

集中化日志管理平台的应用day03 暂时没用
3、项⽬搭建
3.1 项⽬概述
搭建⼀套微服务环境,实现多点⽇志采集,⽤于
web请求的访问链路跟踪,包含以下跟踪点:
请求的前台⻚⾯
请求到达nginx的转发记录
请求的后台⽅法
请求的业务输出标记
远程的⽅法调⽤(如有涉及)
3.2 设计⽬标
3.2.1 检索维度
可以按常⽤维度做到快速检索:
某次请求
某个⽤户
某个终端
3.2.2 分布式环境
机器以集群形式部署多台
微服务存在docker等容器化部署场景
不同机器的同⼀服务⽇志要做到集中展示
3.2.3 低⼊侵
在保障⽇志内容详尽的前提下,尽量做到业务代码⽆感知
3.2.4 低耦合
⽇志服务不要影响主业务的进⾏,⽇志down机不能阻断业务执⾏
3.2.5 时效性
⽇志在分布式环境中⽆法做到完全实时,但要尽量避免过⻓的时间差
3.2.6 缓冲与防丢失
在⽇志服务不可⽤时,对应⽤的⽇志产出要做到暂存,缓冲,防⽌丢失
3.3 软件设计
3.3.1 基本概念
本项⽬中,与请求链路相关的概念约定如下:
rid(requestId
):⼀次请求的唯⼀标示,⽣成后⼀直传递到调⽤结束
sid(sessionId
):⽤户会话相关,涉及登陆时存在,不登陆的操作为空
tid(terminalId
):同⼀个终端的请求标示,可以理解为同⼀个设备。可能对应多个⽤户的多次请
求
3.3.2 前台⻚⾯
⻚⾯⾸次加载时⽣成tid,写⼊当前浏览器的cookie,后续请求都会携带
⻚⾯请求时,⽣成唯⼀性的rid作为⼀次请求的发起
如果⽤户session作为sid,⽤于识别同⼀⽤户的⾏为
3.3.3 nginx
⽅案⼀:通过accesslog可以打印,fifilebeat采集本地⽂件⽅式可以送⼊kafka通道
⽅案⼆:lua脚本可以直接送⼊kafka
logstash获取kafka⽇志数据,进⼊es
3.3.4 java服务端
gateway作为统⼀⽹关,处理三个维度变量的⽣成与下发
各个微服务集成kafka,将⾃⼰需要的⽇志送⼊kafka
3.3.5 ⽅法调⽤
Aop切⾯,拦截器等系统组件可以以插件形式介⼊⽇志采集,缺点是⽆法灵活做到个性化定制
注解操作灵活,可以⾃由定制输出内容,缺点是对代码存在轻微⼊侵
3.3.6 远程调⽤
远程⽅法之间的调⽤,三个id通过显式参数形式进⾏传递,由当前服务到下⼀个服务
3.3.7 系统拓扑
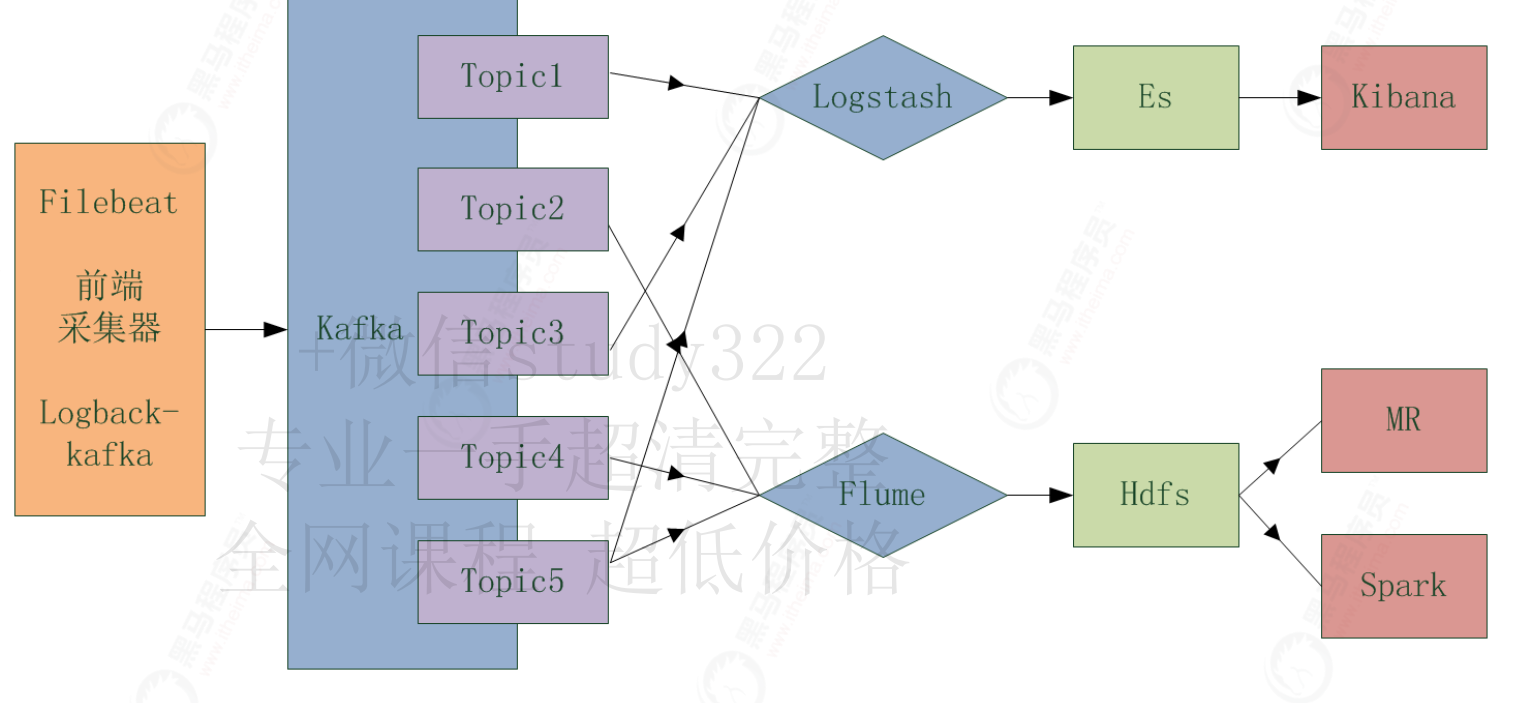
3.4 框架搭建
搭建⼀个微服务项⽬,集成⽇志平台的对接。
3.4.1 模块划分
⽗pom:maven项⽬的⽗pom,⽤于整个项⽬的依赖继承,版本传递和约束
nacos:springcloud的注册中⼼和配置中⼼
gateway:微服务⽹关,请求链路进⼊后台的第⼀道关⼝
web:springboot集成web组件,⽤于模拟我们的上层web项⽬
user:基于springcloud微服务模块,⽤于模拟实际项⽬中的⼀个⽤户微服务
utils:存放⽇常使⽤的⼀些⼯具类
3.4.2 nacos
Nacos ⽀持基于 DNS 和基于 RPC 的服务发现(可以作为springcloud的注册中⼼)、动态配置服
务(可以做配置中⼼)、动态 DNS 服务。
1)快速启动参考:https://nacos.io/zh-cn/docs/quick-start.html
2)下载解压,可以修改conf/application.properties,配置端⼝信息
3)启动: sh /opt/app/nacos/bin/startup.sh -m standalone
3.4.7 ⽗pom
1)访问 http://start.spring.io
2)选择版本,并填写相关坐标
3)选择相关依赖组件
4)⽣成⽅式选explorer,因为我们只需要pom作为⽗坐标,其他⽂件不需要
5)拷⻉⽂件到idea,并修改类型为pom
3.4.3 web⼦模块
1)使⽤maven命令⾏⼯具,创建maven项⽬
2)添加cloud代码:
3)增加配置⽂件:bootstrap.properties
<packaging>pom</packaging>
#操作演示:打开dos或者idea的terminal,或者gitbash等⼯具,进⼊交互模式,逐步创建项⽬
mvn archetype:generate
#也可以⼀步到位直接指定参数
mvn archetype:generate -DgroupId=com.itheima.logdemo -DartifactId=web -
DpackageName=com.itheima.logdemo.web -DarchetypeArtifactId=maven-archetype
quickstart -DinteractiveMode=false
@SpringBootApplication
@EnableDiscoveryClient
@RestController
public class App {
public static void main(String[] args) {
new SpringApplicationBuilder(App.class).run(args);
}
}
3.4.4 user
⼦模块
1)mvn步骤同上
2)增加配置⽂件:bootstrap.properties
3.4.5 ⼯具包utils
1)mvn步骤同上
2)引⼊常⽤坐标
3)定义LogBean,记录⽇志信息
#服务名
spring.application.name=web
#端⼝号
server.port=8002
#配置中⼼url
spring.cloud.nacos.config.server-addr=39.98.133.153:9105
#注册中⼼
spring.cloud.nacos.discovery.server-addr
=39.98.133.153:9105
#服务名
spring.application.name=user
#端⼝号
server.port=8003
#配置中⼼url
spring.cloud.nacos.config.server-addr=39.98.133.153:9105
#注册中⼼
spring.cloud.nacos.discovery.server-addr=39.98.133.153:9105
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
package com.itheima.logdemo.utils;
import com.alibaba.fastjson.JSON;
public class LogBean {
private String rid,sid,tid,from,message;
4)web和user引⼊ustils的坐标
3.4.6 logback-kafka
1)以web项⽬为例,springboot默认使⽤logback做⽇志,添加kafka依赖
https://github.com/danielwegener/logback-kafka-appender
2)logback配置⽂件,配置前需要先从km创建demo topic,并配置logstash配置⽂件
public LogBean(String rid, String sid, String tid, String from, String
message) {
this.rid = rid;
this.sid = sid;
this.tid = tid;
this.from = from;
this.message = message;
}
//getter and setter...
@Override
public
String toString() {
return JSON.toJSONString(this);
}
}
<dependency>
<groupId>com.github.danielwegener</groupId>
<artifactId>logback-kafka-appender</artifactId>
<version>0.2.0-RC2</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.2</version>
</dependency>
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="30 seconds" debug="false">
<!-- lOGGER PATTERN 根据个⼈喜好选择匹配 -->
<property name="logPattern"
value="logback:[ %-5level] [%date{HH:mm:ss.SSS}] %logger{96}
[%line] [%thread]- %msg%n"></property>
<!-- 控制台的标准输出 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<charset>UTF-8</charset>
<pattern>${logPattern}</pattern>
</encoder>
</appender>
<!-- This example configuration is probably most unreliable under failure
conditions but wont block your application at all -->
<appender
name="kafka"
class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder
class
="ch.qos.logback.classic.encoder.PatternLayoutEncoder"
>
<pattern
>%msg%n
</pattern>
</encoder>
<topic>demo</topic>
<!-- we don't care how the log messages will be partitioned -->
<keyingStrategy
class="com.github.danielwegener.logback.kafka.keying.NoKeyKeyingStrategy"/>
<!-- use async delivery. the application threads are not blocked by
logging -->
<deliveryStrategy
class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStra
tegy"/>
<!-- each <producerConfig> translates to regular kafka-client config
(format: key=value) -->
<!-- producer configs are documented here:
https://kafka.apache.org/documentation.html#newproducerconfigs -->
<!-- bootstrap.servers is the only mandatory producerConfig -->
<producerConfig>bootstrap.servers=39.98.133.153:9103</producerConfig>
<!-- don't wait for a broker to ack the reception of a batch. -->
<producerConfig>acks=0</producerConfig>
<!-- wait up to 1000ms and collect log messages before sending them as
a batch -->
<producerConfig>linger.ms=1000</producerConfig>
<!-- even if the producer buffer runs full, do not block the
application but start to drop messages -->
<producerConfig>max.block.ms=0</producerConfig>
<!-- define a client-id that you use to identify yourself against the
kafka broker -->
<producerConfig>client.id=${HOSTNAME}-${CONTEXT_NAME}-logback
relaxed</producerConfig>
<!-- there is no fallback <appender-ref>. If this appender cannot
deliver, it will drop its messages. -->
</appender>
<logger name="kafka">
<appender-ref ref="kafka"/>
</logger>
3)启动web,测试log
⽇志通道,进kibana查看⽇志输出情况
3.4.7 ⼿写KafkaAppender
1)utils项⽬的pom中引⼊spring-kafka
2)utils中定义kafka appender
<root level="INFO">
<appender-ref ref="STDOUT"/>
</root>
</configuration>
private final Logger logger = LoggerFactory.getLogger("kafka");
@GetMapping("/test")
public Object test(){
logger.info("this is a test");
return "this is a test";
}
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.2</version>
</dependency>
import ch.qos.logback.classic.spi.ILoggingEvent;
import ch.qos.logback.core.AppenderBase;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import java.util.HashMap;
import java.util.Map;
public class KafkaAppender extends AppenderBase<ILoggingEvent> {
//定义属性,可以从logback.xml配置⽂件中获取
private String topic,brokers;
private KafkaTemplate kafkaTemplate;
@Override
public void
start
() {
Map<String
, Object
> props = new HashMap<>();
//连接地址
props
.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
//
重试,
0为不启⽤重试机制
props
.put
(ProducerConfig.RETRIES_CONFIG, 1);
//控制批处理⼤⼩,单位为字节
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//批量发送,延迟为1毫秒,启⽤该功能能有效减少⽣产者发送消息次数,从⽽提⾼并发量
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//⽣产者可以使⽤的最⼤内存字节来缓冲等待发送到服务器的记录
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 1024000);
//键的序列化⽅式
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
IntegerSerializer.class);
//值的序列化⽅式
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
this.kafkaTemplate = new KafkaTemplate<Integer, String>(new
DefaultKafkaProducerFactory<>(props));
super.start();
}
@Override
public void stop() {
super.stop();
}
@Override
protected void append(ILoggingEvent iLoggingEvent) {
kafkaTemplate.send(topic,iLoggingEvent.getMessage());
}
public String getTopic() {
return topic;
}
public void setTopic(String topic) {
this.topic = topic;
}
public String getBrokers() {
3)web的logback中配置
appender
3.5总结
1)⽇志收集环境的⼀些设计⽬标
2)前期准备⼯作,搭建基础微服务框架
3)需要注意,springcloud默认使⽤logback做⽇志
4)两种⽅式展示如何在cloud环境中集成kafka和中间件平台
5)测试⽇志的完整通道
return brokers;
}
public void setBrokers(String brokers) {
this.brokers = brokers;
}
}
<appender name="kafka" class="com.itheima.logdemo.utils.KafkaAppender">
<topic
>demo</topic>
<brokers>39.98.133.153:9103</brokers>
</appender>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号