[自然语言处理入门]六、文本匹配基础
六、文本匹配基础
学习路线参考:
https://blog.51cto.com/u_15298598/3121189
https://github.com/Ailln/nlp-roadmap
https://juejin.cn/post/7113066539053482021
https://zhuanlan.zhihu.com/p/100567371
https://cloud.tencent.com/developer/article/1884740
本节学习使用工具&阅读文章:
https://zhuanlan.zhihu.com/p/393929685
https://blog.csdn.net/qq_38587650/article/details/123724353
https://blog.csdn.net/laobai1015/article/details/120143102
https://zhuanlan.zhihu.com/p/79202151
1. 文本匹配简介
文本匹配,是一个很宽泛的概念,广义上来看,只要目的是研究两段文本之间的关系,基本都可以视作是文本匹配问题。由于在不同的场景下对”匹配“的定义可能非常不同,因此文本匹配并不是一个完整独立的研究方向。不过,有相当多的NLP任务可以建模成文本匹配问题,这其中的模型结构、训练方法等也是高度相似的。
-
应用场景
-
文本语义相似度 & 复述识别:判断两段文本是否表达了同样的语义,即是否构成复述关系
-
问答匹配:给定问题和该问题的答案候选池,从候选池中找出可以准确回答问题的最佳答案候选
-
对话匹配:在问答匹配的基础上引入了历史session(multi-turn),可看作进阶版的问答匹配
-
自然语言推理/文本蕴含识别:给定一个句子A作为前提(premise),另一个句子B作为假设(hypothesis),若A能推理出B,则A、B为蕴含关系(entailment),若A与B矛盾,则A、B为矛盾关系(contradiction),否则A、B独立(neutral),可以看做一个三分类问题
-
信息检索(Information Retrieval):信息检索场景下,一般先通过检索方法召回相关项,再对相关项进行rerank,文本匹配的方法同样可以套用在这个场景
-
-
无监督文本匹配
对于无监督的文本匹配,我们需要实时把握两个重点:文本表征和相似函数的度量。文本表征指的是我们将文本表示为计算机可以处理的形式,更准确了来说是数字化文本。而这个数字化文本,必须能够表征文本信息,这样才说的通。相似函数的度量就是你选择何种函数对文本相似度进行一个判定,比如欧氏距离,余弦距离,Jacard相似度,海明距离等等。
-
有监督文本相似度:SiamGRU和ESIM模型
-
2. BM25
用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法。
算法描述:我们有一个query和一批文档\(D=\{d_1,d_2,……,d_n\}\),现在要计算query和每篇文档d之间的相关性分数,我们的做法是,先对query进行切分,得到单词\(q_i\)。单词的分数由3部分组成:
- query中每个单词和文档d之间的相关性
- 单词和query之间的相关性
- 每个单词的权重
query和文档之间的分数等于所有单词分数之和。
-
单词权重
单词的权重最简单的就是用idf值:\(IDF(q_i)=log{N-df_i+0.5\over df_i+0.5}\)
其中N表示索引中全部文档数,\(df_i\)为包括了\(q_i\)的文档的个数。根据IDF的作用,对于某个\(q_i\),包含\(q_i\)的文档数越多,说明\(q_i\)重要性越小,或者区分度越低。因此IDF可以用来刻画\(q_i\)与文档的相似性。
-
单词和文档的相关性
在TF-IDF中,这个信息直接就用“词频”:出现的次数越多越相关。
但是实际上词频和相关性之间的关系是非线性的。具体来说,每一个词对于文档相关性的分数不会超过一个特定的阈值,当词出现的次数达到一个阈值后,其影响不再线性增长,而这个阈值会跟文档本身有关。
在具体操作上,我们对于词频做了标准化处理,具体公式如下:
\(S(q_i,d)={(k_1+1)tf_{td}\over K+tf_{td}}\),\(K=k_1(1-b+b*{L_d\over L_{ave}})\)
其中,\(tf_{td}\)是单词t在文档d中的词频,\(L_d\)是文档d的长度,\(L_{ave}\)是所有文档的平均长度。变量\(k_1\)是一个正参数,用来标准化文章词频的范围。b是另一个可调参数(0<b<1),决定使用文档长度来表示信息量的范围:当b为1,完全使用文档长度来权衡词的权重,当b为0表示不使用文档长度。
-
单词和权重的相关性
当query很长时,我们还需要刻画单词与query的之间的权重。对于短的query,这一项不是必须的:\(S(q_i, Q)={(k_3+1)tf_{tq}\over k_3+tf_{tq}}\)
这里\(tf_{tq}\)表示单词t在query中的词频,\(k_3\)是一个可调正参数,用于矫正query中的词频范围。
-
最终公式
\(RSV_d=\sum_{t∈q}[log{N\over df_t}]·{(k_1+1)tf_{tf}\over k_1((1-b)+b×(L_d/L_{ave}))+tf_{td}}·{(k_3+1)tf_{tq}\over k_3+tf_{tq}}\)
经过试验,上面三个可调参数, \(k_1\) 和 \(k_3\) 可取1.2~2,b取0.75
3. DSSM双塔模型
微软公司提出的一种基于深度神经网络的语义模型,其核心思想是将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之间的余弦相似度,从而训练得到隐含语义模型,达到检索的目的。
通过一个非线性投影将query和documents映射到一个共同的语义空间。其次,对于给定query和每个documents的相关性,通过语义空间下向量间的一个余弦相似度计算出。神经网络模型使用点击数据进行训练,因此给定query的点击documents的条件概率能够最大化。不同于之前的一些无监督方式学习的潜在语义模型,DSSM直接针对网络文档排序进行优化,因此得到了不错的表现。而且在处理大规模词汇表时,DSSM采用了一种词哈希的方法,在没有任何损失的情况下,将高维的queries和documents向量映射到低维letter-n-gram向量。在语义模型中增加了这一层,词哈希方法能够支持大规模词汇表,这在网络检索中尤为重要。
-
结构


- Term Vector:表示文本的embedding向量。
- Word Hashing:为解决term vector太大问题,对bag-of-word向量降维。
- Multi-layer nonlinear projection:表示深度学习网络的隐层。
- Semantic feature:表示query和document最终的embedding向量。
- Relevance measured by cosine similarity:表示query与document之间的余弦相似度。
- Posterior probability computed by softmax:表示通过softmax函数把query与正样本document的语义相似性转化为一个后验概率。
DSSM使用一个DNN模型将语义空间中的高维稀疏文本特征映射到低维稠密特征。第一个隐藏层包含30k个神经元,用于词哈希操作。词哈希特征经过多层非线性映射,最后一层的神经元生成了DNN模型的语义空间特征。
-
Word Hashing
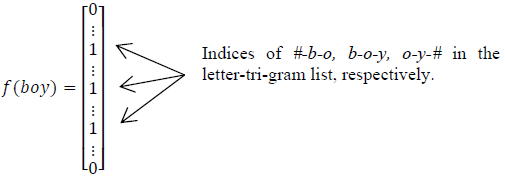
word hashing方法:给定一个词,以单词good为例,首先在该单词上添加开始和结束标记:#good#。然后将其转换成字母n-gram的形式: #go, goo, ood, od#。最后,这个词将通过一个字母n-gram向量表示。
这样做的好处有两个:首先是压缩空间,50 万个词的 one-hot 向量空间可以通过 letter-trigram 压缩为一个 3 万维的向量空间。其次是增强范化能力,三个字母的表达往往能代表英文中的前缀和后缀,而前缀后缀往往具有通用的语义。
这样的方法可能存在两个不同的词语有着相同的字母n-gram向量表示的问题,也就是冲突问题。
如果处理的是中文文本,所以这里我们不分词,而是仿照英文的处理方式,对应到中文的最小粒度就是单字了。由于常用的单字为 1.5 万左右,因此输入层采用字向量(one-hot)作为输入,向量空间约为1.5 万维。
-
表示层
DSSM 的表示层采用 BOW 的方式,相当于把字向量的位置信息抛弃了,整个句子里的词都放在一个袋子里了,不分先后顺序。 紧接着是一个含有多个隐层的 DNN。用 tanh 作为隐层和输出层的激活函数,最终输出一个128维的低纬语义向量。
-
匹配层
Query 和 Doc 的语义相似性可以用这两个语义向量(128 维) 的 cosine 距离来表示:\(R(Q,D)=cosine(y_Q,y_D)={y^T_Qy_D\over ||y_Q||||y_D||}\)
通过softmax函数可以把这个语义相似性转化为后验概率:\(P(D^+|Q)={exp(\gamma R(Q, D^+))\over \sum _{D'∈D}exp(\gamma R(Q, D'))}\)
其中\(\gamma\)为softmax的平滑因子,\(D^+\)为Query下的正样本,\(D'\) 为 Query 下的负样本(采取随机负采样),D 为 Query 下的整个样本空间。
在训练阶段,通过极大似然估计,我们最小化损失函数:\(L=-log \prod_{Q,D^+}P(D^+|Q)\)
-
实施细节
为了确定训练参数并防止过拟合,实验将点击数据分成不重叠的两部分:训练集和验证集。实验过程中,模型在训练集上训练,训练参数在验证集上进行优化。在训练阶段,模型的训练采用的是基于SGD的mini-batch方法,每个mini-batch包含1024个训练样本。实验表明,DNN模型通常在整个数据集上迭代20轮之内达到收敛。
-
优缺点
优点:DSSM 用字向量作为输入既可以减少切词的依赖,又可以提高模型的泛化能力,因为每个汉字所能表达的语义是可以复用的。另一方面,传统的输入层是用 Embedding 的方式(如 Word2Vec 的词向量)或者主题模型的方式(如 LDA 的主题向量)来直接做词的映射,再把各个词的向量累加或者拼接起来,由于 Word2Vec 和 LDA 都是无监督的训练,这样会给整个模型引入误差,DSSM 采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度会比较高。
缺点:上文提到 DSSM 采用词袋模型(BOW),因此丧失了语序信息和上下文信息。另一方面,DSSM 采用弱监督、端到端的模型,预测结果不可控。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号