Hbase Region Server整体架构
Region Server的整体架构
本文主要介绍Region的整体架构,后续再慢慢介绍region的各部分具体实现和源码
RegionServer逻辑架构图

RegionServer职责
1、 监听协作,通过zk来侦听master、meta位置、集群状态等信息的变化,更新本地数据。
2、 管理region的offline、online、open、close等操作,这些操作是和hmaster配合这来做的,region的状态有如下这些
- offline、opening、open、closing、close、offline等这些状态,hmaster通过zk来和regionServer协调具体的region的上线、下线、操作timeout等操作。
3、 rpcService服务,分发收到的读写请求到具体的region上执行。
在1.0中rpc服务对于请求的做了种类、优先级等的区分,不同handler处理不同优先级的请求 。
4、 有一些全局的线程去监控、发现、执行具体region的flush、compaction、split这三种region的核心操作。
5、 LogRoller,定时将wal日志进行切分,是一个可运行的thread ,会定时roll所有的wal,也可以接受外部的roll请求,然后将log来分割 。
WAL,写操作日志,整个regionServer中维护着这样一份日志,所有的region的wal都是写在这一份日志中。
在wal被roll后,会向相关的region发送flush request请求。
6、 Leases,leases管理机制,所有region涉及到超时的操作都注册到lease中,定期统一检查移除expire并调用expireHandler。
7、 待补充
RegionServer的内部线程
- healthChecker:这个是负责检查集群的健康状况的,可以在自定执行的脚本(配置路径),然后定期去执行并识别返回值。
- pauseMonitor:这个是定时调用jmx中的gc接口,检查当前虚拟机的GC情况,gc次数以及消耗时间,并提示报警。
- cacheFlusher:检查flush的request,并flush memstore
- compactSplitThread:compactpact
- compactionChecker:定期检查,提交compactionrequest 。
- periodicFlusher:定期刷新,定期提交flushrequest
- lease:整个rs中lease的管理,例如scaner的lesase
- storefileRefresher:定期更新region store file for second region owner.
其它关于RegionServer的点
每个regionServer启动的时候,都会分配一个startcode,和host,port,startcode统一构成一个regionserver的唯一标志,所以在一台机器重启后和以前其实是两个不同rs,这样可以区分。
Region
region的逻辑架构图

region组件&流程
region构成
每个region表示table中一个数据的分区,每个region包含多个Store,每个Store对应一个family的读写操作,一个Store中包含一个memStore和多个HfileStore,写的数据是直接写到memestore中,然后定时刷新到存储(hdfs)中形成一个HFile,读的时候会综合memstore和所有HFileStore中的数据 。
每个region提供split、flush、compaction的策略和操作方法,但是这个触发以及执行是由RegionServer中的线程来具体做的。
MVCC多版本控制协议
多版本控制协议的实现类,hbase中采用的是多版本控制协议的方式,来做操作的回滚、操作的原子性、操作在未完成时候的不可见等问题。
在hbase中通过MultiVersionConsistencyControl类来管理多版本的控制协议,可以同时支持多个写操作,若是其中的一个写操作失败可以rollback相应的写操作。
具体的操作是每一个/一批操作获得一个唯一的一个mvcc版本号,先将这部分操作的数据 写入到memstore内存中-->写入到wal中-->其他操作,若是其中的一步失败可,可以更具mvcc version id删除已经写到memstore中的操作(实际上,memstore可以理解为一个简单的SortSet<KeyValue>,失败的话直接删除相应的KeyValue就OK了)。
在整个系统中MultiVersionConsistencyControl维护着一个readpoint,这个在读的时候若是需要控制原子性(未写完的数据不可见),则只需读取mvcc version <=readpoint的即可。
关于readpoint的更新,当一个write操作完成的时候,会更新readpoint,因为同时可以支持多个write的操作,但是只有一个readpoint,所以MultiVersionConsistencyControl中存储了一个write操作的queue, write操作在开始的时候会在queue注册自己,当有一个write完成的时候,会将这个write的mvcc操作置成完成OK状态,并随之遍历mvcc写操作queqe,然后遍历整个queue,更新readpoint并移除readpoint前面的write mvcc 版本 。
一个region中存在一个唯一的MultiVersionConsistencyControl,所以目前的操作原子性支持到region级别的。
KeyValue的数据结构如下:

在内存中时候会存在mvcc版本号,写到hfile中时候,不会写这个mvcc版本号。
HStore(针对一个family)
Store没什么好说的,就是针对一个family一个Store,负责这个family上的读写操作,一个Store中包含一个MemStore和多个HFileStore。
memStore
memStore是hbase写数据的时候(hbase写的数据就是一个个的KeyValue,delete写实写成一个KeyValue,只是type是delete在检索的时候这个来排除相应的kv)的一个缓冲区,所有的keyValue都先写入memstore中。
MemStore说白了就是一个SortSet<KeyValue>(下面封装了一个ConcurrentNavigableMap<KV,KV>),所有写入的数据直接写入到这个Set中就行了,memstore中还维护了一个MemStoreLAB,起作用就是在添加kv的时候,将KeyValue内存复制到全局的MemStoreChunkPool(这个就是为了一个大内存,内面的内存都是一块一块的,简称一个chunk,这个主要就是为了避免内存碎片,因为对于高并发写入的时候,memStore的flush还是挺频繁的。
关于MemStore的flush操作,MemStore中维护了两个kvSet,一个是正常的kvSet一个是snapShotKvSet,正常情况下是数据写入到kvSet中,snapshot是空的,flush的时候会将当前kvSet赋值给snapshotKvSet,kvSet重新new一个,切换(切换的时候是需要加memStore全局锁的,但是这个时间很短)完成后,由于snapShotKvSet是不变的,所以就可以慢慢得刷新到hdfs中了,在刷写hdfs,但是在刷新的时候需要解决两个问题:
1、 刷的时候,snapshot中不能有变化的(因为这个时候有可能rollback啊,rollback的时候也会从snapshot中找的,若找到了也一样删除):这个解决就是在snapshot之前会等待当前所有的mvcc 的write请求都完成,才flush 。
2、 读数据:读的时候其实MemStoreScanner会检索这两kvSet,这里面其实也是一个HeapScanner
MemStoreChunkPool (统一buffer)
MemStore中的统一buffer,放入MemStore的kvSet的KeyValue都是先System.copyArray到这里的一个chunk中,在添加到kvSet中,主要是为了减少内存碎片,这个MemStoreChunkPool也是全局唯一的单例,所有的memStore的空间都会在这上面申请。
StoreFile
一个StoreFile就是一个HFile的对照,HFile的格式见附件的一篇pdf介绍。
Put/Delete
Put和delete其实是一样的流程,构造成KeyValue,然后放入到memstore中,若是事务的话,则所有涉及到的rowlock一起申请锁,不是的话,则是一样一行处理,锁其实也是一个一个申请的 。
原子transition
hbase是支持操作的transition的,具体的操作也是通过mvcc来控制的,这一批操作是同一个mvcc version,若是成功则都成功,若是失败则都rollback,对应在HbaseClient接口上是mutate接口上,一般都是非原子行的
Scan/Get(lsm的HeapScanner)
Hbase中get和scan最终都是会转化为scan的操作,只不过get只是拿到一row数据,scanner的搜索就是一个典型的lsm树的搜索,如下
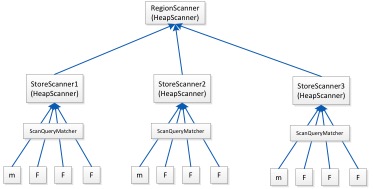
HeapScanner是为lsm数结构的检索而写的,lsm数的子树都是一个排过序的Scanner,HeapScanner就是为了使得自己的next方法返回的KeyValue是有序的,其子节点也可能是一个HeapScanner,这个过程可以迭代的。
HeapScanner的内部其实是把所有的Scanner放在一个PriorityQueue<KeyValueScanner> heap中,这个heap queue的比较器使用scanner的第一个元素作为(peek出来),所以每次取出来的HeapScanner.poll出来的元素就是第一个元素最小的scanner,poll出第一个元素后, 再把这个Scanner放入到heap queue中,再取出来的时候,得到的还是最小的。
整个Scanner的大致流程如下:
HRegion.getScanner(Scan)--->
HRegion.getScanner(Scan , additionalScanners)(family检查)
--->HRegion.instantiateRegionScanner(Scan,additionalScanners)
---->RegionScannerImpl(scan, additionalScanners, region)
readPt : 根据isolationLevel来确定是否需要读入最新未跟新完以及查询过程中更新的数据,也可以选择只读取这个scanner创建的时候mvcc中complete的最新readPoint的 。
isScan = scan.isGetScan() ? -1 : 0;
scanners = new ArrayList<KeyValueScanner>();
joinedScanners = new ArrayList<KeyValueScanner>();
典型的lsm树种的对个排序的scanner,一般来说都不会出现joinedScanners的情况,都是scanners,包含每个Store一个Scanner以及additional scanner
每个Store通过 store.getScanner(scan, entry.getValue(), this.readPt) 来获取一个scanner,参数是scan、qualifiler、readPoint
---->RegionScannerImpl(scan,additionalScanners,region)
storeHeap = new KeyValueHeap(scanners, region.comparator);
RegionScannerImpl主要的检索属性,filter中也可以设置在哪停止的属性,通过filterAllRemaining方法返回true
----->RegionScannerImpl.nextInternal(outResults, limit)
最终落在这个方法上
----->KeyValueHeap.next(List<Cell> result, int limit)
这个其实就是HeapScanner的检索逻辑了,这个HeapScanner就如上图所示,中间过程基本都是包装一层的HeapScanner,最终会落到MemStoreScanner和StoreFileScanner上,在这两个之上的StoreScanner会过一遍ScanQueryMatcher这个,它的作用就是处理过期、删除、maxVersion等过滤的。
MemStoreScanner
memStore其是本身就是一个有序的Set,所以直接检索就行了,但是如果没有mvcc 版本的控制,其实会检索到最新写的KV 。
StoreFileScanner
HfileStore的Scanner逻辑会复杂一些,每次scanner都是新建一个HfileReader(这个若是放在单机普通硬盘上,太多的scanner的话,会很慢,因为每个get其实都会转成scanner,其实每个scanner都会是一个硬盘寻址,可能会慢一些),这个其实就是从具体的kv开始定位,先HFile的index(每个block的startRow、endRow)信息,然后再定位block,需要具体的block的时候,先去缓存里面查询,若是缓存里面没有,再去硬盘上读,读完后先放到cache中 。
storefile检索的调用流程
StoreFileScanner.next ----- >HFileScanner(具体的实现是ScannerV2).next() ,首先在当前block的buffer中找,找不到,寻找下一个block(当然前提是先判断有没有对到最后一个block)------->AbstractScannerV2.readNextDataBlock------->ScannerV2.readBlock,这个方法里面会构造block的cachekey(hfileName+offset +encode),然后现在cache中找。
BlockCache(统一管理cache)
具体cache的配置由CacheConfig来配置,使用的是LruBlockCache cache,然后根据配置决定是否需要再这个之上再加BucketCache,作为其的耳机缓存,这个由配置"hbase.bucketcache.ioengine 等一系列参数决定,详见CacheConfig.instantiateBlockCache()方法,这个cache是单例,全局唯一的,默认是只有lru的cache的,没有BucketCache作为二级缓存,这个单机版跟踪过,确实没有)
一篇介绍hbase几种cache的博客
http://www.cnblogs.com/cenyuhai/p/3707971.html
Flush
flush操作由region内部定义,但是调用以及内存管理都是由外部(region server)来管理触发的外部有一个FlushRequester来管理这些待flush的的region,然后定时触发flush操作 ,如上所述,这个flush操作其实定义在region内部的,只不过在另外的线程中来调用的。
flush是以region为单位的,一个region中可能包含多个memstore,若是一个达到flush的条件后,则会整体flush这个region下的所有memstore,一般的flush触发条件如下:
距离上次flush的时间达到limit了;
已经写得数据量达到limit了;
已经改变的chang数目(transition num)达到limit;
wal被roll后;
数据量的触发条件由每次写操作前检查,达到limit则触发FlushRequest,其它的都是由rs中的固定线程定期检查,调用region的shouldFlush()来判断,针对一个Region的flush是单个且同步的,同一时间只可能有一个FlushRequest,相同直接不接收,同一时间只能有一个现成在进行flush操作,具体的flush操作在方法Region.internalFlushcache中,这个在memstore中会细讲。
Compact
Compact操作也是,它的selectCompactFile(若是select的file为空,则表明不需要compact)的逻辑都是在region中,select的具体逻辑见HStore.requestCompaction()方法中,先选择相应的Hfile,然后在读取这些文件并合并成一个Hfile,最终切换Store中的reader 。
选择过程中会判断是需要minor compaction 或者 major compaction,然后以CompactionRequest的方式提交到regionserver中,由regionserver来调起具体compaction操作,region中会根据需要compact的Hfile的大小分为big compaction和small compaction,然后由不同的线程去执行。
OffPeakHours,一个很有意思的东西,可以设置不做compact的时间段[startHour,endHour)
startHour配置: hbase.offpeak.start.hour
endHour配置:hbase.offpeak.end.hour
minor compaction的选择选择策略
minor compact的选择策略就是尽可能多选择小的、多的HFile来做一次compact
Split
1、split是由RegionSplitPolicy提供的策略来定的,0.94以后使用的默认policy是IncreasingToUpperBoundRegionSplitPolicy,当然这个也可以自定义配置(可以配置hbase.regionserver.region.split.policy来配置,也可以实现单表独立的,写在create table时候的metainfo中,来覆盖这个配置)
2、关于RegionSplitPolicy的几个方法
byte[] getSplitPoint() :默认实现是拿size最大的store的split point ,每个store的splitpoint是自己存储管理的。
shouldSplit() ,判断这个region是否需要split
3、默认的实现 IncreasingToUpperBoundRegionSplitPolicy
是否split由一些参数决定
maxFileSize : tableMeta中自定义、或者hbase.hregion.max.filesize来定义,前一个优先使用
3、split判定策略
有一个region的时候,第一次split是flush的时候,此次split后有两个region
第二次当达到(Min(2*2*flushSize, splitSize))的时候,这次split后有三个region
第三次当达到(Min(3*3*flushSize, splitSize))的时候,这次split后有四个region啦
以此类推 ................
WAL和EditlogReplay
Editlog即wal写的日志,位于hdfs之上,因为写操作都是写在memStore中,意外宕机的话,这部分数据都消失了,所以需要些内存的时候写一份在硬盘上,整个RegionServer的wal是唯一的一个,所有的region的editlog都是写到一起,Editlog存储的其实就是一个个的HLog.Entry,HLog.Entry的结构如下:
WALEdit:KeyValue list
HLogKey:tableName、regionEncode、squenceId、writeTime等
每个Entry标志属于哪个region,并有squenceId,等到需要recove相应的region(crash了)的时候,会先把Editlog按照region切分,每个region的editlog存在${region_dir}/recovered.edits中,这个region启动的时候发现这个这文件会启动replay的流程,详见Region.replayRecoveredEditsIfAny方法中,其实就是判断这个log的squenceId和hfile的squenceId(hfile写入会写入最大和最小squenceId)作比较,看是否已经固化到hfile中了,若没有则将这些操作重新写到memstore中,否则则跳过 。
对于comprocess只会执行 preWALRestore、postWALRestore操作 ,不会执行其他的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号