
Day4 Scrum冲刺博客
Day4 Scrum冲刺博客
1. 团队会议
因为各成员有不同的课程与实习安排,难以找到大家都在的线下时间,所以采用线上会议代替站立式会议。
1)昨天已完成的工作
- 前端
- 实现了数据过滤与分页核心逻辑与分页控制功能
- 完成了表单中的通知公告初稿
- 后端
- 实现了大模型api的意图整理和栏目分类
- 实现了关键词划分算法
- 实现了数据清洗正则化的加强
- 测试
- 检查新加入各代码文件格式清晰性
2)今天计划完成的工作
- 前端
- 初步完成了四个通知栏目页的搭建
- 后端
- 完成了数据库建立的完整流程
- 完成了时间信息的提取函数
- 规定了部分接口格式
- 测试
- 检查新加入各代码文件格式清晰性
- 准备开始测试
3)工作中遇到的困难
- 前端
- 于每个栏目接口返回的数据结构存在细微差异,需要额外处理字段适配。
- 后端
- 在时间信息提取函数开发过程中,发现部分爬取数据的日期格式不统一(如 yyyy/MM/dd、yyyy-MM-dd、中文日期等),需要编写更全面的正则与容错处理。
- 测试
- 在确认新加入代码文件的格式时,对于不同方向的代码差异较大,需对代码语言进行学习确认。
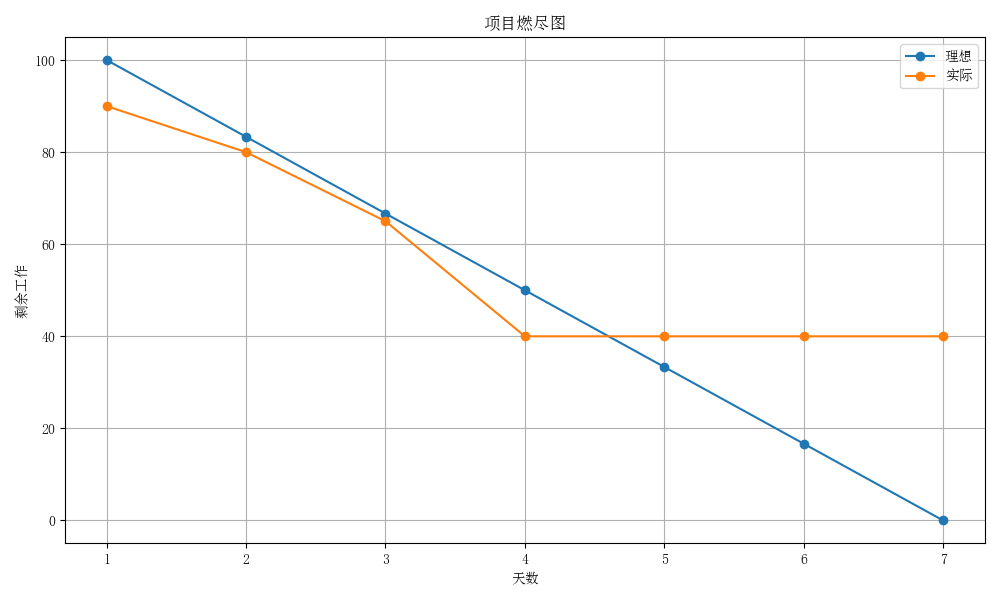
2. 项目燃尽图
今日为第四天,已快于理想进度。
3.代码/文档签入记录
-
今日签入记录
![]()
-
签入记录链接:https://github.com/sevanthea7/GdutInfoHub/commits/main/
-
相关联issue见commit记录中
#后链接内容 -
接口文档与返回格式文档见
docs/api_doc.md与docs/return_doc.md
4. 运行截图
-
前端
-
初步完成了通知栏目页的搭建
-
相关功能代码
// 总数据条数 const totalItems = computed(() => filteredNotices.value.length); // 总页数 const totalPages = computed(() => Math.ceil(totalItems.value / PAGE_SIZE.value) ); // 当前页码 const currentPage = ref(1); // 当前页显示的数据 const currentPageData = computed(() => { const startIndex = (currentPage.value - 1) * PAGE_SIZE.value; const endIndex = startIndex + PAGE_SIZE.value; return filteredNotices.value.slice(startIndex, endIndex); }); // 可见页码 const visiblePages = computed(() => { const pages = []; const total = totalPages.value; const current = currentPage.value; if (total <= 5) { for (let i = 1; i <= total; i++) { pages.push(i); } return pages; } pages.push(1); if (current > 3) { pages.push("..."); } const start = Math.max(2, current - 1); const end = Math.min(total - 1, current + 1); for (let i = start; i <= end; i++) { pages.push(i); } if (current < total - 2) { pages.push("..."); } pages.push(total); return pages; }); // 上一页 const prevPage = () => { if (currentPage.value > 1) { currentPage.value--; } }; // 下一页 const nextPage = () => { if (currentPage.value < totalPages.value) { currentPage.value++; } }; // 跳转指定页码 const goToPage = (page) => { if (typeof page === "number" && page >= 1 && page <= totalPages.value) { currentPage.value = page; } }; // 监听总页数变化 watch(totalPages, () => { if (currentPage.value > totalPages.value) { currentPage.value = Math.max(1, totalPages.value); } }); </script>
![]()
-
-
-
后端
-
实现了时间关键词的提取与解析
import re from datetime import datetime, timedelta def extract_and_convert_time(input_sentences): """ 提取句子中的时间关键词,并转换为具体日期(mm月dd日格式) 参数: input_sentences: list,输入的句子列表(如["明天图书馆有什么活动", "最近宿舍的热水供应时间"]) 返回: list,每个元素为字典,包含句子、提取的时间关键词、转换后的具体日期 """ # 1. 定义时间关键词正则模式(覆盖直接日期、相对时间、模糊时间) # 直接日期:支持“11月13日”“十二月十号”“12-05”“2025年3月20日”等格式 direct_date_pattern = r""" (?:\d{4}年)? # 可选的年份(如2025年) (?:\d{1,2}月|十二|十一|十|九|八|七|六|五|四|三|二|一) # 月份(数字或中文) (?:\d{1,2}日|\d{1,2}号|十|十一|十二|十三|十四|十五|十六|十七|十八|十九|二十|二十一|二十二|二十三|二十四|二十五|二十六|二十七|二十八|二十九|三十|三十一) # 日期(数字或中文) |(?:\d{1,2}-\d{1,2}) # 短横线格式(如12-05) """ # 相对时间关键词(映射为天数偏移) relative_time_map = { "今天": 0, "明天": 1, "后天": 2, "大后天": 3, "昨天": -1, "前天": -2, "大前天": -3, "本周": 0, "本周一": 0 - datetime.now().weekday(), "本周二": 1 - datetime.now().weekday(), "本周三": 2 - datetime.now().weekday(), "本周四": 3 - datetime.now().weekday(), "本周五": 4 - datetime.now().weekday(), "本周六": 5 - datetime.now().weekday(), "本周日": 6 - datetime.now().weekday() } # 模糊时间关键词(映射为日期范围) fuzzy_time_map = { "最近": (0, 7), # 今天到7天后 "近期": (0, 14), # 今天到14天后 "近几天": (0, 3), # 今天到3天后 "近一周": (0, 7), # 今天到7天后 "近两周": (0, 14), # 今天到14天后 "近一个月": (0, 30)# 今天到30天后 } # 合并所有时间关键词模式(忽略空格,使用VERBOSE模式) time_pattern = re.compile( rf""" ({direct_date_pattern}|{"|".join(re.escape(k) for k in relative_time_map.keys())}|{"|".join(re.escape(k) for k in fuzzy_time_map.keys())}) """, re.VERBOSE | re.IGNORECASE ) # 中文数字转阿拉伯数字(用于月份/日期转换) chinese_num_map = { "一": 1, "二": 2, "三": 3, "四": 4, "五": 5, "六": 6, "七": 7, "八": 8, "九": 9, "十": 10, "十一": 11, "十二": 12, "十三": 13, "十四": 14, "十五": 15, "十六": 16, "十七": 17, "十八": 18, "十九": 19, "二十": 20, "二十一": 21, "二十二": 22, "二十三": 23, "二十四": 24, "二十五": 25, "二十六": 26, "二十七": 27, "二十八": 28, "二十九": 29, "三十": 30, "三十一": 31 } # 2. 处理每个句子 result = [] today = datetime.now().date() # 当前日期(仅日期部分,忽略时间) for sentence in input_sentences: # 提取所有时间关键词(去重) time_keywords = list(set(time_pattern.findall(sentence))) converted_times = [] for keyword in time_keywords: keyword = keyword.strip() # 3. 处理相对时间(如“明天”“昨天”) if keyword in relative_time_map: offset_days = relative_time_map[keyword] target_date = today + timedelta(days=offset_days) converted_times.append(target_date.strftime("%m月%d日")) # 4. 处理模糊时间(如“最近”“近一周”) elif keyword in fuzzy_time_map: start_offset, end_offset = fuzzy_time_map[keyword] start_date = today + timedelta(days=start_offset) end_date = today + timedelta(days=end_offset) converted_times.append(f"{start_date.strftime('%m月%d日')}-{end_date.strftime('%m月%d日')}") # 5. 处理直接日期(如“11月13日”“十二月十号”“12-05”) else: try: # 处理短横线格式(如12-05) if "-" in keyword: month, day = map(int, keyword.split("-")) # 处理点格式(如12.05) if "." in keyword: month, day = map(int, keyword.split(".")) else: # 处理中文/数字混合格式(如“十二月十号”“11月13日”) # 提取月份(替换“月”为分隔符) month_part = re.search(r"(.*?)[月]", keyword).group(1) if "月" in keyword else "" # 提取日期(替换“日”“号”为分隔符) day_part = re.search(r"[月](.*?)[日号]", keyword).group(1) if any(c in keyword for c in ["日", "号"]) else "" # 中文数字转阿拉伯数字 month = chinese_num_map.get(month_part, int(month_part) if month_part.isdigit() else 1) day = chinese_num_map.get(day_part, int(day_part) if day_part.isdigit() else 1) # 构造日期(年份默认为当前年) target_date = datetime(today.year, month, day).date() # 若日期已过(如当前12月,输入“1月5日”,自动视为明年) if target_date < today and month < today.month: target_date = datetime(today.year + 1, month, day).date() converted_times.append(target_date.strftime("%m月%d日")) except (ValueError, AttributeError): # 日期格式错误时,保留原关键词 converted_times.append(f"无法识别:{keyword}") # 整理结果 # 包含原句对比,方便测试 # result.append({ # "句子": sentence, # "时间关键词": time_keywords, # "具体时间": converted_times if converted_times else ["未提取到时间"] # }) # 输入大模型 result.append(converted_times) return result # ------------------------------ 测试示例 ------------------------------ if __name__ == "__main__": # 测试输入句子列表 test_sentences = [ "明天图书馆有什么活动?", "最近宿舍的热水供应时间是几点?", "11月13日的讲座取消了吗?", "十二月十号有没有社团招新?", "昨天忘记去取快递了,后天能补取吗?", "近一周的食堂菜单会更新吗?", "2025年3月20日的会议地点在哪里?", "12-05的考试安排出来了吗?", "本周五下午有体育课吗?", "近一个月的天气预报怎么样?" ] # 执行时间提取与转换 output = extract_and_convert_time(test_sentences) # 打印结果 # for item in output: # print("-" * 50) # print(f"句子:{item['句子']}") # print(f"时间关键词:{item['时间关键词']}") # print(f"具体时间:{item['具体时间']}") print(output) # 本周五识别结果为本周,待改进![]()
-
整合知识库建立整体流程
from src.crawler.LLM_api.label_agent import create_database_JSON from src.crawler.data_clean.reprocess import keyword_process from src.crawler.library import crawl_library_func SAVE_PATH = "src/crawler/news_data" def data_process_func(save_path): crawl_library_func(save_path) keyword_process(save_path) create_database_JSON(save_path) print('知识库信息已更新') data_process_func(SAVE_PATH)
-

5. 每人每日总结
- 前端
- 张洁:今天主要完成了四个通知栏目页面的初步结构搭建,包括基础布局、静态数据占位以及路由配置的整理。在实现过程中,需要在保证页面一致性的同时兼顾不同栏目内容的展示逻辑,因此在组件复用与结构划分上进行了一些尝试。整体框架已经清晰,后续会进一步完善细节与交互。
- 吴佳童:负责与张洁一起完成通知栏目页的搭建,并参与部分组件内容布局优化。在开发中对每个页面的展示结构进行了梳理,确保页面切换与信息展示稳定无误。同时检查了相关组件的数据流向,为后续与后端的真实数据联调提供基础。
- 李恺凝:为四个通知栏目页提供了 UI 指导与版面结构建议,包括标题层级、信息块分布、色彩和间距统一等,使页面在视觉上保持一致性和层次感。同时根据前端开发需求调整了部分图形样式与布局规范,确保设计与实现能够顺利对齐。
- 后端
- 王韵清:完成了系统数据库的整体结构设计与建立,实现了基本的数据表划分和字段定义,使后续的数据存储、查询和爬虫接入有了稳定的基础。在过程中对一些字段间关联关系做了多次调整,确保逻辑合理、扩展性良好。
- 曾钰仪:实现了时间信息的自动提取函数,能够从爬取的原始文本中稳定识别并解析日期格式。在适配不同网页的时间写法时遇到一些不一致问题,但已通过正则优化提升了兼容性,为后续的排序和筛选功能打下基础。
- 徐伊彤:制定并实现了部分接口的格式规范,包括响应结构、字段命名规则与基本的请求处理流程。在对齐前后端沟通内容时对接口格式进行过几轮调整,最终确定了统一风格,为团队后续协作提供标准。
- 测试
- 戴军霞:今天主要对新增的代码文件进行了格式与规范性检查,包括缩进、命名风格与注释完整性等。在代码结构频繁更新的情况下,需要逐项比对与复核,确保整体项目代码质量保持一致。后续将继续完善测试用例准备工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号