


【R语言学习笔记】2. 线性回归与CART回归树的应用及对比
1. 目的:根据房子信息,判断博士顿地区的房价。
2. 数据来源:论文《Hedonic housing prices and the demand for clean air》,数据中共含506个观测值,及16个变量。其中,每个观测值代表一个人口普查区。
boston <- read.csv("boston.csv") # 读取文件
str(boston) # 查看数据结构
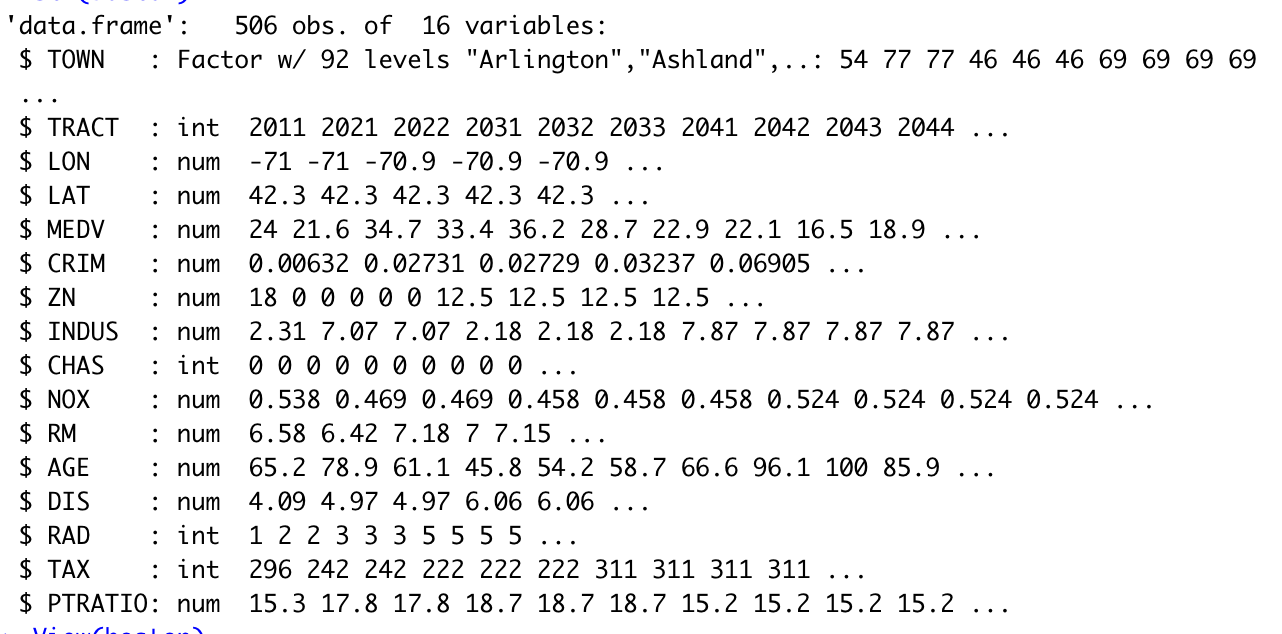
3. 变量介绍:
(1)town:每一个人口普查区所在的城镇
(2)LON: 人口普查区中心的经度
(3)LAT: 人口普查区中心的纬度
(4)MEDV: 每一个人口普查区所对应的房子价值的中位数 (单位为$1000)
(5)CRIM: 人均犯罪率
(6)ZN: 土地中有多少是地区是大量住宅物业
(7)INDUS: 区域中用作工业用途的土地占比
(8)CHAS: 1:该人口普查区紧邻查尔斯河;0: 该人口普查区没有紧邻查尔斯河
(9)NOX: 空气中氮氧化物的集中度 (衡量空气污染的指标)
(10)RM: 每个房子的平均房间数目
(11)AGE: 建于1940年以前的房子的比例
(12)DIS: 该人口普查区距离波士顿市中心的距离
(13)RAD: 距离重要高速路的远近程度 (1代表最近;24代表最远)
(14)TAX: 房子每$10,000价值所对应的税收金额
(15)PTRATIO: 该城镇学生与老师的比例
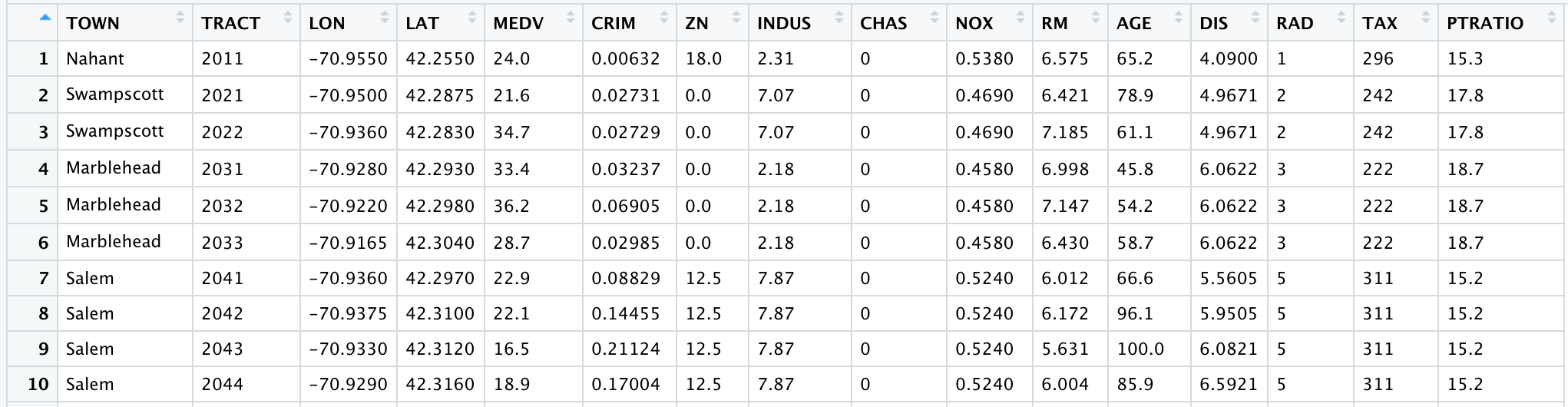
View(boston) # 查看数据
4. 应用及分析
4.1 数据探索
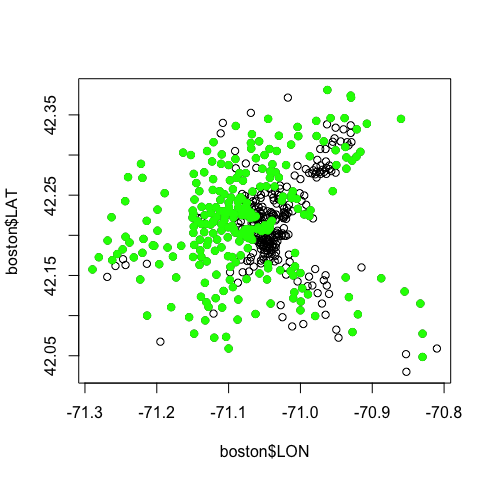
plot(boston$LON, boston$LAT) # 根据人口普查区的经度和纬度作图
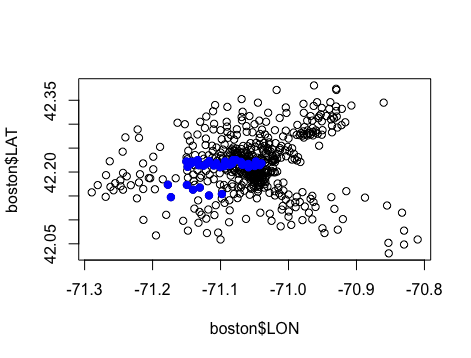
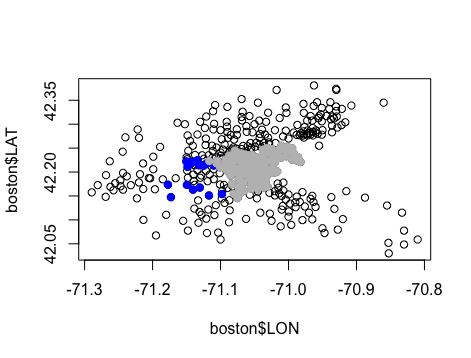
points(boston$LON[boston$CHAS == 1], boston$LAT[boston$CHAS==1], col = 'blue', pch = 19) # 蓝色代表紧邻查尔斯河的人口普查区
summary(boston$NOX) # NOX的平均数大约为0.55 points(boston$LON[boston$NOX >= 0.55], boston$LAT[boston$NOX >= 0.55], col = 'gray', pch = 19) # 灰色代表NOX大于平均值的地区
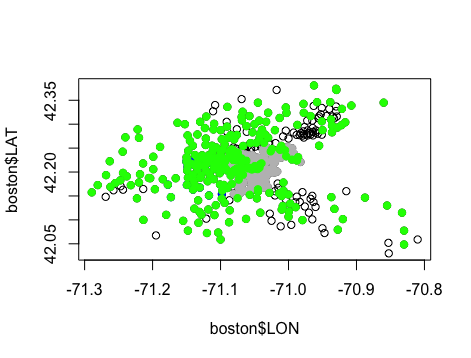
summary(boston$MEDV) #各地区中位数房价 的 中位数为21.2 points(boston$LON[boston$MEDV >= 21.2], boston$LAT[boston$MEDV >= 21.2], col = 'green', pch = 19) # 绿色代表中位数房价 高于中位数的地区
4.2 运用经度和纬度两个自变量构建线性回归模型
model1 <- lm(MEDV ~ LON + LAT, data = boston) # 经度和纬度为自变量,中位数房价为因变量 summary(model1) # not a good model

虽然自变量“纬度”非常显著,但是模型的调整后R^2只有0.1036,因此,线性回归模型不是非常理想。
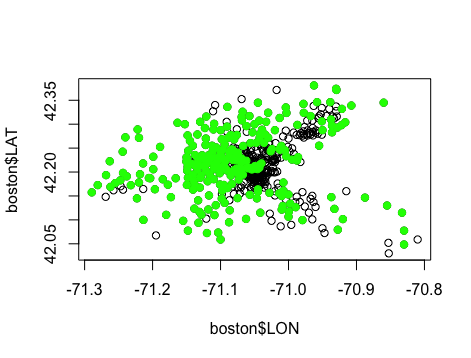
plot(boston$LON, boston$LAT) points(boston$LON[boston$MEDV >= 21.2], boston$LAT[boston$MEDV >= 21.2], col = 'green', pch = 19) # 绿色代表实际房价中位数 高于中位数的地区
points(boston$LON[model1$fitted.values >= 21.2], boston$LAT[model1$fitted.values >= 21.2], col = 'yellow', pch = 19) # 黄色代表线性回归模型所预测的中位数房价 高于 中位数的地区
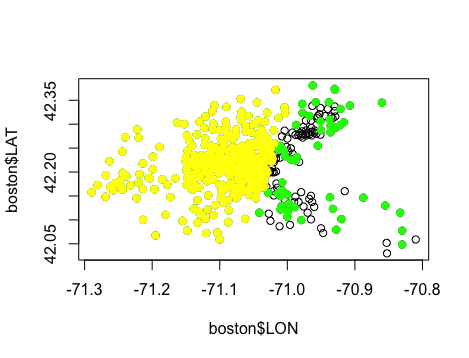
上图进一步证实了线性回归模型不是很理想,因为模型完全忽略了图像中右半部分的地区。同时,这也证实了“自变量’纬度'不显著”的说法。
4.3 运用经度和纬度两个自变量构建CART回归树
library(rpart) # 加载rpart包,用于构建CART模型 library(rpart.plot) # 加载rpart.plot包,用于绘制回归树 tree1 <- rpart(MEDV ~ LAT + LON, data = boston) # 不需要加method="class",因为构建的是回归树而非分类树 prp(tree1, digits = 4) # 绘制回归树
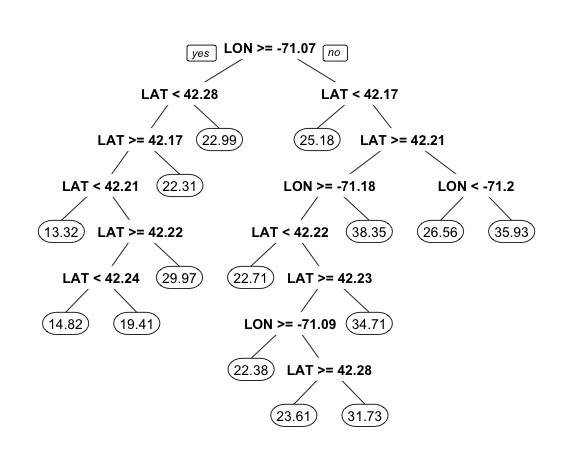
points(boston$LON[boston$MEDV >= 21.2], boston$LAT[boston$MEDV >= 21.2], col = 'green', pch = 19) # 绿色为原数据中房价中位数 高于 中位数的 地区
fitted <- predict(tree1) # 运用回归树tree1预测每个地区的房价中位数 points(boston$LON[fitted >= 21.2], boston$LAT[fitted >= 21.2], col = 'yellow', pch = 19) # 黄色为预测数据高于中位数的地区

由此不难看出,与线性回归模型相比,回归树tree1的准确性显著提高。
4.4 运用全部自变量构建线性回归模型并不断优化
library(caTools) # 加载caTools包,将数据分为70%训练集和30%测试集 set.seed(123) # 设置种子 spl <- sample.split(boston$MEDV, SplitRatio = 0.7) train <- subset(boston, spl == T) # 训练集 test <- subset(boston, spl == F) # 测试集
lm1 <- lm(MEDV ~ LAT + LON + CRIM + ZN + INDUS + CHAS + NOX + RM + AGE + DIS + RAD + TAX + PTRATIO, data = train) # 运用训练集数据构建线性回归模型 summary(lm1)

其中,CRIM, CHAS, NOX, RM, AGE, DIS, RAD, TAX, PTRATIO为显著变量,模型调整后R^2为0.6525,较之前线性回归模型的调整后R^2相比显著提高。
lm1pred <- predict(lm1, newdata = test) # 将模型应用到测试集用于预测集
library(forecast) # 加载forecast包
accuracy(lm1pred, test$MEDV) # 计算模型准确性
接着,依次剔除模型中最不显著的自变量LAT, INDUS, LON,直至所有自变量均显著,构建以下线性回归模型:
lm4 <- lm(MEDV ~ CRIM + ZN + CHAS + NOX + RM + AGE + DIS + RAD + TAX + PTRATIO, data = train) # 将模型应用到测试集用于预测集
summary(lm4) lm4pred <- predict(lm4, newdata = test)
accuracy(lm4pred, test$MEDV)
对比两个模型的准确性:
library(forecast) accuracy(lm1pred, test$MEDV) # 应用所有自变量的模型准确性 (模型4) accuracy(lm4pred, test$MEDV) # 剔除LAT, INDUS, LON以后的模型准确性 (模型1)

对比ME, RMSE, MAE, MPE, MAPE, 不难发现模型4略微比模型1准确。
4.5 运用全部自变量构建CART回归树并不断优化
tree3 <- rpart(MEDV ~ LAT + LON + CRIM + ZN + INDUS + CHAS + NOX + RM + AGE + DIS + RAD + TAX + PTRATIO, data = train) prp(tree3)
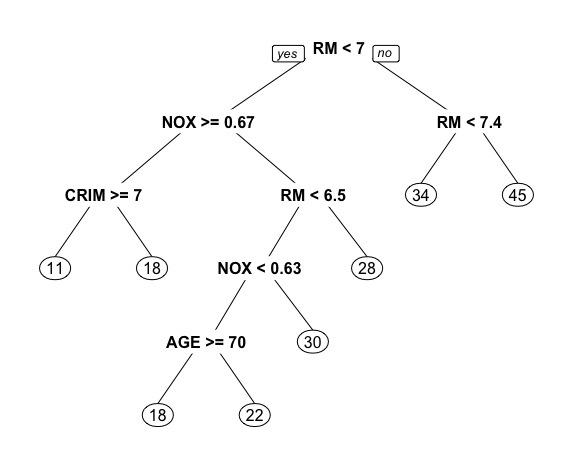
treepred <- predict(tree3, newdata = test) # 将回归树tree3应用到训练集,进行预测 accuracy(treepred, test$MEDV) # 回归树tree3的准确性

通过对比ME, RMSE, MAE, MPE, MAPE等指标,发现该回归树tree3的准确定略低于线性回归模型 (模型1以及模型4)
接下来,通过引入cp, 进行交叉检验来寻找最佳的回归树模型
library(caret) library(lattice) library(ggplot2) library(e1071) tr.control <- trainControl(method = 'cv', number = 10) cp.grid <- expand.grid(.cp = (0:10)*0.001) tr <- train(MEDV ~ LAT + LON + CRIM + ZN + INDUS + CHAS + NOX + RM + AGE + DIS + TAX + PTRATIO, data = train, method = 'rpart', trControl = tr.control, tuneGrid = cp.grid) tr # cp = 0.001

基于cp=0.001,构建新的回归树
best.tree <- tr$finalModel prp(best.tree)
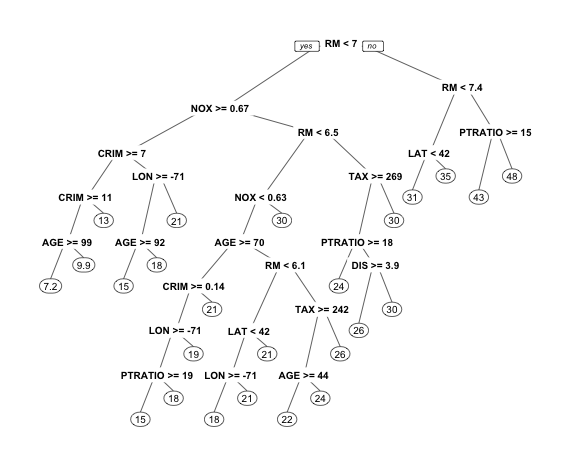
best.tree.pred <- predict(best.tree, newdata = test) # 将新的回归树best.tree应用到训练集数据中进行预测 accuracy(best.tree.pred, test$MEDV) # 回归树best.tree的准确性

虽然引入cp,做了交叉检验以后,回归树best.tree与回归树tree3相比,准确率有所提升,但准确率仍低于线性回归模型(模型4)。因此,回归树模型不一定是一个更好的选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号