

python分析好友情况,并且制作机器人聊天
1首先安装Pyechart库
打开cmd,在cmd中使用pip命令安装pyecharts库,如下所示:
pip install pyecharts -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
2我们先分析我们好友性别比例情况吧,可用该函数实现。
1 def fun_analyse_sex(friends): 2 sexs = list(map(lambda x:x['Sex'],friends[1:]))#收集性别数据 3 counts = list(map(lambda x:x[1],Counter(sexs).items()))#统计不同性别的数量 4 counts = sorted(counts) 5 labels = ['secret','male','female']#2:女,1:男,0:保密 6 colors = ['red','yellow','blue'] 7 plt.figure(figsize=(8,5), dpi=80) 8 plt.axes(aspect=1) 9 plt.pie(counts, #性别统计结果 10 labels=labels, #性别展示标签 11 colors=colors, #饼图区域配色 12 labeldistance = 1.1, #标签距离圆点距离 13 autopct = '%3.1f%%', #饼图区域文本格式 14 shadow = False, #饼图是否显示阴影 15 startangle = 90, #饼图起始角度 16 pctdistance = 0.6 #饼图区域文本距离圆点距离 17 ) 18 plt.legend(loc='upper left')#标签位置 19 plt.title('mywechat''%sfemale and male' % friends[0]['NickName']) 20 plt.show()
运行的显示效果如下:
![]()
哈哈,比例好像有点不对。
3我们再来试试分析微信朋友的个性签名吧,并把它分为积极,消极和中性,且做成词云图。

def fun_analyse_Signature(friends): signatures = '' emotions = [] for friend in friends: signature = friend['Signature'] if signature != None: signature = signature.strip().replace("span","").replace("class","").replace("emoji","")#去除无关数据 signature = re.sub(r'1f(\d.+)',"",signature) if len(signature) > 0: nlp = snownlp.SnowNLP(signature) emotions.append(nlp.sentiments)#nlp.sentiments:权值 signatures += " ".join(jieba.analyse.extract_tags(signature,5))#关键字提取 back_coloring = np.array(Image.open("xiaohuangren.jpg"))#图片可替换 word_cloud2 = WordCloud(font_path = 'simkai.ttf', background_color = 'white', max_words = 1200, mask = back_coloring, margin = 15) word_cloud2.generate(signatures) image_colors = ImageColorGenerator(back_coloring) plt.figure(figsize=(8,5),dpi=160) plt.imshow(word_cloud2.recolor(color_func=image_colors)) plt.axis("off") plt.show() word_cloud2.to_file("signatures.jpg") #人生观 count_positive = len(list(filter(lambda x:x>0.66,emotions)))#大于0.66为积极 count_negative = len(list(filter(lambda x:x<0.33,emotions)))#小于0.33为消极 count_neutral = len(list(filter(lambda x:x>=0.33 and x <= 0.66,emotions))) labels = [u'积极',u'中性',u'消极'] values =(count_positive,count_neutral,count_negative) plt.rcParams['font.sans-serif'] = ['simHei'] plt.rcParams['axes.unicode_minus'] = False plt.xlabel("情感判断") plt.ylabel("频数") plt.xticks(range(3),labels) plt.legend(loc='upper right') plt.bar(range(3),values,color='rgb') plt.title(u'%s的微信好友签名信息情感分析情况' % friends[0]['NickName']) plt.show()
效果运行如下:
![]()
生成柱状图效果
![]()
4我们再来分析微信好友数量和群数量情况吧,代码如下


import itchat from itchat.content import TEXT from itchat.content import * import sys import time import re import os @itchat.msg_register([TEXT,PICTURE,FRIENDS,CARD,MAP,SHARING,RECORDING,ATTACHMENT,VIDEO],isGroupChat=True) def receive_msg(msg): groups = itchat.get_chatrooms(update=True) friends = itchat.get_friends(update=True) print ("群数量:",len(groups)) for i in range(0,len(groups)): print (i+1,"--",groups[i]['NickName'],groups[i]['MemberCount'],"人") print ("好友数量",len(friends)-1) for f in range(1,len(friends)):#第0个好友是自己,不统计 if friends[f]['RemarkName']: # 优先使用好友的备注名称,没有则使用昵称 user_name = friends[f]['RemarkName'] else: user_name = friends[f]['NickName'] sex = friends[f]['Sex'] print (f,"--",user_name,sex) itchat.auto_login(hotReload=True) itchat.run()
运行效果如下:![]() 下面一些就不截图了。
下面一些就不截图了。
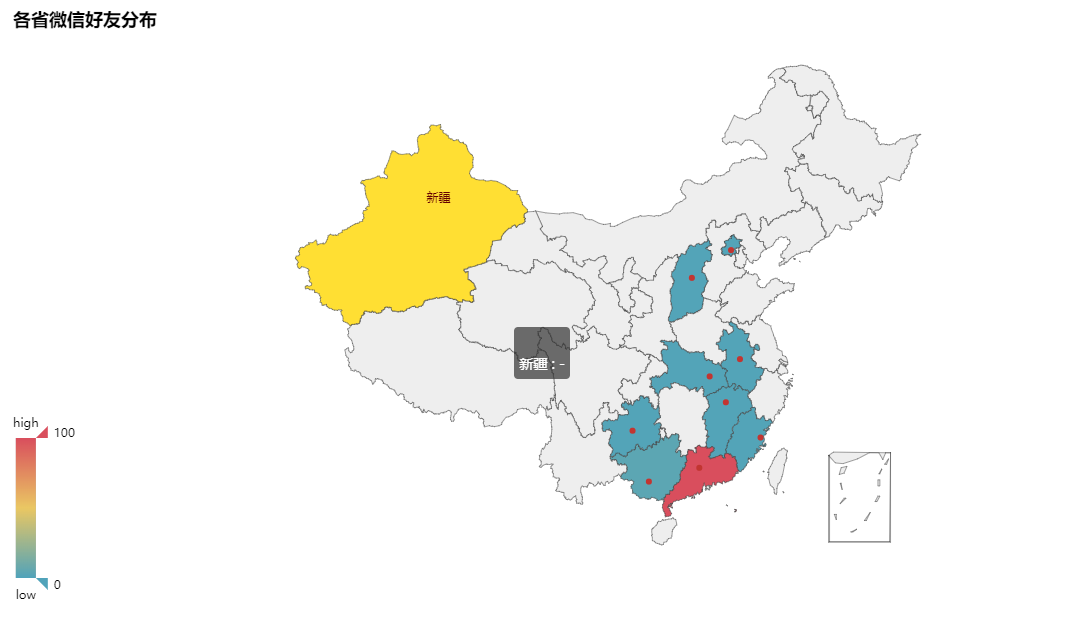
5我们再来做个好友所在地分析吧:代码如下:(先把好友信息存进csv文件里面,在把csv文件内容用地图显示)
 下面一些就不截图了。
下面一些就不截图了。def analyseLocation(friends): headers = ['NickName','Province','City'] with open('F:\\www\cgi-bin\wechat_data.xlsx','w',encoding='utf-8',newline='',) as csvFile: writer = csv.DictWriter(csvFile, headers) writer.writeheader() for friend in friends[1:]: row = {} row['NickName'] = friend['NickName'] row['Province'] = friend['Province'] row['City'] = friend['City'] writer.writerow(row) def shou_data_in_countrymap(save_road,file_name,sheet_name='wechat1',\ column_name='Province'): '''将这些个好友在全国地图上做分布''' f=open(file_name,'rb') data=pd.read_excel(f,sheetname=sheet_name) province_list = data[column_name].fillna('NAN').tolist() #将 dataframe 的列转化为 list,其中的 nan 用“NAN”替换 count_province = pd.value_counts(province_list)#对 list 进行全频率统计 value =count_province.tolist() attr =count_province.index.tolist() map=Map("各省微信好友分布", width=1200, height=600) map.add("", attr, value, maptype='china', is_visualmap=True, visual_text_color='#000', is_label_show = True) #显示地图上的省份 map.show_config() map.render(save_road+'map1'+'.html') f.close()
效果如下:
![]()

![]()
6最后我们来做个微信机器人聊天:代码如下(我们要申请一个茉莉机器人) 可以在这里申请一个:http://www.itpk.cn/
import itchat import requests def get_response(msg): apiurl = 'http://i.itpk.cn/api.php' #moli机器人的网址 data={ "question": msg, #获取到聊天的文本信息 "api_key": "215bbeaf9f4788d1c57d3c06ec76b659", "api_secret": "cjoxg5lqrt58" } r=requests.post(apiurl,data=data) #构造网络请求 return r.text @itchat.msg_register(itchat.content.TEXT) #好友消息的处理 def print_content(msg): return get_response(msg['Text']) @itchat.msg_register([itchat.content.TEXT], isGroupChat=True) #群消息的处理 def print_content(msg): return get_response(msg['Text']) itchat.auto_login(True) #自动登录 itchat.run()
运行效果后会有个二维码扫描就会自动回复消息了。
好了 到了完整代码了:
import itchat import numpy as np #import os from collections import Counter import matplotlib.pyplot as plt #from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator from PIL import Image #import time import re import snownlp import jieba import jieba.analyse import pandas as pd #from pandas import DataFrame #import openpyxl import csv from pyecharts import Map def fun_analyse_sex(friends): sexs = list(map(lambda x:x['Sex'],friends[1:]))#收集性别数据 counts = list(map(lambda x:x[1],Counter(sexs).items()))#统计不同性别的数量 counts = sorted(counts) labels = ['保密','男','女']#2:女,1:男,0:保密 colors = ['red','yellow','blue'] plt.figure(figsize=(8,5), dpi=80) plt.axes(aspect=1) plt.pie(counts, #性别统计结果 labels=labels, #性别展示标签 colors=colors, #饼图区域配色 labeldistance = 1.1, #标签距离圆点距离 autopct = '%3.1f%%', #饼图区域文本格式 shadow = False, #饼图是否显示阴影 startangle = 90, #饼图起始角度 pctdistance = 0.6 #饼图区域文本距离圆点距离 ) plt.legend(loc='upper left')#标签位置 plt.title('mywechat''%sfemale and male' % friends[0]['NickName']) plt.show() def fun_analyse_Signature(friends): signatures = '' emotions = [] for friend in friends: signature = friend['Signature'] if signature != None: signature = signature.strip().replace("span","").replace("class","").replace("emoji","")#去除无关数据 signature = re.sub(r'1f(\d.+)',"",signature) if len(signature) > 0: nlp = snownlp.SnowNLP(signature) emotions.append(nlp.sentiments)#nlp.sentiments:权值 signatures += " ".join(jieba.analyse.extract_tags(signature,5))#关键字提取 back_coloring = np.array(Image.open("xiaohuangren.jpg"))#图片可替换 word_cloud2 = WordCloud(font_path = 'simkai.ttf', background_color = 'white', max_words = 1200, mask = back_coloring, margin = 15) word_cloud2.generate(signatures) image_colors = ImageColorGenerator(back_coloring) plt.figure(figsize=(8,5),dpi=160) plt.imshow(word_cloud2.recolor(color_func=image_colors)) plt.axis("off") plt.show() word_cloud2.to_file("signatures.jpg") #人生观 count_positive = len(list(filter(lambda x:x>0.66,emotions)))#大于0.66为积极 count_negative = len(list(filter(lambda x:x<0.33,emotions)))#小于0.33为消极 count_neutral = len(list(filter(lambda x:x>=0.33 and x <= 0.66,emotions))) labels = [u'积极',u'中性',u'消极'] values =(count_positive,count_neutral,count_negative) plt.rcParams['font.sans-serif'] = ['simHei'] plt.rcParams['axes.unicode_minus'] = False plt.xlabel("情感判断") plt.ylabel("频数") plt.xticks(range(3),labels) plt.legend(loc='upper right') plt.bar(range(3),values,color='rgb') plt.title(u'%s的微信好友签名信息情感分析情况' % friends[0]['NickName']) plt.show() def ger_friend_msg(): #得到的信息存进csv文件里面 import time RemarkName = get_data('RemarkName') NickName = get_data('NickName') # 是一个列表 City = get_data('City') Province = get_data('Province') Sex = get_data('Sex') Signature = get_data('Signature') data = {'备注': RemarkName, '昵称': NickName, '城市': City, '省份': Province, '性别': Sex, '微信签名': Signature} # 字典,字典的value是列表 frame = DataFrame(data) time = time.strftime("%Y-%m-%d_%H_%M_%S", time.localtime()) # 生成一个当前事件,以这个时间来命名最后地csv文件,能很直白地看出最新执行脚本的时间和最新的csv文件 file_name = time + '微信好友.csv' frame.to_csv('f:\\www\\靓仔贵雨\\friends.csv', encoding='utf_8_sig', index=True) def get_data(arg): #得到所有信息 data_list = [] for i in friends: value = i[arg] if value == 1:#1代表男/2代表女 value = '男'#这里把1/2换成了男女 data_list.append(value) elif value == 2: value = '女' data_list.append(value) elif value == 0: value = '未知' data_list.append(value) else: data_list.append(value) return data_list def analyseLocation(friends): headers = ['NickName','Province','City'] with open('F:\\www\cgi-bin\wechat_data.xlsx','w',encoding='utf-8',newline='',) as csvFile: writer = csv.DictWriter(csvFile, headers) writer.writeheader() for friend in friends[1:]: row = {} row['NickName'] = friend['NickName'] row['Province'] = friend['Province'] row['City'] = friend['City'] writer.writerow(row) def shou_data_in_countrymap(save_road,file_name,sheet_name='wechat1',\ column_name='Province'): '''将这些个好友在全国地图上做分布''' f=open(file_name,'rb') data=pd.read_excel(f,sheetname=sheet_name) province_list = data[column_name].fillna('NAN').tolist() #将 dataframe 的列转化为 list,其中的 nan 用“NAN”替换 count_province = pd.value_counts(province_list)#对 list 进行全频率统计 value =count_province.tolist() attr =count_province.index.tolist() map=Map("各省微信好友分布", width=1200, height=600) map.add("", attr, value, maptype='china', is_visualmap=True, visual_text_color='#000', is_label_show = True) #显示地图上的省份 map.show_config() map.render(save_road+'map1'+'.html') f.close() #if __name__ == "__main__": def main(): itchat.auto_login(hotReload=True) friends = itchat.get_friends(update=True) fun_analyse_sex(friends) fun_analyse_Signature(friends) #ger_friend_msg() save_road=r'F:\www\cgi-bin\pictuer' file_name='F:\\www\cgi-bin\wechat_data.xlsx' shou_data_in_countrymap(save_road,file_name) main()
今天分享就到这里了~~~~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号