Python 文件操作
文件是一个存储在辅助存储器上的数据序列,可以包含任何数据内容!(文件时数据的集合和抽象,类似的,函数是程序的集合和抽象)
一、对文件的操作:(数据从内存到硬盘的过程)
前提:
1.首先应知道文件的路径和文件名(绝对路径或相对路径)
2.文件的编码方式(文件到底是以什么编码储存的,如UTF-8 ,GBK,GB2312等)
3.操作文件的方式(只读、只写、追加、写读等等)(文件是以什么方式储存的就以什么方式打开)
#如:fo = open("item",mode="r",encoding="utf-8") #在pycharm下默认的编码方式是utf-8
文件操作流程:
1、打开文件,得到文件句柄并复制给一个变量
2、通过句柄对文件进行操作
3、关闭文件
##打开文件:
#1、打开文件,得到文件句柄并赋值给一个变量(得到文件的对象) f=open('文件路径、文件名','r',encoding='utf-8') #2、通过句柄对文件进行操作 data=f.read() #3、关闭文件 f.close()
#1、由应用程序向操作系统发起系统调用open(....) #2、操作系统打开该文件,并返回一个函数句柄给应用程序 #3、应用程序将文件句柄赋值给变量f
关闭文件的注意事项:
打开一个文件包含两部分资源:操作系统及打开的文件+应用程序的变量。在操作完毕一个文件时,必须把该文件的这两部分资源一个不落的回收,回收方法是:
1、f.close() # 回收操作系统级打开的文件,必须写 2、del f # 回收应用程序级的变量,可写可不写
其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源,而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们在操作完毕文件之后,一定要记住f.close()。
## with:由于很多时候会忘记在最后写上f.close(),可以使用with,在运行完with里面的内容之后会自动关闭文件
with open('文件名','r',encoding='utf-8') as f:#默认的是r,因此r可以不写 content = f.read() print(content) #Python文件
文件的编码:(Python是通过操作系统来操作文件的)
f=open(.....)是由操作系统打开文件,那如果没有为open指定编码,那么打开文件的默认编码很明显就是由操作系统说的算,此时操作系统会用自己默认的编码去打开文件,在windows中是gbk编码,在linux和mac系统中是utf-8编码。
文件的打开方式:
文件句柄=open('文件路径','模式')
找到文件详解:文件与py的执行文件在相同的路径下,直接用文件的名字既可以打开文件
文件与py的执行文件不在相同的路径下,就要使用绝对路径来寻找文件
文件的路径,需要用取消转义的方式来表示:1、\\ 或/ 2、r’文件的绝对路径'
f=open("/Users/Dell/Desktop/Python_file_study/file_test.txt",mode="a",encoding="gbk") fo = f.write("Python") f.close() #PythonPython
#####################打开文件###################3
#f=open('文件名','r',encoding='utf-8') #f=open('文件名','encoding='utf-8') 在打开文件时,默认模式为读。
1、读文件的第一种方式:read方法,用read方法会一次性的读出文件中的所有内容
f=open('item','r',encoding='utf-8') content=f.read() #bytes---->str(unicode)
print(content,type(content))
f.close()
#python #python <class 'str'> (在python3中字符串的编码方式是Unicode)
###打开非文本文字的文件 "rb" f = open("item",mode="rb") fo = f.read() print(fo,type(fo)) f.close() #b'python' <class 'bytes'>
2、读一部分内容:f.read(n),指定读n个单位(n个字符)字符是什么?你能看到的文字的最小单位
f = open("item",mode="r",encoding="utf-8") fo = f.read(2) print(fo) f.close() #py
3、读文件的第三种方式:按照行读,每次执行f.readline就会往下读一行。
f=open('item','r',encoding='utf-8') content1=f.readline() print(content1.strip()) # strip去掉空格、制表符、换行 #python1 content2=f.readline() print(content2.strip())
f.close() #python2
4、读文件的第四种方式:readlines,返回一个列表,将文件中的每一行作为列表中的每一项,返回一个列表。
f=open('item','r',encoding='utf-8') content=f.readlines() print(content) f.close() #['python1\n', 'python2']
5、读:最常用的方法。
##节省计算机内存资源(推荐使用)
f=open('item','r',encoding='utf-8') for line in f: #逐行读入文件的内容到内存,并逐行处理,节省内存资源(Python将文件本身作为一个行序列) print(line.strip()) f.close() # python1 # python2
##readlines将文件的全部内容读入内存并按行生成一个列表(如果文件很大或者不知道文件大小的时候,不推荐使用) f = open('item','r',encoding='utf-8') for line in f.readlines(): print(line.strip()) f.close() # python1 python2
6, ###写文件##
以 w 方式操作文件,没有此文件就创建文件,有就覆盖原文件的内容(其实进行的是两部操作:1,将原文件的内容全部删除 2,将要写的内容添加进去)
f = open('file_test','w',encoding='utf-8') f.write("量化金融") f.close()
如果写成bytes类型,需要进行写的内容编码方式的额外说明
##"wb"方式写 f = open('item','wb') f.write("量化金融".encode("utf-8"))#文件是以什么方式写进去,要看文件是以什么为默认的编码方式 f.close()
PS:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型
7.追加写a
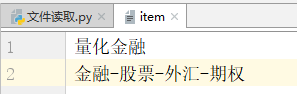
##a的追加写 f = open('item','a',encoding="utf") #追加写 f.write("金融-股票-外汇-期权") f.close()

##a的追加写 f = open('item','a',encoding="utf") #追加写 f.write("\n金融-股票-外汇-期权") f.close()
##例题:读取货物清单

#读取货物清单并以字典的形式显示 fo = open("goods","r",encoding="utf-8") goods_list = [] for line in fo: goods_dict = {} line = line.strip() goods_lst = line.split() print(goods_lst ) goods_dict["name"] = goods_lst [0] goods_dict["price"] = goods_lst[1] goods_dict["surplus"] = goods_lst[2] goods_list.append(goods_dict) print(goods_list) fo.close() ############### 'Computer', '10000', '10'] ['Apple', '4500', '18'] ['Car', '560000', '12'] [{'name': 'Computer', 'price': '10000', 'surplus': '10'}, {'name': 'Apple', 'price': '4500', 'surplus': '18'}, {'name': 'Car', 'price': '560000', 'surplus': '12'}]
##去掉文件空格、制表符、换行符之后打印出来
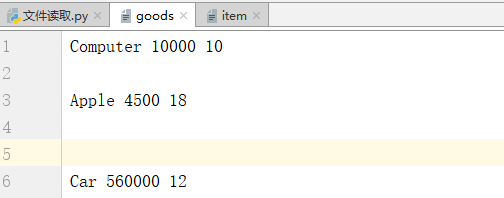
#去除去掉文件中的空格、制表符、换行符之后打印出来 fo = open("goods","r",encoding="utf-8") for line in fo: if line.strip(): print(line.strip()) fo.close() ### Computer 10000 10 Apple 4500 18 Car 560000 12
文件的打开模式:

#1. 打开文件的模式有(默认为文本模式):
r:只读模式【默认模式,文件必须存在,不存在则抛出异常】
w:只写模式【不可读;不存在则创建;存在则清空内容】
a:追加写模式【不可读;不存在则创建;存在则只追加内容】
#2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(bytes)(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp/png格式、视频文件的avi格式)
rb
wb
ab
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
####
在Python文件操作中没有改操作。
w+:可写可读:一当使用W+时上来文件就清空了。
尽管可读:1、新写入后,指针(光标)文件的最后
2、光标在最后,需要主动移动光标才可读
##w+模式
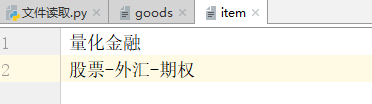
# w+ fo = open("item","w+",encoding="utf-8") fo.write("Python") fo.seek(0) #需要主动移动光标才可读 print(fo.read()) fo.close() #Python

##r+的操作方法也是一样的:
# r+ fo = open("item","r+",encoding="utf-8") fo.read() fo.write("金融") fo.seek(0) print(fo.read()) fo.close() ##Python金融
###在r+模式下若先写后读,则光标移动到写的最后一个字符的位置。读的内容是写的最后一个字符之后的内容
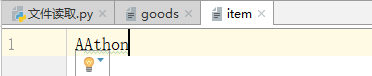
# r+ fo = open("item","r+",encoding="utf-8") fo.write("AA") print(fo.read()) fo.close() ##thon
################################ f=open('item','w+',encoding='utf-8') f.write('abc\n') f.write('span') f.seek(0) # 将光标移到文件的起始位置 print(f.read())
################################# # abc # span
备注:
一般情况下:文件操作,要么读,要么写,很少会用到读写、写读同时用的。
常用的:
r、w、a
rb、wb、ab 不需要指定编码(关于b的归类为非文字类)
#####
fo=open('item','rb') content = fo.read() fo.close() print(content) f = open('item','wb') f.write(content) f.close() ##b'abc\r\nspan'
文件内的光标移动:
1、seek 光标移动到指定位置
f.seek(0) 移动到文件最开始
f.seek(0,2) 移动到最末尾
f.seek() 是按字节移动光标,而不是字符(按字节定光标的位置)
f.read(n) 按字符读取文件的值
f.tell() #返回光标所在的位置(字节数)
fo=open('item','r',encoding="utf-8") fo.seek(3) #第三个字节处 print(fo.tell())#告诉用户光标所在的位置 print(fo.read()) fo.close() ## 3 化金融
#######################################
#写入一个字符串,然后只读后几位
# item = “量化金融” fo=open('item','a+',encoding="utf-8") fo.write("外汇") count = fo.tell()#返回当前光标所在的位置 fo.seek(count-9)#设置光标的位置,读取后三个中文字符(由于每个中文字符占3个字节所以减9) print(fo.read()) fo.close() ##融外汇
# f.truncate(n) 从文件开始的位置只保留指定字节的内容
f.truncate(3)
### item = “量化金融” fo=open('item','r+',encoding="utf-8") fo.truncate(3) print(fo.read()) fo.close() #量
with open("金融量化交易",encoding="utf-8") as f1,open("外汇","w",encoding="utf-8") as f2: for line in f1: if "炒币" in line: line = line.replace("炒币","外汇") f2.write(line)#写文件 import os os.remove("金融量化交易")#删除文件 os.rename("外汇","金融量化交易")#将文件重命名

###
##需求:将用户的用户名及密码保存在文件中,并模拟登陆验证
#需求:将用户的用户名及密码保存在文件中,并模拟登陆验证 user_name = input("请输入要注册的用户名:") user_password = input("请输入要注册的密码:") with open("info_list","w",encoding="utf-8") as f1: f1.write("{}\n{}".format(user_name,user_password)) print("恭喜你注册成功!") i = 0 info = [] while i < 3: uname = input("请输入用户名:") upwd = input("请输入密码:") with open("info_list","r",encoding="utf-8") as f2: for line in f2: info.append(line.strip()) if uname==info[0] and upwd==info[1]: print("用户名及密码正确,正在登陆") break else: print("用户名或密码错误!") i += 1
总结:
打开文件:
#open(路径,打开方式,编码方式)
#打开方式:r w a r+ w+ a+
#r+ 打开文件直接写和读完再写
#编码方式:UTF-8
操作文件:
#读
#read 一次性读完整个文件,将整个文件看成一个大的字符串。
#readlines 也是一次性读取整个文件,并按行切分成一个列表。
#readline 一行一行读
#不知道在哪里结束
#有些文件是不按行的 如视频、图片文件 因此需要按字节读rb
# 最好的方法是按for循环对整个文件遍历,每次循环只读取一行,因此内存里只有一行数据。
#写
# write
#光标--- 文件指针
seek()指定光标移动的位置
tell()获取光标当前的位置
truncate()截取文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号