记录一次dcgm-expoter中DCGM_FI_XID_ERRORS无法清空的问题
背景
训练集群中使用dcgm-expoter对GPU状态进行采集和上报,服务中通过获取promethes数据监测显卡的负载情况及报错情况,其中监测报错使用的DCGM_FI_XID_ERRORS指标获取,这个指标用起来有问题,首先是错误码不会清除,观测到Xid31错误后,每次采集这张卡都会返回xid31,即便这个错误只是一个瞬时的错误,后查看官网找到了另一个指标DCGM_EXP_XID_ERRORS_COUNT,他是gauge类型,表示dcgm采集周期内(默认应该是5分钟)xid错误的计数,由此衍生出了后边一系列的改造,包括在测试环境复现Xid31错误,重置DCGM_FI_XID_ERRORS指标以及改为使用DCGM_EXP_XID_ERRORS_COUNT进行错误监测。
复现Xid31错误
DCGM_FI_XID_ERRORS指标一直返回Xid31错误,以为GPU报故障了,后来才知道是之前报错遗留的状态码。错误大概长下边这样

训练集群发现这个错误已经过去了及其久远的时光,也没法还原当时的错误现场,所以想办法在测试环境复现Xid31错误
复现Xid31错误
nvidia官网给出了dcgm-expoter的两种docker启动方案,1是使用自带的nv-hostengine直接启动,2是启动时通过-r指定其他的nv-hostengine,官方图如下:
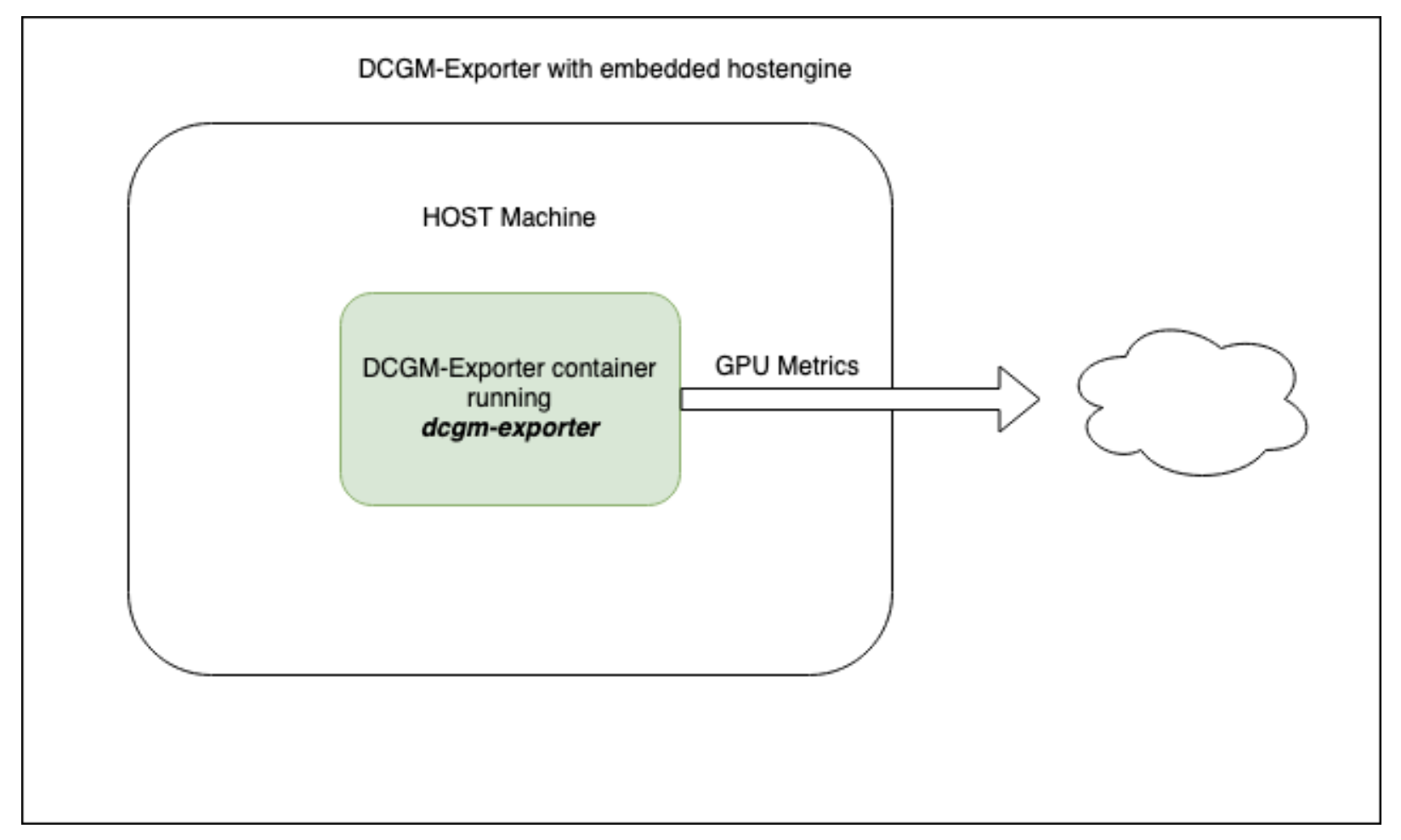
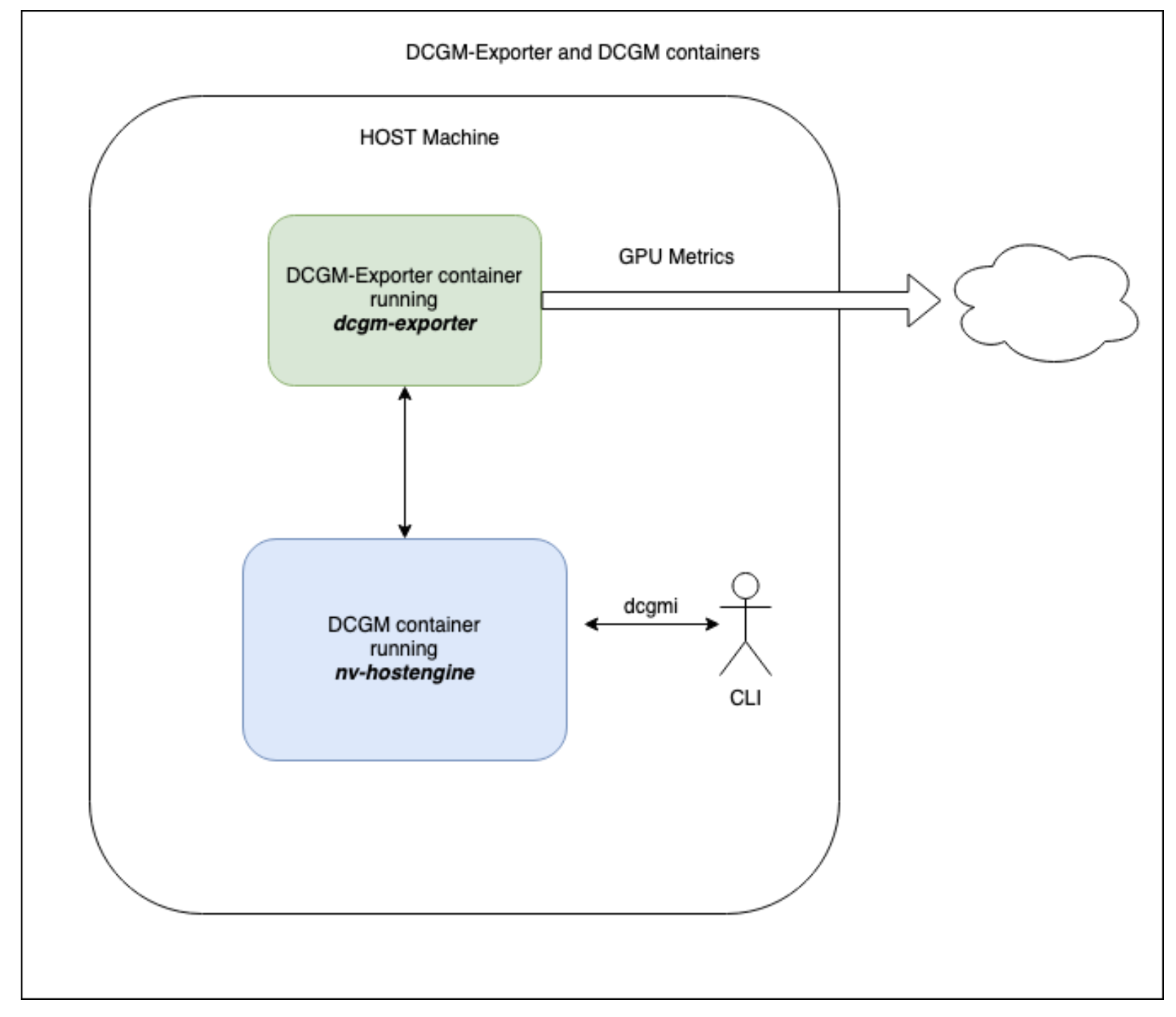
这里先介绍一下dcgm,nv-hostengine以及dcgm-expoter的关系,dcgm是管理GPU及监测的工具,nv-hostengine是dcgm用来采集和维护gpu状态的服务,通常启动dcgm服务时会默认同时启动nv-hostengine,执行dcgmi -v命令观察
会发现输出结果中上边是dcgm客户端版本,下边是hostengine版本
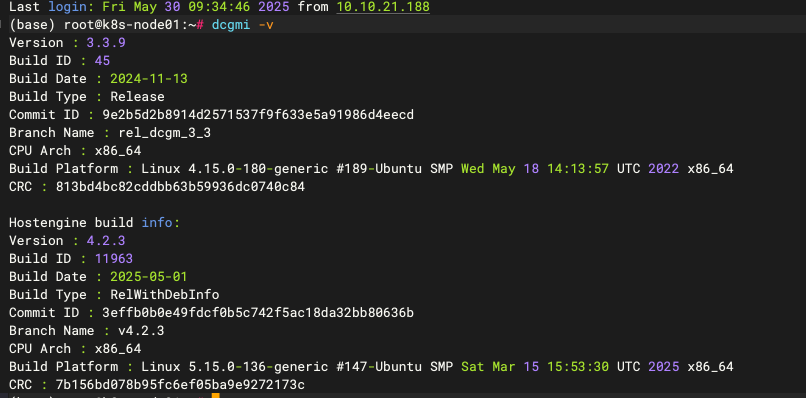
如果不启动dcgm服务直接运行dcgm命令会发现只显示dcgm版本信息。
启动nv-hostengine容器,用宿主机5555端口提供服务
docker run -d --gpus all --cap-add SYS_ADMIN -p 5555:5555 nvcr.io/nvidia/cloud-native/dcgm:4.2.3-1-ubuntu22.04
dcgm-expoter是由go编写的专门用来对dcgm指标进行采集的工具,它会定时访问nv-hostengine中的gpu指标信息并通过默认的9400端口暴露http,通常为promethes提供gpu监测,启动dcgm-expoter的命令如下
sudo docker run -d --gpus all --net host --cap-add SYS_ADMIN -v ./default-counters.csv:/etc/dcgm-exporter/dcgm-golden-metrics.csv dcgm-exporter:4.2.3-4.1.1-ubuntu22.04 -f /etc/dcgm-exporter/dcgm-golden-metrics.csv -r localhost:5555
-f 指定要监控的dcgm指标,传入一个文件,具体在官方包里有
-r 指定nv-hostengine地址,如不指定则使用包里自带的嵌入式nv-hostengine,这样的话外部的dcgm客户端是无法与exporter用到同一个nv-hostengine,这点很重要,后边错误注入时会用到
上边命令启动了一个采集器容器,映射本地的./default-counters.csv作为指标列表文件,指定宿主机的5555为外部nv-hostengine地址,需要注意版本需要与nv-hostengine对应,dcgm-exporter:4.2.3-4.1.1-ubuntu22.04中的4.2.3指的就是需要4.2.3版本的nv-hostengine,版本不对应很容易出现各种问题。
此时进入采集器容器执行dcgmi -v观察是否有连接到nv-hostengine,如果有则可以开始进行错误注入了。
1.运行dcgmi test --inject --gpuid 0 -f 230 -v 31伪造一个xid31错误,注意这个错误不会进入系统日志
2.curl localhost:9400/metrics观察是否有31错误,你应该能看到类似下边的结果

如果你在./default-counters.csv中增加了DCGM_EXP_XID_ERRORS_COUNT指标,还应该能找到下边的输出

结尾
如果你正在做对GPU中XID错误的监测,需要注意DCGM_FI_DEV_XID_ERRORS指标获取的是最后一次报错的状态码,如果多次报错它是无法识别的,而DCGM_EXP_XID_ERRORS_COUNT则会返回该显卡每个xid错误的周期内计数,这里附上一个官方的xid附录方便进行错误分级用于后续故障转移和故障恢复,官方的xid解释其实不是很明确且好多xid错误及其不常见,可以对比参考DeepSeek以及阿里训练平台对Xid的收集。
https://docs.nvidia.com/deploy/xid-errors/index.html
关于清空DCGM_EXP_XID_ERRORS_COUNT计数问题,我提了question,截止目前还没回复,暂时只能通过重启采集器实现计数清零。之前理解有误,DCGM_EXP_XID_ERRORS_COUNT是Gauge类型而非Counter类型,虽然它以COUNT结尾,这里明确一下他的含义,表示采集周期内各个xid错误的计数,下边是实验证明
手动触发2个31和2个42,之后每分钟再加一个31重复两分钟
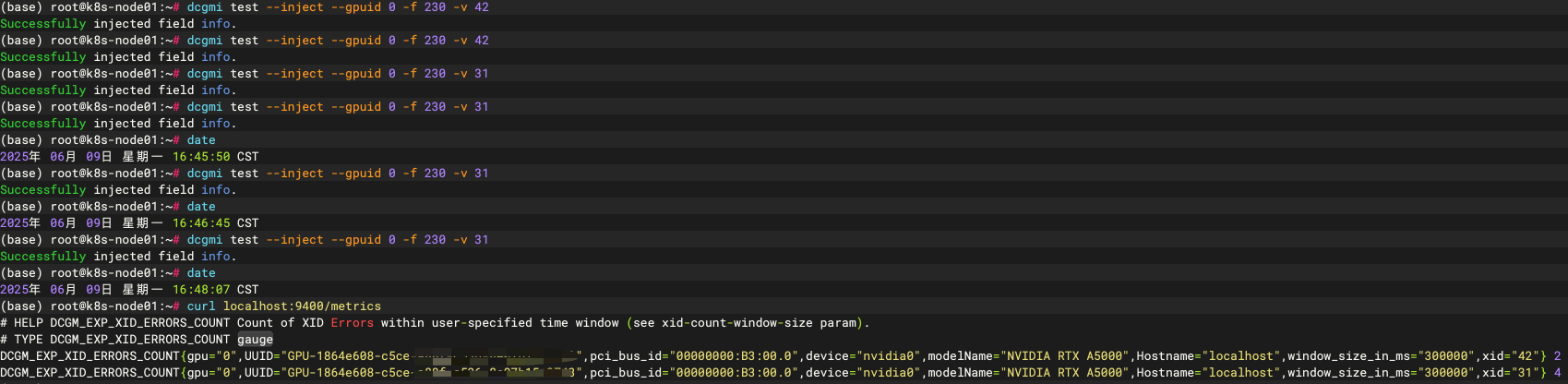
等待5分钟后观察发现42没了只有31计数为4(这里因为几秒钟的差异导致原始的2个31还没清除)

再过一分钟后发现只有1个31的计数


 浙公网安备 33010602011771号
浙公网安备 33010602011771号