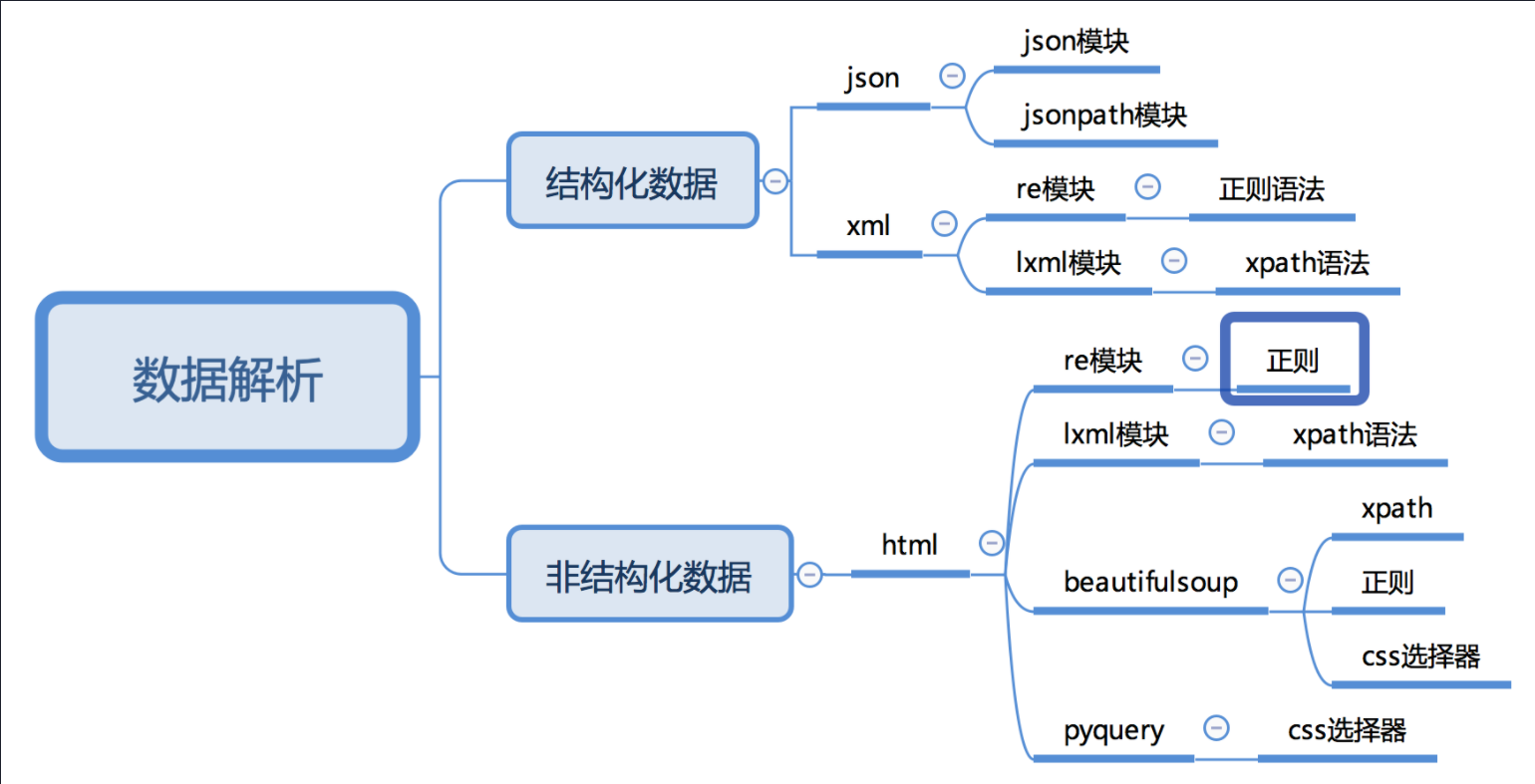
数据解析
常用数据解析的方法
lxml模块
简介
- lxml模块可以利用XPath规则语法,来快速的定位HTML\XML 文档中特定元素以及获取节点信息(文本内容、属性值)
- XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,可用来在 HTML\XML 文档中对元素和属性进行遍历。
- 提取xml、html中的数据需要lxml模块和xpath语法配合使用
谷歌浏览器插件
xpath helper插件可以帮助我们提高效率
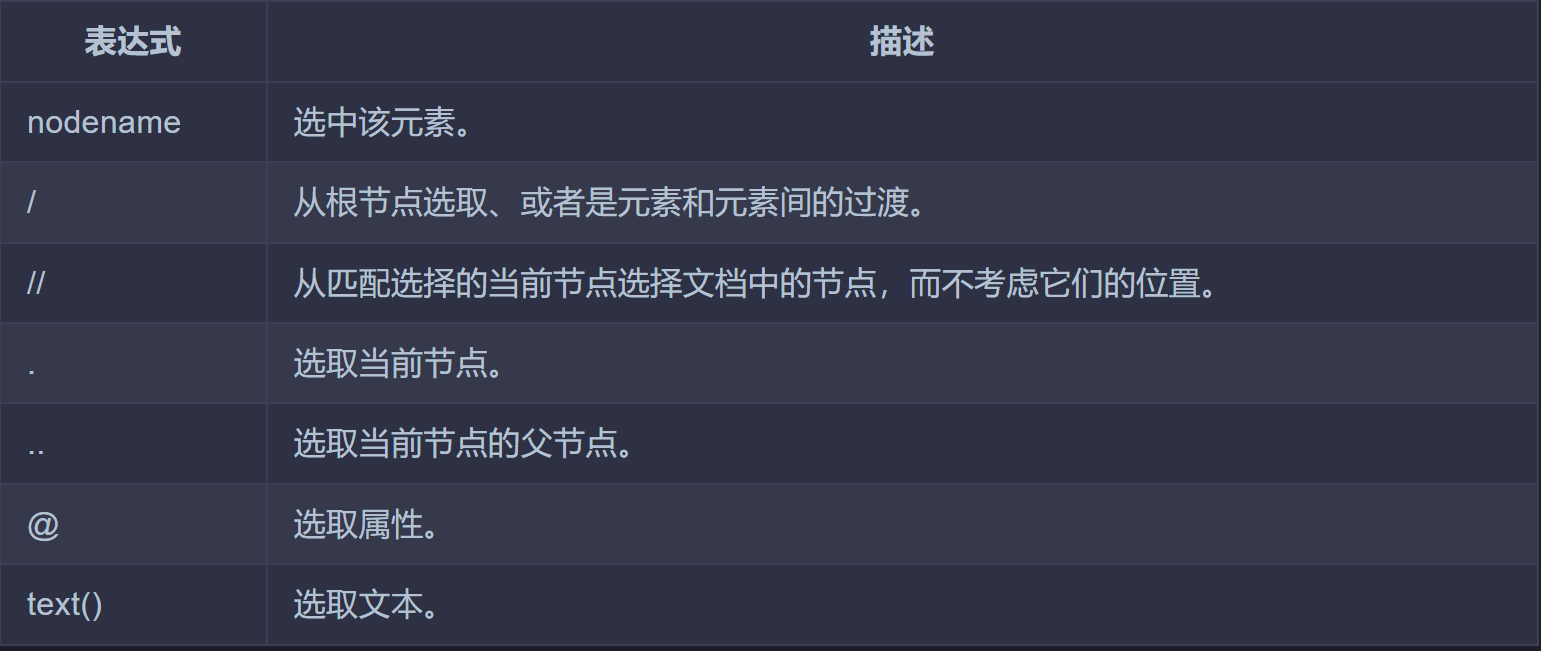
xpath基础结点选择语法
lxml模块的安装与使用
# 安装
pip3 install lxml
# lxml模块的使用
from lxml import etree
html = etree.HTML(text)
ret_list = html.xpath("xpath语法规则字符串")
print(ret_list) # 返回的是符合条件的列表
pyquery模块
# 功能类似于jQuery 选择器的语法
from pyquery import PyQuery as pq
"""
====> 下列方法括号内可以有参数,该参数可以是任何 jQuery 选择器的语法,
find():找出指定子元素
filter():对结果进行过滤,找出指定元素
children():获取所有子元素
parent():获取父元素
parents():获取祖先元素
siblings():获取兄弟元素
"""
# 初始化
textParse = pq(一段HTML代码)
# 获取
result = textParse('CSS标签').text()
print(result)
"""
add_class():增加class
remove_class():移除class
remove():删除指定元素
"""
result2=textParse("a").attr("href")
print(result2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号