
Day6 Scrum冲刺博客
Day6 Scrum冲刺博客
周末两天均有成员参加国家体质测试,全体休息两天
1. 团队会议
因为各成员有不同的课程与实习安排,难以找到大家都在的线下时间,所以采用线上会议代替站立式会议。
1)大前天已完成的工作
- 前端
- 完成请求体与接口规定
- 前后端初步尝试对接联调
- 后端
- 完成了适配更多网站的爬虫程序
- 完成了问答接口的本地调试
- 测试
- 初步完成多个功能的测试代码
2)今天计划完成的工作
- 前端
- 完成了问答模式与栏目模式的前后端对接
- 后端
- 完成了适配更多网站的爬虫程序
- 重新整理接口与知识库,与前端完成对接
- 测试
- 完成多个基础功能的测试代码
3)工作中遇到的困难
- 前端
- 真正联调过程中发现Axios 不支持真正的流式响应,浏览器端 Axios 基于 XMLHttpRequest,而 XMLHttpRequest 的 responseType属性不允许设为 stream,合法值仅有: arraybuffer | blob | document | json | text。
- 后端
- 在适配更多网站的爬虫时,不同站点的HTML结构差异较大,通用解析规则难以直接适用,需要手动为异常页面编写额外逻辑,影响开发效率。
- 测试
- 测试过程中发现部分功能缺乏足够的边界条件验证,导致自动化测试需要补充额外mock数据与场景,增加了测试代码编写的复杂度。
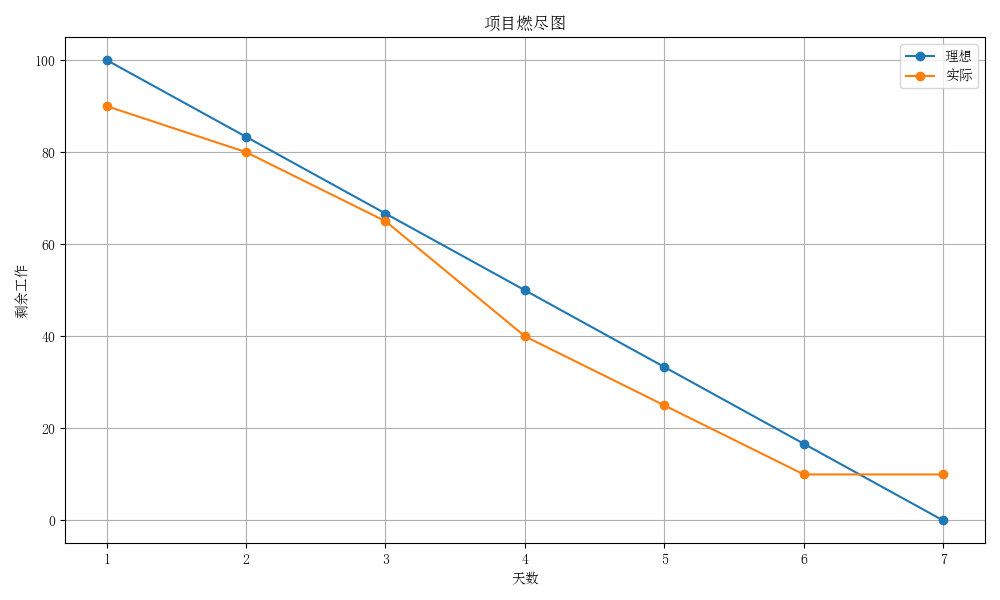
2. 项目燃尽图
今日为第六天,已快于理想进度,准备收尾工作。
3.代码/文档签入记录
-
今日签入记录
![]()
-
签入记录链接:https://github.com/sevanthea7/GdutInfoHub/commits/main/
-
相关联issue见commit记录中
#后链接内容 -
接口文档与返回格式文档见
docs/api_doc.md与docs/return_doc.md
4. 运行截图
-
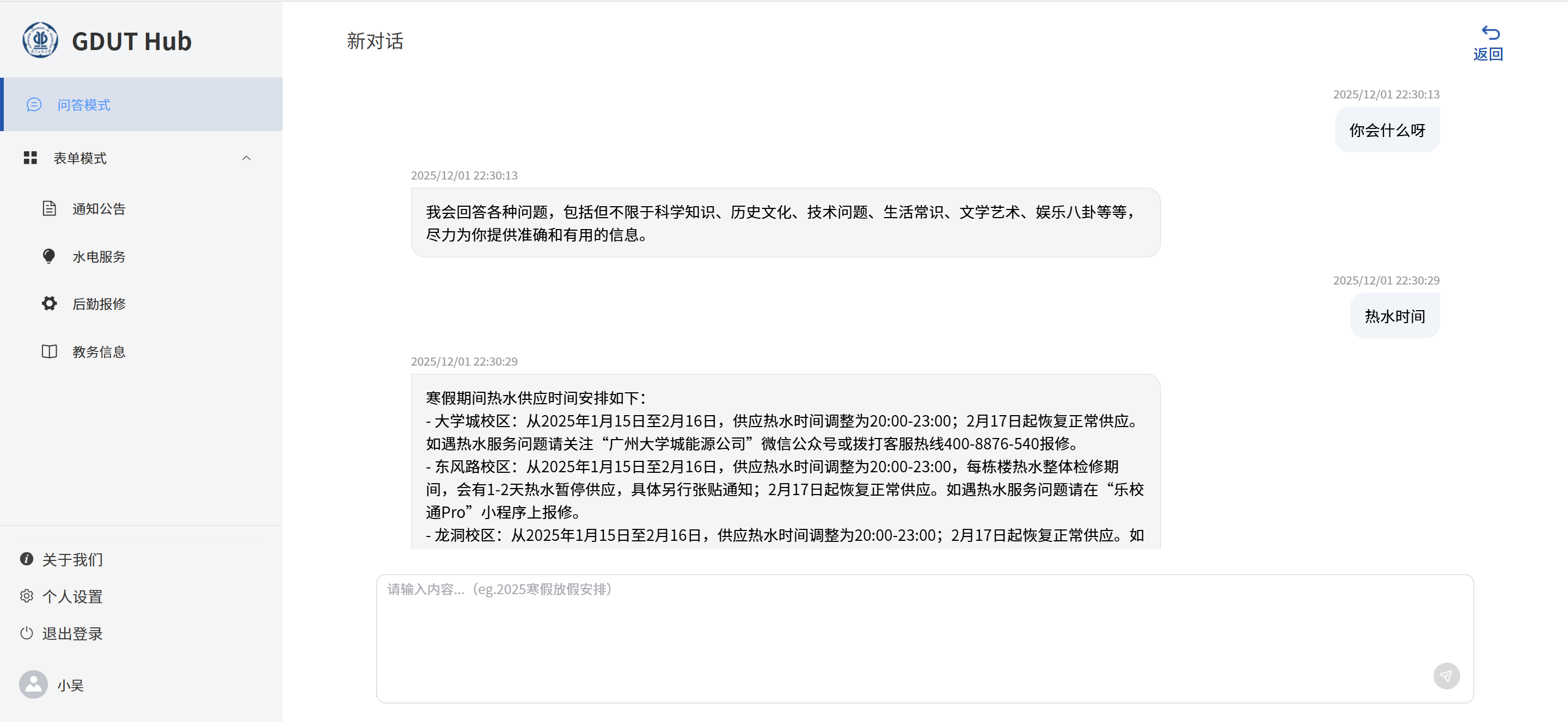
前端
-
问答模式前后端接口联调
核心代码: // 发送流式请求 const sendStreamRequest = async (question) => { isStreaming.value = true; streamingContent.value = ""; currentTime.value = formatTime(new Date()); try { const response = await fetch("/api/stream", { method: "POST", headers: { "Content-Type": "application/json", }, body: JSON.stringify({ question: question.trim() }), }); if (!response.ok) { throw new Error(`HTTP error! status: ${response.status}`); } console.log("响应体:", response); // 处理流式响应 await processRealStream(response); } catch (error) { console.error("流式请求错误:", error); streamingContent.value = "抱歉,请求过程中出现错误,请稍后重试。"; } finally { completeStreamResponse(); } }; // 处理流式数据 const processRealStream = async (response) => { const reader = response.body.getReader(); const decoder = new TextDecoder("utf-8"); let hasContent = false; try { while (true) { const { done, value } = await reader.read(); if (done) break; const chunk = decoder.decode(value, { stream: true }); // 检查状态标记 if (chunk.includes("[STATUS]NO_CONTENT")) { streamingContent.value = "抱歉,无法理解您的问题。"; } else if (chunk.includes("[STATUS]NO_MATCHING_CONTENT")) { streamingContent.value = "抱歉,未找到相关内容。"; } else { hasContent = true; streamingContent.value += chunk; } nextTick(scrollToBottom); } // 如果整个流式过程都没有实际内容 if (!hasContent && !streamingContent.value) { streamingContent.value = "抱歉,未找到相关内容。"; } } finally { reader.releaseLock(); } };![]()
-
-
后端
-
重新整理了与前端对接的接口
这里以栏目模式为例:
import json import os import re def normalize_date(date_str): if not date_str: return "" parts = re.findall(r"\d+", date_str) if len(parts) >= 3: year, month, day = parts[:3] # 补零(保证两位数) month = month.zfill(2) day = day.zfill(2) return f"{year}/{month}/{day}" return date_str def search_news_by_label(label, folder_path): matched_contents = [] for filename in os.listdir(folder_path): if filename.endswith('_database.json'): # 读取所有结尾是_database的文件 file_path = os.path.join(folder_path, filename) with open(file_path, 'r', encoding='utf-8') as f: try: data = json.load(f) # 读取文件 except json.JSONDecodeError: print(f"文件 {filename} 不是有效 JSON,跳过") continue for news in data: news_label = news.get("label") if not isinstance(news_label, str): continue if label == news_label: # matched_contents.append(news) cleaned_news = dict(news) # 复制一份,避免直接修改原数据 # 删除字段 cleaned_news.pop("label", None) cleaned_news.pop("keywords", None) if label != "通知公告" and "column" in cleaned_news: cleaned_news.pop("column", None) if "date" in cleaned_news: cleaned_news["date"] = normalize_date(cleaned_news["date"]) matched_contents.append(cleaned_news) num_lb = len(matched_contents) print(f'查找到 {label} 内容共 {num_lb} 条!') return matched_contents-
运行截图
![]()
-
-
补充了体育馆、通识教育以及党建部相关网站的爬虫
这里以党建部为例:
from bs4 import BeautifulSoup from urllib.parse import urljoin from urllib3.exceptions import InsecureRequestWarning import urllib3 urllib3.disable_warnings(InsecureRequestWarning) from src.crawler.crawler.tool_func import save_json, get_html, parse_detail_page BASE_URL = 'https://zzb.gdut.edu.cn/info/' START_PAGE = "https://zzb.gdut.edu.cn/tzgg.htm" # 列表页地址 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36" } NEWS_TYPE = 'party_news' def parse_list_page(url): resp_text = get_html(url, headers) if resp_text is None: return [] soup = BeautifulSoup(resp_text, "html.parser") rows = soup.find_all("tr") results = [] for tr in rows: a = tr.find("a") if not a: continue link = urljoin(url, a.get("href")) # 过滤非本站链接 if not link.startswith(BASE_URL): continue title = a.get_text(strip=True) results.append({ "title": title, "url": link # "date": date }) return results def crawl_all_pages(start_url): all_results = [] next_page = start_url while next_page: print(f"\n抓取列表页: {next_page}") articles = parse_list_page(next_page) for article in articles: print(f"*抓取文章: {article['title']}") # 抓取内容页 detail = parse_detail_page(article["url"], headers, True) article["content"] = detail["content"] article["date"] = detail["date"] all_results.append(article) # 解析下一页 resp_text = get_html(next_page, headers) if resp_text is None: break soup = BeautifulSoup(resp_text, "lxml") next_link = soup.find("a", class_="Next", string=lambda x: x and "下页" in x) if next_link: next_page = urljoin(next_page, next_link["href"]) else: next_page = None return all_results def crawl_party_func(save_path): data = crawl_all_pages(START_PAGE) save_json(save_path, NEWS_TYPE, data)-
运行截图
![]()
-
-
-
测试
这里以关键词提取测试为例:
def test_search_keyword_skill(): """测试关键词「技能」的搜索功能""" # 1. 执行搜索 result = search_news_by_keywords(['技能'], TEST_FOLDER) # 2. 断言(验证结果符合预期) assert isinstance(result, list), "返回结果必须是列表" # 如果已知有匹配数据,可加:assert len(result) > 0, "未找到任何包含「技能」的新闻" def test_search_nonexistent_keyword(): """测试搜索不存在的关键词(比如「不存在的关键词123」)""" result = search_news_by_keywords(['不存在的关键词123'], TEST_FOLDER) assert isinstance(result, list), "返回结果必须是列表" assert len(result) == 0, "搜索不存在的关键词应返回空列表" def test_search_empty_keywords(): """测试搜索空关键词列表""" result = search_news_by_keywords([], TEST_FOLDER) assert len(result) == 0, "空关键词应返回空列表" def test_invalid_folder_path(): """测试无效的文件夹路径""" result = search_news_by_keywords(['技能'], '../invalid_folder') assert len(result) == 0, "无效路径应返回空列表" if __name__ == '__main__': matched_result = search_news_by_keywords(['技能'], TEST_FOLDER) print("\n" + "=" * 50) print("匹配到的具体内容:") print("=" * 50) for idx, content in enumerate(matched_result, 1): print(f"\n【第{idx}条】") print(content[:200] + "..." if len(content) > 200 else content)


5. 每人每日总结
- 前端
- 吴佳童:今天参与完成了问答模式与栏目模式的前后端对接工作。对多个接口进行了调试,验证了传参流程及数据渲染逻辑,并在联调中修复了部分字段不一致的问题,使整体流程更加顺畅。
- 张洁:完成了栏目模式接口的重新整理与定义工作,重新规范了字段格式、响应结构及调用方式。此举有效减少了前后端沟通成本,为后续功能扩展与联调提供了更清晰的标准。
- 李恺凝:协助完成问答与栏目模式的接口对接,重点处理前端展示逻辑及交互部分。在联调过程中对返回数据结构进行了适配,确保页面内容能够正确解析与展示,提升了功能稳定性。
- 后端
- 王韵清:继续完善爬虫功能,成功适配更多目标网站。针对结构变化较大的页面进行了规则调整和解析优化,提高了数据抓取的准确性与稳定性,为知识库后续更新提供了坚实基础。
- 曾钰仪:完成了时间转换函数的修正工作,解决了跨格式解析不准确的问题。通过多轮测试验证了转换结果的稳定性,增强了数据清洗与时间管理模块的可靠性。
- 徐伊彤:对现有接口与知识库进行全面梳理,优化了接口流程并与前端完成对接验证。修复了部分数据格式与字段映射问题,使整体服务流程更统一、更易维护。
- 测试
- 戴军霞:编写并完成了多个基础功能的测试代码,覆盖接口响应、错误处理以及前端基础逻辑。整理了测试报告与发现的问题,为后续改进提供了有价值的参考依据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号