面试官:你们项目里的线程池是怎么用的?怎么管理的?
线程池这个问题,平时写业务时好像没什么存在感,很多代码里随手就是一个:
ExecutorService executor = Executors.newFixedThreadPool(10);
看起来也能跑,任务也能异步执行,线上一开始也不一定会出问题。
但如果面试官问一句:你们项目里的线程池是怎么用的?怎么管理的?
这时候如果只回答一句“用 Executors.newFixedThreadPool()”,基本就比较危险了。因为生产环境里,线程池不是简单创建几个线程来跑任务,而是要控制资源、控制队列、控制拒绝策略,还要能监控和调整。
本文内容:
- 为什么不建议直接使用
Executors - 常见内置线程池到底有什么问题
ThreadPoolExecutor的几个核心参数怎么理解- 生产环境里线程池一般怎么创建
- 项目中如何统一管理和监控线程池
为什么不建议直接使用 Executors
先用一张图把 Executors 的问题放到一起看:它的风险并不只是“线程池怎么创建”,而是默认参数把很多边界隐藏掉了。
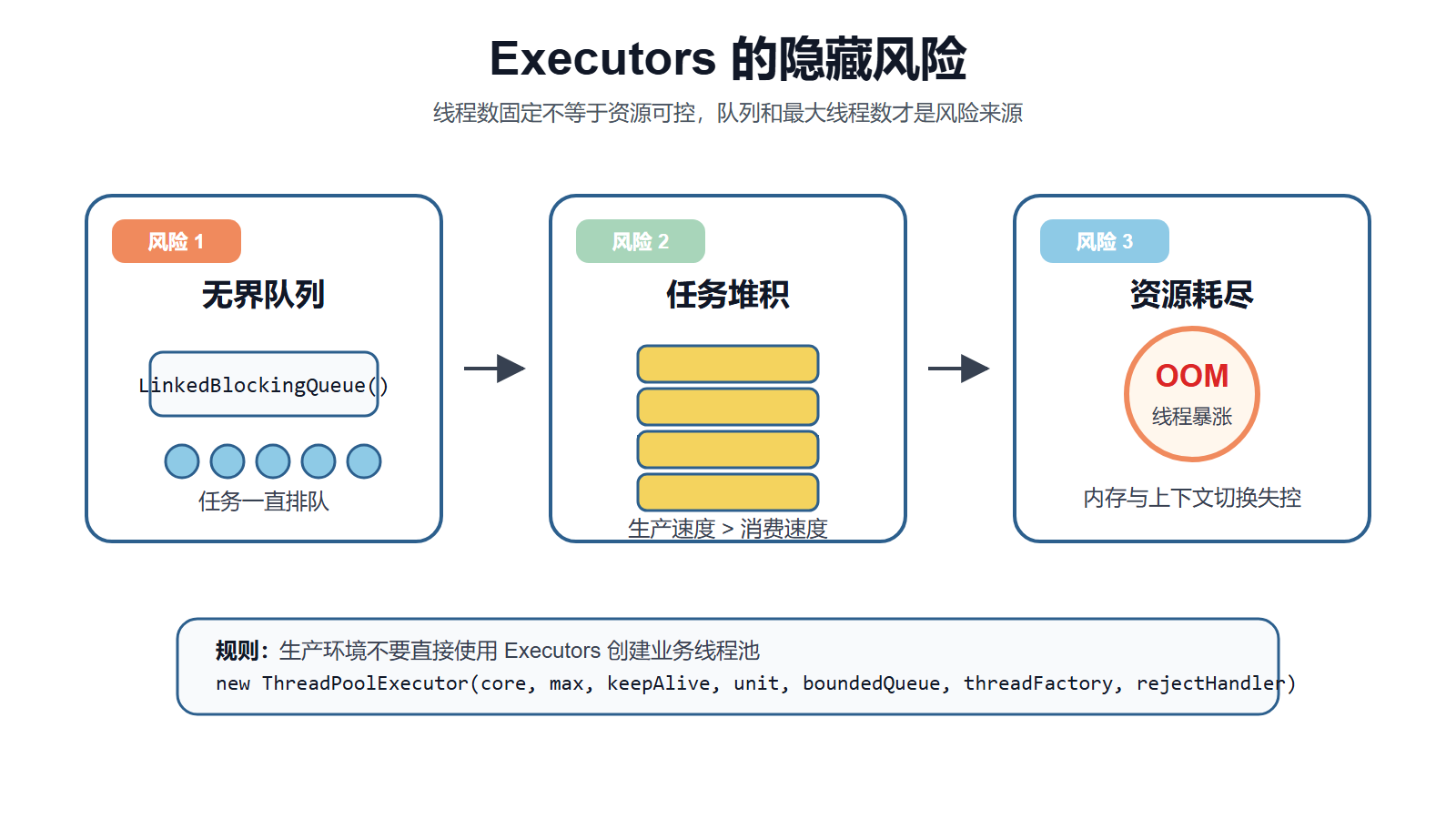
图里最需要关注的是两个边界:队列有没有上限,线程数有没有上限。这两个边界如果没有控制住,任务高峰期就很容易从“异步处理”变成“异步堆积”。
《阿里巴巴 Java 开发手册》中有一条比较常见的规范:
线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式创建。
这句话很多人都背过,但不一定真正理解它的问题在哪里。
我们先看一个最常见的 FixedThreadPool:
ExecutorService executor = Executors.newFixedThreadPool(10);
从使用上看,它创建了一个固定大小为 10 的线程池,好像挺安全的,因为线程数固定了,不会无限创建线程。
但问题不在线程数,而在队列。
newFixedThreadPool 的源码如下:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
注意最后一行:
new LinkedBlockingQueue<Runnable>()
LinkedBlockingQueue 如果不指定容量,默认容量是:
Integer.MAX_VALUE
也就是说,这个队列基本上可以认为是无界队列。
如果线程池里有 10 个线程,某一段时间内任务突然变多,那么前 10 个任务会被线程执行,后面的任务就会一直进入队列。因为队列几乎没有上限,所以线程池不会拒绝任务,任务只会越堆越多。
如果任务生产速度一直大于消费速度,最后占用的就是堆内存,严重时就会导致 OOM。
所以 FixedThreadPool 最大的问题不是“线程数固定”,而是“队列没限制”。
这也是为什么生产环境里一般要求使用 ThreadPoolExecutor 显式创建线程池,把核心线程数、最大线程数、队列大小、线程工厂、拒绝策略都写清楚。
几种内置线程池的问题
Executors 里提供了几种常见线程池:
FixedThreadPoolSingleThreadExecutorCachedThreadPoolScheduledThreadPool
它们不是完全不能用,而是不适合在生产代码里不加控制地直接用。我们分别来看一下。
FixedThreadPool
前面已经看过它的源码:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
它的参数相当于:
- 核心线程数等于最大线程数
- 线程数固定
- 使用无界
LinkedBlockingQueue
因为队列是无界的,所以当核心线程都在忙时,后续任务只会一直排队,不会触发扩容,也不容易触发拒绝策略。
很多人以为固定线程池比较稳,其实它只是把压力藏到了队列里。队列没满之前,系统看起来都还正常;等到内存撑不住时,问题就已经比较严重了。
SingleThreadExecutor
SingleThreadExecutor 的源码也很类似:
public static ExecutorService newSingleThreadExecutor() {
return new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
它只有一个工作线程,后面的任务都会排队串行执行。
如果只是少量后台任务,问题不明显。但如果任务提交速度很快,而这个单线程消费不过来,任务还是会一直堆到无界队列里。
所以它的问题和 FixedThreadPool 一样,只是更隐蔽,因为大家看到“单线程”时,会觉得它更可控。
实际上线程数是可控了,队列还是不可控。
CachedThreadPool
再看 CachedThreadPool:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
这个线程池的特点是:
- 核心线程数为 0
- 最大线程数是
Integer.MAX_VALUE - 使用
SynchronousQueue - 空闲线程 60 秒后回收
SynchronousQueue 比较特殊,它不存任务。提交任务时,必须马上有线程接收;如果没有空闲线程,就会创建新线程。
这就带来一个问题:如果任务提交很快,任务执行又比较慢,线程池就会不断创建新线程。
线程并不是免费的。线程多了以后,会带来线程栈内存占用,也会带来大量上下文切换。严重时 CPU 会被切换消耗拖住,内存也可能被打满。
所以 CachedThreadPool 的风险不在队列,而在线程数几乎没有上限。
ScheduledThreadPool
ScheduledThreadPool 一般用来执行延迟任务或者周期任务。
它底层使用的是延迟队列,队列本身也没有一个业务意义上的容量限制。如果定时任务提交过多,或者任务执行时间超过了调度周期,也会出现任务堆积。
比如一个任务每 1 秒调度一次,但每次执行需要 5 秒,如果没有控制好,就容易产生积压。
所以定时任务线程池也不能只关注线程数,还要关注任务是否堆积、任务执行耗时是否超过周期。
ThreadPoolExecutor 的几个核心参数
理解 ThreadPoolExecutor 的参数之前,最好先把任务提交后的执行顺序搞清楚。很多线程池问题,都是因为误以为“最大线程数会马上生效”。
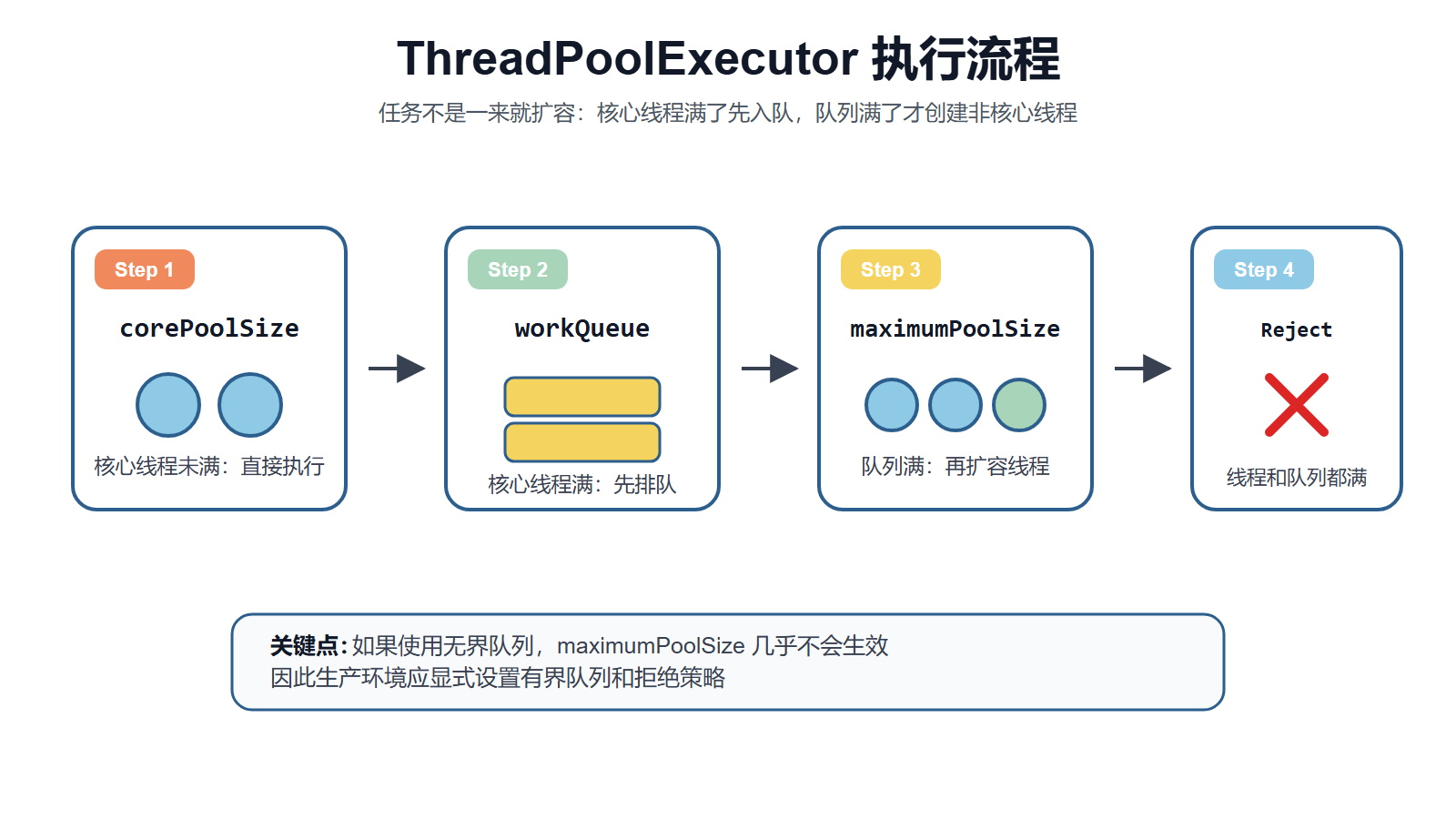
这张图的关键点是:核心线程满了以后,任务会先进入队列;只有队列也满了,才会继续创建非核心线程。所以队列类型和队列容量,会直接影响 maximumPoolSize 是否有机会发挥作用。
既然不建议直接使用 Executors,那我们就要自己创建 ThreadPoolExecutor。
它常用的构造方法如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler);
这些参数不是随便填的,线程池在高峰期怎么表现,基本都由它们决定。
corePoolSize
corePoolSize 表示核心线程数。
当任务提交到线程池时,如果当前线程数还没有达到 corePoolSize,线程池会创建新线程来执行任务。
如果当前线程数已经达到 corePoolSize,任务就会进入队列等待。
所以核心线程数太小,任务容易排队;核心线程数太大,又会造成线程资源浪费,甚至带来更多上下文切换。
一般会根据任务类型来估算一个初始值。
如果是 CPU 密集型任务,比如计算、加密、压缩等,线程数通常可以设置为:
CPU 核心数 + 1
如果是 IO 密集型任务,比如访问数据库、Redis、RPC 接口、文件、网络等,线程经常处于等待状态,线程数可以适当多一些。
常见估算公式是:
线程数 = CPU 核心数 * (1 + IO 耗时 / CPU 耗时)
不过这个公式只能给一个初始值,不能当成最终答案。真正的参数还是要结合压测和线上监控来调整。
maximumPoolSize
maximumPoolSize 表示线程池允许创建的最大线程数。
它不是一开始就生效的。线程池只有在下面几个条件都满足时,才会继续创建非核心线程:
- 核心线程已经满了
- 队列也满了
- 当前线程数还小于
maximumPoolSize
这里有一个很容易被忽略的点:如果使用的是无界队列,那么 maximumPoolSize 基本就没什么机会生效。
因为核心线程满了之后,任务会一直进入队列,而队列又几乎不会满,所以线程数最多也就到 corePoolSize。
这也是为什么我们不建议用无界队列。无界队列不仅可能导致 OOM,还会让最大线程数这个参数失去意义。
keepAliveTime
keepAliveTime 控制的是非核心线程的空闲存活时间。
当线程池里的线程数超过 corePoolSize 后,多出来的线程就是非核心线程。如果这些线程空闲时间超过了 keepAliveTime,就会被回收。
默认情况下,核心线程不会因为空闲而回收。
如果希望核心线程也能超时回收,可以这样设置:
threadPoolExecutor.allowCoreThreadTimeOut(true);
不过这个配置要看场景。
如果某个线程池使用频率很高,核心线程频繁创建和销毁反而会增加开销。如果是低频任务,或者任务波动比较大,可以考虑让核心线程也支持超时回收。
workQueue
队列是线程池里非常关键的一个参数。
它决定了任务来了以后,是先排队,还是扩容线程,还是直接触发拒绝策略。
生产环境里,最重要的一点是:队列最好有容量限制。
ArrayBlockingQueue
ArrayBlockingQueue 是基于数组实现的有界队列,创建时必须指定容量:
new ArrayBlockingQueue<>(1000)
它的特点是容量固定,内存相对可控,比较适合对稳定性要求比较高的业务线程池。
缺点是生产者和消费者共用一把锁,在并发非常高时吞吐一般,但很多业务场景下已经够用了。
LinkedBlockingQueue
LinkedBlockingQueue 是基于链表实现的阻塞队列。
它有两种写法:
new LinkedBlockingQueue<>()
new LinkedBlockingQueue<>(1000)
第一种不指定容量,就是前面说的高风险写法,因为默认容量是 Integer.MAX_VALUE。
第二种指定容量后,是可以使用的。
所以问题不在 LinkedBlockingQueue 这个类本身,而在于很多人用了默认构造方法,导致队列变成了无界队列。
SynchronousQueue
SynchronousQueue 不存储任务,它更像是任务的直接交接。
提交任务时,如果有空闲线程接收,就交给线程执行;如果没有空闲线程,就看线程池是否还能创建新线程;如果不能创建,就触发拒绝策略。
它适合任务执行时间较短、希望任务不要在队列里堆积的场景。
但使用它时一定要控制好 maximumPoolSize,否则就可能变成线程数暴涨。
ThreadFactory
线程工厂经常被忽略,但线上排查问题时它很重要。
比如我们可以给线程设置业务名称:
public class NamedThreadFactory implements ThreadFactory {
private final AtomicInteger count = new AtomicInteger();
private final String name;
public NamedThreadFactory(String name) {
this.name = name;
}
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setName(name + "-" + count.getAndIncrement());
thread.setDaemon(false);
return thread;
}
}
这样当线上出现 CPU 飙高、线程阻塞、死锁等问题时,通过线程名就能知道是哪个业务线程池出了问题。
如果线程名都是默认的 pool-1-thread-1,排查起来就很难受。
RejectedExecutionHandler
当线程池达到最大线程数,并且队列也满了,再提交任务就会触发拒绝策略。
JDK 默认提供了几种策略:
| 策略 | 说明 |
|---|---|
AbortPolicy |
直接抛出 RejectedExecutionException |
DiscardPolicy |
直接丢弃任务,不抛异常 |
DiscardOldestPolicy |
丢弃队列中最早的任务,然后重新提交当前任务 |
CallerRunsPolicy |
由提交任务的线程自己执行任务 |
这几个策略没有绝对好坏,要看业务能不能接受任务丢失、能不能接受调用方被阻塞。
如果任务不能丢,通常不能直接用 DiscardPolicy。
如果希望问题尽快暴露,可以使用 AbortPolicy,但调用方要处理好异常。
如果使用 CallerRunsPolicy,任务不会被丢,但提交任务的线程会被拖住。比如一个 HTTP 请求线程提交异步任务,结果线程池满了,这个异步任务就由请求线程自己执行。如果任务很慢,就会拖慢主链路,严重时还可能把 Tomcat 线程池也拖住。
所以拒绝策略最少要做两件事:
- 记录日志
- 打监控或报警
任务被拒绝说明线程池已经饱和了,这不是普通异常,而是系统处理能力不足的信号。
线程池参数怎么定
线程池参数没有一个通用答案。
比如同样是 8 核机器,一个线程池是做本地计算,另一个线程池是调用下游接口,这两个线程池的参数就不应该一样。
通常可以先按下面这个思路来定初始值:
- 先区分任务类型,是 CPU 密集型还是 IO 密集型
- 估算单个任务耗时,以及任务中等待 IO 的比例
- 根据机器资源给一个初始线程数
- 队列一定要有容量限制
- 拒绝策略要结合业务语义选择
- 上线后通过监控观察,再调整参数
比如一个调用外部接口的异步任务,耗时主要在网络等待上,可以适当把线程数调大一些;但如果任务里有大量计算,就不能盲目加线程,因为线程太多反而会让 CPU 花更多时间做上下文切换。
另外还要注意一点:队列容量不是越大越好。
队列大,只是能放更多任务,不代表处理能力变强。如果队列一直在涨,本质上说明消费能力已经跟不上了。队列越大,任务等待时间可能越长,用户感知到的延迟也可能越明显。
所以线程池要看的不是“能不能放得下”,而是“能不能及时处理完”。
项目里一般怎么封装线程池
参数理解清楚以后,落到项目里还要解决另一个问题:不能让每个业务方都按自己的习惯创建线程池。否则线程名、队列容量、拒绝策略和监控方式都会变得不统一。
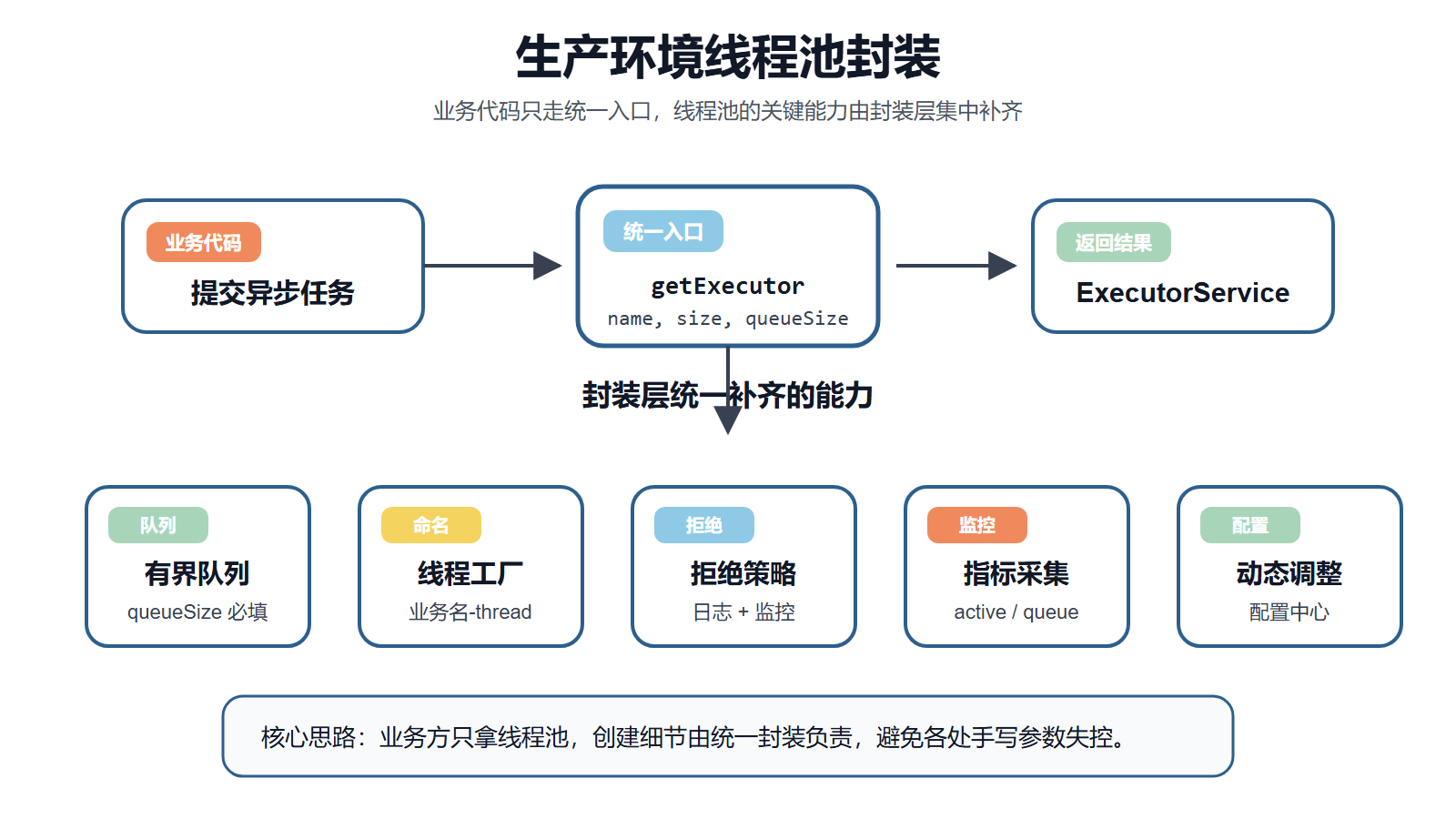
比较稳妥的做法是提供统一入口,让业务只关心线程池名称和必要参数,底层统一补齐有界队列、命名线程工厂、拒绝策略、监控采集和动态配置。
在项目中,最好不要让业务代码到处自己 new ThreadPoolExecutor。
因为每个人写法不一样,有的人不设置线程名,有的人用无界队列,有的人没有拒绝策略,有的人没有监控。最后项目里线程池越来越多,出了问题也不好查。
比较常见的做法是封装一个统一的工具类或者组件,业务方通过统一入口创建线程池。
比如我们可以提供一个方法:
DynamicExecutorHelper.getExecutor(name, size, queueSize)
这里至少要做到几件事:
- 线程池名字由业务传入
- 队列容量必须显式传入
- 线程工厂统一设置线程名
- 拒绝策略统一打日志和监控
- 定时采集线程池指标
- 支持从配置中心动态调整线程数
- 包装任务,传递 MDC 或 trace 上下文
下面看一个简化后的实现思路。
统一创建线程池
核心创建逻辑可以写成这样:
public static ExecutorService getExecutor(String name, int size, int queueSize) {
ExecutorWrapper executorWrapper = executorWrapperCache.getIfPresent(name);
if (executorWrapper == null) {
synchronized (DynamicExecutorHelper.class) {
executorWrapper = executorWrapperCache.getIfPresent(name);
if (executorWrapper == null) {
ensureMonitorInitialized();
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
size,
size,
1,
TimeUnit.MINUTES,
queueSize <= 0 ? new SynchronousQueue<>() : new LinkedBlockingDeque<>(queueSize),
new NamedThreadFactory(name),
new ExecutorRejectedExecutionHandler(name)
);
executorWrapper = new ExecutorWrapper(name, threadPoolExecutor);
executorWrapperCache.put(name, executorWrapper);
rejectCounters.put(name, new AtomicInteger(0));
}
}
}
return executorWrapper.getWrapperExecutorService();
}
这里有几个点比较关键。
第一,线程池按名称缓存,同一个业务线程池不会重复创建。
第二,队列没有使用默认无界队列:
queueSize <= 0 ? new SynchronousQueue<>() : new LinkedBlockingDeque<>(queueSize)
如果 queueSize > 0,就使用有界队列;如果 queueSize <= 0,就使用 SynchronousQueue,表示任务不排队。
第三,线程工厂和拒绝策略都是统一的,这样线程名、日志、监控都能统一起来。
线程池要有监控
线程池创建出来以后,不能只管提交任务,还要定时采集指标。
比如:
private static void recordMetrics(String name, ThreadPoolExecutor threadPoolExecutor) {
SMonitor.recordOne("dynamic_executor_core_" + name + "_" + threadPoolExecutor.getCorePoolSize());
SMonitor.recordOne("dynamic_executor_max_" + name + "_" + threadPoolExecutor.getMaximumPoolSize());
SMonitor.recordOne("dynamic_executor_active_" + name + "_" + threadPoolExecutor.getActiveCount());
SMonitor.recordOne("dynamic_executor_pool_size_" + name + "_" + threadPoolExecutor.getPoolSize());
SMonitor.recordOne("dynamic_executor_queue_size_" + name + "_" + threadPoolExecutor.getQueue().size());
SMonitor.recordOne("dynamic_executor_queue_remain_cap_" + name + "_" + threadPoolExecutor.getQueue().remainingCapacity());
SMonitor.recordOne("dynamic_executor_completed_task_" + name + "_" + threadPoolExecutor.getCompletedTaskCount());
}
这些指标里,最常看的有两个:
threadPoolExecutor.getActiveCount();
threadPoolExecutor.getQueue().size();
getActiveCount() 能看到当前有多少线程正在执行任务。
getQueue().size() 能看到有多少任务正在排队。
如果活跃线程数长期接近线程池大小,说明线程基本都在忙。
如果队列长度持续上涨,说明任务已经开始堆积。
这两个指标要结合起来看。只有活跃线程高,不一定有问题,可能只是高峰期;但如果活跃线程高,同时队列也一直涨,那就要关注了。
拒绝任务要能看到
拒绝策略里不要静默处理。
可以类似这样:
public static class ExecutorRejectedExecutionHandler implements RejectedExecutionHandler {
private final String name;
public ExecutorRejectedExecutionHandler(String name) {
this.name = name;
}
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
if (!executor.isShutdown()) {
SMonitor.recordOne("dynamic_executor_task_reject_" + name);
AtomicInteger rejectCounter = rejectCounters.get(name);
if (rejectCounter != null) {
rejectCounter.incrementAndGet();
}
log.warn("ThreadPool[{}] rejected task, poolSize: {}, active: {}, queueSize: {}, remainingCapacity: {}",
name,
executor.getPoolSize(),
executor.getActiveCount(),
executor.getQueue().size(),
executor.getQueue().remainingCapacity());
r.run();
}
}
}
这里最后的:
r.run();
相当于 CallerRunsPolicy,也就是让提交任务的线程自己执行。
这个做法可以形成一定的反压。线程池忙不过来时,提交方也会被拖慢,任务提交速度自然会下降。
但它不是万能的。如果提交方是主业务线程,而任务又很耗时,就可能影响主链路。因此只要触发拒绝,就应该有日志和报警,后续要看是扩容、降级,还是排查下游耗时。
支持动态调整线程数
线程池参数最好不要写死。
因为线上流量会变化,下游耗时会变化,任务数量也会变化。今天合适的参数,过一段时间不一定还合适。
可以从配置中心读取线程池大小:
private static void adjustThreadPoolSize(String name, ThreadPoolExecutor threadPoolExecutor) {
String coreSizeStr = CommonConfig.get("dynamic.executor.size." + name);
if (coreSizeStr != null && !coreSizeStr.isEmpty()) {
int newSize = Integer.parseInt(coreSizeStr);
resizeThreadPool(threadPoolExecutor, newSize);
}
}
调整时要注意 ThreadPoolExecutor 的约束:
maximumPoolSize >= corePoolSize
所以扩容和缩容的顺序不能写反。
比如:
private static void resizeThreadPool(ThreadPoolExecutor threadPoolExecutor, int newSize) {
int currentMax = threadPoolExecutor.getMaximumPoolSize();
int currentCore = threadPoolExecutor.getCorePoolSize();
if (newSize > currentMax) {
threadPoolExecutor.setMaximumPoolSize(newSize);
threadPoolExecutor.setCorePoolSize(newSize);
} else if (newSize < currentCore) {
threadPoolExecutor.setCorePoolSize(newSize);
threadPoolExecutor.setMaximumPoolSize(newSize);
} else {
threadPoolExecutor.setCorePoolSize(newSize);
}
}
扩容时,先调大 maximumPoolSize,再调大 corePoolSize。
缩容时,先调小 corePoolSize,再调小 maximumPoolSize。
否则可能会因为 maximumPoolSize 小于 corePoolSize 而抛异常。
任务包装和链路上下文
线程池还有一个常见问题:跨线程后日志上下文丢失。
比如主线程里有 traceId,放在 MDC 里。任务提交到线程池后,执行任务的是另一个线程,MDC 默认不会自动传过去。
这时可以在提交任务时包一层:
public static class MdcTaskWrapper<T> implements Runnable, Callable<T>, Supplier<T> {
private final long startTime = System.currentTimeMillis();
private final Runnable runnable;
private final Callable<T> callable;
private final Supplier<T> supplier;
private final Map<String, String> mdcMap;
private MdcTaskWrapper(Runnable runnable, Callable<T> callable, Supplier<T> supplier) {
this.runnable = runnable;
this.callable = callable;
this.supplier = supplier;
Map<String, String> currentMdcMap = MDC.getCopyOfContextMap();
this.mdcMap = currentMdcMap == null ? Collections.emptyMap() : currentMdcMap;
}
@Override
public void run() {
execute();
}
@Override
public T call() throws Exception {
return execute();
}
@Override
public T get() {
return execute();
}
private T execute() {
Map<String, String> oldMdcMap = null;
try {
oldMdcMap = MDC.getCopyOfContextMap();
MDC.setContextMap(mdcMap);
long delay = System.currentTimeMillis() - startTime;
SMonitor.recordQuantile("executor_task_delay", delay);
if (supplier != null) {
return supplier.get();
}
if (callable != null) {
return callable.call();
}
if (runnable != null) {
runnable.run();
}
return null;
} catch (Exception e) {
throw e instanceof RuntimeException ? (RuntimeException) e : new RuntimeException(e);
} finally {
if (oldMdcMap != null) {
MDC.setContextMap(oldMdcMap);
} else {
MDC.clear();
}
}
}
}
这段代码主要做了两件事。
第一,在任务提交时保存当前线程的 MDC:
Map<String, String> currentMdcMap = MDC.getCopyOfContextMap();
第二,在任务真正执行时设置 MDC,执行完再恢复原来的上下文:
MDC.setContextMap(mdcMap);
这样异步任务里的日志也能串到同一条链路上。
另外这里还记录了一个任务排队延迟:
long delay = System.currentTimeMillis() - startTime;
这个指标很有用。它表示任务从提交到真正开始执行,中间等了多久。
有时候队列长度看起来不算特别高,但任务排队时间已经很长了,这说明线程池处理能力可能已经跟不上了。
线程池一般怎么治理
线程池创建出来只是第一步,真正在线上稳定运行,还要持续观察它的状态。活跃线程数、队列长度、拒绝次数和任务排队延迟,往往比单纯看线程数更有价值。
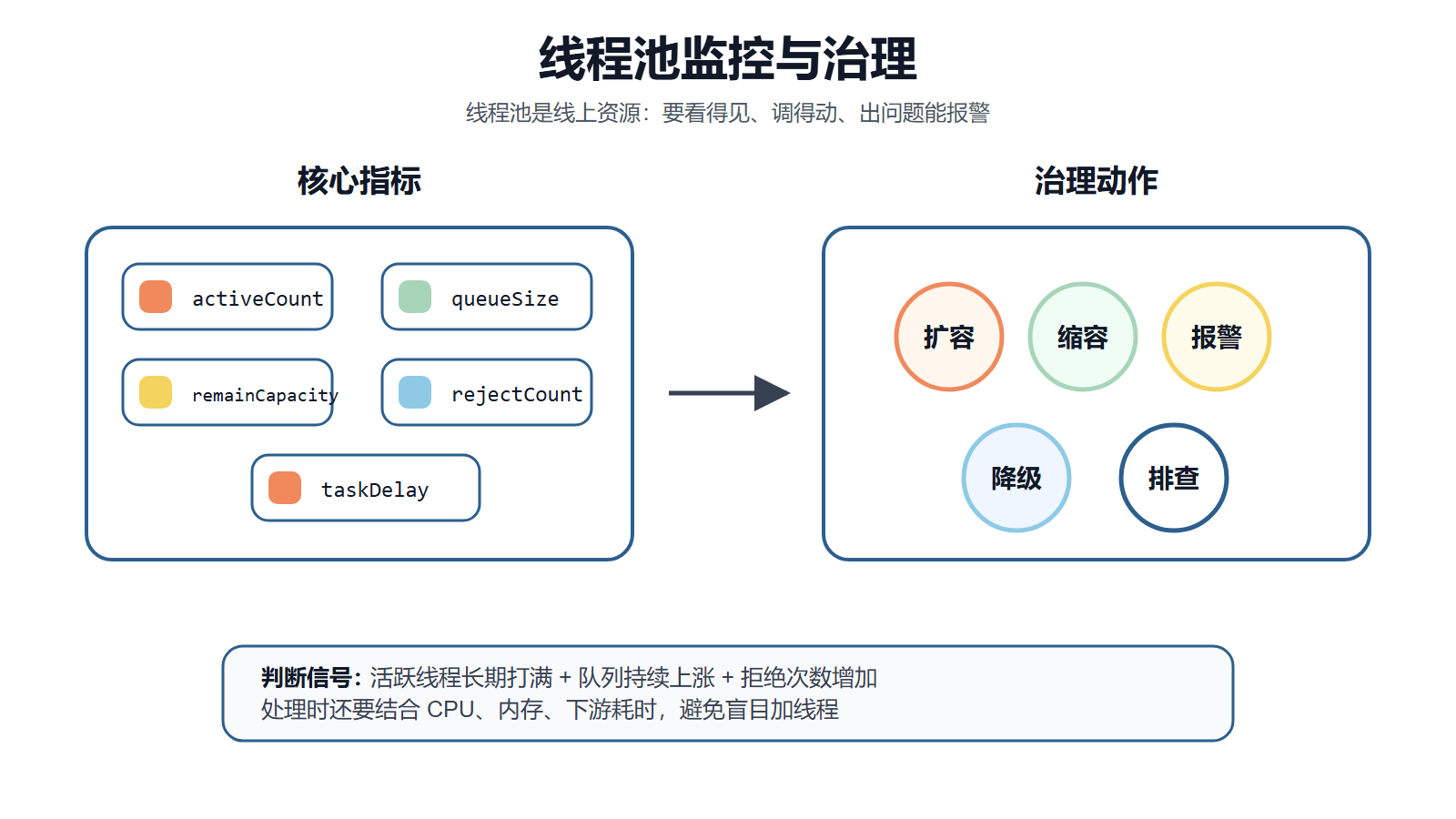
如果这些指标长期异常,就不能只想着把线程数调大,还要结合 CPU、内存和下游耗时一起看,判断是扩容、降级,还是排查慢任务和下游抖动。
如果把线程池当成一个普通工具类,用的时候拿来提交任务,不用的时候不管它,那迟早会出问题。
在线上,线程池更像是一种资源,需要治理。
比较基本的要求有下面几个。
统一创建
业务代码不要到处手写线程池。
统一入口创建线程池,可以保证线程名、队列容量、拒绝策略、监控这些东西都不会漏。
队列有界
不要使用默认无界队列。
不管是 ArrayBlockingQueue,还是指定容量的 LinkedBlockingQueue,重点是容量要明确。
容量明确以后,系统压力过大时才会暴露出来,才有机会触发拒绝策略、报警、降级。
指标可观测
至少要关注这些指标:
| 指标 | 方法 |
|---|---|
| 核心线程数 | getCorePoolSize() |
| 最大线程数 | getMaximumPoolSize() |
| 当前线程数 | getPoolSize() |
| 活跃线程数 | getActiveCount() |
| 队列长度 | getQueue().size() |
| 队列剩余容量 | getQueue().remainingCapacity() |
| 已完成任务数 | getCompletedTaskCount() |
| 拒绝任务数 | 自定义拒绝策略统计 |
其中活跃线程数、队列长度、拒绝任务数是最常看的几个。
参数可调整
线程池参数不是一次写完就永远不动。
如果队列持续上涨,活跃线程长期打满,并且机器资源还有余量,可以考虑扩容线程数。
如果线程池长期很空闲,线程数明显过多,也可以考虑缩容。
不过调参数时不要只看线程池本身,也要看 CPU、内存、下游服务耗时。否则盲目扩容线程数,可能只是把压力转移到数据库、Redis 或下游接口上。
总结
所以回到最开始的问题:你们项目中都是怎么用线程池的?
比较好的回答不是简单说“我们用了 FixedThreadPool”,而是要说清楚这些点:
- 不直接使用
Executors创建业务线程池 - 使用
ThreadPoolExecutor显式指定参数 - 队列使用有界队列,避免任务无限堆积
- 线程工厂统一设置业务线程名
- 拒绝策略要记录日志、打监控,不能静默丢任务
- 线程池指标要定时采集,重点关注活跃线程数、队列长度、拒绝次数
- 参数最好能通过配置中心动态调整
- 异步任务需要考虑 MDC、traceId 等上下文传递
线程池本身不复杂,复杂的是线上环境里的流量变化、下游抖动和任务堆积。
用得好,它可以帮我们削峰、隔离和提升吞吐。
用得不好,它也可能把一个小问题放大成线上事故。
本文来自在线网站:seven的菜鸟成长之路,作者:seven,转载请注明原文链接:www.seven97.top

 浙公网安备 33010602011771号
浙公网安备 33010602011771号