借助 scikit-learn 的 OneHotEncoder 类实现特征值上的独热编码
说明:如果要编码的特征值是分类数据,用 LabelEncoder 类直接编码就可以。进行独热编码的数据一般是顺序型数据,这类数据的原始形式一般是字符串。在进行独热编码之前,应先将映射为数值(这在 SPSS 和 R 语言中极易实现)。
示例
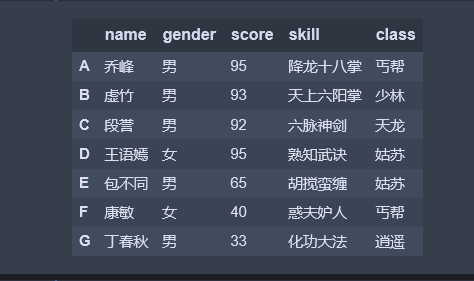
1、创建一个示例数据集
import pandas as pd df = pd.DataFrame([['乔峰', '男', 95, '降龙十八掌', '丐帮'], ['虚竹', '男', 93, '天上六阳掌', '少林'], ['段誉', '男', 92, '六脉神剑', '天龙'], ['王语嫣', '女', 95,'熟知武诀', '姑苏'], ['包不同', '男', 65, '胡搅蛮缠', '姑苏'], ['康敏', '女', 40, '惑夫妒人', '丐帮'], ['丁春秋','男', 33, '化功大法','逍遥']], index=list('abcdefg'.upper()), columns=['name', 'gender', 'score', 'skill', 'class']) df
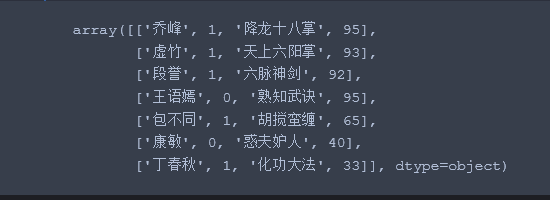
2、将 gender 映射为数值
from sklearn.preprocessing import LabelEncoder X = df[['name', 'gender', 'skill', 'score']].values class_le = LabelEncoder() X[:, 1] = class_le.fit_transform(X[:, 1]) X
3、对 gender 进行独热编码
from sklearn.preprocessing import OneHotEncoder ohe = OneHotEncoder(categorical_features=[0]) ohe.fit_transform(X[:,[1]]).toarray()

非学无以广才,非志无以成学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号