scrapy框架简单使用样例——以当当网为例
scrapy框架简单使用样例——以当当网为例
-
要爬取的地址为http://category.dangdang.com/cp01.01.02.00.00.00.html
-
创建项目,命令行运行命令
scrapy startproject 项目名称 (这里命名为dangdang)
项目结构如下: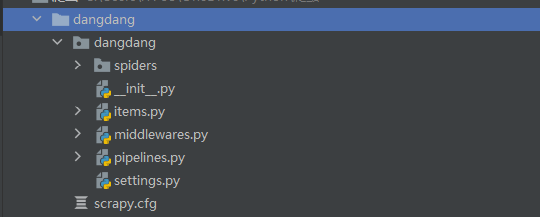
-
命令行
cd命令进入
该目录下输入命令scrapy genspider 爬虫名称 爬取域名 (这里是dangspider)回车后会发现spiders下面多了一个dangspider.py的文件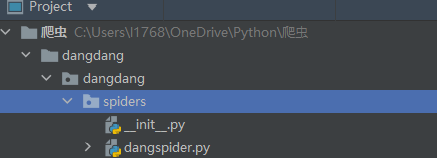
-
打开dangspider.py文件可以看一下
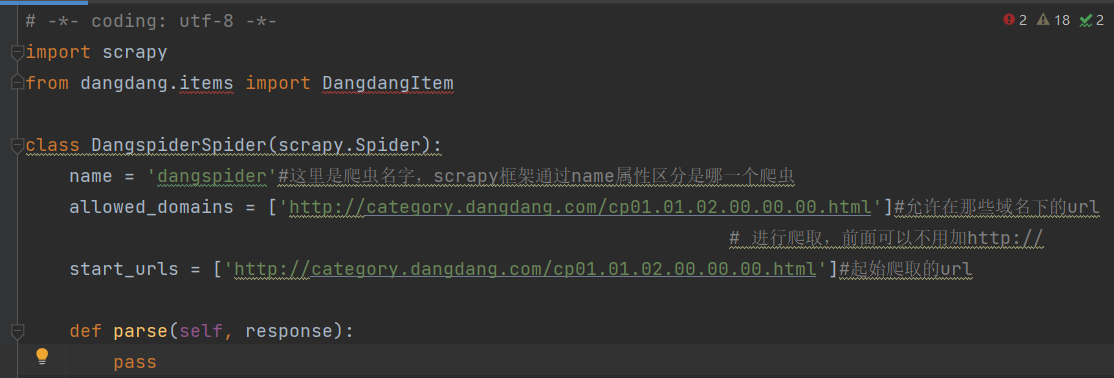
parse函数中的response相当于第三方库中requests.get(url)返回的response,具有类似的属性和方法,parse函数中可以编写对响应内容进行处理的代码
- 打开要爬取的当当的网址,对要爬取的内容进行分析
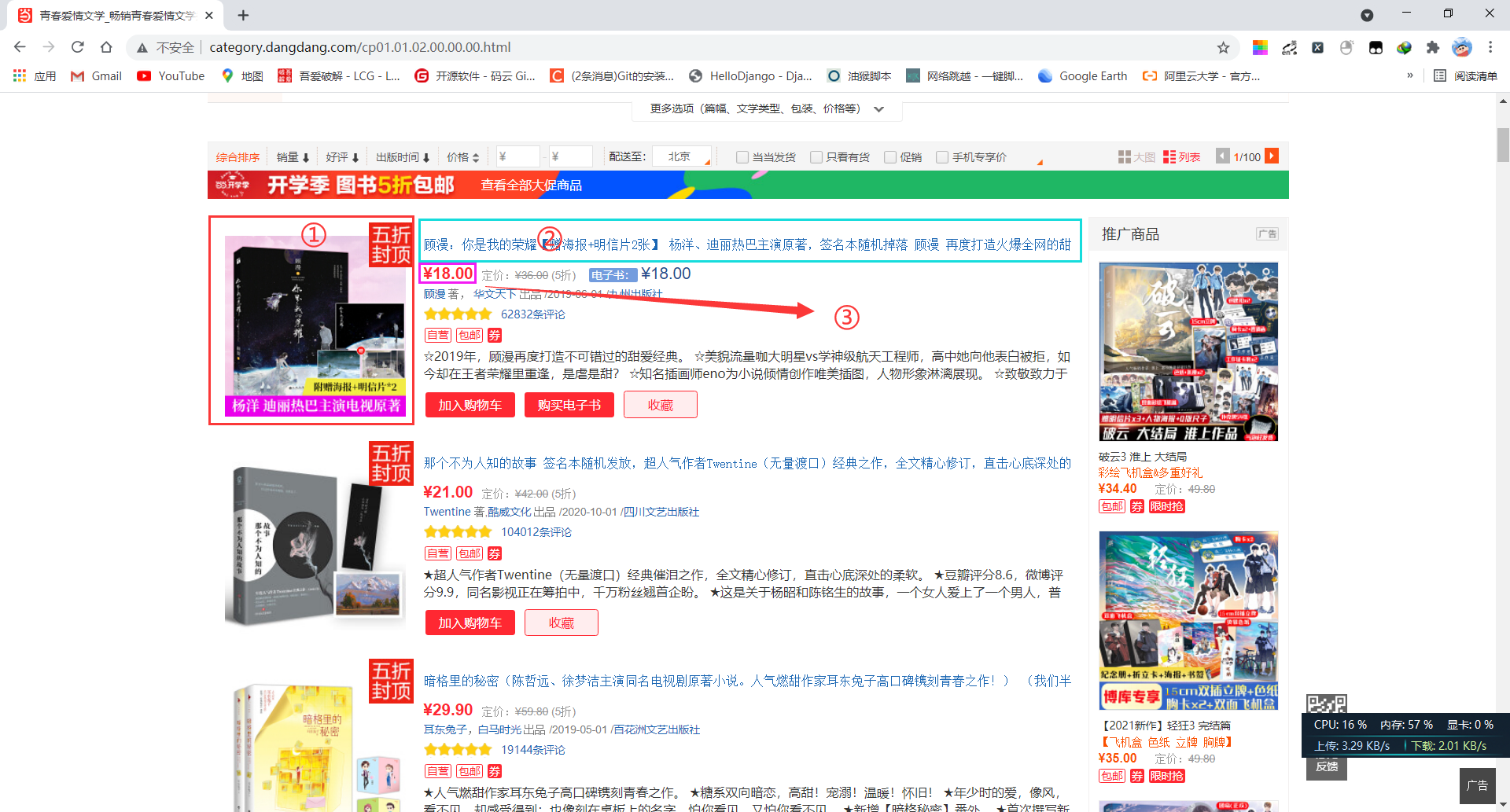
要爬取三部分内容为三部分内容,分别是书名、价格、图片地址
-
根据要爬取的内容在
items.py文件中定义相应的数据结构,如下
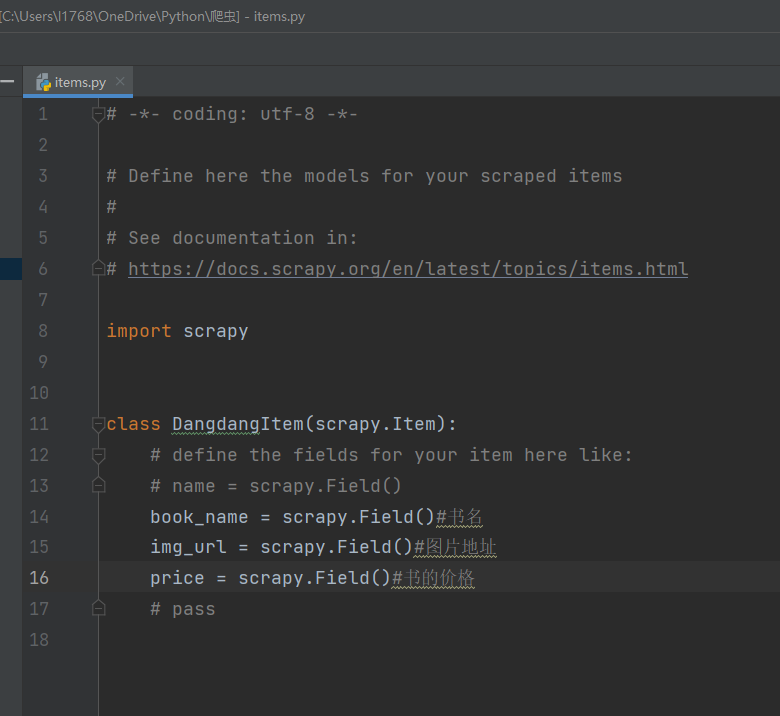
-
为要提取的部分编写xpath表达式,可以打开浏览器插件xpath helper,如下:
-
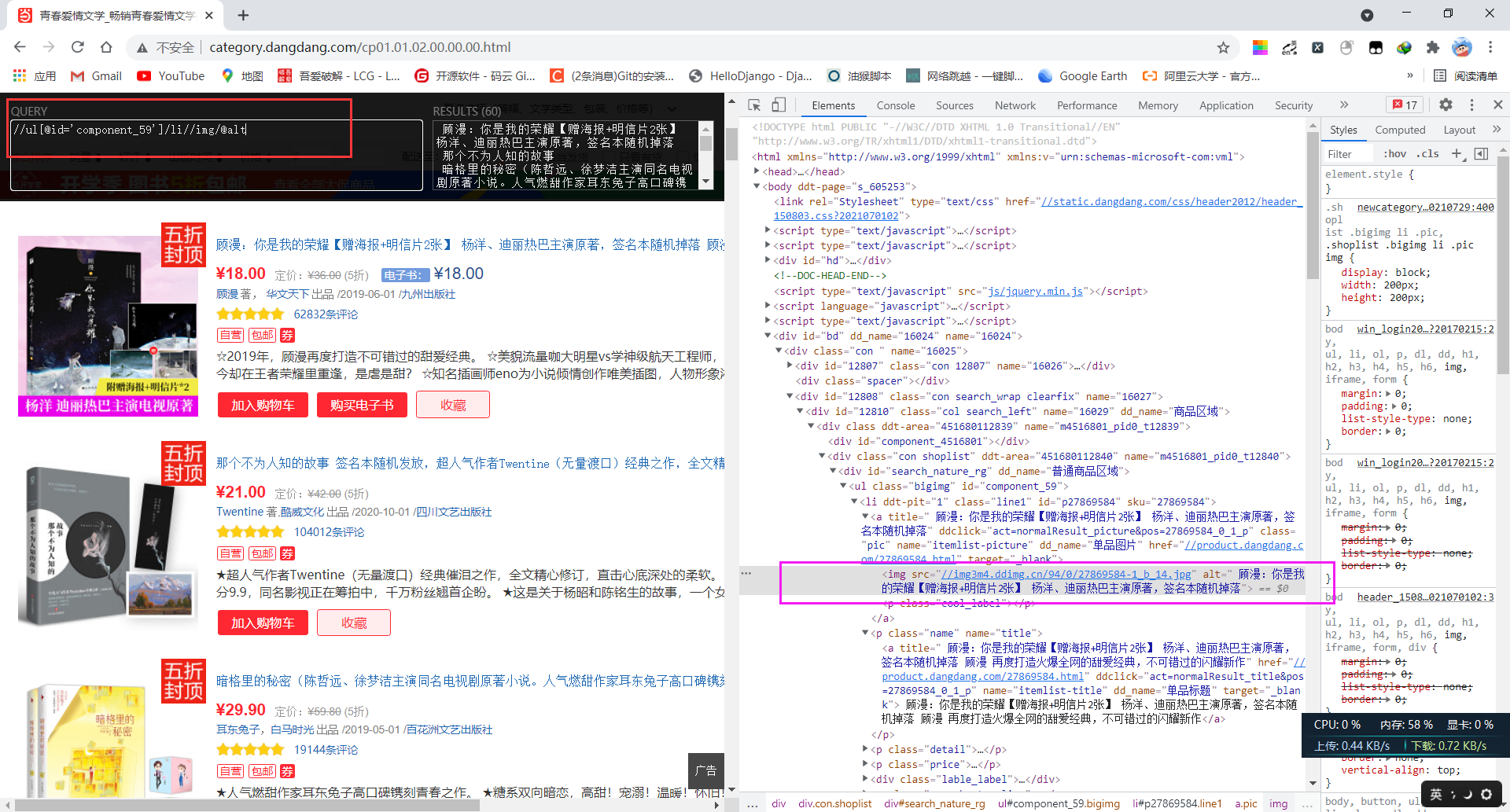
书名xpath提取表达式//ul[@id='component_59']/li//img/@alt -
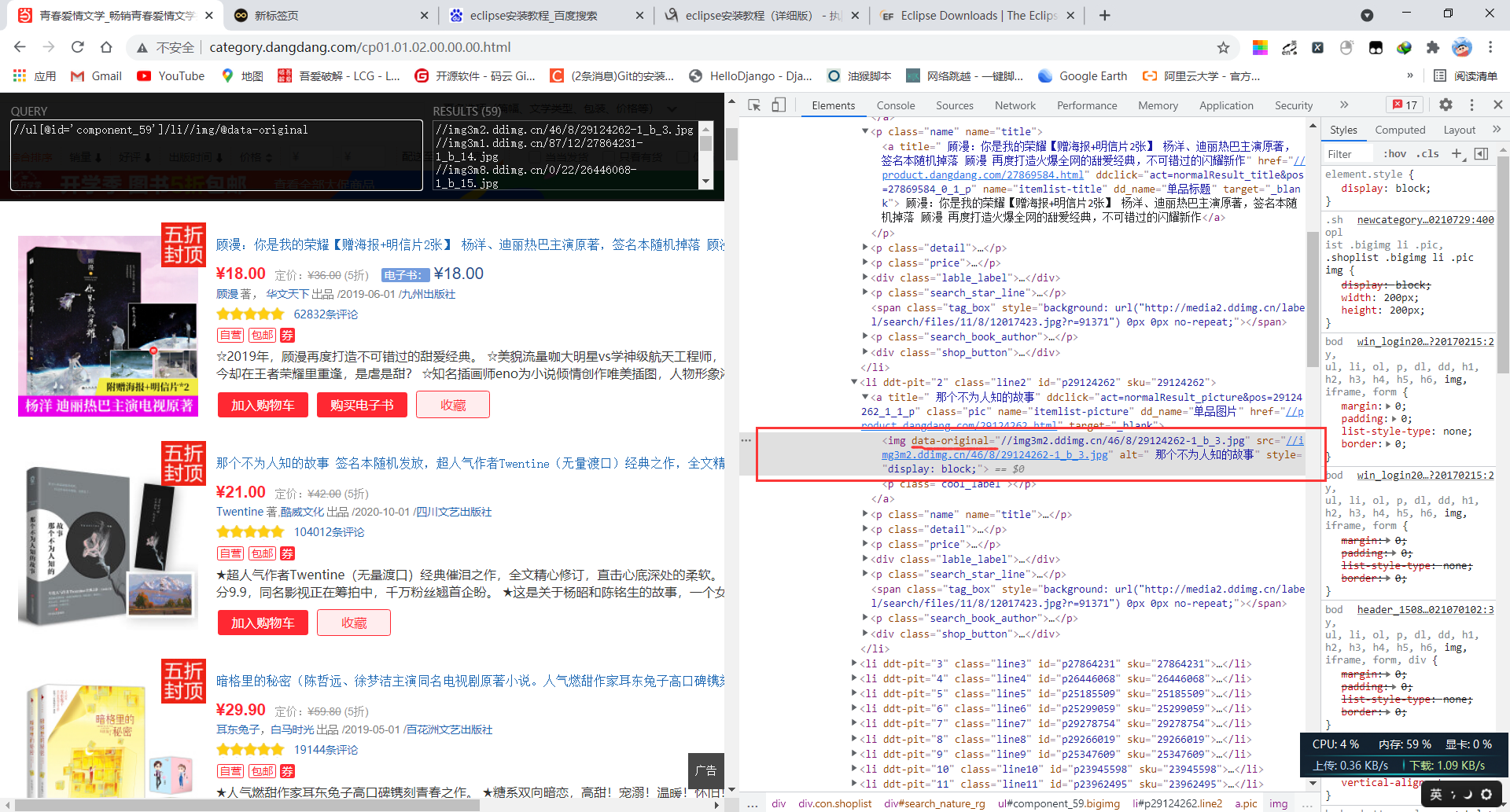
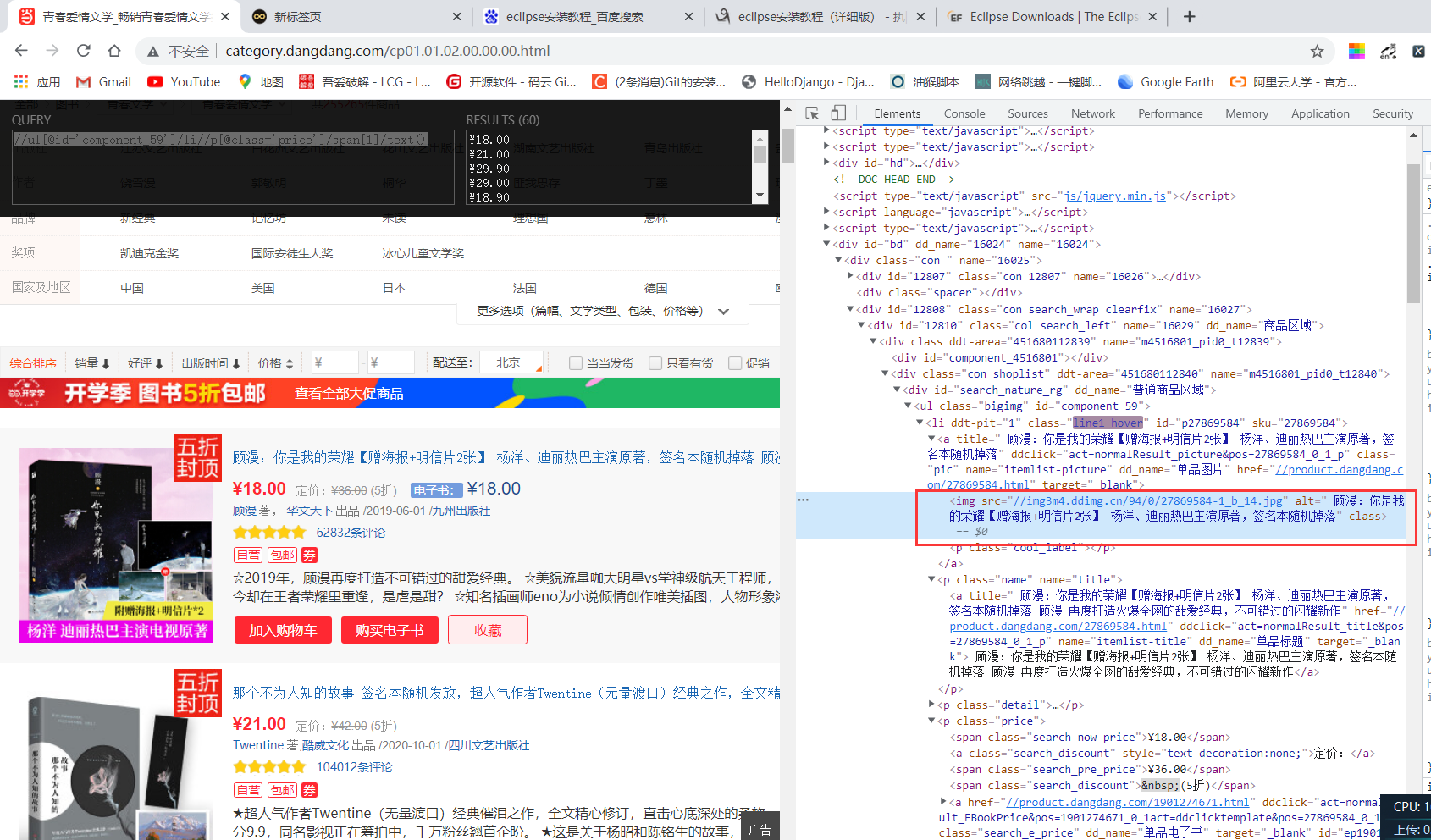
通过观察标签我们发现data-original属性,为此可以断定是图片是懒加载的方式,为此我们提取该属性的值回获取图片的url地址,图片url提取xpath表达式为//ul[@id='component_59']/li//img/@data-origina(上面第一张图),但是通过观察可以发现每一页的第一本书的图的表情没有data-origina属性,为此对于每一页的的第一条数据进行特殊处理提取其src属性,xpath表达式//ul[@id='component_59']/li//img/@src(上面第二张图) -
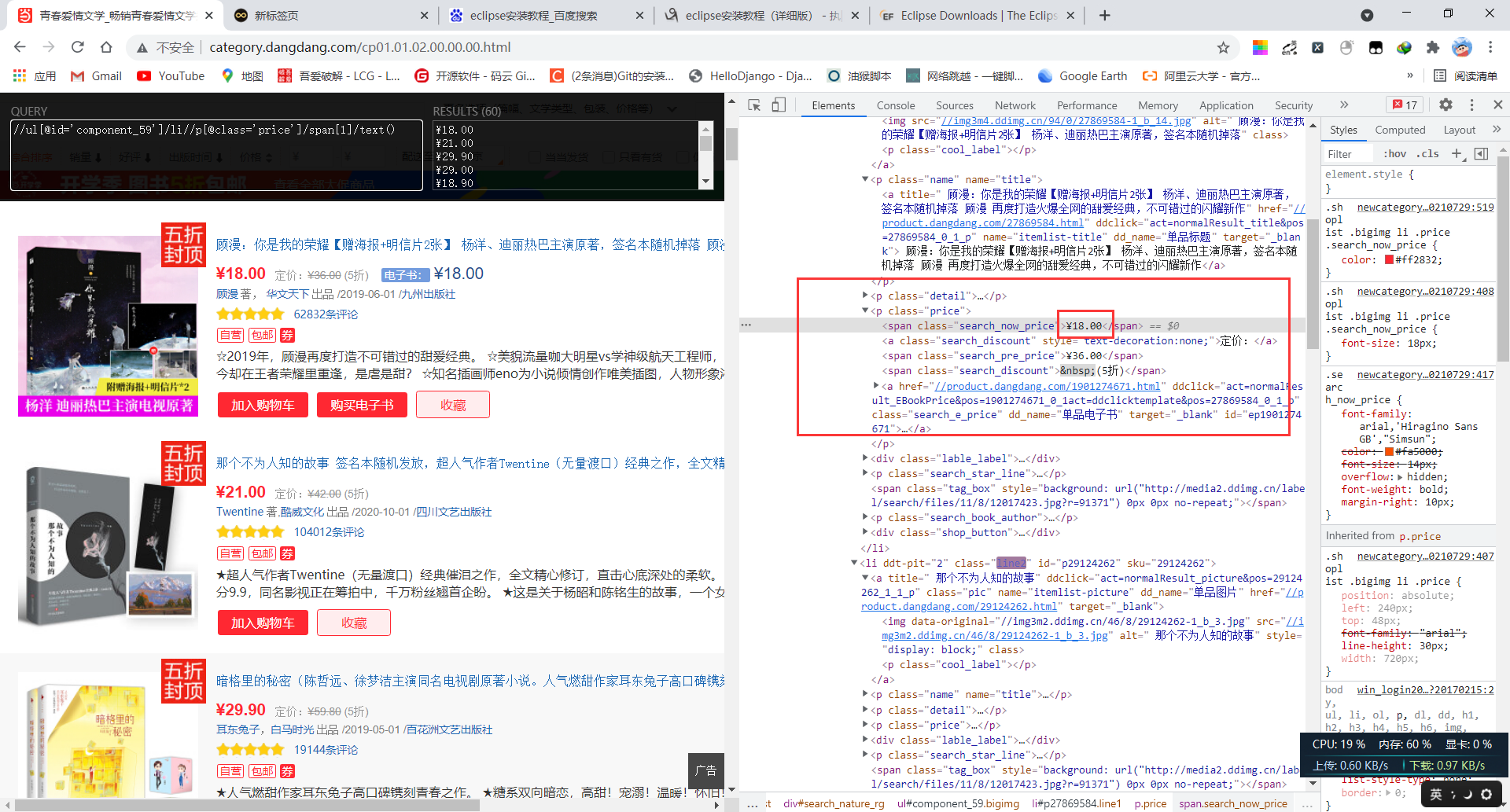
价格提取xpath表达式//ul[@id='component_59']/li//p[@class='price']/span[1]/text()
-
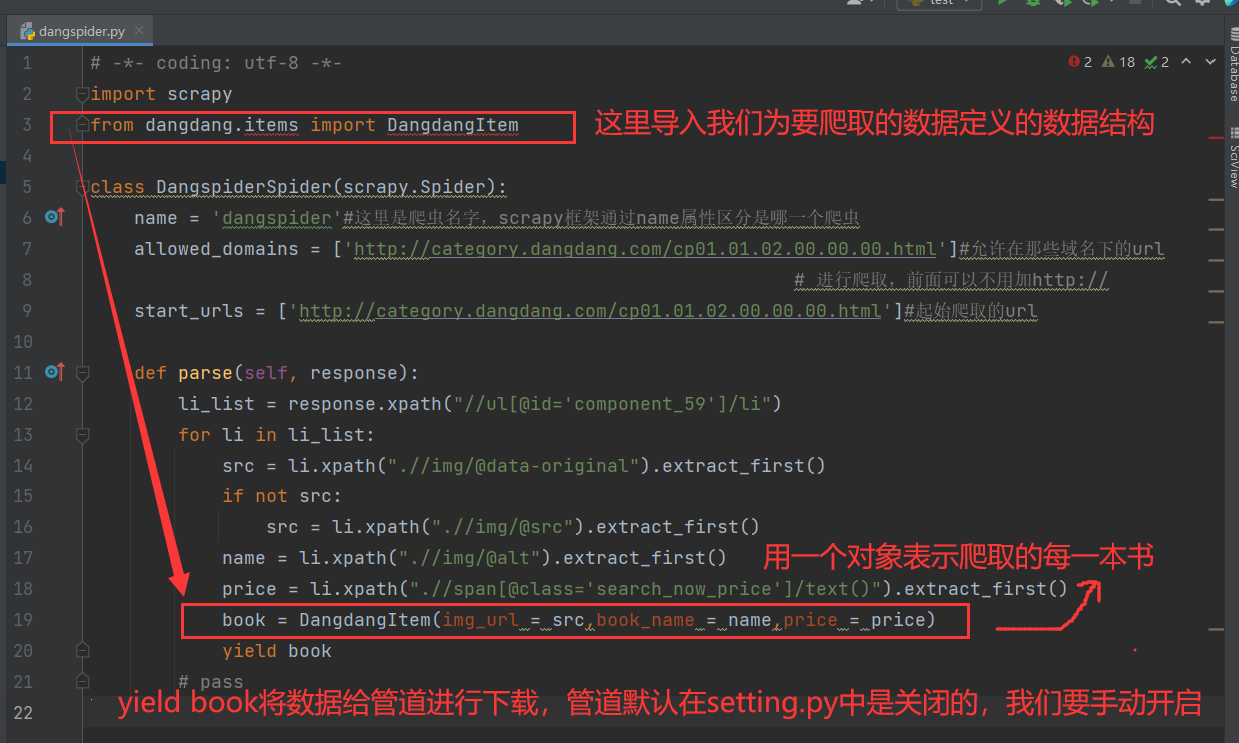
根据上一步的分析,编写parse函数
-
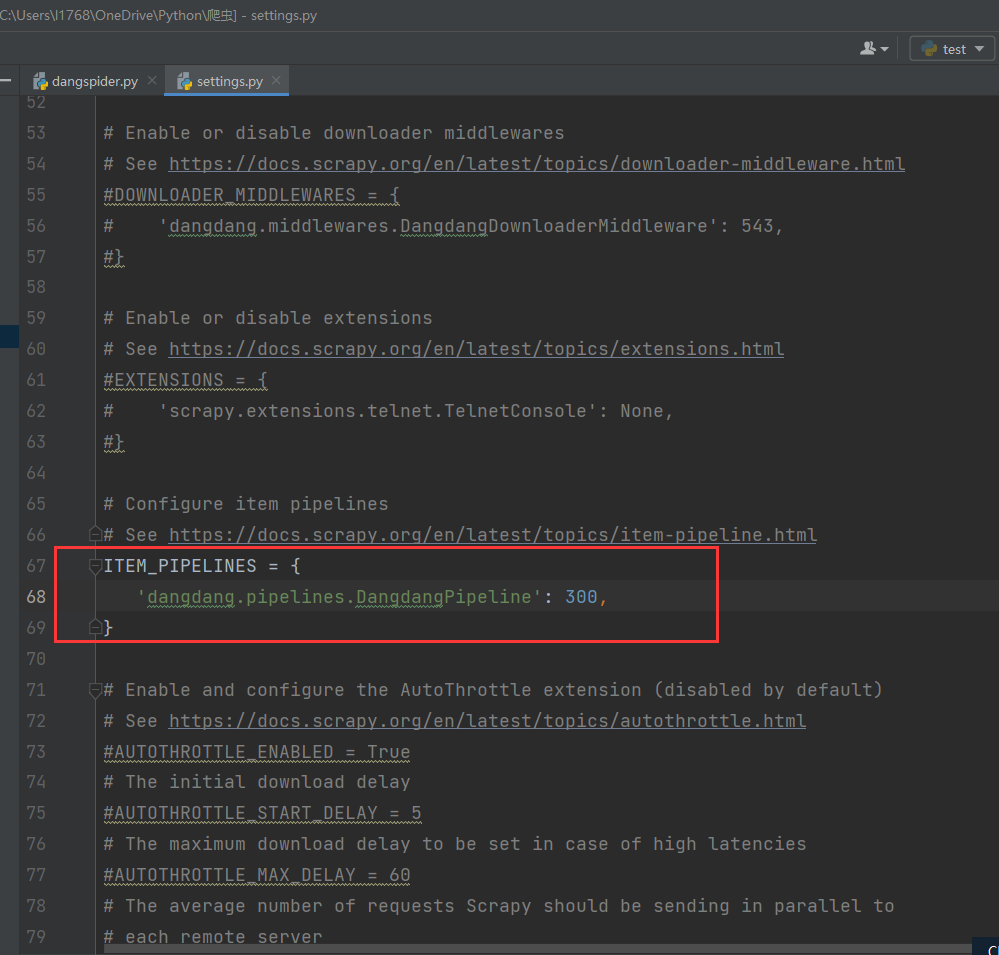
开启管道
-
为管道编写相关函数,我们将爬取的数据保存为json文件,一个对象为json文件一项纪录,process_item函数中的item就是yield送过来的对象
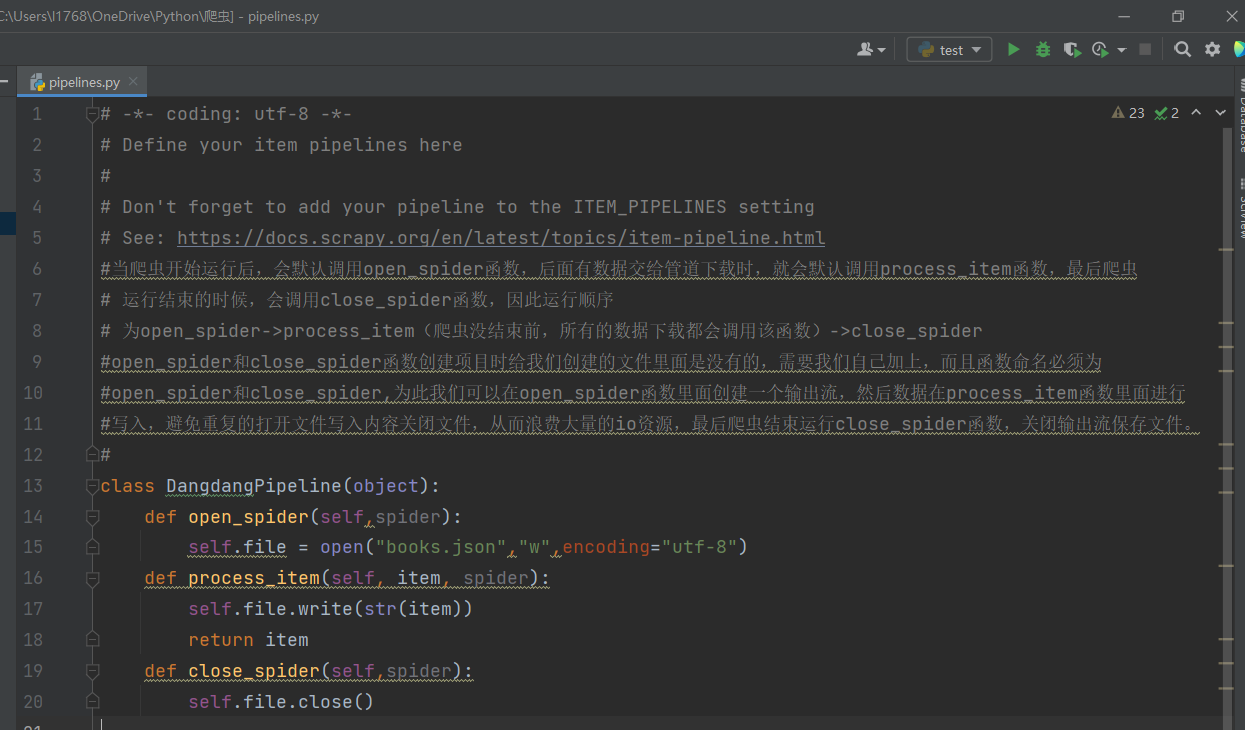
-
我们可以对书的图片进行下载,为此我们可以开辟另外一条管道专门用于图片的下载,图片保存到当前目录下的books文件夹下,为此我们创建books文件夹
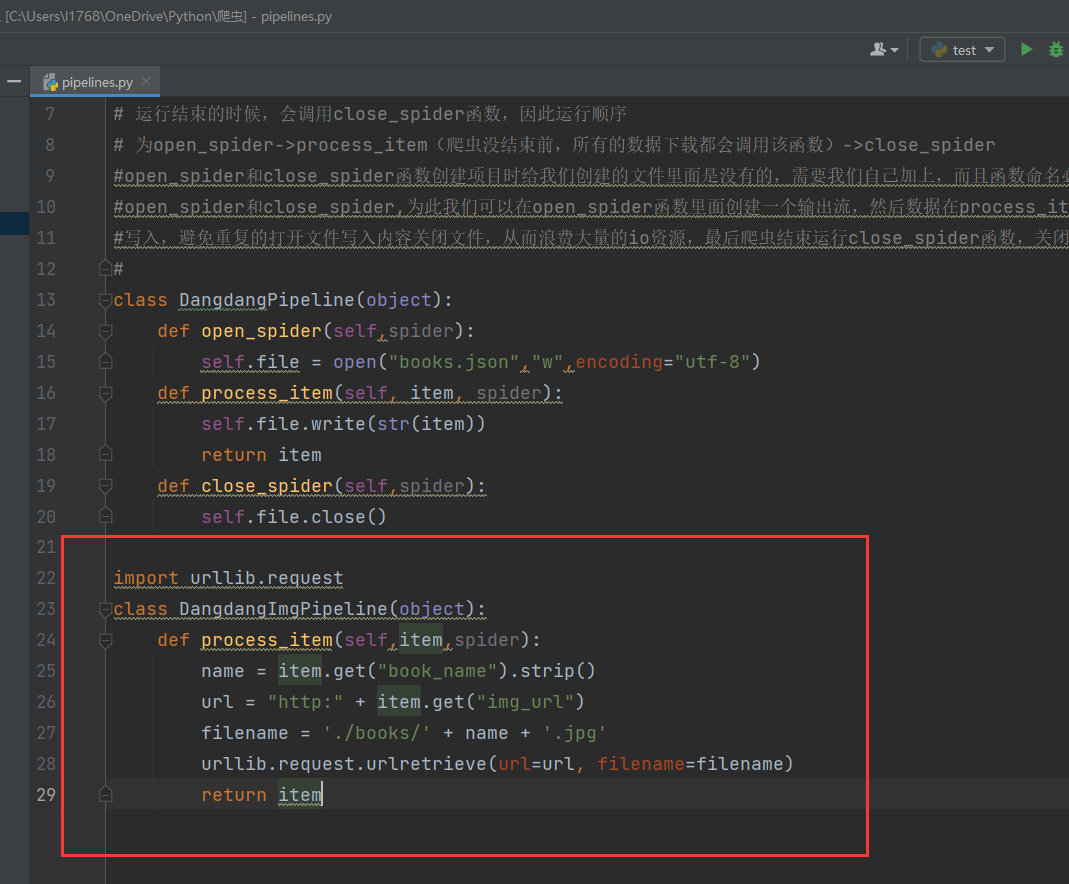
-
对于图片的下载的这条管道我们需要在setting.py文件中进行配置,并设置相应的管道优先级,优先级是数字越小优选级越大
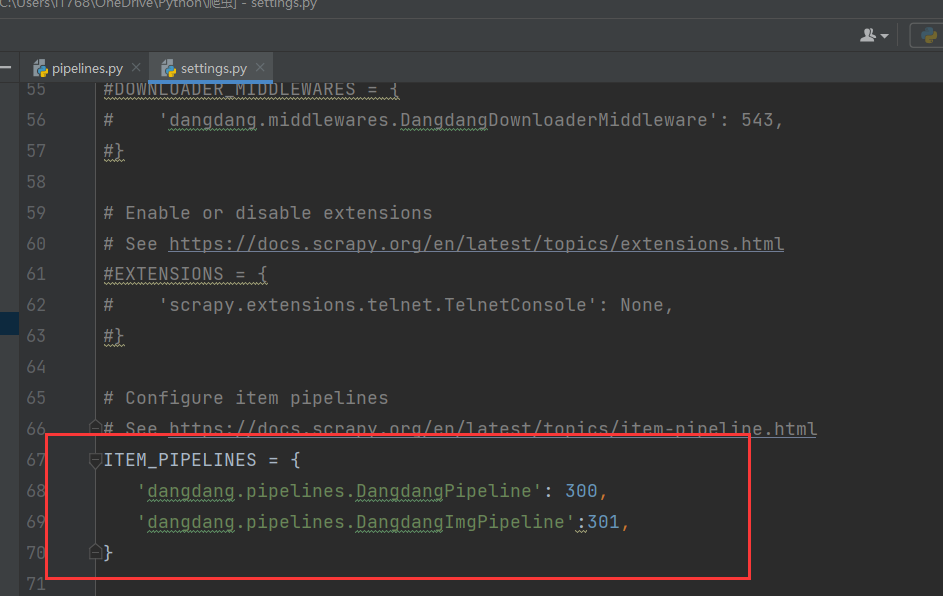
13.最后运行爬虫 scrapy crawl dangspider

- 运行结果
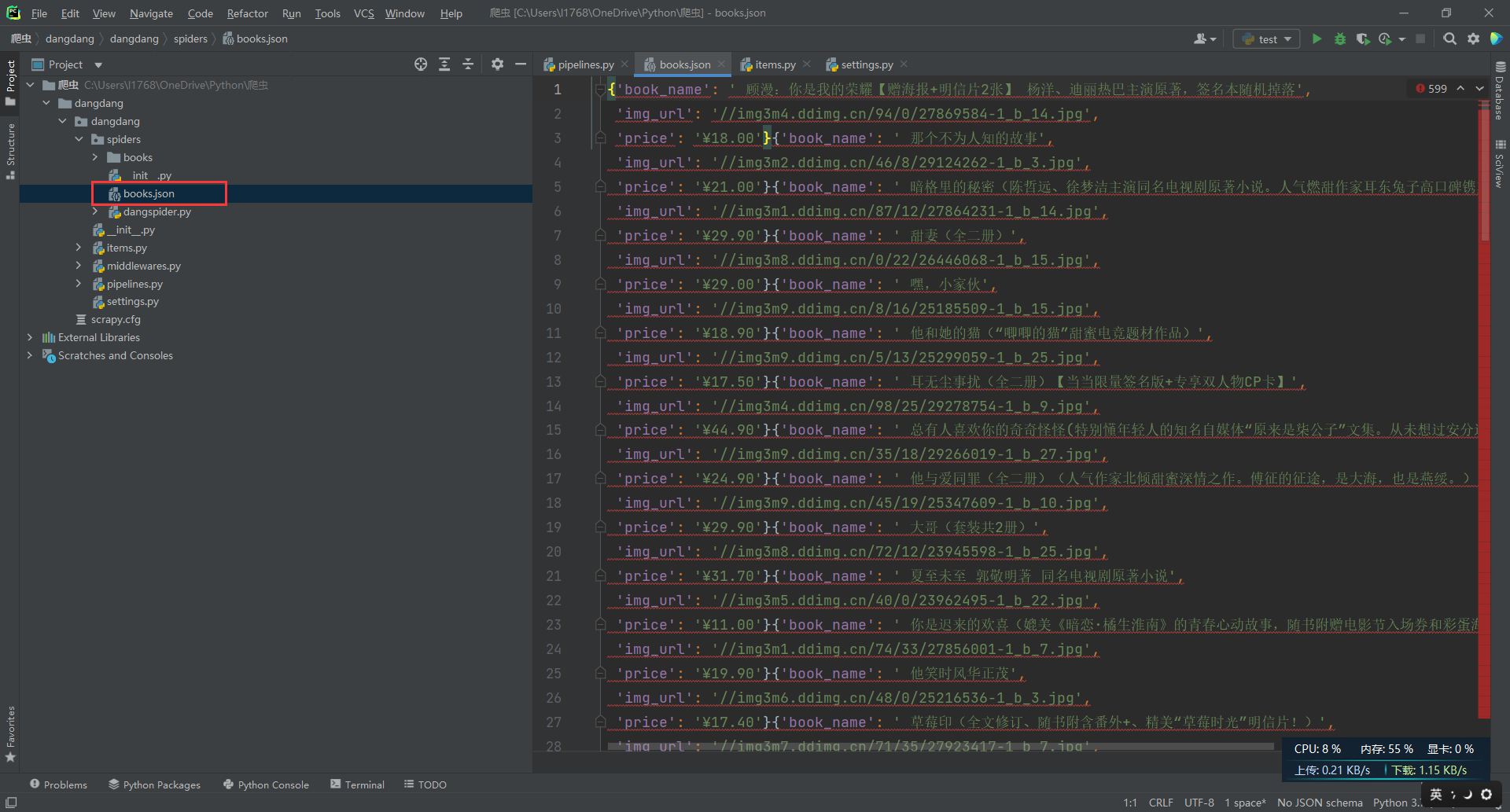
可以看到数据被保存到books.json文件里了
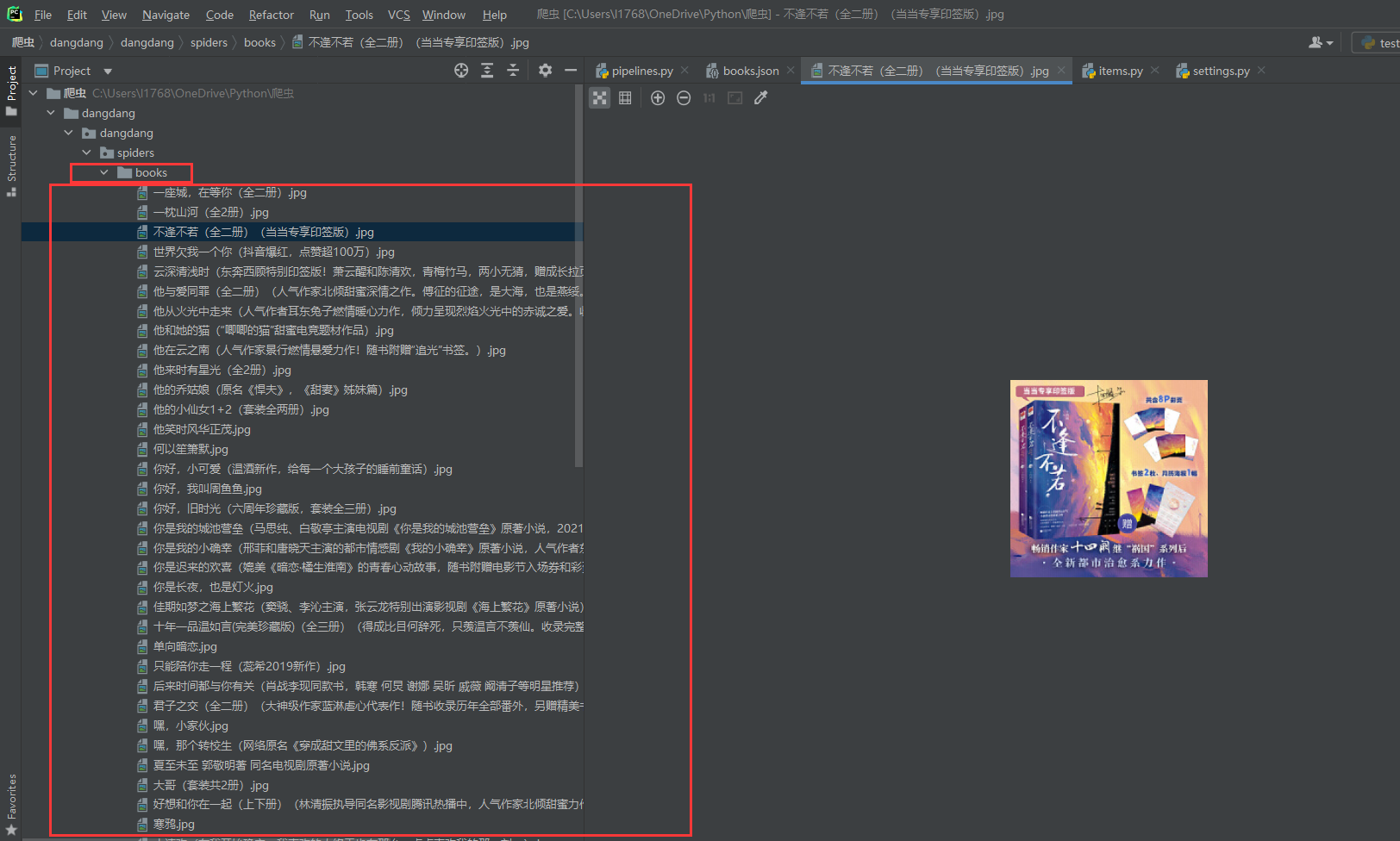
当页的图片也成功的爬取下来了。
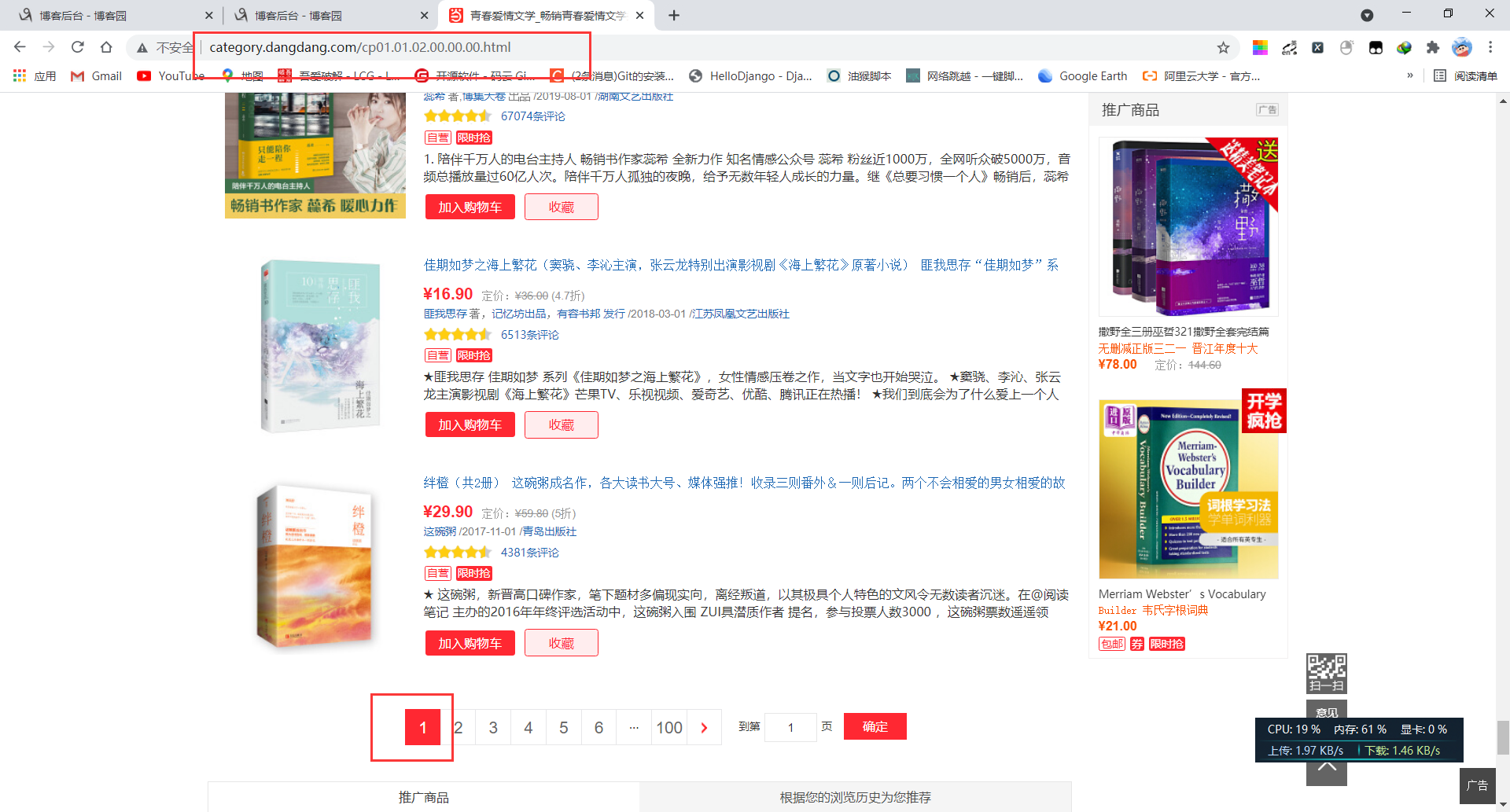
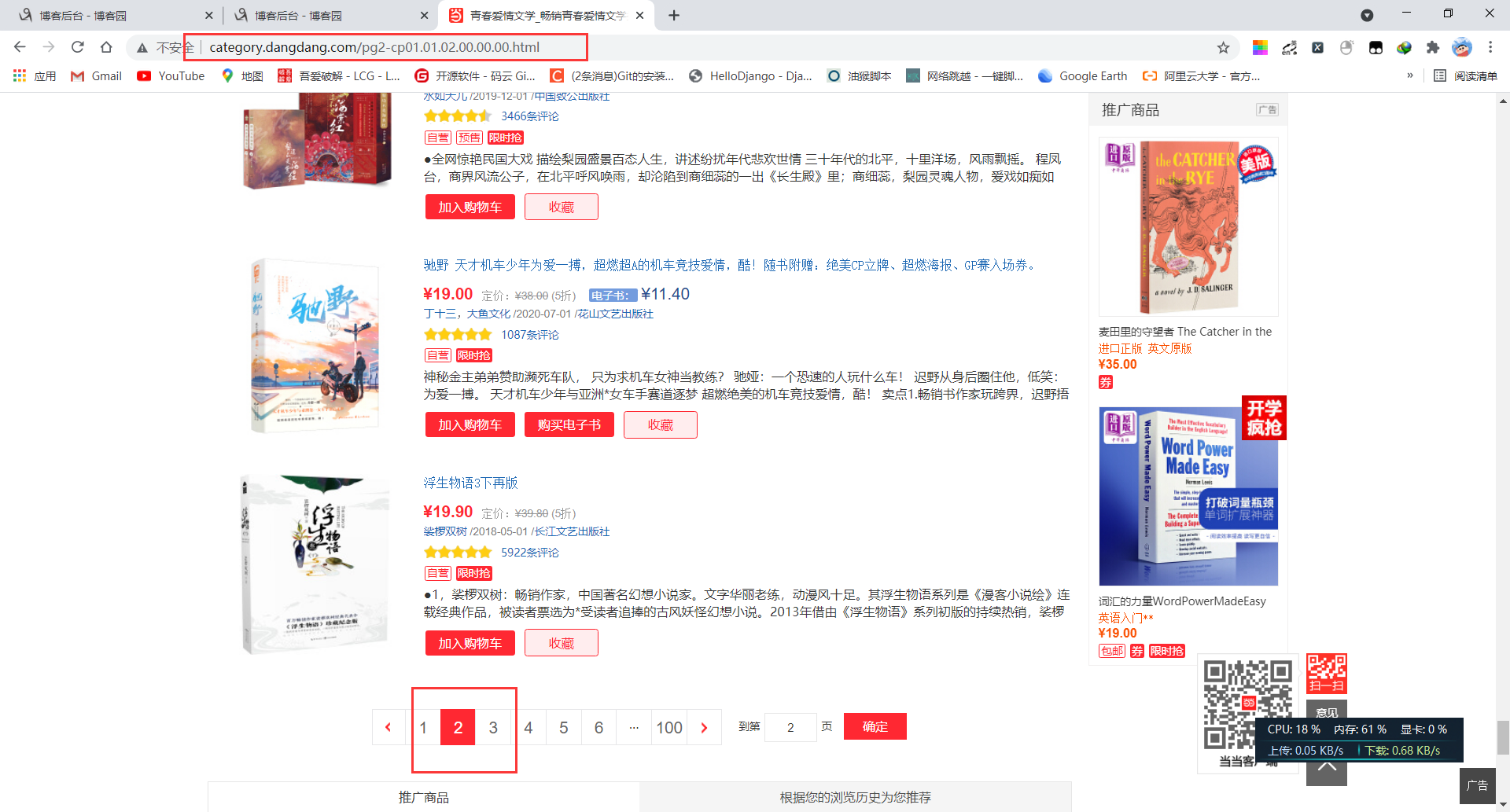
15. 接下来打算爬取100页的数据,因为每页的爬取方式相同,所以我们根据url的变化规律,拼接新的url后发送新的请求
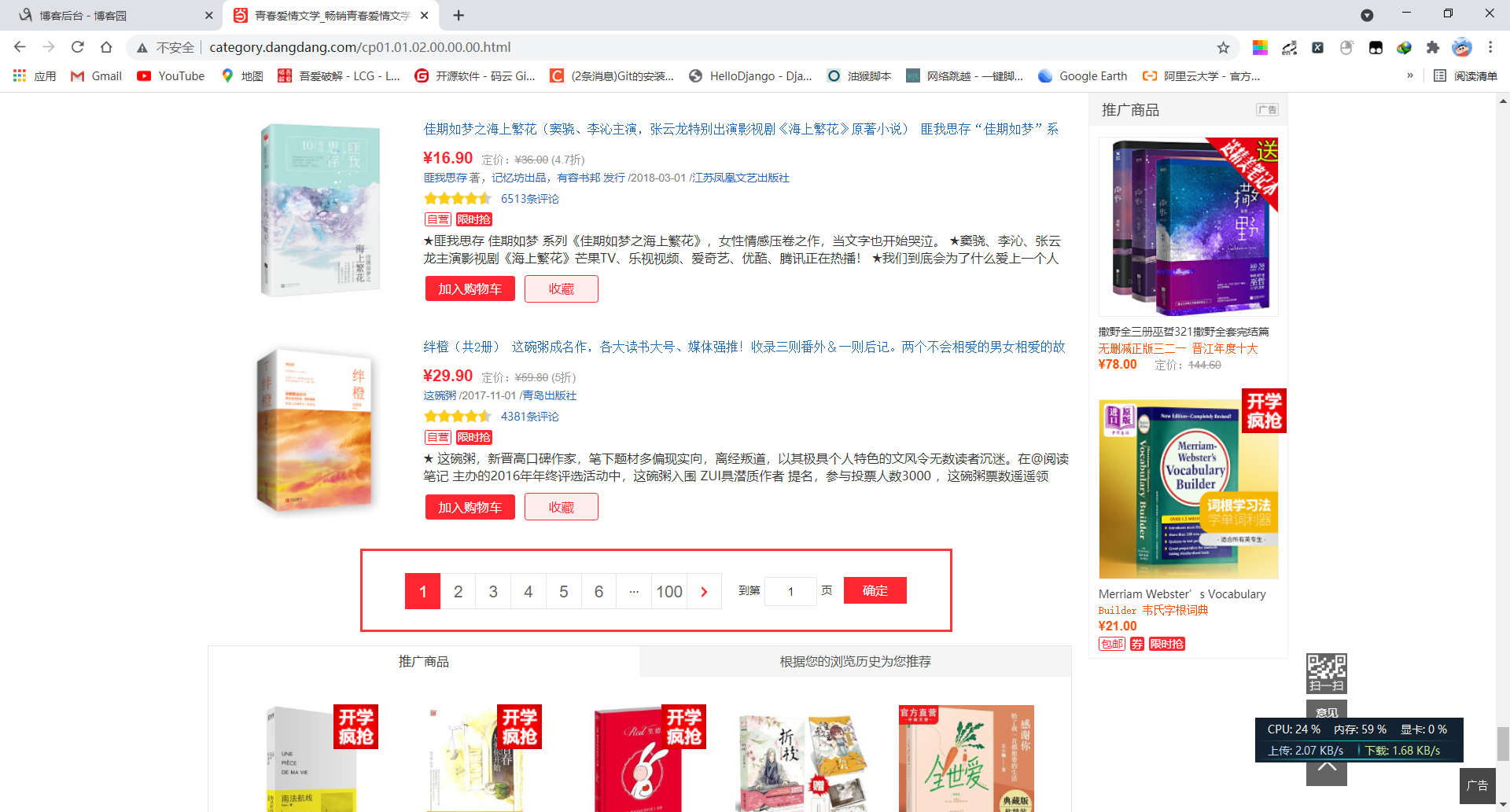
16. 通过观察可以看到url的变化
17. 续写parse函数
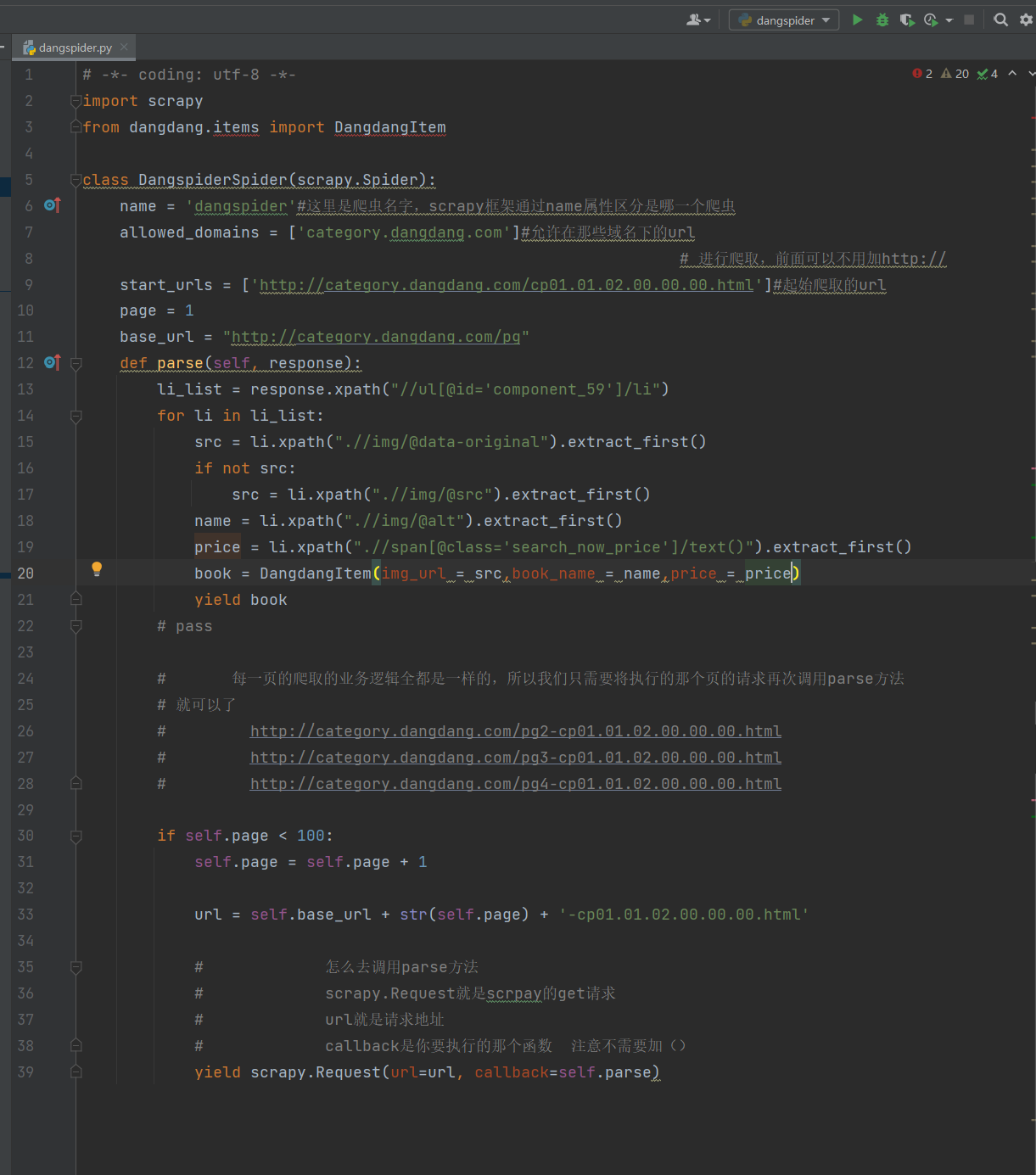
18. 再次运行爬虫即可得到100页我们要爬取的数据
本文来自博客园,作者:seonwee,转载请注明原文链接:https://www.cnblogs.com/seonwee/p/15239993.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号