Kafka源码剖析_副本拉取日志流程
每篇一句:临渊羡鱼 不如退而结网
背景
在分布式系统中,数据复制、数据分区、事务、一致性是不可逃避的问题
作为分布式、高性能的流处理平台,Kafka通过副本来解决了数据复制的问题,它的副本机制是实现kafka数据高可靠的基础
kafka写入消息核心流程
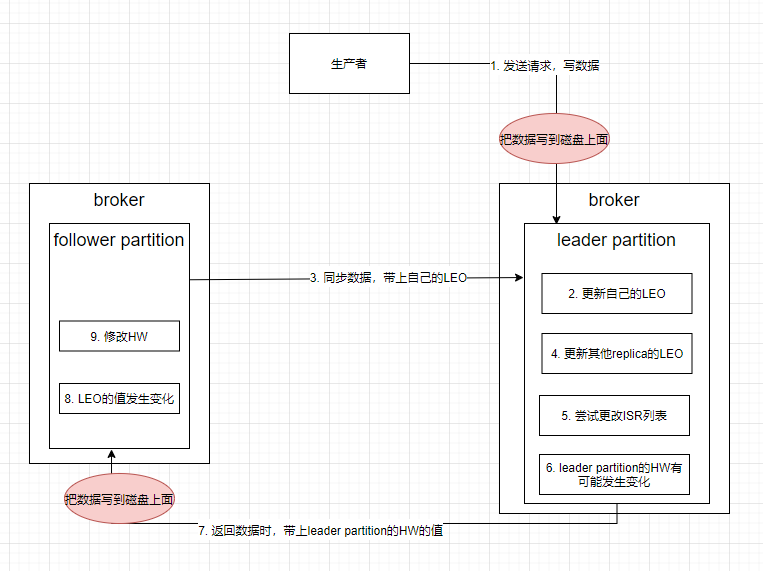
follower副本同步日志源码流程
kafka中每个topic都有N个分区,每个分区都有M个副本,每个副本的实体就是Replica
在kafka代码中,每个副本在创建时都会尝试成为leader,但是每个分区有且仅有一个leader副本,其余的副本都会成为follower
leader职责:响应客户端(produce、broker、comsumer)读写请求
follower职责:与leader同步消息
因此以下就从源码的角度分析,follower副本是如何进行日志同步的
//1. 尝试进行选举
ReplicaManager.becomeLeaderOrFollower()
▼
//2. 选举失败,无奈成为可怜的小Follower
ReplicaManager.makeFollowers()
—> 此方法最核心功能就是触发创建以及启动副本同步线程
replicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset)
▼
//3. 为分区添加副本同步线程
ReplicaFetcherManager.addFetcherForPartitions
—> 此方法最核心功能就是启动副本同步线程
val fetcherThread = createFetcherThread(brokerAndFetcherId.fetcherId, brokerAndFetcherId.broker)
fetcherThread.start()
▼
//4. 采用门面设计模式,其封装了副本同步线程的所有核心操作
AbstractFetcherThread.doWork()
▼
//5. 开始进行消息同步操作,同时此方法还会将返回的结果写入到本地副本的Log实例中
AbstractFetcherThread.processFetchRequest()
▼
//6. 发送网络请求给主replica
AbstractFetcherThread.fetch()
ReplicaFetcherThread.fetch()
▼
ReplicaFetcherThread.sendRequest()
▼
//7. 真正执行数据拉取操作的方法。KafkaApis是服务器端非常核心的一个类,它封装了很多重要的操作
KafkaApis.handleFetchRequest()
▼
//8. 将leader副本里fetch的数据写到follower副本节点的Log对象里,具体落地时间交由操作系统决定
ReplicaFetcherThread.processPartitionData()
副本常用配置
1. replica.fetch.max.bytes:指定副本间同步消息的最大值
此值需与message.max.bytes对齐,避免某条大消息可以写入kafka,但是在副本间却复制失败问题
2. num.replica.fetchers:每个broker用来做副本拉取的线程数量
3. replica.fetch.backoff.ms:距离下次follower副本fetch的时间间隔(避免无消息时频繁fetch导致无谓的资源损耗)
4. replica.fetch.wait.max.ms:单次fetch最大等待时间
核心类介绍
AbstractFetcherThread:ReplicaFetcherThread的抽线基类,实现了很多重要的字段和方法
abstract class AbstractFetcherThread(name: String, //线程名称
clientId: String, //用来标识拉取消息的线程
val sourceBroker: BrokerEndPoint, //Broker地址
failedPartitions: FailedPartitions, //处理过程中出现失败的分区
fetchBackOffMs: Int = 0, //获取操作重试间隔
isInterruptible: Boolean = true, //线程是否允许中断
val brokerTopicStats: BrokerTopicStats) //BrokerTopicStats's lifecycle managed by ReplicaManager
extends ShutdownableThread(name, isInterruptible) {
//定义拉取的数据类型,type是scala高阶用法,在需要做FetchResponse.PartitionData[Records] 的地方使用FetchData效果等同,但代码会显得更简洁
type FetchData = FetchResponse.PartitionData[Records]
//定义leader epoch的数据类型
type EpochData = OffsetsForLeaderEpochRequest.PartitionData
......
}
FetchData里定义的是PartitionData类型
public PartitionData(Errors error, //错误码
long highWatermark, //高水位
long lastStableOffset, //最新LSO值
long logStartOffset, //最新Log Start Offset值
//期望的Read Replica
//KAFKA 2.4后支持部分Follower副本对外提供服务
Optional<Integer> preferredReadReplica,
//该分区对应的已终止事务列表
List<AbortedTransaction> abortedTransactions,
Optional<FetchResponseData.EpochEndOffset> divergingEpoch,
//消息集合,最重要的字段
T records)
ReplicaManager:负责管理和操作Broker中的副本(这个类非常重要,是构建kafka副本同步机制的重要组件之一)
public class ReplicaManager(val config: KafkaConfig, //配置管理类
metrics: Metrics, //监控指标项
time: Time, //定时器
val zkClient: KafkaZkClient, //Zookeeper客户端
scheduler: Scheduler, //Kafka调度器
val logManager: LogManager, //日志管理器。负责创建和管理分区的日志对象,里面定义了很多操作日志对象的方法
val isShuttingDown: AtomicBoolean, //是否已经关闭
quotaManagers: QuotaManagers, //配额管理器
val brokerTopicStats: BrokerTopicStats, //Broker主题监控指标类
val metadataCache: MetadataCache, //Broker元数据缓存
logDirFailureChannel: LogDirFailureChannel,
//处理延时PRODUCE请求的Purgatory
val delayedProducePurgatory: DelayedOperationPurgatory[DelayedProduce],
//处理延时FETCH请求的Purgatory
val delayedFetchPurgatory: DelayedOperationPurgatory[DelayedFetch],
//处理延时DELETE_RECORDS请求的Purgatory
val delayedDeleteRecordsPurgatory: DelayedOperationPurgatory[DelayedDeleteRecords],
//处理延时ELECT_LEADERS请求的Purgatory
val delayedElectLeaderPurgatory: DelayedOperationPurgatory[DelayedElectLeader],
threadNamePrefix: Option[String],
val alterIsrManager: AlterIsrManager) extends Logging with KafkaMetricsGroup {
}
ReplicaManager的两大核心方法
def appendRecords(timeout: Long, //请求处理超时时间
requiredAcks: Short, //是否需要等待其他副本写入
internalTopicsAllowed: Boolean,
origin: AppendOrigin, //写入方来源
entriesPerPartition: Map[TopicPartition, MemoryRecords], //按分区分组,实际要写入的消息集合
responseCallback: Map[TopicPartition, PartitionResponse] => Unit, //写入成功后,要执行回调的逻辑函数
delayedProduceLock: Option[Lock] = None, //专属保护消费者组操作线程安全的锁对象
recordConversionStatsCallback: Map[TopicPartition, RecordConversionStats] => Unit = _ => ()): Unit = { //消息格式转换操作的回调统计逻辑
......
appendToLocalLog(internalTopicsAllowed = internalTopicsAllowed, origin, entriesPerPartition, requiredAcks)
......
delayedProduceRequestRequired(requiredAcks, entriesPerPartition, localProduceResults)
......
}
---
def fetchMessages(timeout: Long, //请求处理超时时间
replicaId: Int, //副本ID
fetchMinBytes: Int, //能够获取的最小字节数
fetchMaxBytes: Int, //能够获取的最大字节数
hardMaxBytesLimit: Boolean, //对能否超过最大字节数做硬限制
fetchInfos: Seq[(TopicPartition, PartitionData)], //规定了读取分区的信息
quota: ReplicaQuota, //配额控制类,判断读取过程中是否做限速控制
responseCallback: Seq[(TopicPartition, FetchPartitionData)] => Unit, //Response回调逻辑函数
isolationLevel: IsolationLevel,
clientMetadata: Option[ClientMetadata]): Unit = {
//读取本地日志
//根据读取结果确定Response
}
小结
1、kafka的数据其实并没有真正落地到磁盘,仅写到内存中就向客户端返回结果。(副本本质就是一份数据写到多台服务器的内存中,既保证高性能,又能保证数据高可靠)
在对数据可靠性要求比较严格的场景,可设置kafka数据落盘时间定期将内存数据刷写磁盘,但性能方面会有损耗
2、本篇文章仅是大致走一下副本拉取数据的流程(方便后期相关源码阅读),屏蔽了不少细节,如想了解更多的细节可阅读参考文档
参考文档
- replica副本同步机制:https://www.cnblogs.com/zhy-heaven/p/10994122.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号