编写高质量代码:改善Java程序的151个建议(第5章:数组和集合___建议70~74)
建议70:子列表只是原列表的一个视图
List接口提供了subList方法,其作用是返回一个列表的子列表,这与String类subSting有点类似,但它们的功能是否相同呢?我们来看如下代码:
1 public class Client70 { 2 public static void main(String[] args) { 3 // 定义一个包含两个字符串的列表 4 List<String> c = new ArrayList<String>(); 5 c.add("A"); 6 c.add("B"); 7 // 构造一个包含c列表的字符串列表 8 List<String> c1 = new ArrayList<String>(c); 9 // subList生成与c相同的列表 10 List<String> c2 = c.subList(0, c.size()); 11 // c2增加一个元素 12 c2.add("C"); 13 System.out.println("c==c1? " + c.equals(c1)); 14 System.out.println("c==c2? " + c.equals(c2)); 15 } 16 }
c1是通过ArrayList的构造函数创建的,c2是通过列表的subList方法创建的,然后c2又增加了一个元素"C",现在的问题是输出的结果是什么呢?列表c与c1、c2之间是什么关系呢?先不回答这个问题,我们先来回想一下String类的subString方法,看看它是如何工作的,代码如下:
1 public static void testStr() { 2 String str = "AB"; 3 String str1 = new String(str); 4 String str2 = str.substring(0) + "C"; 5 System.out.println("str==str1? " + str.equals(str1)); 6 System.out.println("str==str2? " + str.equals(str2)); 7 }
很明显,str和str1是相等的(虽然不是同一个对象,但用equals方法判断是相等的),但它们与str2不相等,这毋庸置疑,因为str2在对象池中重新生成了一个新的对象,其表面值是ABC,那当然与str和str1不相等了。
说完了subString的小插曲,现在回到List是否相等的判断上来。subList与subString的输出结果是一样的吗?让事实说话,运行结果如下:c==c1? false c==c2? true
很遗憾,与String类正好相反,同样是一个sub类型的操作,为什么会相反呢?c2是通过subList方法从c列表中生成的一个子列表,然后c2又增加了一个元素,可为什么增加了一个元素还会相等呢?我们从subList的源码来分析一下:
1 public List<E> subList(int fromIndex, int toIndex) { 2 return (this instanceof RandomAccess ? 3 new RandomAccessSubList<>(this, fromIndex, toIndex) : 4 new SubList<>(this, fromIndex, toIndex)); 5 }
subList的方法是由AbstractList实现的,它会根据是不是可以随机存取来提供不同的SubList实现方式,不过,随机存取的使用频率比较高,而且RandomAccessSubList也是subList的子类,所以所有的操作都是由Sublist类实现的(除了自身的SubList方法外),那么,我们就直接看看SubList类的代码:
1 class SubList<E> extends AbstractList<E> { 2 //原始列表 3 private final AbstractList<E> l; 4 //偏移量 5 private final int offset; 6 private int size; 7 //构造函数,注意list参数就是我们的原始列表 8 SubList(AbstractList<E> list, int fromIndex, int toIndex) { 9 /*下标校验代码 略*/ 10 //传递原始列表 11 l = list; 12 offset = fromIndex; 13 //子列表的长度 14 size = toIndex - fromIndex; 15 this.modCount = l.modCount; 16 } 17 //获得制定位置的元素 18 public E get(int index) { 19 /*下标校验 略*/ 20 //从原始字符串中获得制定位置的元素 21 return l.get(index+offset); 22 } 23 //增加或插入 24 public void add(int index, E element) { 25 /*下标校验 略*/ 26 //直接增加到原始字符串上 27 l.add(index+offset, element); 28 /*处理长度和修改计数器*/ 29 } 30 /*其它方法 略*/ 31 }
通过阅读这段代码,我们就非常清楚subList方法的实现原理了:它返回的SubList类也是AbstractList的子类,其所有的get、set、add、remove等都是在原始列表上的操作,它自身并没有生成一个新的数组或是链表,也就是子列表只是原列表的一个视图(View)而已。所有的修改动作都映射到了原列表上。
我们例子中的c2增加了一个元素C,不过增加的元素C到了c列表上,两个变量的元素仍然保持一致,相等也就是自然的了。
解释完相等的问题,再回过头来看看变量c与c1不行等的原因,很简单,因为通过ArrayList构造函数创建的List对象实际上是新列表,它是通过数组的copyOf动作生成的,所生成的列表c1与原列表c之间没有任何关系(虽然是浅拷贝,但元素类型是String,也就是说元素是深拷贝的),然后c又增加了元素,因为c1与c之间已经没有一毛线关系了。
注意:subList产生的列表只是一个视图,所有的修改动作直接作用于原列表。
建议71:推荐使用subList处理局部列表
我们来看这样一个简单的需求:一个列表有100个元素,现在要删除索引位置为20~30的元素。这很简单,一个遍历很快就可以完成,代码如下:
1 public class Client71 { 2 public static void main(String[] args) { 3 // 初始化一个固定长度,不可变列表 4 List<Integer> initData = Collections.nCopies(100, 0); 5 // 转换为可变列表 6 List<Integer> list = new ArrayList<Integer>(initData); 7 // 遍历,删除符合条件的元素 8 for (int i = 0; i < list.size(); i++) { 9 if (i >= 20 && i < 30) { 10 list.remove(i); 11 } 12 } 13 } 14 }
或者将for循环改为:
1 for(int i=20;i<30;i++){ 2 if(i<list.size()){ 3 list.remove(i); 4 } 5 }
相信首先出现在大家脑海中的实现算法就是此算法了,遍历一遍,符合条件的删除,简单而使用,不过,有没有其它方式呢?有没有“one-lining”一行代码就解决问题的方式呢?
有,直接使用ArrayList的removeRange方法不就可以了吗?不过好像不可能呀,虽然JDK上由此方法,但是它有protected关键字修饰着,不能直接使用,那怎么办?看看如下代码:
1 public static void main(String[] args) { 2 // 初始化一个固定长度,不可变列表 3 List<Integer> initData = Collections.nCopies(100, 0); 4 // 转换为可变列表 5 List<Integer> list = new ArrayList<Integer>(initData); 6 //删除指定范围内的元素 7 list.subList(20, 30).clear(); 8 }
上一个建议讲了subList方法的具体实现方式,所有的操作都是在原始列表上进行的,那我们就用subList先取出一个子列表,然后清空。因为subList返回的list是原始列表的一个视图,删除这个视图中 的所有元素,最终都会反映到原始字符串上,那么一行代码解决问题了。
顺便贴一下上面方法调用的源码:
public void clear() { removeRange(0, size()); }
1 protected void removeRange(int fromIndex, int toIndex) { 2 ListIterator<E> it = listIterator(fromIndex); 3 for (int i=0, n=toIndex-fromIndex; i<n; i++) { 4 it.next(); 5 it.remove(); 6 } 7 }
建议72:生成子列表后不要再操作原列表
前面说了,subList生成的子列表是原列表的一个视图,那在subList执行完后,如果修改了原列表的内容会怎样呢?视图是否会改变呢?如果是数据库视图,表数据变更了,视图当然会变了,至于subList生成的视图是否会改变,还是从源码上来看吧,代码如下:
1 public class Client72 { 2 public static void main(String[] args) { 3 List<String> list = new ArrayList<String>(); 4 list.add("A"); 5 list.add("B"); 6 list.add("C"); 7 List<String> subList = list.subList(0, 2); 8 //原字符串增加一个元素 9 list.add("D"); 10 System.out.println("原列表长度:"+list.size()); 11 System.out.println("子列表长度:"+subList.size()); 12 } 13 }
程序中有一个原始列表,生成了一个子列表,然后在原始列表中增加一个元素,最后打印出原始列表和子列表的长度,大家想一下,这段程序什么地方会出现错误呢?list.add("D")会报错吗?不会,subList并没有锁定原列表,原列表当然可以继续修改。难道有size方法?正确,确实是size方法出错了,输出结果如下:
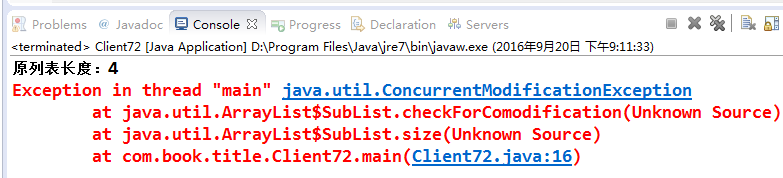
什么,居然是subList的size方法出现了异常,而且还是并发修改异常?这没道理呀,这里根本就没有多线程操作,何来并发修改呢?这个问题很容易回答,那是因为subList取出的列表是原列表的一个视图,原数据集(代码中的lsit变量)修改了,但是subList取出的子列表不会重新生成一个新列表(这点与数据库视图是不相同的),后面在对子列表继续操作时,就会检测到修改计数器与预期的不相同,于是就抛出了并发修改异常。出现这个问题的最终原因还是在子列表提供的size方法的检查上,还记得上面几个例子中经常提到的修改计数器?原因就在这里,我们来看看size的源代码:
1 public int size() { 2 checkForComodification(); 3 return size; 4 }
其中的checkForComodification()方法就是用于检测是否并发修改的,代码如下:
1 private void checkForComodification() 2 { 3 //判断当前修改计数器是否与子列表生成时一致 4 if(modCount != l.modCount) 5 throw new ConcurrentModificationException(); 6 else 7 return; 8 }
modCount 是从什么地方来的呢?它是在subList子列表的构造函数中赋值的,其值等于生成子列表时的修改次数吗。因此在生成子列表后再修改原始列表,l.modCount的值就必然比modeCount大1,不再保持相等了,于是就抛出了ConcurrentModificationException异常。
subList的其它方法也会检测修改计数器,例如set、get、add等方法,若生成子列表后,再修改原列表,这些方法也会抛出ConcurrentModificationException异常。
对于子列表的操作,因为视图是动态生成的,生成子列表后再操作原列表,必然会导致"视图 "的不稳定,最有效的方法就是通过Collections.unmodifiableList方法设置列表为只读状态,代码如下:
1 public static void main(String[] args) { 2 List<String> list = new ArrayList<String>(); 3 List<String> subList = list.subList(0, 2); 4 //设置列表为只读状态 5 list=Collections.unmodifiableList(list); 6 //对list进行只读操作 7 //...... 8 //对subList进行读写操作 9 //...... 10 }
这在团队编码中特别有用,比如我生成了一个list,需要调用其他同事写的共享方法,但是一些元素是不能修改的,想想看,此时subList方法和unmodifiableList方法配合使用是不是就可以解决我们的问题了呢?防御式编程就是教我们如此做的。
这里还有一个问题,数据库的一张表可以有多个视图,我们的List也可以有多张视图,也就是可以有多个子列表,但问题是只要生成的子列表多于一个,任何一个子列表都不能修改了,否则就会抛出ConcurrentModificationException异常。
注意:subList生成子列表后,保持原列表的只读状态。
建议73:使用Comparator进行排序
在项目开发中,我们经常要对一组数据进行排序,或者升序或者降序,在Java中排序有多种方式,最土的方式就是自己写排序算法,比如冒泡排序、快速排序、二叉树排序等,但一般不需要自己写,JDK已经为我们提供了很多的排序算法,我们采用"拿来主义" 就成了。在Java中,要想给数据排序,有两种实现方式,一种是实现Comparable接口,一种是实现Comparator接口,这两者有什么区别呢?我们来看一个例子,就比如给公司职员按照工号排序吧,先定义一个职员类代码,如下所示:
1 import org.apache.commons.lang.builder.CompareToBuilder; 2 import org.apache.commons.lang.builder.ToStringBuilder; 3 public class Employee implements Comparable<Employee> { 4 // 工号--按照进入公司的先后顺序编码的 5 private int id; 6 // 姓名 7 private String name; 8 // 职位 9 private Position position; 10 11 public Employee(int _id, String _name, Position _position) { 12 id = _id; 13 name = _name; 14 position = _position; 15 } 16 //getter和setter方法略 17 // 按照Id排序,也就是按照资历的深浅排序 18 @Override 19 public int compareTo(Employee o) { 20 return new CompareToBuilder().append(id, o.id).toComparison(); 21 } 22 23 @Override 24 public String toString() { 25 return ToStringBuilder.reflectionToString(this); 26 } 27 28 } 29 //枚举类型(三个级别Boss(老板)、经理(Manager)、普通员工(Staff)) 30 enum Position { 31 Boss, Manager, Staff 32 }
这是一个简单的JavaBean,描述的是一个员工的基本信息,其中id是员工编号,按照进入公司的先后顺序编码,position是岗位描述,表示是经理还是普通职员,这是一个枚举类型。
注意Employee类中的compareTo方法,它是Comparable接口要求必须实现的方法,这里使用apache的工具类来实现,表明是按照Id的自然序列排序的(也就是升序),现在我们看看如何排序:
1 public static void main(String[] args) { 2 List<Employee> list = new ArrayList<Employee>(5); 3 // 两个职员 4 list.add(new Employee(1004, "马六", Position.Staff)); 5 list.add(new Employee(1005, "赵七", Position.Staff)); 6 // 两个经理 7 list.add(new Employee(1002, "李四", Position.Manager)); 8 list.add(new Employee(1003, "王五", Position.Manager)); 9 // 一个老板 10 list.add(new Employee(1001, "张三", Position.Boss)); 11 // 按照Id排序,也就是按照资历排序 12 Collections.sort(list); 13 for (Employee e : list) { 14 System.out.println(e); 15 } 16 }
在收集数据的时候本来应该从老板到员工,为了结果更清晰,故将其打乱,从员工到老板,排序结果如下:

是按照ID升序排列的,结果正确,但是,有时候我们希望按照职位来排序,那怎么做呢?此时,重构Employee类已经不合适了,Employee已经是一个稳定类,为了排序功能修改它不是一个好办法,哪有什么好的解决办法吗?
有办法,看Collections.sort方法,它有一个重载方法Collections.sort(List<T> list, Comparator<? super T> c),可以接收一个Comparator实现类,这下就好办了,代码如下:
1 class PositionComparator implements Comparator<Employee> { 2 @Override 3 public int compare(Employee o1, Employee o2) { 4 // 按照职位降序排列 5 return o1.getPosition().compareTo(o2.getPosition()); 6 } 7 }
创建了一个职位排序法,依据职位的高低进行降序排列,然后只要Collections.sort(list)修改为Collections.sort(list,new PositionComparator() )即可实现按照职位排序的要求。
现在问题又来了:按职位临时倒叙排列呢?注意只是临时的,是否需要重写一个排序器呢?完全不用,有两个解决办法:
- 直接使用Collections.reverse(List <?> list)方法实现倒序排列;
- 通过Collections.sort(list , Collections.reverseOrder(new PositionComparator()))也可以实现倒序排列。
第二个问题:先按照职位排序,职位相同再按照工号排序,这如何处理呢?这可是我们经常遇到的实际问题。很好处理,在compareTo或者compare方法中判断职位是否相等,相等的话再根据工号排序,使用apache工具类来简化处理,代码如下:
@Override public int compareTo(Employee o) { return new CompareToBuilder().append(position, o.position) .append(id, o.id).toComparison(); }
在JDK中,对Collections.sort方法的解释是按照自然顺序进行升序排列,这种说法其实不太准确的,sort方法的排序方式并不是一成不变的升序,也可能是倒序,这依赖于compareTo的返回值,我们知道如果compareTo返回负数,表明当前值比对比值小,零表示相等,正数表明当前值比对比值大,比如我们修改一下Employee的compareTo方法,如下所示:
@Override public int compareTo(Employee o) { return new CompareToBuilder().append(o.id, id).toComparison(); }
两个参数调换了一下位置,也就是compareTo的返回值与之前正好相反,再使用Collections.sort进行排序,顺序也就相反了,这样也实现了倒序。
第三个问题:在Java中,为什么要有两个排序接口呢?
其实也很好回答,实现了Comparable接口的类表明自身是可以比较的,有了比较才能进行排序,而Comparator接口是一个工具类接口,它的名字(比较器)也已经表明了它的作用:用作比较,它与原有类的逻辑没有关系,只是实现两个类的比较逻辑,从这方面来说,一个类可以有很多的比较器,只要有业务需求就可以产生比较器,有比较器就可以产生N多种排序,而Comparable接口的排序只能说是实现类的默认排序算法,一个类稳定、成熟后其compareTo方法基本不会变,也就是说一个类只能有一个固定的、由compareTo方法提供的默认排序算法。
注意:Comparable接口可以作为实现类的默认排序算法,Comparator接口则是一个类的扩展排序工具。
建议74:不推荐使用binarySearch对列表进行检索
对一个列表进行检索时,我们使用最多的是indexOf方法,它简单、好用,而且也不会出错,虽然它只能检索到第一个符合条件的值,但是我们可以生成子列表后再检索,这样也即可以查找出所有符合条件的值了。
Collections工具类也提供了一个检索方法,binarySearch,这个是干什么的?该方法也是对一个列表进行检索的,可查找出指定值的索引,但是在使用这个方法时就有一些注意事项,我们看如下代码:
1 public class Client74 { 2 public static void main(String[] args) { 3 List<String> cities = new ArrayList<String> (); 4 cities.add("上海"); 5 cities.add("广州"); 6 cities.add("广州"); 7 cities.add("北京"); 8 cities.add("天津"); 9 //indexOf取得索引值 10 int index1= cities.indexOf("广州"); 11 //binarySearch找到索引值 12 int index2= Collections.binarySearch(cities, "广州"); 13 System.out.println("索引值(indexOf):"+index1); 14 System.out.println("索引值(binarySearch):"+index2); 15 } 16 }
先不考虑运行结果,直接看JDK上对binarySearch的描述:使用二分搜索法搜索指定列表,以获得指定对象。其实现的功能与indexOf是相同的,只是使用的是二分法搜索列表,所以估计两种方法返回的结果是一样的,看结果:
索引值(indexOf):1
索引值(binarySearch):2
结果不一样,虽然我们说有两个"广州" 这样的元素,但是返回的结果都应该是1才对呀,为何binarySearch返回的结果是2呢?问题就出在二分法搜索上,二分法搜索就是“折半折半再折半” 的搜索方法,简单,而且效率高。看看JDK是如何实现的。
1 private static final int BINARYSEARCH_THRESHOLD = 5000; 2 public static <T> 3 int binarySearch(List<? extends Comparable<? super T>> list, T key) { 4 if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD) 5 //随机存取列表或者元素数量少于5000的顺序存取列表 6 return Collections.indexedBinarySearch(list, key); 7 else 8 //元素数量大于5000的顺序存取列表 9 return Collections.iteratorBinarySearch(list, key); 10 }
ArrayList实现了RandomAccess接口,是一个顺序存取列表,使用了indexedBinarySearch方法,代码如下:
1 private static <T> int indexedBinarySearch( 2 List<? extends Comparable<? super T>> list, T key) { 3 // 默认商界 4 int low = 0; 5 // 默认下界 6 int high = list.size() - 1; 7 8 while (low <= high) { 9 //中间索引,无符号右移一位 10 int mid = (low + high) >>> 1; 11 //中间值 12 Comparable<? super T> midVal = list.get(mid); 13 //比较中间值 14 int cmp = midVal.compareTo(key); 15 //重置上界和下界 16 if (cmp < 0) 17 low = mid + 1; 18 else if (cmp > 0) 19 high = mid - 1; 20 else 21 //找到元素 22 return mid; // key found 23 } 24 //没有找到,返回负值 25 return -(low + 1); // key not found 26 }
这也没啥说的,就是二分法搜索的Java版实现。注意看第10和14行代码,首先是获得中间的索引值,我们的例子中也就是2,那索引值是2的元素值是多少呢?正好是“广州” ,于是就返回索引值2,正确,没问题,我们再看看indexOf的实现,代码如下:
1 public int indexOf(Object o) { 2 //null元素查找 3 if (o == null) { 4 for (int i = 0; i < size; i++) 5 if (elementData[i]==null) 6 return i; 7 } else { 8 //非null元素查找 9 for (int i = 0; i < size; i++) 10 //两个元素是否相等,注意这里是equals方法 11 if (o.equals(elementData[i])) 12 return i; 13 } 14 return -1; 15 }
indexOf方法就是一个遍历,找到第一个元素值相等则返回,没什么玄机,回到我们的程序来看,for循环的第二遍即是我们要查找的 " 广州 " ,于是就返回索引值1了,也正确,没有任何问题。
两者的算法都没有问题,难道是我们用错了。这的确是我们使用的错误,因为二分法查询的一个首要前提是:数据集以实现升序排列,否则二分法查找的值是不准确的。不排序怎么确定是在小区(比中间值小的区域) 中查找还是在大区(比中间值大的区域)中查找呢?二分法查找必须要先排序,这是二分法查找的首要条件。
问题清楚了,解决办法很easy,使用Collections.sort排下序即可解决。但这样真的可以解决吗?想想看,元素数据是从web或数据库中传递进来的,原本是一个有规则的业务数据,我们为了查找一个元素对它进行了排序,也就是改变了元素在列表中的位置,那谁来保证业务规则的准确性呢?所以说,binarySearch方法在此处受限了,当然,拷贝一个数组,然后再排序,再使用binarySearch查找指定值,也可以解决该问题。
使用binarySearch首先要考虑排序问题,这是我们经常忘记的,而且在测试期间还不好发现问题,等到投入生产环境后才发现查找到的数据不准确,又是一个bug产生了,从这点看,indexOf要比binarySearch简单的多.
使用binarySearch的二分法查找比indexOf的遍历算法性能上高很多,特别是在大数据集且目标值又接近尾部时,binarySearch方法与indexOf方法相比,性能上会提升几十倍,因此从性能的角度考虑时可以选择binarySearch。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号