
java容器
java容器:[容器本身引用类型,在回溯代码中记得要清除(撤销选择),容器中存放的元素也是引用类型,(实际上存放的是地址变量,是对象的引用,即指向对象的地址值)]
容器在java.util包下,顾名思义。这是大佬实现好的工具类,提供给开发者使用的,
看到源代码就会发现,这些接口的实现类很有规律的,
1.都是先定义一个用来存放数据的数据结构,有默认的初始化大小,也可以自定义大小,(在hash表部分官方有初始化推荐,容量最好是2的倍数,散列分布更均匀)
提供自动扩容的机制,
2.都会去实现父接口中的增删改查方法,同时根据自己这个类的特点来设计一些自己的特有方法,可以是新增的方法,也可以是对父接口中的方法进行重写和重载
所以总结起来就是,为我们提供好了存储数据的数据结构和增删改查的方法
http://doc.canglaoshi.org/jdk8/docs/api/index.html jdk8AP文档
(是真的佩服大佬写的代码,最少冗余和耦合,高可扩展性且保证逻辑没有错误,给开发者提供最便捷的开发体验感。orz)
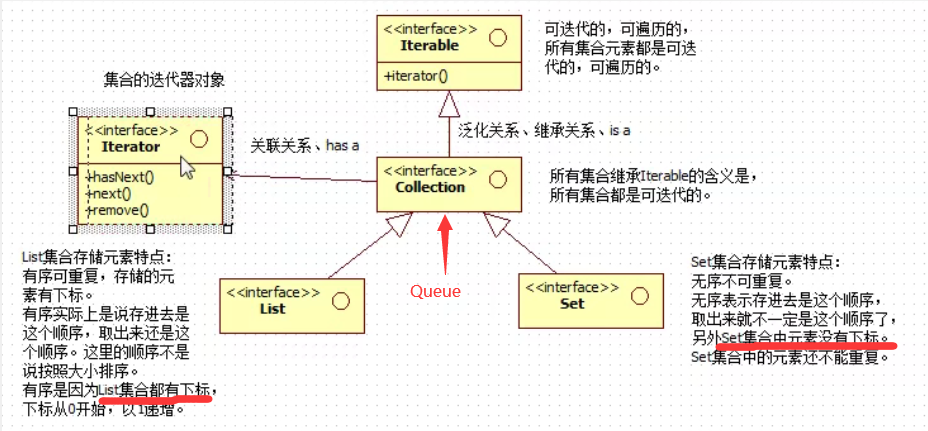
接口:Collection、Map 这两个接口之间没有继承关系
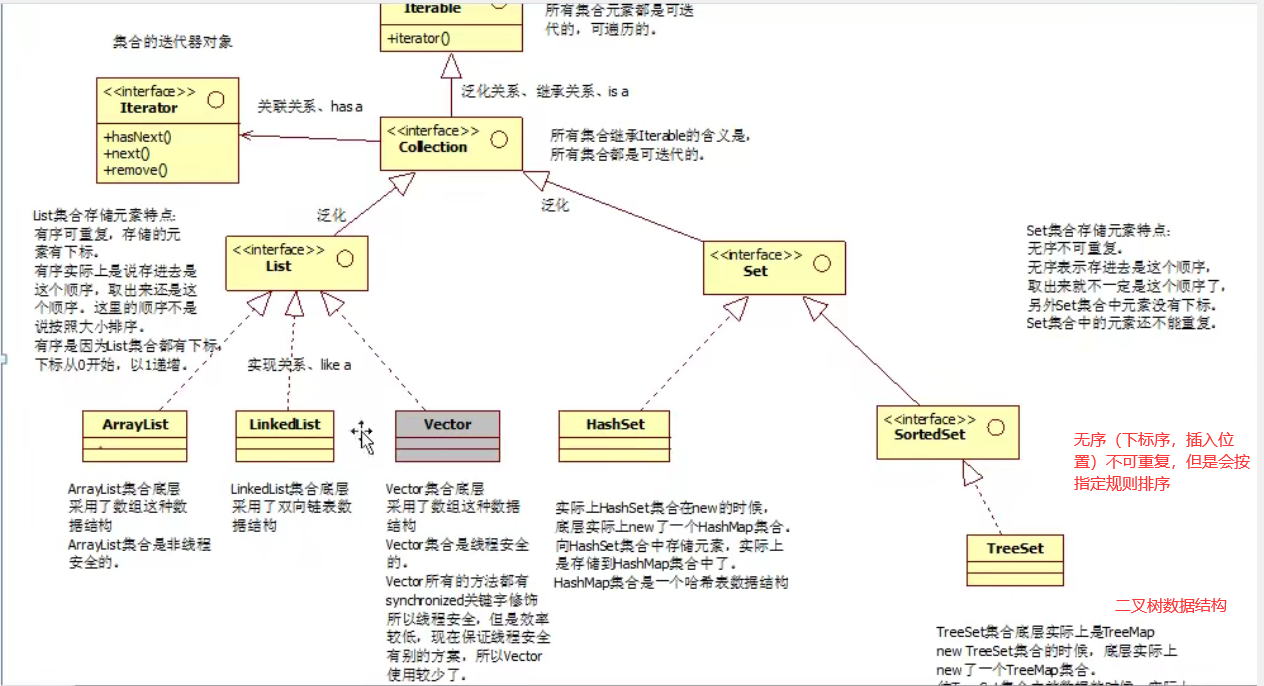
集合接口:Collection。子接口:List,Set,Queue,Deque
实现类:List:ArrayList、LinkedList、Vector、Stack
Set:HashSet,(其实是使用HashMap来实现的)
Set子接口SortedSet,实现类TreeSet(使用TreeMap实现)
往Set集合中存放元素其实是存放在map的key上,调用的是map的put方法
实现类还有:PriorityQueue,Stack
一些截图:来自B站动力节点公开视频

1.Collection集合,存放的是单个元素
1.1关于Collection中的常用方法
- size(),isEmpty()
- add(E e)
- remove(Object o), clear()
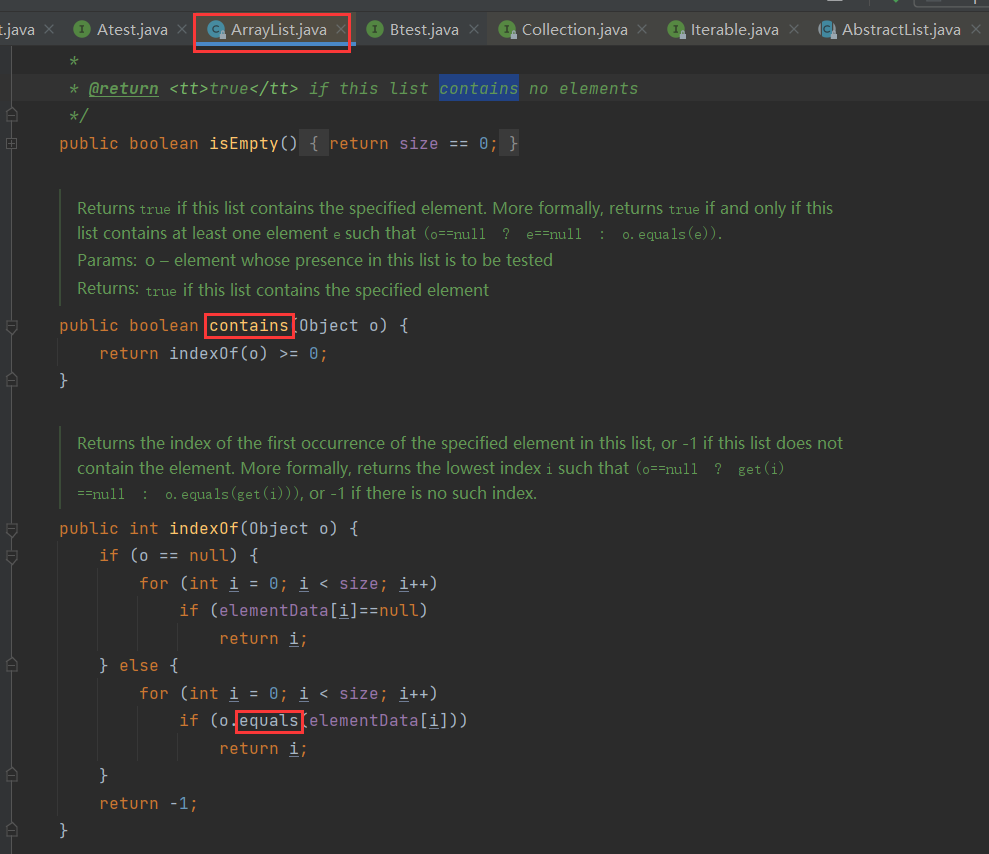
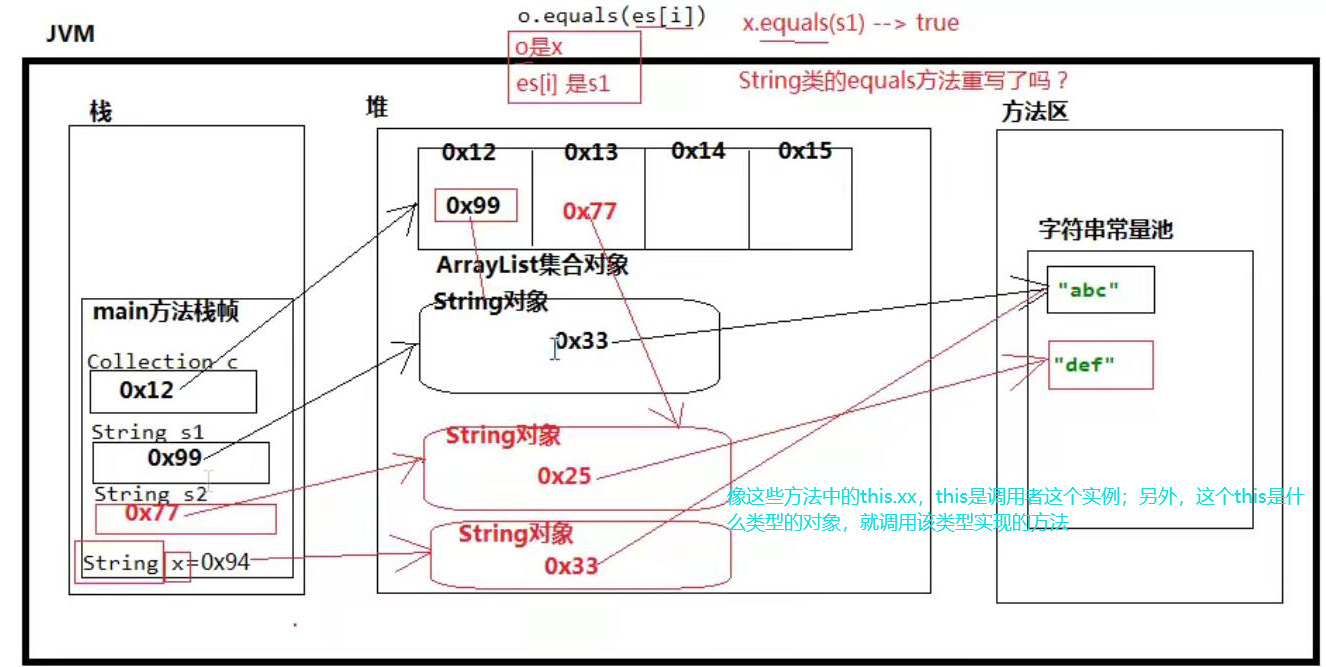
- contains(Object o) (o==null ? e==null : o.equals(e)).
- iterator() 放回一个迭代器对象
这里值得关注的是remove和contains方法,这两个方法都调用了equals方法,
Integer、String这两个类是重写了equals方法的,比较的是内容,而非地址值,所以在leetcode刷题使用集合的话是没有问题的,不需要重写
1.2List(在leetcode中栈,队列,链表题用的比较多)
1.2.1List特点:元素有序可重复,有序指的是按存放的顺序有序,
因为有序的特点,所以list是带有下标的。可以方便的通过下标添加,移除,查找元素(在leetcode中XXX类题用起来比较放方便)
1.2.2List的常用方法:继承Collection接口,所以是包含Collection中的方法,当然还有自己新的方法,比如增加,删除的重载方法
- size(),isEmpty()
1.2.3实现类ArrayList和LinkedList(补充)
【测试集合类代码 集合中自定义类型要重写equals方法】 感觉下面两个类名改成ListTest会好一些(哈哈)
/** * 测试List集合的有序可重复, * String和Integer类型已经重写了equals方法 * contains和remove方法 */ public class CollectionTest { public static void main(String[] args) { System.out.println("========ArrayList=========="); System.out.println("========String=========="); Collection<String> c = new ArrayList<String>(); c.add(new String("abc")); String s = new String("abc"); String s1 = "abc"; System.out.println(c.contains(s)); System.out.println(c.contains(s1)); c.add(s1); System.out.println(c.size()); c.remove("abc"); c.remove(new String("abc")); System.out.println(c.size()); Collection<Integer> c1 = new LinkedList<Integer>(); System.out.println("========LinkedList=========="); System.out.println("========Integer=========="); c1.add(2); c1.add(1); c1.add(0); c1.add(new Integer(1)); // 增强for for (int x:c1 ) { System.out.print(x+" "); } System.out.println(); c1.remove(new Integer(2)); System.out.println(c1); } } /** 运行结果: ========ArrayList========== ========String========== true true 2 0 ========LinkedList========== ========Integer========== 2 1 0 1 [1, 0, 1] */
/** * 集合中存放自定义的类型要重写equals方法 */ public class CollectionTest1 { public static void main(String[] args) { Collection<User> users = new LinkedList<>(); users.add(new User(1,"xl")); users.add(new User(2,"xf")); User x = new User(1,"xl"); // 没有重写equals的结果为false System.out.println(users.contains(x));//false<没有重写> true<重写后> users.remove(x); System.out.println(users.size());//2<没有重写> 1<重写后> } } class User{ private int id; private String name; public User(int id, String name) { this.id = id; this.name = name; } /** * 定义的比较规则,如果id和姓名都相同则为同一个User * @param obj * @return */ @Override public boolean equals(Object obj) { if(this==obj)return true; //判断是否为同一个对象,地址相等 if(obj==null||!(obj instanceof User)){return false;}//如果要进行比较的obj为空,或者不是这种类型的对象 return this.id== ((User) obj).id&&this.name.equals(((User) obj).name); } @Override public String toString() { return "[id:"+ id+" name:"+name+"]"; } }
1.3Set(leetcode中判断重复啥的用的很多,hash,,这里去看看链表中的重复节点,判断链表是否有环这道题,不用重写方法,是应为存放的是同一个引用,哈哈)
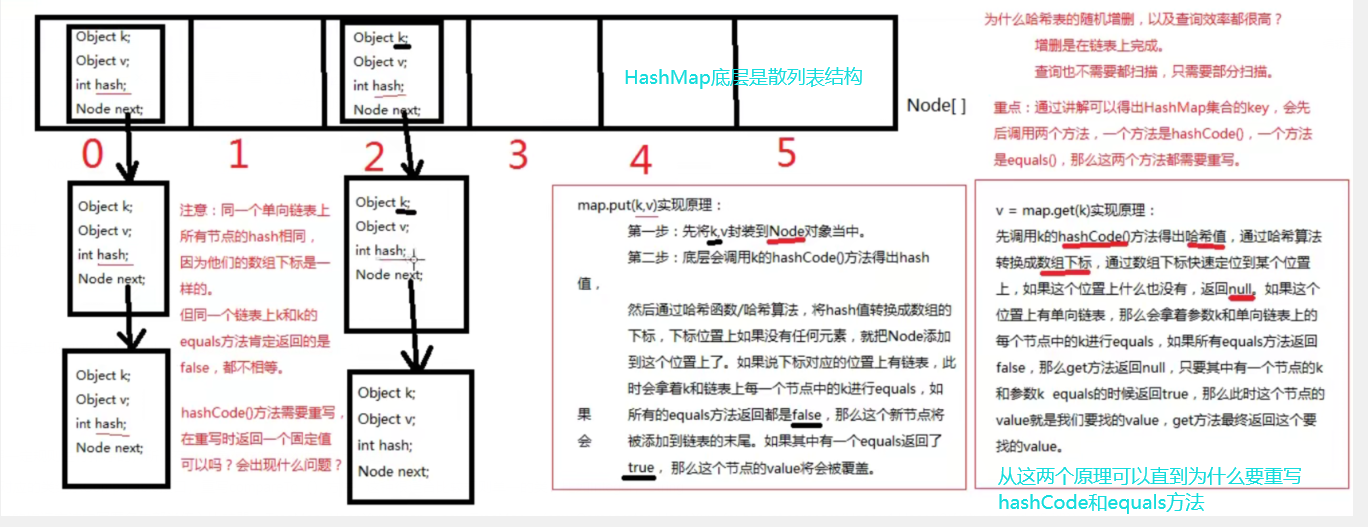
1.3.1Set特点:无序不可重复,元素存放的顺序和取出的顺序不能保证是相同的,所以这里的下标是没有意义的,干脆不提供下标,可以这样记忆(其实底层是hash表和二叉树是没有数组下标的)
其底层的数据结构的是HashSet(HashMap 散列表) TreeSet(TreeMap 二叉树) 往set当中存元素,相当于往map中的key上存元素,所以,map中key的重写规则和set中元素的重写是一致的
1.3.2Set的方法,和List接口、Collection接口中的方法差不多,没有下标,所以没有重载方法
【测试HashSet代码】
/** * 测试set集合无序不可重复 * 存放在HashSet中的类型要同时重写equals和hashCode方法 * 注意这里要使用IEDA自带的生成方法 * * 进阶,学会根据业务来定义正确的比较规则 */ public class HashSetTest { public static void main(String[] args) { HashSet<String> set = new HashSet<>(); set.add("abc"); set.add(new String("3235")); set.add(new String("abc")); set.add(new String("bc")); set.add(new String("3235")); System.out.println(set.size());// 3 String str = new String("abc"); for(String s:set){ System.out.print(s+" "); //bc abc 3235 } set.remove(str); System.out.println(set.size());// 2 HashSet<Student> set1 = new HashSet<Student>(); set1.add(new Student(1,"xl")); set1.add(new Student(1,"xl")); System.out.println(set1.size());// 只重写equals方法为2 同时重写equals和hashCode方法为1 Student stu = new Student(1,"xl"); set1.remove(stu); System.out.println(set1.size());// 只重写equals方法为2 同时重写equals和hashCode方法为1 } } class Student{ private int id; private String name; public Student(int id, String name) { this.id = id; this.name = name; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return id == student.id && Objects.equals(name, student.name); } @Override public int hashCode() { return Objects.hash(id, name); } /** * 定义的比较规则,如果id和姓名都相同则为同一个Student * @param obj * @return */ // @Override // public boolean equals(Object obj) { // if(this==obj)return true; //判断是否为同一个对象,地址相等 // if(obj==null||!(obj instanceof Student)){return false;}//如果要进行比较的obj为空,或者不是这种类型的对象 // return this.id== ((Student) obj).id&&this.name.equals(((Student) obj).name); // } @Override public String toString() { return "[id:"+ id+" name:"+name+"]"; } }
1.4List和Set的区别,以及重写方法
- 有序可重复,无序不可重复
- 有下标,可以使用下标进行增删查改,和遍历, Set可以使用增强for来遍历
- List中的元素对应的类必须重写equals方法(因为contains和remove方法中,是调用了equals方法,这个equals的初衷是留给我们根据业务逻辑来定义的,多是比较指定部分内容是否相同判断是否为同一元素;题外话:另外,要删除一个元素,在删除时,我们可能已经找不到其引用了(生命周期去了解一下),这个时候新new了一个对象,比如是根据从数据库中查出来的数据new的,这条数据封装的对象用来判断集合中是否包含它【这个场景举得并不好,数据还要去查数据库的】)
- HashSet中的对象对应的类必须同时重写hashCode和equals方法,参看HashMap的数据结构和put,get的代码实现
- TreeSet中的对象对应的类必须是可比较的,这里有两种方法来实现,参看TreeMap的数据结构。put。get方法
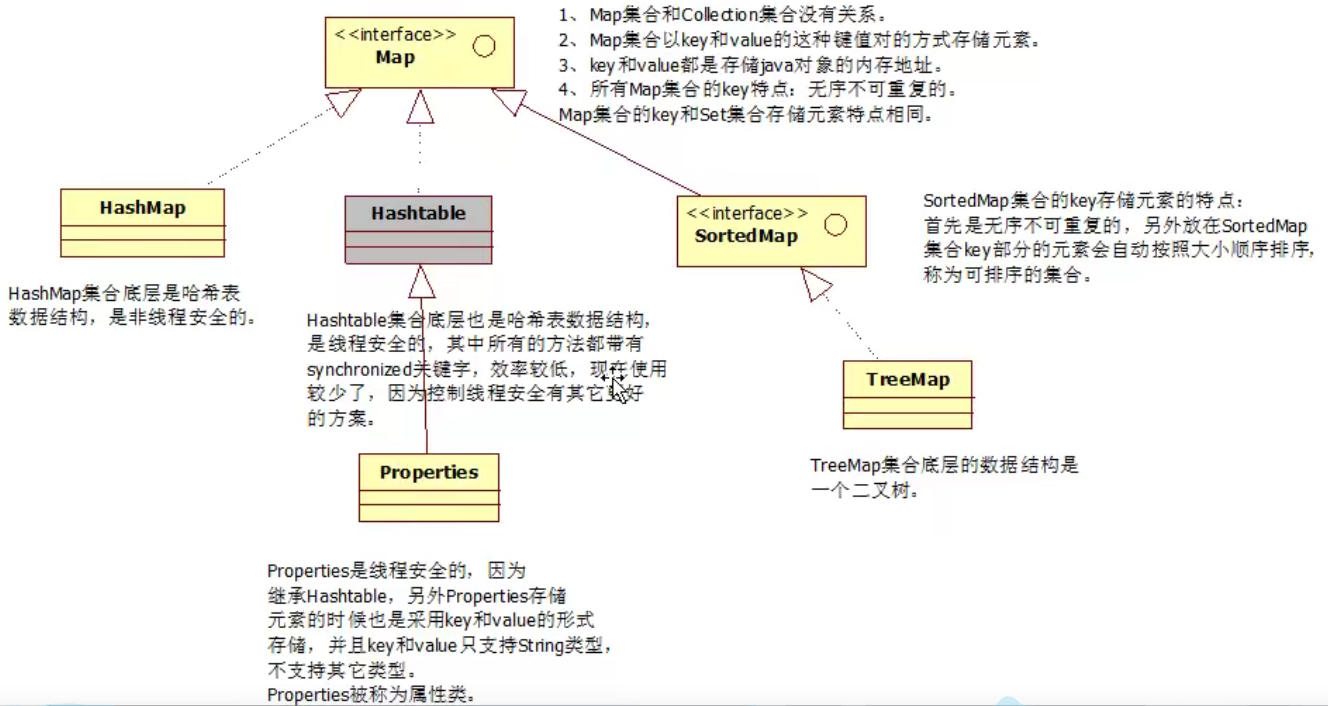
2.map接口:实现类HashMap
子接口SortedMap,实现类TreeMap
2.1Map的遍历
map.keySet(); return Set 可以通过增强for循环get(key)遍历元素,也可以使用iterator
map.entrySet() return Set<Map.Entry<k,v>> 这种方式的效率更高,不用先搞keyset在用key去找元素
2.2Map的常用方法
- size()
- put(K key, V value)
- getOrDefault(Object key, V defaultValue) get(Object o)
- containsKey(Object key) containsValue(Object value)
- entrySet() return Set<Map.Entry<K,V>> keySet() return Set<K>
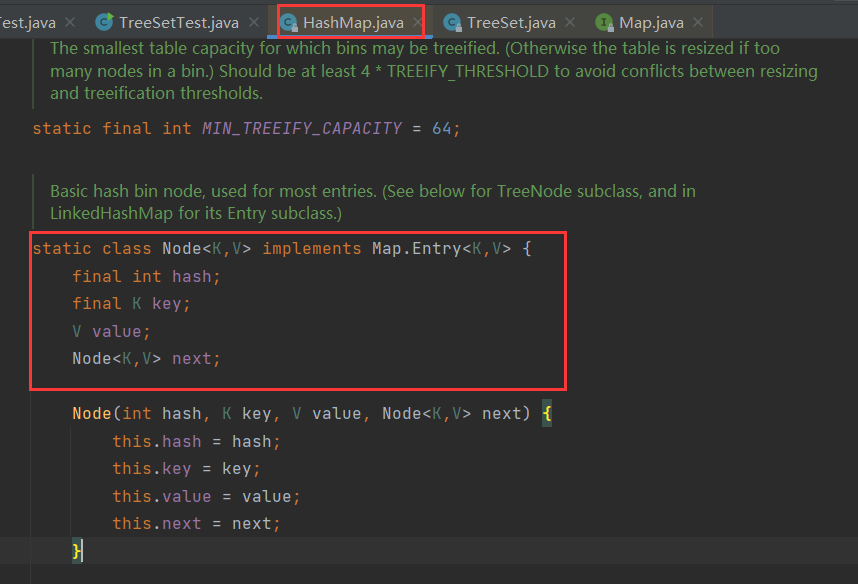
2.3HashMap【存放在HashMap的k要重写hashCode和equals,底层数据结构为散列表】
底层为散列表 Node[] nodes ;
class Node{
E k;
E v;
int hash;
Node next;
}
- put()实现原理
- get()实现
可以用来统计某个元素出现的次数 map.put(key,map.getOrDefualt(key,0)+1);
【HashMap的遍历,以及常用方法测试】
/** * map的k可以=null,也可以v=null 也可以同时为null 开发不会这么搞的 * key相同,则原来的value会被覆盖 * 对map使用keySet的方法遍历 * 对map使用entrySet的方法遍历 Set<Map.Entry<Integer,String>> data = map.entrySet(); * 使用迭代器遍历 * 测试map.put(5,map.getOrDefault(5,"lalala")+"hahh"); */ public class MapIteratorTest { public static void main(String[] args) { HashMap<Integer,String> map = new HashMap<>(); //map.put(null,null); 可以k=null,也可以v=null 也可以同时为null 开发不会这么搞的 map.put(1,"ab"); map.put(2,"cd"); map.put(3,"bc"); map.put(4,"gh"); map.put(1,"gh"); System.out.println(map.size());//5, k=1,v="gh" 原来的”ab“被覆盖 System.out.println(map.get(1)); Set<Integer> key = map.keySet(); for (int x:key ) { System.out.println("key:"+x+"---> value:"+map.get(x)); } // 这里来玩一波Iterator Iterator<Integer> it = key.iterator(); while(it.hasNext()){ int k = it.next(); System.out.println(k+"--->"+map.get(k)); } Set<Map.Entry<Integer,String>> data = map.entrySet(); for(Map.Entry<Integer,String> x:data){ System.out.println(x.getKey()+"--->"+x.getValue()); } map.put(5,map.getOrDefault(5,"lalala")+"hahh"); System.out.println(map.get(5)); } } //运行结果 4 gh key:1---> value:gh key:2---> value:cd key:3---> value:bc key:4---> value:gh 1--->gh 2--->cd 3--->bc 4--->gh 1--->gh 2--->cd 3--->bc 4--->gh lalalahahh
2.4TreeMap【存放的自定义类型要指定比较规则,底层结构为搜索二叉树】
存入的元素是按照一定规则进行排序的,所以存入对象对应的类必须是可比较的
方法1:存入对象对应的类继承Comparable接口,重写compareTo()方法 这种很适合比较规则单一的类,比如Integer,String
方法2:在定义map的构造方法中写匿名内部类传入比较器 TreeMap<User,Xxx> map = new TreeMap<>(new Comparator<User,Xxx>{public int compare(User u1,User u2){return u1.id-u2.id}});
这里也可以在存入对象对应的类中去创建比较器的类,class User implements Comparator{。。。}
这种方法比较适合复杂的对象,比较规则复杂,或者比较规则要经常改变
【源码中对二叉树节点的定义】
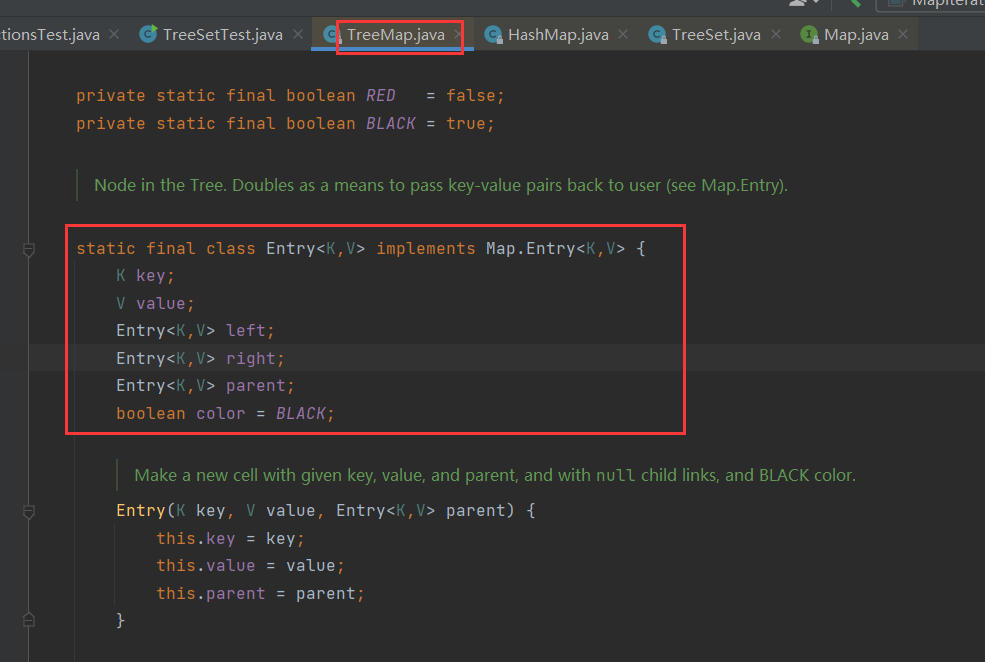
【源码中put的实现,搜索二叉树的插入】
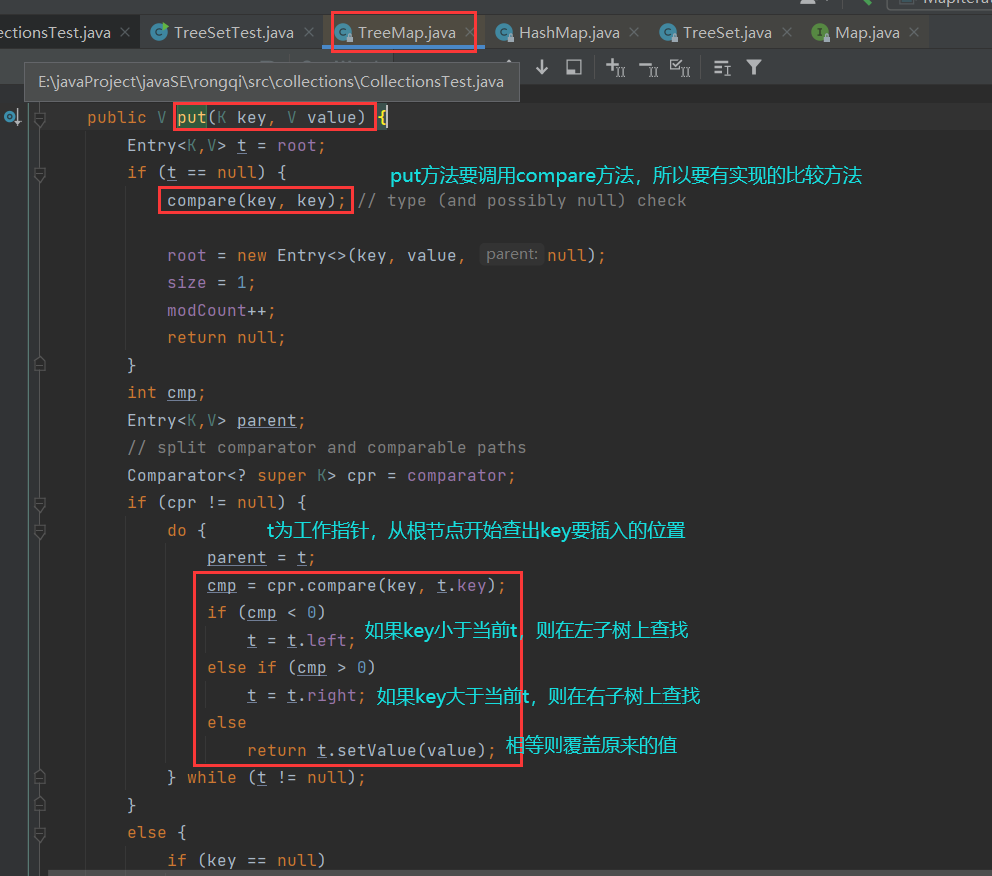
【这里代码以TreeSet为例】
/** * TreeSet--->SortedSet===>Set * 放入TreeSet集合中的元素会按照比较规则排序,这是一边放入一边排序的,底层是二叉搜索树,所以不指定规则连放都放不进去 * 如果自定义的类型不能转换成java.lang.Comparable,会发生运行时异常ClassCastException * * 有两种方法来定义比较规则 * ①放入其中的类实现Comparable接口,重写compareTo(Object o)方法 * * ②定义比较器类 1.显示定义 eg: class VipComparator implements Comparator<Vip>{ public int compare(Vip o1, Vip o2) {retrun ..}} * 2. 匿名内部类 TreeSet<Vip> s = new TreeSet<>(new Comparator<Vip>() {public int compare(Vip o1, Vip o2) {retrun ..}}); * 通过构造方法将定义的比较器类对象传入 * * 以上两种方法来说,第一种适合比较规则单一的,不会改变 * 方法二适合比较规则复杂多变的,可以自定义不同的比较器,根据需求来选择在容器的构造器中传入合适的比较器,灵活 */ public class TreeSetTest { public static void main(String[] args) { TreeSet<Worker> set = new TreeSet<Worker>();//运行时异常 set.add(new Worker(12));//collection.Worker cannot be cast to java.lang.Comparable set.add(new Worker(14)); set.add(new Worker(10)); set.add(new Worker(22)); for(Worker x:set){ System.out.println(x.getAge()); //10 12 14 22 } //==============使用方法② 直接在构造方法中使用匿名内部类传入一个比较器========== //Anonymous new Comparator<Vip>() can be replaced with lambda TreeSet<Vip> s = new TreeSet<>(new Comparator<Vip>() { @Override //按照rank降序name升序排列, public int compare(Vip o1, Vip o2) { return o2.getRank()-o1.getRank()==0?o1.getName().compareTo(o2.getName()):o2.getRank()-o1.getRank(); } }); s.add(new Vip(1,"zhangsan")); s.add(new Vip(19,"zhangsan")); s.add(new Vip(99,"zhangsan")); s.add(new Vip(0,"zhangsan")); s.add(new Vip(99,"lisi")); s.add(new Vip(1,"zhangsi")); for (Vip v:s ) { System.out.println(v); } // 定义了一个专门用来比较Vip的比较类,Comparator接口 重写public int compare(Object o1, Object o2);方法 TreeSet<Vip> set1 = new TreeSet<>(new VipCompare()); set1.add(new Vip(1,"zhangsan")); set1.add(new Vip(19,"zhangsan")); set1.add(new Vip(99,"zhangsan")); set1.add(new Vip(0,"zhangsan")); set1.add(new Vip(99,"lisi")); set1.add(new Vip(1,"zhangsi")); System.out.println(set1); } } // 方法1 class Worker implements Comparable<Worker>{ private int age; public int getAge(){ return age; } Worker(int age){ this.age = age; } @Override public int compareTo(Worker o) { return this.age-o.age; } } // 方法2 使用匿名内部类或者定义一个比较器类 //按照rank降序name升序排列, class Vip{ private int rank; private String name; public Vip(int rank, String name) { this.rank = rank; this.name = name; } public int getRank() { return rank; } public void setRank(int rank) { this.rank = rank; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public String toString() { return "rank:"+rank+" name:"+name; } } class VipCompare implements Comparator<Vip>{ @Override //按照rank升序name升序排列, public int compare(Vip o1, Vip o2) { return o1.getRank()-o2.getRank()==0?o1.getName().compareTo(o2.getName()):o1.getRank()-o2.getRank(); } } //运行结果 10 12 14 22 rank:99 name:lisi rank:99 name:zhangsan rank:19 name:zhangsan rank:1 name:zhangsan rank:1 name:zhangsi rank:0 name:zhangsan [rank:0 name:zhangsan, rank:1 name:zhangsan, rank:1 name:zhangsi, rank:19 name:zhangsan, rank:99 name:lisi, rank:99 name:zhangsan]
3.Iterable接口
Iterator迭代器对象
遍历List和map
(Iterable接口中的抽象方法
/**Returns an iterator over elements of type T.
Returns:an Iterator.
*/
Iterator<T> iterator(); 这里的Iterator也是一个接口,所以说函数的返回值类型不仅可以是(类)的对象,也可以是(接口类型),不过在实现类这里要返回接口类型的实现类对象,或者new 接口类型使用匿名内部类的方法
)
(Iterator接口中的抽象方法:
boolean hasNext();
E next();
default void remove()
)
可去看看Iterable。Collection。Iterator。和ArrayList的关系, 继承,关联/?、? Collection接口继承了Iterable【有返回Iterator对象的方法】,在集合的实现类中有对获取这个对象的实现方法,也有对Iterator接口进行实现的类
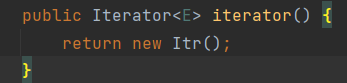
ArrayList实现Collection中的iterator方法。放回Iterator迭代器接口的实现类对象

这类是ArrayList中的类,实现了迭代器接口中的 hasNext(),next(),remove()方法
使用:
Collection<Integer> c = new ArrayList<>(); Iterator it = c.iterator(); while(it.hasNext()){ sout(it.next()); }
it迭代器对象有类似快照的特点,在使用其遍历元素的时候,不能使用集合提供的增删改方法修改集合,否则会报异常,修改集合需要重新获取新的迭代器对象
(这个方法说实话刷题反正基本上是用不到的,但是可以看看源代码哈哈哈哈)
4.collections工具类
大佬开发的工具类,方便开发者对集合进行某些操作,这里只测试sort方法
/** * 测试Collections中的sort(list)方法, * sort()方法不能对set直接排序,但是可以 List<xx> list = new ArrayList<>(set);再对list排序 * * 待排序的list中的元素必须是可比较的 */ public class CollectionsTest { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("abc"); list.add("abf"); list.add("aba"); list.add("abb"); Collections.sort(list); for(String s:list){ System.out.println(s); } List<Person> list1 = new LinkedList<>(); list1.add(new Person(22)); list1.add(new Person(2)); list1.add(new Person(62)); list1.add(new Person(42)); Collections.sort(list1); for(Person p:list1){ System.out.println(p.getAge()); } } } class Person implements Comparable<Person>{ private int age; public int getAge(){ return age; } Person(int age){ this.age = age; } @Override public int compareTo(Person o) { return this.age-o.age; } } //结果 aba abb abc abf 2 22 42 62
5.重要结论,必须要掌握
- 必须要知道继承结构图,接口下面有那些子接口,都分别有哪些实现类
- List集合中的自定义类型一定要重写equals方法(contains,remove方法按内容比两个元素是否相同【生活中的逻辑是这样的】)
- HashSet、HashMap的K部分自定义类型,要同时重写hashCode和equals方法 (由于底层使用了散列表数据结构,所以要重新写hashCode函数,根据put,get方法的实现知道为什么要重写equals方法)
- TreeSet、TreeMap的K部分自定义类型,要具有可比较性(这是因为底层实现是搜索二叉树结构,put元素进去,必须要知道是怎么比较大小,才知道是在那边子树插入元素)
- 两种方法实现比较,1.自定的类型实现Comparable接口,重写compareTo(Object o)方法,(这个根据名字来记忆就是,类变成了可比较的,该类对象调用这个方法是和其他对象比,使用to) 2.使用TreeSet、TreeMap提供的有参构造器,传入比较器对象,具体看代码实现。两种方法中,1适合比较规则单一的,2适合比较规则多变的。
- 清楚常用实现类的特点,底层结构,知道什么情况下使用什么类,熟悉常用方法的原理
- 进阶:学会看源代码,学习源代码的编码风格和类之间结构设计,使用以上工具开发一个小项目(欢迎大家推荐);进一步了解java的继承,多态,接口,泛型对于框架设计的好处和使用,设计模式
PS:
上面提到的leetcode中的使用,请在之后的做题过程中规范起来,参照这篇文章。
专门写一篇leetcode中JAVA集合数据结构的使用场景,分析如何选择使用哪种类型的实现类,之后就按照这个去写代码,效率up
分个类:hash。链表,数组,栈,队列、排序、回溯
整个笔试面试题专题
预告:泛型;继承、抽象类、接口、多态;分析一下容器的源码,主要从设计上面(很好的巩固练习),接口和继承关系,以及容器特点的测试代码
算是第一比较认真写博客了,哈哈哈,下次提前写好提纲(内容怎么排版最容易记住知识点和突出重点呢),学会文章布局,配上代码和图片

 浙公网安备 33010602011771号
浙公网安备 33010602011771号