

配置java
1. 虚拟机安装 centos 7
解决contos7完成后没有网络
cd /etc/sysconfig/network-scripts/
修改
vim ifcfg-ens33
修改 ONBOOT=no 为 ONBOOT=yes
重启
systemctl restart network(重启服务命令)
查看 ip
ifconfig(查看ip)
安装 vim
yum -y install vim*
安装完成后开始配置 vim
vim /etc/vimrc
添加下面的内容(选择添加)
set nu " 设置显示行号
set showmode " 设置在命令行界面最下面显示当前模式等
set ruler " 在右下角显示光标所在的行数等信息
set autoindent " 设置每次单击Enter键后,光标移动到下一行时与上一行的起始字符对齐
syntax on " 即设置语法检测,当编辑C或者Shell脚本时,关键字会用特殊颜色显示
改变hosts名称, 其他两个主机都是同样的配置,不要修改
vim /etc/hosts

重启
reboot
测试端口,如果怎么都进不去,小心防火墙,开放端口
https://jingyan.baidu.com/article/09ea3ede7311dec0afde3977.html
安装java环境
解压java
tar -zxvf jdk-8u261-linux-x64.tar.gz -C /usr/local
进入目录
cd /usr/local
改目录
mv jdk1.8.0_261 java
设置环境变量
打开文件
vim /etc/profile
在末尾添加
export JAVA_HOME=/usr/local/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
使环境变量生效
source /etc/profile
添加软链接
ln -s /usr/local/java/bin/java /usr/bin/java
检查
java -version
centos7实现免密登录
1、先在root用户下,执行ssh-keygen -t rsa,一路回车,接着会产生在/root目录下会产生.ssh目录
ssh-keygen -t rsa
查看.ssh 目录,会发现它下面生成了两个 id_rsa , id_rsa.pub 文件
![]()
2、在 node1 上将公钥(id_rsa.pub)拷贝到其它节点,包括本机
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
在 node2 节点上和 node3 节点都要重复上述 1、2 操作,分别产生各自的一对钥匙,并拷贝到其它节点(包括本机)
配置node2和node3的java
(1)复制虚拟机 java 文件
scp -r /usr/local/java root@node2:/usr/local
scp -r /usr/local/java root@node3:/usr/local
(2) 复制 node1 的 profile 到 node2, node3
scp -r /etc/profile root@node2:/etc/profile
scp -r /etc/profile root@node3:/etc/profile
在node2中
source /etc/profile
在node3中
source /etc/profile
安装hadoop
进入 hadoop 目录
cd /usr/local/hadoop/etc/hadoop
修改 hadoop-env.sh
vim hadoop-env.sh
找到 “export JAVA_HOME” 这行,用来配置 jdk 路径
export JAVA_HOME=/usr/local/java/
执行编辑 core-site.xml 文件的命令:
vim core-site.xml
需要在<configuration>和</configuration>之间加入的代码:
<property> <name>fs.defaultFS</name> <value>hdfs://node1:9000/hbase</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoopdata</value> </property>
执行编辑 hdfs-site.xml 文件的命令:
vim hdfs-site.xml
需要在 <configuration> 和 </configuration> 之间加入的代码:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
执行编辑 yarn-site.xml 文件的命令:
vim yarn-site.xml
需要在 <configuration> 和 </configuration> 之间加入的代码:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>node1:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node1:18088</value>
</property>
执行复制和改名操作命令:
cp mapred-site.xml.template mapred-site.xml
vim 编辑 mapred-site.xml 文件
vim mapred-site.xml
需要在 <configuration> 和 </configuration> 之间加入的代码:
<property> <name>mapreduce.framework.name</na:me> <value>yarn</value> </property>
执行编辑 slaves 文件命令:
vim slaves
加入以下代码
注意:删除 slaves 文件中原来 localhost 那一行!
node2
node3
复制 master 上的 Hadoop 到 node2 和 node3 节点
通过复制 master 节点上的 hadoop,由于我这里有node2和node3,所以复制两次。
复制命令:
scp -r /usr/local/hadoop node2:/usr/local
scp -r /usr/local/hadoop node3:/usr/local
Hadoop 集群的启动-配置操作系统环境变量(三个节点都做)
回到用户目录命令
cd /usr/local/hadoop
然后用 vi 编辑 .bash_profile 文件,命令:
vi ~/.bash_profile
最后把以下代码追加到文件的尾部:
#HADOOP
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存退出后,执行命令:
source ~/.bash_profile
source ~/.bash_profile命令是使上述配置生效
提示:在 node2 和 node3 使用上述相同的配置方法,进行三个节点全部配置。
创建数据目录,命令是:
mkdir /usr/hadoopdata
格式化文件系统
进入目录
cd /usr/local/hadoop/bin
执行格式化文件系统命令:
./hadoop namenode -format
启动和关闭 Hadoop 集群
首先进入安装主目录,命令是:
cd /usr/local/hadoop/sbin
然后启动,命令是:
start-all.sh
执行命令后,系统提示 ”Are you sure want to continue connecting(yes/no)”,输入yes,之后系统即可启动。
注意:可能会有些慢,千万不要以为卡掉了,然后强制关机,这是错误的。
如果要关闭 Hadoop 集群,可以使用命令:
stop-all.sh
jps命令如果失效
vi ~/.bash_profile
修改如下,找到PATH=$PATH:$HOME/bin
![]()
zookeeper 集群搭建
然后在三台服务器分别安装 zookeeper
tar -zxvf zookeeper-3.4.12.tar.gz -C /usr/local
修改目录名
mv /usr/local/zookeeper-3.4.14 /usr/local/zookeeper
修改配置文件
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
打开 zoo.cfg
vim /usr/local/zookeeper/conf/zoo.cfg
修改 zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data
clientPort=2181
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
创建数据存储目录
mkdir -p /usr/local/zookeeper/data
创建 myid 文件, id 与 zoo.cfg 中的序号对应
#在 node1 机器上执行
vim myid 内容 1
#在 node2 机器上执行
vim myid 内容 2
#在 node3 机器上执行
vim myid 内容 3
配置环境变量
vim /etc/profile
在最后加上:
export PATH=$PATH:/usr/local/zookeeper/bin
分别拷贝 zookeeper 到 node2 和 node3 中
scp -r /usr/local/zookeeper node2:/usr/local
scp -r /usr/local/zookeeper node3:/usr/local
拷贝 profile 到 node 2 和 node3 中
scp -r /etc/profile node2:/etc
scp -r /etc/profile node2:/etc
关闭防火墙
systemctl stop firewalld.service #关闭防火墙
systemctl disable firewalld.service #禁止启动防火墙
分别启动
zkServer.sh start
查看状态
zkServer.sh status
验证Hadoop集群是否启动成功
在 master 节点,执行:
jps
如果显示:SecondaryNameNode、 ResourceManager、 Jps 和 NameNode 这四个进程,则表明主节点 master 启动成功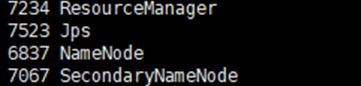
然后分别在 node2 和 node3 节点下执行命令:
jps
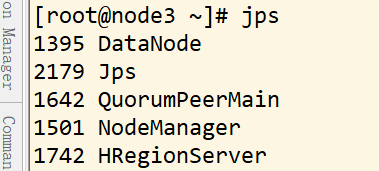
如果成功显示:NodeManager、Jps 和 DataNode,这三个进程,则表明从节点(node2 和 node3)启动成功
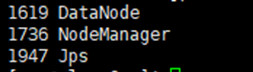
Hbase安装和配置
1、使用 vim 编辑配置文件 hbase-env.sh,尾部添加内容如下:
export JAVA_HOME=/usr/local/java
export HBASE_MANAGES_ZK=false
2. 使用 vim 编辑配置文件 hbase-site.xml,更改内容如下:
vim hbase-site.xml
hbase.rootdir
这个目录是 RegionServer 的共享目录,用来持久化 HBase。URL 需要是 “完全正确” 的,还要包含文件系统的 scheme。 例如 “/hbase” 表示 HBase 在 HDFS 中占用的实际存储位置,HDFS 的 NameNode 运行在主机名为 master5 的 8020 端口,则 hbase.rootdir 的设置应为 “hdfs://master5:8020/hbase”。在默认情况下 HBase 是写在 /tmp 中的。不修改这个配置的话,数据会在重启的时候丢失。
特别注意的是 hbase.rootdir 里面的 HDFS 地址是要跟 Hadoop 的 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、端口必须一致。
hbase.cluster.distributed
HBase 的运行模式。为 false 表示单机模式,为 true 表示分布式模式。若为 false,HBase 和 ZooKeeper 会运行在同一个 JVM 中
默认值为 false
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,node3</value>
</property>
</configuration>
3. 修改 regionservers
vim regionservers
添加主机
node2
node3
4. 然后将 /usr/local 目录下的 hbase 远程拷贝到 node2 和 node3 主机的 /usr/local 目录下:
scp -r /usr/local/hbase node2:/usr/local
scp -r /usr/local/hbase node3:/usr/local
5. 进入目录
cd /usr/local/hbase/bin
6. 启动 hbase 集群
./start-hbase.sh
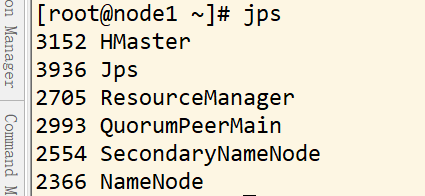
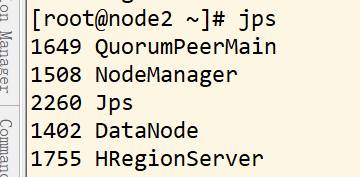
jps 查看集群
主机 node1
主机 node2
主机 node3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号