【python大数据分析课程设计】大数据分析——不同条件下对青少年成绩的影响
一、选题背景
随着社会的发展和教育的普及,越来越多的青少年参与到学习中。学生成绩是评价学生学习成果和学习能力的重要标志,而学习成绩的影响因素是一个复杂的系统工程。为了更好地了解和分析青少年学习成绩的影响因素,需要进行大数据分析来探索不同条件下对青少年成绩的影响。
目标:
-
对教育决策的参考价值:通过分析不同条件下对青少年成绩的影响,可以为教育决策提供重要的参考。教育部门可以根据分析结果,有针对性地制定教育政策和改进教育教学方法,以提高青少年的学习成绩和学习效果。
-
个性化教育的实施依据:不同条件下对青少年成绩的影响分析可以揭示个体差异和特殊需求,为个性化教育提供依据。通过了解不同因素对学生成绩的影响,可以采取有针对性的教育手段,满足学生的个性化需求,促进他们的全面发展。
-
家庭教育的指导意义:分析不同条件下对青少年成绩的影响,可以为家庭教育提供指导意义。家长可以根据分析结果,更好地了解自己孩子的学习情况和影响因素,有针对性地进行家庭教育,提供更好的学习环境和支持,帮助孩子取得更好的学习成绩。
-
学术研究的价值:通过大数据分析不同条件下对青少年成绩的影响,可以为学术研究提供重要的数据支持和研究方向。研究人员可以通过分析数据,深入研究不同因素对学生成绩的影响机制,为教育领域的学术研究做出贡献。
-
总之,通过对不同条件下对青少年成绩的影响进行大数据分析,可以为教育决策、个性化教育、家庭教育和学术研究等方面提供有益的参考和指导,进一步促进青少年的学习发展和教育改革。
二、大数据分析设计方案
本数据集的数据内容与数据特征分析:
该数据来源于![]() 数据集网站,数据集地址:https://www.kaggle.com/datasets/whenamancodes/alcohol-effects-on-study/data
数据集网站,数据集地址:https://www.kaggle.com/datasets/whenamancodes/alcohol-effects-on-study/data
该数据集包含了学生的个人信息以及与成绩相关的数据。以下是对数据内容的初步分析:
-
学生个人信息:包括学校、性别、年龄、居住地、家庭规模、父母婚姻状况等。这些信息可以用于了解学生的背景情况和家庭环境对学业表现的影响。
-
学习相关信息:包括每周学习时间、之前的失败次数、额外的学校支持、家庭支持等。这些信息可以帮助分析学生的学习态度、学习环境和学业困难等因素对成绩的影响。
-
社交和生活习惯信息:包括课余时间、与朋友外出频率、饮酒频率、健康状况等。这些信息可以反映学生的社交活动和生活习惯对学业表现的可能影响。
-
数学成绩:包括第一学期、第二学期和最终的成绩。这些成绩可以用于分析学生在数学方面的学习进展和总体表现。
数据分析的课程设计方案概述:
步骤1:数据预处理和清洗
- 导入数据集并检查数据的完整性和一致性。
- 处理缺失值、异常值和重复值,确保数据的准确性和可靠性。
- 对非数值型特征进行编码或转换为数值型特征,以便后续分析使用。
步骤2:数据探索性分析
- 对数据集进行统计描述和可视化分析,包括计算各个特征的统计指标(均值、标准差、最小值、最大值等)和绘制相关图表(直方图、箱线图、散点图等)。
- 探索各个特征之间的关联性,通过相关系数矩阵、热力图等方法分析特征之间的相关程度。
步骤3:解读和分析结果
- 分析模型的预测结果和特征的重要性,探讨哪些因素对学生成绩的影响较大。
- 根据分析结果提出相应的建议和改进措施,例如针对学习时间、学习支持、课余活动等方面提供个性化的教育指导。
三、数据分析步骤
3.1数据清洗
1 # 加载数据集 2 import pandas as pd 3 4 # 读取CSV文件 5 data = pd.read_csv('Maths.csv') 6 7 # 定义列名对应的中文名称 8 column_names = { 9 'school': '学校', 10 'sex': '性别', 11 'age': '年龄', 12 'address': '居住地', 13 'famsize': '家庭大小', 14 'Pstatus': '父母婚姻状况', 15 'Medu': '母亲教育水平', 16 'Fedu': '父亲教育水平', 17 'Mjob': '母亲职业', 18 'Fjob': '父亲职业', 19 'reason': '选择学校的原因', 20 'guardian': '监护人', 21 'traveltime': '上学时间', 22 'studytime': '每周学习时间', 23 'failures': '过去的失败次数', 24 'schoolsup': '学校辅助教育', 25 'famsup': '家庭辅助教育', 26 'paid': '额外付费课程', 27 'activities': '课外活动', 28 'nursery': '幼儿园', 29 'higher': '是否计划进一步学习', 30 'internet': '互联网访问情况', 31 'romantic': '恋爱关系', 32 'famrel': '家庭关系', 33 'freetime': '课余时间', 34 'goout': '社交活动频率', 35 'Dalc': '工作日饮酒量', 36 'Walc': '周末饮酒量', 37 'health': '健康状况', 38 'absences': '缺勤次数', 39 'G1': '第一学期成绩', 40 'G2': '第二学期成绩', 41 'G3': '最终成绩' 42 } 43 44 # 重命名列名 45 data = data.rename(columns=column_names) 46 47 missing_values = data.isnull() 48 # 统计每列的缺失值数量 49 missing_counts = missing_values.sum() 50 51 # 删除成绩为0的数据行 52 data = data[(data['第一学期成绩'] != 0) & (data['第二学期成绩'] != 0) & (data['最终成绩'] != 0)] 53 54 # 重新设置索引 55 data.reset_index(drop=True, inplace=True) 56 # 去除重复值 57 data = data.drop_duplicates() 58 59 # 打印清洗后的数据 60 data
实验结果:
3.2统计青少年平均一天喝多少酒
1 import matplotlib.pyplot as plt 2 3 # 解决图标中文乱码问题 4 plt.rcParams['font.sans-serif'] = ['kaiti'] 5 6 # 统计喝酒和不喝酒的人数 7 drinker_counts1 = data['周末饮酒量'].value_counts() 8 drinker_counts2 = data['工作日饮酒量'].value_counts() 9 10 labels = ["非常少", '少', '还行', '多', '非常多'] 11 sizes = drinker_counts1+drinker_counts2 12 13 # 绘制饼图 14 plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90) 15 plt.axis('equal') # 设置饼图为圆形 16 plt.title('青少年平均一天喝多少酒') 17 18 # 显示图形 19 plt.show()
实验结果:

通过该数据可得大部分青少年还是比较少喝酒的
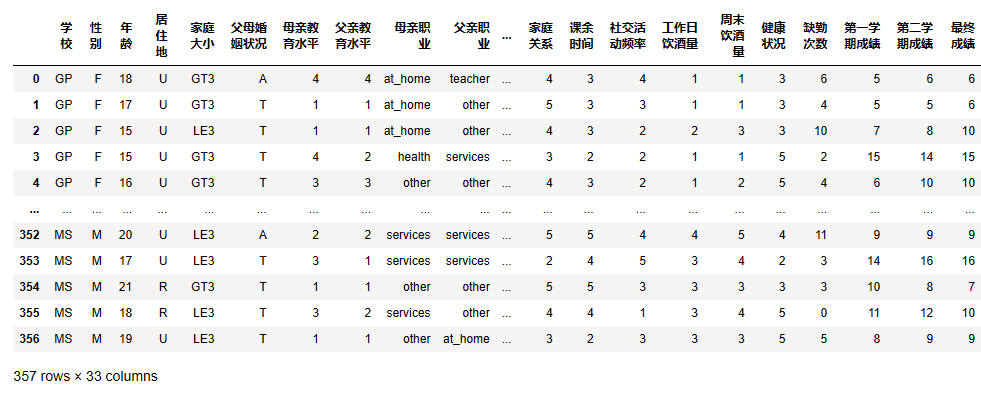
3.3统计周末和工作日饮酒人数比例
1 # 将饮酒量列转换为整数类型 2 data['周末饮酒量'] = data['周末饮酒量'].astype(int) 3 4 # 统计周末喝酒的人数 5 both_drinker_counts = data[(data['周末饮酒量'] > 2) & (data['工作日饮酒量'] <= 2)]['周末饮酒量'].value_counts() 6 7 # 统计工作日喝酒人数 8 both_drinker_counts1 = data[(data['周末饮酒量'] <= 2) & (data['工作日饮酒量'] > 2)]['周末饮酒量'].value_counts() 9 10 # 设置标签和数量 11 labels = ['周末喝酒', '工作日喝酒'] 12 sizes = [both_drinker_counts.sum(), both_drinker_counts1.sum()] 13 14 # 创建饼图 15 plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90) 16 plt.axis('equal') # 设置饼图为圆形 17 plt.title('周末和工作日饮酒人数比例') 18 19 # 显示图形 20 plt.show()
实验结果:
通过该数据显示,98.2%的人喝酒的时间段在周末,所以以下实验将在周末饮酒的数据上进行
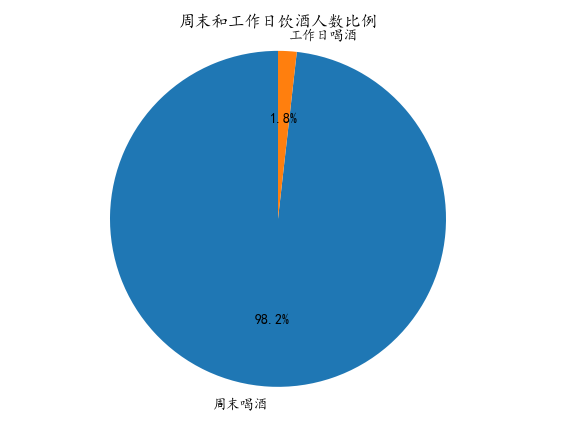
3.4统计周末大量饮酒的学生的成绩变化
1 # 筛选周末喝酒次数大于5的学生数据 2 filtered_data = data[data['周末饮酒量'] == 5] 3 4 # 提取第一学期和最终成绩列 5 grades_first_semester = filtered_data['第一学期成绩'] 6 grades_second_semester = filtered_data['第二学期成绩'] 7 grades_final = filtered_data['最终成绩'] 8 9 # 创建学生编号列表 10 student_ids = range(len(filtered_data)) 11 12 # 绘制折线图 13 plt.figure(figsize=(8, 6)) # 设置图形大小 14 plt.plot(student_ids, grades_first_semester, label='第一学期成绩', marker='o') 15 plt.plot(student_ids, grades_second_semester, label='第二学期成绩', marker='o') 16 plt.plot(student_ids, grades_final, label='最终成绩', marker='o') 17 plt.xlabel('学生编号') # 设置x轴标签 18 plt.ylabel('成绩') # 设置y轴标签 19 plt.title('周末大量饮酒的学生的成绩变化') # 设置标题 20 plt.legend() # 显示图例 21 22 # 显示折线图 23 plt.show()
实验结果:
实验数据显示周末大量饮酒对学生的成绩影响不是很大
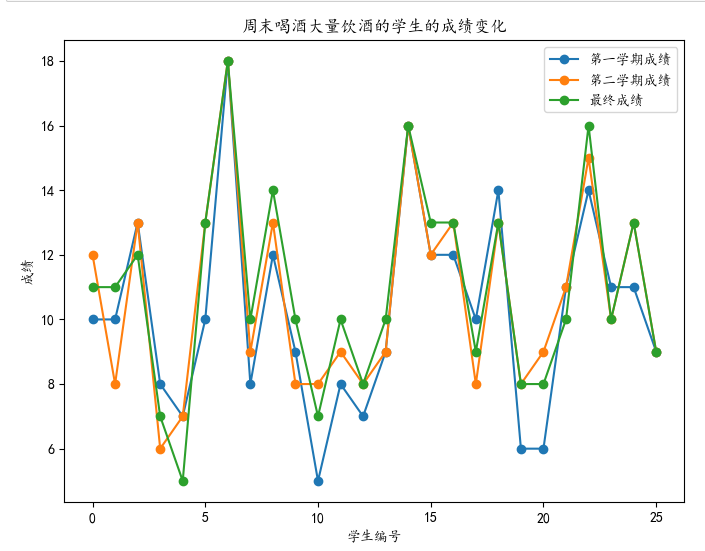
3.5统计男生饮酒的人数比例与女生饮酒的人数比例
1 # 筛选男性和女性喝酒次数大于5的学生数据 2 male_students = data[(data['性别'] == 'M') & (data['周末饮酒量'] >= 2)] 3 female_students = data[(data['性别'] == 'F') & (data['周末饮酒量'] >= 2)] 4 5 # 计算男性和女性喝酒次数大于5的比例 6 total_male_students = len(data[data['性别'] == 'M']) 7 total_female_students = len(data[data['性别'] == 'F']) 8 percentage_male = len(male_students) / total_male_students * 100 9 percentage_female = len(female_students) / total_female_students * 100 10 11 # 创建两个饼图 12 labels = ['经常喝酒', '不经常喝酒', '经常喝酒', '不经常喝酒'] 13 sizes = [len(male_students), total_male_students - len(male_students), 14 len(female_students), total_female_students - len(female_students)] 15 colors = ['lightblue', 'lightgray', 'lightpink', 'lightgray'] 16 17 fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5)) 18 ax1.pie(sizes[:2], labels=labels[:2], colors=colors[:2], autopct='%1.1f%%') 19 ax1.set_title('男性喝酒情况') 20 21 ax2.pie(sizes[2:], labels=labels[2:], colors=colors[2:], autopct='%1.1f%%') 22 ax2.set_title('女性喝酒情况') 23 24 plt.show()
实验结果:
综上所述,男性饮酒的比例在7:3,女性比例在5.6:4.3
3.6统计男性女性喝酒的人数比例
1 # 创建饼图数据 2 labels = ['男性', '女性'] 3 sizes = [percentage_male, percentage_female] 4 colors = ['#ff9999', '#66b3ff'] 5 explode = (0.1, 0) # 突出显示男性部分 6 7 # 绘制饼图 8 plt.pie(sizes, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%', 9 shadow=True, startangle=90) 10 plt.axis('equal') # 设置坐标轴比例一致,使饼图为圆形 11 plt.title('男性女性大量喝酒的比例') 12 plt.show()
实验结果:
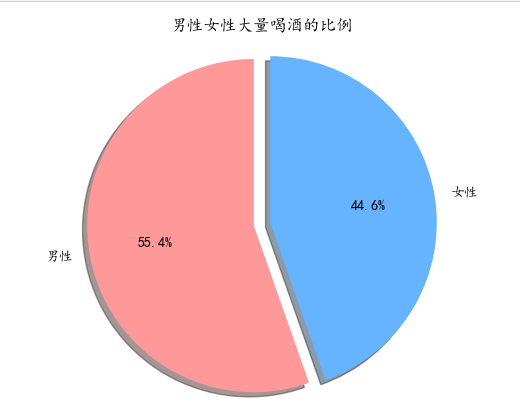
综上所述,男性喝酒的比例比女性的多
3.7学生学习时间情况
1 study_time = data['每周学习时间'] 2 3 # 统计每个学习时间的频数 4 study_time_counts = study_time.value_counts() 5 6 # 排序学习时间的索引顺序 7 study_time_counts.sort_index(inplace=True) 8 9 # 定义新的x轴标签 10 x_labels = ['0-2 小时', '2-5 小时', '5-10 小时', '大于10 小时'] 11 12 # 绘制柱状图 13 plt.bar(study_time_counts.index, study_time_counts.values) 14 plt.xlabel('学习时间') 15 plt.ylabel('频率') 16 plt.title('学生学习时间柱状图') 17 18 # 设置新的x轴标签 19 plt.xticks(study_time_counts.index, x_labels) 20 plt.show()
实验结果:
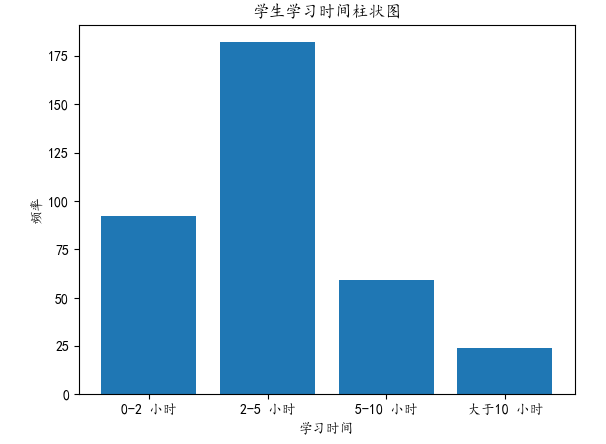
综上所述,学生学习时长一般在2-5小时,很少有学生学习时长大于10小时
3.8学生成绩情况
1 import numpy as np 2 # 提取相关列数据 3 first_semester = data['第一学期成绩'] 4 second_semester = data['第二学期成绩'] 5 final_grade = data['最终成绩'] 6 7 # 创建x轴数据(学生编号) 8 x_values = data.index + 1 9 10 # 设置画布大小 11 fig, ax = plt.subplots(figsize=(10, 6)) 12 13 # 调整子图布局 14 plt.subplots_adjust(bottom=0.15) 15 16 # 绘制散点图 17 plt.scatter(x_values, first_semester, label='第一学期成绩') 18 plt.scatter(x_values, second_semester, label='第二学期成绩') 19 plt.scatter(x_values, final_grade, label='最终成绩') 20 21 plt.xlabel('学生') 22 plt.ylabel('成绩') 23 plt.title('学生成绩散点图') 24 plt.legend() 25 plt.show()
实验结果:
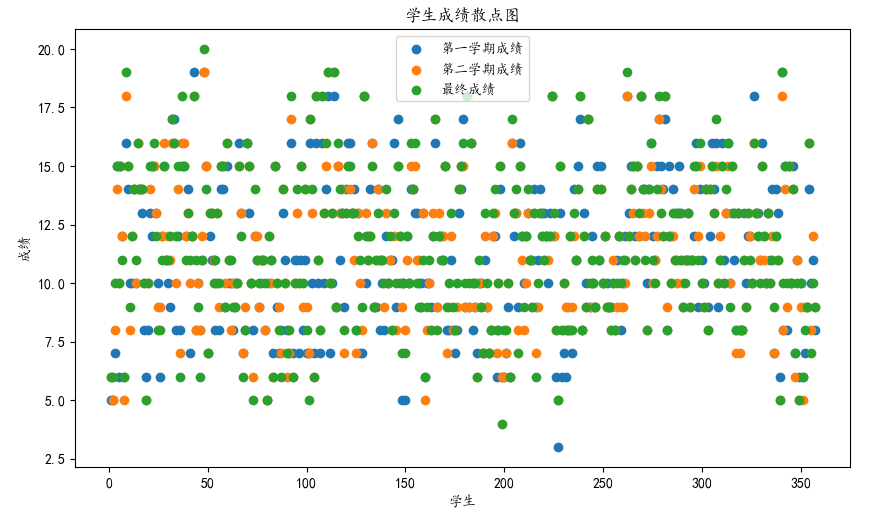
综上所述,学生成绩一般在5-16之间
3.9学习时间对学生成绩的影响
1 from mpl_toolkits.mplot3d import Axes3D 2 3 # 提取相关列数据 4 study_time = data['每周学习时间'] 5 first_semester = data['第一学期成绩'] 6 final_grade = data['最终成绩'] 7 8 # 创建三维散点图 9 fig = plt.figure(figsize=(10, 8)) # 设置画布大小 10 ax = fig.add_subplot(111, projection='3d') 11 ax.scatter(study_time, first_semester, final_grade) 12 13 # 设置坐标轴标签和标题 14 ax.set_xlabel('学习时间(小时/周)') 15 ax.set_ylabel('第一学期年级') 16 ax.set_zlabel('最终成绩') 17 ax.set_title('学习时间对成绩的影响') 18 19 plt.show()
实验结果:
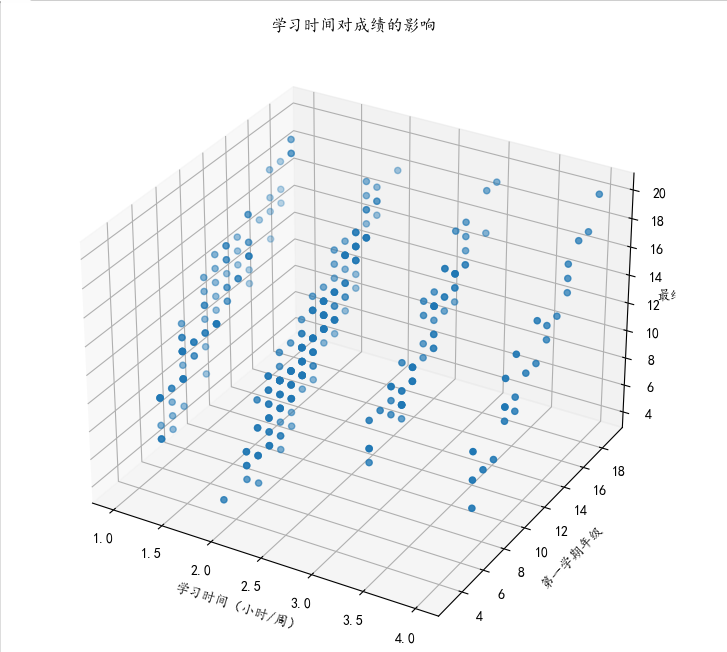
综上所述,学习时间在3以上的学生成绩比学习时间在2的学生成绩要略高一些
3.10接受额外课程与接受家庭辅助教育的成绩对比
1 # 提取相关列数据 2 grades = data['最终成绩'] 3 extra_courses = data['额外付费课程'] 4 family_support = data['家庭辅助教育'] 5 6 # 计算平均成绩 7 mean_grades = data.groupby([extra_courses, family_support])['最终成绩'].mean() 8 9 # 重塑数据框 10 df = mean_grades.unstack() 11 12 # 提取感兴趣的数据 13 only_extra_courses = mean_grades['yes']['no'] 14 only_family_support = mean_grades['no']['yes'] 15 both_extra_courses_family_support = mean_grades['yes']['yes'] 16 17 # 创建雷达图 18 labels = ['额外课程', '家庭辅助教育', '同时接受'] 19 values = [only_extra_courses, only_family_support, both_extra_courses_family_support] 20 21 # 设置雷达图的角度和标签 22 angles = [n / float(len(labels)) * 2 * 3.14159 for n in range(len(labels))] 23 24 # 创建子图 25 fig, ax = plt.subplots(figsize=(8, 8), subplot_kw={'polar': True}) 26 27 # 绘制雷达图 28 ax.plot(angles, values, 'o-', linewidth=2) 29 ax.fill(angles, values, alpha=0.25) 30 31 # 设置刻度和标签 32 ax.set_xticks(angles) 33 ax.set_xticklabels(labels) 34 35 # 设置标题 36 ax.set_title('接受额外课程与接受家庭辅助教育的成绩对比', size=12, color='black', y=1.1) 37 38 # 显示图形 39 plt.show()
实验结果:
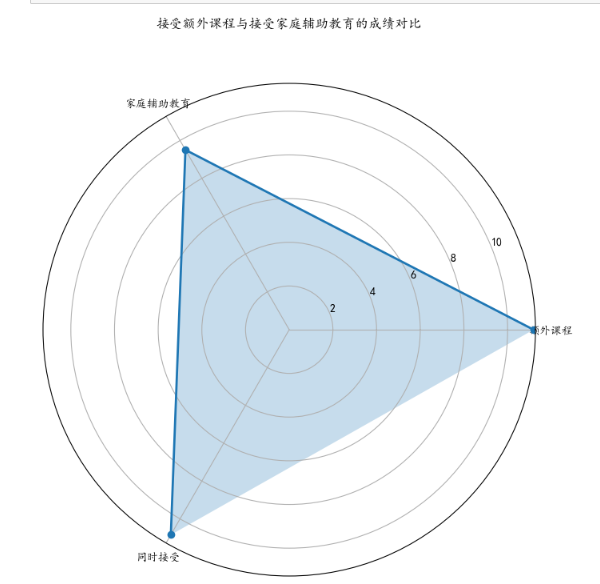
综上所述,接受课外课程的同学平均成绩比家庭辅助教育的成绩好些,同时接受两种教育的并没有想象中那么好
3.11父母其中一方是老师的学生成绩
1 # 筛选父母其中一方是老师的学生数据 2 teacher_parents_data = data[(data['母亲职业'] == 'teacher') | (data['父亲职业'] == 'teacher')] 3 4 # 统计学生的成绩信息 5 average_grade = teacher_parents_data['最终成绩'].mean() 6 max_grade = teacher_parents_data['最终成绩'].max() 7 min_grade = teacher_parents_data['最终成绩'].min() 8 grade_std = teacher_parents_data['最终成绩'].std() 9 10 # 获取学生的成绩信息 11 grades = teacher_parents_data['最终成绩'] 12 13 # 输出统计结果 14 print("平均成绩:", average_grade) 15 print("最高成绩:", max_grade) 16 print("最低成绩:", min_grade) 17 print("成绩标准差:", grade_std) 18 19 # 设置柱状图的参数 20 plt.figure(figsize=(8, 6)) # 设置图形大小 21 plt.plot(range(len(grades)), grades, marker='o') # 生成折线图 22 plt.xlabel('学生编号') # 设置x轴标签 23 plt.ylabel('成绩') # 设置y轴标签 24 plt.title('父母其中一方是老师的学生成绩') # 设置标题
实验结果:
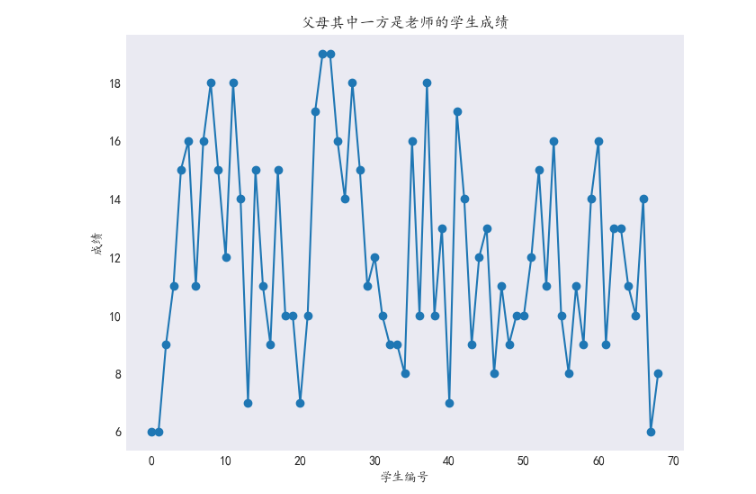
综上所述,父母其中一方是老师的学生成绩普遍在8-16之间
3.12不同条件下的学生成绩对比
1 # 提取相关列数据 2 study_hours = data[data['每周学习时间'] >= 3]['最终成绩'] 3 teacher_parents_data = data[(data['母亲职业'] == 'teacher') | (data['父亲职业'] == 'teacher')] 4 extra_courses = data['额外付费课程'] 5 drinking = data[data['周末饮酒量'] >= 3]['最终成绩'] 6 7 # 计算平均成绩 8 mean_study_hours = study_hours.mean() 9 mean_teacher_parents_data = teacher_parents_data['最终成绩'].mean() 10 mean_drinking = drinking.mean() 11 mean_grades = data.groupby([extra_courses, family_support])['最终成绩'].mean() 12 13 only_extra_courses = mean_grades['yes']['no'] 14 15 # 创建柱状图 16 x = ['每周学习时间>=3', '父母其中一方是老师', '经常饮酒', '额外付费课程'] 17 y = [mean_study_hours, mean_teacher_parents_data, mean_drinking,only_extra_courses] 18 19 plt.bar(x, y) 20 21 # 设置坐标轴标签和标题 22 plt.xlabel('条件') 23 plt.ylabel('平均成绩') 24 plt.title('不同条件下的学生成绩对比') 25 26 plt.show()
实验结果:
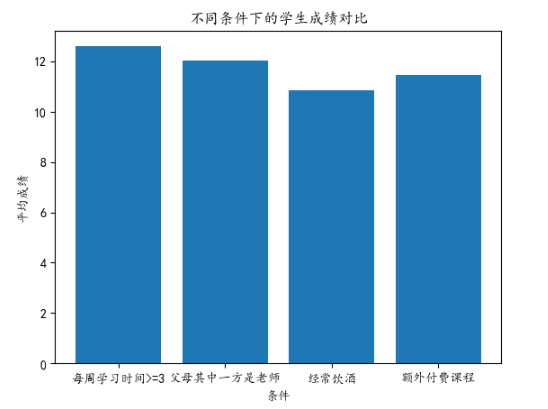
综上所述,每周学习时间在3以上的学生成绩最好,其次是父母其中一方是老师的,喝酒的学生成绩是在其中较差的。
3.12全部代码
1 # 加载数据集 2 import pandas as pd 3 4 # 读取CSV文件 5 data = pd.read_csv('Maths.csv') 6 7 # 定义列名对应的中文名称 8 column_names = { 9 'school': '学校', 10 'sex': '性别', 11 'age': '年龄', 12 'address': '居住地', 13 'famsize': '家庭大小', 14 'Pstatus': '父母婚姻状况', 15 'Medu': '母亲教育水平', 16 'Fedu': '父亲教育水平', 17 'Mjob': '母亲职业', 18 'Fjob': '父亲职业', 19 'reason': '选择学校的原因', 20 'guardian': '监护人', 21 'traveltime': '上学时间', 22 'studytime': '每周学习时间', 23 'failures': '过去的失败次数', 24 'schoolsup': '学校辅助教育', 25 'famsup': '家庭辅助教育', 26 'paid': '额外付费课程', 27 'activities': '课外活动', 28 'nursery': '幼儿园', 29 'higher': '是否计划进一步学习', 30 'internet': '互联网访问情况', 31 'romantic': '恋爱关系', 32 'famrel': '家庭关系', 33 'freetime': '课余时间', 34 'goout': '社交活动频率', 35 'Dalc': '工作日饮酒量', 36 'Walc': '周末饮酒量', 37 'health': '健康状况', 38 'absences': '缺勤次数', 39 'G1': '第一学期成绩', 40 'G2': '第二学期成绩', 41 'G3': '最终成绩' 42 } 43 44 # 重命名列名 45 data = data.rename(columns=column_names) 46 47 # 输出重命名列名后的数据集 48 print("重命名后的数据集:\n") 49 data.head() 50 missing_values = data.isnull() 51 # 统计每列的缺失值数量 52 missing_counts = missing_values.sum() 53 54 # 打印每列的缺失值数量 55 print(missing_counts) 56 # 删除成绩为0的数据行 57 data = data[(data['第一学期成绩'] != 0) & (data['第二学期成绩'] != 0) & (data['最终成绩'] != 0)] 58 59 # 重新设置索引 60 data.reset_index(drop=True, inplace=True) 61 # 去除重复值 62 data = data.drop_duplicates() 63 64 # 打印清洗后的数据 65 data 66 import pandas as pd 67 import matplotlib.pyplot as plt 68 69 # 解决图标中文乱码问题 70 plt.rcParams['font.sans-serif'] = ['kaiti'] 71 72 # 统计喝酒和不喝酒的人数 73 drinker_counts1 = data['周末饮酒量'].value_counts() 74 drinker_counts2 = data['工作日饮酒量'].value_counts() 75 76 labels = ["非常少", '少', '还行', '多', '非常多'] 77 sizes = drinker_counts1+drinker_counts2 78 79 # 绘制饼图 80 plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90) 81 plt.axis('equal') # 设置饼图为圆形 82 plt.title('青少年平均一天喝多少酒') 83 84 # 显示图形 85 plt.show() 86 # 将饮酒量列转换为整数类型 87 data['周末饮酒量'] = data['周末饮酒量'].astype(int) 88 89 # 统计周末喝酒的人数 90 both_drinker_counts = data[(data['周末饮酒量'] > 2) & (data['工作日饮酒量'] <= 2)]['周末饮酒量'].value_counts() 91 92 # 统计工作日喝酒人数 93 both_drinker_counts1 = data[(data['周末饮酒量'] <= 2) & (data['工作日饮酒量'] > 2)]['周末饮酒量'].value_counts() 94 95 # 设置标签和数量 96 labels = ['周末喝酒', '工作日喝酒'] 97 sizes = [both_drinker_counts.sum(), both_drinker_counts1.sum()] 98 99 # 创建饼图 100 plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90) 101 plt.axis('equal') # 设置饼图为圆形 102 plt.title('周末和工作日饮酒人数比例') 103 104 # 显示图形 105 plt.show() 106 # 筛选周末喝酒次数大于5的学生数据 107 filtered_data = data[data['周末饮酒量'] == 5] 108 109 # 提取第一学期和最终成绩列 110 grades_first_semester = filtered_data['第一学期成绩'] 111 grades_second_semester = filtered_data['第二学期成绩'] 112 grades_final = filtered_data['最终成绩'] 113 114 # 创建学生编号列表 115 student_ids = range(len(filtered_data)) 116 117 # 绘制折线图 118 plt.figure(figsize=(8, 6)) # 设置图形大小 119 plt.plot(student_ids, grades_first_semester, label='第一学期成绩', marker='o') 120 plt.plot(student_ids, grades_second_semester, label='第二学期成绩', marker='o') 121 plt.plot(student_ids, grades_final, label='最终成绩', marker='o') 122 plt.xlabel('学生编号') # 设置x轴标签 123 plt.ylabel('成绩') # 设置y轴标签 124 plt.title('周末大量饮酒的学生的成绩变化') # 设置标题 125 plt.legend() # 显示图例 126 127 # 显示折线图 128 plt.show() 129 # 筛选男性和女性喝酒次数大于5的学生数据 130 male_students = data[(data['性别'] == 'M') & (data['周末饮酒量'] >= 2)] 131 female_students = data[(data['性别'] == 'F') & (data['周末饮酒量'] >= 2)] 132 133 # 计算男性和女性喝酒次数大于5的比例 134 total_male_students = len(data[data['性别'] == 'M']) 135 total_female_students = len(data[data['性别'] == 'F']) 136 percentage_male = len(male_students) / total_male_students * 100 137 percentage_female = len(female_students) / total_female_students * 100 138 139 # 创建两个饼图 140 labels = ['经常喝酒', '不经常喝酒', '经常喝酒', '不经常喝酒'] 141 sizes = [len(male_students), total_male_students - len(male_students), 142 len(female_students), total_female_students - len(female_students)] 143 colors = ['lightblue', 'lightgray', 'lightpink', 'lightgray'] 144 145 fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5)) 146 ax1.pie(sizes[:2], labels=labels[:2], colors=colors[:2], autopct='%1.1f%%') 147 ax1.set_title('男性喝酒情况') 148 149 ax2.pie(sizes[2:], labels=labels[2:], colors=colors[2:], autopct='%1.1f%%') 150 ax2.set_title('女性喝酒情况') 151 152 plt.show() 153 # 创建饼图数据 154 labels = ['男性', '女性'] 155 sizes = [percentage_male, percentage_female] 156 colors = ['#ff9999', '#66b3ff'] 157 explode = (0.1, 0) # 突出显示男性部分 158 159 # 绘制饼图 160 plt.pie(sizes, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%', 161 shadow=True, startangle=90) 162 plt.axis('equal') # 设置坐标轴比例一致,使饼图为圆形 163 plt.title('男性女性大量喝酒的比例') 164 plt.show() 165 study_time = data['每周学习时间'] 166 167 # 统计每个学习时间的频数 168 study_time_counts = study_time.value_counts() 169 170 # 排序学习时间的索引顺序 171 study_time_counts.sort_index(inplace=True) 172 173 # 定义新的x轴标签 174 x_labels = ['0-2 小时', '2-5 小时', '5-10 小时', '大于10 小时'] 175 176 # 绘制柱状图 177 plt.bar(study_time_counts.index, study_time_counts.values) 178 plt.xlabel('学习时间') 179 plt.ylabel('频率') 180 plt.title('学生学习时间柱状图') 181 182 # 设置新的x轴标签 183 plt.xticks(study_time_counts.index, x_labels) 184 plt.show() 185 import numpy as np 186 # 提取相关列数据 187 first_semester = data['第一学期成绩'] 188 second_semester = data['第二学期成绩'] 189 final_grade = data['最终成绩'] 190 191 # 创建x轴数据(学生编号) 192 x_values = data.index + 1 193 194 # 设置画布大小 195 fig, ax = plt.subplots(figsize=(10, 6)) 196 197 # 调整子图布局 198 plt.subplots_adjust(bottom=0.15) 199 200 # 绘制散点图 201 plt.scatter(x_values, first_semester, label='第一学期成绩') 202 plt.scatter(x_values, second_semester, label='第二学期成绩') 203 plt.scatter(x_values, final_grade, label='最终成绩') 204 205 plt.xlabel('学生') 206 plt.ylabel('成绩') 207 plt.title('学生成绩散点图') 208 plt.legend() 209 plt.show() 210 from mpl_toolkits.mplot3d import Axes3D 211 212 # 提取相关列数据 213 study_time = data['每周学习时间'] 214 first_semester = data['第一学期成绩'] 215 final_grade = data['最终成绩'] 216 217 # 创建三维散点图 218 fig = plt.figure(figsize=(10, 8)) # 设置画布大小 219 ax = fig.add_subplot(111, projection='3d') 220 ax.scatter(study_time, first_semester, final_grade) 221 222 # 设置坐标轴标签和标题 223 ax.set_xlabel('学习时间(小时/周)') 224 ax.set_ylabel('第一学期年级') 225 ax.set_zlabel('最终成绩') 226 ax.set_title('学习时间对成绩的影响') 227 228 plt.show() 229 # 提取相关列数据 230 grades = data['最终成绩'] 231 extra_courses = data['额外付费课程'] 232 family_support = data['家庭辅助教育'] 233 234 # 计算平均成绩 235 mean_grades = data.groupby([extra_courses, family_support])['最终成绩'].mean() 236 237 # 重塑数据框 238 df = mean_grades.unstack() 239 240 # 提取感兴趣的数据 241 only_extra_courses = df['yes']['no'] 242 only_family_support = df['no']['yes'] 243 both_extra_courses_family_support = df['yes']['yes'] 244 245 # 创建雷达图 246 labels = ['额外课程', '家庭辅助教育', '同时接受'] 247 values = [only_extra_courses, only_family_support, both_extra_courses_family_support] 248 249 # 设置雷达图的角度和标签 250 angles = np.linspace(1, 2 * np.pi, len(labels), endpoint=False).tolist() 251 252 # 添加第一个元素到列表末尾,使雷达图闭合 253 values.append(values[0]) 254 angles.append(angles[0]) 255 256 # 创建子图 257 fig, ax = plt.subplots(figsize=(6, 6), subplot_kw={'polar': True}) 258 259 # 绘制雷达图 260 ax.plot(angles, values, 'o-', linewidth=2) 261 ax.fill(angles, values, alpha=0.25) 262 263 # 设置刻度和标签 264 ax.set_xticks(angles[:-1]) 265 ax.set_xticklabels(labels) 266 267 # 设置标题 268 ax.set_title('接受额外课程与接受家庭辅助教育的成绩对比', size=12, color='black', y=1.1) 269 270 # 显示图形 271 plt.show() 272 # 筛选父母其中一方是老师的学生数据 273 teacher_parents_data = data[(data['母亲职业'] == 'teacher') | (data['父亲职业'] == 'teacher')] 274 275 # 统计学生的成绩信息 276 average_grade = teacher_parents_data['最终成绩'].mean() 277 max_grade = teacher_parents_data['最终成绩'].max() 278 min_grade = teacher_parents_data['最终成绩'].min() 279 grade_std = teacher_parents_data['最终成绩'].std() 280 281 # 获取学生的成绩信息 282 grades = teacher_parents_data['最终成绩'] 283 284 # 输出统计结果 285 print("平均成绩:", average_grade) 286 print("最高成绩:", max_grade) 287 print("最低成绩:", min_grade) 288 print("成绩标准差:", grade_std) 289 290 # 设置柱状图的参数 291 plt.figure(figsize=(8, 6)) # 设置图形大小 292 plt.plot(range(len(grades)), grades, marker='o') # 生成折线图 293 plt.xlabel('学生编号') # 设置x轴标签 294 plt.ylabel('成绩') # 设置y轴标签 295 plt.title('父母其中一方是老师的学生成绩') # 设置标题 296 # 提取相关列数据 297 study_hours = data[data['每周学习时间'] >= 3]['最终成绩'] 298 teacher_parents_data = data[(data['母亲职业'] == 'teacher') | (data['父亲职业'] == 'teacher')] 299 extra_courses = data['额外付费课程'] 300 drinking = data[data['周末饮酒量'] >= 3]['最终成绩'] 301 302 # 计算平均成绩 303 mean_study_hours = study_hours.mean() 304 mean_teacher_parents_data = teacher_parents_data['最终成绩'].mean() 305 mean_drinking = drinking.mean() 306 mean_grades = data.groupby([extra_courses, family_support])['最终成绩'].mean() 307 308 only_extra_courses = mean_grades['yes']['no'] 309 310 # 创建柱状图 311 x = ['每周学习时间>=3', '父母其中一方是老师', '经常饮酒', '额外付费课程'] 312 y = [mean_study_hours, mean_teacher_parents_data, mean_drinking,only_extra_courses] 313 314 plt.bar(x, y) 315 316 # 设置坐标轴标签和标题 317 plt.xlabel('条件') 318 plt.ylabel('平均成绩') 319 plt.title('不同条件下的学生成绩对比') 320 321 plt.show()
四、总结
通过数据分析和挖掘,我们可以得出以下有益的结论:
- 接受额外付费课程和家庭辅助教育对学生最终成绩有一定的影响。
- 学生同时接受额外付费课程和家庭辅助教育的平均成绩没有接受额外课程的成绩高。
- 只接受额外付费课程的学生平均成绩是较好的。
- 喝酒对学生的成绩是有影响的,但是影响不大。
- 每周学习时间在5-10小时的学生成绩最好。
这些结论表明,接受额外付费课程对学生的学习成绩具有积极的影响,喝酒对学生的成绩是有消极影响的。我们的分析结果达到了预期的目标,帮助我们理解了这些因素与学生成绩之间的关系。
在完成本设计过程中,我获得了以下收获:
- 理解了数据清洗和去重的重要性,以确保分析结果的准确性。
- 学习了如何使用Pandas库进行数据处理和分析,包括数据提取、分组计算和数据重塑等操作。
- 掌握了使用Matplotlib库绘制雷达图、柱状图的基本方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号