
第四次作业
1.用图与自己的话,简要描述Hadoop起源与发展阶段。Hadoop最早起源于lucene下的Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
问题的可解决提供方案:分布式文件系统(GFS),可用于处理海量网页的存储,分布式计算框架(MAPREDUCE),可用于处理海量网页的索引计算问题。Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
Hadoop发展:Nutch项目面世后,面对数据量巨大的网页显示出了架构的灵活性不够。当时正好借鉴了谷歌分布式文件系统,做出了自己的开源系统NDFS分布式文件系统。第二年谷歌又发表了论文介绍了MapReduce系统,Nutch开发人员也开发出了MapReduce系统。随后NDFS和MapReduce命名为Hadoop,成为了Apache顶级项目。
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
(1)名称节点最主要功能:名称节点记录了每个文件中各个块所在的数据节点的位置信息,负责管理分布式文件系统的命名空间,保存了两个核心的数据结构,即FsImage和EditLog。
(2)第二名称节点主要功能:是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。在紧急情况下,可辅助恢复名称节点。
(3)数据节点主要功能:分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
(4)相互关系:分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群,这些节点分为主从节点,主节点可叫作名称节点,从节点可叫作数据节点。名称节点为了防止
EditLog过大的问题:引入了第二名称节点。
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
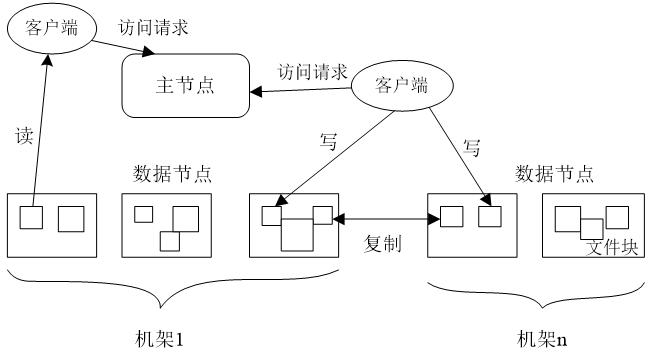
冗余数据保存
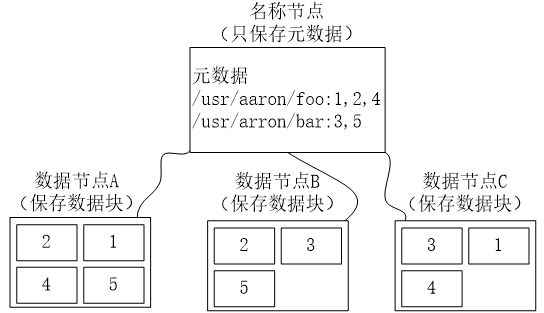
数据存储策略

 浙公网安备 33010602011771号
浙公网安备 33010602011771号