
k8s部署微服务项目实战--react前端+springboot/python后端-第七节 k8s环境下中间件搭建-kafka集群以及使用
上两节,我分别给大家分享了mariaDB集群和redis集群的搭建使用,这一节关于kafka集群,我想我们更应该关注kafka的使用,因为kafka集群和zookeeper集群的搭建教程在网上实在太多,更重要的是我们的项目关于kafka集群的搭建原原本本是根据网上教程来的,除了业务相关的其他没有任何改动,所以多说无益,我列举了之前参考的kafka集群和zookeeper集群的搭建链接如下,再次对链接的博主表示感谢:
https://www.cnblogs.com/ding2016/p/8280696.html
https://www.cnblogs.com/ding2016/p/8282907.html
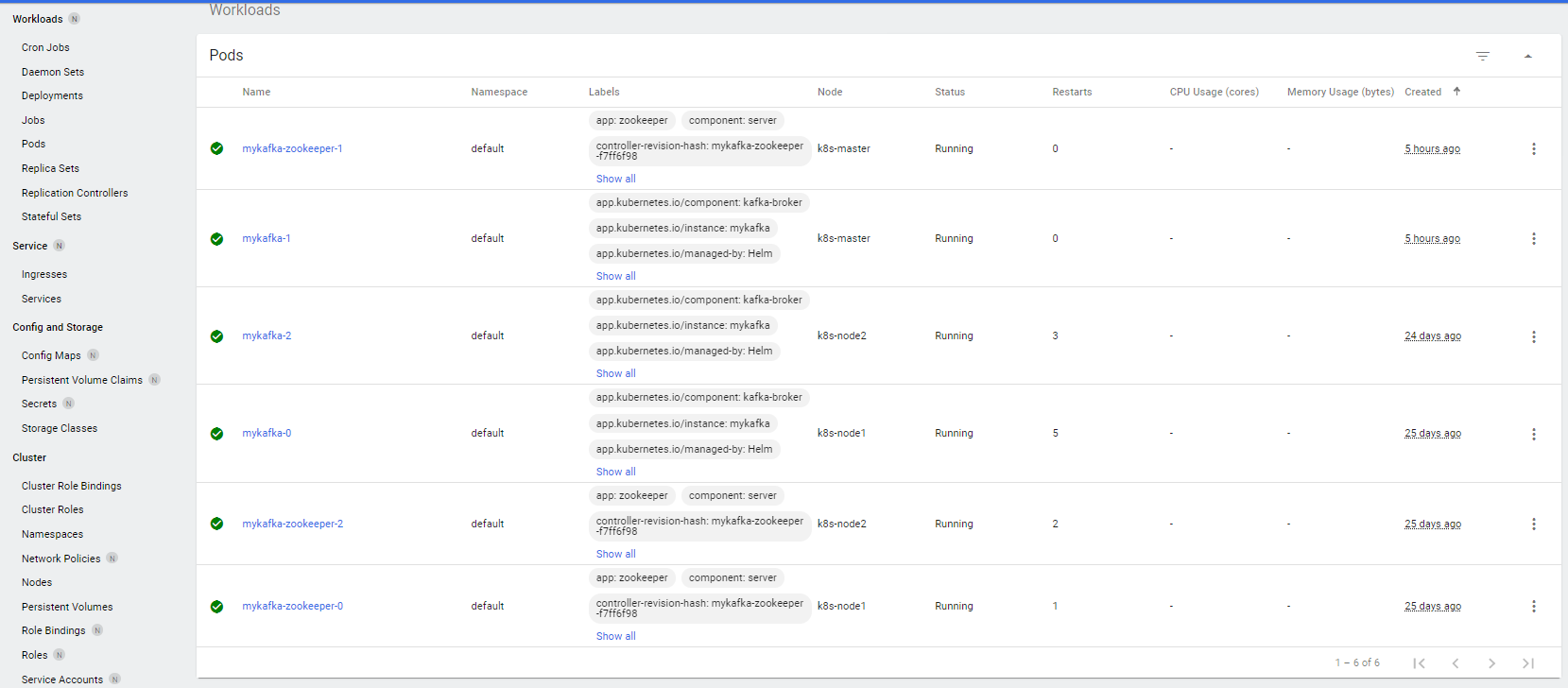
按照教程完成以后,您当前的kafka集群和zookeeper集群应该类似下图:
好了,下面开始我们这一节的正题----kafka的使用,我想通过下面三个问题来完成对kafka的应用:
问题一:Kafka能做什么?
问题二:我们用Kafka解决什么问题?
问题三:我们怎样用Kafka解决的问题以及过程中出现了哪些始料未及的问题?
OK,我们下面一一对这几个问题进行回答。
(一)Kafka能做什么?
传统的同步通信方式存在着明显的劣势(性能低,稳定性差),由此我们引入了异步的通信方式即消息队列。Kafka作为消息队列的一种(其他的例如RocketMQ、ActiveMQ、RabbitMQ、zeroMQ等),是一个分布式的,支持多分区(partition)的、多副本的,基于zookeeper协调的分布式消息系统。最耀眼的点就是可以无负担的处理极高的并发量(据说时几十万级别),因此广泛使用在消息通信、日志收集、hadoop的批处理以及一些时效性极强的系统中。
(二)我们用Kafka解决什么问题?
我们使用Kafka来进行日志的收集(没有使用Kafka来进行消息通信是考虑到我们的系统并发量少,并且微服务之间的通信有同步的需求),系统每执行一次测试用例集的运行,就会生成一个jobID(即认为每一次执行就是一项任务,分配一个任务ID),该jobID就作为Kafka的topic,后续所有此次任务过程中产生的log信息都会存到这个topic中,后续的ELK等模块就可以根据jobID即topic来从kafka中获取该次任务执行的log并进行分析。到此,凭您的经验,一定能想到我们这个需求其实对Kafka集群提出了两个难题:
1. 我们系统中kafka的topic(即jobID)并不是事先已知的topic,完全都是根据用户每次创建或者选择的测试用例集而动态生成的topic,最直接的影响就是consumer(消费者)无法事先写死这些topic。
2. 因为log记录的是测试用例运行的情况,因此要求向topic写入的消息应该是顺序的,而不能是无序的。
(三)我们怎样用Kafka解决的问题以及过程中出现了哪些始料未及的问题?
回答这个问题分两步走,首先,我来回答上个问题提到的两个难题;其次我给大家介绍一下代码中的实现。
难题1:我们系统中kafka的topic(即jobID)并不是事先已知的topic,完全都是根据用户每次创建或者选择的测试用例集而动态生成的topic,最直接的影响就是consumer(消费者)无法事先写死这些topic。
解决思路:kafka client端给consumer提供的api中支持consumer监听模糊匹配的topic pattern(类似与wildcard的*操作),因此,只要我们给生成的topic名字固定一个规则,例如统一命名为smartocr.xxxxxxx,那consumer监听的topic的pattern就可以写成smartocr.*,这样后续生成的topic都可以加入到consumer的监听列表中,问题得以解决。
难题2:因为log记录的是测试用例运行的情况,因此要求向topic写入的消息应该是顺序的,而不能是无序的。
解决思路:考虑到没有更好的方案(如果您对这种情况有更好的思路,请不吝赐教),我们采用的方案就是在创建topic的时候只给它分配一个分区(partition),这样由于测试用例的执行是串行的,就能保证往这个partition上写的消息一定是顺序的。
好了,下面给大家上代码,看一下项目中Kafka的使用以及上述难题解决的代码。
第一步:引入kafka依赖,以及配置kafka。在pom.xml中加入kafka的依赖:
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency>
注意:这里不要引用kafka-client这个依赖,这是原生的kafka客户端,现在都使用spring-kafka,封装性更好。
在application.properties中配置kafka:
spring.kafka.bootstrap-servers=mykafka-0.mykafka-headless.default.svc.cluster.local:9092,mykafka-1.mykafka-headless.default.svc.cluster.local:9092,mykafka-2.mykafka-headless.default.svc.cluster.local:9092
spring.kafka.producer.retries=3
spring.kafka.producer.batch-size=16384
spring.kafka.producer.buffer-memory=33554432
spring.kafka.producer.acks=1
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
注意:bootstrap-servers列出的是所有kafka的pod的dns域名和端口;另外我这里只把producer(生产者)的配置列在配置文件中,而消费者因为有特殊属性的配置,所以我将其放到kafka的全局配置文件KafkaConfig.java中了。
第二步:配置kafka的全局配置文件KafkaConfig.java,其中设置了一些全局配置参数,例如ackMode是Manual还是Auto,以及consumer的一些关键配置(例如METADATA_MAX_AGE_CONFIG---多久扫描一下元数据即topic信息,这对扫描动态topic很关键;AUTO_OFFSET_RESET_CONFIG----每次从offset位置读取还是从最开始的位置读取等等此类配置)。另外全局配置文件中重写了listenerContainerFactory以及adminClient。
package com.example.demo.configuration; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.kafka.annotation.EnableKafka; import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; import org.springframework.kafka.core.ConsumerFactory; import org.springframework.kafka.core.DefaultKafkaConsumerFactory; import org.springframework.kafka.core.KafkaAdmin; import org.springframework.kafka.listener.ContainerProperties.AckMode; import java.util.HashMap; import java.util.Map; import org.apache.kafka.clients.admin.AdminClient; import org.apache.kafka.clients.admin.AdminClientConfig; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.StringDeserializer; import org.omg.CORBA.PRIVATE_MEMBER; import org.springframework.beans.factory.annotation.Value; @Configuration @EnableKafka public class KafkaConfig { @Value("${spring.kafka.bootstrap-servers}") private String bootstrapServers; private Map<String, Object> consumerProperties(){ Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); props.put(ConsumerConfig.METADATA_MAX_AGE_CONFIG, 5000); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500); props.put(ConsumerConfig.GROUP_ID_CONFIG, "smartocr"); //props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return props; } @Bean public ConsumerFactory<String, String> consumerFactory(){ return new DefaultKafkaConsumerFactory<>(consumerProperties()); } @Bean public ConcurrentKafkaListenerContainerFactory<String, String> listenerContainerFactory(){ ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.getContainerProperties().setAckMode(AckMode.MANUAL); factory.setConcurrency(3); return factory; } @Bean public KafkaAdmin kafkaAdmin() { Map<String, Object>props = new HashMap<>(); props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers); props.put(AdminClientConfig.METADATA_MAX_AGE_CONFIG, 5000); KafkaAdmin admin = new KafkaAdmin(props); return admin; } @Bean public AdminClient adminClient() { return AdminClient.create(kafkaAdmin().getConfigurationProperties()); } }
第三步:最重要的一步,就是创建消费者Consumer,使用上面重写的adminClient和listenerContainerFactory。
package com.example.demo.consumer; import java.util.Arrays; import org.apache.kafka.clients.admin.AdminClient; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.kafka.support.Acknowledgment; import org.springframework.stereotype.Component; @Component public class OcrConsumer { @Autowired private AdminClient adminClient; @KafkaListener(containerFactory = "listenerContainerFactory", topicPattern = "smartocr.*", groupId = "smartocr") public void listenGroup(ConsumerRecord<String, String>record, Acknowledgment ack) { System.out.printf("smartocr.* = %s, offset = %d, value = %s \n",record.topic(),record.offset(),record.value()); ack.acknowledge(); if("Job Done!".equals(record.value())) { adminClient.deleteTopics(Arrays.asList(record.topic())); } } }
注意:重点关注topicPattern,这是我们统一定义的topic的格式。
第四步:在代码中创建Kafka的topic并使用生产者向topic中写入log信息。
String kafkaKey = UUID.randomUUID().toString().replaceAll("-", ""); //insert into kafka String kafkaTopic = "smartocr." + kafkaKey; NewTopic topic = new NewTopic(kafkaTopic, 1, (short)1); CreateTopicsResult topics = adminClient.createTopics(Arrays.asList(topic)); Thread.sleep(6000); try { topics.all().get(); System.out.println("Ready to send message to topic "+kafkaTopic); kafkaTemplate.send(kafkaTopic, 0, kafkaKey, "Log for Job "+kafkaKey+"begins!"); } catch (Exception e) { // TODO: handle exception System.out.print("create topics fail due to "+e.getMessage()); e.printStackTrace(); } finally { adminClient.close(); }
注意,标红的部分就是创建topic,我们写死了只有1个partition分区,topic的名字也是固定前缀的格式。而后调用kafkaTemplate.send来发送消息了。
好了,代码很简单,是吧?但是研究太费时了~~
最后我很想跟您再聊一下另外一种可能的实现方式,思路如下,您觉得是否可行呢?
思路:1. 使用最原生的kafka-client依赖
2. 每次生成一个新的topic就new一个新的线程,线程中new一个consumer来监听,job结束后再结束掉这个线程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号