R 基于朴素贝叶斯模型实现手机垃圾短信过滤
# 读取数数据, 查看数据结构
df_raw <- read.csv("sms_spam.csv", stringsAsFactors=F)
str(df_raw)
length(df_raw$type)
# 将数据分为特征值矩阵 X 和 类标向量y 两部分,将 y 换为因子
X <- df_raw$text
y <- factor(df_raw$type)
length(y)
# 查看类标向量 y 的结构和组成
str(y)
table(y)
# 安装和加载文本挖掘包
#install.packages("tm")
library(NLP)
library(tm)
# 创建语料库
X_corpus <- VCorpus(VectorSource(X))
######## 1 清洗文本数据 ########
# 1.1 将文本中的字母转换为小写
X_corpus_clean <- tm_map(X_corpus, content_transformer(tolower))
# 1.2 去除文本中的数字
X_corpus_clean <- tm_map(X_corpus_clean, removeNumbers)
# 1.3 去除文本中的停用词
X_corpus_clean <- tm_map(X_corpus_clean, removeWords, stopwords())
# 1.4 去除文本中的标点符号
X_corpus_clean <- tm_map(X_corpus_clean, removePunctuation)
# 添加包
#install.packages("SnowballC")
library(SnowballC)
# 1.5 提取文本中每个单词的词干
X_corpus_clean <- tm_map(X_corpus_clean, stemDocument)
# 1.6 删除额外的空白
X_corpus_clean <- tm_map(X_corpus_clean, stripWhitespace)
# 1.7 将文本文档拆分成词语, 创建文档——单词矩阵
X_dtm <- DocumentTermMatrix(X_corpus_clean)
############# 2 准备输入数据 #############
# 2.1 划分训练数据集和测试数据集
X_dtm_train <- X_dtm[1:4169, ]
X_dtm_test <- X_dtm[4170:5559, ]
y_train <- y[1:4169]
y_test <- y[4170:5559]
# 说明:因为原始数据 df_raw 是随机选取的,所以可以直直接去前 75% 的数据为测试数据
# 2.2 检查样本分分布是否偏斜
prop.table(table(y_train))
prop.table(table(y_test))
# 2.3 过滤 DTM, 选取频繁出现的单词
X_freq_words <- findFreqTerms(X_dtm_train, 5) # 此处可以试错调整,以调节模型的性能
# 过滤 DTM
X_dtm_train_freq <- X_dtm_train[, X_freq_words]
X_dtm_test_freq <- X_dtm_test[, X_freq_words]
# 2.4 将矩阵文本编码为数值
# 2.4.1定义一个变量转换函数
convert_counts <- function(x) {
x <- ifelse(x > 0, "Yes", "No")
}
# 2.4.2 转换训练矩阵和测试矩阵
X_train <- apply(X_dtm_train_freq, MARGIN=2, convert_counts)
X_test <- apply(X_dtm_test_freq, MARGIN=2, convert_counts)
############# 3 基于数据训练模型 ############
# install.packages("e1071")
library(e1071)
# 训练模型, 拉普拉斯估计参数默认为 0
NB_classifier <- naiveBayes(X_train, y_train)
############## 4 评估模型的性能 #############
# 4.1 对测试集中的样本进行预测
y_pred <- predict(NB_classifier, X_test)
# 比较预测值和真实值
# library(gmodels)
CrossTable(x=y_test, y=y_pred,
prop.chisq = F, prop.t = F, prop.c = F,
dnn = c("actural", "predict"))
模型 NB_classifier 在测试集上进行预测的混淆矩阵为:
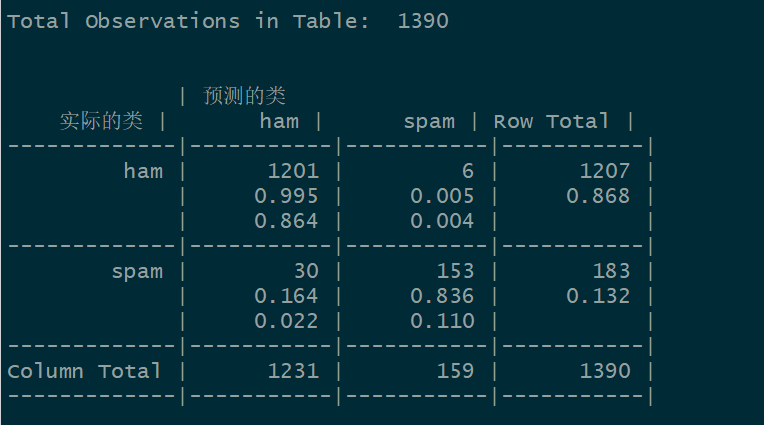
准确率 = 0.864 + 0.110 = 0.974
对模型调参
################## 5 提高模型的性能 ##################
# 5.1 添加拉普拉斯估计,训练模型
NB_classifier2 <- naiveBayes(x = X_train, y = y_train, laplace = 1)
# 5.2 对测试集中的样本进行预测
y_pred2 <- predict(NB_classifier2, X_test)
# 5.3 比较预测值和真实值
CrossTable(x = y_test, y = y_pred2,
prop.chisq = F, prop.t = T, prop.c = F,
dnn = c("actural", "predict"))
经过参数调优后的模型 NB_classifier2 在测试集上进行预测的混淆矩阵为:
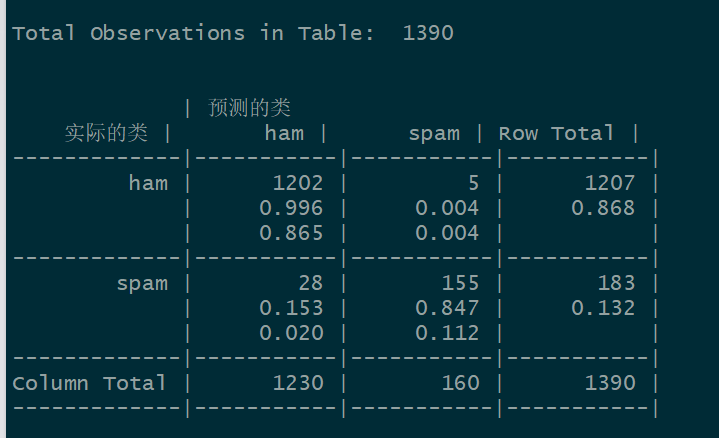
准确率 = 0.865 + 0.112 =0.977
按语:
经过拉普拉斯估计参数的调节,模型准确率有 0.974 提高至 0.977,在高准确的前提下能有提升,实属不易。
非学无以广才,非志无以成学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号