

test学习
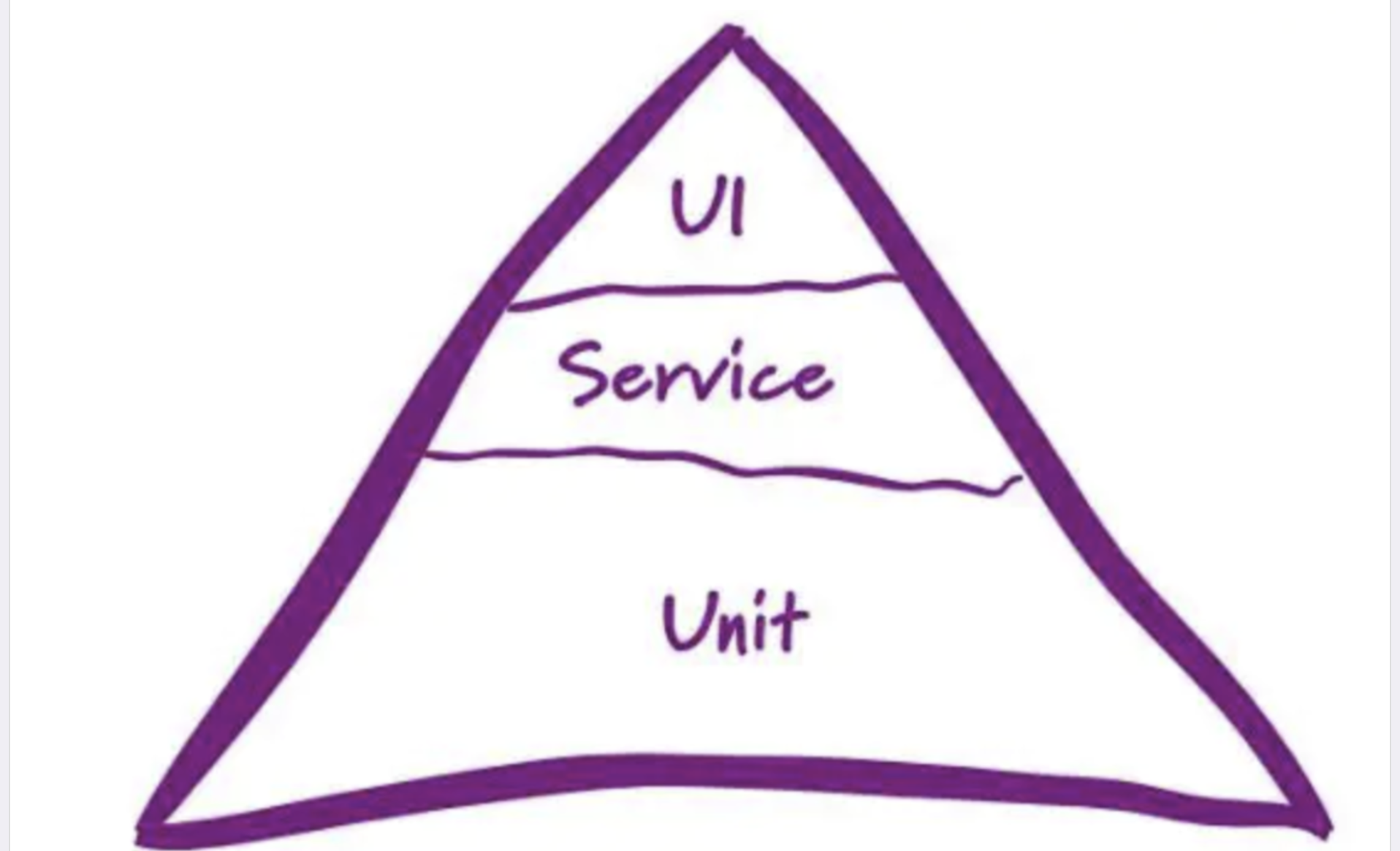
测试的金字塔模型
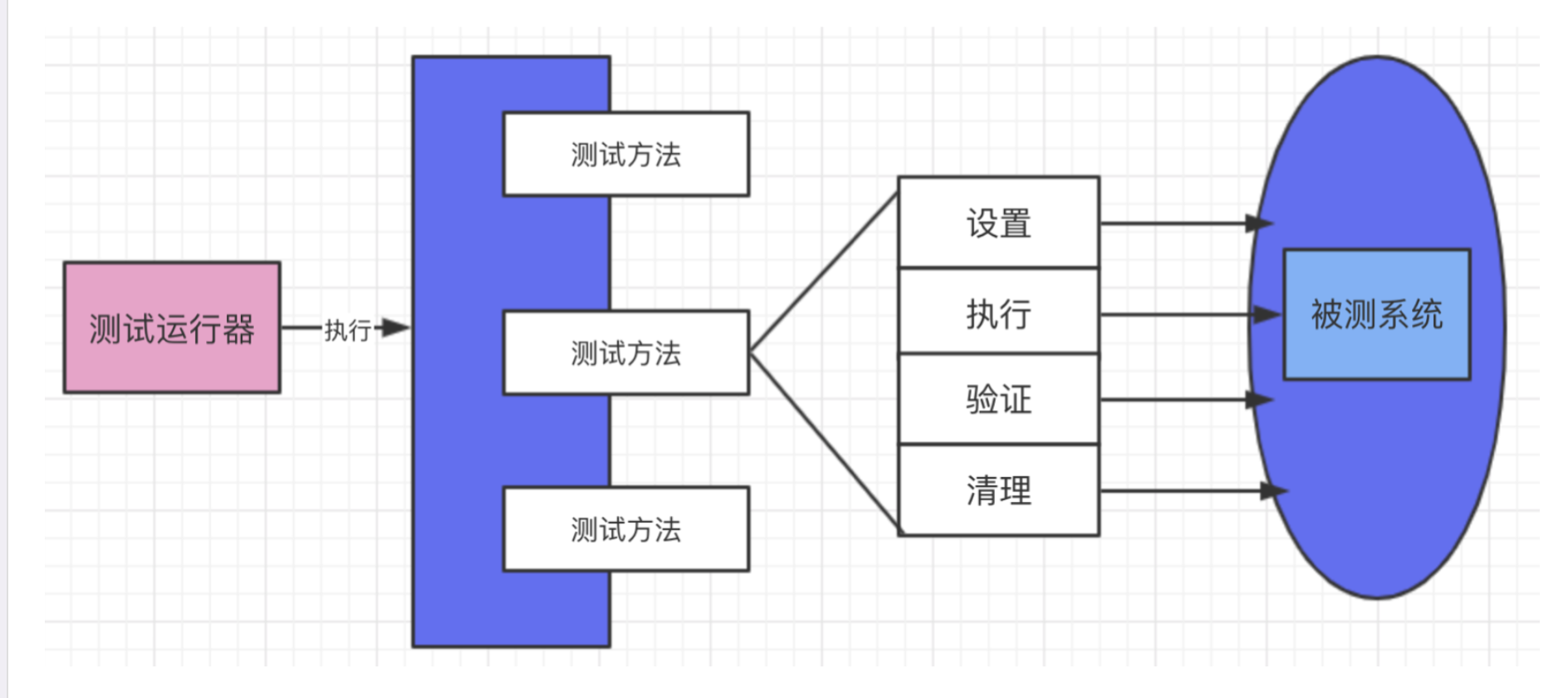
白盒测试的概念
import unittest #导入test的库
关于测试的几个概念
测试用例:就是测试类里面编写的测试方法
测试套件:就是测试用例的集合,在一个测试套件可以有很多的测试用例,它的英文单词是TestSuite
测试执行:TestRunner,执行测试套件或者测试用例
测试报告:TestReport,就是执行所有测试用例后的结果信息
在test中的断言是使用
assertEqual():比较的是两个对象的==关系
assertIn():比较的是两个对象的包含关系
assertIs():比较两个字符串的内存地址
assertTrue()断言为真 assertFalse()断言为假
类测试固件:不建议使用 @classmethod def setUpClass(cls) -> None: cls.driver=webdriver.Chrome() cls.driver.maximize_window() cls.driver.get('http://www.baidu.com') cls.driver.implicitly_wait(30) @classmethod def tearDownClass(cls) -> None: cls.driver.quit()
import unittest class Testsina(unittest.TestCase): def setUp(self) -> None: self.deriver=webdriver.Chrome() self.deriver.maximize_window() self.deriver.get('https://mail.sina.com.cn/') self.deriver.implicitly_wait(10) def tearDown(self) -> None: self.deriver.quit() #测试固件的编写
3,测试固件的参数化
当我们需要重复进行测试固件的编写的时候,我们可以通过创建一个新的类,将测试固件当作这个类的方法来实现代码的简便化
from selenium import webdriver import unittest class Init(unittest.TestCase): def setUp(self) -> None: self.driver=webdriver.Chrome() self.driver.maximize_window() self.driver.get('http://www.baidu.com') self.driver.implicitly_wait(10) def tearDown(self) -> None: self.driver.quit()
在真正需要写测试用例的时候,直接套用参数化后的测试固件
import unittest from selenium.webdriver.common.by import By from selenium import webdriver import time as t from test.init import Init class Testbaidu(Init): self.driver.具体操作
测试参数化
pip install parameterized
在unittest测试框架中,参数化需要借助第三方的库parameterized
from parameterized import parameterized,param #引入第三方的库,主要目的是实现测试参数化
def tearDown(self) -> None: self.deriver.quit() @parameterized.expand([ param("","","请输入邮箱名"), param("asda","asdad","您输入的邮箱名格式不正确"), param("asdad@sina.com","sadas","登录名或密码错误") ]) def test_username_password_erro(self,username,password,result): self.deriver.find_element(By.ID,'freename').send_keys(username) self.deriver.find_element(By.ID, 'freepassword').send_keys(password) self.deriver.find_element(By.LINK_TEXT, '登录').click() t.sleep(3) so = self.deriver.find_element(By.XPATH,'/html/body/div[3]/div/div[2]/div/div/div[4]/div[1]/div[1]/div[1]/span[1]') self.assertEqual(so.text, result)
测试报告
测试报告:unittest生成测试报告需要借助第三方的库HtmlTestRunner.py的文件,此文件需要放在python3的lib目录下.
import unittest import os import HTMLTestRunner #导入测试报告的库
测试报告模块的代码
def tests(): """获取要执行的测试模块""" suite=unittest.TestLoader().discover( #start_dir指的是测试模块的路径 start_dir=os.path.dirname(__file__), #pattern指的是通过正则方法加载所有的测试模块 pattern='test_*py') return suite
测试报告的输出
def run(): filename=os.path.join(os.path.dirname(__file__),"report","index.html")
#创建测试报告的储存路径 fp=open(filename,"wb")
#通过二进制的写法,将测试用写入fp runner=HTMLTestRunner.HTMLTestRunner( stream=fp,
#通过数据流的方式写入 title='自动化测试',
#测试报告的title description='ui test'
#测试报告的说明
) runner.run(tests())
if __name__ == '__main__':
run()
#运行测试报告

 浙公网安备 33010602011771号
浙公网安备 33010602011771号