

2022.4.2数据库设计与性能分析
软件开发中,关于数据库的设计
-
分析需求:分析业务和需要处理的数据库的需求
-
概要设计:设计关系图E-R图
设计数据库的步骤:(个人博客)
-
收集信息,分析需求
-
用户表(用户登录注销,用户的个人信息,写博客,创建分类)。
-
分类表(文章分类,谁创建的)
-
-
友链表(友链信息)
-
自定义表((系统信息,某个关键的字,或者一些主字段)key : value
-
-
标识实体(把需求落地到每个字段)
三大范式
-
第一范式(1NF)
原子性:保证每一列不可再分
-
第二范式(2NF) 前提:满足第一范式每张表只描述一件事情
-
第三范式(3NF) 前提:满足第一范式和第二范式 第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
规范性和性能的问题
关联查询的表不得超过三张表
-
考虑商业化的需求和目标,(成本,用户体验! )数据库的性能更加重要
-
在规范性能的问题的时候,需要适当的考虑一下规范性!
-
故意给某些表增加一些冗余的字段。(从多表查询中变为单表查询)
-
故意增加一些计算列(从大数据量降低为小数据量的查询:索引)
性能分析
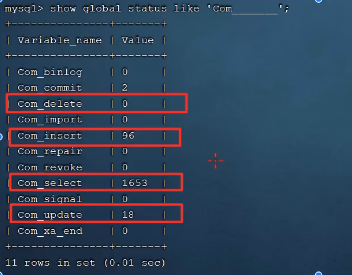
查看执行频次
查看当前数据库的 INSERT, UPDATE, DELETE, SELECT 访问频次: SHOW GLOBAL STATUS LIKE 'Com_______'; 或者 SHOW SESSION STATUS LIKE 'Com_______'; 例:
1 show global status like 'Com_______'
慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。 MySQL的慢查询日志默认没有开启,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息: # 开启慢查询日志开关 slow_query_log=1 # 设置慢查询日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志 long_query_time=2 更改后记得重启MySQL服务,日志文件位置:/var/lib/mysql/localhost-slow.log
查看慢查询日志开关状态:
1 show variables like 'slow_query_log';
profile
show profile 能在做SQL优化时帮我们了解时间都耗费在哪里。通过 have_profiling 参数,能看到当前 MySQL 是-
-
否支持 profile 操作:
SELECT @@have_profiling; -
查看profile 开启状态 0是未开启:
SELECT @@profiling; -
profiling 默认关闭,可以通过set语句在session/global级别开启 profiling:
SET profiling = 1; -
查看所有语句的耗时:
show profiles; -
查看指定query_id的SQL语句各个阶段的耗时:
show profile for query query_id; -
查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query query_id;
explain
EXPLAIN 或者 DESC 命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。 语法: 直接在select语句之前加上关键字 explain / desc EXPLAIN SELECT 字段列表 FROM 表名 HWERE 条件;
EXPLAIN 各字段含义:
-
id:select 查询的序列号,表示查询中执行 select 子句或者操作表的顺序(id相同,执行顺序从上到下;id不同,值越大越先执行,多表查询)
-
select_type:表示 SELECT 的类型,常见取值有 SIMPLE(简单表,即不适用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(SELECT/WHERE之后包含了子查询)等
-
type:表示连接类型,性能由好到差的连接类型为 NULL、system、const(主键或唯一索引)、eq_ref、ref、range、index、all
-
possible_key:可能应用在这张表上的索引,一个或多个
-
Key:实际使用的索引,如果为 NULL,则没有使用索引
-
Key_len:表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好
-
rows:MySQL认为必须要执行的行数,在InnoDB引擎的表中,是一个估计值,可能并不总是准确的
-
filtered:表示返回结果的行数占需读取行数的百分比,filtered的值越大越好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号