awk,sed,cut,uniq
一. cut 列提取命令
cut [选项] 文件名 -f 列号:提取第几列
-d 分隔符:按照指定的分割符进行分割
-c 字符范围:不依赖分割符来分割,而是通过字符范围进行字段提取(“-m”表示从第一个字符提取到第m个,“n-m”表示从第n提取到第m个字符,“n-”表示从第n个字符开始
提取到结尾)
#cut 命令默认的分割符是制表符,即tab键,对于空格的支持比较差
1.文本内容,用制表符分割
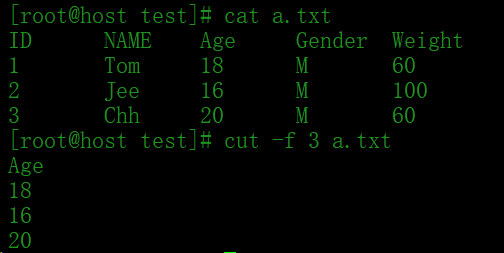


[root@host test]# cat a.txt ID NAME Age Gender Weight 1 Tom 18 M 60 2 Jee 16 M 100 3 Chh 20 M 60
awk 输出格式和输出类型
输出类型: %ns 输出字符串。n是数字指代输出几个字符 %ni 输出整数。n是数字指代输出几个数字 %m.nf 输出浮点数。m和n是数字,指 整数位数和小数位数。如;%8.2f 代表:2位小数,6位整数 输出格式: \a 输出警告声音 \b 输出退格键(Backspace键) \f 清除屏幕 \n 换行 \r 回车(Enter键) \t 水平输出退格键(Tab键) \v 垂直输出退格键(Tab键)
二. awk
A.语法:
awk '条件1{动作1} 条件2{动作2} ...' 文件名
条件:一般使用关系表达式作为条件 x>10 判断x变量是否大于10 x==y 判断变量x是否等于变量y A ~ B 判断字符串A中是否包含能匹配B表达式的字符串 A!~ B 判断字符串A中是否不包含能匹配B表达式的字符串
例:格式化输出

printf是标准的格式化输出,必须手动指定输出类型和输出格式。
B.awk的条件
1.BEGIN是awk的保留字,是一种特殊的条件类型。BEGIN的执行时机是“在awk程序一开始时,尚未读取任何数据之前执行”。所以BEGIN定义的动作只能被执行一次。整个命令定义了两个动作,先打印“Hello World”,然后输出过滤后的2和4列。
[root@host test]# cat a.txt ID NAME Age Gender Weight 1 Tom 18 M 60 2 Jee 16 M 100 3 Chh 20 M 60 [root@host test]# awk 'BEGIN{printf "Hello World \n"}{printf $2 "\t" $4 "\n"}' a.txt Hello World NAME Gender Tom M Jee M Chh M
2.END也是awk保留字,不过刚好和BEGIN相反。END是在awk程序处理完所有数据,即将结束时执行时执行。END后的动作只在程序结束时执行一次。
[root@host test]# awk 'END{printf "Hello World \n"}{printf $2 "\t" $4 "\n"}' a.txt NAME Gender Tom M Jee M Chh M Hello World
3.运算符
设定条件,符合条件的才会进行相应动作,不满足不运行

识别字符串用 //
[root@host test]# cat a.txt ID NAME Age Gender Weight 1 Tom 18 M 80 2 Jee 16 M 100 3 Chh 20 M 50 [root@host test]# awk '$2 ~ /Tom/ {printf $3 "\n"}' a.txt 18 [root@host test]# awk '$2 ~ /Tom/ {printf $3 "\n"}' a.txt 18 [root@host test]# awk '/Chh/ {printf $0 "\n"}' a.txt 3 Chh 20 M 50 [root@host test]# awk '/Chh/ {print}' a.txt 3 Chh 20 M 50
截取 df -h
[root@master ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 986M 4.0K 986M 1% /dev tmpfs 997M 0 997M 0% /dev/shm tmpfs 997M 41M 957M 5% /run tmpfs 997M 0 997M 0% /sys/fs/cgroup /dev/vda1 40G 2.8G 35G 8% / tmpfs 200M 0 200M 0% /run/user/0 [root@master ~]# df -h |awk '/vda/ {printf $1 "\t" $5 "\n"}' /dev/vda1 8% [root@master ~]# df -h | awk '{printf $2 "\t" $3 "\n"}' Size Used 986M 4.0K 997M 0 997M 41M 997M 0 40G 2.8G 200M 0
C. awk 内置变量
内置变量 作用
$0 代表awk读入的一整行数据
$n 代表awk读入的当前行的第n列数据
NR 代表当前awk正在处理的行的行号
NF 代表当前awk读取数据总字段数(列)
FS 用来声明awk的分隔符,如{FS=:}
1./etc/passwd
[root@master ~]# cat /etc/passwd |grep "/bin/bash" | awk 'BEGIN {FS=":"} {printf $1 "\t" $3 "\n"}' root 0 admin 1000 tom 1001
2.
D.awk流程控制
因命令语句长,输入格式时需注意:
1.多个条件{动作}可以用空格分割,也可以用回车分割。
2.在一个动作中,如果需要执行多个命令,需要用“;”分割,或用回车分割。
3.在awk中,变量的赋值与调用都不需要加入“$”符。
4. 条件中判断两个值是否相同,请使用“==”,以便和变量赋值进行区分。
1,若年龄小于30,则输出 $2 is Hello!
[root@host test]# awk '{if (NR>=2){if ($3<30) printf $2 " is Hello!\n"}}' a.txt Tom is Hello! Jee is Hello! Chh is Hello!
2.统计当前文件夹下的文件/文件夹占用的大小
[root@c1 work]# ll 总用量 12 -rw-r--r-- 1 root root 18 3月 28 14:26 123.txt -rw-r--r-- 1 root root 18 3月 28 14:26 abc.txt -rw-r--r-- 1 root root 1330 3月 28 10:54 passwd [root@c1 work]# ls -l|awk 'BEGIN{size=0}{size+=$5} END{print "Size is:" size }' Size is:1366 [root@c1 work]# ls -l|awk 'BEGIN{size=0}{size+=$5} END{print "Size is:" size/1024/1024 "M" }' Size is:0.00130272M
3.统计显示/etc/passwd的账号总人数
[root@c1 work]# awk -F':' 'BEGIN{count=0}$1!~/^$/{count++} END{print "Count=" count}' passwd #排除空行可能 Count=28
4.统计UID大于100的用户名
[root@c1 work]# awk -F':' 'BEGIN{count=0}{if($3>100) name[count++]=$1} END{for(i=0;i<count;i++) print i,name[i]}' passwd 0 systemd-bus-proxy 1 systemd-network 2 polkitd 3 libstoragemgmt 4 abrt 5 chrony
5.统计 netstat -anp 状态下为CONNECTED和LISTEN的连接数
[root@c1 work]# netstat -anp|awk '$6~/CONNECTED|LISTEN/{sum[$6]++} END{for(i in sum) print i,sum[i]}' LISTEN 6 CONNECTED 90
E.awk函数
定义:
function 函数名 (参数列表){
函数体
}
1.通过定义的函数格式,去匹配并传递参数
[root@host test]# awk 'function test(a,b) {printf a "\t" b "\n"}{ test($2,$5) }' a.txt NAME Weight Tom 80 Jee 100 Chh 50 Ayy 70
F.awk中调用脚本
对于小的单行程序来说,将脚本作为命令行自变量传递给awk是非常简单的,而对于多行程序就比较难处理。当程序是多行的时候,使用外部脚本是很适合的。首先在外部文件中写好脚本,然后可以使用 awk -f 选项,使其读入脚本并执行。
[root@host test]# cat pass.awk #!/bin/bash BEGIN {FS=":"} {print $1 "\t" $3} [root@host test]# awk -f pass.awk /etc/passwd
awk 与sed
#awk 和 sed 都可以处理文本 #awk 侧重于复杂逻辑处理 #sed 侧重于正则处理
三. sed命令
sed主要:进行数据选取,替换,删除,新增的命令
选项:
-n: 一般sed命令会把所有数据都输出到屏幕,如果加入此选择,则只会把经过sed命令处理的行输出到屏幕。 -e: 允许对输入数据应用多条sed命令编辑。 -f: 脚本文件名:从sed脚本中读入sed操作。和awk命令的-f非常类似。 -r: 在sed中支持扩展正则表达式。 -i: 用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出
动作:
p: 打印,输出指定的行 d: 删除,删除指定的行 s: 字串替换,用一个字符串替换另外一个字符串。格式为“行范围s/ 旧字串/新字串/g”(和vim中的替换格式类似) a \:追加,在当前行后添加一行或多行。添加多行时,除最后一行外,每行末尾需要用“\”代表数据未完结。 i \:插入,在当期行前插入一行或多行。插入多行时,除最后一行外,每行末尾需要用“\”代表数据未完结。 c \:整行替换,用c后面的字符串替换原数据行,替换多行时,除最后一行外,每行末尾需用“\”代表数据未完结。
注:使用sed命令,它所有的修改都不会直接修改文件的内容,而是在内存中进行处理然后打印到屏幕上,使用 -i 选项才会保存到文本中。
A.行数据操作
1.显示某行的信息
[root@host test]# vim a.txt ID NAME Age Gender Weight 1 Tom 18 M 60 2 Jee 16 M 100 3 Chh 20 M 50 4 Ayy 30 W 70 [root@host test]# sed -n '2p' a.txt 1 Tom 18 M 60
2.删除数据
[root@host test]# sed '2,5d' a.txt ID NAME Age Gender Weight [root@host test]# cat a.txt #用sed 删除掉的文件内容并没有真的修改文件 ID NAME Age Gender Weight 1 Tom 18 M 80 2 Jee 16 M 100 3 Chh 20 M 50 4 Ayy 30 W 70
3.追加、插入数据
格式:sed ‘2[ a | i ]’ 文件名 a 在指定行后面追加 i 在指定行前面插入 [root@host test]# sed '2a Hello World' a.txt ID NAME Age Gender Weight 1 Tom 18 M 80 Hello World 2 Jee 16 M 100 3 Chh 20 M 50 4 Ayy 30 W 70 [root@host test]# sed '2i hello tom' a.txt ID NAME Age Gender Weight hello tom 1 Tom 18 M 80 2 Jee 16 M 100 3 Chh 20 M 50 4 Ayy 30 W 70 #假如要追加多行,则需要用 \ 作为一行的结束,最后一行不需要 [root@host test]# sed '2a 333 \ > TOMCAT \ > age 20 \ > cat ' a.txt ID NAME Age Gender Weight 1 Tom 18 M 80 333 TOMCAT age 20 cat 2 Jee 16 M 100 3 Chh 20 M 50 4 Ayy 30 W 70 [root@host test]# sed -n '2a Hello \ #-n 的作用是只显示追加部分 > Tom \ > Cat ' a.txt Hello Tom Cat
4.整行替换数据
[root@host test]# cat a.txt |sed '2c Hello World' ID NAME Age Gender Weight Hello World 2 Jee 16 M 100 3 Chh 20 M 50 4 Ayy 30 W 70
5.字符串替换
c 进行整行替换,假如想进行关键词替换(一行中的一部分),需要用s 来进行替换。
格式: sed ‘ns/old/new/g’ 文件名 #n代表第几行
例1: [root@host test]# cat a.txt ID NAME Age Gender Weight 1 Tom 18 M 80 2 Jee 16 M 100 3 Chh 20 M 50 4 Ayy 30 W 70 [root@host test]# sed '2s/80/66666/g' a.txt ID NAME Age Gender Weight 1 Tom 18 M 66666 2 Jee 16 M 100 3 Chh 20 M 50 4 Ayy 30 W 70 例2:把 Jee 注释掉 [root@host test]# sed '3s/^/#/g' a.txt ID NAME Age Gender Weight 1 Tom 18 M 80 #2 Jee 16 M 100 3 Chh 20 M 50 4 Ayy 30 W 70 例3:将指定内容替换成空 [root@host test]# sed -e '4s/Chh//g ; 5s/Ayy//g' a.txt ID NAME Age Gender Weight 1 Tom 18 M 80 2 Jee 16 M 100 3 20 M 50 4 30 W 70
6.使用 -n 输出奇偶行
[root@c1 work]# nl passwd |sed -n '{n;p}' 2 bin:x:1:1:bin:/bin:/sbin/nologin 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 8 halt:x:7:0:halt:/sbin:/sbin/halt 10 operator:x:11:0:operator:/root:/sbin/nologin [root@c1 work]# nl passwd |sed -n '{p;n}' 1 root:x:0:0:root:/root:/bin/bash 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin [root@c1 work]# nl passwd |sed -n '1~2p' [root@c1 work]# nl passwd |sed -n '2~2p' [root@c1 work]# nl passwd |sed -n '{n;p;n}' 2 bin:x:1:1:bin:/bin:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 8 halt:x:7:0:halt:/sbin:/sbin/halt 11 games:x:12:100:games:/usr/games:/sbin/nologin 14 systemd-bus-proxy:x:999:997:systemd Bus Proxy:/:/sbin/nologin 17 polkitd:x:998:996:User for polkitd:/:/sbin/nologin 20 rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin 23 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin 26 tcpdump:x:72:72::/:/sbin/nologin [root@c1 work]# nl passwd |sed -n '{n;n;p}' 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin 15 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin 18 libstoragemgmt:x:997:995:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin 21 tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin 24 ntp:x:38:38::/etc/ntp:/sbin/nologin
7.符号 & (代替前面的匹配原则,简化了替换中作用)
(元字符 \u \I \U \L :转换为大写/小写字符 )
1. [root@c1 work]# cat passwd root:x:0:0:root:/root:/bin/bash Tom_cat:x:0:0:root:/root:/bin/bash _Jerry:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin [root@c1 work]# sed 's/^[a-z_*]\+/& /' passwd root :x:0:0:root:/root:/bin/bash Tom_cat:x:0:0:root:/root:/bin/bash _ Jerry:x:0:0:root:/root:/bin/bash bin :x:1:1:bin:/bin:/sbin/nologin daemon :x:2:2:daemon:/sbin:/sbin/nologin 2.将用户名的首字母转换为 大写/小写 [root@c1 work]# sed 's/^[a-z_-]\+/\u&/' passwd Root:x:0:0:root:/root:/bin/bash Tom_cat:x:0:0:root:/root:/bin/bash _Jerry:x:0:0:root:/root:/bin/bash Bin:x:1:1:bin:/bin:/sbin/nologin 3.将文件夹下的.txt文件名转换为大写 [root@c1 test]# ls a.txt b.txt c.txt [root@c1 test]# ls *.txt|sed 's/^\w\+/\U&/' A.txt B.txt C.txt
8.获取passwd 中 USER,UID,GID
a.获取USER [root@c1 work]# sed 's/\(^[a-z_-]\+\):.*$/\1/' passwd b.获取USER,UID [root@c1 work]#sed 's/\(^[a-z_-]\+\):x:\([0-9]\+\):\([0-9]\+\):.*$/\1 \2/' passwd c. 获取全部: [root@c1 work]#sed 's/\(^[a-z_-]\+\):x:\([0-9]\+\):\([0-9]\+\):.*$/USER:\1 UID:\2 GID:\3/' passwd
9.符号 ()
-\( \) : 替换某种(部分)字符串 (\1,\2) [root@c1 work]# ifconfig ens33 | sed -n '/inet /p' inet 192.168.10.10 netmask 255.255.255.0 broadcast 192.168.10.255 [root@c1 work]# ifconfig ens33 | sed -n '/inet /p'|sed 's/i.*t \([0-9.]\+\) .*$/\1/' 192.168.10.10
10.符号 r与w
r:复制指定文件插入到匹配行 (未改变) w:复制匹配行拷贝指定文件里(改变文件) 源文件 <---> 目标文件 [root@c1 work]# sed '1r 123.txt' abc.txt AAAAA 11111 22222 33333 BBBBB CCCCC [root@c1 work]# cat 123.txt 11111 22222 33333 [root@c1 work]# cat abc.txt AAAAA BBBBB CCCCC [root@c1 work]# sed '1w 123.txt' abc.txt AAAAA BBBBB CCCCC [root@c1 work]# cat 123.txt AAAAA [root@c1 work]# cat abc.txt AAAAA BBBBB CCCCC
11 : 退出sed
[root@c1 work]# sed '/nologin/q' passwd root:x:0:0:root:/root:/bin/bash Tom_cat:x:0:0:root:/root:/bin/bash _Jerry:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin
四.字符处理命令
A.sort 排序
sort 选项 文件名 -n 以数值型进行排序,默认使用字符串类型排序 -r 反向排序
-t 指定分隔符,默认分割符是 空格 -k n[,m] 按照指定字段范围排序,从n字段开始到m字段结束。(指定第几列或第几列的第几个字符)
-f 忽略大小写
-b 忽略每行前的空白部分
-u 删除重复行(=下面的uniq)
1.sort命令默认使用每行开头第一个字符进行排序,若反向排序加 -r 选项
[root@host test]# sort /etc/passwd abrt:x:173:173::/etc/abrt:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin bin:x:1:1:bin:/bin:/sbin/nologin chrony:x:996:994::/var/lib/chrony:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin dbus:x:81:81:System message bus:/:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
2.按照指定的排序字段进行排序,使用 -t 指定分割符,并使用 -k 指定字段号
[root@host test]# sort -t ":" -k 3 /etc/passwd root:x:0:0:root:/root:/bin/bash time:x:1000:1000:time:/home/time:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin bin:x:1:1:bin:/bin:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin 注意:此时的排序并不是 0,1,2,而是使用的是 字符排序。加 -n 就是 数值排序 [root@host test]# sort -n -t ":" -k 3 /etc/passwd
3.ip部分
[root@host test]# cat ip.txt 10.0.0.9 a 10.0.0.8 k 10.0.0.7 f 10.0.0.7 n 10.0.0.8 c 10.0.0.8 z 10.0.0.9 o [root@host test]# sort -t" " -k2 ip.txt 10.0.0.9 a 10.0.0.8 c 10.0.0.7 f 10.0.0.8 k 10.0.0.7 n 10.0.0.9 o 10.0.0.8 z [root@host test]# sort -rk2 ip.txt 10.0.0.8 z 10.0.0.9 o 10.0.0.7 n 10.0.0.8 k 10.0.0.7 f 10.0.0.8 c 10.0.0.9 a
B.uniq
a.
uniq对指定的ASCII文件或标准输入进行唯一性检查,以判断文本文件中重复出现的行。常用于系统排查及日志分析。
b.命令格式
格式:
uniq [options] [file1 [file2]]
-c 去重计数(count) *****
-d 仅显示重复出现的行,2次或2次以上的行,默认的去重包含1次
-u
uniq从已经排序好的文本文件file1中删除重复的行,输出到标准输出或file2。常作为过滤器,配合管道使用。
在使用uniq命令前,必须确保操作的文本文件已经经过sort排序。若不带参数运行uniq,将删除重复的行。
1.重复行连续
[root@host test]# cat test.txt 123456 123456 HelloWorld tomcat [root@host test]# uniq test.txt 123456 HelloWorld tomcat
2.重复行不连续,uniq不生效,需要先排序
[root@host test]# cat test.txt 123456 HelloWorld 123456 tomcat [root@host test]# sort test.txt | uniq 123456 HelloWorld tomcat
3.去重计数
[root@host test]# vim ip.txt [root@host test]# [root@host test]# cat ip.txt 10.0.0.9 10.0.0.8 10.0.0.7 10.0.0.7 10.0.0.8 10.0.0.8 10.0.0.9 [root@host test]# sort ip.txt |uniq -c 2 10.0.0.7 3 10.0.0.8 2 10.0.0.9
4.-d选项
[root@host test]# cat ip.txt 10.0.0.9 10.0.0.8 10.0.0.7 10.0.0.7 10.0.0.8 10.0.0.8 10.0.0.9 [root@host test]# uniq -d ip.txt 10.0.0.7 10.0.0.8 [root@host test]# sort ip.txt|uniq -d 10.0.0.7 10.0.0.8 10.0.0.9

 浙公网安备 33010602011771号
浙公网安备 33010602011771号