

大数据项目实战之在线教育(01数仓需求)
第1章 数据仓库概念
数据仓库是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。
数据仓库是出于分析报告和决策支持目的而创建的,为需要业务智能的企业,提供指导业务流程改进、监控时间、成本、质量以及控制。
第2章 项目需求及架构设计
2.1 项目需求分析
一、数据采集平台搭建
二、实现数据仓库分层的搭建
三、实现数据清洗、聚合、计算等操作
四、统计各指标,如统计通过各地址跳转注册的用户人数、统计各平台的用户人数、统计支付金额topN的用户
2.2 项目框架
2.2.1 技术选型
一、数据存储:Hdfs
二、数据处理:Hive、Spark
三、任务调度:Azkaban
2.2.2 流程设计
2.2.3 框架版本选型


第3章 用户注册模块需求
3.1原始数据格式及字段含义
1.baseadlog 广告基础表原始json数据
{
"adid": "0", //基础广告表广告id
"adname": "注册弹窗广告0", //广告详情名称
"dn": "webA" //网站分区
}
- basewebsitelog 网站基础表原始json数据
{
"createtime": "2000-01-01",
"creator": "admin",
"delete": "0",
"dn": "webC", //网站分区
"siteid": "2", //网站id
"sitename": "114", //网站名称
"siteurl": "www.114.com/webC" //网站地址
}
- memberRegtype 用户跳转地址注册表
{
"appkey": "-",
"appregurl": "http:www.webA.com/product/register/index.html", //注册时跳转地址
"bdp_uuid": "-",
"createtime": "2015-05-11",
"dt":"20190722", //日期分区
"dn": "webA", //网站分区
"domain": "-",
"isranreg": "-",
"regsource": "4", //所属平台 1.PC 2.MOBILE 3.APP 4.WECHAT
"uid": "0", //用户id
"websiteid": "0" //对应basewebsitelog 下的siteid网站
}
- pcentermempaymoneylog 用户支付金额表
{
"dn": "webA", //网站分区
"paymoney": "162.54", //支付金额
"siteid": "1", //网站id对应 对应basewebsitelog 下的siteid网站
"dt":"20190722", //日期分区
"uid": "4376695", //用户id
"vip_id": "0" //对应pcentermemviplevellog vip_id
}
- pcentermemviplevellog用户vip等级基础表
{
"discountval": "-",
"dn": "webA", //网站分区
"end_time": "2019-01-01", //vip结束时间
"last_modify_time": "2019-01-01",
"max_free": "-",
"min_free": "-",
"next_level": "-",
"operator": "update",
"start_time": "2015-02-07", //vip开始时间
"vip_id": "2", //vip id
"vip_level": "银卡" //vip级别名称
}
- memberlog 用户基本信息表
{
"ad_id": "0", //广告id
"birthday": "1981-08-14", //出生日期
"dt":"20190722", //日期分区
"dn": "webA", //网站分区
"email": "test@126.com",
"fullname": "王69239", //用户姓名
"iconurl": "-",
"lastlogin": "-",
"mailaddr": "-",
"memberlevel": "6", //用户级别
"password": "123456", //密码
"paymoney": "-",
"phone": "13711235451", //手机号
"qq": "10000",
"register": "2016-08-15", //注册时间
"regupdatetime": "-",
"uid": "69239", //用户id
"unitname": "-",
"userip": "123.235.75.48", //ip地址
"zipcode": "-"
}
其余字段为非统计项 直接使用默认值“-”存储即可
3.2数据分层
在hadoop集群上创建 ods目录
hadoop dfs -mkdir -p /user/atguigu/ods
在hive里分别建立三个库,dwd、dws、ads 分别用于存储etl清洗后的数据、宽表和拉链表数据、各报表层统计指标数据。
create database dwd;
create database dws;
create database ads;
各层级 ods 存放原始数据
dwd 结构与原始表结构保持一致,对ods层数据进行清洗
dws 以dwd为基础进行轻度汇总
ads 报表层,为各种统计报表提供数据
各层建表语句:
表模型:
dwd层 6张基础表

dws层 宽表和拉链表
宽表
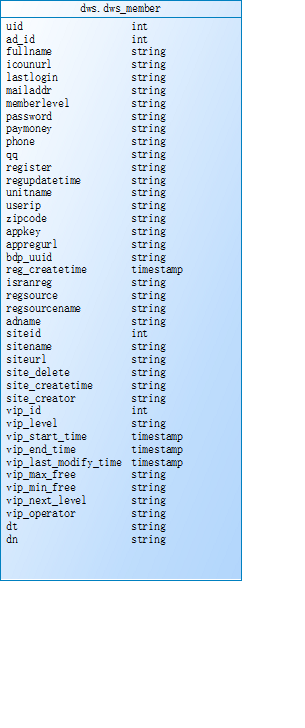
拉链表

报表层各统计表

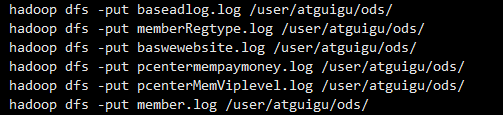
3.3模拟数据采集上传数据
模拟数据采集 将日志文件数据直接上传到hadoop集群上,
3.4 ETL数据清洗
需求1:必须使用Spark进行数据清洗,对用户名、手机号、密码进行脱敏处理,并使用Spark将数据导入到dwd层hive表中
清洗规则 用户名:王XX 手机号:137*****789 密码直接替换成******
3.5基于dwd层表合成dws层的宽表
需求2:对dwd层的6张表进行合并,生成一张宽表,先使用Spark Sql实现。有时间的同学需要使用DataFrame api实现功能,并对join进行优化。
3.6拉链表
需求3:针对dws层宽表的支付金额(paymoney)和vip等级(vip_level)这两个会变动的字段生成一张拉链表,需要一天进行一次更新
3.7报表层各指标统计
需求4:使用Spark DataFrame Api统计通过各注册跳转地址(appregurl)进行注册的用户数

需求5:使用Spark DataFrame Api统计各所属网站(sitename)的用户数

需求6:使用Spark DataFrame Api统计各所属平台的(regsourcename)用户数
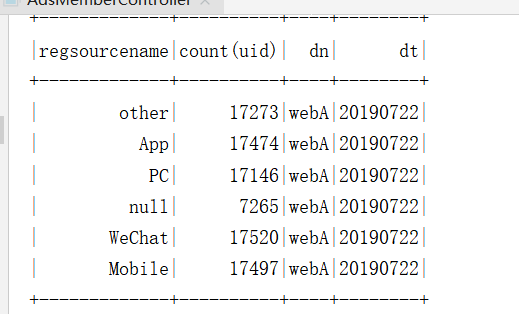
需求7:使用Spark DataFrame Api统计通过各广告跳转(adname)的用户数
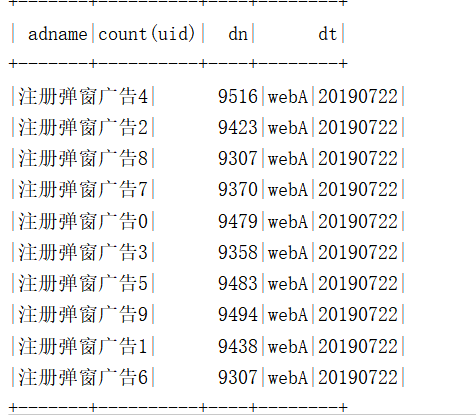
需求8:使用Spark DataFrame Api统计各用户级别(memberlevel)的用户数

需求9:使用Spark DataFrame Api统计各vip等级人数

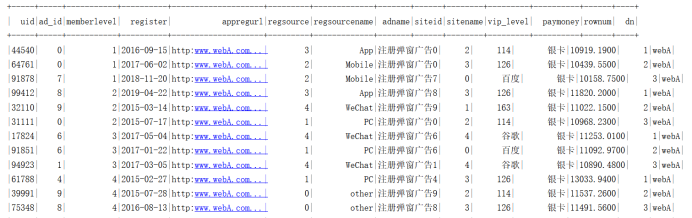
需求10:使用Spark DataFrame Api统计各分区网站、用户级别下(website、memberlevel)的top3用户
第4章 用户做题模块需求
4.1原始数据格式及字段含义
- QzWebsite.log 做题网站日志数据
{
"createtime": "2019-07-22 11:47:18", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"domain": "-",
"dt": "20190722", //日期分区
"multicastgateway": "-",
"multicastport": "-",
"multicastserver": "-",
"sequence": "-",
"siteid": 0, //网站id
"sitename": "sitename0", //网站名称
"status": "-",
"templateserver": "-"
}
- QzSiteCourse.log 网站课程日志数据
{
"boardid": 64, //课程模板id
"coursechapter": "-",
"courseid": 66, //课程id
"createtime": "2019-07-22 11:43:32", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"helpparperstatus": "-",
"sequence": "-",
"servertype": "-",
"showstatus": "-",
"sitecourseid": 2, //网站课程id
"sitecoursename": "sitecoursename2", //网站课程名称
"siteid": 77, //网站id
"status": "-"
}
- QzQuestionType.log 题目类型数据
{
"createtime": "2019-07-22 10:42:47", //创建时间
"creator": "admin", //创建者
"description": "-",
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"papertypename": "-",
"questypeid": 0, //做题类型id
"quesviewtype": 0,
"remark": "-",
"sequence": "-",
"splitscoretype": "-",
"status": "-",
"viewtypename": "viewtypename0"
}
- QzQuestion.log 做题日志数据
{
"analysis": "-",
"answer": "-",
"attanswer": "-",
"content": "-",
"createtime": "2019-07-22 11:33:46", //创建时间
"creator": "admin", //创建者
"difficulty": "-",
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"lecture": "-",
"limitminute": "-",
"modifystatus": "-",
"optnum": 8,
"parentid": 57,
"quesskill": "-",
"questag": "-",
"questionid": 0, //题id
"questypeid": 57, //题目类型id
"quesviewtype": 44,
"score": 24.124501582742543, //题的分数
"splitscore": 0.0,
"status": "-",
"vanalysisaddr": "-",
"vdeoaddr": "-"
}
- QzPointQuestion.log 做题知识点关联数据
{
"createtime": "2019-07-22 09:16:46", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"pointid": 0, //知识点id
"questionid": 0, //题id
"questype": 0
}
- QzPoint.log 知识点数据日志
{
"chapter": "-", //所属章节
"chapterid": 0, //章节id
"courseid": 0, //课程id
"createtime": "2019-07-22 09:08:52", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"excisenum": 73,
"modifystatus": "-",
"pointdescribe": "-",
"pointid": 0, //知识点id
"pointlevel": "9", //知识点级别
"pointlist": "-",
"pointlistid": 82, //知识点列表id
"pointname": "pointname0", //知识点名称
"pointnamelist": "-",
"pointyear": "2019", //知识点所属年份
"remid": "-",
"score": 83.86880766562163, //知识点分数
"sequece": "-",
"status": "-",
"thought": "-",
"typelist": "-"
}
- QzPaperView.log 试卷视图数据
{
"contesttime": "2019-07-22 19:02:19",
"contesttimelimit": "-",
"createtime": "2019-07-22 19:02:19", //创建时间
"creator": "admin", //创建者
"dayiid": 94,
"description": "-",
"dn": "webA", //网站分区
"downurl": "-",
"dt": "20190722", //日期分区
"explainurl": "-",
"iscontest": "-",
"modifystatus": "-",
"openstatus": "-",
"paperdifficult": "-",
"paperid": 83, //试卷id
"paperparam": "-",
"papertype": "-",
"paperuse": "-",
"paperuseshow": "-",
"paperviewcatid": 1,
"paperviewid": 0, //试卷视图id
"paperviewname": "paperviewname0", //试卷视图名称
"testreport": "-"
}
- QzPaper.log 做题试卷日志数据
{
"chapter": "-", //章节
"chapterid": 33, //章节id
"chapterlistid": 69, //所属章节列表id
"courseid": 72, //课程id
"createtime": "2019-07-22 19:14:27", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"papercatid": 92,
"paperid": 0, //试卷id
"papername": "papername0", //试卷名称
"paperyear": "2019", //试卷所属年份
"status": "-",
"suitnum": "-",
"totalscore": 93.16710017696484 //试卷总分
}
- QzMemberPaperQuestion.log 学员做题详情数据
{
"chapterid": 33, //章节id
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"istrue": "-",
"lasttime": "2019-07-22 11:02:30",
"majorid": 77, //主修id
"opertype": "-",
"paperid": 91,//试卷id
"paperviewid": 37, //试卷视图id
"question_answer": 1, //做题结果(0错误 1正确)
"questionid": 94, //题id
"score": 76.6941793631127, //学员成绩分数
"sitecourseid": 1, //网站课程id
"spendtime": 4823, //所用时间单位(秒)
"useranswer": "-",
"userid": 0 //用户id
}
- QzMajor.log 主修数据
{
"businessid": 41, //主修行业id
"columm_sitetype": "-",
"createtime": "2019-07-22 11:10:20", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"majorid": 1, //主修id
"majorname": "majorname1", //主修名称
"sequence": "-",
"shortname": "-",
"siteid": 24, //网站id
"status": "-"
}
- QzCourseEduSubject.log 课程辅导数据
{
"courseeduid": 0, //课程辅导id
"courseid": 0, //课程id
"createtime": "2019-07-22 11:14:43", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"edusubjectid": 44, //辅导科目id
"majorid": 38 //主修id
}
- QzCourse.log 题库课程数据
{
"chapterlistid": 45, //章节列表id
"courseid": 0, //课程id
"coursename": "coursename0", //课程名称
"createtime": "2019-07-22 11:08:15", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"isadvc": "-",
"majorid": 39, //主修id
"pointlistid": 92, //知识点列表id
"sequence": "8128f2c6-2430-42c7-9cb4-787e52da2d98",
"status": "-"
}
- QzChapterList.log 章节列表数据
{
"chapterallnum": 0, //章节总个数
"chapterlistid": 0, //章节列表id
"chapterlistname": "chapterlistname0", //章节列表名称
"courseid": 71, //课程id
"createtime": "2019-07-22 16:22:19", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"status": "-"
}
- QzChapter.log 章节数据
{
"chapterid": 0, //章节id
"chapterlistid": 0, //所属章节列表id
"chaptername": "chaptername0", //章节名称
"chapternum": 10, //章节个数
"courseid": 61, //课程id
"createtime": "2019-07-22 16:37:24", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"outchapterid": 0,
"sequence": "-",
"showstatus": "-",
"status": "-"
}
- QzCenterPaper.log 试卷主题关联数据
{
"centerid": 55, //主题id
"createtime": "2019-07-22 10:48:30", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"openstatus": "-",
"paperviewid": 2, //视图id
"sequence": "-"
}
- QzCenter.log 主题数据
{
"centerid": 0, //主题id
"centername": "centername0", //主题名称
"centerparam": "-",
"centertype": "3", //主题类型
"centerviewtype": "-",
"centeryear": "2019", //主题年份
"createtime": "2019-07-22 19:13:09", //创建时间
"creator": "-",
"description": "-",
"dn": "webA",
"dt": "20190722", //日期分区
"openstatus": "1",
"provideuser": "-",
"sequence": "-",
"stage": "-"
}
Centerid:主题id centername:主题名称 centertype:主题类型 centeryear:主题年份
createtime:创建时间 dn:网站分区 dt:日期分区
- QzBusiness.log 所属行业数据
{
"businessid": 0, //行业id
"businessname": "bsname0", //行业名称
"createtime": "2019-07-22 10:40:54", //创建时间
"creator": "admin", //创建者
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"sequence": "-",
"siteid": 1, //所属网站id
"status": "-"
}
4.2模拟数据采集上传数据
4.3解析数据
需求1:使用spark解析ods层数据,将数据存入到对应的hive表中,要求对所有score 分数字段进行保留1位小数并且四舍五入。
4.4维度退化
需求2:基于dwd层基础表数据,需要对表进行维度退化进行表聚合,聚合成dws.dws_qz_chapter(章节维度表),dws.dws_qz_course(课程维度表),dws.dws_qz_major(主修维度表),dws.dws_qz_paper(试卷维度表),dws.dws_qz_question(题目维度表),使用spark sql和dataframe api操作

dws.dws_qz_chapte : 4张表join dwd.dwd_qz_chapter inner join dwd.qz_chapter_list join条件:chapterlistid和dn ,inner join dwd.dwd_qz_point join条件:chapterid和dn, inner join dwd.dwd_qz_point_question join条件:pointid和dn
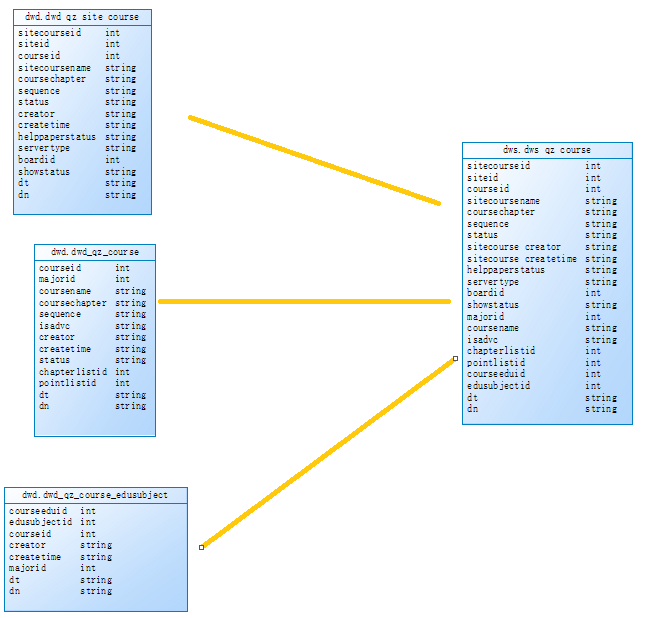
dws.dws_qz_course:3张表join dwd.dwd_qz_site_course inner join dwd.qz_course join条件:courseid和dn , inner join dwd.qz_course_edusubject join条件:courseid和dn
dws.dws_qz_major:3张表join dwd.dwd_qz_major inner join dwd.dwd_qz_website join条件:siteid和dn , inner join dwd.dwd_qz_business join条件:businessid和dn

dws.dws_qz_paper: 4张表join qz_paperview left join qz_center join 条件:paperviewid和dn,
left join qz_center join 条件:centerid和dn, inner join qz_paper join条件:paperid和dn
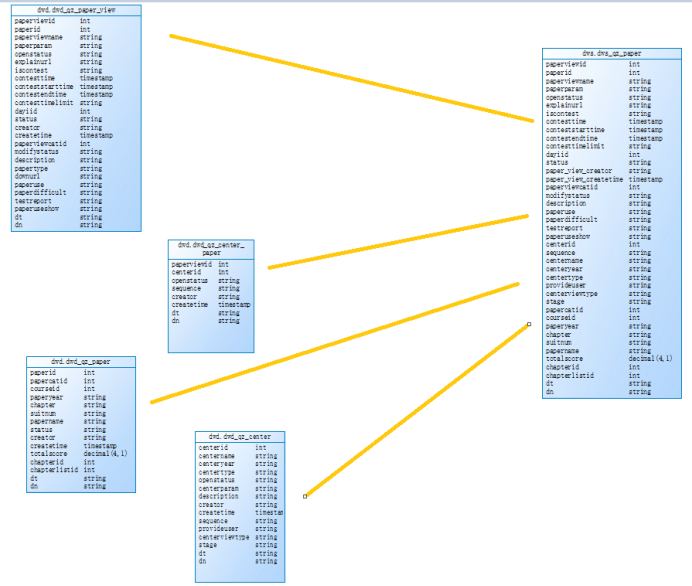
dws.dws_qz_question:2表join qz_quesiton inner join qz_questiontype join条件:
questypeid 和dn

4.5宽表合成
需求3:基于dws.dws_qz_chapter、dws.dws_qz_course、dws.dws_qz_major、dws.dws_qz_paper、dws.dws_qz_question、dwd.dwd_qz_member_paper_question 合成宽表dw.user_paper_detail,使用spark sql和dataframe api操作
dws.user_paper_detail:dwd_qz_member_paper_question inner join dws_qz_chapter join条件:chapterid 和dn ,inner join dws_qz_course join条件:sitecourseid和dn , inner join dws_qz_major join条件majorid和dn, inner join dws_qz_paper 条件paperviewid和dn , inner join dws_qz_question 条件questionid和
4.6报表层各指标统计
需求4:基于宽表统计各试卷平均耗时、平均分,先使用Spark Sql 完成指标统计,再使用Spark DataFrame Api。
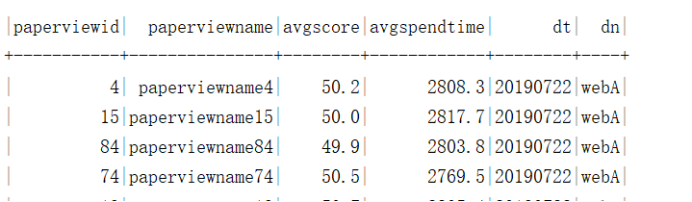
需求5:统计各试卷最高分、最低分,先使用Spark Sql 完成指标统计,再使用Spark DataFrame Api。
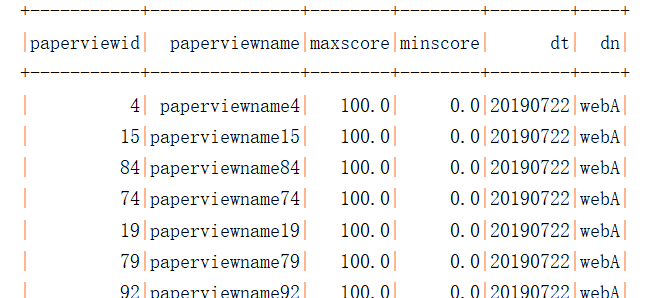
需求6:按试卷分组统计每份试卷的前三用户详情,先使用Spark Sql 完成指标统计,再使用Spark DataFrame Api。

需求7:按试卷分组统计每份试卷的倒数前三的用户详情,先使用Spark Sql 完成指标统计,再使用Spark DataFrame Api。

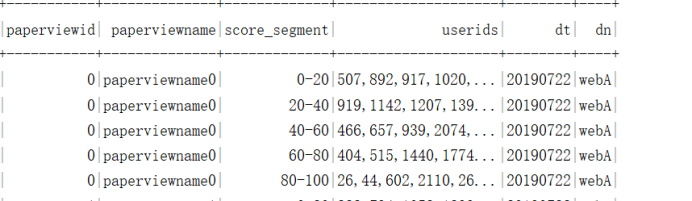
需求8:统计各试卷各分段的用户id,分段有0-20,20-40,40-60,60-80,80-100
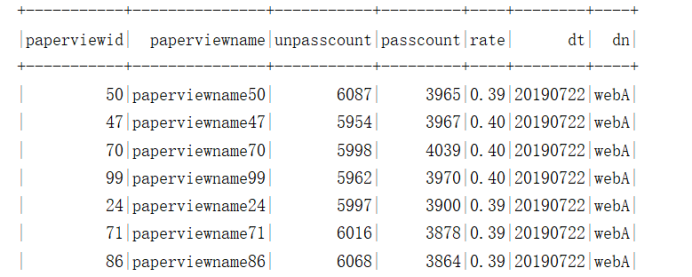
需求9:统计试卷未及格的人数,及格的人数,试卷的及格率 及格分数60
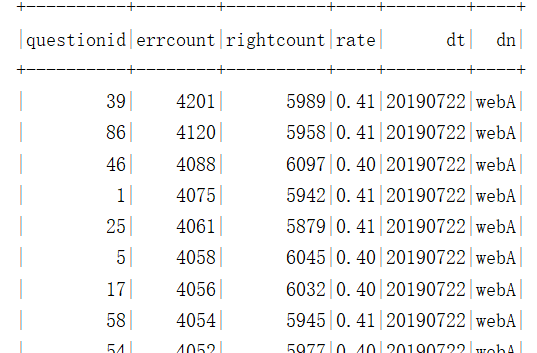
需求10:统计各题的错误数,正确数,错题率
4.7将数据导入mysql
需求11:统计指标数据导入到ads层后,通过datax将ads层数据导入到mysql中
第5章 售课模块
5.1原始数据格式及字段含义
1.salecourse.log 售课基本数据
{
"chapterid": 2, //章节id
"chaptername": "chaptername2", //章节名称
"courseid": 0, //课程id
"coursemanager": "admin", //课程管理员
"coursename": "coursename0", //课程名称
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"edusubjectid": 7, //辅导科目id
"edusubjectname": "edusubjectname7", //辅导科目名称
"majorid": 9, //主修id
"majorname": "majorname9", //主修名称
"money": "100", //课程价格
"pointlistid": 9, //知识点列表id
"status": "-", //状态
"teacherid": 8, //老师id
"teachername": "teachername8" //老师名称
}
- courseshoppingcart.log 课程购物车信息
{
"courseid": 9830, //课程id
"coursename": "coursename9830", //课程名称
"createtime": "2019-07-22 00:00:00", //创建时间
"discount": "8", //折扣
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"orderid": "odid-0", //订单id
"sellmoney": "80" //购物车金额
}
3.coursepay.log 课程支付订单信息
{
"createitme": "2019-07-22 00:00:00", //创建时间
"discount": "8", //支付折扣
"dn": "webA", //网站分区
"dt": "20190722", //日期分区
"orderid": "odid-0", //订单id
"paymoney": "80" //支付金额
}
5.2模拟数据采集上传数据
Hadoop dfs -put salecourse.log /user/atguigu/ods
Hadoop dfs -put coursepay.log /user/atguigu/ods
Hadoop dfs -put courseshoppingcart.log /user/atguigu/ods
5.3解析数据导入到对应hive表中
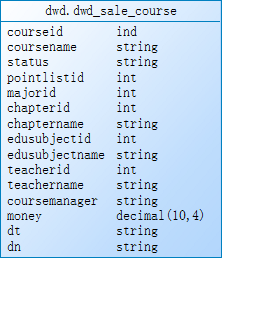
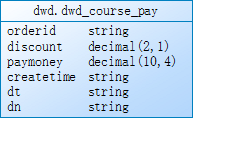

5.4关联join聚合表
dwd.dwd_sale_course 与dwd.dwd_course_shopping_cart join条件:courseid、dn、dt
dwd.dwd_course_shopping_cart 与dwd.dwd_course_pay join条件:orderid、dn、dt
不允许丢数据,关联不上的字段为null,join之后导入dws层的表
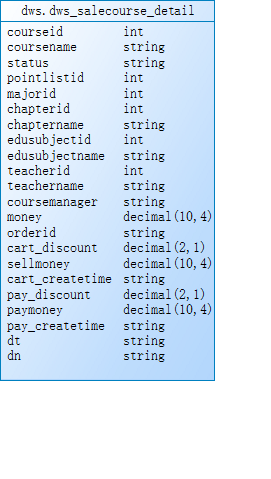
5.5要求
1:通过Spark UI观察每个task的运行情况、数据量
2:解决数据倾斜问题
第6章 思考
(1)第一层表哪些用overwrite合适,哪些用append合适
(2)数据过滤后,重组成需要的数据进行插入表的时候如何控制分区个数,即如何解决小文件过多问题。
(3)合成宽表时一个用户会对应多条明细支付金额数据,如何合并
(4)分区的场景和作用,为什么需要分区
代码例子
def etlBaseWebSiteLog(ssc: SparkContext, sparkSession: SparkSession) = {
import sparkSession.implicits._ //隐式转换
ssc.textFile("/user/atguigu/ods/baswewebsite.log").mapPartitions(partition => {
partition.map(item => {
val jsonObject = ParseJsonData.getJsonData(item)
val siteid = jsonObject.getIntValue("siteid")
val sitename = jsonObject.getString("sitename")
val siteurl = jsonObject.getString("siteurl")
val delete = jsonObject.getIntValue("delete")
val createtime = jsonObject.getString("createtime")
val creator = jsonObject.getString("creator")
val dn = jsonObject.getString("dn")
(siteid, sitename, siteurl, delete, createtime, creator, dn)
})
}).toDF().coalesce(1).write.mode(SaveMode.Overwrite).insertInto("dwd.dwd_base_website")
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号