
Day2 Scrum冲刺博客
Day2 Scrum冲刺博客
1. 团队会议
因为各成员有不同的课程与实习安排,难以找到大家都在的线下时间,所以采用线上会议代替站立式会议。
1)昨天已完成的工作
- 前端
- 前端项目初始化完成,实现了路由、菜单配置和登录页面
- "关于我们"弹窗初步完成
- 后端
- 完成了爬虫程序的初步实践
- 产生了示例数据,用于后续的数据存储结构构建和数据清晰实践
- 测试
- 完成了初步的测试计划,尝试部署了框架
2)今天计划完成的工作
- 前端
- 实现个人设置弹窗以及问答模式静态页面,实现问答模式缓存
- "关于我们"细节修正
- 后端
- 完成爬虫数据的数据清洗
- 增加爬虫程序适配的信息网站
- 测试
- 检查各代码文件格式清晰性
3)工作中遇到的困难
- 前端
- Vue嵌套路由架构设计中的缓存策略问题,需要根据路由层级关系正确放置 的位置,确保缓存的是实际切换的内容组件,而不是布局容器组件。
- 后端
- 不同信息网站的页面结构差异较大,适配规则需要针对性编写,通用化不够。
- 测试
- 部分功能目前尚未稳定上线,影响测试覆盖率,需要等待前后端进一步联调。
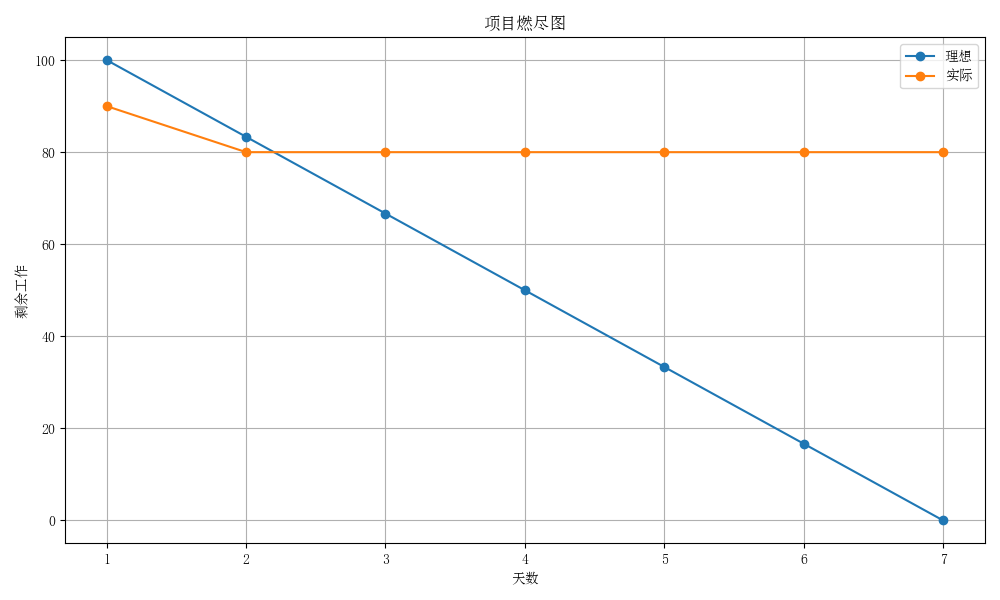
2. 项目燃尽图
今日为第二天,已快于理想进度。
3.代码/文档签入记录
-
今日签入记录
![]()
-
签入记录链接:https://github.com/sevanthea7/GdutInfoHub/commits/main/
-
相关联issue见commit记录中
#后链接内容 -
接口文档与返回格式文档见
docs/api_doc.md与docs/return_doc.md,暂未更新
4. 运行截图
-
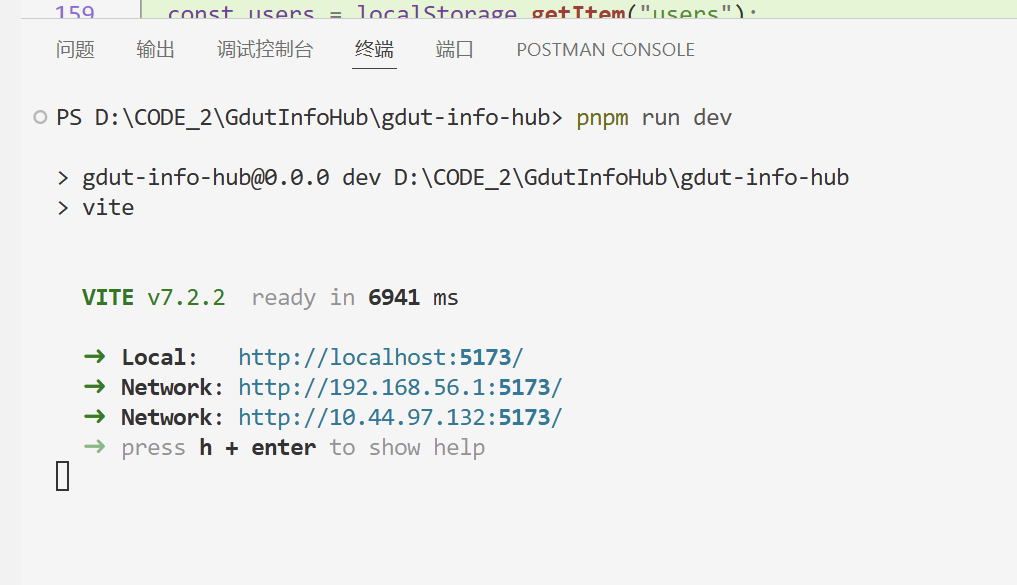
前端
-
前端项目初始化完成
import { defineConfig, loadEnv } from "vite"; import path from "path"; import vue from "@vitejs/plugin-vue"; import { viteMockServe } from "vite-plugin-mock"; export default defineConfig(({ mode, command }) => { const env = loadEnv(mode, process.cwd()); const { VITE_APP_ENV } = env; return { base: VITE_APP_ENV === "development" ? "/" : "/", plugins: [ vue(), viteMockServe({ mockPath: "mock", enable: command === "serve" && VITE_APP_ENV === "development", // 仅开发环境启用mock logger: false, // 关闭mock日志(可选) }), ], server: { port: 5173, host: true, open: true, proxy: { "/api": { target: "http://127.0.0.1:5000", changeOrigin: true, // 后端接口带/api前缀,无需rewrite! // 如果后端接口不带/api,才需要:rewrite: (path) => path.replace(/^\/api/, "") }, }, }, resolve: { alias: { "~": path.resolve(__dirname, "./"), "@": path.resolve(__dirname, "./src"), }, extensions: [".mjs", ".js", ".ts", ".jsx", ".tsx", ".json", ".vue"], }, }; });![]()
-
-
后端
-
数据爬取完成,存入JSON,JSON格式存在
docs\return_doc.md-
爬虫模块更新代码
import requests from bs4 import BeautifulSoup from tool_func import save_json from urllib.parse import urljoin # 配置 start_page = 'https://library.gdut.edu.cn/xwgg/xwdt.htm' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36" } save_path = "src/crawler/news_data" news_type = 'library_news' def get_page_urls(page_url): # 获取当前列表页的所有文章 URL、标题、日期 resp = requests.get(page_url, headers=headers) resp.encoding = resp.apparent_encoding soup = BeautifulSoup(resp.text, "html.parser") articles = [] for li in soup.select("div.lm_list ul li"): a_tag = li.find("a") span_tag = li.find("span") if a_tag and span_tag: title = a_tag.text.strip() href = urljoin(page_url, a_tag['href']) date = span_tag.text.strip() articles.append({ "title": title, "url": href, "date": date }) return articles def get_article_content(article_url): # 获取文章正文内容 resp = requests.get(article_url, headers=headers) resp.encoding = resp.apparent_encoding soup = BeautifulSoup(resp.text, "html.parser") content_div = soup.select_one("div.nr-info div.v_news_content") # 正文内容区域在这部分的所有p标签里 if content_div: paragraphs = [p.get_text(strip=True) for p in content_div.find_all("p")] content = "\n".join(paragraphs) else: content = "" return content def crawl_all_pages(start_url): # 抓取所有文章分页 results = [] next_page = start_url while next_page: print(f"抓取页面: {next_page}") articles = get_page_urls(next_page) for article in articles: article["content"] = get_article_content(article["url"]) results.append(article) # 添加爬取到的内容 resp = requests.get(next_page, headers=headers) resp.encoding = resp.apparent_encoding soup = BeautifulSoup(resp.text, "html.parser") next_link = soup.select_one("span.p_next a") # 得到下一页的链接 if next_link: next_page = urljoin(next_page, next_link['href']) else: next_page = None return results # test lines data = crawl_all_pages(start_page) save_json(save_path, news_type, data)
-
-
-
数据清洗完成,示例数据可见
-
数据清洗更新代码
import json import re import os # 指定文件夹路径 folder_path = 'src/crawler/news_data' # 用于保存所有整理后的内容 all_contents = [] # 遍历文件夹里的所有 JSON 文件 for filename in os.listdir(folder_path): if filename.endswith('_raw.json'): file_path = os.path.join(folder_path, filename) with open(file_path, 'r', encoding='utf-8') as f: try: data = json.load(f) except json.JSONDecodeError: print(f"文件 {filename} 不是有效 JSON,跳过") continue # 正则化处理: # 1. 去掉开头结尾空白 # 2. 将连续换行或空白替换为一个空格 # 3. 去掉多余空格 if 'content' in data: data['content'] = re.sub(r'[\s\u2028\u2029]+', ' ', data['content']).strip() # 新文件名,把 "_raw" 换成 "_cleaned",如果没有 "_raw" 就直接加 "_cleaned" new_filename = filename.replace('_raw', '_cleaned') new_file_path = os.path.join(folder_path, new_filename) # 写入新文件 with open(new_file_path, 'w', encoding='utf-8') as f: json.dump(data, f, ensure_ascii=False, indent=2) print(f"已生成 {new_filename}")
![]()
-

5. 每人每日总结
- 前端
- 吴佳童:今天主要围绕问答模式功能展开开发工作,完成了“个人设置”弹窗的页面构建,并实现了问答模式的静态页面布局。为提升用户体验,我还为问答模式增加了本地缓存逻辑,确保用户多轮对话时信息能够保留。同时,在与设计同学的沟通中,进一步明确了页面结构与交互细节,为后续接口联调做好了准备。
- 张洁:今天主要负责“关于我们”页面的细节修正。根据前端整体风格指南和团队反馈,对排版、字重、留白、结构层级等进行了优化,整体页面更为清晰美观。同时检查了组件的规范性,使其更便于后续维护和扩展。
- 李恺凝:今天与前端同学协作,推动了问答模式页面的静态实现,实现了页面的初步落地。根据实际效果对交互逻辑进行了微调,并就“个人设置”弹窗的用户体验细节进行了补充设计说明。同时整理了后续优化方向,确保页面视觉表现与整体系统风格保持一致。
- 后端
- 王韵清:今天主要负责扩展爬虫程序的适配范围,根据学校新的信息网站结构,补充了相应的爬取逻辑与解析规则。同时重新梳理了多个页面的结构,修复了部分链接无法正确获取的问题。通过调试确保新增页面的数据都能够正确爬取并进入清洗流程。
- 徐伊彤:今天主要完成爬虫数据的清洗逻辑编写,包括正则规则整理、文本异常处理、字段过滤与结构化转换。在调试过程中,对部分网页结构不一致的情况进行了适配,使处理脚本更加稳健。通过对多批测试数据的清洗,确保最终输出的结构化数据可供知识库模块直接使用。
- 曾钰仪:今天与数据清洗同学协作,完成了爬虫数据的清洗流程验证,并补充了部分更严格的文本处理规则。同时同步检查了清洗结果与知识库结构之间的字段匹配情况,确保后续知识库的构建不会出现数据缺失或格式错误。为后续接口对接工作打下了基础。
- 测试
- 戴军霞:今天主要完成项目各代码文件格式、命名规范及可读性的检查工作,重点关注模块划分、注释规范及文件结构的整洁性。整理了需要在后续版本中改进的规范问题,并为下一阶段的测试计划编写提供了基础依据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号