
【Python】BeautifulSoup的简单使用
BeautifulSoup是解析网页的基本库之一。简单用法如下:
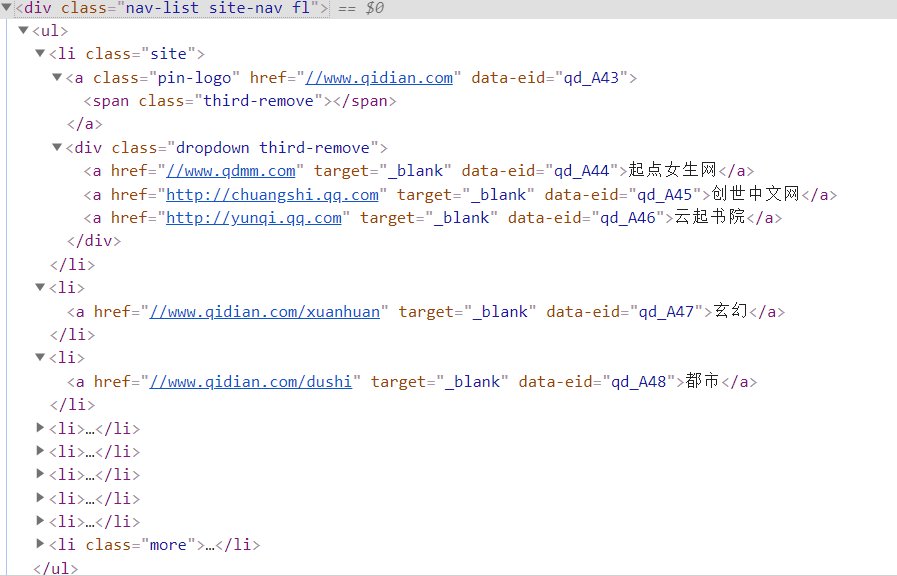
这里选取class为“nav-list site-nav fl”的div标签,如上图所示
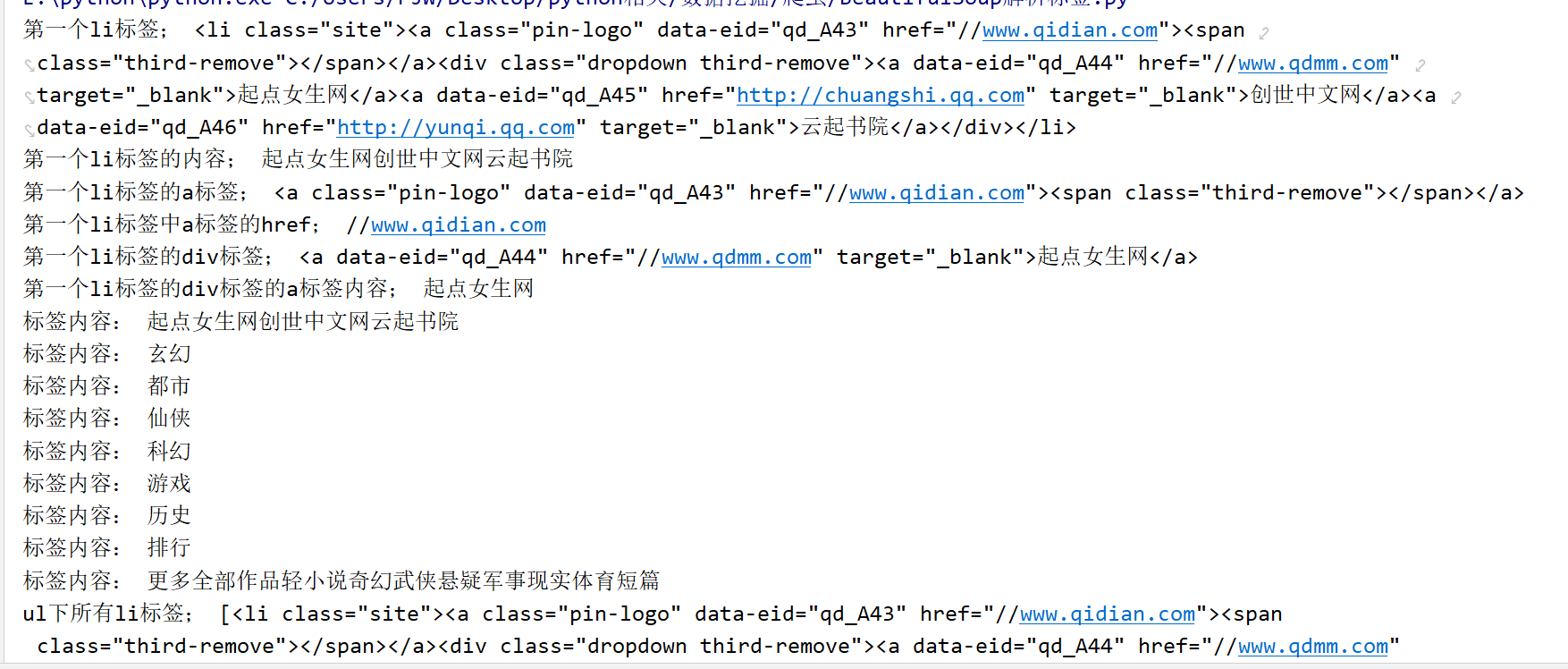
from bs4 import BeautifulSoup div = '<div class="nav-list site-nav fl"><ul><li class="site"><a class="pin-logo" href="//www.qidian.com" data-eid="qd_A43"><span class="third-remove"></span></a><div class="dropdown third-remove"><a href="//www.qdmm.com" target="_blank" data-eid="qd_A44">起点女生网</a><a href="http://chuangshi.qq.com" target="_blank" data-eid="qd_A45">创世中文网</a><a href="http://yunqi.qq.com" target="_blank" data-eid="qd_A46">云起书院</a></div></li><li><a href="//www.qidian.com/xuanhuan" target="_blank" data-eid="qd_A47">玄幻</a></li><li><a href="//www.qidian.com/dushi" target="_blank" data-eid="qd_A48">都市</a></li><li><a href="//www.qidian.com/xianxia" target="_blank" data-eid="qd_A49">仙侠</a></li><li><a href="//www.qidian.com/kehuan" target="_blank" data-eid="qd_A50">科幻</a></li><li><a href="//www.qidian.com/youxi" target="_blank" data-eid="qd_A56">游戏</a></li><li><a href="//www.qidian.com/lishi" target="_blank" data-eid="qd_A52">历史</a></li><li><a href="//www.qidian.com/rank" target="_blank" data-eid="qd_A53">排行</a></li><li class="more"><a href="javascript:" id="top-nav-more" target="_blank" data-eid="qd_A54">更多<span></span></a><div class="dropdown"><a href="//www.qidian.com/all" target="_blank" data-eid="qd_A169">全部作品</a><a href="//www.qidian.com/2cy" target="_blank" data-eid="qd_A55">轻小说</a><a href="//www.qidian.com/qihuan" target="_blank" data-eid="qd_A51">奇幻</a><a href="//www.qidian.com/wuxia" target="_blank" data-eid="qd_A57">武侠</a><a href="//www.qidian.com/lingyi" target="_blank" data-eid="qd_A58">悬疑</a><a href="//www.qidian.com/junshi" target="_blank" data-eid="qd_A59">军事</a><a href="//www.qidian.com/xianshi" target="_blank" data-eid="qd_A60">现实</a><a href="//www.qidian.com/tiyu" target="_blank" data-eid="qd_A61">体育</a><a href="//www.qidian.com/duanpian" target="_blank" data-eid="qd_A196">短篇</a></div></li></ul></div>' soup = BeautifulSoup(div,"lxml") print("第一个li标签;",soup.ul.find("li",{"class":"site"}))#第一个li标签 #输出结果:<li class="site"><a class="pin-logo" data-eid="qd_A43" href="//www.qidian.com"><span class="third-remove"></span></a><div class="dropdown third-remove"><a data-eid="qd_A44" href="//www.qdmm.com" target="_blank">起点女生网</a><a data-eid="qd_A45" href="http://chuangshi.qq.com" target="_blank">创世中文网</a><a data-eid="qd_A46" href="http://yunqi.qq.com" target="_blank">云起书院</a></div></li> print("第一个li标签的内容;",soup.ul.find("li",{"class":"site"}).text) #标签内容 #输出结果:起点女生网创世中文网云起书院 print("第一个li标签的a标签;",soup.ul.find("li",{"class":"site"}).a)#第一个li标签的a标签 #输出结果:<a class="pin-logo" data-eid="qd_A43" href="//www.qidian.com"><span class="third-remove"></span></a> print("第一个li标签中a标签的href;",soup.ul.find("li",{"class":"site"}).a['href'])#a标签的href #输出结果://www.qidian.com print("第一个li标签的div标签;",soup.ul.find("li",{"class":"site"}).find("div",{"class":"dropdown third-remove"}).a) #输出结果:<a data-eid="qd_A44" href="//www.qdmm.com" target="_blank">起点女生网</a> print("第一个li标签的div标签的a标签内容;",soup.ul.find("li",{"class":"site"}).find("div",{"class":"dropdown third-remove"}).a.text)#a标签内容 #输出结果:起点女生网 childs = soup.ul.children #ul的子标签 for child in childs: print("标签内容:",child.text)#逐个打印其标签内容 print("ul下所有li标签;",soup.ul.find_all("li"))#ul下所有li标签,输出为列表
输出结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号