
Jmeter脚本 CSV文件参数读取乱码问题
前言
Deep Seek 告诉我,99%的CSV乱码问题都能解决。重点检查 文件真实编码 和 CSV组件的显示编码设置。
踩坑之——配了[CSV文件参数]组件后,[调试取样器]读取的变量乱码
1、上配置
(1)创建CSV文件(由.xls文件重命名获得,注意这个地方),并在Jmeter脚本中进行【CSV数据文件配置】组件配置
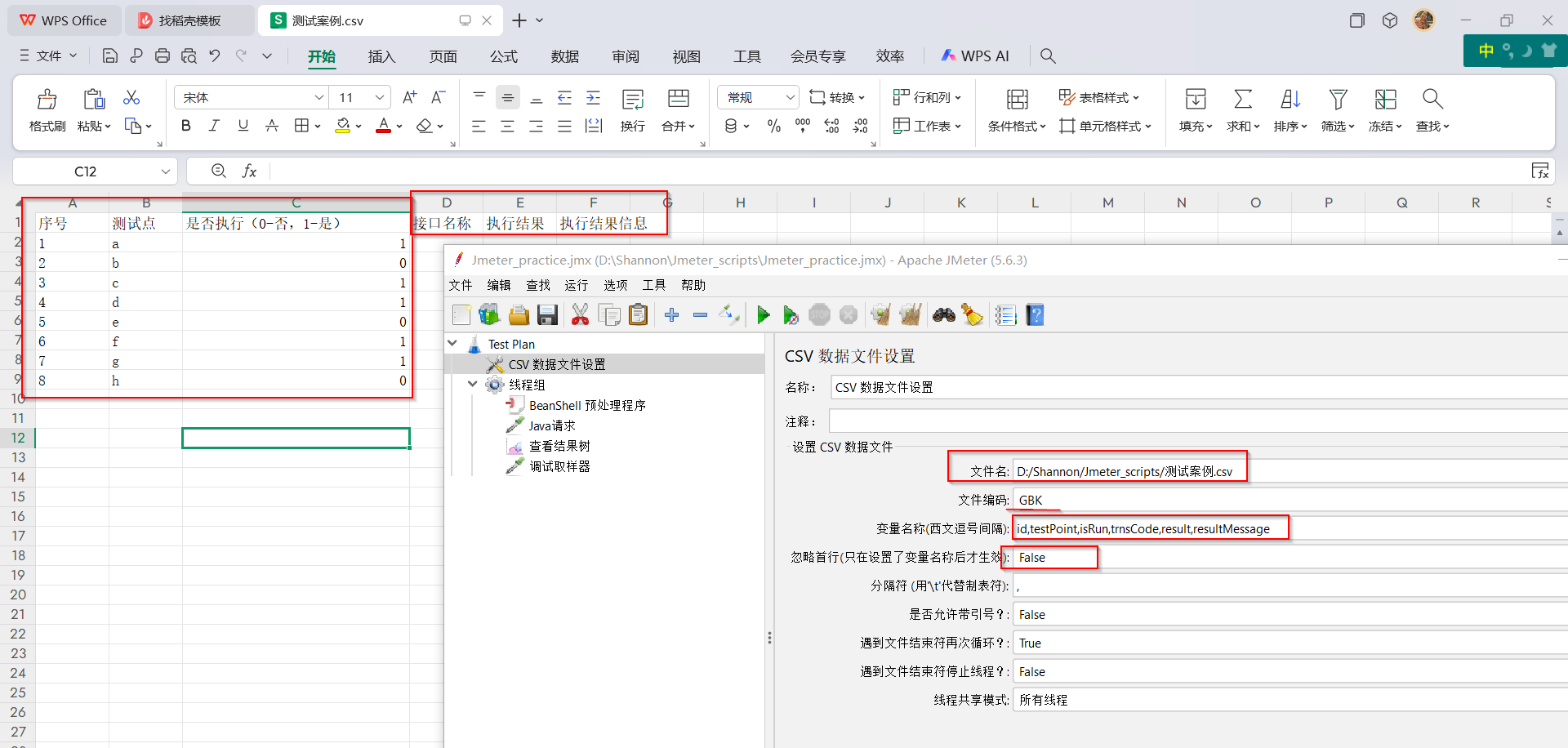
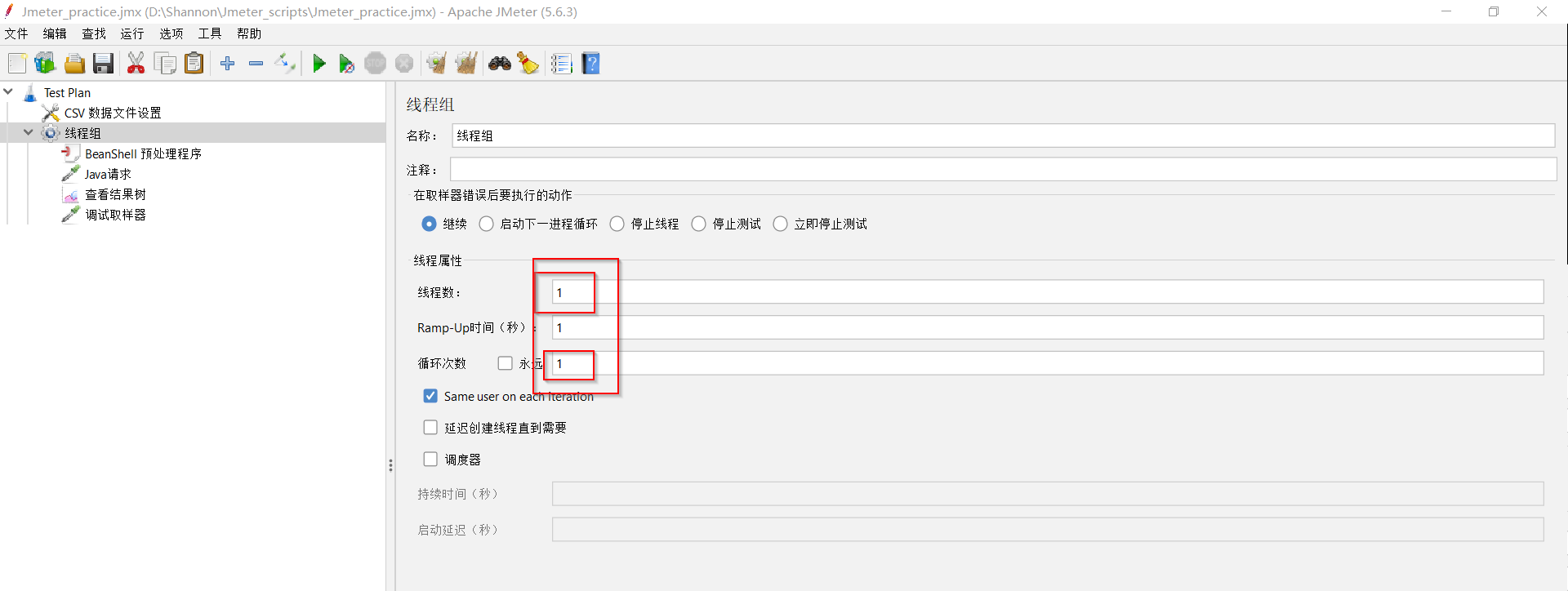
(2)添加【线程组】组件,且保持默认参数设置
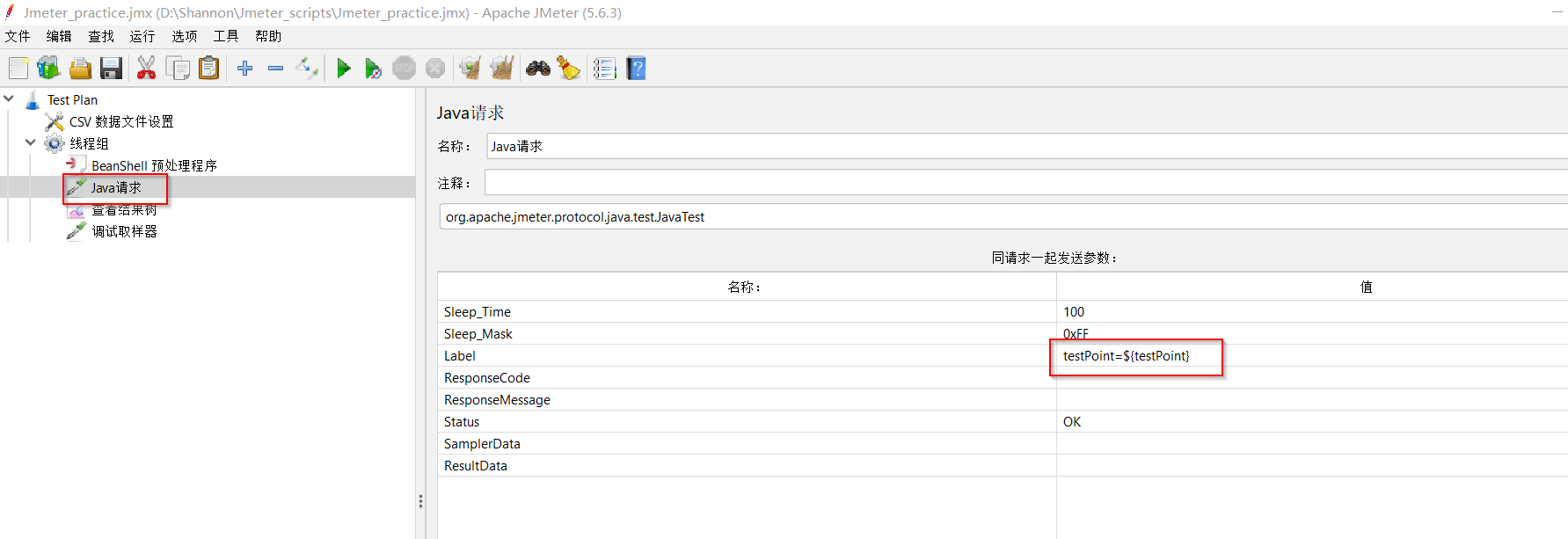
(3)使用【Java请求】组件(一个测试用组件)读取「测试案例」文件中的testPoint变量值
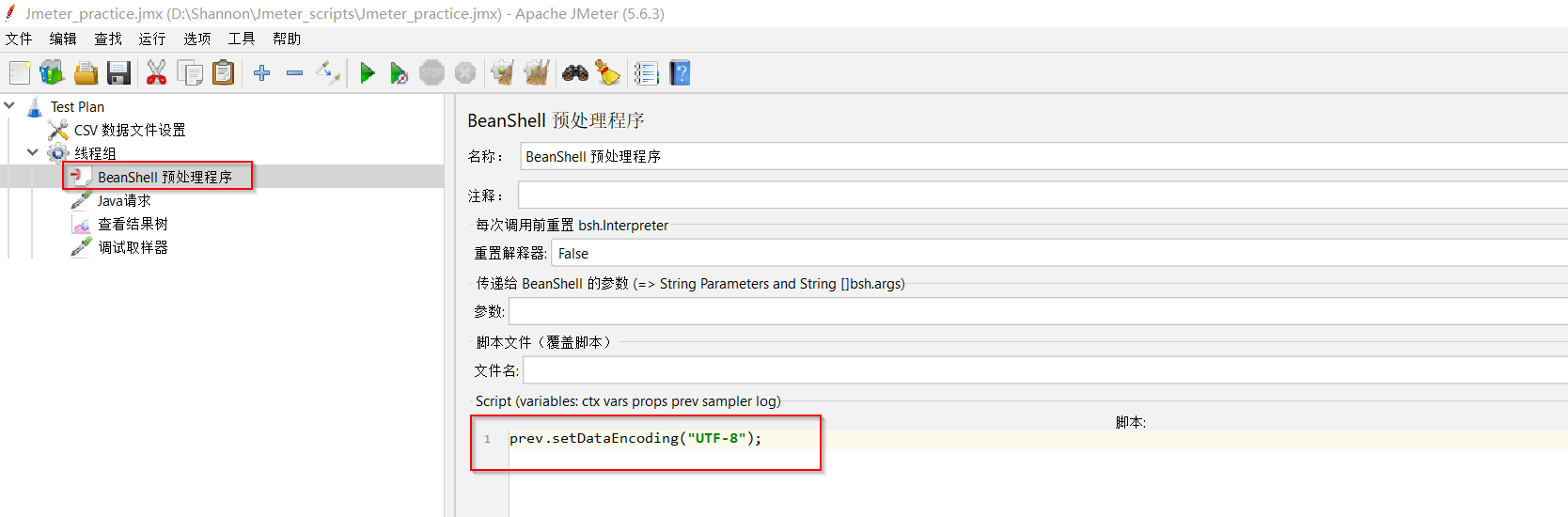
(4)使用【BeanShell预处理】组件(前置处理器)设置同级各组件输出结果的编码格式
(5)使用【调试取样器】读取每条测试案例的参数值

(6)使用【察看结果树】组件查看脚本执行结果
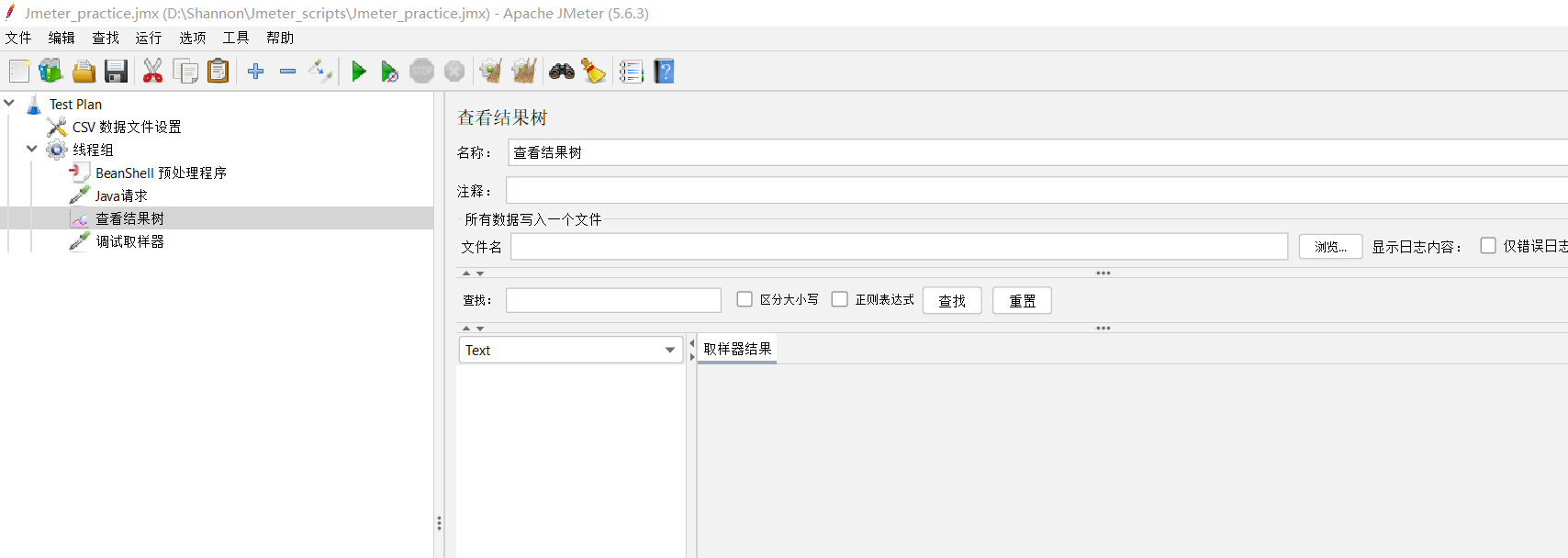
2、看执行情况 - 从CSV读取到的数据全部乱码
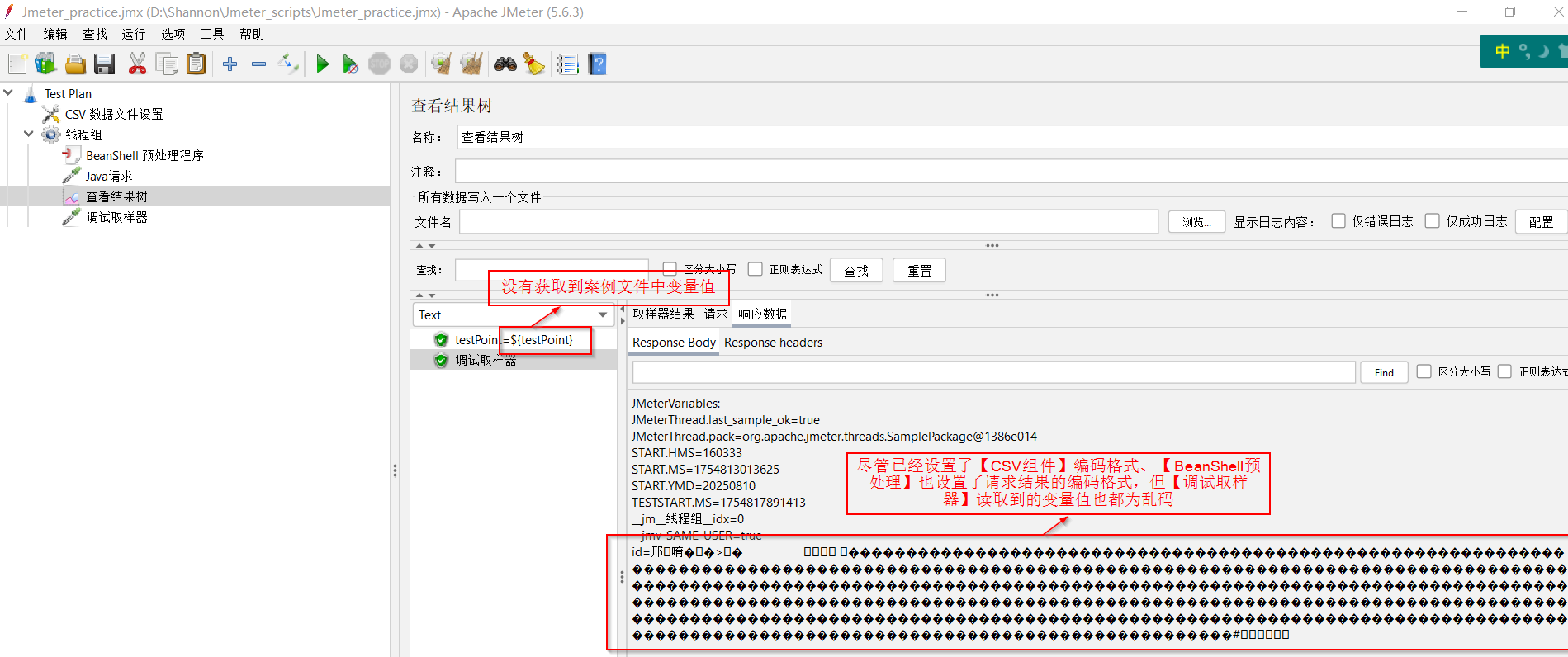
3、分析请教
1 【Deep Seek 深情解答】
2 您遇到的 CSV 变量乱码问题通常是由多个环节的编码设置不一致造成的。以下是系统化的解决方案:
3
4 ### 问题根源分析
5 1. **CSV 文件实际编码**:文件可能保存为 ANSI/GBK 而非 UTF-8
6 2. **CSV 组件读取编码**:未显式指定读取编码
7 3. **JMeter 变量处理**:变量在传递过程中编码不一致
8 4. **调试取样器显示**:结果树未正确识别编码
9
10 ### 完整解决方案
11
12 #### 第一步:确认并转换 CSV 文件编码
13 1. 用记事本打开 CSV 文件 → 另存为 → 选择 **UTF-8** 编码保存
14 
15 2. 推荐使用专业工具验证:
16 ```bash
17 # 使用 file 命令检查编码 (Linux/Mac)
18 file -i your_data.csv
19
20 # 预期输出:charset=utf-8
21 ```
22
23 #### 第二步:正确配置 CSV 数据文件组件
24 在 CSV Data Set Config 中:
25 ```properties
26 Filename: /path/to/your_data.csv
27 File Encoding: UTF-8 # 必须显式设置
28 Variable Names: col1,col2
29 ```
30 
31
32 #### 第三步:添加编码转换后置处理器 (JSR223 + Groovy)
33 在 HTTP 请求后添加 **JSR223 PostProcessor**:
34 ```groovy
35 // 强制转换所有CSV变量为UTF-8
36 vars.entrySet().each { entry ->
37 def rawValue = entry.getValue()
38 if (rawValue instanceof byte[]) {
39 vars.put(entry.getKey(), new String(rawValue, "UTF-8"))
40 } else {
41 // 处理字符串类型变量
42 byte[] bytes = rawValue.getBytes("ISO-8859-1") // 先转回原始字节
43 vars.put(entry.getKey(), new String(bytes, "UTF-8"))
44 }
45 }
46 ```
47
48 #### 第四步:调试取样器显示优化
49 在 **View Results Tree** 中:
50 1. 选择调试取样器结果
51 2. 顶部下拉菜单选择 **UTF-8** 编码
52 
53
54 #### 第五步:JMeter 启动脚本永久设置 (推荐)
55 修改 `jmeter.bat`/`jmeter.sh` 启动脚本:
56 ```diff
57 # 在HEAP设置后添加编码参数
58 :SET_HEAP
59 set HEAP=-Xms1g -Xmx2g
60 + set JVM_ARGS=%JVM_ARGS% -Dfile.encoding=UTF-8
61 ```
62
63 ### 验证流程
64 1. 添加 **Debug Sampler** 查看原始变量值
65 2. 在需要的位置添加以下代码打印日志:
66 ```groovy
67 // JSR223 Sampler 验证
68 log.info("=== CSV 变量验证 ===");
69 vars.entrySet().each {
70 log.info(it.getKey() + " = " + it.getValue());
71 }
72 ```
73 3. 检查控制台日志(日志本身需确保UTF-8输出)
74
75 ### 常见陷阱排查
76 1. **BOM 头问题**:用 Notepad++ 打开 CSV → 编码 → 转为 UTF-8 无 BOM
77 2. **操作系统语言干扰**:
78 ```properties
79 # 在 user.properties 中添加
80 sampleresult.default.encoding=UTF-8
81 jsyntaxtextarea.encoding=UTF-8
82 ```
83 3. **数据库源数据问题**:如果 CSV 来自数据库,确保导出时指定 UTF-8
84
85 ### 替代方案:使用函数转换
86 在需要的地方直接使用:
87 ```java
88 ${__changeEncoding(${your_var},ISO-8859-1,UTF-8)}
89 ```
90
91 > 通过以上步骤,99% 的 CSV 乱码问题都能解决。重点检查 **文件真实编码** 和 **CSV组件的显式编码设置**,配合启动参数可彻底解决问题。
4、调试&解决
Jmeter脚本里,CSV和BeanShell组件里的编码格式排列组合后,仍然乱码,因此推测,问题还是出在CSV文件本身的真实编码上
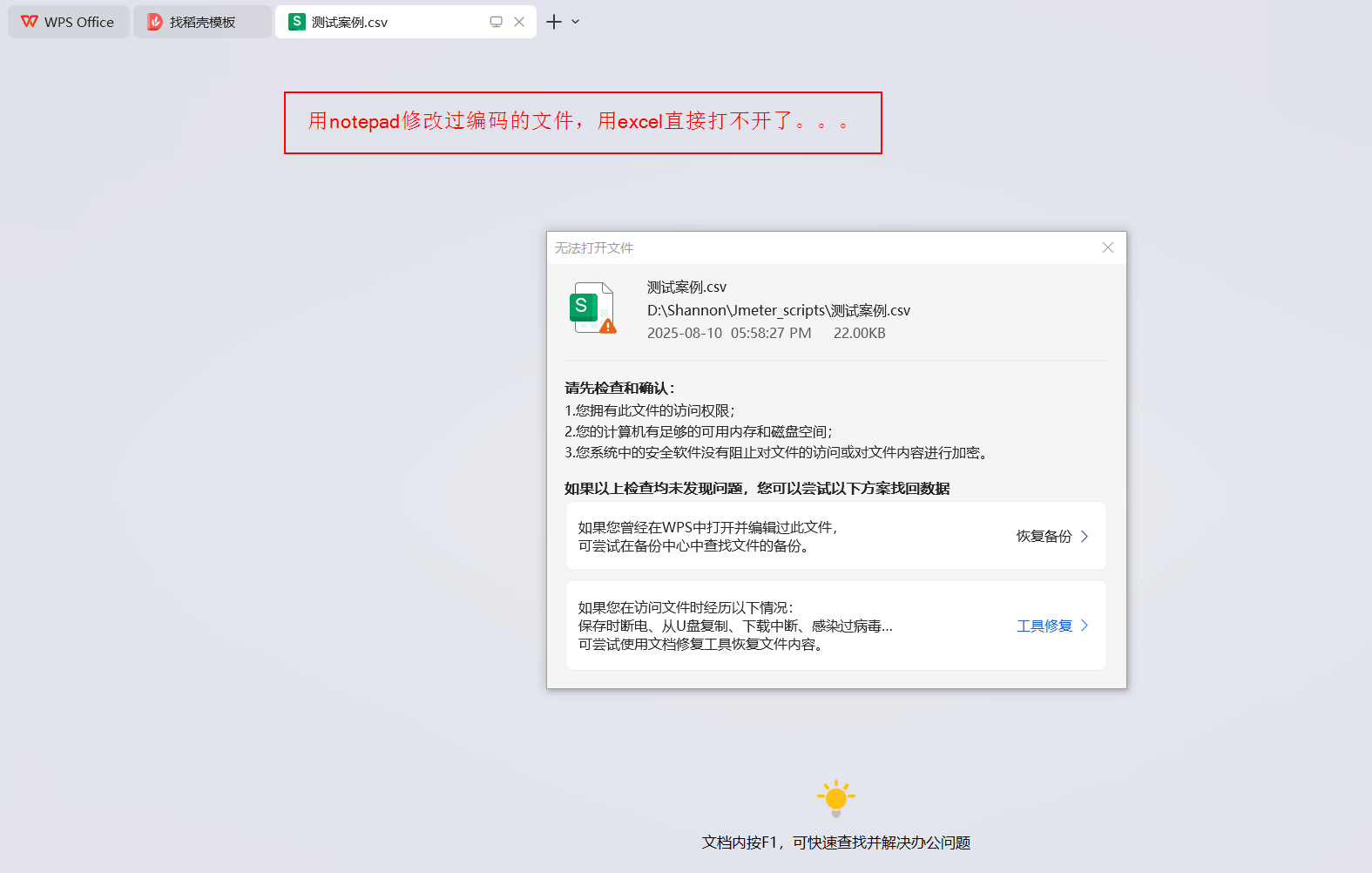
(1) 尝试DS给的第一个方法 - 修改CSV文件的编码
—— 用记事本打开 CSV 文件 → 另存为 → 选择 **UTF-8** 编码保存,发现问题没有得到解决,且结果更糟糕了:



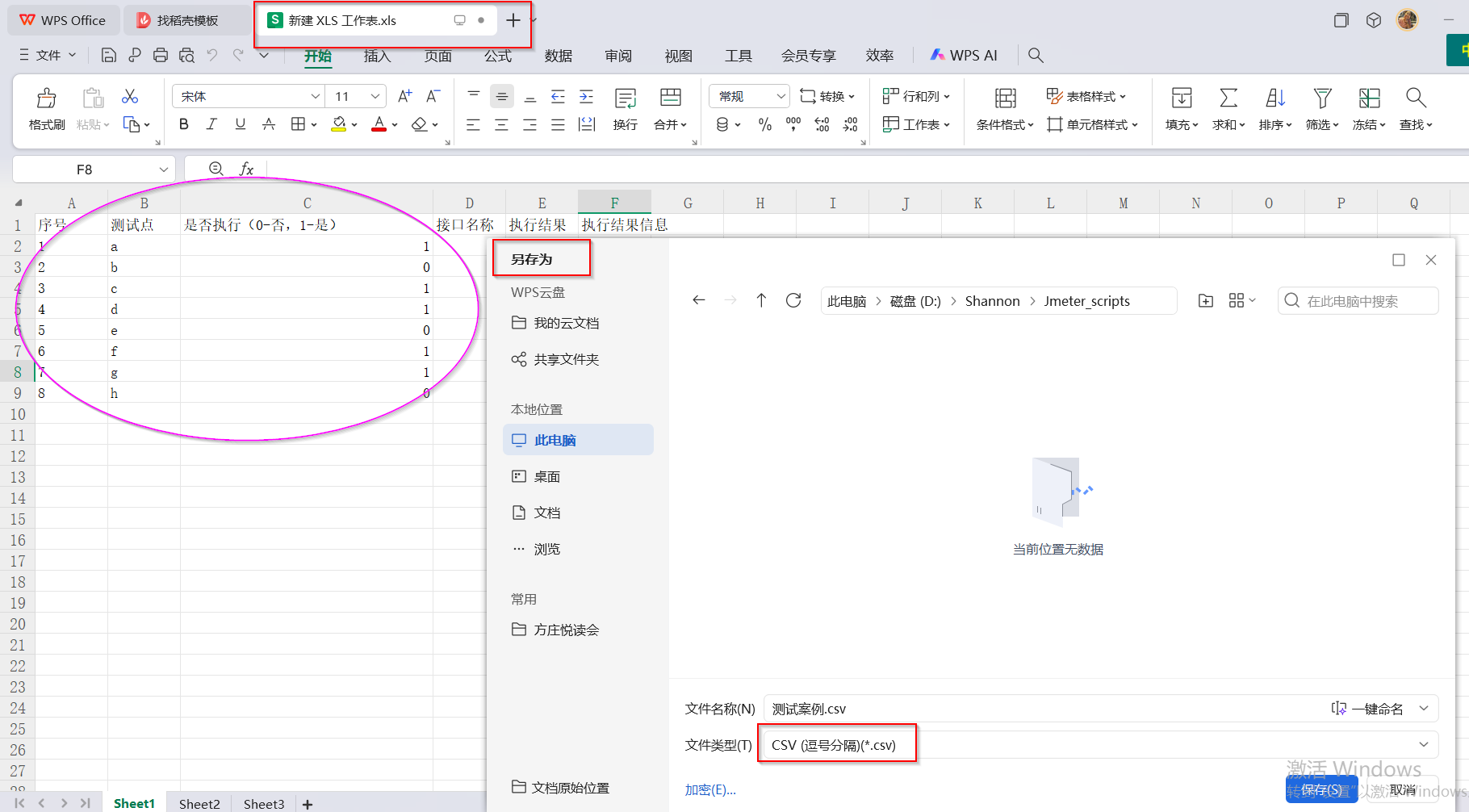
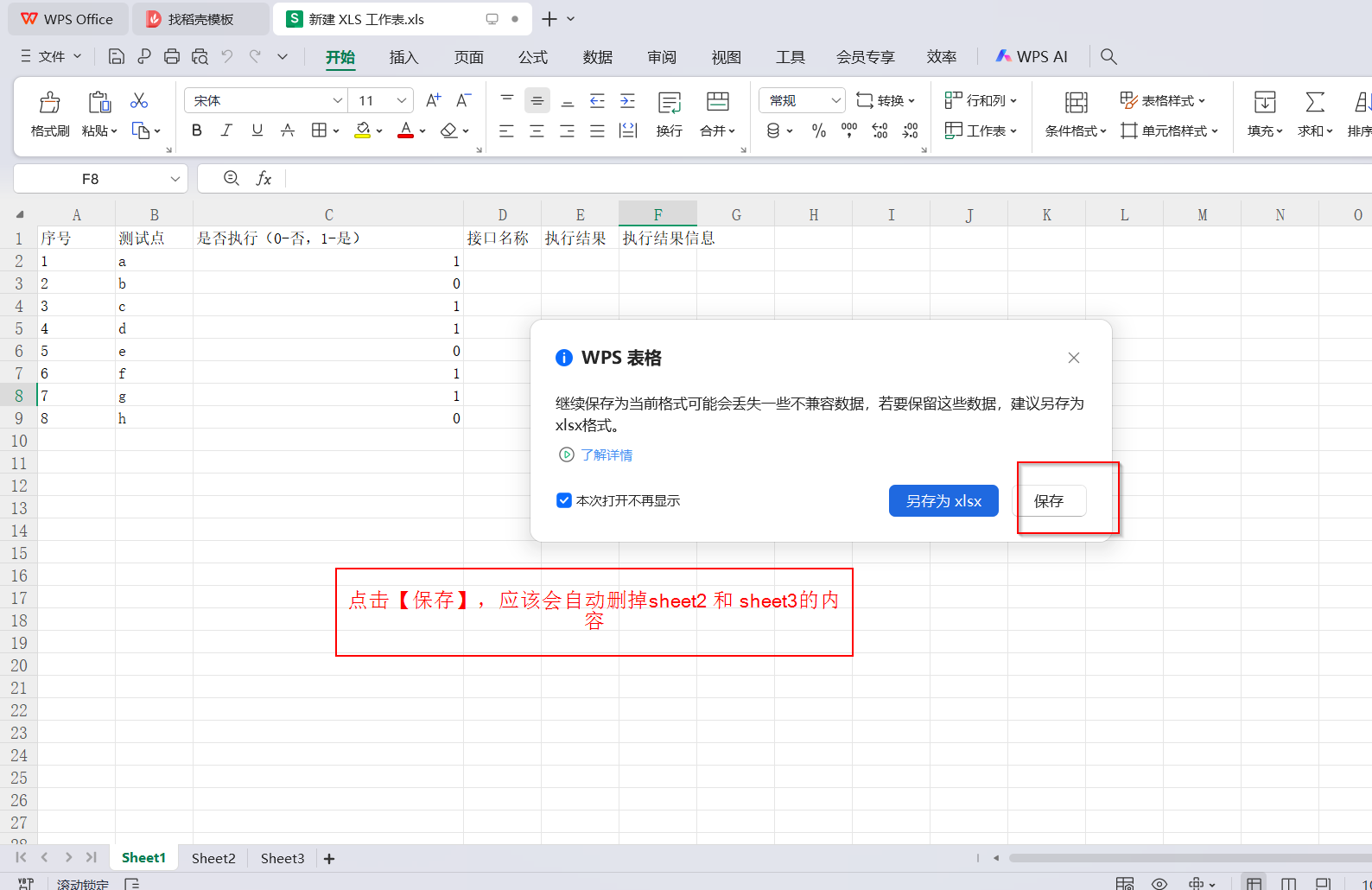
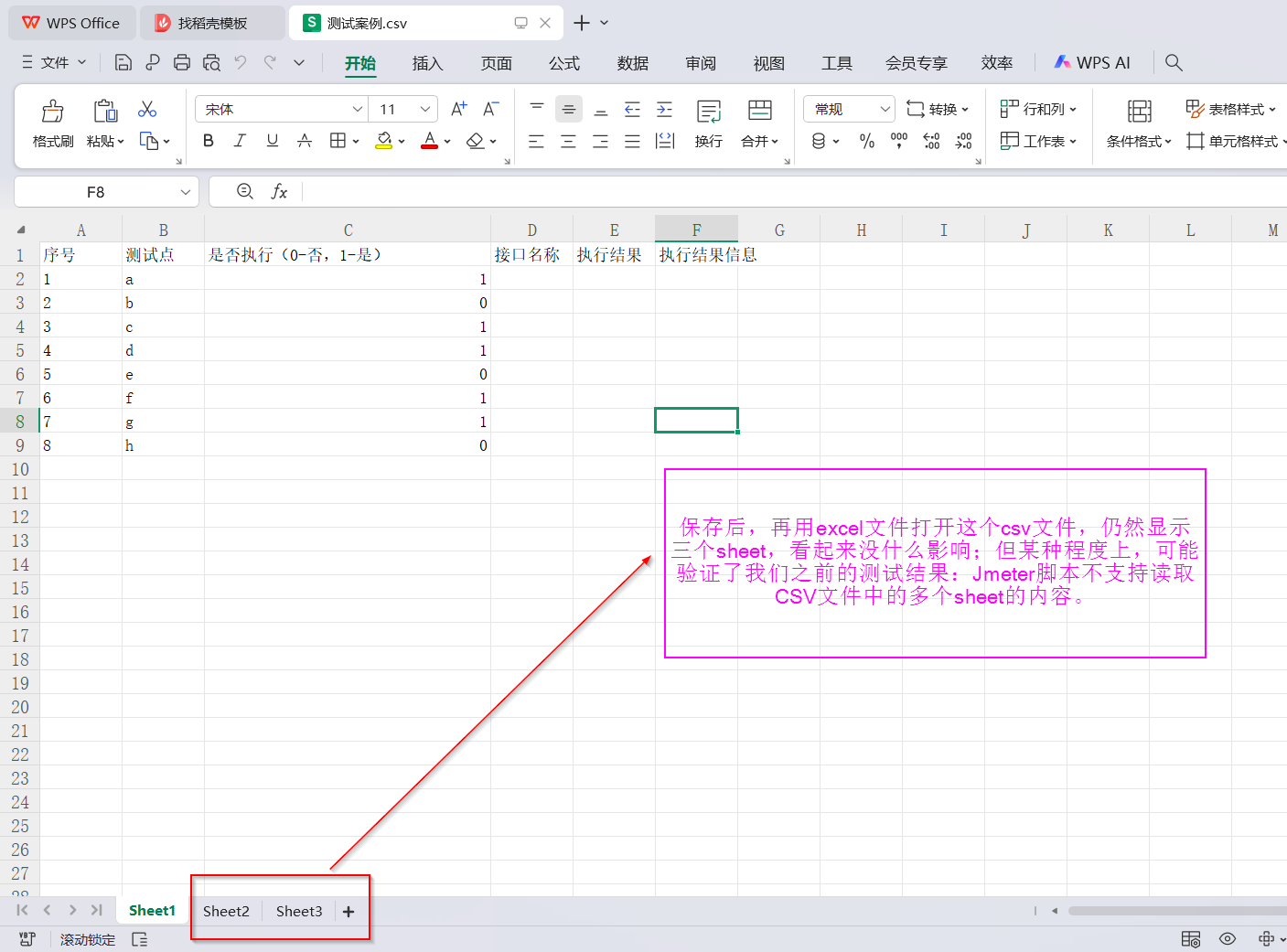
(2)重新创建.xls文件,并通过 文件->另存为 .csv文件的方式 —— 问题解决啦!!!
——回想了一下,这个CSV文件是由我创建的.xls文件经内容编辑后,重命名并修改后缀名得来的,可能问题就出在这里

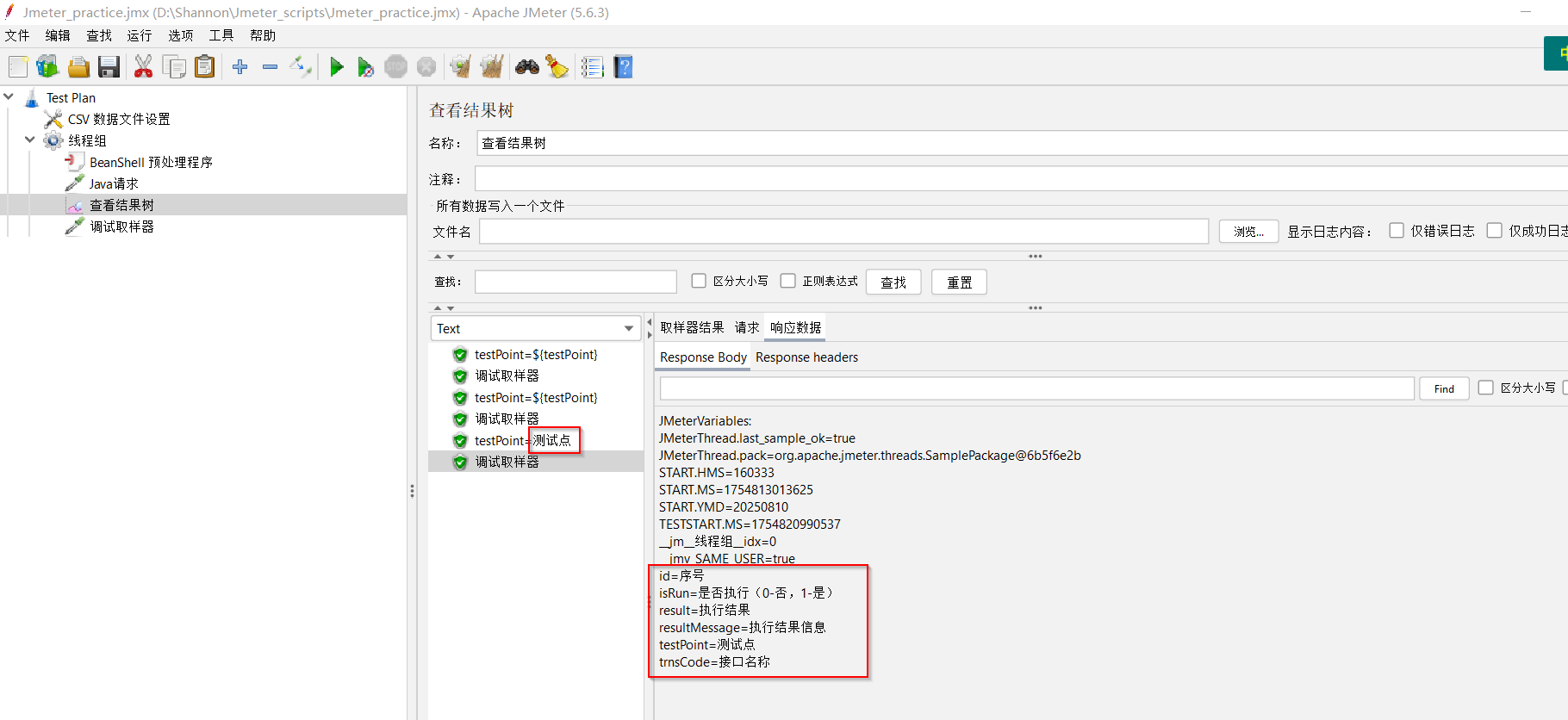
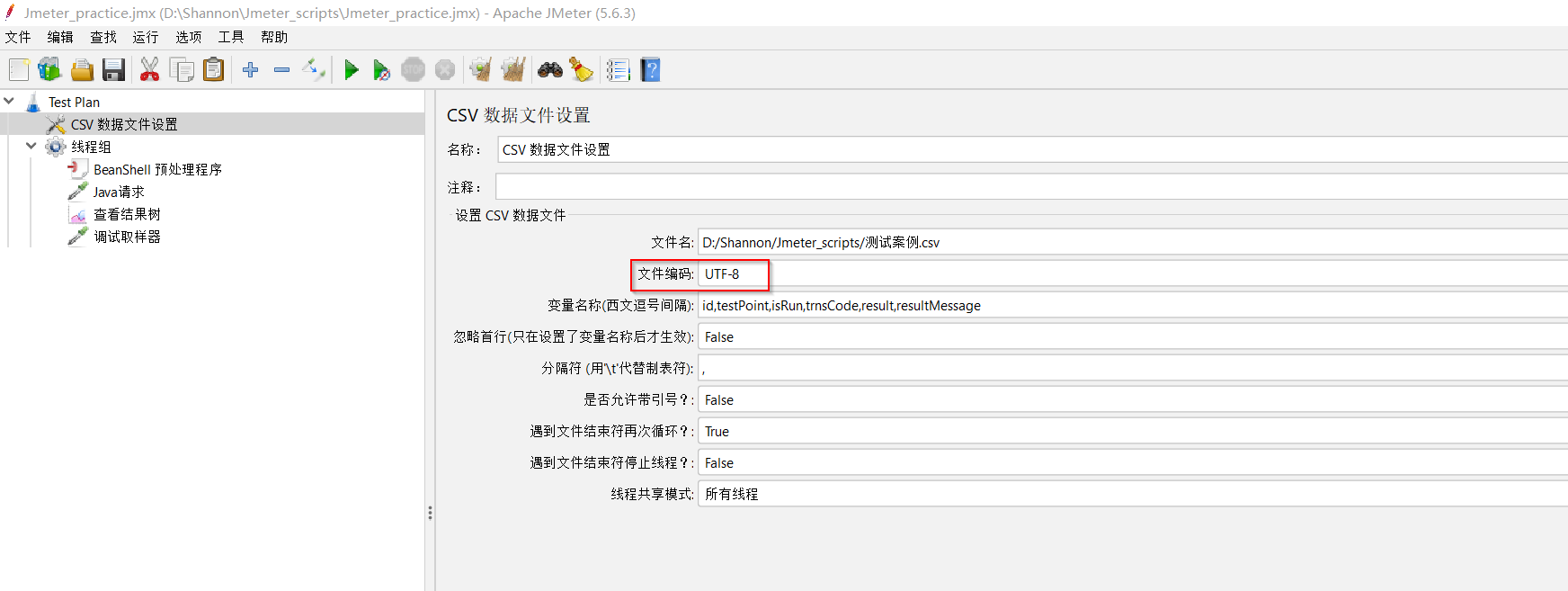
(3)继续尝试 —— 将【CSV数据文件配置】配置中的“文件编码”改为“UTF-8”,发现,结果又乱码了
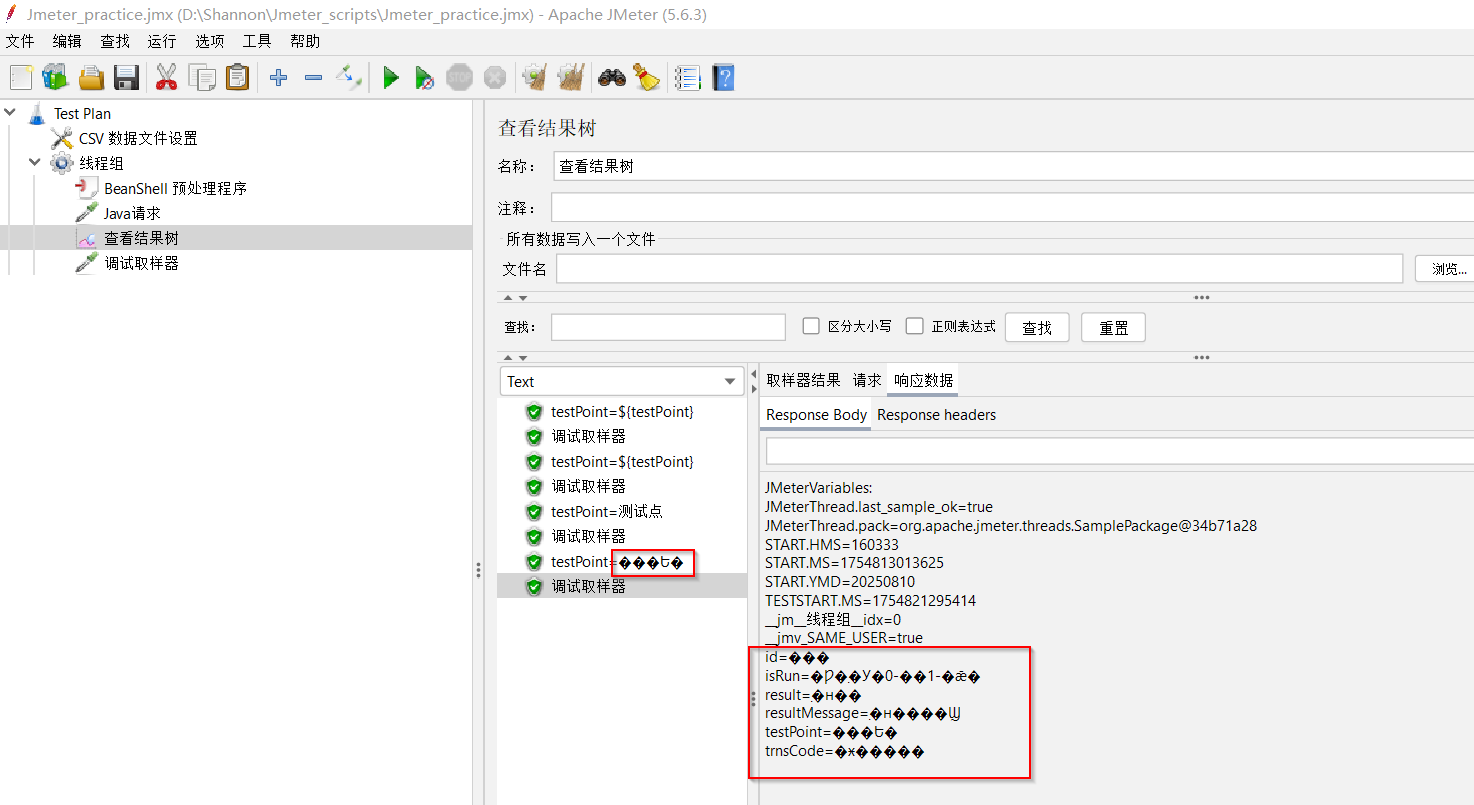
(4)甚至再继续将BeanShell中的编码格式改为 GBK也不好使 —— ![image]()

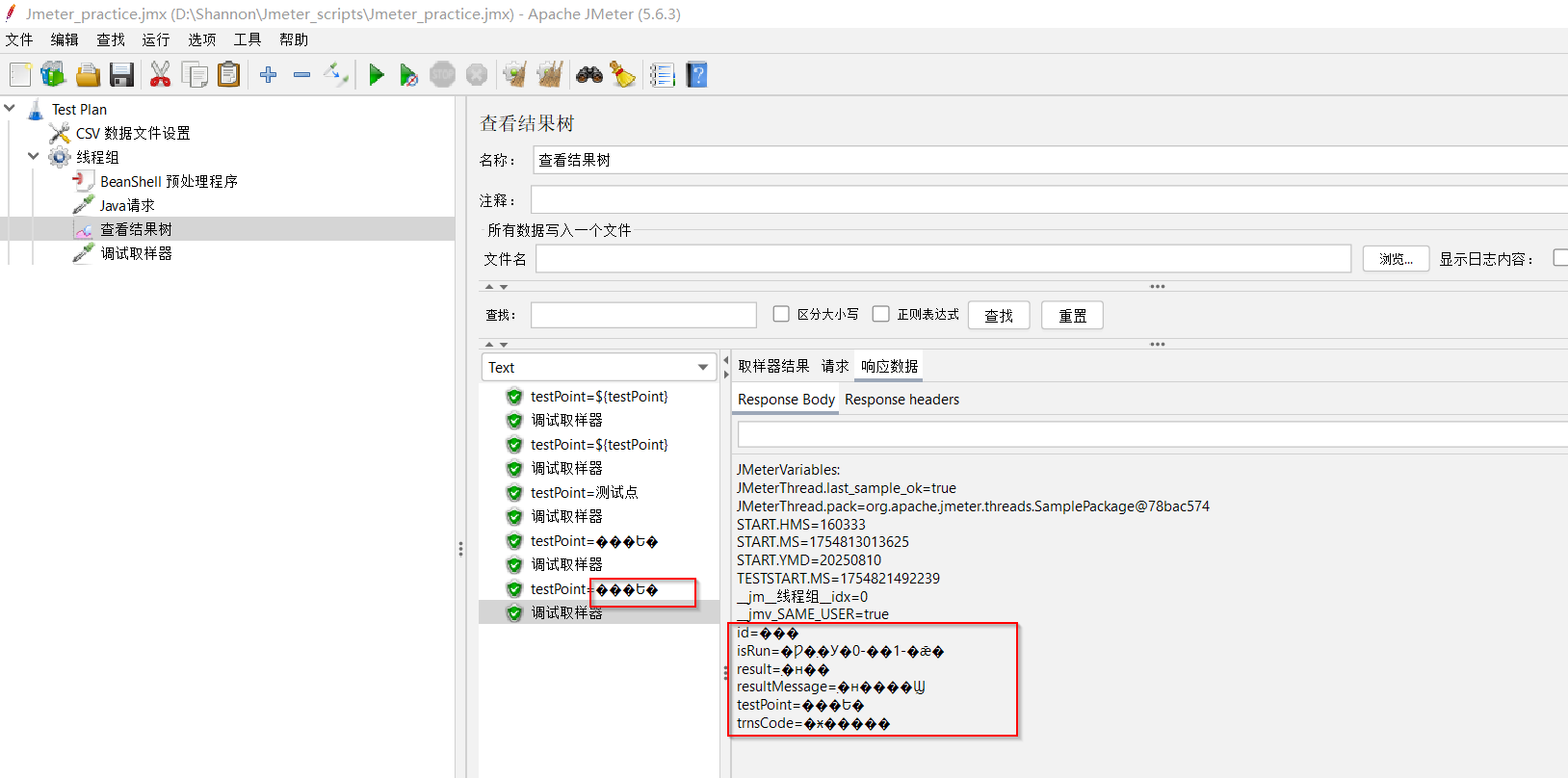
(5)将【CSV数据文件配置】配置中的“文件编码”改回“GBK”,再把BeanShell中的编码格式也改为 “GBK”怎么样呢 —— Okay的哟!!!



(6)将【CSV数据文件配置】配置中的“文件编码”改回“GBK”,直接把BeanShell组件删掉怎么样呢??? —— 竟然完全没问题!!!
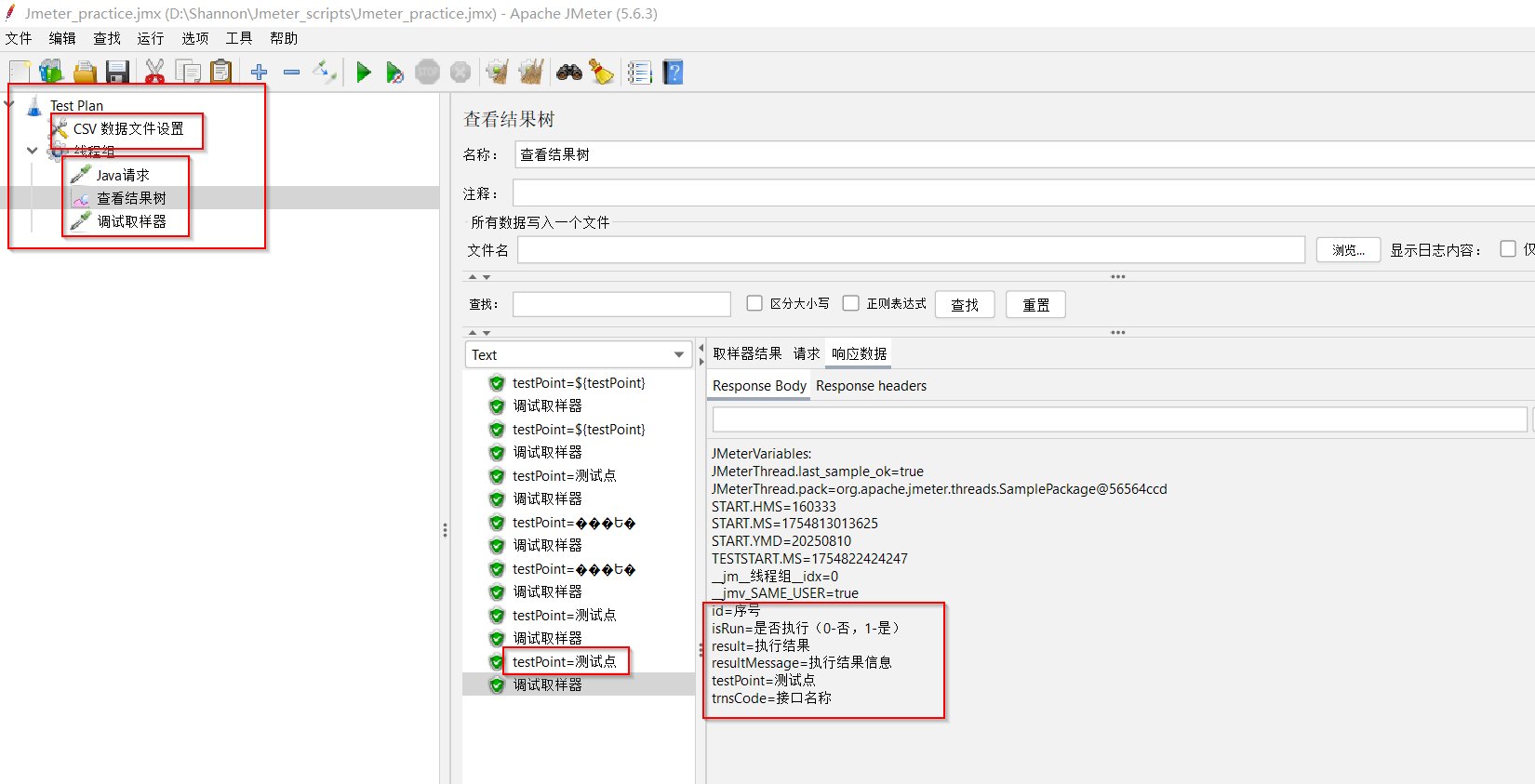
总结
为确保Jmeter脚本中的引入的CSV参数文件内容读取不乱码,有以下关键操作及配置供参考——
1. CSV文件的创建,尽量采用如下步骤:新建excel工作表 -> 输入文件内容 -> 文件 -> 另存为 -> 选择.csv后缀格式文件;
2. Jmeter的【CSV数据文件配置】组件参数中“文件编码” ,尽量选择“GBK” (目前的验证结果,UTF-8 会导致读取乱码);
3. Jmeter脚本中,是否通过【BeanShell预处理程序】组件为请求组件设置编码格式,目前验证结果,没影响,所以宝子们可以随意啦!~
呛呛!~ 今天的Jmeter踩坑博客就到这里啦!~ 日拱一卒,功不唐捐!~ 山遥路远,行则将至!~ 与亲爱、可爱的诸君共勉 ღ( ´・ᴗ・` )比心
下期预告
我们将 对 【CSV数据文件配置】CSV文件参数读取与【线程组】组件的线程数关系进行一番梳理!~
posted on 2025-08-10 18:51 Shannon_Zhang 阅读(252) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号