by the previous interceptor in the chain of interceptors.
* @return
*/
@Override
public ProducerRecord<String, Object> onSend(ProducerRecord<String, Object> record) {
System.out.println("拦截消息:" + record.toString());
return record;
}
/**
* 服务器收到消息后的一个确认
*
* @param metadata The metadata for the record that was sent (i.e. the partition and offset).
* If an error occurred, metadata will contain only valid topic and maybe
* partition. If partition is not given in ProducerRecord and an error occurs
* before partition gets assigned, then partition will be set to RecordMetadata.NO_PARTITION.
* The metadata may be null if the client passed null record to
* {@link org.apache.kafka.clients.producer.KafkaProducer#send(ProducerRecord)}.
* @param exception The exception thrown during processing of this record. Null if no error occurred.
*/
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (metadata != null) {
System.out.println("服务器收到该消息:" + metadata.offset());
} else {
System.out.println("消息发送失败了,exception = " + exception);
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
方式一:在配置类KafkaConfig.java中增加拦截器配置:
public Map<String, Object> producerConfigs() {
HashMap<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, keySerializer);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, valueSerializer);
// 设置分区策略为轮询策略
// props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class);
// 设置分区策略为自定义策略,有key,则按默认策略。没有key,则轮询
// props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomerPartitioner.class);
// 添加拦截器,多个用逗号拼接
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomerProducerInterceptor.class.getName());
return props;
}
删除heTopic主题,执行test09测试方法,拦截成功:

方式二在配置文件中配置拦截器:
先注释掉自定义的kafkaTemplate,使用项目启动默认生成的。
// @Bean
public KafkaTemplate<String, ?> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
配置拦截器:
spring:
application:
# 应用名称
name: spring-boot-01-kafka-base
kafka:
# kafka连接地址
bootstrap-servers: 192.168.200.129:9092
# 配置生产者(有24个配置)
producer:
# value默认是StringSerializer.class序列化
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
# key也默认是StringSerializer.class序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
# 配置分区策略:轮询策略
# partitioner.class: org.apache.kafka.clients.producer.RoundRobinPartitioner
# 配置生产者拦截器
interceptor:
classes: com.bjpowernode.config.CustomerProducerInterceptor
# 配置消费者(有24个配置)
consumer:
auto-offset-reset: latest
# 配置模板默认的主题topic名称
template:
default-topic: default-topic
删除heTopic主题,执行test09测试方法,拦截成功。
获取生产者发送的消息
新建一个模块spring-boot-02-kafka-base
- pom.xml配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.bjpowernode</groupId>
<artifactId>spring-boot-02-kafka-base</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-boot-02-kafka-base</name>
<description>spring-boot-02-kafka-base</description>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
- 主启动类:
package com.bjpowernode;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class KafkaBaseApplication {
public static void main(String[] args) {
SpringApplication.run(KafkaBaseApplication.class, args);
}
}
- application.yaml配置文件
spring:
application:
# 应用名称
name: spring-boot-02-kafka-base
kafka:
# kafka连接地址
bootstrap-servers: 192.168.200.129:9092
# 配置生产者(有24个配置)
# producer:
# 配置消费者(有24个配置)
# consumer:
- 生产者
package com.bjpowernode.producer;
import jakarta.annotation.Resource;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
@Component
public class EventProducer {
// 加入了spring-kafka依赖+.yml配置。springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
public void sendEvent() {
kafkaTemplate.send("helloTopic", "hello kafka");
}
}
- 消费者:
package com.bjpowernode.consumer;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class EventConsumer {
@KafkaListener(topics = {"helloTopic"},groupId = "helloGroup")
public void onEvent(String event) {
System.out.println("读取到的事件:" + event);
}
}
- 生产者:
package com.bjpowernode.consumer;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class EventConsumer {
@KafkaListener(topics = {"helloTopic"},groupId = "helloGroup")
public void onEvent(String event) {
System.out.println("读取到的事件:" + event);
}
}
- 测试类:
package com.bjpowernode;
import com.bjpowernode.producer.EventProducer;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class KafkaBaseApplicationTests {
@Autowired
private EventProducer eventProducer;
@Test
void test01() {
eventProducer.sendEvent();
}
}
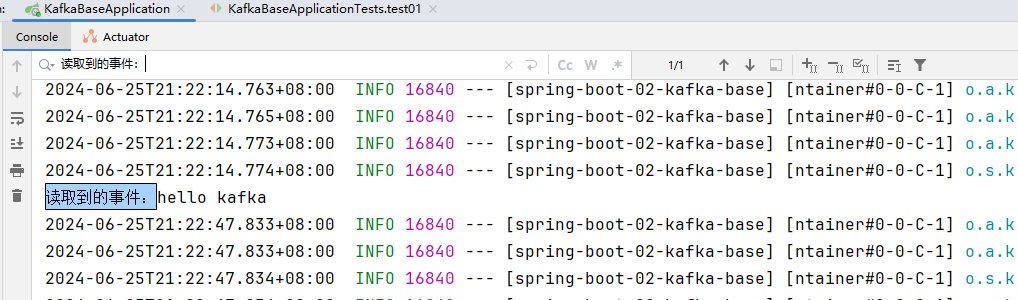
- 启动服务,开始进行监听;
- 运行测试方法test01发送消息,正常消费消息:
在消费者增加注解@Payload,标记该参数是消息体内容
package com.bjpowernode.consumer;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;
@Component
public class EventConsumer {
@KafkaListener(topics = {"helloTopic"},groupId = "helloGroup")
public void onEvent(@Payload String event) {
System.out.println("读取到的事件:" + event);
}
}
重启项目并运行测试方法,可以看到还是正常消费消息。
在参数增加消息头内容注解@Header:标记该参数是消息头内容
package com.bjpowernode.consumer;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;
@Component
public class EventConsumer {
@KafkaListener(topics = {"helloTopic"}, groupId = "helloGroup")
public void onEvent(@Payload String event,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
// @Header(value = KafkaHeaders.RECEIVED_KEY) String key,没有key接收会报错
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition) {
System.out.println("读取到的事件:" + "event = " + event + ", topic = " +
topic + ", partition = " + partition);
}
}
重新启动项目,并执行测试方法test01:

我们还可以用ConsumerRecord<String, String> record来接收消息,用这个接收消息比较全:
package com.bjpowernode.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;
@Component
public class EventConsumer {
@KafkaListener(topics = {"helloTopic"}, groupId = "helloGroup")
public void onEvent(@Payload String event,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
// @Header(value = KafkaHeaders.RECEIVED_KEY) String key,没有key接收会报错
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition,
ConsumerRecord<String, String> record) {
System.out.println("读取到的事件:" + "event = " + event + ", topic = " +
topic + ", partition = " + partition);
System.out.println("读取到的事件:" + "record = " + record.toString());
}
}
重新启动项目,并执行测试方法test01:

在ConsumerRecord<String, String> record上面添加@Payload注解会报错吗,我们加了后重新测试,发现正常消费。只是这个注解感觉不是那么清晰
获取生产者发送的对象消息
- 增加User类
package com.bjpowernode.modole;
import lombok.*;
import java.util.Date;
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User {
private int id;
private String phone;
private Date birthDay;
}
- 在EventProducer.java类中增加发送User对象的方法
@Resource
private KafkaTemplate<String, Object> kafkaTemplate2;
public void sendEvent2() {
User user = User.builder().id(1209).phone("13709090909").birthDay(new Date()).build();
kafkaTemplate2.send("helloTopic", user);
}
- 在消费者增加消费方法
package com.bjpowernode.consumer;
import com.bjpowernode.modole.User;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;
@Component
public class EventConsumer {
// @KafkaListener(topics = {"helloTopic"}, groupId = "helloGroup")
public void onEvent(@Payload String event,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
// @Header(value = KafkaHeaders.RECEIVED_KEY) String key,没有key接收会报错
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition,
ConsumerRecord<String, String> record) {
System.out.println("读取到的事件:" + "event = " + event + ", topic = " +
topic + ", partition = " + partition);
System.out.println("读取到的事件:" + "record = " + record.toString());
}
// @KafkaListener(topics = {"helloTopic"}, groupId = "helloGroup")
public void onEvent2(@Payload User user,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition,
ConsumerRecord<String, String> record) {
System.out.println("读取到的事件:" + "user = " + user + ", topic = " +
topic + ", partition = " + partition);
System.out.println("读取到的事件:" + record.toString());
}
}
- 配置类配置生产者值序列化方式,消费者值反序列化方式
spring:
application:
# 应用名称
name: spring-boot-02-kafka-base
kafka:
# kafka连接地址
bootstrap-servers: 192.168.200.129:9092
# 配置生产者(有24个配置)
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
# 配置消费者(有24个配置)
consumer:
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
- 增加测试方法:
@Test
void test02() {
eventProducer.sendEvent2();
}
-
启动服务,并执行test02方法
启动服务报错

增加pom.xml的依赖:
<dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency>再次启动服务并执行test02方法,我们发现发送正常,消费报错

User类不在受信任的包中,java.util,java.lang
这里需要增加配置才能满足我们正常反序列化对象。
spring: application: # 应用名称 name: spring-boot-02-kafka-base kafka: # kafka连接地址 bootstrap-servers: 192.168.200.129:9092 # 配置生产者(有24个配置) producer: value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 配置消费者(有24个配置) consumer: value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer properties: # 信任所有的类 spring.json.trusted.packages: "*"再次启动项目并执行测试方法,正常发送和消费消息:

我们也可以通过发送字符串的方式发送user,通过将user对象转成字符串,然后接收再转换为user对象:
- 准备json和对象相互转换的工具类:
package com.bjpowernode.util;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class JSONUtils {
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
public static String toJSON(Object object) {
try {
return OBJECT_MAPPER.writeValueAsString(object);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
public static <T> T toBean(String json, Class<T> clazz) {
try {
return OBJECT_MAPPER.readValue(json, clazz);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
}
- 消费者如下:
package com.bjpowernode.consumer;
import com.bjpowernode.modole.User;
import com.bjpowernode.util.JSONUtils;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;
@Component
public class EventConsumer {
// @KafkaListener(topics = {"helloTopic"}, groupId = "helloGroup")
public void onEvent(@Payload String event,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
// @Header(value = KafkaHeaders.RECEIVED_KEY) String key,没有key接收会报错
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition,
ConsumerRecord<String, String> record) {
System.out.println("读取到的事件1:" + "event = " + event + ", topic = " +
topic + ", partition = " + partition);
System.out.println("读取到的事件1:" + "record = " + record.toString());
}
// @KafkaListener(topics = {"helloTopic"}, groupId = "helloGroup")
public void onEvent2(@Payload User user,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition,
ConsumerRecord<String, String> record) {
System.out.println("读取到的事件2:" + "user = " + user + ", topic = " +
topic + ", partition = " + partition);
System.out.println("读取到的事件2:" + record.toString());
}
@KafkaListener(topics = {"helloTopic"}, groupId = "helloGroup")
public void onEvent3(@Payload String userJSON,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition,
ConsumerRecord<String, String> record) {
User user = JSONUtils.toBean(userJSON, User.class);
System.out.println("读取到的事件3:" + "user = " + user + ", topic = " +
topic + ", partition = " + partition);
System.out.println("读取到的事件3:" + record.toString());
}
}
- 生产类增加方法::
public void sendEvent3() {
User user = User.builder().id(1209).phone("13709090909").birthDay(new Date()).build();
String userJSON = JSONUtils.toJSON(user);
kafkaTemplate.send("helloTopic", userJSON);
}
- 测试类:
@Test
void test03() {
eventProducer.sendEvent3();
}
- 配置yaml文件:
spring:
application:
# 应用名称
name: spring-boot-02-kafka-base
kafka:
# kafka连接地址
bootstrap-servers: 192.168.200.129:9092
# 配置生产者(有24个配置)
# producer:
# value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
# 配置消费者(有24个配置)
# consumer:
# value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
# properties:
# 信任所有的类
# spring.json.trusted.packages: "*"
- 启动项目,并执行test03方法,正常发送并消费:

- 通过占位符读取主题和分组
# 自定义的配置
kafka:
topic:
name: helloTopic
consumer:
group: helloGroup
修改@KafkaListener注解的主题和分组为读取配置的方式,重新启动并测试,正常发送和消费消息:
// @KafkaListener(topics = {"helloTopic"}, groupId = "helloGroup")
@KafkaListener(topics = {"${kafka.topic.name}"}, groupId = "${kafka.consumer.group}")
public void onEvent3(@Payload String userJSON,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition,
ConsumerRecord<String, String> record) {
User user = JSONUtils.toBean(userJSON, User.class);
System.out.println("读取到的事件3:" + "user = " + user + ", topic = " +
topic + ", partition = " + partition);
System.out.println("读取到的事件3:" + record.toString());
}
默认情况下,Kafka消费者消费消息后会自动发送确认信息给Kafka服务器,表示消息已经被成功消费。但在某些场景下,我们希望在消息处理成功后再发送确认,或者在消息处理失败时选择不发送确认,以便Kafka能够重新发送该消息
注释onEvent3,新建一个onEvent4,接收参数增加Acknowledgment ack,在代码中手动确认消息
// @KafkaListener(topics = {"helloTopic"}, groupId = "helloGroup")
// @KafkaListener(topics = {"${kafka.topic.name}"}, groupId = "${kafka.consumer.group}")
public void onEvent3(@Payload String userJSON,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition,
ConsumerRecord<String, String> record) {
User user = JSONUtils.toBean(userJSON, User.class);
System.out.println("读取到的事件3:" + "user = " + user + ", topic = " +
topic + ", partition = " + partition);
System.out.println("读取到的事件3:" + record.toString());
}
@KafkaListener(topics = {"${kafka.topic.name}"}, groupId = "${kafka.consumer.group}")
public void onEvent4(@Payload String userJSON,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition,
ConsumerRecord<String, String> record,
Acknowledgment ack) { // 开启手动确认模式,才能使用这个参数,否则启动项目会报错
User user = JSONUtils.toBean(userJSON, User.class);
System.out.println("读取到的事件4:" + "user = " + user + ", topic = " +
topic + ", partition = " + partition);
System.out.println("读取到的事件4:" + record.toString());
// 手动确认消息,就是告诉kafka服务器,该消息我已经收到了,默认情况下kafka是自动确认
ack.acknowledge();
}
配置文件中开启手动确认模式
spring:
application:
# 应用名称
name: spring-boot-02-kafka-base
kafka:
# kafka连接地址
bootstrap-servers: 192.168.200.129:9092
# 配置生产者(有24个配置)
# producer:
# value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
# 配置消费者(有24个配置)
# consumer:
# value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
# properties:
# 信任所有的类
# spring.json.trusted.packages: "*"
# 配置消息监听器
listener:
# 开启消息监听的手动确认模式
ack-mode: manual
# 自定义的配置
kafka:
topic:
name: helloTopic
consumer:
group: helloGroup
启动项目,并执行test03方法:
正常发送并消费:

注释掉手动确认代码,再次启动项目,并执行test03测试方法:会重复消费,项目再次启动,又会消费
// 手动确认消息,就是告诉kafka服务器,该消息我已经收到了,默认情况下kafka是自动确认
// ack.acknowledge();
我们通常将业务代码try catch起来,这样正常执行就ack,报错就不提交,这样可以重复消费
@KafkaListener(topics = {"${kafka.topic.name}"}, groupId = "${kafka.consumer.group}")
public void onEvent4(@Payload String userJSON,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition,
ConsumerRecord<String, String> record,
Acknowledgment ack) { // 开启手动确认模式,才能使用这个参数,否则启动项目会报错
try {
User user = JSONUtils.toBean(userJSON, User.class);
System.out.println("读取到的事件4:" + "user = " + user + ", topic = " +
topic + ", partition = " + partition);
System.out.println("读取到的事件4:" + record.toString());
// 手动确认消息,就是告诉kafka服务器,该消息我已经收到了,默认情况下kafka是自动确认
ack.acknowledge();
} catch (Exception e) {
e.printStackTrace();
}
}
消费者指定topic、partition、offset消费
新增消费方法onEvent5注释掉onEvent4方法的监听注解:
/* @KafkaListener(topicPartitions = {
@TopicPartition(
topic = "${kafka.topic.name}",
partitions = {"0", "1", "2"},
partitionOffsets = {
@PartitionOffset(partition = "3", initialOffset = "3"),
@PartitionOffset(partition = "4", initialOffset = "3")
}
)
}, groupId = "${kafka.consumer.group}") */
public void onEvent5(@Payload String userJSON,
@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(name = KafkaHeaders.RECEIVED_PARTITION) String partition,
ConsumerRecord<String, String> record,
Acknowledgment ack) { // 开启手动确认模式,才能使用这个参数,否则启动项目会报错
try {
User user = JSONUtils.toBean(userJSON, User.class);
System.out.println("读取到的事件5:" + "user = " + user + ", topic = " +
topic + ", partition = " + partition);
System.out.println("读取到的事件5:" + record.toString());
// 手动确认消息,就是告诉kafka服务器,该消息我已经收到了,默认情况下kafka是自动确认
ack.acknowledge();
} catch (Exception e) {
e.printStackTrace();
}
}
生产类增加方法:
public void sendEvent4() {
for (int i = 0; i < 25; i++) {
User user = User.builder().id(i).phone("1370909090" + i).birthDay(new Date()).build();
String userJSON = JSONUtils.toJSON(user);
kafkaTemplate.send("helloTopic", "k" + i, userJSON);
}
}
测试类增加方法:
@Test
void test04() {
eventProducer.sendEvent4();
}
删除所有topic,增加KafkaConfig.java配置类helloTopic,并指定5个分区
package com.bjpowernode.config;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaConfig {
@Bean
public NewTopic newTopic() {
return new NewTopic("helloTopic", 5, (short) 1);
}
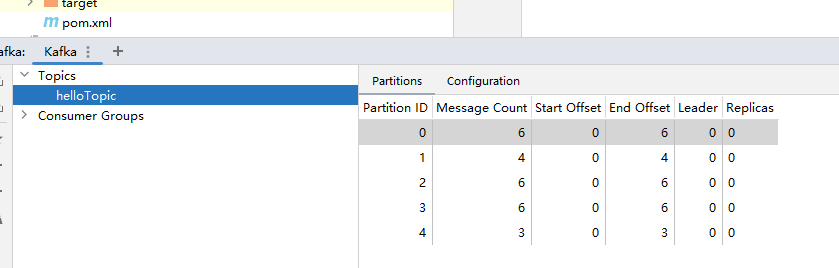
}
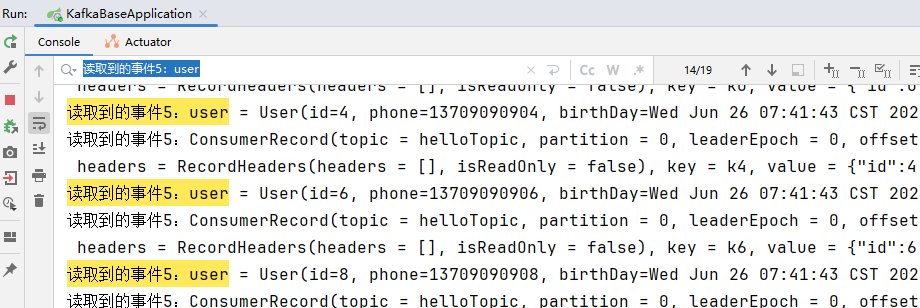
执行测试方法test04发送消息:0,1,2分区分别有6,4,6条消息,3,4分区分别有6,3条消息。
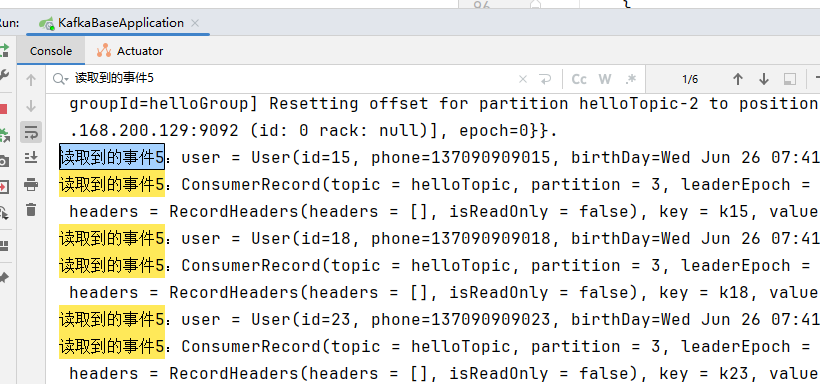
打开onEvent5上@KafkaListener注解,启动项目:
通过日志,我们可以看到读到了3条记录,这3条记录是3分区从3的位置开始,往后读了3条
再次重启项目,依然是读了3条。
为了让0,1,2能消费到消息,我们修改application.yaml配置:
spring:
application:
# 应用名称
name: spring-boot-02-kafka-base
kafka:
# kafka连接地址
bootstrap-servers: 192.168.200.129:9092
# 配置生产者(有24个配置)
# producer:
# value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
# 配置消费者(有24个配置)
consumer:
auto-offset-reset: earliest
# value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
# properties:
# 信任所有的类
# spring.json.trusted.packages: "*"
# 配置消息监听器
listener:
# 开启消息监听的手动确认模式
ack-mode: manual
# 自定义的配置
kafka:
topic:
name: helloTopic
consumer:
group: helloGroup2
再次启动项目,我们可以看到读取了19条消息:0,1,2分区6+4+6,再加上3分区的3条,一共19条。
消费者批量消费消息
-
创建项目
spring-boot-03-kafka-basepackage com.bjpowernode; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class KafkaBaseApplication { public static void main(String[] args) { SpringApplication.run(KafkaBaseApplication.class, args); } } -
pom.xml<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.3</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.bjpowernode</groupId> <artifactId>spring-boot-03-kafka-base</artifactId> <version>0.0.1-SNAPSHOT</version> <name>spring-boot-03-kafka-base</name> <description>spring-boot-03-kafka-base</description> <properties> <java.version>17</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <scope>runtime</scope> <optional>true</optional> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build> </project> -
application.yamlspring: application: # 应用名称 name: spring-boot-03-kafka-base kafka: # kafka连接地址(ip+port) bootstrap-servers: 192.168.200.129:9092 # 配置消息监听器 listener: # 设置批量消费,默认是单个消息消费 type: batch consumer: # 批量消费每次最多消费多少条消息 max-poll-records: 20 # 从第一条消息开始接收 auto-offset-reset: earliest -
EventConsumer.javapackage com.bjpowernode.consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.springframework.stereotype.Component; import java.util.List; @Component public class EventConsumer { // @KafkaListener(topics = {"batchTopic"}, groupId = "batchGroup") public void onEvent(List<ConsumerRecord<String, String>> records) { System.out.println("批量消费,records.size() = " + records.size() + ",records = " + records); } } -
将spring-boot-02-kafka-base的
model包和util包拷贝过来 -
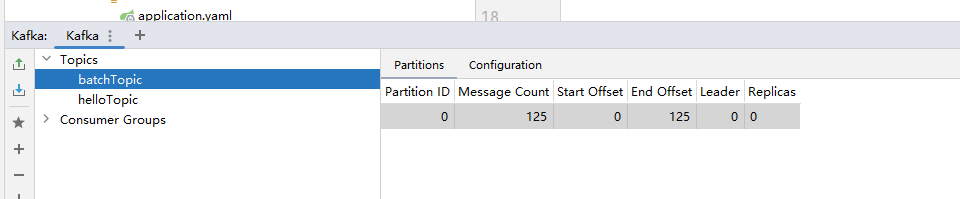
EventProducer.javaimport com.bjpowernode.util.JSONUtils; import jakarta.annotation.Resource; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.stereotype.Component; import java.util.Date; @Component public class EventProducer { @Resource private KafkaTemplate<String, String> kafkaTemplate; public void sendEvent() { for (int i = 0; i < 125; i++) { User user = User.builder().id(i).phone("1370909090" + i).birthDay(new Date()).build(); String userJSON = JSONUtils.toJSON(user); kafkaTemplate.send("batchTopic", userJSON); } } } -
测试方法:
package com.bjpowernode; import com.bjpowernode.producer.EventProducer; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; @SpringBootTest class KafkaBaseApplicationTests { @Autowired private EventProducer eventProducer; @Test void test01() { eventProducer.sendEvent(); } } -
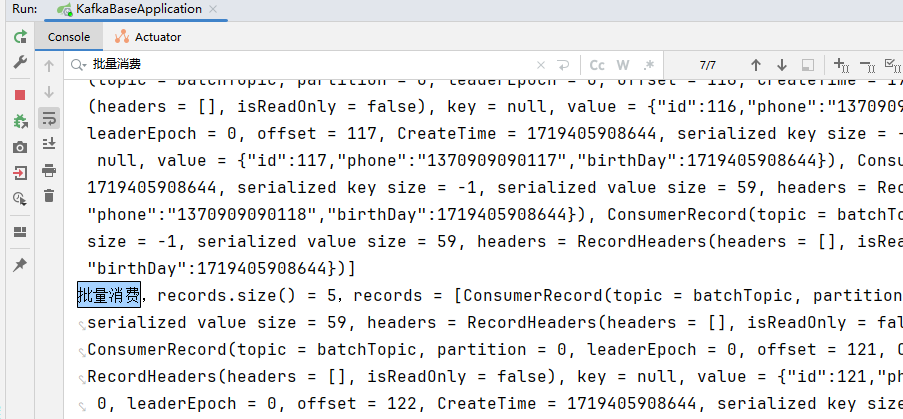
运行测试方法后,打开监听器注解,启动服务:
一共有7次消费记录
消费消息时的消息拦截
在消息消费之前,我们可以通过配置拦截器对消息进行拦截,在消息被实际处理之前对其进行一些操作,例如记录日志、修改消息内容或执行一些安全检查等;
-
创建项目
spring-boot-04-kafka-basepackage com.bjpowernode; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.context.ConfigurableApplicationContext; import org.springframework.kafka.config.KafkaListenerContainerFactory; import org.springframework.kafka.core.ConsumerFactory; import java.util.Map; @SpringBootApplication public class KafkaBaseApplication { public static void main(String[] args) { ConfigurableApplicationContext context = SpringApplication.run(KafkaBaseApplication.class, args); System.out.println("------------"); Map<String, ConsumerFactory> beansOfType1 = context.getBeansOfType(ConsumerFactory.class); beansOfType1.forEach((k,v) ->{ System.out.println(k + " -- " + v); // DefaultKafkaConsumerFactory }); System.out.println("------------"); Map<String, KafkaListenerContainerFactory> beansOfType2 = context.getBeansOfType(KafkaListenerContainerFactory.class); beansOfType2.forEach((k,v) ->{ System.out.println(k + " -- " + v); // ConcurrentKafkaListenerContainerFactory }); } } -
pom.xml<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.3</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.bjpowernode</groupId> <artifactId>spring-boot-04-kafka-base</artifactId> <version>0.0.1-SNAPSHOT</version> <name>spring-boot-04-kafka-base</name> <description>spring-boot-04-kafka-base</description> <properties> <java.version>17</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build> </project> -
创建自定义消费者拦截器
CustomConsumerInterceptor.java:package com.bjpowernode.intercepter; import org.apache.kafka.clients.consumer.ConsumerInterceptor; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.OffsetAndMetadata; import org.apache.kafka.common.TopicPartition; import java.util.Map; /** * 自定义的消费者拦截器 */ public class CustomConsumerInterceptor implements ConsumerInterceptor<String, String> { /** * 在消费消息之前执行 * * @param records records to be consumed by the client or records returned by the previous interceptors in the list. * @return */ @Override public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) { System.out.println("onConsume方法执行:records = " + records); return records; } /** * 消息拿到之后,提交offset之前执行该方法 * * @param offsets A map of offsets by partition with associated metadata */ @Override public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) { System.out.println("onCommit方法执行:offsets = " + offsets); } @Override public void close() { } @Override public void configure(Map<String, ?> configs) { } } -
application.yamlspring: application: # 应用名称 name: spring-boot-04-kafka-base kafka: # kafka连接地址(ip+port) bootstrap-servers: 192.168.200.129:9092 consumer: properties: # 拦截器配置,执行先后顺序取决于配置顺序,多个用,拼接 interceptor: com.bjpowernode.interceptor.CustomConsumerInterceptor -
EventConsumer.javapackage com.bjpowernode.consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.stereotype.Component; @Component public class EventConsumer { @KafkaListener(topics = {"intTopic"}, groupId = "intGroup") public void onEvent(ConsumerRecord<String, String> record) { System.out.println("消息消费,record = " + record); } } -
将spring-boot-02-kafka-base的
model包和util包拷贝过来 -
EventProducer.javapackage com.bjpowernode.producer; import com.bjpowernode.modole.User; import com.bjpowernode.util.JSONUtils; import jakarta.annotation.Resource; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.stereotype.Component; import java.util.Date; @Component public class EventProducer { @Resource private KafkaTemplate<String, String> kafkaTemplate; public void sendEvent() { User user = User.builder().id(1028).phone("13709090901").birthDay(new Date()).build(); String userJSON = JSONUtils.toJSON(user); kafkaTemplate.send("intTopic", "k", userJSON); } } -
测试方法:
package com.bjpowernode; import com.bjpowernode.producer.EventProducer; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; @SpringBootTest class KafkaBaseApplicationTests { @Autowired private EventProducer eventProducer; @Test void test01() { eventProducer.sendEvent(); } } -
先启动服务,让消费者开始监听,然后运行测试方法发送消息,可以看到拦截器生效了

方式二,使用代码注册拦截器:
- 创建配置类
KafkaConfig.java
package com.bjpowernode.config;
import com.bjpowernode.interceptor.CustomConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.consumer.key-deserializer}")
private String keyDeserializer;
@Value("${spring.kafka.consumer.value-deserializer}")
private String valueDeserializer;
public Map<String,Object> consumerConfigs() {
HashMap<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 键值反序列化,自定义配置方式一定要配置,不然会报错
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, keyDeserializer);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer);
//添加一个消费拦截器
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomConsumerInterceptor.class.getName());
return props;
}
@Bean
public ConsumerFactory<String, String> myConsumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public KafkaListenerContainerFactory<?> myKafkaListenerContainerFactory(ConsumerFactory<String, String> myConsumerFactory) {
ConcurrentKafkaListenerContainerFactory<String, String> listenerContainerFactory = new ConcurrentKafkaListenerContainerFactory<>();
listenerContainerFactory.setConsumerFactory(myConsumerFactory);
return listenerContainerFactory;
}
}
-
监听消息时使用我们的监听器容器工厂Bean,指定
containerFactory,不指定,拦截器不会拦截;package com.bjpowernode.consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.stereotype.Component; @Component public class EventConsumer { @KafkaListener(topics = {"intTopic"}, groupId = "intGroup",containerFactory="myKafkaListenerContainerFactory") public void onEvent(ConsumerRecord<String, String> record) { System.out.println("消息消费,record = " + record); } } -
修改
application.yaml,配置键值反序列化,注释掉拦截器配置:spring: application: # 应用名称 name: spring-boot-04-kafka-base kafka: # kafka连接地址(ip+port) bootstrap-servers: 192.168.200.129:9092 consumer: # key反序列化 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # value反序列化 value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # properties: # 拦截器配置,执行先后顺序取决于配置顺序,多个用,拼接 # interceptor: # classes: com.bjpowernode.interceptor.CustomConsumerInterceptor启动服务,可以看到只有一个我们自己定义的ConsumerFactory,
而KafkaListenerContainerFactory有2个,一个我们自己定义的,一个原来默认的。这里2个用得ConsumerFactory是不同的。

发送消息后看服务消费:

消息转发
消息转发就是应用A从TopicA接收到消息,经过处理后转发到TopicB,再由应用B监听接收该消息,即一个应用处理完成后将该消息转发至其他应用处理,这在实际开发中,是可能存在这样的需求的;
-
将
spring-boot-04-kafka-base直接复制并粘贴一份改名为spring-boot-05-kafka-base -
修改
pom.xml、application.yaml,将里面的spring-boot-04-kafka-base全部替换成spring-boot-05-kafka-base -
右键
pom.xml添加为maven工程 -
删除
config包,interceptor包 -
修改
EventConsumer.javapackage com.bjpowernode.consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.messaging.handler.annotation.SendTo; import org.springframework.stereotype.Component; @Component public class EventConsumer { @KafkaListener(topics = {"topicA"}, groupId = "aGroup") @SendTo(value = "topicB") public String onEventA(ConsumerRecord<String, String> record) { System.out.println("消息A消费,record = " + record); return record.value() + "forward message"; } @KafkaListener(topics = {"topicB"}, groupId = "bGroup") public void onEventB(ConsumerRecord<String, String> record) { System.out.println("消息B消费,record = " + record); } } -
修改
EventProducer.java:package com.bjpowernode.producer; import com.bjpowernode.modole.User; import com.bjpowernode.util.JSONUtils; import jakarta.annotation.Resource; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.stereotype.Component; import java.util.Date; @Component public class EventProducer { @Resource private KafkaTemplate<String, String> kafkaTemplate; public void sendEvent() { User user = User.builder().id(1028).phone("13709090901").birthDay(new Date()).build(); String userJSON = JSONUtils.toJSON(user); kafkaTemplate.send("topicA", "k", userJSON); } } -
启动服务,发送消息:

消息消费的分区策略
Kafka消费消息时的分区策略:是指Kafka主题topic中哪些分区应该由哪些消费者来消费;
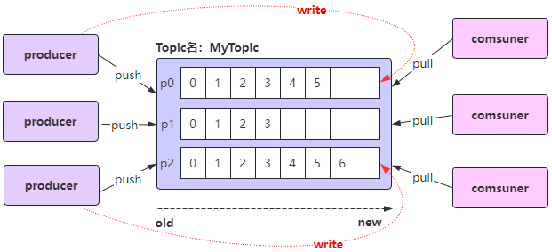
Kafka有多种分区分配策略,默认的分区分配策略是RangeAssignor,除了RangeAssignor策略外,Kafka还有其他分区分配策略:
- RoundRobinAssignor
- StickyAssignor
- CooperativeStickyAssignor
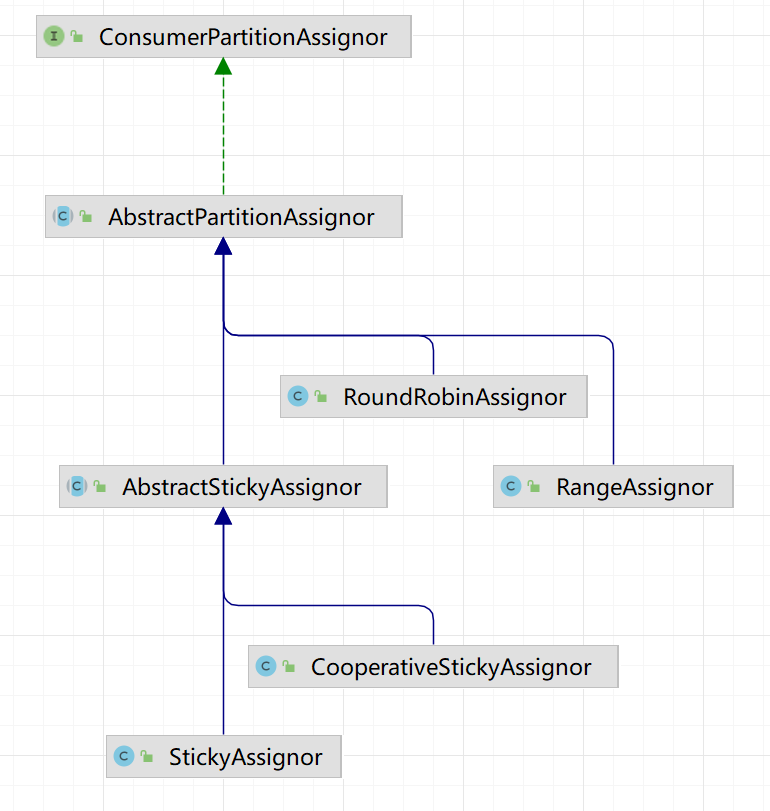
这些策略各有特点,可以根据实际的应用场景和需求来选择适合的分区分配策略;
RangeAssignor策略是根据消费者组内的消费者数量和主题的分区数量,来均匀地为每个消费者分配分区。
Kafka默认的消费分区分配策略:RangeAssignor;假设如下:
一个主题myTopic有10个分区;(p0 - p9)
一个消费者组内有3个消费者:consumer1、consumer2、consumer3;
RangeAssignor消费分区策略:
-
计算每个消费者应得的分区数:分区总数(10)/ 消费者数量(3)= 3 ... 余1;
每个消费者理论上应该得到3个分区,但由于有余数1,所以前1个消费者会多得到一个分区;
consumer1(作为第一个消费者)将得到 3 + 1 = 4 个分区;
consumer2 和 consumer3 将各得到 3 个分区;
-
具体分配:分区编号从0到9,按照编号顺序为消费者分配分区:
consumer1 将分配得到分区 0、1、2、3;
consumer2 将分配得到分区 4、5、6;
consumer3 将分配得到分区 7、8、9;
-
将
spring-boot-05-kafka-base直接复制并粘贴一份改名为spring-boot-06-kafka-base -
修改
pom.xml、application.yaml,将里面的spring-boot-05-kafka-base全部替换成spring-boot-06-kafka-basespring: application: # 应用名称 name: spring-boot-06-kafka-base kafka: # kafka连接地址(ip+port) bootstrap-servers: 192.168.200.129:9092 # 配置消费者(有24个配置) consumer: auto-offset-reset: earliest -
右键
pom.xml添加为maven工程 -
修改
EventConsumer.java// 开启3个线程去消费 @KafkaListener(topics = {"myTopic"}, groupId = "myGroup", concurrency = "3") public void onEvent(ConsumerRecord<String, String> record) { System.out.println(Thread.currentThread().getId() + "消息消费,record = " + record); } -
修改
EventProducer.javapublic void sendEvent() { for (int i = 0; i < 100; i++) { User user = User.builder().id(1028 + i).phone("13709090901" + i).birthDay(new Date()).build(); String userJSON = JSONUtils.toJSON(user); kafkaTemplate.send("myTopic", "k" + i, userJSON); } } -
创建
KafkaConfig.javapackage com.bjpowernode.config; import org.apache.kafka.clients.admin.NewTopic; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class KafkaConfig { @Bean public NewTopic newTopic() { return new NewTopic("myTopic", 10, (short) 1); } } -
注释掉@KafkaListener注解,先执行测试方法,发送100条消息,然后放开@KafkaListener注解,启动项目;
-
查看消费日志:
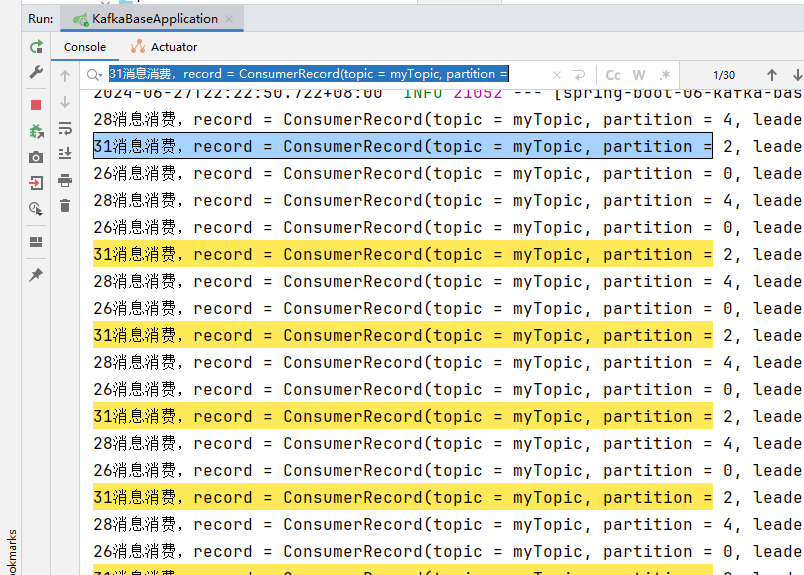
线程ID为26的消费41条,消费消息的分区为:0,1,2,3
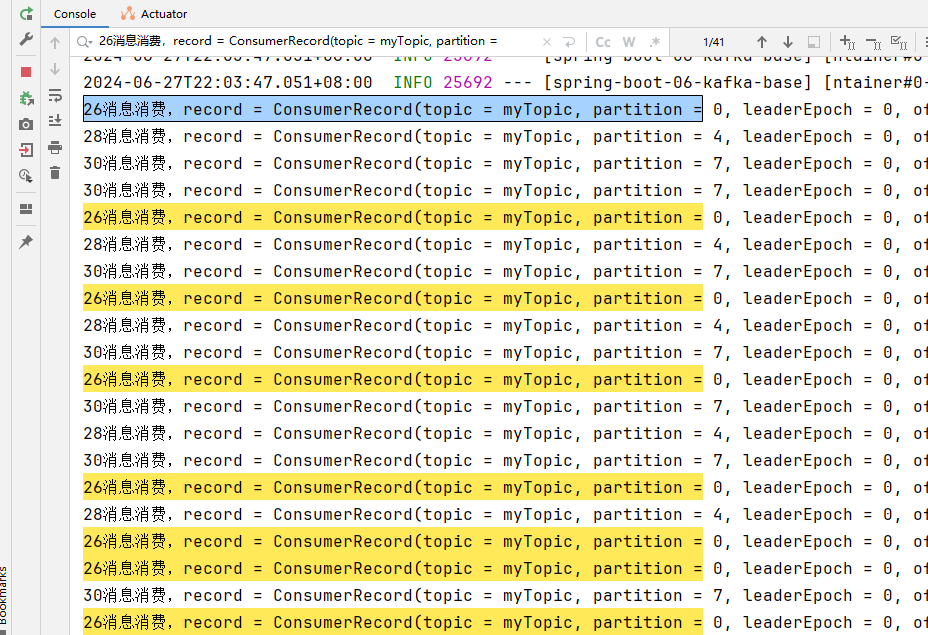
线程ID为28的消费33条,消费消息的分区为:4,5,6
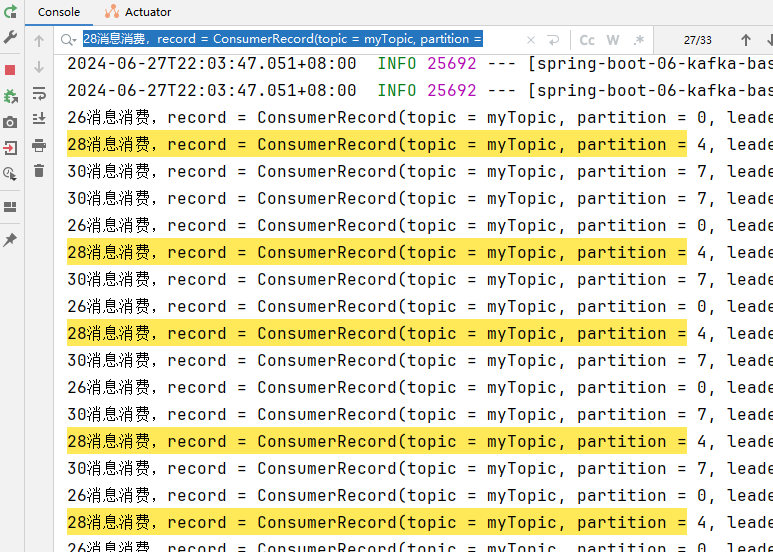
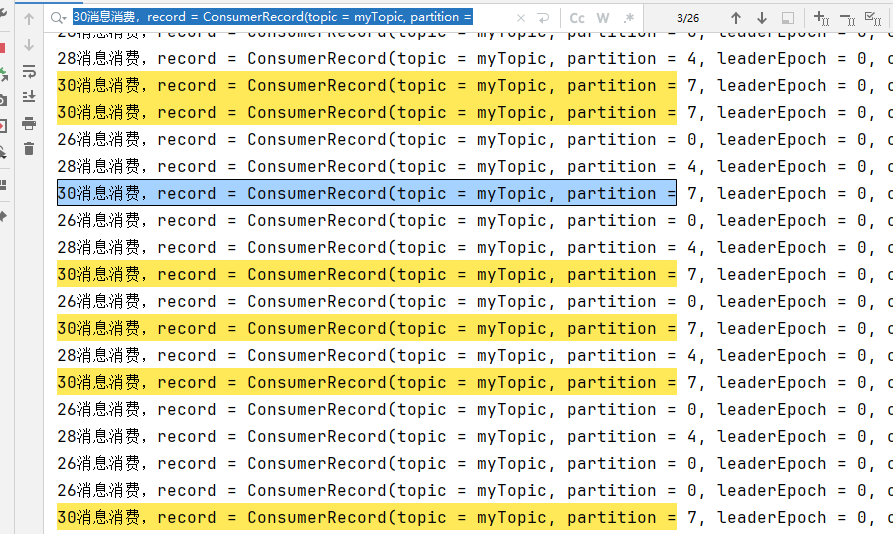
线程ID为30的消费26条,消费消息的分区为:7,8,9
-
修改配置文件,改成RoundRobinAssignor策略
spring: application: # 应用名称 name: spring-boot-06-kafka-base kafka: # kafka连接地址(ip+port) bootstrap-servers: 192.168.200.129:9092 # 配置消费者(有24个配置) consumer: auto-offset-reset: earliest properties: partition: assignment: # 配置消费消息的分区策略为轮询 strategy: org.apache.kafka.clients.consumer.RoundRobinAssignor -
修改@KafkaListener注解的消费组ID为
myGroup2,这样启动项目可以重新消费:@KafkaListener(topics = {"myTopic"}, groupId = "myGroup2", concurrency = "3") -
查看消费日志:
线程ID为26的消费41条,消费消息的分区为:0,3,6,9
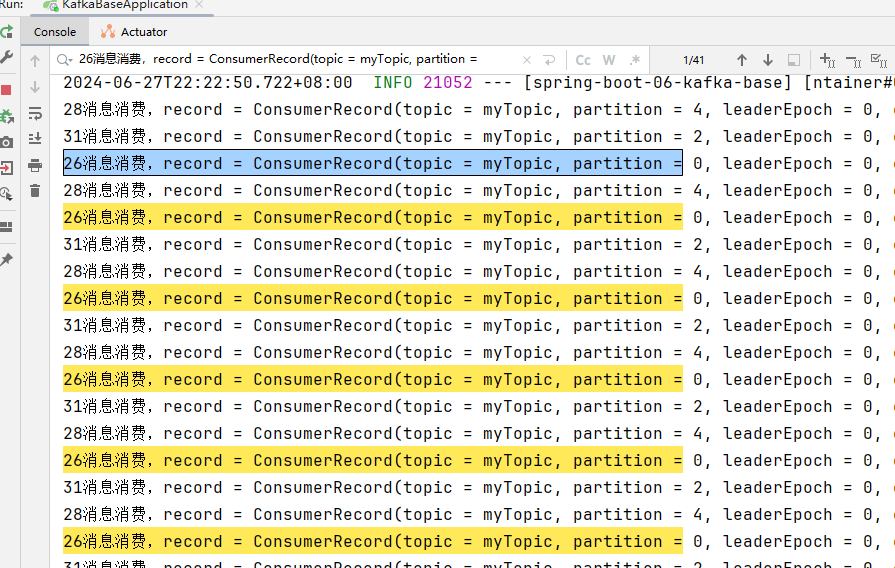
线程ID为28的消费29条,消费消息的分区为:1,4,7
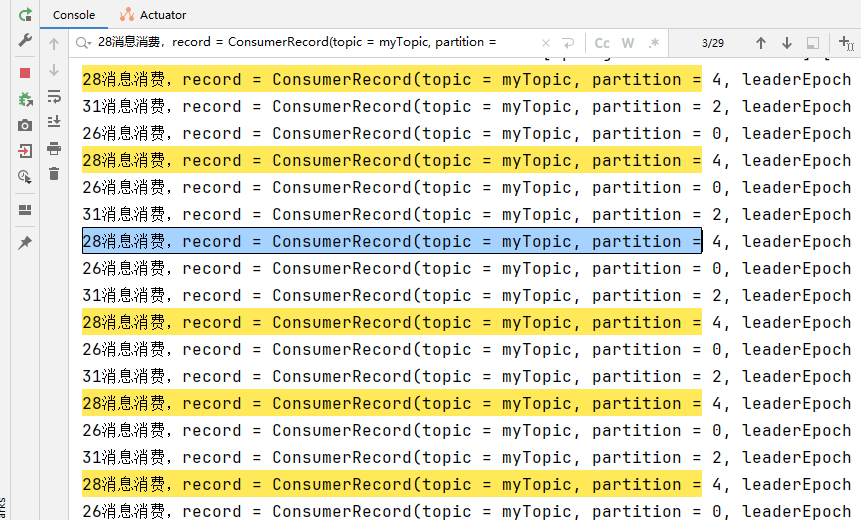
线程ID为31的消费30条,消费消息的分区为:2,5,8
-
方式二,通过自定义方式进行设置轮询分配策略
-
在
KafkaConfig.java配置文件进行配置@Value("${spring.kafka.bootstrap-servers}") private String bootstrapServers; @Value("${spring.kafka.consumer.key-deserializer}") private String keyDeserializer; @Value("${spring.kafka.consumer.value-deserializer}") private String valueDeserializer; @Value("${spring.kafka.consumer.auto-offset-reset}") private String autoOffsetReset; public Map<String, Object> consumerConfigs() { HashMap<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); // 键值反序列化,自定义配置方式一定要配置,不然会报错 props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, keyDeserializer); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer); // 从最早的消息开始消费 props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset); // 指定使用轮询的消息消费分区器 props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RoundRobinAssignor.class.getName()); return props; } @Bean public ConsumerFactory<String, String> myConsumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } @Bean public KafkaListenerContainerFactory<?> myKafkaListenerContainerFactory(ConsumerFactory<String, String> myConsumerFactory) { ConcurrentKafkaListenerContainerFactory<String, String> listenerContainerFactory = new ConcurrentKafkaListenerContainerFactory<>(); listenerContainerFactory.setConsumerFactory(myConsumerFactory); return listenerContainerFactory; } -
修改消费方法注解,指定自定义的容器,分组改成
myGroup3,这样等下可以再次消费@KafkaListener(topics = {"myTopic"}, groupId = "myGroup3", concurrency = "3", containerFactory = "myKafkaListenerContainerFactory") -
修改application.yaml配置文件
spring: application: # 应用名称 name: spring-boot-06-kafka-base kafka: # kafka连接地址(ip+port) bootstrap-servers: 192.168.200.129:9092 # 配置消费者(有24个配置) consumer: # key反序列化 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # value反序列化 value-deserializer: org.apache.kafka.common.serialization.StringDeserializer auto-offset-reset: earliest # properties: # partition: # assignment: # 配置消费消息的分区策略 # strategy: org.apache.kafka.clients.consumer.RoundRobinAssignor -
重新启动服务,发现效果一样。
-
-
StickyAssignor消费分区策略:
尽可能保持消费者与分区之间的分配关系不变,即使消费组的消费者成员发生变化,减少不必要的分区重分配;
尽量保持现有的分区分配不变,仅对新加入的消费者或离开的消费者进行分区调整。这样,大多数消费者可以继续消费它们之前消费的分区,只有少数消费者需要处理额外的分区;所以叫“粘性”分配;
-
CooperativeStickyAssignor消费分区策略:
与 StickyAssignor 类似,但增加了对协作式重新平衡的支持,即消费者可以在它离开消费者组之前通知协调器,以便协调器可以预先计划分区迁移,而不是在消费者突然离开时立即进行分区重分配;
Kafka事件(消息、数据)的存储
kafka的所有事件(消息、数据)都存储在/tmp/kafka-logs目录中,可通过log.dirs=/tmp/kafka-logs配置;
Kafka的所有事件(消息、数据)都是以日志文件的方式来保存;
Kafka一般都是海量的消息数据,为了避免日志文件过大,日志文件被存放在多个日志目录下,日志目录的命名规则为:<topic_name>-<partition_id>;
比如创建一个名为 firstTopic 的 topic,其中有 3 个 partition,那么在 kafka 的数据目录(/tmp/kafka-log)中就有 3 个目录,firstTopic-0、firstTopic-1、firstTopic-2;
00000000000000000000.index 消息索引文件
00000000000000000000.log 消息数据文件
00000000000000000000.timeindex 消息的时间戳索引文件
00000000000000000006.snapshot 快照文件,生产者发生故障或重启时能够恢复并继续之前的操作
leader-epoch-checkpoint 记录每个分区当前领导者的epoch以及领导者开始写入消息时的起始偏移量
每次消费一个消息并且提交以后,会保存当前消费到的最近的一个offset;
在kafka中,有一个__consumer_offsets的topic, 消费者消费提交的offset信息会写入到 该topic中,__consumer_offsets保存了每个consumer group某一时刻提交的offset信息,__consumer_offsets默认有50个分区;
consumer_group 保存在哪个分区中的计算公式:
Math.abs(“groupid”.hashCode()) % groupMetadataTopicPartitionCount ;
测试一下:
package com.bjpowernode;
public class Test {
public static void main(String[] args) {
int partition = Math.abs("myGroupx2".hashCode()) % 50;
System.out.println(partition);
}
}
kafka插件看不到__consumer_offsets,可以安装zookeeper插件
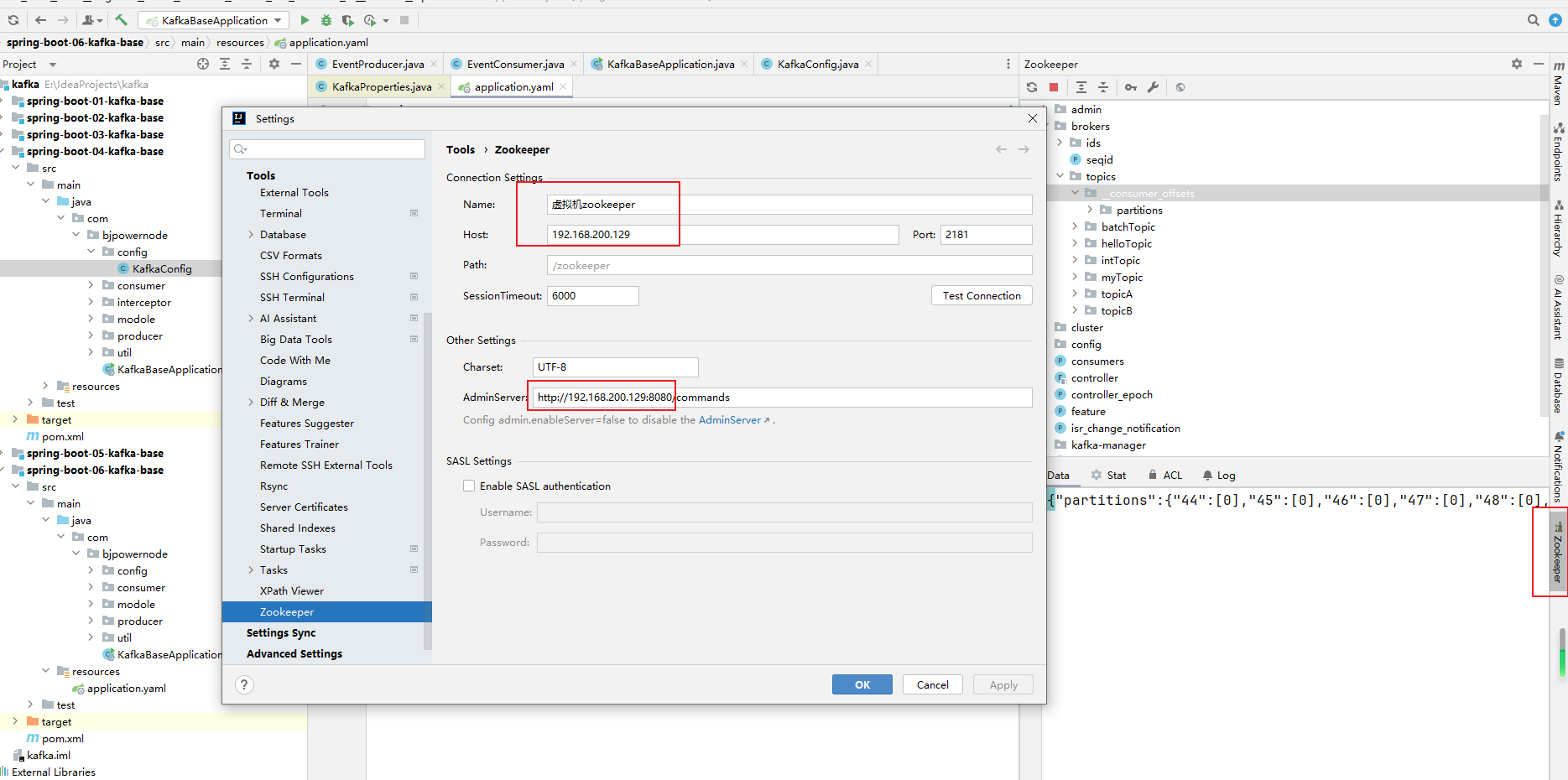
Offset详解
-
生产者Offset
生产者发送一条消息到Kafka的broker的某个topic下某个partition中;
Kafka内部会为每条消息分配一个唯一的offset,该offset就是该消息在partition中的位置;
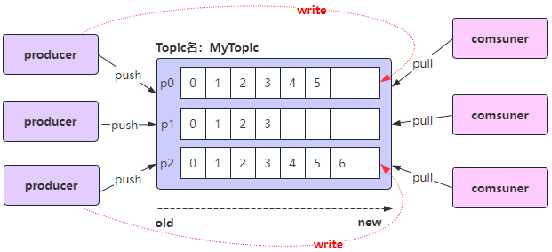
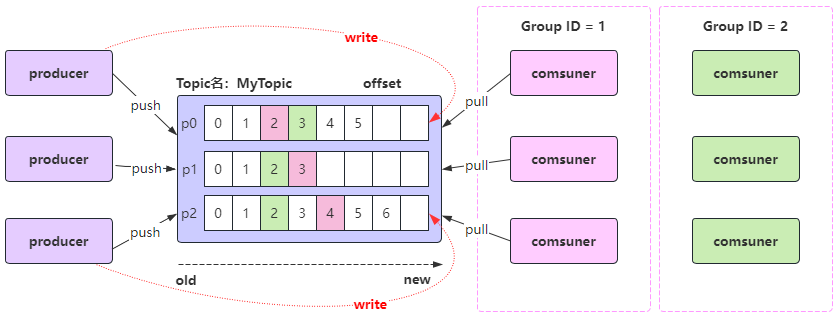
-
消费者Offset
消费者offset是消费者需要知道自己已经读取到哪个位置了,接下来需要从哪个位置开始继续读取消息;
每个消费者组(Consumer Group)中的消费者都会独立地维护自己的offset,当消费者从某个partition读取消息时,它会记录当前读取到的offset,这样,即使消费者崩溃或重启,它也可以从上次读取的位置继续读取,而不会重复读取或遗漏消息;(注意:消费者offset需要消费消息并提交后才记录offset)
每个消费者组启动开始监听消息,默认从消息的最新的位置开始监听消息,即把最新的位置作为消费者offset;
分区中还没有发送过消息,则最新的位置就是0;
分区中已经发送过消息,则最新的位置就是生产者offset的下一个位置;
消费者消费消息后,如果不提交确认(ack),则offset不更新,提交了才更新;
命令行命令:
./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group osGroup --describe结论:消费者从什么位置开始消费,就看消费者的offset是多少,消费者offset是多少,它启动后,可以通过上面的命令查看;
-
-
将
spring-boot-06-kafka-base直接复制并粘贴一份改名为spring-boot-07-kafka-base -
修改
pom.xml、application.yaml,将里面的spring-boot-06-kafka-base全部替换成spring-boot-07-kafka-basespring: application: # 应用名称 name: spring-boot-07-kafka-base kafka: # kafka连接地址(ip+port) bootstrap-servers: 192.168.200.129:9092 -
右键
pom.xml添加为maven工程,删除config包 -
修改
EventConsumer.javapackage com.bjpowernode.consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.springframework.stereotype.Component; @Component public class EventConsumer { // @KafkaListener(topics = {"osTopic"}, groupId = "osGroup") public void onEvent(ConsumerRecord<String, String> record) { System.out.println(Thread.currentThread().getId() + "消息消费,record = " + record); } } -
修改
EventProducer.javapackage com.bjpowernode.producer; import com.bjpowernode.modole.User; import com.bjpowernode.util.JSONUtils; import jakarta.annotation.Resource; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.stereotype.Component; import java.util.Date; @Component public class EventProducer { @Resource private KafkaTemplate<String, String> kafkaTemplate; public void sendEvent() { for (int i = 0; i < 2; i++) { User user = User.builder().id(1028 + i).phone("13709090901" + i).birthDay(new Date()).build(); String userJSON = JSONUtils.toJSON(user); kafkaTemplate.send("osTopic", "k" + i, userJSON); } } } -
注释掉@KafkaListener注解,先执行测试方法,发送2条消息,然后放开@KafkaListener注解,启动项目
这个osGroup分组现在还没消费过消息,那么从最新的位置开始消费,我们可以看到启动项目后,没有消费到消息
此时我们查看该group消费情况:
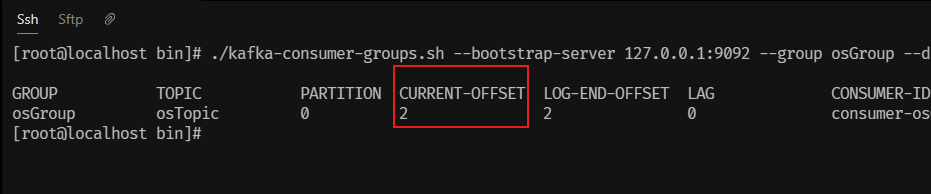
-
停掉服务,再次注释掉@KafkaListener注解,执行测试方法,发送2条消息

-
放开@KafkaListener注解,启动项目,这时可以看到消费到2条数据,前面的2条数据是消费不到的
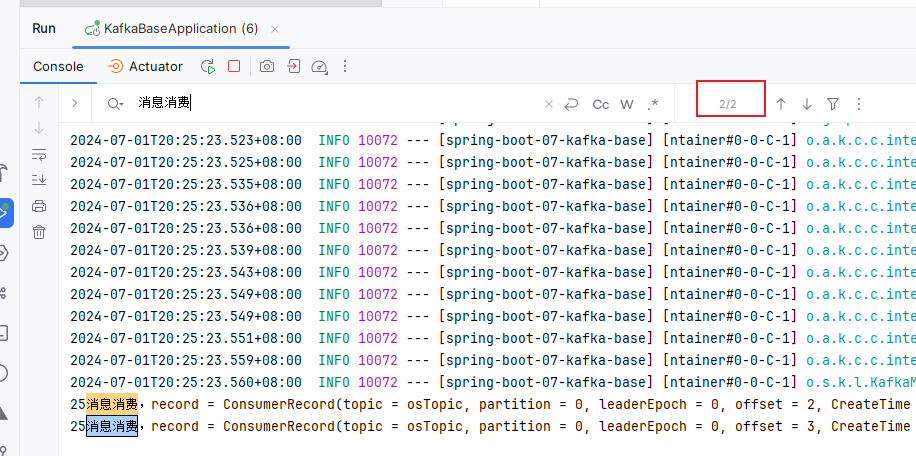

-
停掉服务,删除osTopic主题。
-
我们先不发消息,先把服务启动起来,也就是监听器开始工作,就会帮我们创建topic。

-
可以看到消费者从0开始消费。现在我们把项目停掉,但是这个消费组已经在kafka中做了记录了上一次消费的位置是0。
-
注释掉@KafkaListener注解,执行测试方法,发送2条消息,然后放开@KafkaListener注解,启动项目

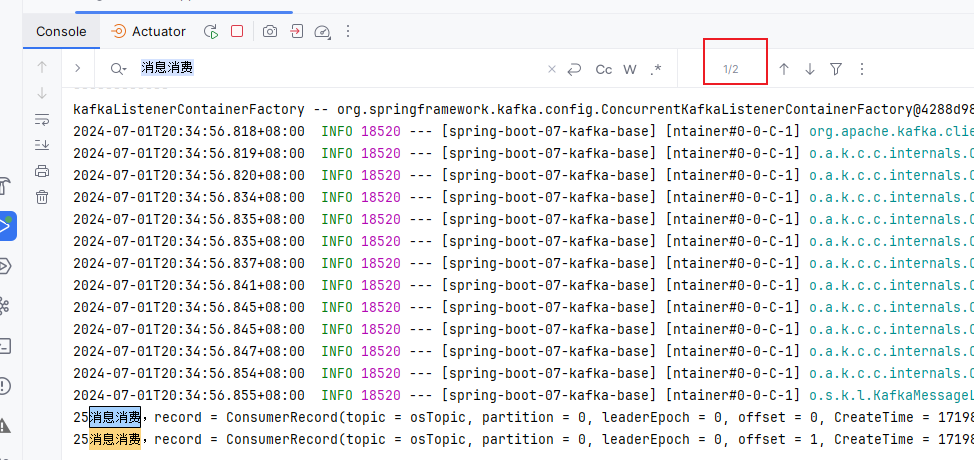

-
测试手动提交时,offset不更新
- 修改application.yaml配置文件,更新为手动提交:
spring: application: # 应用名称 name: spring-boot-07-kafka-base kafka: # kafka连接地址(ip+port) bootstrap-servers: 192.168.200.129:9092 # 配置消息监听器 listener: # 开启消息监听的手动确认模式 ack-mode: manual-
更新
EventConsumer.java,改为手动提交package com.bjpowernode.consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.kafka.support.Acknowledgment; import org.springframework.stereotype.Component; @Component public class EventConsumer { // @KafkaListener(topics = {"osTopic"}, groupId = "osGroup") public void onEvent(ConsumerRecord<String, String> record, Acknowledgment ack) { System.out.println(Thread.currentThread().getId() + "消息消费,record = " + record); // ack.acknowledge(); } } -
先不消费,注释掉@KafkaListener注解,执行测试方法,发送2条消息
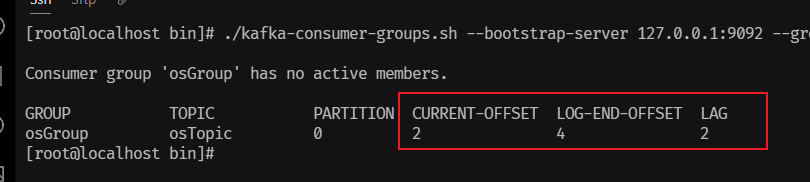
-
然后放开@KafkaListener注解,启动项目,已经消费2条
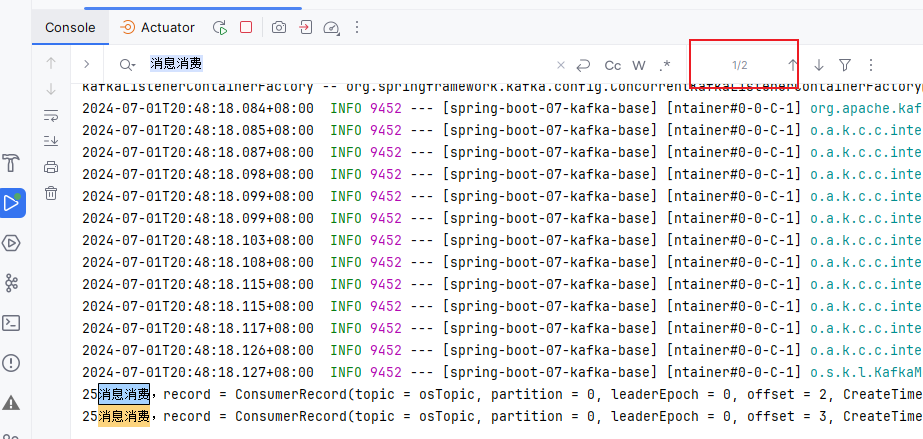
但是消费者offset任然没变

- 再次启动项目,又可以消费:
-
打开消费者手动确认注释
ack.acknowledge(); -
再次启动项目,消费到2条,offset更新为4,没有消息消费了,此时再次启动项目,不会再消费到了:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号