raft协议
what:
raft是分布式的一致性协议(Consensus),其相对pasox更加简单。用来保障servers上副本一致性的一种算法。
一致性协议是为了确保容错性,也就是即使系统中有一两个服务器当机,也不会影响其处理过程
how:
确保一致性的核心思想:
采用选举机制,参选者需要说服大多数选民(服务器)投票给他,一旦选定(leader)后,其他的server就是(follower)跟随leader操作,从而确保分布式的一致性。
选leader:
参考如下图(也是follower状态转化图):
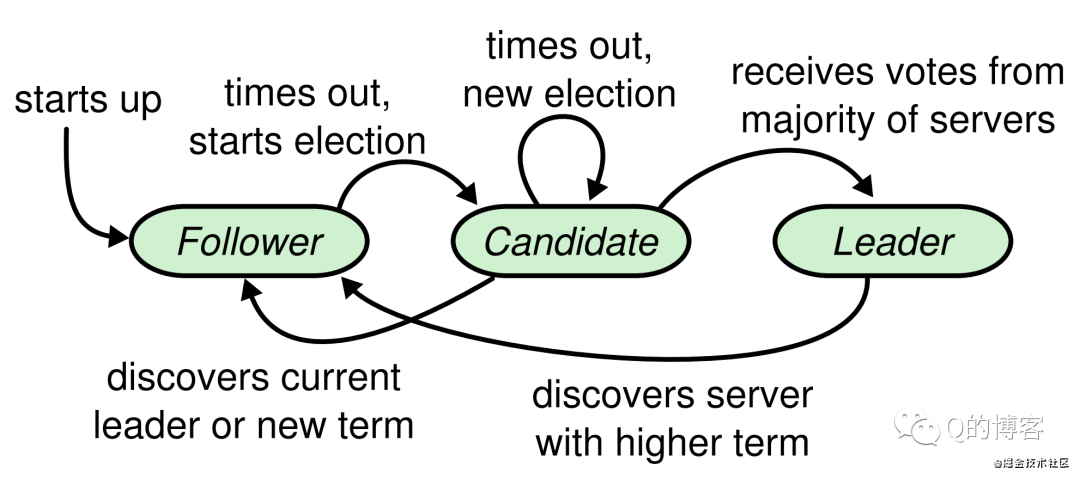
Raft 的选主基于一种“心跳机制”。leader 会周期性的向所有节点发送心跳包来维持自己的权威。
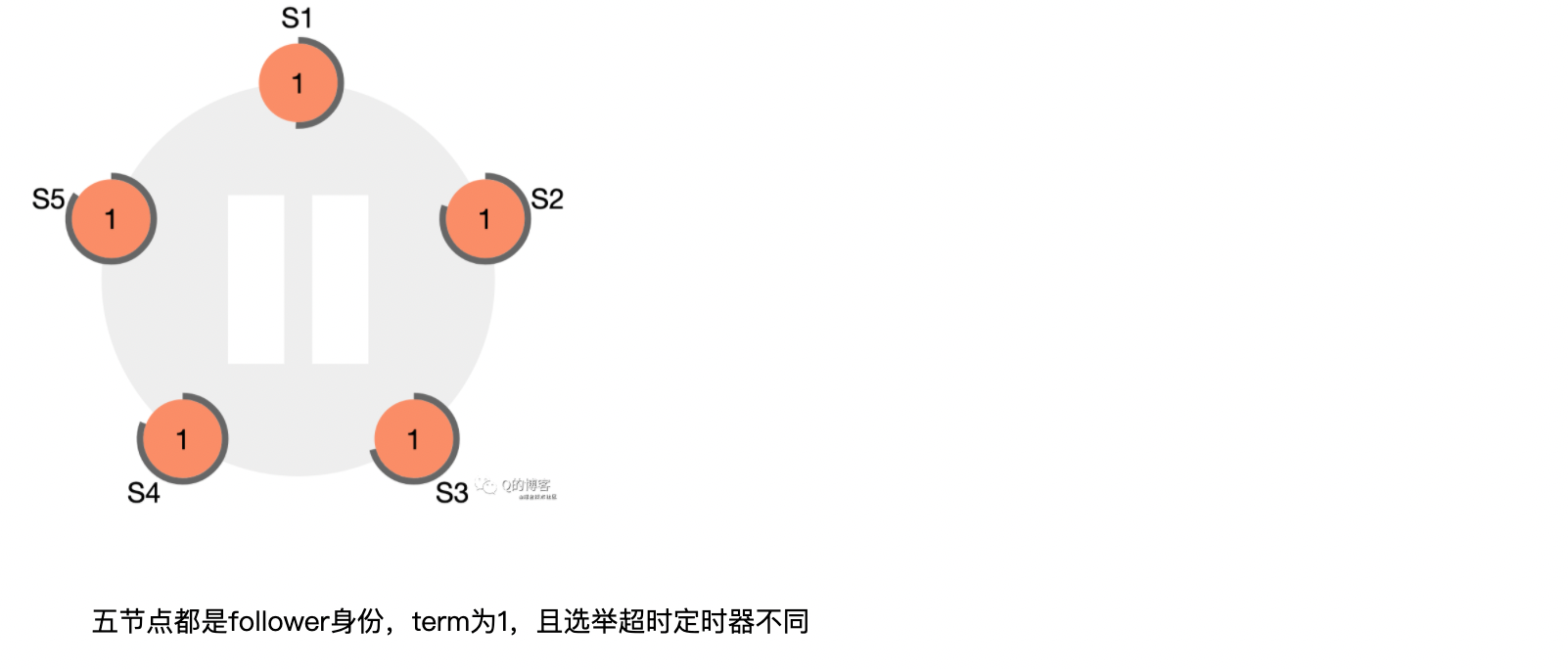
第一步:准备选举自己
刚启动时,所以的server节点都是follower身份(Step: starts up)。没有leader时,某个server节点和leader的心跳先超时,它就会从follower变为candidate,而发起选举(Step: times out, starts election)。(注意:为了各节点不同时变为candidate,在各节点的固定超时时间上某个范围内的随机数)。如下图:
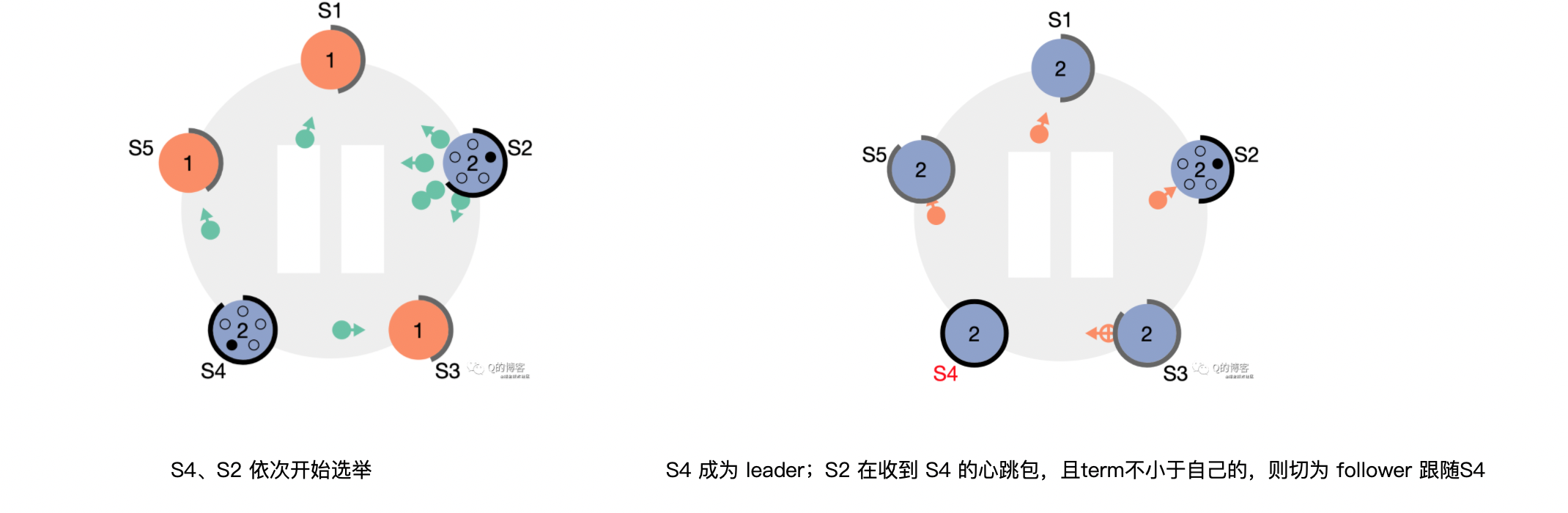
第二步:开始选举自己:
节点身份切换为 candidate,并将term加上1。然后它会向集群其它节点发送“请给自己投票”的消息(RequestVote RPC)。

第三步:选择结果:
candidate会有3种结果,分别对应上面状态图的3条线。
1. 选举成功(Step: receives votes from majority of servers):

2、选举失败(Step: discovers current leader or new term):
Candidate 在等待投票回复的时候,收到其它自称是 leader 节点发送的心跳包,且term 不小于 candidate 当前的 term,那么 candidate 会承认这个 leader,并将身份切回 follower。term 比自己小,candidate 会拒绝这次请求并保持选举状态。
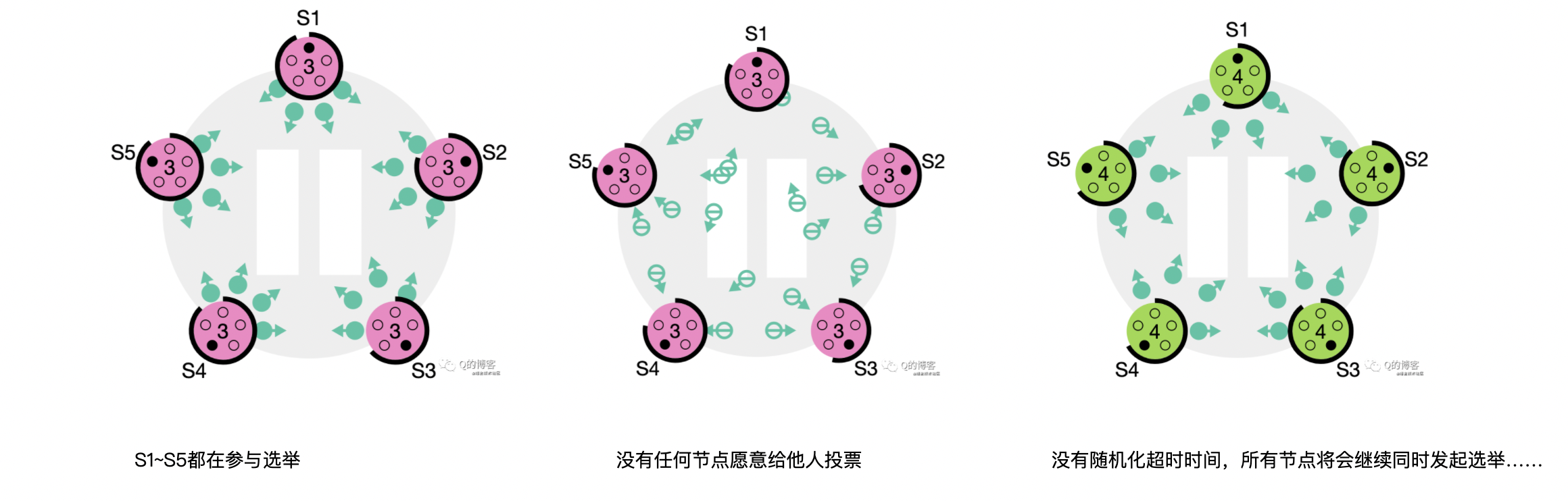
3、选举超时(Step: times out, new election):
多个 follower 同时成为 candidate,选票是可能被瓜分的,如果没有任何一个 candidate 能得到大多数节点的支持,那么每一个 candidate 都会超时。这里的“特殊处理”指的就是前文所述的随机化选举超时时间。此时 candidate 需要增加自己的 term,然后发起新一轮选举。
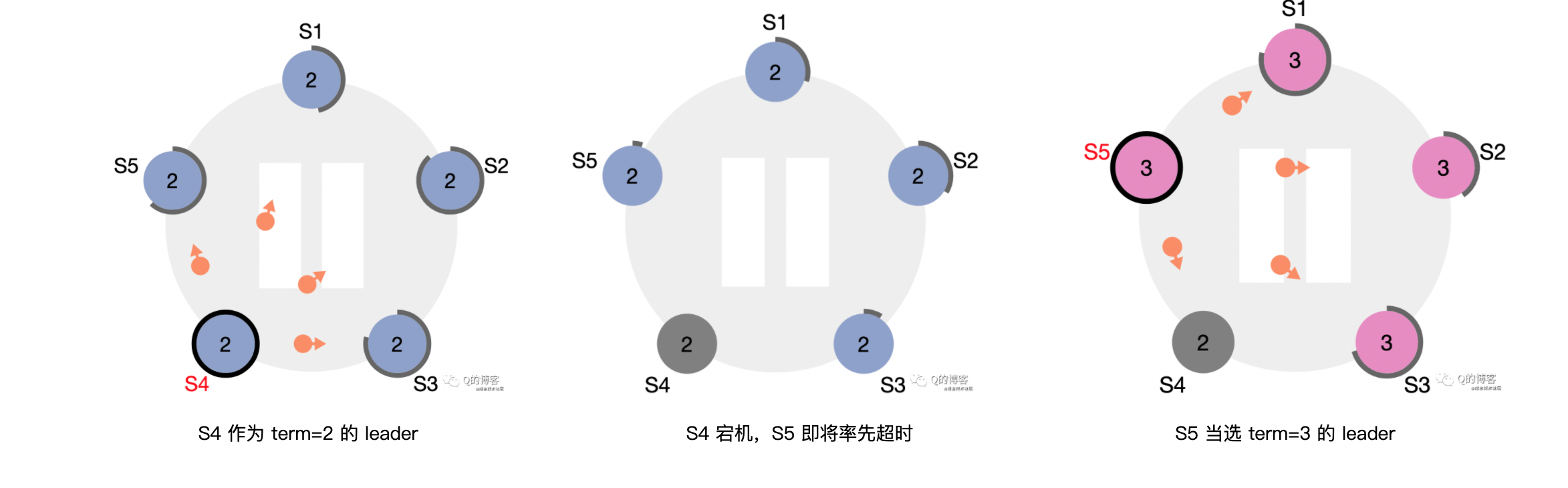
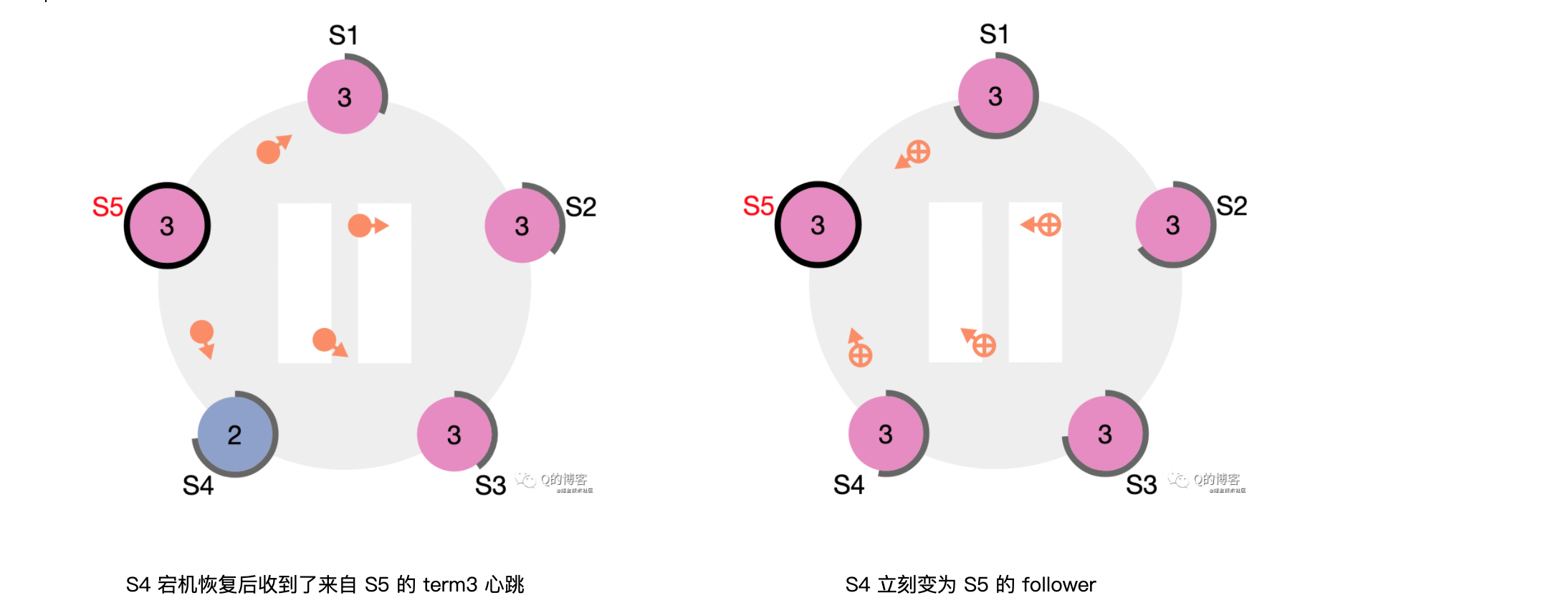
第四步、老leader更换:
即上面状态图的:discovers server with higher term。一段时间后老 leader 恢复了(如:网络故障、或者机器宕机恢复),收到了来自新leader 的心跳包,发现心跳中的 term 大于自己的 term,此时该节点会立刻切换为 follower 并跟随的新 leader。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号