阻塞优先队列(PriorityBlockingQueue)详解
文章就通过图文介绍阻塞队列的三个主要方法(构造方法,入队和出队)和其中需要用到的子方法,方便你更快更好地理解优先队列。首先,强烈推荐先去学习堆排序,因为优先队列是按照堆排序原理设计的。
1.构造方法
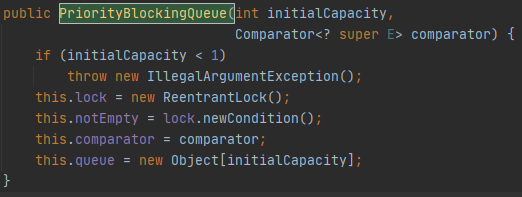
PriorityBlockingQueue有四个构造方法,其余两个最后都会调用上图的构造器。输入参数initialCapacity和comparator分别是队列的初始容量和队列中对象的比较器。初始容量默认为11。比较器默认为null。lock和notEmpty用于线程同步。
2.offer
所有往队列中加入元素的方法最后都会调用offer方法。
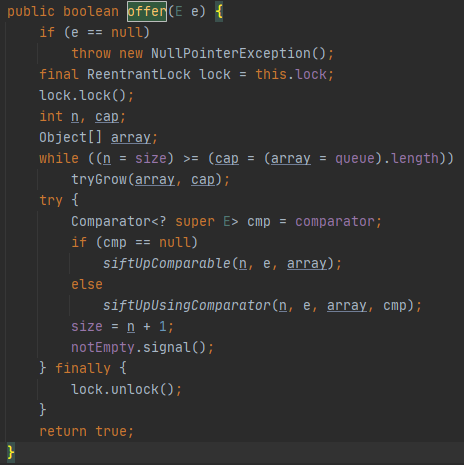
方法有三个功能,分别是:扩容,插入新元素和同步。我将分别来说,功能的代码会混合出现,放心,我先分开说明,如果需要重组,我会再次强调。
2.1 扩容

size是当前队列的长度,cap是当前队列的容量。当长度大于等于容量时,就会执行扩容方法tryGrow();
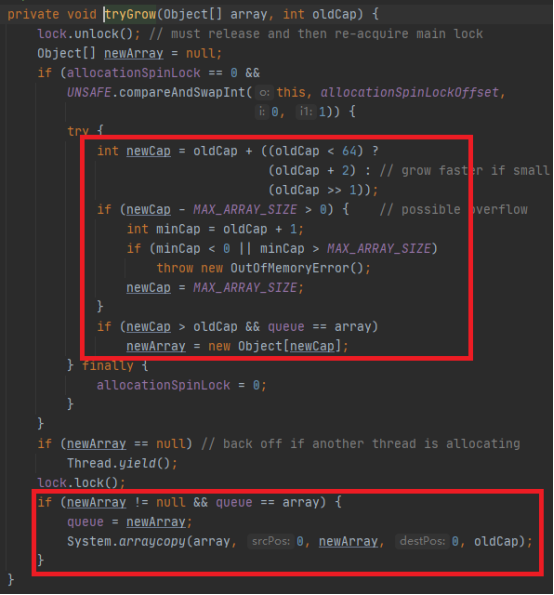
扩容部分已经用红框标出,其余都是同步,下面再说。
扩容步骤:
1)计算新容量。如果就容量小于64,那么容量翻倍再增加两个槽位。否则,新容量=旧容量*1.5。
2)判断新容量是否超过了最大允许容量(Integer.MAX_VALUE - 8),如果是,内存溢出。
3)新建Object数组,称为新队列的容器。
4)复制原有数据到新数组。
至此,扩容结束。
2.2)插入新元素
扩容结束会就会插入新元素。
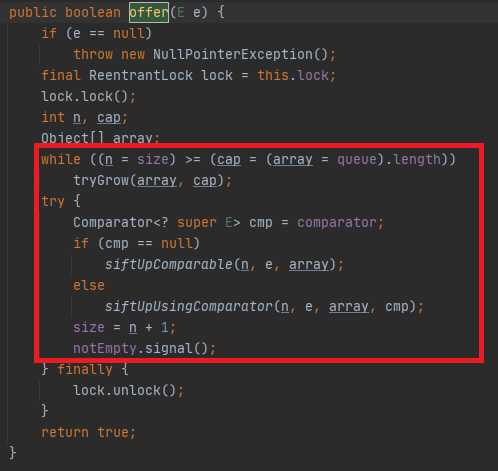
如果在构造方法中给定了比较器,那么执行siftUpComparable()方法,否则执行siftUpUsingComparator()。两者的区别仅仅是如果没有给定比较器,那么优先队列会自己的比较逻辑;否则,使用给定比较器的比较逻辑。下面以siftUpComparable()进行说明。
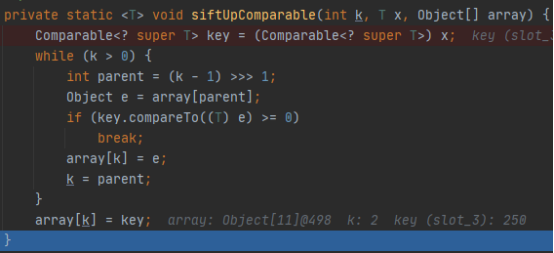
插入参数分别是k(目前队列长度),x(插入的元素),array(当前队列)。接下来的代码直接说明不方便理解,所以下面使用一个例子进行说明。
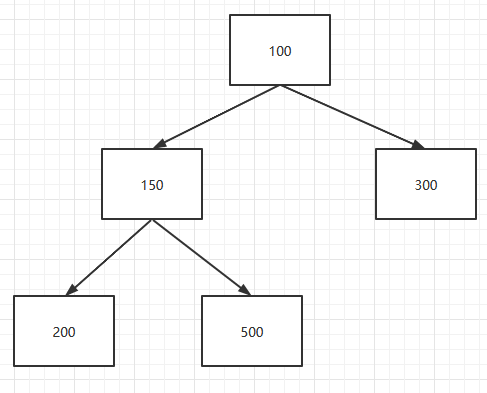
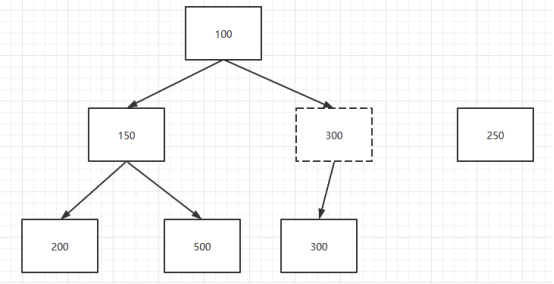
假设存储的队列array如下:

实际表达的数据结构如下:
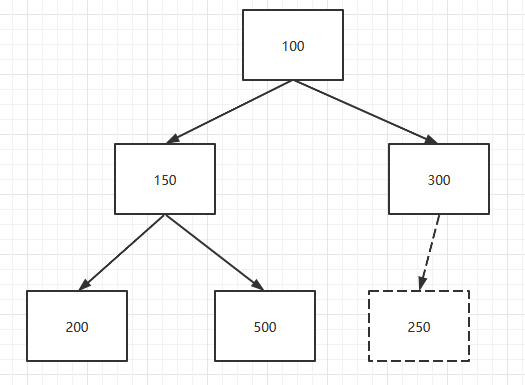
现在,要插入一个新元素250。
k最初是队列长度,实际是当前操作的array槽位,它会在操作中不断减少。代码中没有将250加入到array[k]的地方,但是逻辑上可以这样认为。
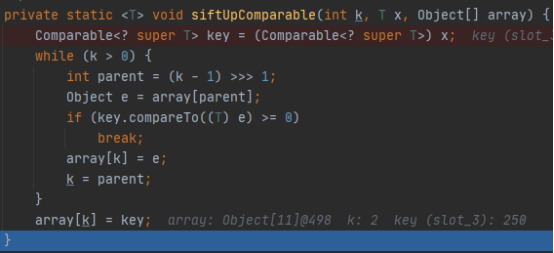
首先计算parent=(k-1) >> 1,就是计算250的父元素索引。
然后获取父元素的值并进行比较,如果新元素小于父元素,那么将父元素放到当前操作的槽位k中,k变为父元素原先的索引。在本例子中,如下图进行变化:
接着,计算k所在元素的父元素索引并获取父元素。本例子中是100,100 <= 250。符合跳出循环的条件。因此,250放入到k所指示的位置。
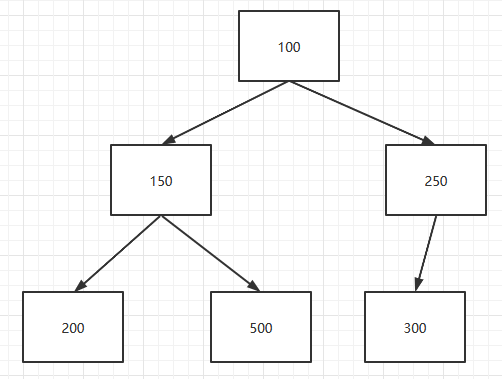
在offer()方法中还有一个增加队列长度的操作,加入新元素结束。
2.3) 同步
为了更好地说明同步,使用两个线程举例子。假设当前队列已经满载了,线程A先到,因此它负责扩容,线程B后到。
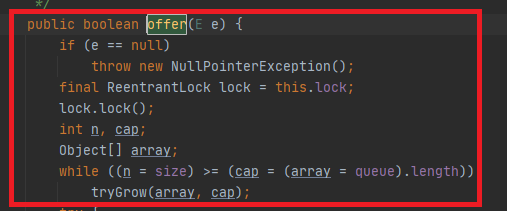
线程A拿到锁,因此进行扩容。如果此时线程B到来,那么它必须先等待。
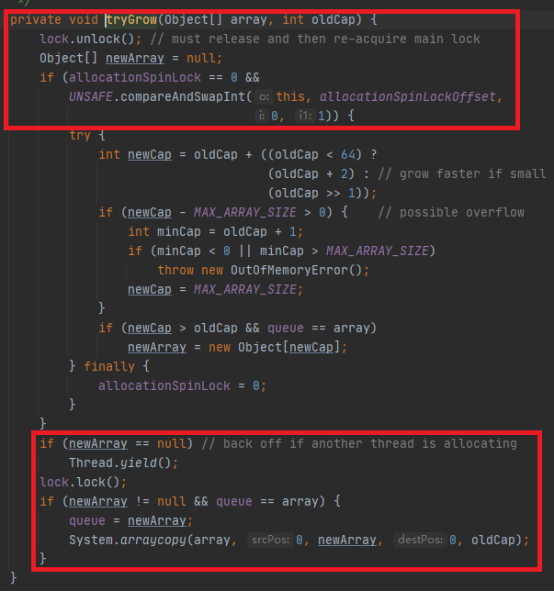
线程A首先释放锁(线程B可以开始进行),然后使用CAS修改allocationSpinLock为1,它是一个标志位。然后进行扩容操作。完事后再把allocationSpinLock修改为0。另外一个注意的点是newArray,只有线程A扩容完成后,它才不会是null。其余时候,它都是null。
扩容期间,线程B在线程A释放锁后获得了锁。然后它也发现队列满了,因此也进入到扩容方法中。但此时,由于allocationSpinLock == 0,它无法进行扩容。然后newArray == null。因此它让出了cpu时间片。
让出时间片有两个结果:线程B再次获得了cpu和线程A获得了cpu。前者发生意义不大:

因为在线程A扩容完成之前,它都无法跳出循环。
不过一种情况另外,线程A完成扩容后cpu时间片到了,此时轮到线程B操作。那么newArray != null,所以由线程B完成队列原有数据复制的操作。
如果线程A在线程B让出时间片后获得cpu,那么由线程A自己完成数据复制操作。
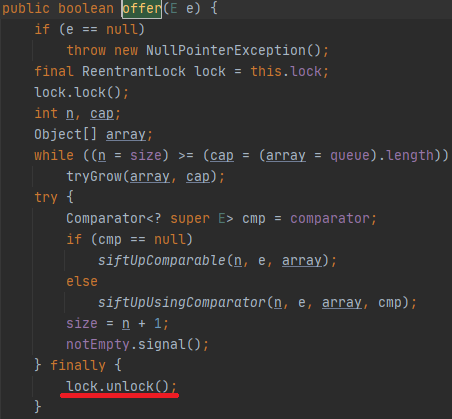
完成数据复制操作的线程完成加入数据的操作后,才会释放锁。
3.总结
出队操作就不详细讲述了。首先,出队没有同步操作,方法也不复杂。其次,如果你知道堆排序的原理应该清楚,入队是向上调整,出队是向下调整。将当作是课后作业吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号