
Python工具箱系列(六十五)
语音识别(下)
北京大学的饶毅教授是非常令人尊敬的科学家。他的一篇最短致辞,轰动全网,是一个学者、有良知的人对学生的期待与祝福。为了方便比对,先将饶毅的原文列举如下。
在祝福裹着告诫呼啸而来的毕业季,请原谅我不敢祝愿每一位毕业生都成功、都幸福;因为历史不幸地记载着:有人的成功代价是丧失良知;有人的幸福代价是损害他人。从物理学来说,无机的原子逆热力学第二定律出现生物是奇迹;从生物学来说,按进化规律产生遗传信息指导组装人类是奇迹。超越化学反应结果的每一位毕业生都是值得珍惜的奇迹;超越动物欲望总和的每一位毕业生都应做自己尊重的人。过去、现在、将来,能够完全知道个人行为和思想的只有自己;世界上很多文化借助宗教信仰来指导人们生活的信念和世俗行为;而对于无神论者——也就是大多数中国人——来说,自我尊重是重要的正道。在你们加入社会后看到各种离奇现象,知道自己更多弱点和缺陷,可能还遇到小难大灾后,如何在诱惑和艰难中保持人性的尊严、赢得自己的尊重并非易事,却很值得。这不是:自恋、自大、自负、自夸、自欺、自闭、自怜,而是:自信、自豪、自量、自知、自省、自赎、自勉、自强。自尊支撑自由的精神、自主的工作、自在的生活。
我祝愿:
退休之日,你觉得职业中的自己值得尊重;迟暮之年,你感到生活中的自己值得尊重。不要问我如何做到,50年后返校时告诉母校你如何做到:在你所含全部原子再度按热力学第二定律回归自然之前,它们既经历过物性的神奇,也产生过人性的可爱。我们下载视频后,提取后进行音频分割,并且使用两种方法进行语音识别。以下代码演示了这个过程。
import auditok
import paddle
# 导入百度在线的API
from aip import AipSpeech
from moviepy.editor import VideoFileClip
from paddlespeech.cli.asr import ASRExecutor
from paddlespeech.cli.asr.infer import ASRExecutor
from paddlespeech.cli.text import TextExecutor
def extract_audio(videofile, audiofile):
"""
从视频文件导出音频来
Args:
videofile (string): 视频文件
audiofile (string): 音频文件
"""
video = VideoFileClip(videofile)
video.audio.write_audiofile(audiofile, ffmpeg_params=[
"-ar", "16000", "-ac", "1"])
def splitaudio(audiofilename, plotflag=False, playflag=False):
"""
分割音频文件
Args:
audiofilename (string): 音频文件
plotflag (bool, optional): 是否画图显示
playflag (bool, optional): 是否播放分割后的音频片断
Returns:
list: 切分后的音频片断文件列表
"""
region = auditok.load(audiofilename)
if plotflag:
regions = region.split_and_plot(min_dur=1, max_dur=50, max_silence=0.5)
else:
regions = region.split(min_dur=1, max_dur=50, max_silence=0.5)
# 将分割进行输出
filelist = []
recfile = open('split.csv', 'w', encoding='utf-8')
for index, clip in enumerate(regions):
if playflag:
clip.play(progress_bar=True)
filename = f"clip-{index}.wav"
clip.save(filename)
filelist.append(filename)
recfile.write(
f"""{filename},{clip.meta['start']},{clip.meta['end']}\r\n""")
recfile.close()
return filelist
def stt_paddlespeech(audiofilename):
"""
对语音进行文字识别,并且使用标点符号进行标注
Args:
audiofilename (string): 音频文件
Returns:
string: 文字识别结果
"""
asr_executor = ASRExecutor()
text_executor = TextExecutor()
text = asr_executor(
audio_file=audiofilename,
device=paddle.get_device())
result = text_executor(
text=text,
task='punc',
model='ernie_linear_p3_wudao',
device=paddle.get_device())
return result
def get_file_content(audiofilename):
"""
读取文件
Args:
audiofilename (string): 音频文件
Returns:
bytes: 音频文件的内容(字节流)
"""
with open(audiofilename, "rb") as fp:
return fp.read()
def stt_baiduspeech(audiofilename):
"""
使用百度云语音技术进行识别
Args:
audiofilename (string): 音频文件
Returns:
string: 文字识别结果
"""
APP_ID = "25488691"
API_KEY = "znWXeviMeMu4hR3Z8AHzkL6H"
SECRET_KEY = "c9MGyuik2ahPVNa1ECVDav6SctBoZ52z"
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.asr(
get_file_content(audiofilename),
"wav",
16000,
{
# 普通话
"dev_pid": 1536,
},
)
return result['result']
targetaudio_linux = "/root/test/wave/beijin.wav"
# 第一步,将视频文件中的音频志出来
extract_audio('/root/test/mp4/beijin.mp4', targetaudio_linux)
# 第二步,先分割音频
result = splitaudio(targetaudio_linux, plotflag=True)
# 第三步,对每个片断,使用paddlespeech/baidu api进行识别,并且将结果保存到文件中
with open('result.csv', 'w', encoding='utf-8') as fout:
for file in result:
result1 = stt_paddlespeech(file)
result2 = stt_baiduspeech(file)
fout.write(f'{file},{result1},{result2[0]}\r\n')上述代码在第一次运行时,会下载所需要的模型库,相对较慢。后续再次运行时会快一些,但语音识别的过程本身还是比较慢的。在代码中,将分割结果与识别结果分别保存起来,后续使用excel进行加工后,将两种方式的效果与原文比对如下图所示。
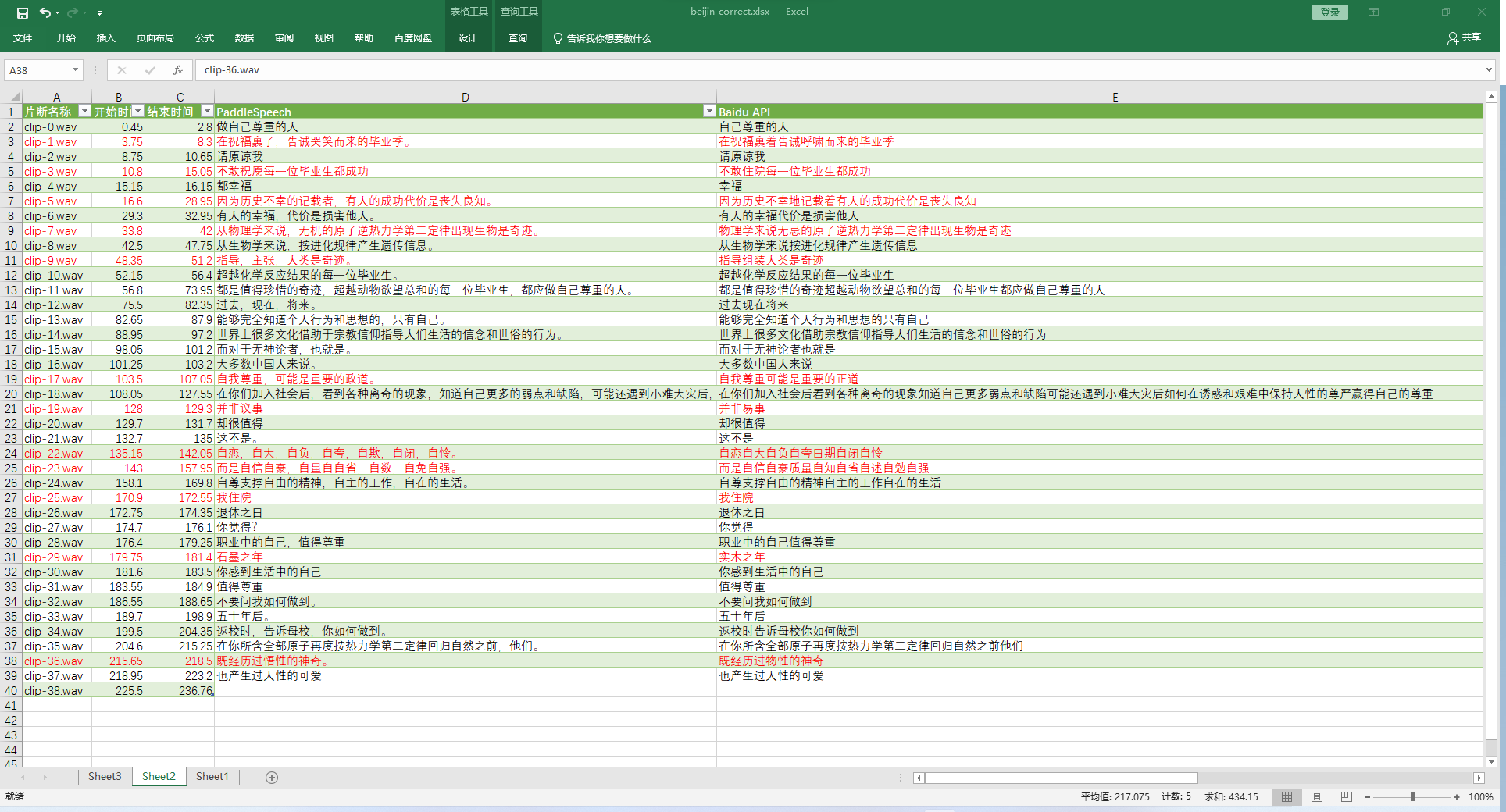
标红的行为识别不正确的地方。统计下来有12个片断识别不太正确,识别效果一言难尽非常感人,所以还是人类自身的识别能力非凡。最后将安装第三库的过程重复如下。
pip install moviepy
pip install auditok
pip install baidu-aip从效果上来看,无论是在线API还是离线模型,识别结果效果都差强人意。如果用于电影字幕的制作,效果可能更差,最终还是需要人去校对,否则翻译出来的结果令人啼笑皆非。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号