Pandas的rank函数
对Series来说:通过为各组分配一个平均排名的方式来破坏平级关系
1 对Series来说
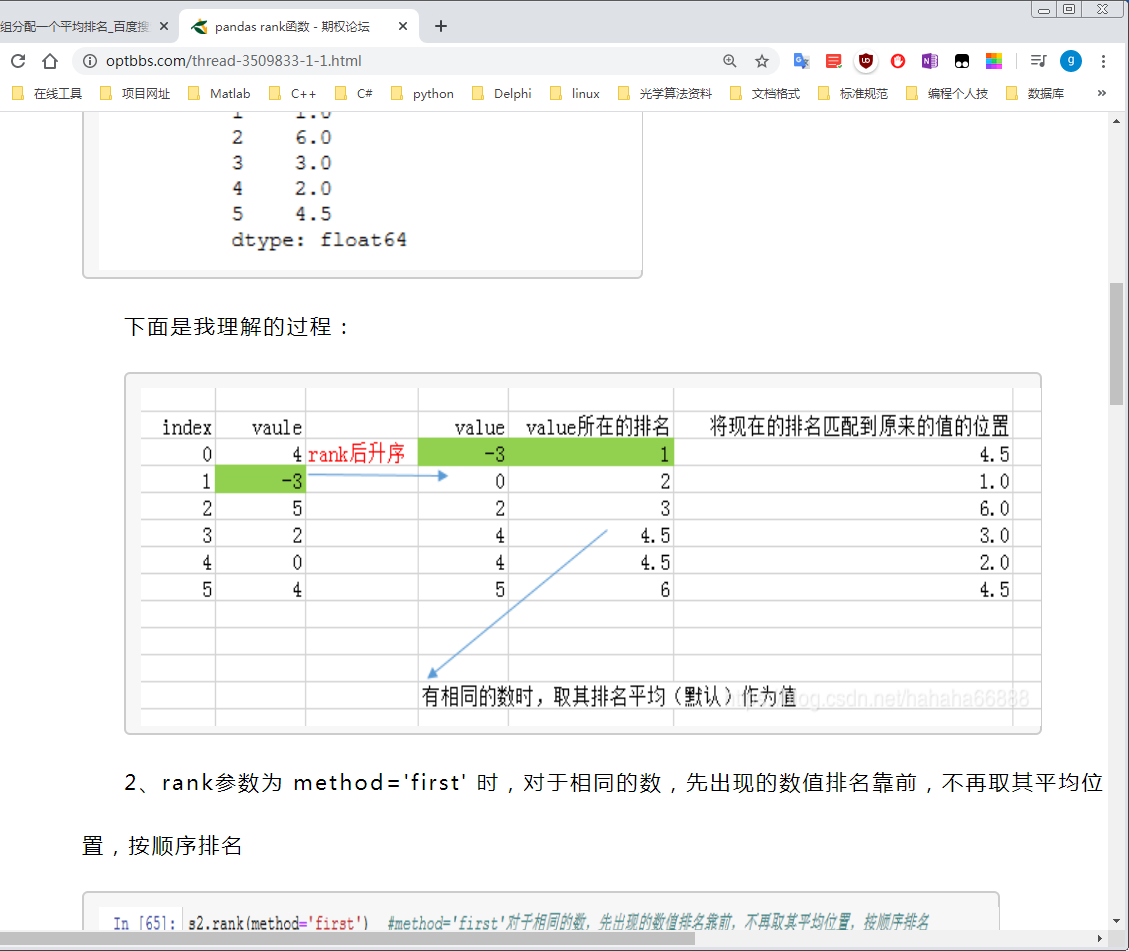
1.返回的是排名,把原数据升序(默认)后每个值所在的排名位置返回到原来所在的位置的索引所在的行.
有相同的数时,取其排名平均(默认)作为值.
In [42]: s2 Out[42]: 0 4 1 -3 2 5 3 2 4 0 5 4 dtype: int64
In [43]: s2.rank() Out[43]: 0 4.5 1 1.0 2 6.0 3 3.0 4 2.0 5 4.5 dtype: float64
下面是理解过程
2.rank参数为method='first'时,对于同样的数,先出现的数值排名靠前,不再取其平均位置,按顺序排名
In [44]: s2.rank(method='first') Out[44]: 0 4 1 1 2 6 3 3 4 2 5 5 dtype: float64
3.参数为ascending=False降序排列
In [46]: s2.rank(ascending=False) Out[46]: 0 2.5 1 6.0 2 1.0 3 4.0 4 5.0 5 2.5 dtype: float64
4.method='max'使用整个分组的最大排名
In [48]: s2.rank(ascending=False,method='max')
Out[48]:
0 3
1 6
2 1
3 4
4 5
5 3
dtype: float64
5.method='min'使用整个分组的最小排名
In [49]: s2.rank(ascending=False,method='min') Out[49]: 0 2 1 6 2 1 3 4 4 5 5 2 dtype: float64
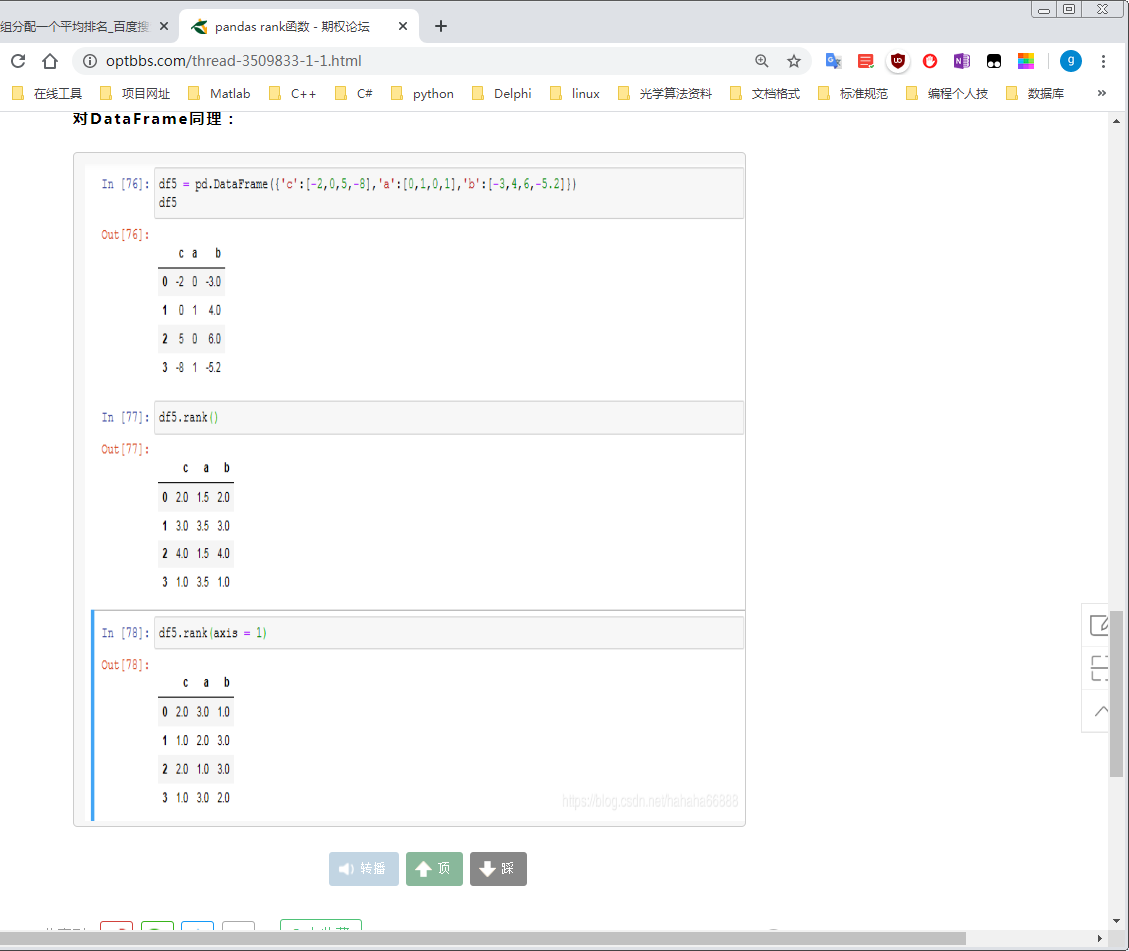
对DataFrame同理:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号