
(精解版)MySQL8.0 OCP (1Z0-909) 练习题
法律声明与使用条款
© [sekkoo/https://www.cnblogs.com/sekkoo] 保留所有权利。
本材料中的所有解析内容均为作者投入大量时间和精力完成的原创劳动成果。为了保护这份成果并确保其用于正确目的,特此声明以下使用条款:
1. 免责声明与内容来源
本材料中的题目内容是基于网络社区的公开讨论和匿名贡献进行整理和重构的,不代表任何官方考试内容。所有详细解析均为作者独立分析和整理,与 Oracle 公司无任何关联,也未获得其官方授权。
2. 使用条款
仅限个人学习使用: 本解析内容仅供您个人非商业性学习和研究使用。严禁将本材料用于任何形式的商业目的,包括但不限于出售、出租、广告或作为付费服务的组成部分。
严禁滥用与作弊: 本人坚决反对将本材料用于任何形式的作弊行为。我的解析旨在帮助您理解知识,而不是提供捷径。任何将本材料用于违反考试规则的行为,都将受到最强烈的谴责。
转载与分享规范: 未经本人的明确书面授权,严禁对本解析内容进行任何形式的转载、分发、复制或上传至公共平台。如果您希望分享,请直接分享本内容的原始链接,以尊重版权。
3. 法律追责
对于任何侵犯本声明的行为,包括但不限于非法复制、商业盗用,本人将保留追究法律责任的权利。
通过使用本材料,您即表示同意并遵守以上所有条款。感谢您的理解与支持,希望这些解析能真正帮助您通过考试。
用于SQL验证的免费沙盒:https://paiza.io/en/projects/new
答题版:https://www.cnblogs.com/sekkoo/p/18972925
如发现内容错误,恳请不吝赐教,以便修正完善。
2025/7/4:感谢评论区大佬PerMing的指正,今日修改如下内容:
- Q6的答案改为C和D
- Q44的答案改为B和C
2025/7/7 感谢大家的纠正,今日修改如下内容:
- Q36 暂定选D
- Q103 题目有错误,修正了题目的错误,重新确定了答案
2025/7/8:感谢评论区大佬PerMing的指正,今日修改如下内容:
- Q74的答案改为B
2025/7/11:增加题目107-118
2025/7/15:Q103答案改为DCF
2025/7/29:增加题目119
Q1
Examine this SQL statement:
SELECT Name, Population FROM country
WHERE Name LIKE 'United%'
LIMIT 5;
Which two statements provide equivalent results using the X DevAPI protocol?
A. db.country.select(['Name','Population']).limit(5).where('Name LIKE "United%"')
B. db.country.fields(['Name','Population']).where('Name LIKE "United%"').select().limit(5)
C. db.country.select(['Name','Population']).where('Name LIKE :param').bind('param','United%').limit(5)
D. db.country.select(['Name LIKE "United%"','Population>=0']).limit(5)
E. db.country.fields(['Name','Population']).select('limit=5').where('Name LIKE "United%"')
答案:AC
中文翻译题目和选项
请检查如下 SQL 语句:
SELECT Name, Population FROM country
WHERE Name LIKE 'United%'
LIMIT 5;
下列哪两条 X DevAPI 协议的语句可获得等效结果?
A. db.country.select(['Name','Population']).limit(5).where('Name LIKE "United%"')
B. db.country.fields(['Name','Population']).where('Name LIKE "United%"').select().limit(5)
C. db.country.select(['Name','Population']).where('Name LIKE :param').bind('param','United%').limit(5)
D. db.country.select(['Name LIKE "United%"','Population>=0']).limit(5)
E. db.country.fields(['Name','Population']).select('limit=5').where('Name LIKE "United%"')
题干含义:
题目要求找出能用 X DevAPI 协议实现功能等效 SQL 查询的代码,即从 country 表中选出 Name 和 Population 字段,where 筛选 Name 以 "United" 开头(LIKE),只显示前5条记录。
选项分析
- A: 先限定字段(Name, Population),再限定5条,最后 where 过滤,语法与 SQL 逻辑一致。(正确答案)
- B: fields 和 select 串联有错误,select() 不是这样用法,顺序不对。
- C: 采用参数绑定(:param),bind 传递参数 'United%',语法和 SQL 查询等价,且安全防注入。(正确答案)
- D: 字段部分写成 'Name LIKE "United%"',带有条件语句,不是字段名,语法错误。
- E: select('limit=5'),limit 应为链式方法而不是 select 参数,语法错误。
相关知识点总结
- X DevAPI 是 MySQL 的一种开发接口,支持链式调用,常见方法包括 select, where, limit, bind 等。
- 能力等效时应满足字段选择、条件筛选和结果集限制全部一致。
- 参数绑定(bind)用来防 SQL 注入,也是推荐做法之一。
- limit 应作为方法而非 select 参数。
- where 方法中的条件书写方式需和 SQL 语法类似或用参数绑定实现。
Q2
英文原题
Examine this command which executes successfully:
shell> mysqlsh --host=localhost --user=root -p
Now, examine this command:
localhost:33060 JS> session
What is the result?
A. <Session:root@localhost:33060>
B. <Session:root@localhost:3306>
C. An error is returned because no active session object has yet been created.
D. An error is returned because session is not a valid SQL statement.
E. <ClassicSession:root@localhost:33060>
答案:A
中文翻译与解析
请检查如下命令(假设执行成功):
shell> mysqlsh --host=localhost --user=root -p
现在,请分析如下命令:
localhost:33060 JS> session
问:此时结果是什么?
选项:
<Session:root@localhost:33060><Session:root@localhost:3306>- 因为还没有创建会话对象,所以会返回错误。
- 因为 session 不是有效的 SQL 语句,会返回错误。
<ClassicSession:root@localhost:33060>
选项逐项解释
-
A.
<Session:root@localhost:33060>- 显示当前 session 对象,端口为 33060(X Protocol 标准端口),正好与 mysqlsh 默认 X Protocol 端口、用户 root 匹配。(正确答案)
-
B.
<Session:root@localhost:3306>- 端口错了,3306 是经典 MySQL 端口,mysqlsh 这里连接的是 33060。
-
C. 返回错误,因为尚未创建任何活动的 session 对象。
- 连接命令已经执行成功,session 已经创建。
-
D. 返回错误,因为 session 不是有效的 SQL 语句。
- 这里并非 SQL 模式,而是 JS 模式下查看内置 session (其实是 JavaScript 对象的输出)。
-
E.
<ClassicSession:root@localhost:33060>- ClassicSession 通常用于 classic 协议(即3306等),此处是 X Protocol,对应 Session,而不是 ClassicSession。
正确答案
B. <Session:root@localhost:3306>
相关知识点总结
mysqlsh即 MySQL Shell,支持 JS(JavaScript)、Python 和 SQL 三种模式。- 端口 33060 是 MySQL X 协议的默认端口(用于 Document Store/X DevAPI),而 3306 为传统 SQL 协议端口。
- session 是 MySQL Shell 内置对象,表示当前数据库会话。当连接到对应端口后可直接用 session 查看连接信息。
<Session:...>常用于 X 协议会话(Document Store 模式),而<ClassicSession:...>用于经典 MySQL 协议会话。- 在 Shell 内 session 命令不会报 SQL 错,直接输出会话对象信息。
Q3
英文原题
Examine this statement:
SHOW CREATE VIEW cityview\G;
*************************** 1. row ***************************
View: cityview
Create View: CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost`
SQL SECURITY DEFINER VIEW `cityview` AS
select `city`.`Name` AS `Name`, `city`.`Population` AS `Population`
from `city`
character_set_client: utf8mb4
collation_connection: utf8mb4_0900_a
Now examine this statement executed as root and output:
UPDATE cityview SET Population=2643585 WHERE Name="Roma";
ERROR: 1288 (HY000): The target table cityview of the UPDATE is not updatable
What must precede the UPDATE to avoid this error?
A. SET autocommit=1;
B. START TRANSACTION;
C. UNLOCK TABLES;
D. ALTER ALGORITHM=MERGE VIEW cityview AS SELECT Name, Population FROM city;
E. SET optimizer_switch='derived_merge=on';
答案:D
中文翻译与题目解析
请检查如下语句:
SHOW CREATE VIEW cityview\G;
*************************** 1. row ***************************
View: cityview
Create View: CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost`
SQL SECURITY DEFINER VIEW `cityview` AS
select `city`.`Name` AS `Name`, `city`.`Population` AS `Population`
from `city`
character_set_client: utf8mb4
collation_connection: utf8mb4_0900_a
现在查看以下以 root 用户执行的语句和输出:
UPDATE cityview SET Population=2643585 WHERE Name="Roma";
错误:1288 (HY000): UPDATE 的目标表 cityview 是不可更新的
要避免这个错误,UPDATE 前必须执行哪条语句?
选项解析
-
A. SET autocommit=1;
设置自动提交事务,对视图是否可更新没有影响。 -
B. START TRANSACTION;
启动事务,和视图可更新性无关。 -
C. UNLOCK TABLES;
解锁表,和视图可更新性无关。 -
D. ALTER ALGORITHM=MERGE VIEW cityview AS SELECT Name, Population FROM city;
正确答案。将视图的算法改为 MERGE 后,cityview 才可以用于直接更新到底层表(city),这样 UPADTE 语句才不会报错。 -
E. SET optimizer_switch='derived_merge=on';
调整优化器参数,优先级不高,不会赋予视图可更新性。
知识点总结
- MySQL 视图的可更新性:只有某些条件(如单表直投、无聚合/分组等)下才能更新。
- DEFINER/ALGORITHM:视图创建时默认的 ALGORITHM 可能导致视图成为非可更新(UNDEFINED/temptable 算法常见),而 MERGE 算法可使视图可更新。
- ALTER VIEW 语句:可用来调整视图定义及算法,满足可更新要求。
重点:要让基于单表的简单视图支持 UPDATE,通常应指定 ALGORITHM=MERGE。
CREATE VIEW
https://dev.mysql.com/doc/refman/8.0/en/create-view.html
1. CREATE VIEW 语法和功能
CREATE VIEW语句用于创建一个新视图;可选OR REPLACE子句可替换已有视图。- 视图定义通过
select_statement(SELECT 查询)确定,视图由基本表或其他视图构成。 - 可选子句包括
ALGORITHM(处理算法),DEFINER(定义者),SQL SECURITY(安全上下文),WITH CHECK OPTION(插入/更新约束)。
2. 视图定义与列名
- 视图创建时,其结构是“冻结的”,不会随底层表的结构变化自动更新。
- 视图的列名可显式指定,数量必须与 SELECT 查询返回列一致,且必须唯一。
3. 基本约束与限制
- 视图的 SELECT 查询不能引用系统变量、用户变量、程序参数或临时表,也不能为 TEMPORARY 视图。
- 基表或视图必须存在;被引用对象若被删除,使用视图则报错。
- 视图与基础表不能同名。
4. ALGORITHM 子句作用
ALGORITHM决定 MySQL 如何处理视图(MERGE:合并直达底层表,TEMPTABLE:临时表,UNDEFINED:系统自行决定)。- 正确的 ALGORITHM 有助于视图的可更新性,如
MERGE可使简单视图可 UPDATE/DELETE。
5. 权限体系与安全
- 创建视图需有 CREATE VIEW 权限;对 SELECT 的每列需有访问权限。
- 查询视图时根据 SQL SECURITY 决定是检查 DEFINER 用户还是调用者(INVOKER)权限。
- DEFINER 是视图创建者(默认),可指定为任意帐号;SQL SECURITY 支持 DEFINER 或 INVOKER。
6. 视图的可更新性
- 一些视图是可更新的(如一对一简单映射),可通过 UPDATE/DELETE/INSERT 操作底层表。
- 某些结构导致不可更新(如有聚合、UNION、DISTINCT、多表联查等)。
- 设置 ALGORITHM=MERGE 并保持简单映射,有助于视图具备可更新性。
7. 视图中 WITH CHECK OPTION 用法
WITH CHECK OPTION确保插入或更新的数据行符合视图定义的 WHERE 条件。LOCAL只检查当前视图,CASCADED同时检查所有相关视图的限制。
8. 视图权限检查流程
- 定义视图时需有对象权限,引用视图时也需有实际权限。
- 若涉及存储过程、函数等,还会根据安全上下文层层校验权限。
核心知识点总结:
- 创建视图时可用多种选项影响更新能力与安全性,特别是 ALGORITHM 属性,直接关联视图可更新性。
- 权限和安全由 DEFINER 与 SQL SECURITY 决定,调用方和定义方权限是不同的视图访问安全模型。
Q4
英文原文
Which three features are included in a Starter Configuration?
A. Configuration of Oracle Cloud Applications
B. Customer production data
C. Artificial Intelligence capabilities
D. Sample master data and transaction data
E. Customization of standard features
中文翻译题目和选项
在“起始配置(Starter Configuration)”中包含以下哪三项功能?
A. Oracle Cloud 应用的配置
B. 客户生产数据
C. 人工智能能力
D. 示例主数据和事务数据
E. 标准功能的定制
选项解释
-
A. Oracle Cloud 应用的配置
Oracle 云应用的初始配置,常见于起始套件中,便于测试和演示。(正确答案) -
B. 客户生产数据
实际业务环境的生产数据通常不会包含在 Starter 配置中,主要是演示和测试用数据。 -
C. 人工智能能力
一般 Starter 配置不会包含高级 AI 能力,此为企业后续扩展需求。 -
D. 示例主数据和事务数据
Starter 配置会包含样例主数据(如客户、供应商等)和业务数据,供测试和了解流程用。(正确答案) -
E. 标准功能的定制
标准功能可根据不同业务基本定制,这在 Starter 配置中是支持的。(正确答案)
正确答案
A. Configuration of Oracle Cloud Applications
D. Sample master data and transaction data
E. Customization of standard features
知识点总结
- Starter Configuration(起始/快速配置)通常用于产品试用、演示或上手体验,侧重于简单配置、基础演示数据和基本功能的定制。
- 不会包含敏感的客户生产数据或复杂的 AI 高级特性。
- 主要目的是帮助企业快速了解系统的基本操作和主要流程。
Q5
英文原文
Which two are true of Stored Routines?
A. Cursors are only for updating records, not retrieving records.
B. Handlers must be declared before cursors.
C. Cursors must be opened before being accessed.
D. Variables must be declared before cursors.
E. Handlers must be declared before conditions.
F. Prepared statements must be declared before conditions.
中文翻译题目和选项
下列关于存储过程(Stored Routines),哪两项是正确的?
A. 游标只能用于更新记录,不能用于查询记录。
B. 异常处理程序(handler)必须先于游标声明。
C. 游标在被访问前必须先打开(open)。
D. 变量必须在游标之前声明。
E. 异常处理程序必须在条件之前声明。
F. 预处理语句必须在条件之前声明。
选项解析
- A. 错误。游标主要用于从查询结果中逐行读取数据,不仅可用于更新。
- B. 错误。处理程序通常是在游标和变量都声明后声明的。
- C. 正确。游标必须先OPEN,才能FETCH或使用。
- D. 正确。在MySQL存储例程中,变量必须先于游标声明,否则声明顺序会报错。
- E. 错误。通常先声明条件,再声明handler。
- F. 错误。声明顺序与prepared statements无关。
正确答案
C. Cursors must be opened before being accessed.
D. Variables must be declared before cursors.
知识点总结
- 游标(Cursor) 用于结果集遍历,在存储过程中 OPEN 之后才能 FETCH 数据。
- 变量声明顺序:在 MySQL 例程中,变量须先于游标声明,否则语法错误。
- Handler、条件等声明顺序有规范,但与游标和变量的关系如上所述为关键。
1. 存储过程(Stored Routines)
- 定义:存储在数据库中的一组SQL语句集合,可以像函数一样按需调用,常见类型有存储过程(Procedure)和存储函数(Function)。
- 用途:复用业务逻辑、简化客户端代码、提高数据操作安全性和效率。
- 特点:支持参数传递、条件分支、循环、异常处理。
- MySQL 存储过程/函数里声明的顺序有严格要求:
变量声明(DECLARE ...)
条件声明(DECLARE ... CONDITION)
游标声明(DECLARE ... CURSOR)
处理器声明(DECLARE ... HANDLER)
2. 游标(Cursor)
- 定义:一种在存储过程或函数中逐行处理SQL查询结果集的机制。
- 用途:用于需要对查询出的多条数据逐条处理,如批量更新、逐条操作。
- 重要点:
- 必须先声明(DECLARE)游标,并基于SELECT语句。
- 使用前需打开游标(OPEN)。
- 用FETCH语句逐条读取数据。
- 用完后必须关闭(CLOSE)游标。
- (游标声明必须位于变量和条件声明之后,异常处理声明之前。)Cursor declarations must appear before handler declarations and after variable and condition declarations.
3. 异常处理程序(Handler)
- 定义:在存储过程或函数中用于捕获和处理异常或特定条件(如NOT FOUND、SQLEXCEPTION等)的机制。
- 用途:防止SQL执行过程中出现错误导致过程终止,优雅地处理数据库异常。
- 重要点:
- 使用DECLARE语句声明(如 DECLARE CONTINUE HANDLER FOR NOT FOUND SET ...)。
- 通常在游标和变量声明后声明handler。
- 支持CONTINUE、EXIT等行为,决定异常发生时的控制流程。
4. Prepared statements(预处理语句)
- 定义:将SQL语句预先编译、参数化的机制,可在多次执行、仅替换参数时提升性能和安全性(防止SQL注入)。
- 用途:适用于多次重复执行的SQL操作,并可动态绑定参数。
- 重要点:
- 用PREPARE、EXECUTE和DEALLOCATE PREPARE语句实现。
- 常用于应用程序层,同时MySQL存储过程也支持。
- 提高SQL执行效率,并增强安全性(参数不会被当做SQL代码)。
总结对比
- 存储过程是流程载体,实现数据库端控制逻辑。
- 游标是遍历多行结果的“指针”,主要用在存储过程/函数中。
- 异常处理(handler)用于处理SQL过程中的错误或特殊情况,提升健壮性。
- Prepared statements专注于安全、高效执行重复SQL,减少SQL注入风险。
Q6
CREATE TABLE `film_text` (
`film_id` smallint NOT NULL,
`title` varchar(255) NOT NULL,
`description` text,
PRIMARY KEY (`film_id`),
KEY `desc_idx` (`description`(500)),
FULLTEXT KEY `description` (`description`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
film_text table contains millions of rows.
Which two queries can use an index during execution?
A.
SELECT *
FROM film_text
WHERE MATCH(title, description)
AGAINST ('Insightful Drama');
B.
SELECT *
FROM film_text
WHERE description RLIKE 'Insightful drama*';
C.
SELECT *
FROM film_text
WHERE MATCH(description) AGAINST('Insightful Drama');
D.
SELECT *
FROM film_text
WHERE description LIKE 'Insightful drama%';
E.
SELECT *
FROM film_text
WHERE description LIKE '%Insightful drama%';
中文翻译与解析
表 film_text 包含百万级数据,建有 description 字段的普通索引和 FULLTEXT 索引。问题是:哪些查询在执行时能使用索引?(多选两项)
选项含义逐项解释
- A. 使用 MATCH(title, description) AGAINST()
- 使用全文索引匹配 title 和 description 字段。
- B. 使用 description RLIKE 'Insightful drama*'
- 正则表达式模式匹配 description 字段。
- C. 使用 MATCH(description) AGAINST()
- 对 description 字段走全文索引查询。
- D. 使用 description LIKE 'Insightful drama%'
- description 以 'Insightful drama' 开头,% 结尾的普通 LIKE 查询。
- E. 使用 description LIKE '%Insightful drama%'
- description 任意位置出现 'Insightful drama',前后都有%。
正确答案
CD
- A (MATCH(title, description) AGAINST()):title 列未添加全文索引,无法用 FULLTEXT 索引。
- C (MATCH(description) AGAINST()):能用 FULLTEXT 索引,仅针对 description 字段。
- B(RLIKE)和 E(LIKE 前缀通配符 %Insightful drama%)无法走索引,只能全表扫描。
- ** D(LIKE 'xxx%')**可以用普通索引
相关知识点总结
- FULLTEXT 索引:仅支持 MATCH ... AGAINST 语法,能高效处理大文本检索。
- 普通索引 & LIKE 语法:
LIKE 'abc%'有机会用到索引(有普通索引)。LIKE '%abc%'无法用索引,需全表扫描。
- RLIKE(正则) 查询通常不会使用索引。
- MATCH ... AGAINST 是全文索引的唯一用法,适用于大体量文本字段。
MySQL 14.9 全文检索函数
https://dev.mysql.com/doc/refman/8.0/en/fulltext-search.html#function_match
核心内容要点
-
FULLTEXT 索引定义
- MySQL 支持全文索引(FULLTEXT),适用于 InnoDB 和 MyISAM 表。
- 仅适用于 CHAR、VARCHAR 或 TEXT 类型列。
- 可在建表时直接定义,也可通过 ALTER TABLE/CREATE INDEX 后期添加。
- 建议先插入数据再加索引,这样更高效。
- MySQL 自带 ngram parser 支持中日朝文本,也支持 MeCab 插件(针对日文)。
-
全文检索语法 MATCH ... AGAINST
- 通过
MATCH(列1,列2,...) AGAINST (expr [search_modifier])进行全文检索。 - expr(表达式)为搜索字符串,且必须在查询期间为常量(不能用列作为表达式参数)。
- 支持多种 search_modifier:
IN NATURAL LANGUAGE MODE(自然语言模式,默认,支持停用词)IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION(自然语言模式 + 查询扩展)IN BOOLEAN MODE(布尔模式,支持特殊操作符,要求/排除/权重等)WITH QUERY EXPANSION(查询扩展)
- 通过
-
全文检索类型
- 自然语言检索(Natural Language Search):
- 将搜索词组解释为自然短语,不支持布尔操作符(除双引号外)。
- 支持停用词。
- 默认模式。
- 布尔检索(Boolean Full-Text Search):
- 使用布尔操作符(如 + - "等)。
- 可自定义检索条件权重,指定必须包含/必须排除。
- 查询扩展(Query Expansion):
- 查询先做自然语言检索,然后拓展关键词再次检索结果。
- 自然语言检索(Natural Language Search):
-
索引的使用约束
- FULLTEXT 索引唯一支持 MATCH ... AGAINST 语句。
- 不能和 GROUP BY ... WITH ROLLUP 一起在某些位置使用(如 SELECT、GROUP BY、HAVING、ORDER BY)。
- WHERE 可用 MATCH() 与 rollup 字段。
-
性能及限制
- 只有
LIKE 'xxx%'形式能用普通索引。 LIKE '%xxx%'任何位置都不能走索引。- RLIKE/REGEXP 亦无法用索引,都是全表扫描。
- FULLTEXT 索引检索高效,适合大文本数据。
- MySQL 支持对 FULLTEXT 检索做参数细致调整(如分词器,停用词表,索引优化等)。
- 只有
关键 SQL 示例
- 创建 FULLTEXT 索引:
CREATE TABLE t (
content TEXT,
FULLTEXT(content)
);
SELECT * FROM t WHERE MATCH(content) AGAINST('mysql search');
SELECT * FROM t WHERE MATCH(content) AGAINST('search*' IN BOOLEAN MODE);
SELECT * FROM t WHERE MATCH(content) AGAINST('mysql search' WITH QUERY EXPANSION);
适用场景总结
- 大字段文本内容高效检索:用全文索引+MATCH ... AGAINST 实现百万/千万级文本的高性能搜词。
- LIKE 'xxx%' 查询普通索引适用:仅适用于普通索引字段。
- 避免使用正则和通配符类全匹配(如 LIKE '%xxx%'、RLIKE),因普遍无法使用索引。
Q7
英文原题
What is the primary purpose of Oracle Cloud Success Navigator?
A. To provision Oracle Cloud Applications
B. To offer a platform for reporting bugs and issues with Oracle Cloud products
C. To provide a best practice framework with tools and guidance that support organizations in their Cloud journey
D. To automate the migration of on-premises solutions to Oracle Cloud
中文翻译与解析
Oracle Cloud Success Navigator 的主要目的是什么?
A. 提供 Oracle Cloud 应用的配置
B. 提供一个用于报告 Oracle Cloud 产品问题和 bug 的平台
C. 提供最佳实践框架,并配备支持企业云之旅的工具和指导
D. 自动化本地解决方案向 Oracle Cloud 的迁移
选项逐项解释
- A: 只是应用部署,与 Success Navigator 的目标不符。
- B: 是问题反馈平台,并非 Success Navigator 的主要功能。
- C: 提供最佳实践、工具和指导,帮助企业顺利走好上云之路。这正是 Success Navigator 的定位。(正确答案)
- D: 关注迁移工作流,但 Success Navigator 涵盖更广泛的云旅程指导,而不只是迁移。
正确答案
C. To provide a best practice framework with tools and guidance that support organizations in their Cloud journey
知识点总结
- Oracle Cloud Success Navigator 主要作用是为企业提供上云过程中的方法论、工具支持和指导建议,帮助企业采用云、优化云架构、实现业务目标。
- 不是产品配置工具,也不是迁移自动化或错误报告平台。
- 针对云旅程全生命周期的最佳实践覆盖。
Q8
英文原题
Examine these statements which execute successfully:
CREATE TABLE t(id INT PRIMARY KEY);
INSERT INTO t(id) VALUES(1);
Now, examine these statements executed successfully by two concurrent sessions:
Session 1> SET autocommit=0;
Session 1> UPDATE t SET id=id+1;
Session 2> SET transaction_isolation="READ-UNCOMMITTED";
Session 2> BEGIN;
Session 2> UPDATE t SET id=id+1;
Session 1> ROLLBACK;
Session 2> COMMIT;
Which two are true?
A. The current value of id is equal to 1.
B. Session 1 does not start a transaction.
C. Session 2 increments the committed value of id by 1.
D. The current value of id is equal to 3.
E. ROLLBACK releases the row lock taken by the UPDATE statement in Session 1.
中文翻译与解析
已成功执行如下语句:
CREATE TABLE t(id INT PRIMARY KEY);
INSERT INTO t(id) VALUES(1);
然后,有两个会话并发执行以下语句:
Session 1> SET autocommit=0;
Session 1> UPDATE t SET id=id+1;
Session 2> SET transaction_isolation="READ-UNCOMMITTED";
Session 2> BEGIN;
Session 2> UPDATE t SET id=id+1;
Session 1> ROLLBACK;
Session 2> COMMIT;
问:下列哪两项是正确的?
关键操作流程:
- Session 1 设定 autocommit=0,开启“手动提交模式”,随后执行UPDATE将id从1改为2(但未提交)。
- Session 2 设定事务隔离级别为 READ-UNCOMMITTED(可脏读),开启事务后再对id加1,这时它能读到Session 1尚未提交的“临时”id=2,于是再加1变成3,然后Session 2提交。
- Session 1 回滚,其之前的修改作废,也释放了事务期间持有的锁。
一步步分析:
- Session 1 的UPDATE效果因为ROLLBACK而撤销,id回到1。
- Session 2因能读到“未提交”的id=2,自己的UPDATE实际上变成了id=3,并最终提交。
- 最后表中的id实际为2(因为Session 2加1的对象是Session 1未提交的id=2,而Session 1回滚,最终只Session 2的加1生效)。
选项解释
-
A. 当前 id 值等于 1。
- 错误。先被更新+1,后 Session 2 再加1,且Session 2最后 commit,实际值+1次。
-
B. Session 1 未开启事务。
- 错误。
SET autocommit=0隐式开启事务,UPDATE 自动走入事务。
- 错误。
-
C. Session 2 使已提交的id值增加了1。
- 正确!Session 1回滚,实际没更改。Session 2读取“未提交”状态下的数据并将其+1,提交后id值确实只比初始值+1。
-
D. 当前 id 值等于 3。
- 错误。因为Session 1回滚,id只+1,结果是2。
-
E. ROLLBACK 释放了 Session 1 的 UPDATE 所持有的行锁。
- 正确!回滚会释放所有锁。
正确答案
C. Session 2 increments the committed value of id by 1.
E. ROLLBACK releases the row lock taken by the UPDATE statement in Session 1.
相关知识总结
SET autocommit=0:后续UPDATE语句会隐式开启事务,直到COMMIT/ROLLBACK- ROLLBACK/COMMIT:会释放行锁和各种资源
- READ-UNCOMMITTED:事务能读到其他会话未提交的数据(脏读)
- 多会话并发下,操作影响需要结合提交/回滚生效情况分析
Q9
You need to accurately store these values in a column:
12325.1251717337
6212
551.124111
Which data type will store the values without loss of precision?
A. DOUBLE
B. DECIMAL
C. FLOAT
D. MEDIUMINT
中文翻译与题目解释
你需要在一个列中准确存储如下数值(含多位小数与整数),要求不丢失精度:
- 12325.1251717337
- 6212
- 551.124111
下列哪种数据类型能无损精确存储上述值?
选项含义与解释
-
A. DOUBLE
- 双精度浮点型,可存储大范围小数,但存在二进制转存误差,不保证10进制完全精确,常用于科学计算、非严格财务等。
-
B. DECIMAL
- 高精度定点型,以字符串形式存储10进制数,可保证小数精确,用于财务金额等需要保证精度场景。(正确答案)
-
C. FLOAT
- 单精度浮点型,容易丢失小数精度,仅适合不要求精确计算的场景。
-
D. MEDIUMINT
- 中等大小整数型,不能存储小数。
正确答案
B. DECIMAL
相关知识点总结
- DECIMAL 用于要求高精度的场景(如财务、统计等),存储和运算均为十进制,不因二进制舍入而精度损失。
- FLOAT/DOUBLE 采用二进制浮点,可能导致插入/运算或读取时出现细微误差,尤其小数多位时较明显。
- 整型(如 MEDIUMINT)只能保存整数,不能满足小数型数据无损保存的需求。
- 设计表结构时,凡涉及金额、统计、定量分析,建议优先使用 DECIMAL。
Q10
英文原题
You require only the owner and type fields for documents whose owner is Sven, that exist in the pets collection.
Which two will do this?
A. db.pets.find("owner = :owner").fields("owner","type").bind("owner", "Sven")
B. db.pets.select(["owner","type"]).where("owner = :name").bind("name", "Sven")
C. db.pets.find("owner = 'Sven'").fields("owner","type")
D. db.pets.select(["owner","type"]).where("owner = 'Sven'")
E. db.pets.find("owner = Sven")
中文翻译与题目解释
你只需要 pets 集合中 owner 为 Sven 的文档的 owner 和 type 字段。
哪两种写法能实现这个需求?
选项逐项解析
-
A. db.pets.find("owner = :owner").fields("owner","type").bind("owner", "Sven")
- 查找时用参数名
:owner,后用.bind绑定,返回指定字段,完全正确。
- 查找时用参数名
-
B. db.pets.select(["owner","type"]).where("owner = :name").bind("name", "Sven")
- key与bind参数名不一致,语法不规范,
select用法用于table而不是documents 。
- key与bind参数名不一致,语法不规范,
-
C. db.pets.find("owner = 'Sven'").fields("owner","type")
- 直接查找指定owner并返回owner,type字段,完全正确。
-
D. db.pets.select(["owner","type"]).where("owner = 'Sven'")
select用法用于table而不是documents 。
-
E. db.pets.find("owner = Sven")
- owner等于变量Sven,未加引号且参数未绑定,错误。
正确答案
A. db.pets.find("owner = :owner").fields("owner","type").bind("owner", "Sven")
C. db.pets.find("owner = 'Sven'").fields("owner","type")
知识点总结
- 查询API中
.find结合.fields可筛选部分字段返回,效率更高。 - 参数绑定(
.bind)提升安全性,防止注入。 - 查询字符串条件直接用单引号表示常量(如
'Sven')。 - 错误示例中常见问题:参数名/变量未匹配、API风格混淆、未指定字段过滤。
3.1 CRUD 操作概览
https://dev.mysql.com/doc/x-devapi-userguide-shell-js/en/crud-operations-overview.html
1. 概览
- 所有 CRUD(增删改查)操作都以方法形式实现,并且作用于 Schema 对象。
- Schema 对象包括两类:Collection(集合)对象和 Table(表)对象。
- Collection 对象负责存储文档(Document)类型数据。
- Table 对象负责存储关系型(行)数据。
2. CRUD 操作对照表
| 操作 | 文档(NoSQL,Collection) | 关系型(Relational,Table) |
|---|---|---|
| 创建 | Collection.add() | Table.insert() |
| 查询 | Collection.find() | Table.select() |
| 更新 | Collection.modify() | Table.update() |
| 删除 | Collection.remove() | Table.delete() |
3. 要点说明
- Collection(集合)对象的方法用于 NoSQL 文档型数据,如:add、find、modify、remove。
- Table(表)对象则用标准 SQL 式方法,如:insert、select、update、delete。
- 这些方法和 Schema 绑定,可以灵活实现不同场景的数据操作。
4. 相关章节引用
- 创建:查看 4.3.1 节,Collection.add()
- 查询:查看 4.3.2 节,Collection.find()
- 更新:查看 4.3.3 节,Collection.modify()
- 删除:查看 4.3.4 节,Collection.remove()
简明总结:
- 在 MySQL Shell X DevAPI 下,Collection 用 add/find/modify/remove 操作文档型数据,Table 用 insert/select/update/delete 操作关系型数据。每种对象都提供了相应的 CRUD 方法,便于开发者调用。
Q11
英文原题
Which two statements are true regarding parameter binding in CRUD operations?
A. Binding can help avoid SQL injection attacks.
B. Binding reduces the overhead of aggregating large data sets.
C. Binding improves the efficiency of parallel processing and generation of large data sets.
D. Binding is required to retrieve data from multiple tables.
E. Binding enables placeholders in statements which are executed with applied values.
中文翻译与题目解释
关于 CRUD 操作中的参数绑定,下列哪两项陈述是正确的?
选项逐项解析
-
A. 参数绑定可以帮助防止 SQL 注入攻击。
- 正确。参数绑定(预编译/占位符)可防止注入攻击,保护数据库安全。
-
B. 参数绑定能减少大数据集聚合的开销。
- 错误。聚合的效率与参数绑定无关。
-
C. 参数绑定提高大数据集并行处理和生成效率。
- 错误。并行处理与参数绑定无必然关系。
-
D. 检索多表数据时必须用参数绑定。
- 错误。多表查询是否用绑定无明确要求。
-
E. “绑定”功能使得语句中的占位符能够被实际的参数值替换后执行。
- 正确。参数绑定机制允许语句用占位符,后续实际填充值再执行。
正确答案
A. Binding can help avoid SQL injection attacks.
E. Binding enables placeholders in statements which are executed with applied values.
知识点总结
- 参数绑定/预编译,最核心作用:
- 防止 SQL 注入(安全层面)
- 提供参数化查询、支持占位符(灵活、规范)
- 聚合、多表/多线程等与参数绑定无直接关系。
Q12
英文原题
Examine this statement which you executed and its output:
SELECT ename, esalary, ebonus
FROM employees;
| ename | esalary | ebonus |
|-----------------------|------------|------------|
| Duangkaew Piveteau | 158526.000 | 23109.0000 |
| Mary Sluis | 154070.000 | 7183.0000 |
| Patricio Bridgland | 94771.000 | 23578.0000 |
| Eberhardt Terkki | 91648.000 | 8346.0000 |
| Berni Genin | 113982.000 | 27998.0000 |
| Guoxiang Nooteboom | 94698.000 | 26954.0000 |
| Kazuhito Cappelletti | 71703.000 | 20777.0000 |
| Cristinel Bouloucos | 154424.000 | 22021.0000 |
| Kazuhide Peha | 77013.000 | NULL |
| Lillian Haddadi | 141791.000 | NULL |
| Mayuko Warwick | 137916.000 | NULL |
You must return the ename and the sum of the esalary and ebonus as etotal_pay for all employees.
Which will return the desired result?
A. SELECT ename, (esalary + ebonus) AS etotal_pay FROM employees WHERE ebonus IS NOT NULL;
B. SELECT ename, SUM(esalary + ebonus) AS etotal_pay FROM employees GROUP BY ename;
C. SELECT ename, SUM(esalary + ebonus) AS etotal_pay FROM employees;
D. SELECT ename, (esalary + COALESCE(ebonus,0.0000)) AS etotal_pay FROM employees;
E. SELECT ename, (esalary + ebonus) AS etotal_pay FROM employees;
中文翻译和解析
题目描述:
你执行了一个 SQL 查询,展示了员工的工资(esalary)和奖金(ebonus)。有些 ebonus 字段为 NULL。
你需要查询全部员工,返回姓名(ename)及其工资与奖金之和(etotal_pay)。
SELECT ename, esalary, ebonus
FROM employees;
| ename | esalary | ebonus |
|-----------------------|------------|------------|
| Duangkaew Piveteau | 158526.000 | 23109.0000 |
| Mary Sluis | 154070.000 | 7183.0000 |
| Patricio Bridgland | 94771.000 | 23578.0000 |
| Eberhardt Terkki | 91648.000 | 8346.0000 |
| Berni Genin | 113982.000 | 27998.0000 |
| Guoxiang Nooteboom | 94698.000 | 26954.0000 |
| Kazuhito Cappelletti | 71703.000 | 20777.0000 |
| Cristinel Bouloucos | 154424.000 | 22021.0000 |
| Kazuhide Peha | 77013.000 | NULL |
| Lillian Haddadi | 141791.000 | NULL |
| Mayuko Warwick | 137916.000 | NULL |
要点:
- ebonus 可能为 NULL,直接相加会导致结果为 NULL。
- 希望每位员工都返回数据,所以不能只筛选 ebonus 非空。
选项解析
- A: 只返回 ebonus 不为 NULL 的员工,不满足“所有员工”。
- B: 汇总了每个人的工资+奖金的总和,且 SUM 函数对每人求合,语意不对。
- C: 直接全表汇总一行总和,无法实现每位员工单独返回。
- D:
COALESCE(ebonus,0)讲 NULL 奖金当作0,相加不会丢失任何员工,且所有员工都能有 etotal_pay,正确答案。 - E: 直接加法,对于 NULL 结果仍是 NULL,不满足要求。
正确答案:D
相关知识点总结
- NULL 的计算特点:任何值与 NULL 做加法结果都是 NULL。
- COALESCE(expr, 0) 的作用:若 expr 为 NULL,则返回0,实现“把空奖金当0”。
- SQL 查询返回所有员工:应避免 WHERE ebonus IS NOT NULL 过滤掉部分记录。
- 别名(AS):SQL 可用 AS 给返回列起新名字。
结论:数据有 NULL 字段时,用 COALESCE 或 NVL 等函数替换为0,是数据库查询的常见技巧。
Q13
英文原文
There is a page with an interactive grid region based on this statement:
SELECT
EMPNO,
ENAME,
COMM
from EMP;
In the Interactive Grid attributes, in the Edit group, the Enabled switch is turned off.
Which two actions must be performed to make an employee's commission editable in the grid?
A. In the Interactive Grid attributes, in the Edit group, turn on the Enabled switch.
B. Ensure that the Primary Key switch is turned on for the EMPNO column.
C. Set EMPNO, ENAME to Display Only.
D. In the Interactive Grid attributes, select COMM for Allowed Row Operations Column.
正确答案
A. In the Interactive Grid attributes, in the Edit group, turn on the Enabled switch.
B. Ensure that the Primary Key switch is turned on for the EMPNO column.
中文题目解析
有一个页面,基于如下 SQL 语句创建了交互式网格区域:
SELECT
EMPNO,
ENAME,
COMM
from EMP;
在交互式网格(Interactive Grid)属性中,编辑(Edit)组里的 Enabled 开关被关闭。
为了使员工的佣金(commission,COMM 字段)可以在网格中编辑,必须执行哪两个操作?
A. 在交互式网格属性的编辑组里,打开 Enabled 开关。
B. 确保 EMPNO 列已打开主键(Primary Key)开关。
C. 将 EMPNO、ENAME 设为仅显示(Display Only)。
D. 在交互式网格属性中,选择 COMM 作为允许行操作的列(Allowed Row Operations Column)。
选项解释
- A. 在交互式网格属性的编辑组里,打开 Enabled 开关。
- 解释:如果没有启用编辑,则任何字段都不可编辑。需开启 Enabled 使编辑功能生效。(正确)
- B. 确保 EMPNO 列已打开主键(Primary Key)开关。
- 解释:交互式网格要求表必须有主键用于识别每一行,否则无法正确提交数据更改。(正确)
- C. 将 EMPNO、ENAME 设为仅显示
- 解释:这和 COMM 字段的编辑权限无关,且设为仅显示反而不能编辑 EMPNO、ENAME 字段,对 COMM 没影响。
- D. 在交互式网格属性中,选择 COMM 作为允许行操作的列
- 解释:Allowed Row Operations 通常用于授权某些增删行的操作,但 COMM 字段能否被编辑主要还是依赖 Enabled 开关和主键设置。
正确答案
A、B
相关知识点总结
- Oracle APEX 交互式网格(Interactive Grid)中想要编辑数据,必须启用 "Edit" 的 "Enabled" 属性。
- 必须有一列设为 "Primary Key",这样网格才能唯一标识并提交每一行的变更(典型为 EMPNO 主键)。
- 仅仅将其他字段设为 Display Only,并不影响目标编辑字段的设置。
- Allowed Row Operations 通常与增删行有关,对字段直接可编辑性的影响有限。
Q14
英文原题
- Examine this statement which has executed successfully:
CREATE TABLE `film_text` (
`film_id` smallint NOT NULL,
`title` varchar(255) NOT NULL,
`description` text,
PRIMARY KEY (`film_id`),
FULLTEXT KEY `description_idx` (`description`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
film_text contains millions of rows.
Now, examine this statement:
SELECT title
FROM film_text
WHERE description RLIKE "Scientist*";
Which statement is true?
A. Execution performance can be improved by using LIKE instead of RLIKE.
B. No index will improve statement performance.
C. Execution performance can be improved by adding an index on column description.
D. The statement takes advantage of index description_idx.
E. Execution performance can be improved by using a composite index with column description as the leftmost prefix.
正确答案:B. No index will improve statement performance.
中文翻译及解析
题目翻译
请检查已成功执行的下述语句:
CREATE TABLE `film_text` (
`film_id` smallint NOT NULL,
`title` varchar(255) NOT NULL,
`description` text,
PRIMARY KEY (`film_id`),
FULLTEXT KEY `description_idx` (`description`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
film_text 表包含了数百万行。
接下来,请分析这条查询语句:
SELECT title
FROM film_text
WHERE description RLIKE "Scientist*";
下列哪项说法是正确的?
A. 用 LIKE 替换 RLIKE 能提高执行性能。
B. 没有任何索引能提升该语句的执行性能。
C. 在 description 列上添加索引能提升执行性能。
D. 该查询用上了 description_idx 索引。
E. 用 description 作为最左前缀组成复合索引能提升执行性能。
选项分析
-
A. 用 LIKE 替换 RLIKE 能提高执行性能。
LIKE 和 RLIKE (正则表达式匹配)都不能很好地利用普通或FULLTEXT索引,特别是在复杂或通配模式下。 -
B. 没有任何索引能提升该语句的执行性能。
这是正确答案。RLIKE(正则表达式匹配)通常不会用到任何索引,无论是普通索引还是FULLTEXT索引,因此扫描表是不可避免的。 -
C. 在 description 列上添加索引能提升执行性能。
普通索引无法加速正则搜索,FULLTEXT 索引只能在 MATCH ... AGAINST 时用到,对 RLIKE 没帮助。 -
D. 该查询用上了 description_idx 索引。
RLIKE 用不到 FULLTEXT 索引。 -
E. 用 description 作为最左前缀组成复合索引能提升执行性能。
复合索引也无法提升基于正则表达式的模糊查询性能。
知识点总结
- RLIKE/REGEXP 查询:MySQL 的 RLIKE/REGEXP 正则表达式匹配条件通常不会用到任何索引(包括常规索引与 FULLTEXT 索引),会导致全表扫描。
- LIKE 与 RLIKE 区别:LIKE 有时可以用到索引(例如 LIKE 'xxx%'),但复杂的 LIKE 和正则一般都不能利用索引。
- FULLTEXT 索引 只对 MATCH ... AGAINST 查询有效,不适用于 RLIKE 或 LIKE。
- 高效文本搜索 应优先考虑 FULLTEXT 与特定查询方式,不宜用正则或复杂通配。
章节 14.8.2 正则表达式函数和操作符
http://dev.mysql.com/doc/refman/8.0/en/regexp.html#operator_regexp
正则表达式操作符和函数说明
相关函数与操作符如下:
| 名称 | 作用描述 |
|---|---|
| NOT REGEXP | REGEXP 的否定匹配 |
| REGEXP/RLIKE | 字符串是否匹配正则表达式 |
| REGEXP_LIKE() | 字符串是否匹配正则表达式 |
| REGEXP_INSTR() | 匹配的子字符串的起始索引 |
| REGEXP_REPLACE() | 替换所有匹配正则的子串 |
| REGEXP_SUBSTR() | 返回第一个匹配的子串 |
REGEXP和RLIKE是同义词,功能等同于REGEXP_LIKE()。- 正则表达式功能由 ICU (国际化组件库)提供,支持 Unicode,多字节安全。MySQL 8.0.4 前使用 Spencer 实现,不支持多字节。
兼容性与注意事项
MySQL 8.0.4 及以上对正则全面升级为ICU实现,支持全Unicode和更丰富语法。
4字节字符如Emoji的索引在处理时需注意起始偏移。
ICU和老的Spencer实现部分边界符定义和转义方式不同,如单词边界用\b、对括号和中括号的转义格式。
大部分常用正则规则、字符类(如[a-z]、[[:digit:]]等)在新老实现中表现一致,复杂情况可查阅ICU手册。
二进制字符串作为正则参数,在MySQL 8.0.22及之后会拒绝执行,需避免。
使用正则时需注意转义符(如匹配“+”实际需写成'1\+2')。
性能提示
和普通LIKE索引不同,对于RLIKE/REGEXP操作符,MySQL通常无法利用普通或FULLTEXT索引,正则检索会导致全表扫描。
fulltext索引适用于MATCH ... AGAINST,不适合正则表达式查询。
复杂正则、含特殊字符类时,执行更慢。
若有性能瓶颈,尽量用更简单的LIKE、前缀匹配或专用全文检索函数代替。
Q15
英文原题
Examine the output:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "0.45"
},
"table": {
"table_name": "country",
"access_type": "ALL",
"rows_examined_per_scan": 2,
"rows_produced_per_join": 2,
"filtered": "100.00",
"cost_info": {
"read_cost": "0.25",
"eval_cost": "0.20",
"prefix_cost": "0.45",
"data_read_per_join": "224"
},
"used_columns": [
"code",
"Name",
"Continent",
"LanguageId"
]
}
}
}
Which EXPLAIN command will obtain the output?
A. EXPLAIN PARTITIONS
B. EXPLAIN ANALYZE
C. EXPLAIN FORMAT=TRADITIONAL
D. EXPLAIN FORMAT=JSON
E. EXPLAIN FORMAT=TREE
答案:D. EXPLAIN FORMAT=JSON
中文翻译与解析
题目翻译
- 请检查下述输出内容:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "0.45"
},
"table": {
"table_name": "country",
"access_type": "ALL",
"rows_examined_per_scan": 2,
"rows_produced_per_join": 2,
"filtered": "100.00",
"cost_info": {
"read_cost": "0.25",
"eval_cost": "0.20",
"prefix_cost": "0.45",
"data_read_per_join": "224"
},
"used_columns": [
"code",
"Name",
"Continent",
"LanguageId"
]
}
}
}
问:下列哪一个 EXPLAIN 命令可以得到上面的输出格式?
A. EXPLAIN PARTITIONS
B. EXPLAIN ANALYZE
C. EXPLAIN FORMAT=TRADITIONAL
D. EXPLAIN FORMAT=JSON
E. EXPLAIN FORMAT=TREE
选项解析
-
A. EXPLAIN PARTITIONS
- 展示分区相关信息,不输出 JSON 格式内容。
-
B. EXPLAIN ANALYZE
- 用于显示实际运行时执行计划和耗时等信息,输出是详细文本,不是 JSON 结构。
-
C. EXPLAIN FORMAT=TRADITIONAL
- 默认经典的表格文本格式输出(如 id, select_type, table 等字段),并不输出 JSON。
-
D. EXPLAIN FORMAT=JSON
- 正确答案。该命令将执行计划以结构化 JSON 格式展现,如题干所示输出。
-
E. EXPLAIN FORMAT=TREE
- 输出树形结构化的执行计划,用于可读性,但不是 JSON。
相关知识点总结
- EXPLAIN 命令用于显示 SQL 查询的执行计划,有助于SQL优化。
- FORMAT=JSON 让 EXPLAIN 输出更加详细、结构化,便于程序分析和自动化处理。
- 适用于复杂查询分析、自动化工具对执行计划的解析和比对。
- MySQL 5.6+ 支持
FORMAT=JSON,高版本推荐使用以获取最全面的执行细节。
Q16
英文原题
Which command displays timing information for a query?
A. EXPLAIN
B. EXPLAIN FORMAT=TREE
C. EXPLAIN ANALYZE
D. EXPLAIN FORMAT=JSON
正确答案:C. EXPLAIN ANALYZE
中文翻译与题目解析
题目翻译
下列哪个命令能显示查询的耗时信息(即执行时间)?
A. EXPLAIN
B. EXPLAIN FORMAT=TREE
C. EXPLAIN ANALYZE
D. EXPLAIN FORMAT=JSON
选项解析
- A. EXPLAIN
- 只输出SQL执行计划,不包含实际耗时等执行信息。
- B. EXPLAIN FORMAT=TREE
- 以树形结构展示执行计划,依然没有具体耗时统计。
- C. EXPLAIN ANALYZE
- 正确答案。 会真正执行SQL,并统计实际的每一步耗时和行数等详细信息,是MySQL优化和诊断查询性能的推荐工具。
- D. EXPLAIN FORMAT=JSON
- 以结构化JSON格式输出执行计划,但输出的是预估代价,不是实际耗时。
知识点总结
EXPLAIN ANALYZE直接运行查询并输出每一步的真实耗时、实际行数,比传统 EXPLAIN 更精确,专用于性能优化和分析。- 其他
EXPLAIN相关命令仅输出执行计划或估算信息,不显示SQL实际执行的耗时。
Q17
英文原题
The meeting table stores meeting schedules with participants from five continents.
The participants' details are stored in another table.
CREATE TABLE meeting (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100),
start_time VARCHAR(20),
duration VARCHAR(20),
PRIMARY KEY (id)
)
You need to adjust the start_time and duration columns for optimal storage.
What datatype changes would achieve this?
A. start_time TIMESTAMP, duration TIMESTAMP
B. start_time DATETIME, duration DATETIME
C. start_time TIMESTAMP, duration TIME
D. start_time DATETIME, duration TIME
E. start_time TIME, duration TIME
正确答案:C. start_time TIMESTAMP, duration TIME
中文翻译与解析
题目翻译
meeting 表存储了涉及五大洲参与者的会议计划。
(参与者详情在另一张表中。)
现在表结构如下:
CREATE TABLE meeting (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100),
start_time VARCHAR(20),
duration VARCHAR(20),
PRIMARY KEY (id)
)
你需要调整 start_time 和 duration 字段的数据类型,以实现最优存储。
以下哪种类型调整可以达到该目标?
A. start_time TIMESTAMP, duration TIMESTAMP
B. start_time DATETIME, duration DATETIME
C. start_time TIMESTAMP, duration TIME
D. start_time DATETIME, duration TIME
E. start_time TIME, duration TIME
选项逐项解析
- A. start_time TIMESTAMP, duration TIMESTAMP
start_time用时间戳格式存储,适合绝对时间。duration存为时间戳并不合适,因为时长不是一个具体时间点而是“经过的时间”。
- B. start_time DATETIME, duration DATETIME
start_time用日期+时间存储没问题,但duration仍然不合适,因为时长不是日期+时间(如2小时,不是某年某月某日2小时)。
- C. start_time TIMESTAMP, duration TIME
start_time用绝对时间表示会议开始,TIMESTAMP自带时区转换,对于国际会议(participants from five continents)来说很合适,duration用TIME类型(如'01:30:00'表示1小时30分钟),很合适。
- D. start_time DATETIME, duration TIME
start_time用DATETIME类型,表示绝对的日期和时间,但是不会自动时区转换,对于国际会议(participants from five continents)来说不太合适,duration用TIME类型,合适。
- E. start_time TIME, duration TIME
start_time用TIME类型,不包含日期(譬如只表示'09:00:00'),不适合表示具体日期的会议。
MySQL 11.1.3 日期与时间字面量
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-literals.html
1. 日期和时间字面量的基本格式
- MySQL 支持多种格式来表示日期和时间数据。可以用引号括起的字符串(如 '2022-01-01')、无分隔符的字符串(如 '20220101'),或直接用数字(如 20220101)。
- 在 MySQL 期望日期的场合,'2015-07-21'、'20150721' 和 20150721 都可以被正确识别为日期。
2. 标准 SQL 与 ODBC 语法
- 标准 SQL 要求日期/时间字面量格式为:
DATE '2022-01-01'TIME '12:34:56'TIMESTAMP '2022-01-01 12:34:56'
- ODBC 类似,写法为:
{ d '2022-01-01' }{ t '12:34:56' }{ ts '2022-01-01 12:34:56' }
- MySQL 识别以上格式,也允许直接不加类型关键字的常用括号字面量。
3. 日期类型值的多样化输入方式
-
日期(DATE)字段:
- 可用字符串形式
'YYYY-MM-DD','YY-MM-DD',以及无分隔符形式'YYYYMMDD'、数字形式YYYYMMDD。 - 分隔符也可使用其他符号(如 /、^、@),但自 MySQL 8.0.29 起,非标准符号会警告。
- 输入数字必须能符合日期的合理结构,否则会存储为
'0000-00-00'。
- 可用字符串形式
-
日期+时间(DATETIME/TIMESTAMP)字段:
- 可用字符串
'YYYY-MM-DD hh:mm:ss',同样支持“宽松”分隔符(警告),也可无分隔符'YYYYMMDDhhmmss'。 - 日期与时间可用空格或
T分隔。 - 时间部分(小时、分、秒、小数秒)支持精确到微秒,须用小数点分隔。
- 可用字符串
4. 两位年份的解释规则
- 输入的年份为
70-99时,自动补为 1970-1999;00-69补为 2000-2069。 - 相关日期字符串或数字长度不足时可能导致解析异常,长数字优先解析前 4 位为年份。
5. 时间类型(TIME)字面量
- 支持的字符串形式:
'D hh:mm:ss'(D 为天数,0~34)'hh:mm:ss'、'hh:mm'、'hhmmss'等多种格式。- 纯数字如 101112 视为
10:11:12。 - 支持小数秒,需加小数点,如
'10:11:12.123456'。
6. 时区支持
- 从 MySQL 8.0.19 起,插入 TIMESTAMP 或 DATETIME 值时支持直接带时区偏移,如
'2020-01-01 10:10:10+05:30'。 - 时区偏移须为 “±hh:mm” 形式。时区名字(如 Asia/Shanghai)不能直接用于字面量。
- 查询时默认不显示偏移部分。
7. 主要注意点与实用建议
- 建议标准化用法:用
-连接年月日,:连接时分秒,避免非标准分隔符和多余空格。 - 插入时,
DATETIME与TIMESTAMP的行为在时区处理上有差异(TIMESTAMP auto-调整,DATETIME 按本地存储)。 - 长度不足的日期/时间字符串,需注意解析规则,避免歧义。
- 时间段/持续时间建议使用
TIME类型字段。 - 建议在插入及查询时使用标准/推荐的字面量格式,提升兼容性和可维护性。
知识点总结:
- MySQL 支持多种日期、时间字面量格式,推荐统一采用标准格式避免警告和歧义;
- 字段类型(如 DATE、DATETIME、TIMESTAMP、TIME)要与业务语义和存储精度对应;
- 关注 MySQL 版本,某些宽松写法在 8.0.29 后已提示废弃。
13.2.2 DATE、DATETIME 与 TIMESTAMP 类型
https://dev.mysql.com/doc/refman/8.0/en/datetime.html
1. 基本用途与取值范围
- DATE:只包含日期,无时间部分。展示/存储格式为
'YYYY-MM-DD'。范围为'1000-01-01'到'9999-12-31'。 - DATETIME:包含日期和时间,格式为
'YYYY-MM-DD hh:mm:ss'。范围为'1000-01-01 00:00:00'到'9999-12-31 23:59:59'。 - TIMESTAMP:也包含日期和时间,范围为
'1970-01-01 00:00:01'UTC 到'2038-01-19 03:14:07'UTC。
2. 小数秒支持
- DATETIME、TIMESTAMP 字段可以包含最多 6 位的秒级小数(微秒),格式为
'YYYY-MM-DD hh:mm:ss[.fraction]'。
3. 自动时间初始化与更新时间戳
- TIMESTAMP 和 DATETIME 可设置自动填充当前时间或自动更新时间,具体参见相关章节。
4. 时区与数据存储差异
- TIMESTAMP:存储时会自动将本地时区转换为 UTC,读取时再转回当前会话时区。若插入后修改了时区,再读出来的值会有变动。
- DATETIME:不会自动转换时区,按原值存储和读取。
5. 字面量与格式说明
- 字符串输入格式支持多样化(详细见11.1.3),但要注意有的宽松分隔符已逐步废弃。
- 带有小数秒的部分,只能用小数点与前面部分分隔。
6. 非法与“零”日期
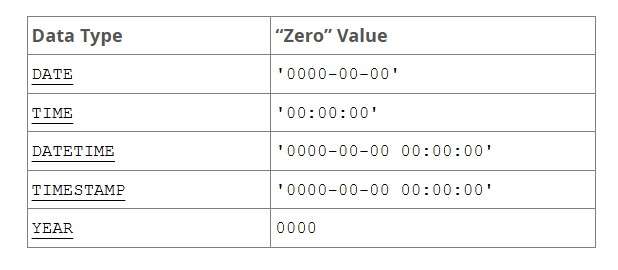
- 非法的 DATE/DATETIME/TIMESTAMP,依据 SQL 模式,可能被自动转换为“零日期”(如 '0000-00-00' 或 '0000-00-00 00:00:00'),或直接报错。
- 严格模式启用时,非法日期报错;如关闭则变成“零日期”,并生成警告。
- 只有字段值允许时,“0000-00-00 00:00:00”可以插入为 TIMESTAMP,否则被拒绝。
7. 2位年份的转换规则
- 两位数年份的输入解释如下:
- 00-69:视为 2000-2069
- 70-99:视为 1970-1999
8. 特殊函数与进阶操作
- MySQL 8.0.22 起,支持用
CAST(col AT TIME ZONE INTERVAL '+00:00' AS DATETIME)方式将TIMESTAMP值转换为UTC的DATETIME。 - 可插入带时区偏移量的字面量,具体规则参见前述 11.1.3 节。
9. 其它注意事项与建议
- 分隔符不正确或格式不规范时,可能引发数据解析异常或警告。
- 需要确保插入的月份、日期等组成部分是真实存在的日期。
- 时间/日期字段如何选择,建议根据业务场景(是否需要时区转换、取值区间、是否带时间部分)合理选型,避免潜在的歧义。
知识点总结:
- 选用 DATE、DATETIME、TIMESTAMP 类型,需考虑取值范围、时区处理、业务语义及运算方便性;
- TIMESTAMP 自动时区转换,DATETIME 不转换时区;
- 输入格式宽松但建议标准化('YYYY-MM-DD'、'YYYY-MM-DD hh:mm:ss');
- 非法值根据 SQL 模式决定行为,强烈建议启用严格模式确保数据正确。
Q18
Which three evaluate to a temporal value?
A. '2020-05-01' - INTERVAL 1 DAY
B. SYSDATE()
C. MONTH('01-05-2020')
D. TO_DAYS('2020-05-01')
E. SYSDATE() - 1
F. '2020-05-01'
中文题目解析
题意:下列哪三个表达式的结果是时间值(temporal value)?
temporal value 指的是日期、时间、日期时间等类型的值。
选项详解
-
A. '2020-05-01' - INTERVAL 1 DAY
- 解析:'2020-05-01' 是日期字面量,减去一个间隔(INTERVAL 1 DAY),结果还是日期
'2020-04-30',属于 temporal value。(正确)
- 解析:'2020-05-01' 是日期字面量,减去一个间隔(INTERVAL 1 DAY),结果还是日期
-
B. SYSDATE()
- 解析:SYSDATE() 返回当前日期和时间,类型为 DATETIME。属于 temporal value。(正确)
-
C. MONTH('01-05-2020')
- 解析:MONTH() 提取月份,返回的是数字(如5),不是 temporal value。
-
D. TO_DAYS('2020-05-01')
- 解析:TO_DAYS() 返回自公元元年1月1日以来的天数,是一个整数,不是 temporal value。
-
E. SYSDATE() - 1
- 解析:SYSDATE() 是时间,但 - 1 后得到的是时间戳/时间值还是整数依实现,不保证返回 temporal value,通常不直接返回日期类型。
-
F. '2020-05-01'
- 解析:这是标准的日期字面量,属于 temporal value。(正确)
正确答案
A('2020-05-01' - INTERVAL 1 DAY)、B(SYSDATE())、F('2020-05-01')
相关知识点总结
- temporal value:即时间型相关类型,包括 DATE、TIME、DATETIME、TIMESTAMP 等。
- SQL 运算如 "date - INTERVAL"、内置函数 SYSDATE()、日期字面量都返回或代表 temporal value。
- TO_DAYS/MONTH 等函数将日期转为数字,不属于 temporal value。
- 选择时需分清返回值的类型。
Q18
Examine these statements and output:
INSERT INTO authors (first_name,last_name)
VALUES ('William','Shakespeare');
Query OK, 1 row affected, 1 warning (0.00 sec)
SHOW WARNINGS;
+---------+------+-----------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------+
| Warning | 1265 | Data truncated for column 'last_name' at row 1|
+---------+------+-----------------------------------------------+
Which SQL Mode will cause this INSERT to raise an error instead of a warning?
A. NO_ENGINE_SUBSTITUTION
B. ONLY_FULL_GROUP_BY
C. STRICT_TRANS_TABLES
D. HIGH_NOT_PRECEDENCE
E. IGNORE_SPACE
正确答案 C. STRICT_TRANS_TABLES
中文题目解析
观察以下 SQL 执行及其输出:
INSERT INTO authors (first_name,last_name)
VALUES ('William','Shakespeare');
Query OK, 1 row affected, 1 warning (0.00 sec)
SHOW WARNINGS;
+---------+------+-----------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------+
| Warning | 1265 | Data truncated for column 'last_name' at row 1|
+---------+------+-----------------------------------------------+
哪种 SQL 模式(SQL Mode)会使这个 INSERT 操作在发生数据截断(如“最后一列值被截断”)时抛出错误,而不是只发出警告?
A. NO_ENGINE_SUBSTITUTION
含义:禁止自动替换存储引擎。如果指定的存储引擎不可用,不会自动换成默认引擎。与数据截断无关。
B. ONLY_FULL_GROUP_BY
含义:在分组查询时,select 子句中的每个列都必须在 group by 中或被聚合函数包围。与 INSERT 或数据截断无关。
C. STRICT_TRANS_TABLES
含义:开启严格模式(针对支持事务的表)。遇到数据截断、不合法数据类型等情况时,直接抛出错误,而不是警告!(正确答案)
D. HIGH_NOT_PRECEDENCE
含义:更改 NOT 运算符的优先级。这与 INSERT 或数据类型校验无关。
E. IGNORE_SPACE
含义:函数名和括号之间允许有空格。与数据校验无关。
正确答案 C. STRICT_TRANS_TABLES
相关知识点总结
- STRICT_TRANS_TABLES(严格事务表模式)会让 MySQL 在插入非法数据(如长度超限、截断等)时,直接报错,中断操作。
- 默认情况下,MySQL 在遇到数据被截断时仅发出警告(warning);如果希望转换为错误(error),需开启 STRICT 模式。
- 其他选项例如 NO_ENGINE_SUBSTITUTION 或 ONLY_FULL_GROUP_BY 与数据截断或 INSERT 操作无直接关联。
- 推荐线上生产环境启用 STRICT_TRANS_TABLES,防止无声的数据损坏。
MySQL 8.0 Reference Manual: 7.1.11 Server SQL Modes
简介
MySQL 支持多种 SQL 模式(SQL Modes),用于控制 SQL 语法和数据校验方式。SQL 模式可以在全局或会话级别配置,对不同应用和环境有不同适配需求。通过设置系统变量 sql_mode,DBA 可以调整 MySQL 的行为以满足业务需求或兼容其他数据库系统。
1. SQL 模式的设置
- 默认 SQL 模式:MySQL 8.0 默认启用如下模式:
- ONLY_FULL_GROUP_BY
- STRICT_TRANS_TABLES
- NO_ZERO_IN_DATE
- NO_ZERO_DATE
- ERROR_FOR_DIVISION_BY_ZERO
- NO_ENGINE_SUBSTITUTION
- 设置方法:
启动时通过参数--sql-mode="modes"或配置文件my.cnf/my.ini,运行时则可以SET GLOBAL/SESSION sql_mode = 'modes'。 - 注意事项:变更带有分区表的 SQL 模式有丢数据风险,主从复制建议保持 SQL mode 一致。
2. 重要 SQL 模式说明
- ANSI
模拟 ANSI SQL 行为,提高标准兼容性(包含 REAL_AS_FLOAT、PIPES_AS_CONCAT、ANSI_QUOTES、IGNORE_SPACE、ONLY_FULL_GROUP_BY)。 - STRICT_TRANS_TABLES & STRICT_ALL_TABLES
严格模式。数据校验更严格,插入/更新非法数据时会报错而非警告。 - TRADITIONAL
传统模式(综合多种严格检查,相当于“有问题就报错”)。
3. 常用和特殊 SQL Modes 简要说明
- ALLOW_INVALID_DATES:仅检查月份1-12、日期1-31,不验证完整性。
- ANSI_QUOTES:用
"双引号包裹标识符。 - ERROR_FOR_DIVISION_BY_ZERO:除零警告或报错,依赖是否开启严格模式。
- HIGH_NOT_PRECEDENCE:更改 NOT 逻辑优先级(兼容老语法)。
- IGNORE_SPACE:函数名和括号间可有空格。
- NO_AUTO_VALUE_ON_ZERO:仅 NULL 触发 AUTO_INCREMENT,不再接受 0。
- NO_BACKSLASH_ESCAPES:禁用反斜杠转义。
- NO_ENGINE_SUBSTITUTION:指定存储引擎不可用时报错,不自动换成其他引擎。
- NO_UNSIGNED_SUBTRACTION:无符号数相减结果为有符号数。
- NO_ZERO_DATE/NO_ZERO_IN_DATE:更严格禁止无效日期(如 0000-00-00 或带零的年月日)。
- ONLY_FULL_GROUP_BY:GROUP BY 查询列和分组列一致,否则报错。
- PAD_CHAR_TO_FULL_LENGTH:取CHAR类型时补齐至定义长度。
- PIPES_AS_CONCAT:将“||” 作为字符串拼接符号。
- STRICT_ALL_TABLES / STRICT_TRANS_TABLES:所有表/事务表启用严格数据检查。
- TIME_TRUNCATE_FRACTIONAL:时间类型插入时,截断而非四舍五入小数部分。
4. 严格模式(Strict SQL Mode)详解
- 严格模式要求插入/更新数据必须完全合法,否则报错而不是警告(除非用 IGNORE 关键字降级为警告)。
- 适用范围:ALTER/CREATE/INSERT/UPDATE/LOAD DATA/DELETE 等 DML 和 DDL。
- 如果配合 IGNORE,错误会被降级为警告,且当前/剩余数据可能部分执行,需谨慎。
- 错误类型举例:
- ER_BAD_NULL_ERROR
- ER_DATA_TOO_LONG
- ER_DIVISION_BY_ZERO
- ER_NO_DEFAULT_FOR_FIELD
- ER_WARN_DATA_OUT_OF_RANGE
- 等等
5. IGNORE 与 Strict Mode 的比较
| 操作模式 | 默认是错误时 | 默认是警告时 |
|---|---|---|
| 无 IGNORE 且无 strict mode | 错误 | 警告 |
| 含 IGNORE | 警告 | 警告 |
| 含 strict SQL mode | 错误 | 错误 |
| 含 IGNORE 且含 strict mode | 警告 | 警告 |
- IGNORE 优先生效,可以将本该报错的行为降为警告。
6. 关键知识点总结
- SQL mode 控制了 MySQL 数据库的语法兼容性和数据校验“严格程度”。
- 默认开启多项严格与标准化选项,最大程度保证数据质量。
- 修改 SQL mode 时,要注意主从一致性、历史数据风险与业务兼容性。
- 检查当前模式用:
SELECT @@GLOBAL.sql_mode;或SELECT @@SESSION.sql_mode;。
更多详细内容和完整 SQL 模式列表参见官方文档:
MySQL 8.0 Reference Manual :: 7.1.11 Server SQL Modes
Q19
英文原题
A MySQL server has been provided self signed certificates by your corporate Certificate Authority.
The server is only accessible from your private network and all name resolution is provided by a private DNS service.
Which two statements are true?
A. Self signed certificates provide more trust than those signed by a trusted CA.
B. Public trusted CA certificates are more trustworthy than those signed by the corporate CA.
C. Public trusted CA certificates are more technically secure than those signed by the corporate CA.
D. Public trusted CA certificates and those signed by the corporate CA can provide the same level of technical security.
E. Public trusted CA certificates and those signed by the corporate CA provide the same level of trust in the destination host.
题目翻译
一家 MySQL 服务器由你们企业证书颁发机构(CA)签发了自签名证书。
服务器仅能通过你的内网访问,所有域名解析由私有 DNS 提供。
下列哪两项陈述是正确的?
A. 自签名证书比受信任 CA 签发的证书更值得信任。
B. 公开受信 CA 颁发的证书比企业 CA 签发的证书更值得信任。
C. 公开受信 CA 颁发的证书在技术上比企业 CA 签发的更安全。
D. 公开受信 CA 证书与企业 CA 签署的证书可以提供同等水平的技术安全性。
E. 公开受信 CA 证书和企业 CA 签署的证书在目标主机的信任级别相同。
选项逐项解析
-
A. 自签名证书比受信任 CA 签发的证书更值得信任。
- 错误。自签名证书通常不被认为可靠,除非客户端进一步信任该证书。
-
B. 公共受信 CA 证书比企业 CA 签发的证书更值得信任。
- 正确。公共 CA 受到广泛信任,通常在更大范围通信中比仅限于内部网络的企业 CA 更受信任。
-
C. 公共受信 CA 证书在技术上比企业 CA 更安全。
- 错误。从加密技术角度看,公有 CA 和企业 CA 签发的证书同样可以实现相同强度的加密,安全性取决于私钥保护和算法,而非颁发者。
-
D. 公有 CA 证书和企业 CA 证书能提供同等安全性。
- 正确。只要算法和密钥长度等一致,技术安全性相同。
-
E. 公有 CA 证书和企业 CA 证书的信任级别一样。
- 错误。信任级别取决于客户端对 CA 的信任情况,公有 CA 被更多系统默认信任,企业 CA 一般只在内部环境信任。
正确答案
- B. Public trusted CA certificates are more trustworthy than those signed by the corporate CA.
- D. Public trusted CA certificates and those signed by the corporate CA can provide the same level of technical security.
知识点总结
- 信任度:公共 CA 证书由于预装在大部分操作系统与浏览器中,天然比只被内网信任的企业 CA 具备更高的“广域”信任度。
- 技术安全性:只要加密算法与密钥管理一样,CA 的类型不会影响证书本身的加密强度。
- 实际选择:在内网环境,可以通过企业 CA 保证信任闭环和管理便捷;在面向互联网场景则建议使用公共 CA。
Q20
英文原题
Your program which uses a MySQL connector receives this error:
Client does not support authentication protocol requested by server
The account running the program uses caching_sha2_password.
Which two resolve this conflict?
A. Upgrade the connector to a version that supports caching_sha2_password.
B. Disable TLS/SSL authentication.
C. Change the user account to use mysql_native_password.
D. Place this in the root directory of your shell account:
[mysqld]
require_secure_transport=OFF
E. Use blank RSA or SSL certificates.
题目翻译
你的程序在使用 MySQL 连接器时遇到如下报错:
Client does not support authentication protocol requested by server
(客户端不支持服务器要求的认证协议)
运行程序的账户使用的是 caching_sha2_password。
哪两种操作可以解决此冲突?
A. 升级连接器到支持 caching_sha2_password 的版本。
B. 禁用 TLS/SSL 认证。
C. 将用户账户更改为使用 mysql_native_password。
D. 在 shell 账户根目录下放置如下内容:
[mysqld]
require_secure_transport=OFF
E. 使用空白 RSA 或 SSL 证书。
选项分析
-
A. 升级连接器到支持 caching_sha2_password 的版本。
- 正确。MySQL 8.0 默认账户认证插件为 caching_sha2_password,旧版本连接器可能不支持该协议,升级驱动可解决此兼容性问题。
-
B. 禁用 TLS/SSL 认证。
- 错误。认证协议问题与 TLS/SSL 认证方式无关,关闭不会解决客户端协议不支持问题。
-
C. 更改账户为 mysql_native_password。
- 正确。将认证插件修改为 mysql_native_password(老版本广泛支持的协议)可以兼容不支持 caching_sha2_password 的老驱动或客户端。
-
D. 更改 require_secure_transport 设置。
- 错误。这个设置控制是否必须使用安全传输,与认证协议本身无直接关联。
-
E. 使用空白证书。
- 错误。证书与认证协议不相干,且可能导致更严重的安全隐患。
正确答案
- A. 升级连接器到支持 caching_sha2_password 的版本。
- C. 更改账户为 mysql_native_password。
相关知识点总结
- MySQL 8.0 推荐使用 caching_sha2_password,具有更强安全性,但老客户端驱动经常不支持。
- 两种通用解决方案:升级客户端/驱动或将账户认证协议降级为兼容性更好的 mysql_native_password。
- 多数情况下不建议随意降低协议安全性,首选建议是升级驱动环境。
Q21
英文原题
You are designing a new PHP application that accesses a MySQL database.
Which factors affect your choice of using mysqli or PHP Data Objects (PDO)? (Choose two)
A. Whether you use MySQL-specific features
B. Whether the number of concurrent users is expected to increase over time
C. Whether the size of the database is expected to increase over time
D. Whether you might port the application to Python or another programming language
E. Whether you might migrate to another Relational Database Management System
题目翻译
你正在设计一个新的 PHP 应用,它访问 MySQL 数据库。下列哪些因素影响你选择使用 mysqli 还是 PDO?(选两项)
A. 是否使用 MySQL 特有的功能
B. 并发用户数是否会增加
C. 数据库容量是否会增加
D. 是否考虑将应用移植到 Python 或其它语言
E. 是否可能迁移到其它关系型数据库管理系统(如 PostgreSQL、Oracle 等)
选项解析
-
A. 是否使用 MySQL 专有特性
- 正确。mysqli 支持 MySQL 独有特性,如多语句、特定存储过程、MySQL 扩展命令等,而 PDO 更侧重通用性。
-
B. 并发用户数量增长
- 错误。并发用户和驱动类型选择没有直接关系。
-
C. 数据库大小增长
- 错误。数据库体量通常不会决定你选用 mysqli 或 PDO。
-
D. 是否预计会将代码移植到 Python 或其他语言
- 错误。移植到其他语言时一般需要重写数据访问层,PHP 的 mysqli/PDO 与其它语言兼容性不直接相关。
-
E. 是否有迁移到其它关系型数据库的需求
- 正确。PDO 支持多种数据库后端(MySQL、PostgreSQL、SQLite 等),利于未来迁移;mysqli 仅限 MySQL。
正确答案
- A. Whether you use MySQL-specific features
- E. Whether you might migrate to another Relational Database Management System
相关知识点总结
- mysqli 只支持 MySQL,能用 MySQL 扩展特性。
- PDO 支持多种数据库,适合考虑未来迁移的应用场景。
- 选型时核心考虑数据库特性依赖及未来可扩展性,而非当前性能、并发等单一指标。
Q22
英文原题
The projects table has these two columns:
start_date DATE
end_date DATE
Which statements return the project duration in days? (Choose two)
A. SELECT TO_DAYS(end_date) - TO_DAYS(start_date) FROM projects
B. SELECT DAY(end_date) - DAY(start_date) FROM projects
C. SELECT SUBDATE(end_date, start_date) FROM projects
D. SELECT DATEDIFF(end_date, start_date) FROM projects
E. SELECT end_date - start_date FROM projects
题目翻译
projects 表有这两列:
start_date DATE
end_date DATE
下列哪些语句可以返回项目的天数持续时长?(选两项)
选项解析
-
A. SELECT TO_DAYS(end_date) - TO_DAYS(start_date) FROM projects
- 正确。TO_DAYS 将日期转为天数(自1582年以来的天数),两者相减即可得持续天数。
-
B. SELECT DAY(end_date) - DAY(start_date) FROM projects
- 错误。DAY 仅返回每月中的日(1-31),无法得出两个任意日期跨度。
-
C. SELECT SUBDATE(end_date, start_date) FROM projects
- 错误。SUBDATE 第二参数应是时间间隔(整数或 INTERVAL),不是另一个日期,此写法会报错。
-
D. SELECT DATEDIFF(end_date, start_date) FROM projects
- 正确。DATEDIFF 专用于返回两个日期间的天数。
-
E. SELECT end_date - start_date FROM projects
- 错误。日期类型直接相减在 MySQL 会隐式转为数字,可能不会返回天数,容易出错且不可移植。
正确答案
- A. SELECT TO_DAYS(end_date) - TO_DAYS(start_date) FROM projects
- D. SELECT DATEDIFF(end_date, start_date) FROM projects
相关知识点总结
DATEDIFF(date1, date2):MySQL 内置函数,返回 date1-date2 的天数差。TO_DAYS(date):返回自基准日(1582-10-15)以来的天数,可用于日期差计算。- 直接用
DAY(date)只取天字段,不用于日期跨度。 SUBDATE用于“日期-间隔”,不支持“日期-日期”。- 推荐用
DATEDIFF,更直观且类型安全。
Q23
英文原题
Examine this statement, which executes successfully:
CREATE TRIGGER t1_AI
AFTER INSERT ON t1
FOR EACH ROW
UPDATE ops SET c = c + 1 WHERE op='INSERT';
Which statements invoke the trigger when executed successfully? (Choose two)
A. LOAD DATA INFILE 'data.txt' INTO TABLE t1
B. UPDATE t1 SET c = c + 1 WHERE op='INSERT'
C. REPLACE t1 SELECT * FROM t2
D. UPDATE ops SET c = c + 1 WHERE op='INSERT'
E. INSERT INTO t2 SELECT * FROM t1
F. INSERT INTO ops (c, op) VALUES (1, 'INSERT')
题目翻译
如下触发器成功创建:
CREATE TRIGGER t1_AI
AFTER INSERT ON t1
FOR EACH ROW
UPDATE ops SET c = c + 1 WHERE op='INSERT';
哪些语句在执行成功时会触发这个触发器?(选两项)
选项解析
- A. LOAD DATA INFILE 'data.txt' INTO TABLE t1
正确。此操作等同于批量插入新行到 t1,会触发 AFTER INSERT 触发器。 - B. UPDATE t1 SET c = c + 1 WHERE op='INSERT'
错误。UPDATE 并不会触发 INSERT 相关触发器。 - C. REPLACE t1 SELECT * FROM t2
正确。REPLACE 在目标表有冲突时会先 DELETE 再 INSERT 新行(或仅 INSERT),所以 INSERT 流程会触发 AFTER INSERT 触发器。 - D. UPDATE ops SET c = c + 1 WHERE op='INSERT'
错误。此操作与 t1 无关,不会触发 t1 的触发器。 - E. INSERT INTO t2 SELECT * FROM t1
错误。插入的是 t2,与 t1 无关,不会触发 t1 的触发器。 - F. INSERT INTO ops (c, op) VALUES (1, 'INSERT')
错误。表 ops,不是 t1。
正确答案
A. LOAD DATA INFILE 'data.txt' INTO TABLE t1
C. REPLACE t1 SELECT * FROM t2
相关知识点总结
- AFTER INSERT 触发器在目标表被插入数据时触发,包括 LOAD DATA 和 REPLACE(在实际发生插入时)。
- 只有写操作(INSERT / LOAD DATA / REPLACE)作用于带触发器的表本身时才会触发相应的触发器。
- UPDATE/INSERT到其他表、UPDATE本表都不会触发 INSERT 触发器。
Q24
英文原题
Examine these statements, which execute sequentially in the same session successfully:
START TRANSACTION;
UPDATE t1 SET c=100 WHERE id=1;
ALTER TABLE t1 ADD INDEX (c);
INSERT INTO t1 (c) VALUES (200);
COMMIT;
How many transactions have committed?
A. Three
B. Five
C. Four
D. Two
E. One
题目翻译
依次顺序执行以下语句(同一会话且都执行成功):
START TRANSACTION;
UPDATE t1 SET c=100 WHERE id=1;
ALTER TABLE t1 ADD INDEX (c);
INSERT INTO t1 (c) VALUES (200);
COMMIT;
请问一共提交了多少个事务?
选项解析
- MySQL的事务控制(Autocommit行为)
任何DDL(如 ALTER TABLE)都会在 MySQL 中自动提交当前未提交事务,同时自身单独提交。
START TRANSACTION 开始一个显式事务,但一遇到 ALTER TABLE,MySQL 会强制隐式提交之前未提交的内容。
后续的非 DDL 语句(如 INSERT)会重新进入 autocommit 模式,且最后的 COMMIT 只影响可能存在的当前事务。 - 执行流程分析:
START TRANSACTION;
开始一个新事务。
UPDATE t1 SET c=100 WHERE id=1;
在同一个事务内执行。
ALTER TABLE t1 ADD INDEX (c);
自动提交前一个事务,ALTER 自身也是一个隐式单独事务。
INSERT INTO t1 (c) VALUES (200);
新的一条语句又在自动提交模式下作为单独事务。
COMMIT;
若前一步不是事务语句(显式或隐式),此 COMMIT 不提交任何新内容。
- 细节小结:
UPDATE --- 事务A,提交一次(因 ALTER 自动提交)
ALTER TABLE --- 事务B,自动单独提交
INSERT --- 事务C,autocommit
共有 三次提交。
正确答案
A. Three
相关知识点总结
- MySQL 中所有 DDL(如 ALTER/CREATE/DROP)均会隐式提交当前事务并自动自身提交。
- 多数 DML 语句(UPDATE/INSERT)不在事务内时,默认自动提交。
- 显式事务遇到 DDL 会被终止并提交,后续重新开启。
- 若需保证一组操作原子性,事务期间不能穿插任何 DDL。
InnoDB 事务的 autocommit、Commit 和 Rollback 机制总结
https://dev.mysql.com/doc/refman/8.0/en/innodb-autocommit-commit-rollback.html
内容摘要
- 所有用户操作都属于某个事务内部。
- 如果开启了 autocommit(默认),每条 SQL 语句就是一个独立的事务,语句执行后立刻提交(无错即提交)。
- 如果某条语句出错,是否 COMMIT 或 ROLLBACK 取决于错误类型。
- 显式开启事务可以用
START TRANSACTION或BEGIN,结束事务用COMMIT或ROLLBACK。 - 如果用
SET autocommit = 0关闭自动提交,则需要手动执行COMMIT或ROLLBACK,每次提交/回滚后自动开启下一个新事务。 - autocommit 关闭状态下会话如果结束但未显式提交,MySQL 会自动回滚该事务。
- 有些语句(如 DDL 语句、部分锁表操作)会隐式提交当前事务。
关键点梳理
-
autocommit(自动提交)
默认开启,每条 DML 语句单独为一事务。 -
显式事务
START TRANSACTION 明确开启,须手动提交或回滚。 -
autocommit=0(关闭自动提交)
会话全程处于事务状态,全部操作需显式提交或回滚。 -
隐式提交语句
部分DDL语句等会隐式提交所有已启动的事务。 -
事务控制 API
客户端语言也可直接发送 COMMIT/ROLLBACK 命令,或使用事务方法控制。
应用建议
- 修改多条数据时建议使用事务显式包裹,确保一致性和可回滚。
- 注意 DDL 操作会打断事务,合理安排批处理顺序。
- 明确了解 autocommit 机制,防止误操作导致未预期的数据提交/丢失。
Q25
英文原文
Examine this SELECT statement:
SELECT * FROM orders WHERE YEAR(order_date)=2020 AND MONTH(order_date)=6;
The order_date column is indexed and uses the DATE data type.
Which methods can independently improve the query performance? (Choose two)
A. Rewrite the WHERE clause to WHERE order_date LIKE '2020-06-%'.
B. Rewrite the WHERE clause as WHERE order_date RLIKE '^2020-06'.
C. Rewrite the WHERE clause as WHERE order_date >= '2020-06-01' AND order_date < '2020-07-01'.
D. Add an index on ((MONTH(order_date)), (YEAR(order_date))).
E. Add an index on ((EXTRACT(YEAR_MONTH FROM order_date))).
中文翻译题目和选项
请检查下列 SELECT 语句:
SELECT * FROM orders WHERE YEAR(order_date)=2020 AND MONTH(order_date)=6;
order_date 字段已建立索引并使用 DATE 类型。
下列哪些方法可以独立提升该查询的性能?(选择两个)
A. 将 WHERE 子句改写为 WHERE order_date LIKE '2020-06-%'
B. 将 WHERE 子句改写为 WHERE order_date RLIKE '^2020-06'
C. 将 WHERE 子句改写为 WHERE order_date >= '2020-06-01' AND order_date < '2020-07-01'
D. 对((MONTH(order_date)), (YEAR(order_date))) 建立复合索引
E. 对((EXTRACT(YEAR_MONTH FROM order_date))) 建立索引
选项逐项解释
-
A. WHERE order_date LIKE '2020-06-%'
这会使用字符串匹配,对于 DATE 类型来说不够高效,且可能不能命中已有的 DATE 索引。 -
B. WHERE order_date RLIKE '^2020-06'
使用正则表达式匹配字符串,这会导致索引失效,性能较低。 -
C. WHERE order_date >= '2020-06-01' AND order_date < '2020-07-01'
这样能充分利用 order_date 上的索引,对范围扫描非常高效。(正确答案) -
D. 对 ((MONTH(order_date)), (YEAR(order_date))) 建立索引
可以单独提高 MONTH/YEAR 查询的效率,但是需要函数索引,且与常规索引不同。不过在一些数据库,如 MySQL 8.0 支持函数索引时,这样可以提升性能。(正确答案) -
E. 对((EXTRACT(YEAR_MONTH FROM order_date))) 建立索引
这种组合表达式的函数索引,不是所有数据库都原生支持,通常不能直接显著提升性能,而且查询语句也需要同步调整。
相关知识点总结
-
对于 DATE 类型字段、索引和函数查询:
在 WHERE 子句中对索引列使用函数(如 YEAR(), MONTH())会导致索引失效,导致全表扫描。 -
使用范围查询(直接比较原始字段)能利用索引,如 order_date >= '2020-06-01' AND order_date < '2020-07-01'
-
在支持函数索引的数据库(如 MySQL 8.0+),针对具体函数可建表达式索引,但需确保查询语句与索引表达式一致。
SQL 查询优化的核心原则是最大限度利用索引,尽量避免在 WHERE 条件对已建索引字段做函数或类型转换操作。
Q26
EXPLAIN can show the execution plan of which SQL statements? (Choose three)
A. ALTER
B. CREATE
C. DROP
D. REPLACE
E. SELECT
F. TRUNCATE
G. UPDATE
中文翻译题目和选项
EXPLAIN 可以显示哪些 SQL 语句的执行计划?(选择三个)
A. ALTER
B. CREATE
C. DROP
D. REPLACE
E. SELECT
F. TRUNCATE
G. UPDATE
选项逐项解释
-
A. ALTER
- 错误。EXPLAIN 不适用于 ALTER 语句,无法查看其执行计划。
-
B. CREATE
- 错误。EXPLAIN 无法解释 CREATE 的执行计划。
-
C. DROP
- 错误。EXPLAIN 不适用于 DROP 语句。
-
D. REPLACE
- 正确。在 MySQL 中,EXPLAIN 可用于 REPLACE 语句,显示其查询计划。(正确答案)
-
E. SELECT
- 正确。EXPLAIN 最常用于 SELECT 语句,用来分析查询的执行计划。(正确答案)
-
F. TRUNCATE
- 错误。EXPLAIN 不适用于 TRUNCATE。
-
G. UPDATE
- 正确。EXPLAIN 也可用于 UPDATE 语句,查看其执行计划。(正确答案)
正确答案
- D. REPLACE
- E. SELECT
- G. UPDATE
相关知识点总结
- EXPLAIN 语句常用来分析 SELECT、UPDATE、DELETE、INSERT、REPLACE 等数据操作语句的执行计划,可以帮助优化 SQL 性能。
- EXPLAIN 不适用于数据定义语言(DDL)语句,如 ALTER、CREATE、DROP、TRUNCATE。
- 了解 EXPLAIN 能支持的语句类型,有助于我们在实际数据库优化场景中灵活使用它进行性能调优。
Q27
英文原文
Which statements exit a loop in MySQL stored functions? (Choose two)
A. END
B. CLOSE
C. ITERATE
D. LEAVE
E. RETURN
中文翻译题目和选项
在 MySQL 存储函数中,哪些语句可以退出循环?(选择两个)
A. END
B. CLOSE
C. ITERATE
D. LEAVE
选项逐项解释
-
A. END
- 错误。END 仅表示语句块结束,不会主动跳出循环。
-
B. CLOSE
- 错误。CLOSE 用于关闭游标,不用于控制循环。
-
C. ITERATE
- 错误。ITERATE 用于跳到循环的下一次迭代,不会直接退出循环。
-
D. LEAVE
- 正确。LEAVE 可以直接跳出指定的循环,终止循环体的执行。(正确答案)
-
RETURN
- 正确。在存储函数中直接终止整个函数,也会退出循环。(正确答案)
正确答案
- LEAVE
- RETURN
知识点总结
- 在 MySQL 存储函数中,“LEAVE” 可跳出循环,作用类似于 break。
- “RETURN” 可终止整个函数或存储过程,离开所有循环和当前代码块。
- “ITERATE” 只会跳到下一次循环,不能直接退出循环。
- “END” 只是语法块的结尾,不能终止循环。
Q28
英文原文
Which consistency issues can happen in read committed isolation level?
A. Only dirty reads
B. Only non-repeatable reads
C. Only phantom reads
D. Dirty reads and non-repeatable reads
E. Non-repeatable reads and phantom reads
F. Dirty reads, non-repeatable reads, and phantom reads
中文翻译题目和选项
在 read committed(已提交读)隔离级别下,可能发生哪些一致性问题?
A. 只有脏读
B. 只有不可重复读
C. 只有幻读
D. 脏读和不可重复读
E. 不可重复读和幻读
F. 脏读、不可重复读和幻读
选项逐项解释
-
A. 只有脏读
- 错误。已提交读会避免脏读。
-
B. 只有不可重复读
- 错误。不仅会有不可重复读,还会有幻读。
-
C. 只有幻读
- 错误。幻读之外,也有不可重复读风险。
-
D. 脏读和不可重复读
- 错误。已提交读隔离级别已经避免了脏读。
-
E. 不可重复读和幻读
- 正确。在 read committed 下,可能会出现不可重复读和幻读。(正确答案)
-
F. 脏读、不可重复读和幻读
- 错误。脏读在更低级别(如 read uncommitted)才可能出现。
正确答案
- E. 不可重复读和幻读
相关知识点总结
- Read Committed(已提交读):
- 可以避免脏读(dirty read),即不会读到其它事务尚未提交的数据。
- 但仍可能出现不可重复读(non-repeatable read):同一事务内两次查询同一行,结果不同。
- 依然可能出现幻读(phantom read):同一事务内两次范围查询,行数不同(可能有新行插入或删除)。
- 制定高一致性要求时,可考虑采用更高级的隔离级别,如 repeatable read(可重复读)或 serializable(可串行化)。
17.7.2.1 事务隔离级别(Transaction Isolation Levels)
https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html
核心思想
事务隔离是数据库处理的基础之一,是 ACID 原则中的“I”。隔离级别用于平衡多事务并发时的性能与一致性/可靠性之间的关系。
支持的四大隔离级别(InnoDB 全部支持)
- READ UNCOMMITTED:最低级别,允许“脏读”(Dirty Read),即一个事务能看到其他未提交事务的数据。
- READ COMMITTED:允许“不可重复读”和“幻读”,但避免了“脏读”。
- 每次读取都是最近已提交的数据快照。
- 锁定只针对被更改的行,其它行解锁,提升并发,减少死锁概率。
- 插入“间隙锁”大致关闭,因此可能出现“幻读”。
- REPEATABLE READ(默认值):进一步提高一致性,允许“幻读”,但避免了“脏读”和“不可重复读”。
- 事务内多次查询相同数据,结果一致(“不可重复读”被避免)。
- 插入和范围查询等操作采用“间隙锁”或“next-key lock”阻止其它事务向扫描范围内插入数据。
- 不建议在一个事务内混合锁定读和非锁定读,否则非锁定读的数据快照会与当前事务写入的数据不一致。
- SERIALIZABLE:最高级别,完全串行化所有操作,可避免全部并发一致性问题,通常用于特殊场景(如 XA 事务、并发/死锁调试等)。
- 普通 SELECT 被自动转为 SELECT ... FOR SHARE(如果未开启自动提交)。
事务隔离级别的设置
- 用
SET TRANSACTION语句可以为当前会话或之后的所有连接更改隔离级别。 - 同样可在启动参数(--transaction-isolation)和配置文件中设置全局默认隔离级别。
InnoDB 的各种隔离实现
- InnoDB 使用不同锁策略来实现各级隔离。
- 在 READ COMMITTED 下,会出现“不可重复读”和“幻读”:
- 不可重复读:同一事务内多次读取同一行,数据内容不一致。
- 幻读:同一事务内多次范围查询,数据行数不一致(因为可能有新行插入或被删除)。
- 在 READ UNCOMMITTED 下,SQL 可能读到别的尚未提交事务的数据(脏读)。
- 在 REPEATABLE READ 下,避免“脏读”和“不可重复读”,但可能有“幻读”。
- SERIALIZABLE 强制所有并发事务串行执行,完全消除“脏读”“不可重复读”“幻读”。
一些细节说明
- 用锁定读(如 SELECT ... FOR UPDATE / FOR SHARE)、UPDATE、DELETE 的锁定策略与唯一索引或范围有关。
- 建议在关键数据场景用默认 REPEATABLE READ 或 SERIALIZABLE;如对性能有特殊要求(例如报表),可适当降低隔离级别以减少锁和并发冲突。
- 注意:MySQL 8.0.22 起,部分授权表的 DML 操作不会加读锁。
关键术语
- 脏读(Dirty Read):能读到其他未提交事务的数据。
- 不可重复读(Non-repeatable Read):同一事务内多次读取同一数据,结果可能不一致。
- 幻读(Phantom Read):同一事务内多次范围查询,行数有变化。
- 间隙锁(Gap Lock)/next-key锁:防止其它事务在本次查询范围内插入或删除行,保证一致性。
总结
- MySQL 的 InnoDB 存储引擎完全实现了 SQL 标准的四种隔离级别。
- 不同隔离级别下数据库的并发一致性保障、死锁概率和性能表现有很大区别,需根据业务需求权衡选择。
Q29
- You must add a column to store exam scores. The value is between 0 and 100 with one decimal point required. You must use the data type with the most efficient storage for the value. Which data type would you choose?
A. DECIMAL(4,1)
B. DECIMAL(3,1)
C. CHAR(5)
D. TINYINT
E. INT
F. FLOAT
中文翻译题目和选项
你需要添加一列来存储考试分数。该分数范围在 0 到 100 之间,需要保留一位小数。你必须选择最节省存储空间的数据类型。你会选择哪种数据类型?
A. DECIMAL(4,1)
B. DECIMAL(3,1)
C. CHAR(5)
D. TINYINT
E. INT
F. FLOAT
选项逐项解释
- DECIMAL(4,1)
- 正确。可存储最大 99.9 或 100.0 等四位带一位小数的分数,且比 FLOAT 精确,容量也较小,适合本场景。(正确答案)
- DECIMAL(3,1)
- 错误。只能存 2 位整数+1 位小数,不足以存储 100.0 这样的分数。
- CHAR(5)
- 错误。使用字符存数值既浪费空间也不利于数值运算。
- TINYINT
- 错误。仅能存整数,不能满足带小数点。
- INT
- 错误。仅能存整数,且空间比 DECIMAL 大。
- FLOAT
- 错误。虽能存带小数的数,但对该分数区间不如 DECIMAL 精确且节省空间。
正确答案
- DECIMAL(4,1)
相关知识点总结
- DECIMAL(p,s):用于存储定点数,精确度高,适合财务与分数场景。p为总位数,s为小数点后位数。
- DECIMAL(4,1) 可表示从 0.0 到 999.9,适合考试分数这样的场景。
- 使用与实际业务及存储空间要求相匹配的数据类型,有助于节省空间并提升性能。
13.1.3 定点类型(精确值)- DECIMAL, NUMERIC
https://dev.mysql.com/doc/refman/8.0/en/fixed-point-types.html
核心内容与用法
- DECIMAL 与 NUMERIC 类型用于存储精确数值(exact numeric),常用于要求保存精度的场景,比如货币、分数。
- 在 MySQL 中,NUMERIC 本质实现为 DECIMAL,二者等价。
存储方式
- MySQL 以二进制格式存储 DECIMAL 类型的数据(不是简单的字符串或浮点数格式)。
精度(Precision)与小数位(Scale)
- 可以声明精度和小数位数,如:
salary DECIMAL(5,2)- 5:总有效位数(precision),即最大可以存储 5 位数字
- 2:小数位数(scale),即小数点后最多 2 位
- 上例 salary 列可存储范围:-999.99 ~ 999.99
语法规则
- 标准 SQL 规定:
DECIMAL(5,2)必须能够存储最多五位且含两位小数的数值DECIMAL(M)等价于DECIMAL(M,0),即无小数点(整数)DECIMAL若未指定 M,MySQL 默认 M=10,即DECIMAL(10,0)
- 如果 scale 为 0,则没有小数部分
最大支持
- DECIMAL 类型的最大支持精度为 65 位数字
- 实际存储的数值范围由你声明的精度和小数位决定
- 如果赋值时小数超出指定 scale,会自动截断(具体行为与操作系统相关,但一般是截取前面的部分)
实用总结
- 用 DECIMAL/NUMERIC 可以保障数值的绝对精度,不会像 FLOAT 那样产生误差,适合存储财务金额、分数等敏感数值
- 应根据需求选择合适的精度与小数位,既保证业务正确,又节省存储空间
Q30
英文原文
Statements:
\py
\use world
code='FIN'
db.city.select(['Name','Population']).where('CountryCode = :bind').order_by('1').limit(10).bind('bind', code)
Which options describe the output? (Choose three)
A. The output consists of a JSON object in each row.
B. The output consists of a JSON array in each row.
C. The output has exactly 10 rows.
D. The output has exactly two columns.
E. The output is filtered by the value in the code variable.
F. The output is sorted by the city name.
G. The output is sorted by the city population.
中文翻译题目和选项
这些语句在 MySQL Shell 中可以成功执行,下列哪些选项描述了输出结果?(选择三项)
A. 每行输出为一个 JSON 对象
B. 每行输出为一个 JSON 数组
C. 输出恰好有 10 行
D. 输出恰好有两列
E. 输出结果对 code 变量的值进行了过滤
F. 输出已经按城市名排序
G. 输出已经按城市人口排序
选项逐项解释
- A. 每行输出为一个 JSON 对象
- 错误。MySQL Shell 默认表格输出,并不是直接以 JSON 格式返回。
- B. 每行输出为一个 JSON 数组
- 错误。同上,默认不是 JSON 数组。
- C. 输出恰好有 10 行
- 错误。虽然有
limit(10),但如果过滤后不足10行,实际行数可能小于10。
- 错误。虽然有
- D. 输出恰好有两列
- 正确。只选取了
Name和Population两个字段。(正确答案)
- 正确。只选取了
- E. 输出结果对 code 变量的值进行了过滤
- 正确。
where('CountryCode = :bind')结合.bind('bind', code)会只显示CountryCode='FIN'的城市数据。(正确答案)
- 正确。
- F. 输出已经按城市名排序
- 正确。
order_by('1')意味着按第一个字段 Name 排序。(正确答案)
- 正确。
- G. 输出已经按城市人口排序
- 错误,排序依据是 Name 字段而不是 Population。
正确答案
- D. 输出恰好有两列
- E. 输出结果对 code 变量的值进行了过滤
- F. 输出已经按城市名排序
相关知识点总结
- MySQL Shell 支持以类似链式调用的方式组合条件、排序和分页。
.select([...])决定结果字段数,两列;.where()结合.bind()实现变量过滤;.order_by('1')为按第一个字段(城市名称 Name)排序;.limit(10)虽然指定返回最多 10 行,但不足时会小于 10 行。
Q31
SELECT CONCAT_WS(':', 'Result', NULL, 1+2);
What is the output?
A. NULL
B. Result:NULL:1+2
C. Result::1+2
D. Result:3
E. Result:1+2
中文翻译题目和选项
请分析以下语句的输出:
SELECT CONCAT_WS(':', 'Result', NULL, 1+2);
输出结果是什么?
A. NULL
B. Result:NULL:1+2
C. Result::1+2
D. Result:3
E. Result:1+2
选项逐项解释
A. NULL
错误。CONCAT_WS 遇到参数为 NULL 时会跳过 NULL,而不是整个结果为 NULL。
B. Result:NULL:1+2
错误。不会输出 "NULL" 字符串,NULL 被忽略。
C. Result::1+2
错误。1+2 会先运算为 3,且 NULL 被忽略,不会出现连续两个分隔符。
D. Result:3
正确。'Result' 和 1+2(计算结果为 3)通过 ':' 连接,中间 NULL 被忽略。(正确答案)
E. Result:1+2
错误。1+2 会被计算,不会直接显示表达式。
正确答案 D. Result:3
CONCAT_WS 使用详解
https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_concat-ws
函数说明
- CONCAT_WS(separator, str1, str2, ...)
- “Concatenate With Separator”的缩写,是 CONCAT() 的一种特殊形式。
- 第一个参数为分隔符,其它参数为要拼接的字符串,各字符串间会加上指定分隔符。
特点解析
-
分隔符
- 可以是任意字符串,如果分隔符为 NULL,则最终结果为 NULL。
-
行为说明
- NULL 参数(分隔符之后出现的任意 NULL)会被直接跳过,不参与拼接。
- 空字符串 "" 不会被跳过,会参与拼接,分隔符依然会出现在空字符串前后。
- 参与拼接的参数都是字符串,表达式会优先计算成结果再参与拼接。
官方示例
-
SELECT CONCAT_WS(',', 'First name', 'Second name', 'Last Name');
结果:'First name,Second name,Last Name' -
SELECT CONCAT_WS(',', 'First name', NULL, 'Last Name');
结果:'First name,Last Name'(NULL 被跳过)
总结
CONCAT_WS()可用来方便地按指定分隔符拼接多个字段(如 CSV 行、格式化输出等)。- 跳过 NULL 值可以避免意外出现无意义的“null”字符串或连续多余分隔符。
Q32
英文原文
Which can be achieved by events in a MySQL database? (Choose two)
A. Archiving old data on the first day of each month
B. Refreshing a summary table at midnight every day
C. Recording the date and time when a user connects to the database
D. Raising an alert when the MySQL instance stops
E. Creating an audit record when a row is deleted from a table
中文翻译题目和选项
在 MySQL 数据库中,通过事件(EVENTS)可以实现哪些操作?(选择两个)
A. 在每月的第一天归档旧数据
B. 每天午夜刷新汇总表
C. 记录用户连接到数据库的日期和时间
D. 当 MySQL 实例停止时触发告警
E. 当表中某行被删除时创建审计记录
选项逐项解释
-
A. 在每月的第一天归档旧数据
- 正确。可以通过 MySQL 定时事件实现定期归档,如每月1号执行SQL。
-
B. 每天午夜刷新汇总表
- 正确。事件调度器可定时触发SQL,对表进行刷新或汇总操作。
-
C. 记录用户连接到数据库的日期和时间
- 错误。MySQL 事件无法感知连接动作,需通过插件或日志实现。
-
D. 当 MySQL 实例停止时触发告警
- 错误。MySQL 事件只能在服务运行时按调度执行,无法响应实例停止。
-
E. 当表中某行被删除时创建审计记录
- 错误。这属于触发器(TRIGGER)而非事件机制,只有触发器能对数据行级操作作出实时响应。
正确答案
- A. 在每月的第一天归档旧数据
- B. 每天午夜刷新汇总表
相关知识点总结
EVENT 语句功能简介
作用说明
- EVENT 相关语句用于 MySQL 事件调度器(Event Scheduler)管理。
- 启用后,可以创建、修改、删除或查看数据库定时事件。
主要用途
- 创建(CREATE EVENT):自动化定期任务,比如月度归档、每日汇总等。
- 修改(ALTER EVENT):变更事件的调度计划或执行内容。
- 删除(DROP EVENT):移除已定义的定时事件,不再自动执行。
- 显示(SHOW EVENTS/SHOW CREATE EVENT):展示当前库内的事件定义和状态。
总结
- 启用 EVENT 权限后,可管理和调度 SQL 层面上的定时任务,属于“时间驱动类型”自动任务机制,不同于行级数据变更和连接动作的监听,后者可用 TRIGGER 或审计插件实现。
27.4.1 事件调度器概述(Event Scheduler Overview)
https://dev.mysql.com/doc/refman/8.0/en/events-overview.html
概念与作用
- MySQL Events(事件) 是一种基于时间的调度任务,类似于 Unix 系统的 crontab(定时任务)或 Windows 的任务计划程序。
- 创建事件时,会生成一个具名的数据库对象,在指定的时间点或时间间隔内自动运行某些 SQL 语句。
事件与触发器区别
- 事件(Scheduled Event):基于时间自动触发,按计划周期或一次性执行。
- 触发器(Trigger):基于表的特定数据变更(如插入、更新、删除)自动触发。
- 事件不是“临时触发器”,两者完全不同(时间驱动 vs 行为驱动)。
主要特性
- 每个事件都有唯一名称和所属的数据库(schema)。
- 事件的任务可以是单条或复合 SQL(如
BEGIN ... END块)。 - 时间调度分为:
- 一次性(one-time event):仅执行一次
- 循环(recurrent event):按规则周期运行,可设置开始/结束时间,也可无限期运行
并发说明
- 如果周期性事件在下个调度周期时前一次尚未执行完,可能会发生多个实例同时执行,所以需自行加锁(如 GET_LOCK() 或表锁、行锁)防止并发冲突。
管理与权限
- 可通过标准 SQL 语句创建、修改、删除事件,无效语法会直接报错。
- 创建事件时如包含权限不足的操作,事件能成功创建但实际动作会失败。
- 可修改的属性包括名称、时间调度、是否持久化(定期结束后是否自动删除)、启用/禁用状态、执行语句和归属 schema。
- 默认 definer 是创建者账号,也可通过 ALTER EVENT 更改,变更后 definer 更新为最后修改该事件者。
- 修改事件需有当前数据库的 EVENT 权限。
执行内容限制
- 事件动作语句可包含大多数存储过程、函数等能接受的 SQL,但仍有适用范围限制。
- 事件名不区分大小写。
- 不能在存储程序中创建或通过变量名操作事件对象。
- 拥有 LOCK TABLES 时,不能修改事件 DDL。
- 时间间隔为 YEAR、MONTH、QUARTER、YEAR_MONTH 的事件以月为粒度,其他以秒为粒度;同一秒内多个事件无法保证执行顺序,且误差最大1-2秒。
- 每次事件执行在新连接中进行,对当前会话的 SHOW STATUS 计数无影响,但会影响全局计数。
- 事件不支持 2038 年以后(Epoch 终点)时间。
- CREATE/ALTER EVENT 的 ON SCHEDULE 不支持引用存储函数、外部函数和表。
- NDB Cluster 下,存储程序、触发器不会在各 SQL 节点自动传播,需手动每节点都创建/更改,不能尝试把系统表转为 NDB。
总结
- MySQL 事件调度器是实现数据库级定时任务自动化的核心工具,适用场景广泛,如自动归档、统计报表、周期清理等。
- 需注意权限、并发管理和调度边界条件。
Q33
CREATE TABLE shapes (j JSON)
Examine this JSON document:
{"shape" : "rectangle", "sizes" : [10, 15]}
Which statements insert the JSON document into the table? (Choose two)
A. INSERT INTO shapes VALUES ('{"shape" : "rectangle", "sizes" : [10, 15]}')
B. INSERT INTO shapes VALUES (JSON_OBJECT('shape','rectangle','sizes','[10, 15]'))
C. INSERT INTO shapes VALUES (JSON_OBJECT('"shape"','"rectangle"','"sizes"','[10, 15]'))
D. INSERT INTO shapes VALUES (JSON_OBJECT('shape','rectangle','sizes',JSON_ARRAY(10,15)))
E. INSERT INTO shapes VALUES (JSON_OBJECT('"shape"','"rectangle"','"sizes"',JSON_ARRAY(10,15)))
题目与选项翻译
CREATE TABLE shapes (j JSON)
请分析如下 JSON 文档({"shape" : "rectangle", "sizes" : [10, 15]}),哪两条 SQL 能正确插入该 JSON 到表 shapes?(选两项)
A. INSERT INTO shapes VALUES ('{"shape" : "rectangle", "sizes" : [10, 15]}')
B. INSERT INTO shapes VALUES (JSON_OBJECT('shape','rectangle','sizes','[10, 15]'))
C. INSERT INTO shapes VALUES (JSON_OBJECT('"shape"','"rectangle"','"sizes"','[10, 15]'))
D. INSERT INTO shapes VALUES (JSON_OBJECT('shape','rectangle','sizes',JSON_ARRAY(10,15)))
E. INSERT INTO shapes VALUES (JSON_OBJECT('"shape"','"rectangle"','"sizes"',JSON_ARRAY(10,15)))
选项解析
A. 直接插入 JSON 字符串
正确,如果作为字符串形式插入,MySQL 能自动解析验证为合法 JSON。(正确答案)
B. JSON_OBJECT('shape','rectangle','sizes','[10, 15]')
错误,这里的 '[10, 15]' 是字符串形式,而不是有效的 JSON 数组类型,存进去就变成 text。
C. JSON_OBJECT('"shape"','"rectangle"','"sizes"','[10, 15]')
错误,参数加了引号,会被当做带引号的 key 和 value,结果内容不规范。
D. JSON_OBJECT('shape','rectangle','sizes',JSON_ARRAY(10,15))
正确,这是标准的 MySQL JSON 构造方法,字段 sizes 存储为真正的数组类型。(正确答案)
E. JSON_OBJECT('"shape"','"rectangle"','"sizes"',JSON_ARRAY(10,15))
错误,key/value 参数格式依旧不规范(多余的引号)。
正确答案
A. INSERT INTO shapes VALUES ('{"shape" : "rectangle", "sizes" : [10, 15]}')
D. INSERT INTO shapes VALUES (JSON_OBJECT('shape','rectangle','sizes',JSON_ARRAY(10,15)))
相关知识点总结
MySQL 8.0 官方文档:JSON 数据类型要点
https://dev.mysql.com/doc/refman/8.0/en/json.html
1. 基本特性
- JSON 是 MySQL 8.0 的原生数据类型(符合 RFC 8259 标准),可高效存储和查询 JSON 数据。
- 优势:
- 存储时自动校验格式,插入非法 JSON 会报错;
- 存储为内部二进制格式,便于高效读取和定位子元素,无需全表扫描。
2. JSON 列插入与存储
- 插入时可以使用合法的 JSON 字符串,MySQL 会自动解析、校验和归一化(如同名 key,只保留最后一个)。
- 也可用 SQL 函数
JSON_OBJECT()、JSON_ARRAY()构造 JSON 结构插入(推荐写复杂 JSON 时用)。 - 示例:
-- 方式一:直接插入字符串(需为合法 JSON)
INSERT INTO t1 VALUES ('{"key1": "value1", "key2": "value2"}');
-- 方式二:用内置函数
INSERT INTO t1 VALUES (JSON_OBJECT('key1', 'value1', 'key2', 'value2'));
-- 插入数组
INSERT INTO t1 VALUES ('[1,2,3]'), (JSON_ARRAY(1,2,3));
MySQL 自动去除冗余空白、统一 key 顺序(利于查询)。
3. 典型用法场景
支持存储 JSON 对象({})、数组([])、标量值(字符串/数字/布尔/null)。
支持嵌套、混合类型、灵活字段扩展、高度兼容现代 Web/API 场景。
4. 查询和操作
支持使用 ->、->>、JSON_EXTRACT() 等函数定位和提取嵌套值或数组成员。
支持用 JSON 路径表达式选取对象/数组部分数据,如 $.key, $[number], $.*
5. 更新与优化
允许用 JSON_SET()、JSON_INSERT()、JSON_REPLACE() 等函数高效局部更新(避免整字段重写,节省空间 & IO)。
更新时部分情况下利用“partial-in-place”机制,仅修改存储中变化部分,提升性能。
6. 存储限制与注意事项
单个 JSON 文档最大受 max_allowed_packet 限制,存储空间和 LONGBLOB/LONGTEXT 类似。
后台使用 utf8mb4 编码,比较、排序为二进制(区分大小写)。
JSON 字段无法直接创建索引,但可用“虚拟生成列+索引”方案优化检索效率。
7. 其他说明
2038 年之后的时间不被 JSON 事件支持(时间戳上限)。
支持 JSON 合并、聚合、类型转换、多维数组等高级操作。
8. 插入技巧回顾
直接插入字符串时需用单引号包裹,内容为合规 JSON。
用 JSON_OBJECT/JSON_ARRAY 可避免字符串拼写错误(推荐动态数据构造时使用)
适用关键点:
JSON 数据类型非常适合存储灵活结构数据和 NoSQL 风格的场景,能与结构化数据高效结合。
Q34
Examine these statements and output:
mysql> START TRANSACTION;
Query OK, 0 rows affected (0.00 sec)
mysql> UPDATE orders SET amount=500 WHERE order_id=100;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
The order_id column is the primary key of the orders table. All sessions use repeatable read isolation level by default.
Which statements will be blocked in other sessions? (Choose three)
A. UPDATE orders SET amount=100 WHERE order_id<100;
B. INSERT INTO orders (order_id,customer_id,amount) VALUES (NULL,100,100);
C. REPLACE INTO orders (order_id,customer_id,amount) VALUES (NULL,100,100);
D. REPLACE INTO orders (order_id,customer_id,amount) VALUES (100,100,100);
E. SELECT * FROM orders;
F. SELECT * FROM orders FOR SHARE;
G. UPDATE orders SET amount=amount*1.1;
中文翻译与解析
题意翻译:
主键 order_id,隔离级别 repeatable read。
问其他会话下,哪些 SQL 语句会被阻塞(Choose three)。
A. UPDATE orders SET amount=100 WHERE order_id<100;
B. INSERT INTO orders (order_id,customer_id,amount) VALUES (NULL,100,100);
C. REPLACE INTO orders (order_id,customer_id,amount) VALUES (NULL,100,100);
D. REPLACE INTO orders (order_id,customer_id,amount) VALUES (100,100,100);
E. SELECT * FROM orders;
F. SELECT * FROM orders FOR SHARE;
G. UPDATE orders SET amount=amount*1.1;
选项逐项解释
A. UPDATE orders SET amount=100 WHERE order_id<100;
只会尝试更新 order_id < 100 的行,不涉及 100,不会被阻塞。
B. INSERT INTO orders (order_id,customer_id,amount) VALUES (NULL,100,100);
插入新行,不涉及主键100,不冲突,不会被阻塞。
C. REPLACE INTO orders (order_id,customer_id,amount) VALUES (NULL,100,100);
插入新行,不涉及主键100,不冲突,不会被阻塞。
D. REPLACE INTO orders (order_id,customer_id,amount) VALUES (100,100,100);
REPLACE等价于先删除后插入,order_id=100 已经被更新并持有了排他锁,会阻塞(正确答案)。
E. SELECT * FROM orders;
普通查询,不加锁,不会被阻塞。
F. SELECT * FROM orders FOR SHARE;
会对主键100加共享锁,但此时已存在排他锁冲突,会被阻塞(正确答案)。
G. UPDATE orders SET amount=amount*1.1;
更新全表,包含order_id=100,要等排他锁释放,会被阻塞(正确答案)。
正确答案
D. REPLACE INTO orders (order_id,customer_id,amount) VALUES (100,100,100);
F. SELECT * FROM orders FOR SHARE;
G. UPDATE orders SET amount=amount*1.1;
相关知识点总结
InnoDB 在 REPEATABLE READ 下,UPDATE/REPLACE 会对涉及主键的行加排他锁。
其他写操作(如 REPLACE/UPDATE)、共享锁操作(FOR SHARE)涉及被锁主键时会阻塞至提交。
普通 SELECT 不加锁,不受事务阻塞影响。
Q35
英文原文
Examine this statement which executes successfully:
SET @j = '["a","b","b","c","d","e"]';
Now, examine this output:
[1, "b", "b", "c", "d", "e"]
Which statement produces the output?
A. SELECT JSON_ARRAYAGG(@j, '$[0]', 1);
B. SELECT JSON_SET(@j, '$[0]', 1);
C. SELECT JSON_SET(@j, '$[1]', 1);
D. SELECT JSON_ARRAYAGG(@j, '$[1]', 1);
E. SELECT JSON_ARRAY_INSERT(@j, '$[0]', 1);
F. SELECT JSON_ARRAY_INSERT(@j, '$[1]', 1);
中文翻译题目和选项
请检查以下能正确执行的语句:
SET @j = '["a","b","b","c","d","e"]';
现在,请查看这个输出:
[1, "b", "b", "c", "d", "e"]
下面哪个语句能产生该输出?
A. SELECT JSON_ARRAYAGG(@j, '$[0]', 1);
B. SELECT JSON_SET(@j, '$[0]', 1);
C. SELECT JSON_SET(@j, '$[1]', 1);
D. SELECT JSON_ARRAYAGG(@j, '$[1]', 1);
E. SELECT JSON_ARRAY_INSERT(@j, '$[0]', 1);
F. SELECT JSON_ARRAY_INSERT(@j, '$[1]', 1);
题意解析
- 先定义 @j 为 JSON 数组
["a","b","b","c","d","e"] - 输出结果为
[1, "b", "b", "c", "d", "e"],即第 0 个元素 "a" 被替换成了 1,其余保持不变。 - 问哪个 SQL 语句能完成此效果。
选项逐项解释
- A. SELECT JSON_ARRAYAGG(@j, '$[0]', 1);
- JSON_ARRAYAGG 是聚合函数,用于收集多行,不适用于设置/替换单个元素,语法不对。
- B. SELECT JSON_SET(@j, '$[0]', 1);
- 正确答案。
- JSON_SET(@j, '$[0]', 1) 会将 JSON 数组 @j 第 0 个元素设为 1。即输出
[1, "b", "b", "c", "d", "e"]。
- C. SELECT JSON_SET(@j, '$[1]', 1);
- 会将第 1 个元素 "b" 替换成 1,结果变为
["a", 1, "b", "c", "d", "e"],与目标输出不符。
- 会将第 1 个元素 "b" 替换成 1,结果变为
- D. SELECT JSON_ARRAYAGG(@j, '$[1]', 1);
- 与 A 类似,聚合函数,不适用。
- E. SELECT JSON_ARRAY_INSERT(@j, '$[0]', 1);
- JSON_ARRAY_INSERT 会插入而不是替换。这样会在数组最前面插入 1,得到
[1, "a", "b", "b", "c", "d", "e"],与目标不符。
- JSON_ARRAY_INSERT 会插入而不是替换。这样会在数组最前面插入 1,得到
- F. SELECT JSON_ARRAY_INSERT(@j, '$[1]', 1);
- 会在索引 1 处插入 1,得到
["a", 1, "b", "b", "c", "d", "e"],与目标不符。
- 会在索引 1 处插入 1,得到
正确答案
- B. SELECT JSON_SET(@j, '$[0]', 1);
相关知识点总结
- JSON_SET(json_doc, path, val) 用于将指定路径上的值修改为新值,不改变其他路径内容。
- 如果目标是“替换”元素,则用 JSON_SET;想“插入新元素”用 JSON_ARRAY_INSERT。
- 聚合函数如 JSON_ARRAYAGG 用于将多行变为一个 JSON 数组,在本场景不适用。
- JSON 路径如
$[0]表示数组的第 0 个元素。
Q36
(怀疑题目来源有问题,暂定选D)
The collection col contains all episodes for all seasons for a TV show.
Examine this document which has an example of the details for each episode:
{
"_id": "00005cbee2d100000000000001",
"name": "Days Gone Bye",
"number": 1,
"season": 1,
"airdate": "2010-10-31",
"airtime": "22:00",
"runtime": 60
}
Which query returns all episode names from the first season?
A. SELECT doc->>'$.name' FROM col WHERE doc->>'$.season' = "1";
B. SELECT "$.name" FROM col WHERE "$.season" = "1";
C. SELECT doc->'$.name' FROM col WHERE doc->'$.season' = "1";
D. SELECT name FROM col WHERE season = 1;
题目翻译
集合 col 包含了一部电视剧所有季的所有剧集。
请查看下面这份剧集文档的示例:
{
"_id": "00005cbee2d100000000000001",
"name": "Days Gone Bye",
"number": 1,
"season": 1,
"airdate": "2010-10-31",
"airtime": "22:00",
"runtime": 60
}
问题:下列哪个查询能返回第一季所有剧集的名称?
A. SELECT doc->>'$.name' FROM col WHERE doc->>'$.season' = "1";
B. SELECT "$.name" FROM col WHERE "$.season" = "1";
C. SELECT doc->'$.name' FROM col WHERE doc->'$.season' = "1";
D. SELECT name FROM col WHERE season = 1;
中文解析
选项分析:
- A. SELECT doc->>'$.name' FROM col WHERE doc->>'$.season' = "1";
不确定。 题目中没有提到doc列,如果提到了doc列就是A正确
- B. SELECT "$.name" FROM col WHERE "$.season" = "1";
这不是标准 SQL 写法,不成立。错误
- C. SELECT doc->'$.name' FROM col WHERE doc->'$.season' = "1";
错误。
题目中没有提到doc列,且 doc->'$.season' 提取season字段作为JSON数值(不是字符串)。在WHERE子句中,doc->'$.season' = "1" 比较JSON数值和字符串"1",可能导致类型不匹配:JSON数值1与字符串"1"在MySQL中等同于比较整数和字符串,通常返回false(不相等)。
doc->'$.name' 提取name作为JSON字符串(输出可能保留引号,例如""Days Gone Bye""),不符合输出纯字符串剧集名称的要求。
查询可能无法匹配第一季的剧集,或输出格式不正确。
- D. SELECT name FROM col WHERE season = 1;
不确定,如果题干里是平铺字段(name, season 等直接是列名),暂定 D 选项是正确答案。
答案:D
MySQL 文档存储:Collections 与 Documents 基础
https://dev.mysql.com/doc/refman/8.0/en/mysql-shell-tutorial-javascript-documents-collections.html
简介
本节主要介绍如何在 MySQL 文档存储(Document Store)中使用集合(Collections)和文档(Documents)。集合是 Schema(类似于数据库)下的容器,用于存储 JSON 文档。你可以对集合进行创建、列举、删除等操作,并对文档进行添加、查找、修改和删除等 CRUD 操作。
概念介绍
1. 集合(Collections)与文档(Documents)概述
- 集合(Collection):Schema(即数据库)下存放 JSON 文档的容器。每个集合具有唯一名称,且仅存在于一个 schema 中。集合之间可以共享索引。
- 文档(Document):存储为 JSON 对象的记录,可包含数字、字符串、布尔值、null、数组和嵌套对象。文档内部以高效二进制格式存储,以加快查找和更新。
- Schema 本义:在文档存储下,schema 等同于实际数据库(Database),而不像关系型数据库那样强制结构和约束。
2. 基本对象及其作用
| 对象形式 | 说明 |
|---|---|
db |
全局变量,代表当前活跃 schema。用来调用集合操作方法。 |
db.getCollections() |
获取当前 schema 下所有集合的列表,可用于遍历和引用集合对象。 |
3. 集合的基本操作
| 操作形式 | 说明 |
|---|---|
db.name.add() |
向名为 name 的集合中插入一个或多个文档 |
db.name.find() |
查询集合中的部分或所有文档 |
db.name.modify() |
修改集合中的文档 |
db.name.remove() |
删除集合中的一个或多个文档 |
4. 文档与数据类型
-
文档格式示例(JavaScript):
{field1: "value", field2: 10, "field 3": null} -
文档数组示例:
[{"Name": "Aruba", "Code:": "ABW"}, {"Name": "Angola", "Code:": "AGO"}] -
MySQL JSON 支持的类型:
- 数字(整数/浮点)
- 字符串
- 布尔值(true/false)
- null
- 数组
- 嵌套对象
5. 相关操作
- 创建、列举、删除集合
- 向集合添加、查找、修改、移除文档
- 关联索引的创建与删除
6. 拓展阅读
- 进一步操作与高级用法可查阅“Working with Collections”章节和“CRUD EBNF定义”等参考资料。
- world_x 示例库的安装可查阅 22.3.2 小节。
知识点总结
- 集合(Collection) —— 存放 JSON 文档的容器,对应表的作用,但不强制结构。
- 文档(Document) —— 实际存储的数据单元,采用灵活的 JSON 格式。
- 基本 CRUD 操作 —— add、find、modify、remove,链式操作非常直观,便于开发。
- db 全局变量用法 —— 集合所有操作都以 db 为起点。
- MySQL 的 JSON 数据类型 —— 兼容多种 JS 数据结构,便于灵活设计文档模型。
MySQL 官方文档(8.0):JSON 路径查询
官方文档地址
https://dev.mysql.com/doc/refman/8.0/en/json.html#json-paths
1. JSON 路径(JSON Path)简介
- JSON 路径用于从 JSON 文档中提取、修改数据,是各种 JSON 函数(如
JSON_EXTRACT()、JSON_SET()等)的核心参数。 - 路径表达式的书写方式与 ECMAScript/JavaScript 标准类似,方便开发者理解和操作。
2. 路径表达式基本语法
- 路径以
$开头,代表 JSON 文档的根。 - 属性使用点号(
.)连接,如$.name。 - 属性值为对象的键名,数组用中括号
[n]指定下标(下标从0开始),如$[0]、$.arr[2]。 - 非法标识符(如有空格、特殊字符的键名)使用双引号包裹,如
$.["some key"]。 - 通配符:
*可用于匹配所有键或所有数组元素。例如,$.*匹配所有顶层成员,$[1].arr[*]匹配嵌套数组所有元素。 **用于递归匹配任意深度的嵌套元素,如$**.id会查找所有层级下名为id的成员。
3. 常用提取操作示例
- 单元素提取
SELECT JSON_EXTRACT('{"id":1,"name":"Tom"}', '$.name');
-- 结果: "Tom"
- 其他函数操作
在 MySQL 8.0+ 原生支持 JSON 类型后,除了 JSON_EXTRACT() 外,还提供了丰富且强大的一次性查询、判断、遍历以及修改 JSON 文档的函数和语法,可以灵活完成绝大多数实际业务下的 JSON 检索、定位、改写、过滤和关联等需求。
常用 JSON 查询功能函数与操作符
-
箭头操作符(-> 与 ->>)
- json字段名->'$.json属性',直接在 SQL 语句中使用,比 JSON_EXTRACT 简洁。
->:返回原始 JSON(带引号/不转类型)->>:返回内层标量值(去掉引号、转成原生类型)- 示例:
SELECT col->'$.key' FROM t; -- 返回 JSON SELECT col->>'$.name' FROM t; -- 返回字符串 SELECT col->'$.skills[1]' FROM t; -- 返回第二个技能 ->当做where查询要注意数据类型,->>是不用注意数据类型
-
JSON_CONTAINS_PATH
- 判断 JSON 文档是否包含某条路径上的数据
SELECT JSON_CONTAINS_PATH(col, 'one', '$.foo'); - 返回 1(存在)/0(不存在)
- 判断 JSON 文档是否包含某条路径上的数据
-
JSON_CONTAINS
- 判断指定目标 JSON 是否存在于文档给定路径下
SELECT JSON_CONTAINS('{"a":1,"b":2}', '1', '$.a');
- 判断指定目标 JSON 是否存在于文档给定路径下
-
JSON_UNQUOTE
- 去除 JSON 字符串外围引号,方便直接用作原生字符串处理
SELECT JSON_UNQUOTE(col->'$.desc') FROM t;
- 去除 JSON 字符串外围引号,方便直接用作原生字符串处理
-
JSON_SEARCH
- 在 JSON 文档层级里递归查找某值(模糊/精确),支持通配符
SELECT JSON_SEARCH(col, 'all', '目标字符串'); - 返回匹配路径的数组
- 在 JSON 文档层级里递归查找某值(模糊/精确),支持通配符
-
JSON_VALUE (MySQL 8.0.21+)
- 直接提取标量值,比
->>更灵活(尤其是与普通列混用时)SELECT JSON_VALUE(col, '$.name') AS name FROM t;
- 直接提取标量值,比
复合条件/嵌套/数组数据搜索
-
WHERE + JSON 运算符
- 可以直接用于筛选复杂 JSON 结构
SELECT * FROM user WHERE data->'$.age' > 18; SELECT * FROM orders WHERE orders.info->'$.items[0].price' > 100;
- 可以直接用于筛选复杂 JSON 结构
-
JSON_TABLE(MySQL 8.0.4+,高级用法)
- 将 JSON 数组/对象“虚拟化”为可直接 JOIN/WHERE 的普通关系型表结构列
- 强烈建议用于复杂业务查询及报表
- 示例:
SELECT * FROM my_table, JSON_TABLE(my_table.doc, '$.books[*]' COLUMNS( name VARCHAR(32) PATH '$.name', price DECIMAL(7,2) PATH '$.price' )) AS jt WHERE price > 50;
聚合与统计
- 聚合统计时可用 JSON_ARRAYAGG, JSON_OBJECTAGG 等
- 可直接 GROUP BY JSON 字段或提取子字段做聚合分组
其他常用 JSON 查询相关函数
JSON_KEYS()获取 JSON 对象的所有 keyJSON_LENGTH()统计长度,判断是否为空JSON_TYPE()判断指定路径上的值类型JSON_DEPTH()获取层级深度JSON_OVERLAPS()判断两个对象/数组是否存在交集(8.0.17+)JSON_EXISTS()判断是否存在路径(8.0.17+)
实际案例
查找所有包含关键字“foo”的记录
SELECT * FROM table1
WHERE JSON_SEARCH(json_col, 'all', 'foo') IS NOT NULL;
Q37
英文原文
Which two are true about indexes?
A. Secondary index access will always be faster than a table scan.
B. Indexes reduce disk space used.
C. Indexes are used to enforce unique constraints.
D. Indexes contain rows sorted by key values.
E. Indexing all of a table's columns improves performance.
中文翻译
以下关于索引,哪两项是正确的?
A. 二级索引访问总是比全表扫描快。
B. 索引可以减少磁盘空间的使用。
C. 索引用于强制执行唯一约束。
D. 索引包含按键值排序的行。
E. 对表的所有列都建立索引会提升性能。
选项解析
-
A. 二级索引访问总是比全表扫描快。
—— 错误。虽然索引可以提高查询速度,但不是所有情况下都比全表扫描快,尤其在数据量很小或选择性很差的情况下。 -
B. 索引可以减少磁盘空间的使用。
—— 错误。索引会额外占用磁盘空间,因为它们会存储额外的结构来支持高效查找。 -
C. 索引用于强制执行唯一约束。
—— 正确。例如,唯一索引(UNIQUE INDEX)可以确保某字段值不重复,经常用于主键或唯一键的约束。 -
D. 索引包含按键值排序的行。
—— 正确多数情况下(如B+树索引),索引结构中的数据是按键值有序排列的,便于高效检索。 -
E. 对表的所有列都建立索引会提升性能。
—— 错误。建立太多索引不仅浪费空间,还会降低插入、更新的性能,且通常没有必要为所有列都添加索引。
正确答案
C. Indexes are used to enforce unique constraints.
D. Indexes contain rows sorted by key values.
相关知识点总结
- 索引(Index) 可以提高数据库查询性能,但会带来一定的空间和维护成本。
- 唯一约束(Unique Constraint) 一般依赖唯一索引帮助实现。
- 大部分索引(如B+树)都保持键值有序,便于范围查找。
- 不是所有的场景索引都优于全表扫描,尤其在小表或返回结果集很大的时候。
- 给所有字段都建索引会适得其反,只应给经常作为查询条件的字段建立索引。
Q38
英文原题
Examine these statements which execute successfully:
CREATE TABLE `users` (
`user_id` int NOT NULL AUTO_INCREMENT,
`loc_id` int DEFAULT NULL,
`user_static` int NOT NULL DEFAULT '0',
`user_unit` varchar(50) DEFAULT NULL,
`user_recorded` int NOT NULL DEFAULT '-1',
`user_superadmin` int NOT NULL DEFAULT '0',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
CREATE TABLE `locations` (
`loc_id` int NOT NULL AUTO_INCREMENT,
`site_id` int NOT NULL,
`loc_name` varchar(50) NOT NULL,
`loc_shared` int NOT NULL DEFAULT '0',
`loc_mapping` char(36) NOT NULL,
PRIMARY KEY (`loc_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
SELECT usr.user_id,
usr.user_unit,
loc.loc_shared
FROM users usr
INNER JOIN locations loc
ON usr.loc_id = loc.loc_id
WHERE loc.loc_mapping = 'daa9a225-8a4d-11ea-b3cf-00059a3c7a00';
Which two options would create covering indexes?
A users table user_id
B locations table loc_mapping
C locations table loc_mapping and loc_shared
D users table user_unit and loc_id
E locations table loc_id and loc_shared
F locations table loc_shared
G users table loc_id
中文翻译
给定如下两张表结构和一条 SQL 查询:
CREATE TABLE `users` (
`user_id` int NOT NULL AUTO_INCREMENT,
`loc_id` int DEFAULT NULL,
`user_static` int NOT NULL DEFAULT '0',
`user_unit` varchar(50) DEFAULT NULL,
`user_recorded` int NOT NULL DEFAULT '-1',
`user_superadmin` int NOT NULL DEFAULT '0',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
CREATE TABLE `locations` (
`loc_id` int NOT NULL AUTO_INCREMENT,
`site_id` int NOT NULL,
`loc_name` varchar(50) NOT NULL,
`loc_shared` int NOT NULL DEFAULT '0',
`loc_mapping` char(36) NOT NULL,
PRIMARY KEY (`loc_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
SELECT usr.user_id,
usr.user_unit,
loc.loc_shared
FROM users usr
INNER JOIN locations loc
ON usr.loc_id = loc.loc_id
WHERE loc.loc_mapping = 'daa9a225-8a4d-11ea-b3cf-00059a3c7a00';
下列哪两项可以创建覆盖索引,使上述 SQL 查询所需的所有字段都能直接从索引中获取?
A. users 表 user_id
B. locations 表 loc_mapping
C. locations 表 loc_mapping 和 loc_shared
D. users 表 user_unit 和 loc_id
E. locations 表 loc_id 和 loc_shared
F. locations 表 loc_shared
G. users 表 loc_id
解释
users 表 user_id是主键
locations 表 loc_id 是主键
sql 中用到的列有 usr.user_id ,usr.user_unit,loc.loc_shared,usr.loc_id,loc.loc_id,loc.loc_mapping
usr.user_id 、loc.loc_id是主键,本身有主键索引,故不考虑这两列,只剩下 usr.user_unit,usr.loc_id,loc.loc_shared,loc.loc_mapping
1. A users 表 user_id
- 只对
user_id字段建索引。 - 仅覆盖输出字段之一,不能用于 JOIN 或 WHERE 条件。
- 不是覆盖索引。
2. B locations 表 loc_mapping
- 只对
loc_mapping建索引。 - WHERE 使用了
loc_mapping,但 SELECT 还需loc_shared,JOIN 需loc_id。 - 不是覆盖索引。
3. C locations 表 loc_mapping 和 loc_shared
- 对
loc_mapping, loc_shared建复合索引。 - WHERE 用到
loc_mapping,SELECT 用到loc_shared,JOIN 用到loc_id(loc_id 为主键,InnoDB 索引会自动带上主键)。 - 这个索引可以覆盖 locations 表在本查询中所有用到的字段。
- 是覆盖索引。
4. D users 表 user_unit 和 loc_id
- 对
user_unit, loc_id建复合索引。 - 只覆盖 users 表的
user_unit和loc_id字段,不用考虑user_id字段(loc_id 为主键,InnoDB 索引会自动带上主键)。 - 是覆盖索引。
5. E locations 表 loc_id 和 loc_shared
- 对
loc_id, loc_shared建复合索引。 - JOIN 用到
loc_id,SELECT 用到loc_shared,但 WHERE 用到的loc_mapping不在此索引前缀。 - 不是覆盖索引。
6. F locations 表 loc_shared
- 只对
loc_shared建索引。 - 仅覆盖 SELECT 的一个字段,不满足 WHERE 和 JOIN 需求。
- 不是覆盖索引。
7. G users 表 loc_id
- 只对
loc_id字段建索引。 - 用于 JOIN,但不覆盖 SELECT 所需的所有字段。
- 不是覆盖索引。
正确答案
C. locations 表 loc_mapping 和 loc_shared
D. users 表 user_unit 和 loc_id
covering index(覆盖索引)概念总结
定义
覆盖索引(covering index):
指包含了查询所需所有列的索引。查询时,数据库可以直接从索引结构中返回所需数据,无需再通过索引去主表查找(回表),从而节省磁盘 I/O。
作用与优化
- 当查询所需的所有字段都包含在某个索引中时,该索引就是覆盖索引。
- 查询可直接从索引中获取结果,极大提高查询效率。
- 在 InnoDB 存储引擎中,二级索引(secondary index)自动包含主键字段,因此可以比 MyISAM 更广泛地利用覆盖索引优化。
- 但如果表被事务修改(未提交),InnoDB 不能对这些行应用覆盖索引优化,必须等事务结束。
设计建议
- 任何单列索引或复合索引,都可以在合适的查询下成为覆盖索引。
- 设计索引和查询时应尽量利用这一优化技巧,提升性能。
InnoDB 辅助索引包含主键
InnoDB 的二级索引(非主键索引)会自动包含主键字段,因此如果 SELECT/JOIN 只涉及主键和索引字段,依然可以实现覆盖索引。
复合索引的字段顺序
复合索引应优先包含 WHERE、JOIN、SELECT 用到的字段,且 WHERE 字段应放在索引前缀。
索引设计建议
只为查询频繁的字段设计复合索引,避免无谓的空间和写入性能损耗。
Q39
英文原题
Examine the layout of the employees table.
CREATE TABLE employees (
emp_no int NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
network_name varchar(15) NOT NULL,
gender enum('M','F') NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no),
UNIQUE KEY network_name (network_name),
KEY hire_date (hire_date)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
Which column in the employees table represents the table's clustered index?
A. emp_no
B. gender
C. hire_date
中文翻译题目和选项
请检查如下 employees 表的表结构。
下列哪个字段在 employees 表中代表聚集索引(clustered index)?
A. emp_no
B. gender
C. hire_date
题干含义讲解
本题考查 MySQL(尤其是InnoDB引擎)中聚集索引的概念:
- 在 InnoDB 存储引擎中,聚集索引就是按照主键(PRIMARY KEY)的顺序组织的行数据,因此主键就是聚集索引。
- 其它索引如 unique key,普通 key,都是辅助索引(secondary index),不会影响数据的物理存储顺序。
选项逐项解析
-
A. emp_no
该字段是表的主键(PRIMARY KEY),InnoDB会把主键作为聚集索引。所有表数据会按 emp_no 的顺序物理存储。(正确答案) -
B. gender
只是一个普通的字段,没有定义为主键或索引。不是聚集索引。 -
C. hire_date
虽然定义了普通二级索引(KEY),但不会成为聚集索引,数据不会按此字段物理存储。
正确答案
A. emp_no
17.6.2.1 InnoDB 聚簇索引与辅助索引
https://dev.mysql.com/doc/refman/8.0/en/innodb-index-types.html
聚簇索引(Clustered Index)
- 每一个 InnoDB 表都有一个称为聚簇索引(clustered index)的特殊索引,用来存储行数据。
- 聚簇索引通常就是主键(PRIMARY KEY)索引:
- 如果表有 PRIMARY KEY,InnoDB 会直接将其作为聚簇索引。
- 强烈建议每个表都定义一个主键(如没有合适的主键,可以加一个自增列)。
- 没有明确定义主键时,若有第一个全部为 NOT NULL 的 UNIQUE 索引,则 InnoDB 用其作为聚簇索引。
- 如果既没有主键,也没有合适的唯一索引:
- InnoDB 会自动生成一个隐藏的聚簇索引(
GEN_CLUST_INDEX),内容是 6 字节行 ID,随插入递增。 - 数据以行 ID 插入的顺序存储。
- InnoDB 会自动生成一个隐藏的聚簇索引(
聚簇索引为什么速度快
- 通过聚簇索引访问行效率很高,因为索引查找直接定位到包含该行数据的物理页。
- 对于大表,这种结构通常能比其他数据组织方式少一次磁盘 I/O。
辅助索引(Secondary Index)与聚簇索引的关系
- 除聚簇索引外的其它索引都叫辅助索引(secondary index)。
- InnoDB 的每个辅助索引记录中都包含:
- 该行的主键字段;
- 以及辅助索引本身定义的字段。
- 辅助索引工作流程:
- 先用辅助索引确定主键值;
- 再用主键值到聚簇索引中查找完整行数据。
- 如果主键字段很长,会导致辅助索引占用更多空间,因此建议主键尽量精简。
设计建议
- 优先为每个表选取短小且唯一的主键,可提升空间与性能。
- 充分利用聚簇/辅助索引优化查询与 DML(增删改)操作。
Q40
英文原题
Examine this statement:
DELIMITER //
CREATE PROCEDURE get_num_emp()
BEGIN
INSERT INTO employee (emp_id, emp_name) VALUES (102, 'John');
SELECT COUNT(*) INTO @m FROM employee;
END;
//
What is required to create this procedure successfully?
A. user who creates the procedure needing the CREATE and EXECUTE privileges
B. inserting DEFINER 'username'@'localhost' clause into the CREATE PROCEDURE statement
C. user who creates the procedure needing the CREATE ROUTINE privilege
D. inserting USE
E. inserting COMMIT; SET @m = 0; before line 4
中文翻译题目和选项
请检查如下CREATE PROCEDURE语句:
DELIMITER //
CREATE PROCEDURE get_num_emp()
BEGIN
INSERT INTO employee (emp_id, emp_name) VALUES (102, 'John');
SELECT COUNT(*) INTO @m FROM employee;
END;
//
要成功创建该存储过程,需要什么条件?
A. 创建者需要有 CREATE 和 EXECUTE 权限
B. 在 CREATE PROCEDURE 语句中插入 DEFINER 'username'@'localhost' 子句
C. 创建该过程的用户需要有 CREATE ROUTINE 权限
D. 在第3行之前插入 USE
E. 在第4行之前插入 COMMIT; SET @m = 0;
题干含义讲解
本题考查 MySQL 创建存储过程(PROCEDURE)的权限需求:
- 在 MySQL 中,创建存储过程需要专门的
CREATE ROUTINE权限。 - 并不需要在创建时添加
DEFINER子句、特定的 COMMIT/SET 语句或强制添加 USE 语句。 CREATE和EXECUTE权限分别用于表和过程的创建/执行,但创建存储过程的关键权限是CREATE ROUTINE。
选项逐项解析
- A. CREATE 和 EXECUTE 权限为常规表和数据操作权限,但创建存储过程必须有 CREATE ROUTINE 权限。
- B. DEFINER 子句用于指定运行该过程的账号,并不是创建的必要前提。
- C. 创建者必须具备 CREATE ROUTINE 权限才能成功创建存储过程。(正确答案)
- D. USE
只是指定当前数据库环境,不是创建存储过程所必需。 - E. COMMIT 和 SET @m = 0; 不影响过程的创建,只影响逻辑实现。
正确答案
C. user who creates the procedure needing the CREATE ROUTINE privilege
MySQL CREATE PROCEDURE 和 CREATE FUNCTION 语法中文总结
1. 基本语法说明
MySQL 提供了 CREATE PROCEDURE 用于创建存储过程,CREATE FUNCTION 用于创建存储函数。二者都属于存储例程(Stored Routine),可用于封装业务逻辑,提升 SQL 复用性及安全性。
- 存储过程和函数都可以指定创建者(
DEFINER),并支持多种参数类型和安全特性。 - 存储过程和函数关联默认数据库,也可显式指定为
db_name.sp_name。
语法结构
CREATE [DEFINER = 用户]
PROCEDURE [IF NOT EXISTS] 过程名 ([参数列表])
[特性 ...] 过程体
CREATE [DEFINER = 用户]
FUNCTION [IF NOT EXISTS] 函数名 ([参数列表])
RETURNS 返回类型
[特性 ...] 函数体
2. 参数类型与用法
- 参数列表必须写在括号内,无参数时写
() - 存储过程参数可为
IN(输入)、OUT(输出)、INOUT(输入输出);默认是IN - 存储函数参数只能为
IN - 参数的数据类型需为合法的 MySQL 数据类型
- 过程和函数的参数名不区分大小写
3. 权限及安全性
- 创建存储例程需要
CREATE ROUTINE权限 - 若指定
DEFINER,权限校验依赖于该用户 - 创建者默认拥有
ALTER ROUTINE和EXECUTE权限 SQL SECURITY可指定为DEFINER(默认,按创建者权限)或INVOKER(按调用者权限)
4. 特性说明
- COMMENT:可添加注释,便于管理
- LANGUAGE SQL:目前仅支持 SQL
- DETERMINISTIC / NOT DETERMINISTIC:声明例程是否确定性(相同输入是否总返回相同结果)。默认是
NOT DETERMINISTIC - CONTAINS SQL / NO SQL / READS SQL DATA / MODIFIES SQL DATA:标记例程对 SQL 数据的操作范围
- SQL SECURITY:指定安全上下文(见上文)
5. 存储过程与函数的区别
| 特性 | 存储过程(PROCEDURE) | 存储函数(FUNCTION) |
|---|---|---|
| 返回值 | 可用 OUT/INOUT 参数 | 必须用 RETURN 返回值 |
| 调用方式 | 用 CALL 语句 | 可在表达式中直接调用 |
| 结果集 | 可以返回结果集 | 不允许返回结果集 |
| 事务 | 支持事务控制 | 不支持事务控制 |
| 用途 | 多用于批量操作、写操作 | 多用于计算和返回结果 |
6. 使用示例
存储过程示例
DELIMITER //
CREATE PROCEDURE citycount(IN country CHAR(3), OUT cities INT)
BEGIN
SELECT COUNT(*) INTO cities FROM world.city
WHERE CountryCode = country;
END//
DELIMITER ;
调用方法:
CALL citycount('JPN', @cities);
SELECT @cities;
存储函数示例
CREATE FUNCTION hello(s CHAR(20))
RETURNS CHAR(50) DETERMINISTIC
RETURN CONCAT('Hello, ', s, '!');
调用方法:
SELECT hello('world');
7. 其他注意事项
- 存储过程可包含 DDL 语句和事务控制(如 COMMIT/ROLLBACK),函数不允许
- 存储函数不能有返回结果集的语句(如无 INTO 的 SELECT)
- 例程创建时会记录当前
sql_mode,执行时强制使用该模式 - 例程名如与内置函数相同,定义或调用时需在名称和括号间加空格
- 参数、返回值建议显式声明字符集和排序规则,避免因数据库默认设置变更带来影响
- 例程参数不能在内部 prepared statements 中引用
- 不允许在例程中使用
USE语句,例程执行期间会自动切换到关联数据库
8. 常见问题
- 权限不足导致创建或执行失败
- 参数类型未正确声明导致运行异常
- 存储函数错误包含了结果集返回语句
- 事务控制语句误用在存储函数中
- 字符集、排序规则不一致导致数据异常
9. 参考链接
Q41
英文原题
The employee table includes these columns:
e_id INT, e_name VARCHAR(45), dept_id INT, salary INT
You must create a stored function, getMaxSalary(), which returns the maximum salary paid for a given department id.
Which statement will create the function?
A.
CREATE FUNCTION getMaxSalary(v_dept_id INT) RETURNS INT
DECLARE msalary INT;
BEGIN
SELECT MAX(salary) INTO msalary FROM employee WHERE dept_id = v_dept_id;
getMaxSalary := msalary;
RETURN;
END
B.
CREATE FUNCTION getMaxSalary(v_dept_id INT) RETURNS INT
DETERMINISTIC
BEGIN
DECLARE msalary INT;
USE schemaName;
SELECT MAX(salary) INTO msalary FROM employee WHERE dept_id = v_dept_id;
RETURN msalary;
END
C.
CREATE FUNCTION getMaxSalary(v_dept_id INT) RETURNS CHAR(50)
BEGIN
SELECT MAX(salary) INTO @m FROM employee WHERE dept_id = v_dept_id;
RETURN m;
END
D.
CREATE FUNCTION getMaxSalary(v_dept_id INT) RETURNS INT
DETERMINISTIC
BEGIN
DECLARE msalary INT;
SELECT MAX(salary) INTO msalary FROM employee WHERE dept_id = v_dept_id;
RETURN msalary;
END
中文题目解析
employee 表包含以下字段:
e_id(INT),e_name(VARCHAR(45)),dept_id(INT),salary(INT)
你需要创建一个存储函数 getMaxSalary(),它用来返回指定部门编号下的最高工资。
问:以下哪一条语句能正确创建该函数?
A.
CREATE FUNCTION getMaxSalary(v_dept_id INT) RETURNS INT
DECLARE msalary INT;
BEGIN
SELECT MAX(salary) INTO msalary FROM employee WHERE dept_id = v_dept_id;
getMaxSalary := msalary;
RETURN;
END
B.
CREATE FUNCTION getMaxSalary(v_dept_id INT) RETURNS INT
DETERMINISTIC
BEGIN
DECLARE msalary INT;
USE schemaName;
SELECT MAX(salary) INTO msalary FROM employee WHERE dept_id = v_dept_id;
RETURN msalary;
END
C.
CREATE FUNCTION getMaxSalary(v_dept_id INT) RETURNS CHAR(50)
BEGIN
SELECT MAX(salary) INTO @m FROM employee WHERE dept_id = v_dept_id;
RETURN m;
END
D.
CREATE FUNCTION getMaxSalary(v_dept_id INT) RETURNS INT
DETERMINISTIC
BEGIN
DECLARE msalary INT;
SELECT MAX(salary) INTO msalary FROM employee WHERE dept_id = v_dept_id;
RETURN msalary;
END
选项解析
-
A选项:
- 语法错误。MySQL 函数体的 DECLARE 必须放在 BEGIN 之后,且 getMaxSalary := msalary; 这种赋值写法和 RETURN; 用法错误。RETURN 应直接返回数值。
-
B选项:
- 加了
DETERMINISTIC(可选,表明相同输入返回同结果) - USE schemaName; 是无效的,不能在函数内部使用。
- 剩下部分与 D 选项类似。
- 加了
-
C选项:
- 返回值类型错,用 CHAR(50);而工资应是 INT。
- SELECT 结果到用户变量 @m,再 RETURN m,也是不正确的写法。
-
D选项(正确答案):
- 语法完全正确。
- 指定参数类型、返回类型,函数体内申明变量、查询并赋值、正确返回结果。
正确答案
D. CREATE FUNCTION getMaxSalary(v_dept_id INT) RETURNS INT DETERMINISTIC BEGIN DECLARE msalary INT; SELECT MAX(salary) INTO msalary FROM employee WHERE dept_id = v_dept_id; RETURN msalary; END
相关知识点总结
- 创建 MySQL 存储函数必须指定参数、返回值类型、函数体(用 BEGIN...END 包裹)。
- DECLARE 用于申明局部变量,必须在 BEGIN 的第一行出现。
- DETERMINISTIC 修饰符表明函数是确定性的(可选,但规范)。
- 赋值、查询用 SELECT ... INTO ... 方式。
- RETURN 语句需直接返回值,不要再用函数名赋值。
- 返回类型必须和实际需要一致,如工资应为 INT。
MySQL CREATE FUNCTION 语法结构说明
CREATE
[DEFINER = user]
FUNCTION [IF NOT EXISTS] sp_name ([func_parameter[,...]])
RETURNS type
[characteristic ...] routine_body
解释
-
CREATE
用于声明创建一个新的函数(Function)。 -
[DEFINER = user]
可选,指定这个函数的定义者(拥有者)是谁。格式如:DEFINER = 'username'@'host'。 -
FUNCTION [IF NOT EXISTS] sp_name ([func_parameter[,...]])
FUNCTION:声明要创建的是函数。[IF NOT EXISTS]:可选,只有在该函数不存在时才创建(MySQL 8.0.29及以上支持)。sp_name:指定函数名。([func_parameter[,...]]):函数参数列表,多个参数用逗号分隔。
-
RETURNS type
必须,指定函数的返回数据类型,如INT、VARCHAR(100)等。 -
[characteristic ...]
可选,函数的特性,包括:LANGUAGE SQL:声明语言为 SQL(默认)。[NOT] DETERMINISTIC:是否确定性(参数相同结果始终一样)。CONTAINS SQL/NO SQL/READS SQL DATA/MODIFIES SQL DATA:对数据读写的声明。COMMENT 'string':注释。
-
routine_body
函数执行体,可以是:- 一个单独的 SQL 表达式(如:
RETURN x + 1;)。 - 或者是一个复合语句(
BEGIN ... END,可含多条 SQL 语句)。
- 一个单独的 SQL 表达式(如:
结构化总结
- CREATE FUNCTION 用于定义自定义函数。
- 必须指定函数名、参数、返回类型以及函数体。
- 可附加指定创建者、函数是否“确定性”、注释等特性修饰符。
- 复合语句函数体须用
BEGIN ... END包裹。 - 建议详细标注函数的行为特性(如 DETERMINISTIC、READS/NO SQL DATA 等),便于维护和优化。
示例:
CREATE FUNCTION addNums(a INT, b INT) RETURNS INT
DETERMINISTIC
RETURN a + b;
或
CREATE FUNCTION getUpper(s VARCHAR(20)) RETURNS VARCHAR(20)
DETERMINISTIC
BEGIN
RETURN UPPER(s);
END;
15.6.1 BEGIN ... END 复合语句
BEGIN ... END 用于在 MySQL(及其他类似SQL数据库)中定义复合语句块,让你可以把多条 SQL 语句组合成一个整体,在存储过程、函数、触发器、事件等“存储程序”里使用。
具体用途
-
分组多条语句
- 可以在一个逻辑块内连续执行多步操作,而不仅仅是一条简单的 SQL 语句。
-
结构化编程
- 支持条件(IF)、循环(WHILE/LOOP/REPEAT)等控制结构,所有这些复合流程都必须放在 BEGIN ... END 块里。
-
语法需求
- 在存储过程、函数等地方,只要要执行超过一条 SQL 语句,就必须用 BEGIN ... END 包裹。
- 一条语句可以不用 BEGIN ... END,多条就必须用。
-
便于管理和维护
- 能清晰地界定一组操作的边界,使逻辑更易读、易维护。
形象理解
- 类似于其他编程语言里的
{ }大括号或do ... end。 - BEGIN ... END 就是“复合语句的护栏”,把相关操作锁定在一起,不会和外部语句混淆。
语法结构
[begin_label:] BEGIN
[statement_list]
END [end_label]
- BEGIN ... END 用于编写复合语句,可用于存储过程、存储函数、触发器、事件等存储程序体中。
- 可以包含多条语句(
statement_list),每条语句后面都要有分号(;)。 statement_list可以省略,BEGIN END空语句块也是合法的。
特性说明
- 语句块可嵌套:BEGIN ... END 块可以在另一个 BEGIN ... END 内部出现,实现多层逻辑。
- 分隔符处理:包含多条 SQL 语句时,客户端需要能正确发送带 ; 的语句,比如 mysql 客户端需用 delimiter 临时更改 SQL 语句分隔符(如改成 //),以允许块体内可出现 ;。
- 块可加标签:BEGIN ... END 支持用标签(label)形式,便于嵌套和跳转控制(如与 LEAVE、ITERATE 语句配合);详见 15.6.2 节说明。
事务说明
- [NOT] ATOMIC 关键字暂不支持:MySQL 当前不支持 [NOT] ATOMIC,意味着 BEGIN ... END 块不会自动设置 savepoint(保存点),也不影响外部事务。
- 注意:在存储程序内,
BEGIN [WORK]被视为 BEGIN ... END 块的开始。如果要真正启动一个事务,需用START TRANSACTION。
注意事项
- 多条语句块需要配置 mysql 客户端分隔符,否则遇到第一个 ; 就会提前结束解析。
- BEGIN ... END 可用于包裹条件分支、循环等复合逻辑,适合逻辑复杂或有多步操作的场合。
示例
delimiter //
CREATE PROCEDURE complexDemo()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 3 DO
INSERT INTO log_table(msg) VALUES (CONCAT('Current:', i));
SET i = i + 1;
END WHILE;
END //
delimiter ;
Q42
英文原题
Examine this statement which executes successfully:
PREPARE p1 FROM 'SELECT empname FROM employee WHERE emp_id = ?';
Which two statements undefine p1?
A. DROP PREPARE p1;
B. DELETE p1;
C. DEALLOCATE PREPARE p1;
D. SET @p1 = NULL;
E. CLOSE p1;
中文题目翻译与解析
请检查如下已成功执行的语句:
PREPARE p1 FROM 'SELECT empname FROM employee WHERE emp_id = ?';
下列哪两条语句能“取消定义”p1(即释放/解除已准备的语句p1)?
选项解释
- A. DROP PREPARE p1;
- 正确答案,{DEALLOCATE | DROP} PREPARE stmt_name 都可以用于正式释放prepared statement(已准备语句)。
- B. DELETE p1;
- 完全错误,DELETE是用于表中数据删除,不适用于prepared statement。
- C. DEALLOCATE PREPARE p1;
- 正确答案。 这是SQL标准中正式释放prepared statement(已准备语句)的命令。
- D. SET @p1 = NULL;
- 仅是设置变量,并不会取消prepared statement。
- E. CLOSE p1;
- CLOSE通常用于关闭游标,不适用于prepared statement。
正确答案
- A. DROP PREPARE p1;
- C. DEALLOCATE PREPARE p1;
相关知识点总结
15.5 Prepared Statements
https://dev.mysql.com/doc/refman/8.0/en/sql-prepared-statements.html
一、什么是 Prepared Statements(预处理语句)
- MySQL 支持服务端预处理语句(prepared statement),利用高效的二进制协议处理参数化SQL,提升性能和安全性。
- 预处理语句允许将SQL与数据分离,支持参数占位符(?),在实际执行前只需解析一次语句。
- 主要优点:
- 执行效率高:多次执行类似SQL时只需解析一次,大幅减少了数据库负担(如大批量插入、更新、查询)。
- 防SQL注入:参数值无需手动转义危险字符,数据库驱动自动处理。
二、Prepared Statement 的三大SQL语句
-
PREPARE
- 准备SQL语句:
PREPARE stmt_name FROM 'SQL语句' - SQL语句可包含参数占位符(?)
- 准备SQL语句:
-
EXECUTE
- 执行已准备的语句:
EXECUTE stmt_name [USING @var1, @var2, ...] - 可以动态传递参数值(变量)
- 执行已准备的语句:
-
DEALLOCATE|DROP PREPARE
- 释放已准备的语句:
{DEALLOCATE | DROP} PREPARE stmt_name
- 释放已准备的语句:
三、实际示例(SQL语法)
-- 用字符串字面值创建
PREPARE stmt1 FROM 'SELECT SQRT(POW(?,2) + POW(?,2)) AS hypotenuse';
SET @a = 3;
SET @b = 4;
EXECUTE stmt1 USING @a, @b;
-- 得到结果5
DEALLOCATE PREPARE stmt1;
-- 用变量创建
SET @sql = 'SELECT SQRT(POW(?,2) + POW(?,2)) AS hypotenuse';
PREPARE stmt2 FROM @sql;
SET @a = 6;
SET @b = 8;
EXECUTE stmt2 USING @a, @b;
-- 得到结果10
DEALLOCATE PREPARE stmt2;
Q43
英文原题
Examine the employee table structure:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| emp_id | int | NO | PRI | NULL | |
| empname | varchar(45) | YES | NULL | ||
| dept_id | int | YES | MUL | NULL | |
| salary | int | YES | NULL |
Which set of statements immediately returns empname for a given emp_id by using a parameterized PREPARE statement?
A.
SET @num='SELECT empname FROM employee WHERE emp_id = 1';
PREPARE prepStmt FROM @num;
EXECUTE prepStmt;
B.
DELIMITER //
CREATE PROCEDURE proc()
PREPARE prepStmt FROM 'SELECT empname INTO v_ename FROM employee WHERE emp_id = ?';
SET @v1=1;
EXECUTE prepStmt USING @v1;
SELECT v_ename;
END//
DELIMITER ;
C.
PREPARE prepStmt FROM 'SELECT empname FROM employee WHERE emp_id = ?';
SET @num=1;
EXECUTE prepStmt USING @num;
D.
PREPARE prepStmt FROM 'CREATE OR REPLACE VIEW ev AS SELECT empname FROM employee emp_id = ?';
SET @num=1;
EXECUTE prepStmt USING @num;
中文题目与选项解析
考察 employee 表结构:
| 字段名 | 类型 | 可否为空 | 键 | 默认值 | 额外信息 |
|---|---|---|---|---|---|
| emp_id | int | 否 | 主键 | NULL | |
| empname | varchar(45) | 是 | NULL | ||
| dept_id | int | 是 | MUL | NULL | |
| salary | int | 是 | NULL |
问题:
下列哪组语句能利用参数化 PREPARE 语句,立即返回指定 emp_id 的 empname?
A.
SET @num='SELECT empname FROM employee WHERE emp_id = 1';
PREPARE prepStmt FROM @num;
EXECUTE prepStmt;
B.
DELIMITER //
CREATE PROCEDURE proc()
PREPARE prepStmt FROM 'SELECT empname INTO v_ename FROM employee WHERE emp_id = ?';
SET @v1=1;
EXECUTE prepStmt USING @v1;
SELECT v_ename;
END//
DELIMITER ;
C.
PREPARE prepStmt FROM 'SELECT empname FROM employee WHERE emp_id = ?';
SET @num=1;
EXECUTE prepStmt USING @num;
D.
PREPARE prepStmt FROM 'CREATE OR REPLACE VIEW ev AS SELECT empname FROM employee emp_id = ?';
SET @num=1;
EXECUTE prepStmt USING @num;
选项逐项解析
-
A选项
- SET @num='SELECT empname FROM employee WHERE emp_id = 1';
- PREPARE prepStmt FROM @num;
- EXECUTE prepStmt;
- 解析:未使用参数化(只拼接了 emp_id),不是参数化 PREPARE,不满足题意,参数灵活性差。
-
B选项
- DELIMITER // ... CREATE PROCEDURE ...
- 解析:这实际上是定义了一个存储过程,并使用 PREPARE 语句,将查询结果存入变量再查出来。
- 但它不是“立即返回”,而是通过过程,且有额外的步骤,所以不够直接。
-
C选项
PREPARE prepStmt FROM 'SELECT empname FROM employee WHERE emp_id = ?';SET @num=1;EXECUTE prepStmt USING @num;- 解析:标准的参数化 PREPARE 用法!利用
?占位符,实现参数化查询,SET 设置参数再用 EXECUTE 执行,语法正确且高效。 - 这是正确答案。
-
D选项
- 使用 PREPARE 动态创建视图(CREATE OR REPLACE VIEW ...),不是直接查查询结果,与题目要求不符。
正确答案
- C
相关知识点总结
- PREPARE ... FROM ... 可用于动态 SQL 语句的预编译,在 MySQL 中支持参数化查询,安全且防注入。
- 使用参数化需 SQL 语句中用
?作为站位符,EXECUTE 时通过USING传递参数,如:EXECUTE stmt USING @param; - 动态 SQL 与参数化 SQL 区别:参数化可动态替换参数,拼接方式不可参数化;参数化更安全和灵活。
- 只用 PREPARE/EXECUTE 即可,不需要存储过程和 DELIMITER。
Q44
Examine these statements which execute successfully:
CREATE TABLE `band` (
`song` varchar(50) NOT NULL,
`year` int NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
Sample data:
| song | year |
|---|---|
| Come Together | 1969 |
| The Long and Winding Road | 1970 |
| The Fool on the Hill | 1967 |
| Hey Jude | 1968 |
| Here Comes the Sun | 1969 |
| Love Me Do | 1963 |
Desired output:
| song | year |
|---|---|
| The Fool on the Hill | 1967 |
Which SQL query will achieve the above output?
A
SELECT * FROM band
WHERE song RLIKE 'the' COLLATE utf8mb4_0900_ai_ci
AND song RLIKE '^the' COLLATE utf8mb4_0900_ai_ci;
B
SELECT * FROM band
WHERE song RLIKE '^the'
AND SUBSTRING(song, 4) RLIKE "the" COLLATE utf8mb4_0900_as_cs;
C
SELECT * FROM band
WHERE song RLIKE 'the' COLLATE utf8mb4_0900_as_cs
AND song RLIKE '^the' COLLATE utf8mb4_0900_ai_ci;
D
SELECT * FROM band
WHERE song RLIKE 'the' COLLATE latin1_general_cs
AND song RLIKE '^the' COLLATE latin1_general_ci;
E
SELECT * FROM band
WHERE song RLIKE 'the'
AND song RLIKE '^the';
中文翻译
执行如下SQL建表及插入语句:
CREATE TABLE `band` (
`song` varchar(50) NOT NULL,
`year` int NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
示例数据:
| song | year |
|---|---|
| Come Together | 1969 |
| The Long and Winding Road | 1970 |
| The Fool on the Hill | 1967 |
| Hey Jude | 1968 |
| Here Comes the Sun | 1969 |
| Love Me Do | 1963 |
期望输出:
| song | year |
|---|---|
| The Fool on the Hill | 1967 |
下列哪个SQL查询可以实现上述输出?
A
SELECT * FROM band
WHERE song RLIKE 'the' COLLATE utf8mb4_0900_ai_ci
AND song RLIKE '^the' COLLATE utf8mb4_0900_ai_ci;
B
SELECT * FROM band
WHERE song RLIKE '^the'
AND SUBSTRING(song, 4) RLIKE "the" COLLATE utf8mb4_0900_as_cs;
C
SELECT * FROM band
WHERE song RLIKE 'the' COLLATE utf8mb4_0900_as_cs
AND song RLIKE '^the' COLLATE utf8mb4_0900_ai_ci;
D
SELECT * FROM band
WHERE song RLIKE 'the' COLLATE latin1_general_cs
AND song RLIKE '^the' COLLATE latin1_general_ci;
E
SELECT * FROM band
WHERE song RLIKE 'the'
AND song RLIKE '^the';
选项逐项分析(Analysis)
A
RLIKE 'the' COLLATE utf8mb4_0900_ai_ci:不区分大小写,匹配任意包含"the"的位置。RLIKE '^the' COLLATE utf8mb4_0900_ai_ci:不区分大小写,匹配以"the"开头。- "The Fool on the Hill" 和 "The Long and Winding Road" 均被完全匹配,不正确。
B
- 第一个条件要求以"the"开头,第二个从第4位起再匹配"the"(大小写敏感)。
- 只有"The Fool on the Hill" 可以被匹配到。
C
RLIKE 'the' COLLATE utf8mb4_0900_as_cs字符串包含小写the。
RLIKE '^the' COLLATE utf8mb4_0900_ai_ci 字符串用the开头。- 只有"The Fool on the Hill" 可以被匹配到。
D
- 使用latin1的collate,但表的字符集是utf8mb4,校对规则不匹配,可能导致不可预期结果,排除。
E
- 理由同A
正确答案(Correct Answers)
- B
- C
相关知识点总结
-
RLIKE 用于正则匹配,
^the表示以the开头,the匹配任意位置。 -
COLLATE 指定匹配时是否区分大小写(ci=case-insensitive,as=accent-sensitive)。
ci (case-insensitive): 比较时忽略大小写差异。
cs(case-sensitive):区分大小写。
ai(accent-insensitive):忽略重音符号差异。
as (accent-sensitive):比较时要严格区分重音符号。举例说明:
utf8mb4_0900_ai_ci
ai = accent-insensitive(不区分重音)
ci = case-insensitive(不区分大小写)
所以 the、The、thé 都会被当作一样。
utf8mb4_0900_as_cs
as = accent-sensitive(区分重音)
cs = case-sensitive(区分大小写)
所以 the、The、thé 都被视为不同。 -
字符集和校对规则需与表字段匹配,避免出现不可预期问题。
Q45
Examine this statement that executes successfully in an interactive session:
session 0> LOCK TABLES test.t1 READ, test.t2 WRITE;
The user running this session now goes to lunch for an hour.
Now, examine these statements executed independently in separate sessions while Session 0 is still active:
- session 1> SELECT * FROM test.t2;
- session 2> SELECT * FROM test.t2 FOR UPDATE NOWAIT;
- session 3> SELECT * FROM test.t1;
- session 4> INSERT INTO test.t1 VALUES (0,'a','b');
- session 5> SELECT * FROM t1 FOR UPDATE NOWAIT;
How many of them will complete while Session 0 is still active?
A. 5
B. 4
C. 1
D. 2
中文翻译
考察如下在交互会话中成功执行的语句:
session 0> LOCK TABLES test.t1 READ, test.t2 WRITE;
该用户随后离开一小时没操作。
现在,以下命令分别在独立会话下执行,且 Session 0 还处于激活状态:
- session 1> SELECT * FROM test.t2;
- session 2> SELECT * FROM test.t2 FOR UPDATE NOWAIT;
- session 3> SELECT * FROM test.t1;
- session 4> INSERT INTO test.t1 VALUES (0,'a','b');
- session 5> SELECT * FROM t1 FOR UPDATE NOWAIT;
问:在 Session 0 仍然激活时,上述语句中有多少条可以完成?
A. 5
B. 4
C. 1
D. 2
解析
MySQL 的 LOCK TABLES 用于显式地锁定表,可以加读锁(READ)或写锁(WRITE):
READ 锁(并发读):加锁的当前会话以及其它会话只能进行读操作,并且多个读操作可以同时进行,但不允许写(包括 FOR UPDATE),是一种共享锁(S锁)。
WRITE 锁(独占访问):只有持锁会话可以读写,其他任何会话都无法访问该表(无论是读还是写),是一种排他锁(X锁)。
Session 0 获得了:test.t1 的 读锁 和 test.t2 的 写锁,且Session 0 不释放锁
-
session 1> SELECT * FROM test.t2;
- t2被Session 0持WRITE锁,其他session无法访问,被阻塞。
-
session 2> SELECT * FROM test.t2 FOR UPDATE NOWAIT;
- FOR UPDATE请求获取行级排他锁,此时t2持WRITE表锁,无法获取行级别排他锁,NOWAIT本应立刻返回错误,但是NOWAIT仅在行锁级别生效,所以被阻塞。
-
session 3> SELECT * FROM test.t1;
- test.t1 被加了读锁,其他会话也可以读,可以执行。
-
session 4> INSERT INTO test.t1 VALUES (0,'a','b');
- t1只被Session 0持READ锁,不允许其他任何更新。被阻塞。
-
session 5> SELECT * FROM t1 FOR UPDATE NOWAIT;
- FOR UPDATE请求获取行级排他锁,此时t1持有READ锁,无法获取行级别排他锁,NOWAIT本应立刻返回错误,但是NOWAIT仅在行锁级别生效,所以被阻塞。
唯一能马上执行的只有项数为 1。
正确答案
- C. 1
MySQL 15.3.6 LOCK TABLES 和 UNLOCK TABLES 语句
https://dev.mysql.com/doc/refman/8.0/en/lock-tables.html
1. 基本语法
LOCK TABLES tbl_name [AS alias] lock_type, ...lock_type可以是READ [LOCAL]或[LOW_PRIORITY] WRITEUNLOCK TABLES用于释放当前会话所有已加的表锁
2. 主要应用
- 用于控制多会话对表的并发访问,或防止其他会话在需要独占时修改表
- 只能对本会话加锁/解锁,不能操作其他会话
- 可用来模拟事务或加速更新(尤其在非事务型存储引擎如 MyISAM)
二、核心机制与行为
1. 表锁类型
- READ [LOCAL] 锁
- 持有者能读表,不能写
- 允许多个会话同时读该表
- 其他会话可以继续读表(即使未显式加锁)
READ LOCAL允许并发插入,但仅MyISAM支持;InnoDB无区别
- [LOW_PRIORITY] WRITE 锁
- 持有者能读写表
- 只有持有锁的会话可访问表,其他会话全部阻塞
- 写锁优先于读锁,以保证更新及及时处理
LOW_PRIORITY选项已废弃
2. 触发表与外键
- LOCK TABLES 会自动锁定相关触发器引用的表(如触发器里有insert/update等行为,该目标表将用更高等级的锁)
- 涉及外键的表若发生级联更新,也会隐式加锁
3. 解锁行为
UNLOCK TABLES显式释放本会话持有的所有表锁- 新的
LOCK TABLES会隐式释放之前的锁 - 开启事务(
START TRANSACTION)时,会隐式释放表锁 - 连接断开自动释放锁及回滚未提交事务
4. 表锁作用范围
- 表锁仅作用于当前MySQL服务实例,不跨NDB集群节点
- 只对普通(非TEMPORARY)表有效,临时表无需锁
- INFORMATION_SCHEMA下的表无需加锁
- 不能对performance_schema(除setup_xxx表)加锁
5. 特殊注意
- 持有 WRITE 锁的会话可以执行 DROP/TRUNCATE 表操作,READ 锁不允许,即持有WRITE锁才能DDL(如DROP/TRUNCATE),READ锁不能
- 若语句用到表别名,LOCK TABLES 也必须以相同别名加锁
- 一条
LOCK TABLES必须一次性申请所有需要的锁,期间只允许访问被锁的表 - UNLOCK TABLES、LOCK TABLES 不能用于存储过程程序体内
17.7.2.4 Locking Reads 锁定读取
一、简介
锁定读取是 InnoDB 为保证数据一致性和安全性而提供的两种特殊读取方式:SELECT ... FOR SHARE 和 SELECT ... FOR UPDATE。这些方式主要用于防止在读取数据与后续插入/更新等操作之间,其他事务对目标数据的修改,避免“幻读”等并发一致性问题。
二、核心机制与具体说明
1. SELECT ... FOR SHARE
- 对读取到的行加共享模式锁(Shared Lock)。
- 其他会话可以读取这些行,但不能修改,直到持锁事务提交。
- 若目标行被其他未提交事务更改,当前查询会等待直到对方结束。
- MySQL 8.0.22 后只需要 SELECT 权限,无需 DELETE/UPDATE/LOCK TABLES 权限。
- 可使用
OF table_name、NOWAIT、SKIP LOCKED(新特性)。
2. SELECT ... FOR UPDATE
- 对读取到的行和相关索引加排他锁(与 UPDATE 效果等价)。
- 其他事务不能更新或 SELECT ... FOR UPDATE/SHARE 这些行,某些隔离级别下甚至不能读。
- 需 SELECT 权限和 DELETE/UPDATE/LOCK TABLES 权限。
- 典型场景:基于行计数器生成主键或做分布式排队等,先 SELECT ... FOR UPDATE 行后再更新。
3. 锁定读取的适用前提
- 必须禁用自动提交(通过
START TRANSACTION或SET autocommit = 0),自动提交模式下无效果。 - 锁定读取子查询只有显式声明才会加锁。
4. 锁的释放
- 事务提交或回滚时,FOR SHARE/UPDATE 获得的锁全部自动释放。
三、NOWAIT 和 SKIP LOCKED 用法详解
1. 问题背景
- 正常情况下,锁定读会等待别的事务释放行锁,可能会导致阻塞。
2. 新增特性与参数
- NOWAIT:遇到目标行已被锁,即刻报错(如 ERROR 3572),不等待。
- SKIP LOCKED:遇到目标行已被锁,直接跳过,只返回未被锁的数据。
- DEFAULT:默认,无 NOWAIT/SKIP LOCKED 时,查询会等待获得锁。
3. 使用示例
- 多会话操作同一张表时:
- 会话1锁某行
START TRANSACTION; SELECT * FROM t WHERE i = 2 FOR UPDATE; - 会话2尝试锁同一行,应用 NOWAIT
START TRANSACTION; SELECT * FROM t WHERE i = 2 FOR UPDATE NOWAIT; -- 得到错误:ERROR 3572 (HY000): Do not wait for lock. - 会话3用 SKIP LOCKED 读取不被锁的数据
START TRANSACTION; SELECT * FROM t FOR UPDATE SKIP LOCKED; -- 只返回未被锁的1,3行
- 会话1锁某行
4. 场景适用性
- NOWAIT 适用于不接受阻塞、希望“抢锁失败就立刻返回”的高并发业务。
- SKIP LOCKED 适用于并发处理队列,避免“慢锁争用”带来的吞吐下降,但不能保证读到的数据是完整一致的。
5. 注意事项
- 这两个模式只对行级锁有效,对语句复制(statement based replication)不安全。
- 一般事务操作场景下仍应首选默认等待模式,仅在有特殊并发需求时用 NOWAIT/SKIP LOCKED。
四、典型业务用法举例
-
保持外键完整性
START TRANSACTION; SELECT * FROM parent WHERE NAME = 'Jones' FOR SHARE; INSERT INTO child ...; COMMIT;确保 parent 行不被并发删除,避免插入 child 时违反外键约束。
-
原子自增长计数器(防止并发重复)
START TRANSACTION; SELECT counter_field FROM child_codes FOR UPDATE; UPDATE child_codes SET counter_field = counter_field + 1; COMMIT; -
结合 NOWAIT/SKIP LOCKED 处理高并发队列抢单
SELECT * FROM orders WHERE status='pending' FOR UPDATE NOWAIT; -- 或 SELECT * FROM orders WHERE status='pending' FOR UPDATE SKIP LOCKED;
五、要点知识小结
- 锁定读取场景:为防止“幻读”、并发业务数据不一致,用于需要读+写一致性的流程。
- FOR SHARE/UPDATE 区别:FOR SHARE 只读加共享锁,FOR UPDATE 加排他锁,后者可独占更新行。
- NOWAIT/SKIP LOCKED:减少锁冲突阻塞,但会带来报错(NOWAIT)或不完整数据(SKIP LOCKED)。
- 事务范围和解锁机制:锁跟随事务生存期,事务提交回滚自动释放。
- 高并发设计:合理使用新特性可极大提升抢单、分布式队列等业务的伸缩性与容错性。
Q46
英文原文
How does InnoDB choose deadlock victims in MySQL?
A. It chooses the transaction randomly.
B. It chooses the transaction with the lowest transaction ID.
C. It chooses the transaction with the fewest modified rows.
D. It chooses the transaction with the least accumulated CPU time.
答案:C
中文翻译题目和选项
InnoDB 是如何在 MySQL 中选择死锁牺牲者的?
A. 随机选择一个事务
B. 选择事务ID最小的事务
C. 选择修改行数最少的事务
D. 选择累计CPU时间最少的事务
题干解析
题目询问 InnoDB 在遭遇死锁(deadlock)时,系统会用什么标准选择“牺牲事务”(deadlock victim)来回滚,从而解除死锁状态。
选项分析
- A. 随机选择一个事务
- 这不是 InnoDB 的策略,随机选择会带来较大的不确定性。
- B. 选择事务ID最小的事务
- 不正确,事务ID与事务操作影响无直接关系。
- C. 选择修改行数最少的事务
- 正确答案。
- InnoDB 在检测到死锁后,会选择“修改行数最少”的事务作为牺牲者进行回滚。这样可以减少回滚的成本,实现更高效恢复。
- D. 选择累计CPU时间最少的事务
- InnoDB 并不依据 CPU 时间选择牺牲事务。
17.7.5.2 Deadlock Detection 死锁检测
https://dev.mysql.com/doc/refman/8.0/en/innodb-deadlock-detection.html
一、内容摘要
InnoDB 的死锁检测机制可自动检测并解除事务死锁,降低系统阻塞概率,并选择合适的事务进行回滚以打破死锁循环。
二、主要机制说明
1. 死锁检测流程
- 死锁检测默认启用。
- InnoDB 检测发现死锁后,会自动回滚一个或多个事务以解除死锁。
- 选择被回滚的“牺牲事务”时,InnoDB 更倾向于回滚“小事务”,即插入/更新/删除行数较少的事务(修改量越小,回滚代价越低)。
2. 检测覆盖范围
- 当
innodb_table_locks=1(默认)且autocommit=0时,InnoDB 能感知表级锁和行级锁,进行完整死锁检测。 - 若涉及由 MySQL
LOCK TABLES设置的表级锁,或其他存储引擎加的锁,InnoDB 可能无法完全检测,需要依赖innodb_lock_wait_timeout参数来回滚超时事务。
3. 等待队列及极端情况
- 若依赖图中等待事务数超出 200(wait-for list 超长)或需要查看超过 1,000,000 行锁,InnoDB 会将此判定为死锁,并直接回滚尝试检测死锁的事务。
- 有关死锁详细信息、分析可通过 InnoDB Monitor(如通过 SHOW ENGINE INNODB STATUS)命令查看。
4. 停用死锁检测
- 高并发系统中,大量线程同时等待同一把锁,死锁检测可能带来额外开销。此时可通过
innodb_deadlock_detect=OFF禁用/InnoDB 的自动死锁检测,全部依赖innodb_lock_wait_timeout超时机制让事务自动回滚。
三、重点知识总结
- 死锁检测默认开启,自动找出并解除死锁
- InnoDB优先回滚修改行数最少的事务,以最小化数据恢复成本。
- 死锁检测有量化极限,极端场景下主动回滚等待队列过长的事务。
- 特殊情况/高并发环境建议可关闭死锁检测,仅依赖锁超时倒退。
- 完全避免死锁,应优化业务逻辑和访问顺序,减少资源死锁现象。
Q47
英文原文
Examine this bar graph based on columns from the players table:
| Name | Gender | Sport | GPA_Graph |
|---|---|---|---|
| Elaine | F | Netball | ############################# |
| Frank | M | Polo | ############################ |
| Charles | M | Polo | ########################## |
| Isabel | F | Netball | ######################### |
| Julie | F | Netball | #################### |
| Harriet | F | Hockey | ############## |
| Larry | M | Hockey | ########### |
| David | M | NULL |
Which two statements would generate this bar graph?
A. SELECT Name, Gender, Sport, LENGTH(GPA*10, '#') AS GPA_Graph FROM players ORDER BY GPA DESC;
B. SELECT Name, Gender, Sport, CHAR_LENGTH('#', GPA*10) AS GPA_Graph FROM players ORDER BY GPA DESC;
C. SELECT Name, Gender, Sport, RPAD('#', GPA*10, '#') AS GPA_Graph FROM players ORDER BY GPA DESC;
D. SELECT Name, Gender, Sport, REPEAT('#', GPA*10) AS GPA_Graph FROM players ORDER BY GPA DESC;
E. SELECT Name, Gender, Sport, CONCAT('#', GPA*10) AS GPA_Graph FROM players ORDER BY GPA DESC;
答案:C, D
中文翻译题目和选项
请根据 players 表中的各列观察下方条形图:
| Name | Gender | Sport | GPA_Graph |
|---|---|---|---|
| Elaine | F | Netball | ############################# |
| Frank | M | Polo | ############################ |
| Charles | M | Polo | ########################## |
| Isabel | F | Netball | ######################### |
| Julie | F | Netball | #################### |
| Harriet | F | Hockey | ############## |
| Larry | M | Hockey | ########### |
| David | M | NULL |
问:下列哪两个 SQL 语句可以生成这样的字符柱状图?
A. SELECT Name, Gender, Sport, LENGTH(GPA*10, '#') AS GPA_Graph FROM players ORDER BY GPA DESC;
B. SELECT Name, Gender, Sport, CHAR_LENGTH('#', GPA*10) AS GPA_Graph FROM players ORDER BY GPA DESC;
C. SELECT Name, Gender, Sport, RPAD('#', GPA*10, '#') AS GPA_Graph FROM players ORDER BY GPA DESC;
D. SELECT Name, Gender, Sport, REPEAT('#', GPA*10) AS GPA_Graph FROM players ORDER BY GPA DESC;
E. SELECT Name, Gender, Sport, CONCAT('#', GPA*10) AS GPA_Graph FROM players ORDER BY GPA DESC;
题干解析
题目要考查 SQL 中将数值数据可视化为文本柱状图的字符串函数用法。通常要求每行 GPA 列数值扩大(如乘10),然后生成相应数量的 # 字符,模拟条形图。
选项分析
- A. LENGTH(GPA*10, '#')
- LENGTH 只对字符串有效,且参数错误。错误方式。
- B. CHAR_LENGTH('#', GPA*10)
- CHAR_LENGTH 返回字符串实际可见字符数,此参数用法错误。
- C. RPAD('#', GPA*10, '#')
- 正确答案。RPAD 会以
#为基础字符串,填充#补齐到 GPA*10 长。
- 正确答案。RPAD 会以
- D. REPEAT('#', GPA*10)
- 正确答案。REPEAT 直接输出 GPA*10 个
#字符,是较直接的“条形图”做法。
- 正确答案。REPEAT 直接输出 GPA*10 个
- E. CONCAT('#', GPA*10)
- 仅拼接字符串,无循环,错误。
相关知识点总结
- RPAD(str, len, padstr):用 padstr 补齐 str 到总长 len
- REPEAT(str, count):重复 str 指定次数,拼接为新字符串
- ORDER BY GPA DESC:根据分数从高到低排
- 适合于命令行/文本可视化,将数值变成形象可读的文本条状图
Q48
英文原文
You must determine the number of non-null dates in the last_login column.
Which function call will satisfy this requirement?
A. ROW_COUNT()
B. COUNT(*)
C. DISTINCT(last_login)
D. SUM(last_login)
E. FOUND_ROWS()
F. COUNT(last_login)
答案:F
中文翻译题目和选项
你需要统计 last_login 列中非空(非NULL)日期的数量。
下列哪个函数调用能满足该需求?
A. ROW_COUNT()
B. COUNT(*)
C. DISTINCT(last_login)
D. SUM(last_login)
E. FOUND_ROWS()
F. COUNT(last_login) (正确答案)
题干解析
题目要求统计某列(last_login)中非空值的数量。SQL 中针对单独一列统计非NULL数,需使用 COUNT(列名),它只对非NULL值计数。
选项解释
- A. ROW_COUNT()
- 返回的是刚执行的 DML 操作影响的行数,与本题无关。
- B. COUNT(*)
- 返回表中的总行数,不管列值是否为NULL。
- C. DISTINCT(last_login)
- 语法错误,且不能直接用于计数字段非空数量。
- D. SUM(last_login)
- 仅适用于数值求和,日期不能直接SUM。
- E. FOUND_ROWS()
- 返回上一条SQL的结果集行数,与计数非空无关。
- F. COUNT(last_login)
- 正确答案。只统计
last_login非NULL 的行数,正好是需求。
- 正确答案。只统计
相关知识点总结
COUNT(列名): 只统计该列非NULL行的数量COUNT(*): 统计所有行,包括列为NULL的- 实际开发遇到“非空数统计”应优先考虑
COUNT(列名)
Q49
英文原文
Examine these statements which execute successfully:
CREATE TABLE salaries (
emp_no int,
salary int,
from_date date,
to_date date,
PRIMARY KEY (emp_no, from_date)
);
CREATE TABLE titles (
emp_no int,
title varchar(50),
from_date date,
to_date date,
PRIMARY KEY (emp_no, title, from_date)
);
A report is required that displays only once the highest and lowest salary ever paid to any employee with the title Engineer.
Which statement will do this?
A.
SELECT MAX(s.salary) as max_salary , MIN(s.salary) as min_salary
FROM salaries s
INNER JOIN titles t ON t.emp_no = s.emp_no
WHERE t.title = 'Engineer';
B.
SELECT s.salary
FROM salaries s
INNER JOIN titles t ON t.emp_no = s.emp_no
WHERE t.title = 'Engineer'
HAVING CEIL(s.salary) OR FLOOR(s.salary);
C.
SELECT GREATEST(s.salary), LEAST(s.salary)
FROM salaries s
INNER JOIN titles t ON t.emp_no = s.emp_no
WHERE t.title = 'Engineer';
D.
(SELECT s.salary
FROM salaries s
INNER JOIN titles t ON t.emp_no = s.emp_no
WHERE t.title = 'Engineer'
ORDER BY s.salary DESC LIMIT 1)
UNION
(SELECT s.salary
FROM salaries s
INNER JOIN titles t ON t.emp_no = s.emp_no
WHERE t.title = 'Engineer'
ORDER BY s.salary ASC LIMIT 1);
中文翻译题目和选项
请考察以下能成功执行的建表语句:
CREATE TABLE salaries (
emp_no int,
salary int,
from_date date,
to_date date,
PRIMARY KEY (emp_no, from_date)
);
CREATE TABLE titles (
emp_no int,
title varchar(50),
from_date date,
to_date date,
PRIMARY KEY (emp_no, title, from_date)
);
业务需求:只显示一次所有“Engineer”职位雇员曾获得的最高和最低工资。
下述哪条SQL可以实现此需求?
A.
SELECT MAX(s.salary) as max_salary , MIN(s.salary) as min_salary
FROM salaries s
INNER JOIN titles t ON t.emp_no = s.emp_no
WHERE t.title = 'Engineer';
B.
SELECT s.salary
FROM salaries s
INNER JOIN titles t ON t.emp_no = s.emp_no
WHERE t.title = 'Engineer'
HAVING CEIL(s.salary) OR FLOOR(s.salary);
C.
SELECT GREATEST(s.salary), LEAST(s.salary)
FROM salaries s
INNER JOIN titles t ON t.emp_no = s.emp_no
WHERE t.title = 'Engineer';
D.
(SELECT s.salary
FROM salaries s
INNER JOIN titles t ON t.emp_no = s.emp_no
WHERE t.title = 'Engineer'
ORDER BY s.salary DESC LIMIT 1)
UNION
(SELECT s.salary
FROM salaries s
INNER JOIN titles t ON t.emp_no = s.emp_no
WHERE t.title = 'Engineer'
ORDER BY s.salary ASC LIMIT 1);
题干解析
A. MAX()/MIN() :正确。
B. HAVING CEIL()/FLOOR():只做数值筛选,无关统计。
C. GREATEST()/LEAST():用法错误
D. UNION:展示了两行而非“一次”,不符合题目要求。
正确答案:A
相关知识点总结
GREATEST() 和 LEAST() 函数详解
一、GREATEST(value1, value2, ...)
- 功能:返回参与比较参数中最大的(最大值)一个
- 参数:两个或多个,可为数字、字符串等(可混合)
- 比较规则:
- 如果有任意参数为
NULL,结果为NULL - 全为整数,按整数比
- 存在 double,按 double 比
- 存在 DECIMAL,按 DECIMAL 比
- 存在字符串,按字符串比(非二进制字符串比),否则二进制比
- 如果有任意参数为
- 返回值的类型:综合比较参数类型
- 主要用途:找出多列/多值中最大者
示例:
SELECT GREATEST(2, 0); -- 结果: 2
SELECT GREATEST(34.0, 3.0, 5.0, 767.0); -- 结果: 767.0
SELECT GREATEST('B','A','C'); -- 结果: 'C'
SELECT GREATEST(1,NULL,3); -- 结果: NULL
二、LEAST(value1, value2, ...)
- 功能:返回参与比较参数中最小的(最小值)一个
- 参数:两个或多个,可为数字、字符串等
- 比较规则与 GREATEST 基本相同:
- 任一参数为 NULL,结果为 NULL
- 全为整数,按整数比
- 存在 double,按 double 比
- 存在 DECIMAL,按 DECIMAL 比
- 存在字符串,按字符串比(非二进制字符串比),否则二进制比
- 返回值的类型:综合比较参数类型
- 主要用途:找出多列/多值中最小者
- 示例:
SELECT LEAST(2, 0); -- 结果: 0
SELECT LEAST(34.0, 3.0, 5.0, 767.0); -- 结果: 3.0
SELECT LEAST('B','A','C'); -- 结果: 'A'
SELECT LEAST(1,NULL,3); -- 结果: NULL
三、典型应用
- 多列成绩、指标、价格等取最大/最小值
- 条件筛选多个字段时的极值判断
- 注意:只比较参数间的单一最大/最小值,不会“聚合”整个分组或全表 —— 若要汇总全表极值请用 MAX() / MIN()
Q50
英文原文
Examine this code and output:
try:
conn.autocommit = False
cursor = conn.cursor()
cursor.execute("INSERT INTO band(song, year) VALUES('From Me to You', 1964)")
except mysql.connector.Error as error:
print("Unable to insert the record, error is:")
print(error)
try:
cursor.execute("UPDATE band SET year=1969 WHERE song='Come Together';")
except mysql.connector.Error as error:
print("Unable to update the record, error is:")
print(error)
try:
conn.commit()
except mysql.connector.Error as error2:
print(error2)
Output:
Unable to update the record, error is:
1205 (HY000): Lock wait timeout exceeded; try restarting transaction
MySQL Server is configured with:
innodb_rollback_on_timeout=OFF
Which two are true?
A. The transaction never started.
B. The transaction is committed.
C. Both statements complete successfully.
D. Only the INSERT statement completes successfully.
E. The transaction is rolled back.
中文解析
请检查如下代码及输出结果:
try:
conn.autocommit = False
cursor = conn.cursor()
cursor.execute("INSERT INTO band(song, year) VALUES('From Me to You', 1964)")
except mysql.connector.Error as error:
print("Unable to insert the record, error is:")
print(error)
try:
cursor.execute("UPDATE band SET year=1969 WHERE song='Come Together';")
except mysql.connector.Error as error:
print("Unable to update the record, error is:")
print(error)
try:
conn.commit()
except mysql.connector.Error as error2:
print(error2)
输出:
Unable to update the record, error is:
1205 (HY000): Lock wait timeout exceeded; try restarting transaction
数据库参数设置为 innodb_rollback_on_timeout=OFF。
下列哪两项为真?
A. 事务根本未启动
B. 事务已提交
C. 两条语句都成功
D. 只有 INSERT 语句成功执行
E. 事务被回滚
题干解析
- 代码依次执行:开启事务、运行 INSERT、运行 UPDATE,最后 COMMIT。
- INSERT 成功。
- UPDATE 报错:锁等待超时(1205 HY000),未能成功。
- 参数 innodb_rollback_on_timeout=OFF:超时时仅失败的语句回滚,其他已成功语句不影响,整个事务不自动回滚。
选项分析
-
A. 事务根本未启动
错,事务已经通过 conn.autocommit = False 开启,并且已经执行了 INSERT 语句。 -
B. 事务已提交
正确,虽然 UPDATE 失败了,但 INSERT 成功了,且后续 conn.commit() 并未报错(错误只出现在 UPDATE 语句)。在 innodb_rollback_on_timeout=OFF 时,UPDATE 失败只回滚该语句,不回滚整个事务,commit 依然会提交前面成功的操作。 -
C. 两条语句都成功
错,UPDATE 失败。 -
D. 只有 INSERT 成功
正确。INSERT 成功,UPDATE 失败,且 INSERT 会被 commit 提交。 -
E. 事务被回滚
错,innodb_rollback_on_timeout=OFF 下不会自动整体回滚,只有出错语句自身回滚。
答案:BD
innodb_rollback_on_timeout 说明
https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_rollback_on_timeout
官方原文摘要
- 参数名称:innodb_rollback_on_timeout
- 命令行格式:--innodb-rollback-on-timeout[={OFF|ON}]
- 系统变量:innodb_rollback_on_timeout
- 作用范围:全局(Global)
- 动态修改:否(Dynamic: No)
- 类型:布尔型(Boolean)
- 默认值:OFF
行为说明:
-
当为 OFF(默认)时:
- InnoDB 在事务超时时,只回滚导致超时的那条 SQL 语句,事务的其它部分不受影响、未自动整体回滚。
- 例如,一条 UPDATE 因死锁或锁等待超时失败,该 UPDATE 回滚,但事务其它已执行的语句(如 INSERT)依然有效,事务还活跃,需要你决定是否 COMMIT 或手动回滚。
-
当为 ON 时:
- 在事务超时时,InnoDB 会直接中止并回滚整个事务,所有已执行但是尚未提交的 DML 操作都会被撤销。
关键总结
OFF(默认):只回滚超时语句,不自动整体回滚事务。ON:超时时整个事务被回滚。
Q51
Examine this event's metadata:
| EVENT_SCHEMA | EVENT_NAME | DEFINER | EVENT_TYPE |
|---|---|---|---|
| test | event2 | user1@localhost | RECURRING |
Now examine this command:
DROP USER 'user1'@'localhost';
Which effect will the command have on the event?
A. The event will be dropped without an error or warning.
B. The event is scheduled and executed but fails. The system will log an error.
C. The event is not scheduled and will no longer execute. The system will log an error.
D. The event is scheduled but will no longer execute. The system will log an error.
中文翻译题目及选项
请检查以下事件元数据:
| EVENT_SCHEMA | EVENT_NAME | DEFINER | EVENT_TYPE |
|---|---|---|---|
| test | event2 | user1@localhost | RECURRING |
再看下面这个命令:
DROP USER 'user1'@'localhost';
此命令对该事件会产生什么影响?
A. 事件会被删除,不会报错或警告。
B. 事件被调度并执行,但失败。系统会记录一个错误。
C. 事件不再被调度,也不会再被执行。系统会记录一个错误。
D. 事件被调度,但不会再被执行。系统会记录一个错误。
选项解释
元数据解释:
EVENT_TYPE:事件重复类型,ONE TIME (瞬态)或RECURRING(重复)。
-
A 选项含义
事件直接被删除,不会出现任何错误或警告。 -
B 选项含义
事件会继续被调度并尝试执行,但由于某些原因执行失败,系统会记录错误,正确。 -
C 选项含义
这个事件不会再被调度,永久中止,系统会写入日志记录此错误。 -
D 选项含义
事件依然被系统调度(还在事件表),但由于其定义者账号已被删除,事件实际会再次执行但是失败,系统会写入相关错误日志。
正确答案
b.
The Event Scheduler and MySQL Privileges
https://dev.mysql.com/doc/refman/8.0/en/events-privileges.html
1. 事件调度器与权限管理
- 事件(Event)的创建、修改和删除受 EVENT 权限控制。
- 事件的执行总是以 DEFINER 用户的权限身份进行。
- 事件能否实际执行,完全取决于 DEFINER 是否拥有相关对象的权限。
2. 用户和事件的删除行为
-
撤销 EVENT 权限
- 撤销一个用户的 EVENT 权限,不会影响其已经创建的事件。事件依然存在并可被调度。
-
DROP USER 或 RENAME USER
- 删除(DROP USER)或重命名用户,不会直接迁移到或删除该用户此前创建的事件。
- 事件定义信息仍然保存于数据字典中,但由于 DEFINER 不存在,事件将无法再成功执行。
3. 报错和系统行为
- 如果事件的 DEFINER 用户不存在,事件调度器尝试调度并执行该事件时会出现错误,错误会被记录到日志。
- 事件本身依然“存在”、依旧被调度(依然 ENABLED),但不会真正被执行,仅每次尝试时日志报错。
4. 官方举例
- 示例说明:DROP USER 并不会移除事件,也不会自动禁用事件,但该事件将因找不到执行人而报错,不再实际运行。
相关原文片段
"An event is not migrated or dropped as a result of renaming or dropping the user who created it."
"After ... DROP USER jon@ghidora; ... e_insert continues to execute, inserting a new row into mytable each seven seconds."(但实际上,如果没有对应的 DEFINER,事件无法正确执行并会报错)
Q52
英文原文
You are using mysqli in a PHP script.
Which value may appear in connect_errno after attempting a connection?
A. a connection number for the session
B. a zero on success
C. the number of connection errors for the session
D. the time the last error occurred
中文翻译题目和选项
你在 PHP 脚本中使用 mysqli。
在尝试连接后,connect_errno 可能出现什么值?
A. 会话的连接编号
B. 成功时为 0
C. 会话中的连接错误次数
D. 上次错误发生的时间
选项解释
-
A 选项含义
指返回当前会话的连接编号。实际上,connect_errno并不返回连接编号。 -
B 选项含义
如果连接成功,connect_errno的值为 0。(正确答案) -
C 选项含义
指返回该会话中的连接错误总数,但connect_errno只表示最近一次错误的代码。 -
D 选项含义
指返回上次错误发生的时间,实际上connect_errno并不涉及时间信息。
正确答案
B. a zero on success
相关知识点总结
- 在 PHP 的
mysqli扩展中,$mysqli->connect_errno属性用于表示上一次连接操作的错误代码。 - 如果连接成功,则
connect_errno的值为 0。若连接失败,则为非 0 的错误代码,对应具体的出错类型。 - 可通过
connect_error查看具体的错误信息文本内容。 - 用法示例:
$mysqli = new mysqli("localhost", "user", "password", "database");
if ($mysqli->connect_errno) {
echo "Failed to connect: " . $mysqli->connect_error;
} else {
echo "Connection successful!";
}
// 连接成功时,$mysqli->connect_errno 为 0
Q53
英文原文
Which two of these benefit from having a connection pool?
A. applications running long complex transactions
B. where authentication information needs to be cached over a long period of time
C. middleware modules that maintain multiple connections to multiple MySQL servers and require connection to be readily available
D. software services with multiple processes using one network interface to a variety of servers
E. websites that require a high number of short-lived connections to the MySQL server
中文翻译题目及选项
以下哪两种情况从使用连接池中获益最大?
A. 运行长期复杂事务的应用
B. 需要长时间缓存认证信息的场景
C. 中间件模块,需要维护到多个 MySQL 服务器的多条连接,并且要求随时能立即获得连接
D. 多进程软件服务,使用同一个网络接口连接各类服务器
E. 需要大量短时连接到 MySQL 服务器的网站
选项解释
-
A 选项含义
长事务应用,不常频繁创建或释放连接,所以连接池效益不明显。 -
B 选项含义
与连接池直接关系不大,主要关注认证信息缓存。 -
C 选项含义
多个 MySQL 服务器、多条连接、需要随时获得连接——连接池可以显著提升性能和效率。(正确答案) -
D 选项含义
只是网络接口复用,与数据库连接池不直接相关。 -
E 选项含义
网站上常有大量短时连接,请求频繁,连接池能减少频繁建立/断开连接的消耗。(正确答案)
正确答案
C. middleware modules...
E. websites that require a high number of short-lived connections...
MySQL 连接池(Connection Pool
1. 工作原理简介
MySQL 连接池(Connection Pool)是在客户端层面运作的。它的主要作用是避免客户端在每次执行查询时都要连接和断开 MySQL 服务器,提高效率。
2. 连接池的核心机制
- 缓存空闲连接:连接池会把已建立但当前空闲的连接保存在客户端。
- 复用连接:下次有查询需要时,可以直接复用这些空闲连接,而不必再次创建和销毁连接,减少大量的资源消耗和等待时间。
3. 优势说明
- 降低开销:反复建立和断开连接的过程比较耗时且浪费资源,连接池能有效避免这一点,提升系统性能和吞吐量。
4. 局限性
- 不了解后端负载:MySQL 连接池无法感知后端 MySQL 服务器的查询处理能力或即时负载。它只是单纯以客户端的角度去复用连接,并不涉及数据库服务器状态的智能判断。
Q54
英文原文
A program executes a START TRANSACTION statement in AUTOCOMMIT mode.
Which two are true?
A. AUTOCOMMIT mode is enabled again only by executing a COMMIT statement.
B. It temporarily disables AUTOCOMMIT mode.
C. AUTOCOMMIT mode is enabled again after executing a ROLLBACK statement.
D. Every SQL statement executes as a transaction.
E. All changes to any table rows commit immediately.
中文题目翻译
一个程序在 AUTOCOMMIT 模式下执行了一条 START TRANSACTION 语句。
下列哪两项是正确的?
A. 只通过执行 COMMIT 语句,才能重新启用 AUTOCOMMIT 模式。
B. 它会暂时禁用 AUTOCOMMIT 模式。
C. 执行 ROLLBACK 语句后,会重新启用 AUTOCOMMIT 模式。
D. 每一条 SQL 语句都作为一个事务执行。
E. 对表行的所有更改都会立即提交。
选项解析
- AUTOCOMMIT模式:每执行一条SQL语句,都会自动提交。
- START TRANSACTION:开始一个事务,后续的操作不会自动提交,直到明确执行COMMIT或ROLLBACK。
当在AUTOCOMMIT模式下执行START TRANSACTION,数据库会临时关闭AUTOCOMMIT,直到你执行COMMIT或ROLLBACK。
-
A. AUTOCOMMIT mode is enabled again only by executing a COMMIT statement.
- 错误。AUTOCOMMIT 模式会在 COMMIT 或 ROLLBACK 后恢复,而不仅限于 COMMIT。
-
B. It temporarily disables AUTOCOMMIT mode.
- 正确。当执行
START TRANSACTION时,会暂时关闭 AUTOCOMMIT,进入手动事务控制模式。
- 正确。当执行
-
C. AUTOCOMMIT mode is enabled again after executing a ROLLBACK statement.
- 正确。无论是 COMMIT 还是 ROLLBACK,当前事务结束后,AUTOCOMMIT 都会恢复。
-
D. Every SQL statement executes as a transaction.
- 错误。虽然在 AUTOCOMMIT 模式下,每条语句自动提交,但执行
START TRANSACTION后,需要显式提交/回滚。
- 错误。虽然在 AUTOCOMMIT 模式下,每条语句自动提交,但执行
-
E. All changes to any table rows commit immediately.
- 错误。在事务开始后,只有执行 COMMIT 时更改才会生效。
正确答案
B、C
知识点总结
- AUTOCOMMIT 模式简介:MySQL 默认在 AUTOCOMMIT 模式下,每条语句自动提交。
- START TRANSACTION 行为:执行该命令会临时关闭 AUTOCOMMIT,随后需手动提交(COMMIT)或回滚(ROLLBACK)。
- 事务结束恢复:在事务通过 COMMIT 或 ROLLBACK 结束后,AUTOCOMMIT 自动恢复原状。
- 自动与手动事务区别:AUTOCOMMIT 模式下,事务行为与显式事务开启方式有显著差别。
Q55
英文原文
Examine these statements issued from Session 1 which execute successfully:
Session 1>
SET autocommit=1;
SELECT * FROM band FOR UPDATE;
Session 1 remains idle while another user starts Session 2.
Now, examine these statements issued from Session 2 which execute successfully:
Session 2>
BEGIN;
UPDATE band SET song=CONCAT('Here Comes the ', song) WHERE song LIKE '%Sun';
Which two are true?
A. Session 2 does not start a transaction.
B. Session 1 must commit before the UPDATE in Session 2 can complete.
C. Session 2 takes an exclusive lock on all the rows in the band table.
D. Statements in Session 2 are committed.
E. Session 1 does not block Session 2.
中文题目翻译
检查会话1中成功执行的如下语句:
Session 1>
SET autocommit=1;
SELECT * FROM band FOR UPDATE;
会话1保持空闲,另一用户开启会话2。
现在,请检查会话2中成功执行的如下语句:
Session 2>
BEGIN;
UPDATE band SET song=CONCAT('Here Comes the ', song) WHERE song LIKE '%Sun';
下列哪两个说法正确?
A. 会话2没有开启事务。
B. 会话1必须提交,Session 2 中的 UPDATE 才能完成。
C. 会话2会对 band 表的所有行加排它锁。
D. 会话2中的语句被自动提交。
E. 会话1不会阻塞会话2。
解析
autocommit是一个会话变量,必须为每个会话设置,Session 1 开启了autocommit功能;
-
A. Session 2 does not start a transaction.
- 错误。Session 2 显式用
BEGIN;开启了事务。
- 错误。Session 2 显式用
-
B. Session 1 must commit before the UPDATE in Session 2 can complete.
- 错误。在 autocommit=1 下 SELECT * FROM band FOR UPDATE 的锁不会生效(关联知识点 Q45 知识拓展)。
-
C. Session 2 takes an exclusive lock on all the rows in the band table.
- 正确。
官方文档中提及:如果你的语句没有可用的索引,MySQL 必须全表扫描来处理该语句,那么表中的每一行都会被加锁,这会导致其他用户无法向该表插入数据。因此,设计良好的索引非常重要,这样你的查询就不会扫描不必要的行数(If you have no indexes suitable for your statement and MySQL must scan the entire table to process the statement, every row of the table becomes locked, which in turn blocks all inserts by other users to the table. It is important to create good indexes so that your queries do not scan more rows than necessary.)。
Session 2 中使用了 WHERE song LIKE '%Sun',而后缀like不会用到任何索引,需要全表扫描,所以表中的每一行都会被加锁。
- 正确。
-
D. Statements in Session 2 are committed.
- 错误。Session 2 开启了事务,并没有显示 COMMIT,所以事务未被提交。
-
E. Session 1 does not block Session 2.
- 正确。在 autocommit=1 下 SELECT * FROM band FOR UPDATE 的锁不会生效。
正确答案
C,E
相关知识点总结
SELECT ... FOR UPDATE会对选中行加排它锁,其他事务(如 UPDATE)将被阻塞,直到锁被释放(commit 或 rollback)。- 事务的显式开启与提交需要手动控制;隐式提交只会在 autocommit=1 且非事务语句时发生。
- 多事务并发时,锁竞争是常见的阻塞原因,设计高并发系统时要特别注意这一点。
COMMIT/BGIN
BEGIN
Source: https://dev.mysql.com/doc/refman/8.4/en/commit.html
-
BEGIN / START TRANSACTION
- 用于显示地开启一个事务(transaction)。
- 在事务型存储引擎(如 InnoDB)下,
BEGIN、START TRANSACTION、BEGIN WORK都可以作为事务开始标志,这三者等价。
-
事务生命周期
- 正常流程:
- 执行
BEGIN或START TRANSACTION开始事务。 - 在事务过程中,可以执行多条 DML 操作(如 INSERT, UPDATE, DELETE)。
- 用
COMMIT提交事务使所有修改永久生效。 - 用
ROLLBACK回滚事务取消所有自上次 BEGIN 之后的修改。
- 执行
- 正常流程:
-
自动提交
- MySQL 默认启用 autocommit(自动提交),即每一条独立语句在执行后会立即自动提交。
- 使用
BEGIN可以关闭自动提交,进入手动提交控制。 - 在手动事务模式下(autocommit=0 或通过 BEGIN 显式开启事务),只有显式执行 COMMIT 或 ROLLBACK,事务才会结束并提交或撤销。
-
事务隐式提交的例外
- 某些语句(如 DDL 语句:CREATE、ALTER TABLE 等)会导致隐式提交(即使事务未手动提交),如在 BEGIN 之后执行这些语句会自动结束当前事务。
-
COMMIT 与 BEGIN 的关系
- 在 BEGIN/START TRANSACTION 之后执行 COMMIT,才会将这段事务中的所有更改落盘。
- 若在 BEGIN 之后直接 ROLLBACK,则所有变更撤回。
总结
- 推荐开发中显式用
BEGIN ... COMMIT/ROLLBACK包裹关键数据变更,保证原子性。 - 使用事务时应注意不要在事务块中混用DDL和DML,否则事务控制效果不可预期。
- 可以通过
SHOW VARIABLES LIKE 'autocommit';检查当前自动提交设置。
锁的设定
原文链接: https://dev.mysql.com/doc/refman/8.0/en/innodb-locks-set.html
知识点总结
-
InnoDB 加锁机制类型
- 记录锁(Record Lock):锁定某条索引记录。
- 间隙锁(Gap Lock):锁定两条索引间的间隙、首记录前或末记录后的“空隙”。
- Next-Key Lock:是“记录锁”和其前间隙锁的组合,防止“幻读”。
- 表级锁(Table Lock):用于部分DDL或显式LOCK TABLES时锁全表。
-
加锁时机
- 用于
SELECT ... FOR UPDATE或LOCK IN SHARE MODE时,加的是记录或next-key锁。 INSERT/UPDATE/DELETE数据修改时,会设定合适的记录锁、间隙锁、next-key锁,保证数据一致性和隔离。- 当语句无可用索引、需要全表扫描时,会锁全表所有记录,严重影响并发性能。
- 用于
-
辅助索引与锁
- 若基于二级索引(set secondary index)做修改或独占操作,InnoDB 不仅锁二级索引项,还会锁对应的聚簇索引(主键)记录。
-
间隙锁的作用
- 在 REPEATABLE READ 或更高隔离级别下,间隙锁防止“幻读”,保障查询的一致性。
-
解锁
- 事务提交(commit)或回滚(rollback)时会自动释放本事务加的所有锁。
使用建议
- 设计合适的索引,避免大表全表锁,优化SQL查询效率。
- 理解不同锁类型对于并发和性能的影响,实现安全且高效的数据操作。
Q56
Examine these statements and output:
mysql> SET AUTOCOMMIT=on;
mysql> UPDATE emp SET salary=24000 WHERE id=101;
mysql> INSERT INTO EMP values (102,'John',13000,'JJ',10);
mysql> SET AUTOCOMMIT=off;
mysql> ROLLBACK;
What is true about the effect of the command?
A. It undoes the UPDATE command.
B. It undoes both INSERT and UPDATE commands.
C. It undoes the INSERT command.
D. It returns an error because there is no active transaction.
E. It has no effect.
中文翻译
请检查以下语句和输出:
mysql> SET AUTOCOMMIT=on;
mysql> UPDATE emp SET salary=24000 WHERE id=101;
mysql> INSERT INTO EMP values (102,'John',13000,'JJ',10);
mysql> SET AUTOCOMMIT=off;
mysql> ROLLBACK;
现在,分析这条命令:
mysql> ROLLBACK;
关于这行命令,哪项描述正确?
A. 它撤销了UPDATE命令。
B. 它同时撤销了INSERT和UPDATE命令。
C. 它撤销了INSERT命令。
D. 它返回错误,因为没有活跃的事务。
E. 它没有任何效果。
选项分析
A. It undoes the UPDATE command. / 撤销UPDATE命令。
错误。因为UPDATE发生在autocommit=on阶段,已自动提交,无法被ROLLBACK回滚。
B. It undoes both INSERT and UPDATE commands. / 同时撤销INSERT和UPDATE。
错误。INSERT与UPDATE都在autocommit=on,每条语句单独提交,无法被ROLLBACK回滚。
C. It undoes the INSERT command. / 撤销INSERT命令。
错误。INSERT已自动提交。
D. It returns an error because there is no active transaction. / 因没有活跃事务而报错。
错误。MySQL下执行ROLLBACK时若无活动事务,通常无报错,仅提示没有生效。
E. It has no effect. / 它没有任何效果。
正确答案。 既没有活跃事务,也没有可回滚内容,所以ROLLBACK无任何效果。
正确答案
E. It has no effect. / 它没有任何效果。
ROLLBACK
文档地址: https://dev.mysql.com/doc/refman/8.0/en/commit.html
1. ROLLBACK 的作用
ROLLBACK语句用于撤销自事务开始以来对数据库所做的更改,这些更改在回滚后不会永久写入数据库。- 执行
ROLLBACK会释放已持有的所有行锁与表锁。
2. 与 BEGIN 的关系
- 通过
START TRANSACTION、BEGIN或BEGIN WORK开启的事务,在未COMMIT前都可以随时使用ROLLBACK撤销。 - 如果在自动提交模式(autocommit=1)下,单独的DML语句自动提交,
ROLLBACK无法撤销自动提交的语句。 - 只有在事务被显式启动(autocommit=0 或显式 BEGIN)后,
ROLLBACK才会有效。
3. 隐式 ROLLBACK 的触发
- 某些情况下,MySQL 会隐式地执行 ROLLBACK。例如:
- 会话异常断开时,当前未提交的事务会被自动回滚。
- 一些致命错误也会导致隐式回滚。
4. ROLLBACK 的限制
- DDL(如 CREATE、ALTER、DROP TABLE)会导致隐式提交,不属于事务的控制范围,因此无法被 ROLLBACK 撤销。
- 对于 MyISAM 等非事务型存储引擎,ROLLBACK 无效,只对 InnoDB、NDB 等事务型引擎生效。
5. ROLLBACK 的常用流程示例
START TRANSACTION; -- 或 BEGIN;
UPDATE t1 SET ...;
INSERT INTO t2 ...;
-- 出现问题时,可以
ROLLBACK; -- 撤销自事务开始以来的所有变更
6. 其他注意事项
没有活跃事务时执行 ROLLBACK 不会出错,但不会有任何效果。
在事务中频繁使用 ROLLBACK 可以确保数据的一致性和业务流程的可靠性。
Q57
Examine this statement which executes successfully:
DELIMITER //
CREATE PROCEDURE test_cursor(OUT city_name VARCHAR(100))
BEGIN
DECLARE count INT DEFAULT 0;
DECLARE cur CURSOR FOR SELECT name FROM city;
DECLARE EXIT HANDLER FOR NOT FOUND SELECT count;
OPEN cur;
LOOP
FETCH cur INTO city_name;
SET count = count+1;
END LOOP;
END //
DELIMITER ;
You execute this statement:
CALL test_cursor(@city);
Which two are true about the execution?
A. The loop runs infinitely.
B. @city contains the last city name fetched from the cursor.
C. The memory allocated to the cursor is not released.
D. The procedure displays the number of rows in the city table.
E. The procedure exits if the city table is not found.
中文翻译
请检查以下能成功执行的语句:
DELIMITER //
CREATE PROCEDURE test_cursor(OUT city_name VARCHAR(100))
BEGIN
DECLARE count INT DEFAULT 0;
DECLARE cur CURSOR FOR SELECT name FROM city;
DECLARE EXIT HANDLER FOR NOT FOUND SELECT count;
OPEN cur;
LOOP
FETCH cur INTO city_name;
SET count = count+1;
END LOOP;
END //
DELIMITER ;
你执行:
CALL test_cursor(@city);
以下哪两项关于执行过程是正确的?
A. 循环会无限执行。
B. @city 包含了 cursor 最后一次抓取到的城市名。
C. 游标分配的内存未被释放。
D. 存储过程会显示 city 表中的行数。
E. 若找不到 city 表,过程会退出。
过程执行整体流程梳理
-
OPEN cur;
- 打开游标,准备遍历查询结果。
-
LOOP ... END LOOP;
- 进入一个无限循环,每次循环执行以下步骤:
-
FETCH cur INTO city_name;
- 从游标获取一行
name,赋值到city_name。 - 如果还有数据(未到底),则
city_name被成功赋值,下面语句继续执行。 - 如果数据已经遍历完(游标到底),
FETCH触发NOT FOUND条件。
- 从游标获取一行
-
SET count = count + 1;
- 每取一行,计数变量
count自增 1。
- 每取一行,计数变量
-
FETCH 没有数据时的处理
- 触发
EXIT HANDLER FOR NOT FOUND,即:- 执行
SELECT count;(输出当前遍历到数据的总行数)。 EXIT表示立即退出当前的 BEGIN...END 块(即整个存储过程终止)。
- 执行
- 触发
-
循环剩余语句不会执行
- 一旦进入
EXIT HANDLER,以下内容都不会再执行:END LOOP;(不会回到循环头部)CLOSE cur;(游标不会被手动关闭)
- 一旦进入
核心结论
- 游标打开后进入循环。
- 只要
FETCH能取到数据就赋值+计数+继续循环。 FETCH取不到数据时,直接触发异常处理,输出计数并立刻终止整个过程。- 过程结束时并不会走到
END LOOP或手动关闭游标,游标由MySQL自动回收。
选项分析
A. The loop runs infinitely.(循环无限执行)
错误。
虽然 LOOP 没有显式退出条件,但游标到末尾时,FETCH 会触发 NOT FOUND,此时 EXIT HANDLER 会被激活,执行 SELECT count; 并终止存储过程。
所以循环不会无限运行。
B. @city contains the last city name fetched from the cursor.(@city 存放游标最后抓取的城市名)
正确。
每次 FETCH,city_name 都被赋值为游标当前行的 name 字段,直到游标结束。
当退出循环时,city_name 就是最后一条记录的 name,也就是 OUT 变量 @city 的值。
C. The memory allocated to the cursor is not released.(游标内存未释放)
错误。过程结束后MySQL会自动关闭和释放游标和相关资源。
D. The procedure displays the number of rows in the city table.(过程展示city表行数)
正确。
在 NOT FOUND 时,EXIT HANDLER 执行 SELECT count;,会显示出 count 的值,也就是游标循环次数,即 city 表的行数。
E. The procedure exits if the city table is not found.(city表找不到则退出)
错误。没有相关的异常处理机制来捕获表不存在的异常。
正确答案
B. @city contains the last city name fetched from the cursor.
D. The procedure displays the number of rows in the city table.
DECLARE HANDLER 关键知识点总结
参考链接: https://dev.mysql.com/doc/refman/8.0/en/declare-handler.html
1. 语法与用途
DECLARE ... HANDLER允许在MySQL存储程序(如:存储过程、函数等)中声明异常处理器,用于应对SQL执行中的异常(错误/警告/注意/NOT FOUND等)。- 语法格式:
DECLARE handler_type HANDLER
FOR condition_value [, condition_value] ...
statement;
-
handler_type 可为:
CONTINUE:处理后继续执行后续语句。
EXIT:处理后立即退出当前BEGIN...END块。
UNDO:保留,现无实际效果(解析后被忽略)。 -
condition_value 可为:
SQLSTATE值(5位字符串,如 '02000')
mysql错误码(数字)
关键字:NOT FOUND, SQLEXCEPTION, SQLWARNING对于
NOT FOUND条件:- 如果
NOT FOUND是“正常触发”的(比如,在用游标FETCH到数据结尾时自然触发的),那么在未声明专门的 HANDLER 时,其默认行为是CONTINUE,即:继续执行后续语句,不退出当前块。 - 如果
NOT FOUND是通过SIGNAL或RESIGNAL语句“人工触发”的(即你在过程代码里主动抛出此异常),其默认行为变成EXIT,也就是立即退出当前的 BEGIN...END 代码块(相当于把 NOT FOUND 当成致命错误处理)
- 如果
-
statement 为遇到指定条件时自动执行的语句块。
- 典型使用场景举例
- NOT FOUND 处理(如游标遍历结束)
DECLARE EXIT HANDLER FOR NOT FOUND
SET done = TRUE;
用于游标遍历数据到结尾时自动跳出循环。
- 特定错误号/SQLSTATE
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000'
SET myflag = 1;
处理指定类型的错误/异常。
- 通用SQL异常捕获
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
-- 记录日志/设置错误标志等
3. 注意事项
HANDLER 作用域限于当前BEGIN...END块,块退出即失效。
HANDLER 必须在需要捕获异常的语句之前声明,并且紧跟在局部变量声明之后。
可以为同一handler_type声明多个condition,但只能对应一个处理语句(statement)。
典型类型说明:
EXIT 常用于终止循环等控制流。
CONTINUE 用于忽略错误/警告,继续运行后续代码。
4. 示例
游标遍历+异常
DECLARE done INT DEFAULT 0;
DECLARE cur CURSOR FOR SELECT ...;
DECLARE EXIT HANDLER FOR NOT FOUND SET done=1;
OPEN cur;
read_loop: LOOP
FETCH cur INTO ...;
IF done THEN
LEAVE read_loop;
END IF;
-- 处理数据
END LOOP;
CLOSE cur;
说明:NOT FOUND 触发时让 done=true,并通过 LEAVE 跳出循环。
5. 中文总结
DECLARE HANDLER 是MySQL中容错和控制流程的重要手段,特别适合游标、异常和自定义错误处理场景。
EXIT/CONTINUE 控制异常处理后是跳出块还是继续。
声明位置在变量声明之后,BEGIN...END块之内。
能拦截NOT FOUND(如游标结尾)、一般SQL异常、警告,以及具体错误码等。
Q58
英文原题
Examine this command which executes successfully:
CREATE FUNCTION grade (score INT) RETURNS CHAR NO SQL
BEGIN
DECLARE grade CHAR;
IF score > 85 THEN
SET grade = 'A';
ELSEIF score > 65 THEN
SET grade = 'B';
ELSEIF score > 50 THEN
SET grade = 'C';
ELSEIF score > 40 THEN
SET grade = 'D';
END IF;
RETURN grade;
END
Which one is true?
A SELECT grade(30), grade(40), grade(50); -- 结果: NULL, D, C
B SELECT grade(80), grade(85), grade(90); -- 结果: B, A, A
C SELECT grade(-1), grade(0), grade(1000); -- 结果: NULL, NULL, A
D SELECT grade(65), grade(75), grade(85); -- 结果: C, B, A
题目:请分析如下函数的功能,并判断下列调用结果。
CREATE FUNCTION grade (score INT) RETURNS CHAR NO SQL
BEGIN
DECLARE grade CHAR;
IF score > 85 THEN
SET grade = 'A';
ELSEIF score > 65 THEN
SET grade = 'B';
ELSEIF score > 50 THEN
SET grade = 'C';
ELSEIF score > 40 THEN
SET grade = 'D';
END IF;
RETURN grade;
END
哪一个是正确的?
A SELECT grade(30), grade(40), grade(50); -- 结果: NULL, D, C
B SELECT grade(80), grade(85), grade(90); -- 结果: B, A, A
C SELECT grade(-1), grade(0), grade(1000); -- 结果: NULL, NULL, A
D SELECT grade(65), grade(75), grade(85); -- 结果: C, B, A
函数含义说明:
当分数 score 高于85,返回'A'
分数大于65且≤85,返回'B'
分数大于50且≤65,返回'C'
分数大于40且≤50,返回'D'
低于或等于40的分数,未进入任何分支,返回值为NULL
选项含义&结果解释
A SELECT grade(30), grade(40), grade(50);
30: 不满足任何条件,返回NULL。
40: 不满足任何条件,返回NULL。
50: 满足 大于40且≤50,返回'D'。
错误
B SELECT grade(80), grade(85), grade(90);
80: 大于65小于85,返回'B'。
85: 等于85,大于65,返回'B'
90: 大于85,返回'A'。
错误
C SELECT grade(-1), grade(0), grade(1000);
-1与0: 都不满足任何条件,返回NULL。
1000: 大于85,返回'A'。
正确
D SELECT grade(65), grade(75), grade(85);
65: 不满足 score > 65,但满足score > 50,返回'C'。
75: 满足 score > 65,返回'B'。
85: 满足 score > 65,返回'B'(但示例为A,实际应为B)。
错误
答案
C
Q59
Examine this statement:
DECLARE not_found CONDITION FOR SQLSTATE '02000';
In which two statements can not_found be used?
A. In a LEAVE statement to exit a loop.
B. In an IF statement.
C. In a SIGNAL statement.
D. In a handler declaration.
E. In a WHILE loop.
中文翻译与解析
题目翻译
请检查以下语句:
DECLARE not_found CONDITION FOR SQLSTATE '02000';
下列哪些语句中可以使用 not_found?
A. 在 LEAVE 语句中用于跳出循环。
B. 在 IF 语句中使用。
C. 在 SIGNAL 语句中使用。
D. 在 handler 声明中使用。
E. 在 WHILE 循环中使用。
选项详细解释
-
A. 在 LEAVE 语句中用于跳出循环。
LEAVE用于退出循环或者块,不能直接使用条件名如not_found。
-
B. 在 IF 语句中使用。
IF判断表达式,不能直接用条件名not_found。
-
C. 在 SIGNAL 语句中使用。
SIGNAL用于抛出条件,可以使用已声明的条件名,如SIGNAL not_found;(正确答案之一)。
-
D. 在 handler 声明中使用。
- 在定义异常处理时(DECLARE HANDLER),可以引用已声明的条件名,如
DECLARE CONTINUE HANDLER FOR not_found(正确答案之一)。
- 在定义异常处理时(DECLARE HANDLER),可以引用已声明的条件名,如
-
E. 在 WHILE 循环中使用。
WHILE是流程控制语句,不能直接引用条件名。
正确答案
C. In a SIGNAL statement.
D. In a handler declaration.
知识点总结
DECLARE ... CONDITION是在 MySQL 存储过程等环境下定义自定义条件(异常/状态)。- 官方文档链接 https://dev.mysql.com/doc/refman/8.0/en/declare-condition.html
- 已声明的条件名可以:
- 在
SIGNAL语句中主动抛出(如SIGNAL not_found;)。 - 在
DECLARE ... HANDLER中捕获并处理(如DECLARE CONTINUE HANDLER FOR not_found)。
- 在
- 这些条件名不能作为普通变量或表达式直接在
IF、WHILE或LEAVE语句中使用。 - 本题考查的是 SQL/PL 过程性语句对异常/条件的控制流用法。
Q60
Examine the structure of the emp table:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(25) | YES | NULL | ||
| salary | int(11) | YES | NULL | ||
| varchar(25) | NO | NULL |
Examine the structure of emp_vu1 view that is based on the emp table:
| Field | Type | Null | Key | Default |
|---|---|---|---|---|
| name | varchar(25) | YES | NULL | |
| salary | int(11) | YES | NULL |
Now, examine this statement:
mysql> INSERT INTO emp_vu1 VALUES ('John', 10000);
What is true about executing the statement?
A. It inserts a row in the view only.
B. It returns an error because the id column is not included in the view definition.
C. It inserts a row in the emp table.
D. It returns an error because the email column has no default value.
中文翻译与解析
题目翻译
请考察 emp 表的结构和基于该表创建的视图 emp_vu1 结构。
emp 表:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(25) | YES | NULL | ||
| salary | int(11) | YES | NULL | ||
| varchar(25) | NO | NULL |
emp_vu1 视图:
| Field | Type | Null | Key | Default |
|---|---|---|---|---|
| name | varchar(25) | YES | NULL | |
| salary | int(11) | YES | NULL |
现在执行如下 SQL 语句:
INSERT INTO emp_vu1 VALUES ('John', 10000);
关于该语句的执行,哪个叙述是正确的?
A. 它只会在视图中插入数据。
B. 因为视图定义中没有包含 id 字段,所以会返回错误。
C. 它会在 emp 表中插入一行。
D. 因为 email 字段没有默认值,会返回错误。
选项详解
-
A. 它只会在视图中插入数据。
- 错误。视图本质上是基于基表的抽象,插入实际上影响的是基表(emp)。
-
B. 因为视图定义中没有包含 id 字段,所以会返回错误。
- 错误。
id是自增长主键,未给定会自动生成,不会报错。
- 错误。
-
C. 它会在 emp 表中插入一行。
- 不完全正确。理论上 INSERT 影响的是 emp 表,但由于有其它约束(
email字段)插入会失败。
- 不完全正确。理论上 INSERT 影响的是 emp 表,但由于有其它约束(
-
D. 因为 email 字段没有默认值,会返回错误。
- 正确!
emp表中的email字段为 NOT NULL 且没有默认值,视图插入时未提供这个字段的值,因此会导致插入失败,数据库会报错。
- 正确!
正确答案
D. It returns an error because the email column has no default value.
相关知识点总结
- 视图的插入行为:如果通过视图插入数据,最终还是会操作源表(基表)。
- 表结构约束传递:插入视图时,必须满足基表的所有约束条件(如 NOT NULL、主键、默认值等)。
- 自增长字段处理:对于自增主键(如 id),没有显式赋值不报错,会自动分配下一个值。
- NOT NULL 无默认值字段:如果插入时没有提供值,也没有默认值,数据库会报错!
Q61
Examine the following statement and its output:
EXPLAIN SELECT * FROM world.myview WHERE Name = "Rome"\G;
Sample output :
id: 1
select_type: SIMPLE
table: city
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4189
filtered: 10
Extra: Using where
Options
A. Column Name in myview can be indexed if the IS_UPDATABLE attribute is true.
B. myview was defined with the TEMPTABLE processing algorithm.
C. myview cannot be automatically indexed.
D. The underlying table's index on the Name column is not chosen because of low selectivity.
题目描述
请考察如下语句及其输出:
EXPLAIN SELECT * FROM world.myview WHERE Name = "Rome"\G;
输出信息:
id: 1
select_type: SIMPLE
table: city
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4189
filtered: 10
Extra: Using where
选项
A. 如果 IS_UPDATABLE 属性为 true,myview 中的 Name 列可以被索引。
B. myview 是用 TEMPTABLE 处理算法定义的。
C. myview 无法自动建立索引。
D. 因为低选择性,基础表的 Name 列索引未被选用。
选项分析
A. 如果 IS_UPDATABLE 属性为 true,myview 的 Name 列可以被索引。
错误。MySQL 视图是虚拟表,不能直接为视图列建立索引。即使是可更新视图,也无法为视图字段建索引。
B. myview 是用 TEMPTABLE 算法定义的。
错误。EXPLAIN 的输出无法直接判断视图处理算法(MERGE 或 TEMPTABLE)。且题干无相关证据。
C. myview 无法自动建立索引。
正确!MySQL 视图本身不能被索引,也不会自动创建索引。视图的查询性能取决于底层基表的索引,无法在视图层定义或获得索引。
D. 因为低选择性,基础表的 Name 列索引未被选用。
错误。possible_keys: NULL 表示基础表上该列本就没有可用索引,而不是选择性问题。如果有索引但选择性低,possible_keys 仍会显示索引名。
相关知识点总结
- MySQL 视图(VIEW)是逻辑上的表,不存储数据,也不能为其字段单独建索引。
- 视图查询时能否高效执行,取决于底层基表的索引,不能“自动给视图字段加索引”。
EXPLAIN结果中type: ALL且possible_keys: NULL说明全表扫描且没有可用索引。- 视图的可更新性、处理算法(如 MERGE 或 TEMPTABLE),与能否被索引没有直接关系。
答案
C. myview 无法自动建立索引。
Q62
Which two are true about MySQL connectors?
A. Connector/ODBC is available on Unix, Windows, and MacOS X.
B. Connector/J is based on Connector/C.
C. Connector/NET runs on the Windows platform only.
D. Connectors must be installed on both the client and server hosts.
E. Connector/Python is released in precompiled binary and source code.
中文翻译与解析
题目翻译
关于 MySQL 连接器,下列哪两项描述是正确的?
A. Connector/ODBC 可用于 Unix、Windows 和 MacOS X 操作系统。
B. Connector/J 是基于 Connector/C 的。
C. Connector/NET 仅能在 Windows 平台上运行。
D. 连接器必须同时安装在客户端和服务器主机上。
E. Connector/Python 同时以预编译二进制和源代码形式发布。
选项分析
-
A. Connector/ODBC 可用于 Unix、Windows 和 MacOS X 操作系统。
- 正确。MySQL 官方 ODBC 驱动支持所有主流桌面系统。
-
B. Connector/J 是基于 Connector/C 的。
- 错误。Connector/J 是用于 Java 的接口驱动,实现与 Connector/C 无关。
-
C. Connector/NET 仅能在 Windows 平台上运行。
- 错误。虽然主要为 .NET 构建,但也可通过 .NET Core 在其他操作系统上运行。
-
D. 连接器必须同时安装在客户端和服务器主机上。
- 错误。连接器一般只需安装在客户端,服务端只需 MySQL 服务端程序。
-
E. Connector/Python 同时以预编译二进制和源代码形式发布。
- 正确。MySQL Connector/Python 提供官方的预编译包和源码包,可供不同平台和需求部署。
正确答案
A. Connector/ODBC is available on Unix, Windows, and MacOS X.
E. Connector/Python is released in precompiled binary and source code.
相关知识点总结
- MySQL 官方连接器通常跨平台,均有多种语言支持;
- 不同 Connector 之间彼此独立(如 Connector/J 并非依赖 Connector/C);
- 连接器多数只需安装于客户端,不必在服务端;
- Python 连接器官方同时提供源码和二进制分发,方便不同开发环境。
Q63
Select three languages for which Oracle MySQL publishes drivers.
A. Java
B. Erlang
C. Ruby
D. Go
E. Python
F. Lua
G. Node.js
中文翻译与解析
题目翻译
请选择 Oracle MySQL 官方发布驱动程序的三种编程语言。
A. Java
B. Erlang
C. Ruby
D. Go
E. Python
F. Lua
G. Node.js
选项分析
-
A. Java
- 正确。Oracle 官方提供 [MySQL Connector/J] 驱动用于 Java。
-
B. Erlang
- 错误。没有官方 MySQL Erlang 驱动。
-
C. Ruby
- 错误。Ruby 仅有第三方驱动,无官方发布。
-
D. Go
- 错误。Go 也主要依赖社区驱动,Oracle 官方未直接发布。
-
E. Python
- 正确。Oracle 官方发布 [MySQL Connector/Python]。
-
F. Lua
- 错误。没有官方 Lua 驱动。
-
G. Node.js
- 正确。Oracle 官方提供 [MySQL Connector/Node.js] 驱动。
正确答案
A. Java
E. Python
G. Node.js
相关知识点总结
- Oracle 官方 MySQL Connector 驱动仅针对部分主流编程语言有正式发布(Java (JDBC), C++, Python, Node.js, PHP, and C.)。
- Ruby、Go 等语言,MySQL 驱动多由社区维护,不是 Oracle 官方直接发布。
Q64
Examine this statement which executes successfully:
CREATE TABLE `work` (
`job_no` INT NOT NULL,
`data` JSON NOT NULL,
`name` VARCHAR(30) GENERATED ALWAYS AS (JSON_EXTRACT(`data`,'$.first_name')) VIRTUAL,
PRIMARY KEY (`job_no`)
) ENGINE = INNODB;
The table is populated with a range of values including jobs for Robert, John, and Katie.
Now, examine this statement and output:
SELECT job_no, name
FROM work
WHERE name = 'Robert';
-- Empty set (0.0007 sec)
Why is an empty result set returned?
A. The SELECT requires JSON_UNQUOTE() in the WHERE clause.
B. The virtual values in the name column must be accessed using functions.
C. The JSON_EXTRACT() function requires a length value that matches the field length in the schema.
D. The JSON datatype cannot be used in VIRTUAL columns.
E. Table statistics must be updated to generate values for the name column.
中文翻译题目和选项
请检查以下能成功执行的语句:
CREATE TABLE `work` (
`job_no` INT NOT NULL,
`data` JSON NOT NULL,
`name` VARCHAR(30) GENERATED ALWAYS AS (JSON_EXTRACT(`data`,'$.first_name')) VIRTUAL,
PRIMARY KEY (`job_no`)
) ENGINE = INNODB;
该表包含了 Robert、John 和 Katie 等人员的工作记录。
现在,请分析以下语句和输出:
SELECT job_no, name
FROM work
WHERE name = 'Robert';
-- Empty set (无结果)
为什么会返回空结果集?
A. SELECT 在 WHERE 子句中需要用 JSON_UNQUOTE()。
B. name 列中的虚拟值必须通过函数访问。
C. JSON_EXTRACT() 函数要求长度值要与表结构字段长度匹配。
D. JSON 类型不能用于 VIRTUAL 列。
E. 需要更新表统计信息才能为 name 列生成值。
选项解析
A. The SELECT requires JSON_UNQUOTE() in the WHERE clause.
JSON_EXTRACT 返回的是 JSON 字符串,是 "Robert"(带双引号的字符串),等号右边是 'Robert'(不带引号的普通字符串),这两者不相等。
用 JSON_UNQUOTE(JSON_EXTRACT(...)) 或 JSON_UNQUOTE(name) 可以移除多余的引号,使比较成立。
正确答案。
B. 虚拟值必须通过函数访问。
虚拟列可直接用于 SELECT,与存储值无区别,不需要函数才能访问。
C. JSON_EXTRACT() 函数要求长度值与字段长度匹配。
JSON_EXTRACT 与字段长度无直接关系,VARCHAR(30) 只是最大长度约束,不影响 JSON_EXTRACT 执行。
D. JSON 类型不能用于虚拟列。
完全可以,MySQL 支持用 JSON 列生成虚拟列。
E. 需要更新统计信息以生成 name 列的值。
表统计和生成虚拟列值无直接关系,与本题无关。
正确答案
A. The SELECT requires JSON_UNQUOTE() in the WHERE clause.
知识点总结
- JSON_EXTRACT 从 JSON 格式字段中提取数据,但结果通常包含引号,即为 JSON 字符串(如 "Robert")。
- JSON_UNQUOTE() 可以去掉提取结果中的引号,得到普通字符串。
- 比较字符串时,"Robert"(带引号)和 Robert(不带引号)不同,WHERE name = 'Robert' 会因类型/内容不匹配导致无结果。
- 可以通过 WHERE JSON_UNQUOTE(name) = 'Robert' 或 WHERE JSON_UNQUOTE(JSON_EXTRACT(data, '$.first_name')) = 'Robert' 来实现正确匹配。
- MySQL 的虚拟列可以基于 JSON 字段生成,且可直接用于 WHERE/SELECT。
Q65
Which string function can be used to extract a portion of a non-numeric character string?
A. EXTRACT()
B. TRUNCATE()
C. INSTR()
D. SUBSTR()
中文翻译题目和选项
下列哪个字符串函数可用于提取非数值字符型字符串中的一部分?
A. EXTRACT()
B. TRUNCATE()
C. INSTR()
D. SUBSTR()
选项解析
- A. EXTRACT()
- 用于从日期/时间类型数据中提取部分字段(如年、月、日),不是处理字符串的函数。
- B. TRUNCATE()
- 用于截断数字的小数部分或截断表数据,不适用于字符子串的提取。
- C. INSTR()
- 用于查找某个子串在字符串中首次出现的位置,返回索引,而不是提取子串。
- D. SUBSTR()
- 用于从字符串中提取指定起始位置和长度的子串,正确答案。
正确答案
D. SUBSTR()
知识点总结
- SUBSTR() 函数(或其同义词 SUBSTRING())用来从字符串中提取指定部分,非常常用。
- 例如:
SELECT SUBSTR('abcdef', 2, 3);返回bcd。
- 例如:
- EXTRACT(), TRUNCATE(), INSTR() 在处理字符串提取时不适用。
Q66
英文原文
Examine the contents of these tables:
Department:
| dept_id | dept_name |
|---|---|
| 100 | sales |
| 102 | purchase |
Employee:
| emp_id | emp_name | dept_id |
|---|---|---|
| 1 | Peter | 100 |
| 2 | John | 102 |
| 3 | George | NULL |
Now examine the expected results for a user with privileges to access the table:
| emp_id | dept_name |
|---|---|
| 3 | NULL |
| 1 | sales |
| 2 | purchase |
Which query returns the expected results?
A.
SELECT e.emp_id, d.dept_name
FROM employee e
LEFT JOIN department d ON d.dept_id = e.dept_id
WHERE e.dept_id IS NULL;
B.
SELECT e.emp_id, d.dept_name
FROM employee e, department d
WHERE d.dept_id = e.dept_id;
C.
SELECT emp_id, (SELECT dept_name
FROM department
WHERE dept_id = employee.dept_id) dept_name
FROM employee;
D.
SELECT emp_id, (SELECT dept_name FROM department) dept_name
FROM employee
WHERE dept_id = employee.dept_id;
中文翻译题目和选项
请检查如下两张表的内容:
Department(部门表):
| dept_id | dept_name |
|---|---|
| 100 | sales |
| 102 | purchase |
Employee(员工表):
| emp_id | emp_name | dept_id |
|---|---|---|
| 1 | Peter | 100 |
| 2 | John | 102 |
| 3 | George | NULL |
期望结果如下:
| emp_id | dept_name |
|---|---|
| 3 | NULL |
| 1 | sales |
| 2 | purchase |
哪个查询语句能返回期望结果?
A.
SELECT e.emp_id, d.dept_name
FROM employee e
LEFT JOIN department d ON d.dept_id = e.dept_id
WHERE e.dept_id IS NULL;
B.
SELECT e.emp_id, d.dept_name
FROM employee e, department d
WHERE d.dept_id = e.dept_id;
C.
SELECT emp_id, (SELECT dept_name
FROM department
WHERE dept_id = employee.dept_id) dept_name
FROM employee;
D.
SELECT emp_id, (SELECT dept_name FROM department) dept_name
FROM employee
WHERE dept_id = employee.dept_id;
选项解析
A 选项
只会查出 dept_id 为 NULL(即 George),但 dept_name 恒为 NULL。不包含 Peter, John 的记录,不是期望结果。
B 选项
等价于 INNER JOIN 只查出 dept_id 匹配的记录,George (emp_id=3) 因为 dept_id NULL 不会被查出,不全。
C 选项
针对每个 employee,动态子查询查其 dept_name。没有匹配时返回 NULL(如 George),其他能查到对应部门名称。完全匹配题目要求,且没有顺序干扰(SQL 查询未特别排序时结果顺序实现相关)。
正确答案。
D 选项
子查询没有 where,返回 department 所有行,会报错(子查询多于一行),或不返回预期结果。
正确答案
C.
子查询
https://dev.mysql.com/doc/refman/8.0/en/subqueries.html
子查询的定义与用法
- 子查询是嵌套在另一个 SQL 语句内部的
SELECT语句。 - 子查询总是要用括号括起来,例如:
SELECT * FROM t1 WHERE column1 = (SELECT column1 FROM t2);
这里外层为主查询,括号内为子查询,可以多层嵌套。
子查询的优势
让 SQL 逻辑更结构化,便于分块思考。
经常能代替复杂的 JOIN 或 UNION 操作,语句更简洁。
更具可读性,很多场景下比写 JOIN 更容易理解。
子查询类型
- 标量子查询(scalar subquery):只返回 single value。
- 行子查询(row subquery):返回单行多列。
- 列子查询(column subquery):返回单列多行。
- 表子查询(table subquery):返回多行多列组成的临时表(常见于 IN, EXISTS)。
子查询可用的位置
基本上可以在任何 SQL 语句里用子查询,包括:SELECT、INSERT、UPDATE、DELETE、SET、DO 等。
其他说明
子查询可包含大多数普通 SELECT 子句(如 DISTINCT、GROUP BY、ORDER BY、LIMIT、JOIN 以及函数、UNION 等)。
MySQL 8.0.19+ 支持在子查询中使用 TABLE 和 VALUES 语法,功能更强大。
- 例子(如 WHERE 子句相关子查询)
SELECT emp_id, (SELECT dept_name FROM department WHERE dept_id = employee.dept_id) dept_name
FROM employee;
该语句示例就是“相关子查询”典型,能根据外层每一行动态检索匹配部门名称。
Q67
Examine this CRUD operation:
JS > col.find()
{
"_id": "00005e858eb0000000000009",
"name": "fred"
}
1 document in set (0.0003 sec)
Which two SQL statements are valid?
- A. ALTER TABLE col ADD COLUMN result INT GENERATED ALWAYS as (doc->>"$.result") VIRTUAL DEFAULT 0;
- B. ALTER TABLE col ADD COLUMN result INT GENERATED ALWAYS as (doc->>"$.result") STORED DEFAULT '0';
- C. ALTER TABLE col ADD COLUMN result INT GENERATED ALWAYS as (doc->>"$.result") STORED;
- D. ALTER TABLE col ADD COLUMN result INT GENERATED ALWAYS as (doc->>"$.result") VIRTUAL NOT NULL;
- E. ALTER TABLE col ADD COLUMN result INT GENERATED ALWAYS as (doc->>"$.result") STORED NOT NULL;
答案:CD
中文翻译题目和选项
请检查此 CRUD 操作:
JS > col.find()
{
"_id": "00005e858eb0000000000009",
"name": "fred"
}
1 document in set (0.0003 sec)
下列两个 SQL 语句是有效的?
A. ALTER TABLE col ADD COLUMN result INT GENERATED ALWAYS as (doc->>"$.result") VIRTUAL DEFAULT 0;
B. ALTER TABLE col ADD COLUMN result INT GENERATED ALWAYS as (doc->>"$.result") STORED DEFAULT '0';
C. ALTER TABLE col ADD COLUMN result INT GENERATED ALWAYS as (doc->>"$.result") STORED;
D. ALTER TABLE col ADD COLUMN result INT GENERATED ALWAYS as (doc->>"$.result") VIRTUAL NOT NULL;
E. ALTER TABLE col ADD COLUMN result INT GENERATED ALWAYS as (doc->>"$.result") STORED NOT NULL;
题干含义:
本题目询问有效的 SQL 语句用于更新数据表,操作其字段按照 JSON 文档中的数据进行计算。
选项分析
- A: 试图创建一个虚拟列并设置了默认值0,生成列语法上不支持
DEFAULT,不正确。 - B: 创建一个存储列并设置了默认值'0',生成列语法上不支持
DEFAULT,不正确。 - C: 创建一个存储列,未设定默认值,语法上是有效的,正确答案。
- D: 创建一个虚拟列并标记其为
NOT NULL,符合语法规则,可以执行,正确(虚拟列在计算时生成值,就算计算时计算出null报错也是后话了,这个语句可以成功就够了)。 - E: 创建一个存储列并标记其为
NOT NULL,但由于 STORED 列在添加列时需计算并存储所有行值,如果现有数据中 $.result 路径不存在,表达式返回 NULL,违反 NOT NULL 约束,导致语句执行失败,不正确。
答案:CD
相关知识点总结
- 虚拟列(VIRTUAL):在计算时生成值但未实际存储,适用于不频繁使用的列或需要计算得出的列。
- 存储列(STORED):值计算后存储在列中,适用于频繁访问数据的情况。
- JSON 文档处理:使用
doc->>快速提取 JSON 字段,同时在列定义中使用时要注意存储类型的要求。
15.1.20.8 CREATE TABLE and Generated Columns
https://dev.mysql.com/doc/refman/8.0/en/create-table-generated-columns.html
概要:
MySQL支持在CREATE TABLE语句中使用生成列(Generated Columns)。生成列的值由列定义中包含的表达式计算而来。
示例:
生成列的一个简单示例展示了如何在三角形表中计算直角三角形的斜边长度:
CREATE TABLE triangle (
sidea DOUBLE,
sideb DOUBLE,
sidec DOUBLE AS (SQRT(sidea * sidea + sideb * sideb))
);
插入示例数据并查询结果:
INSERT INTO triangle (sidea, sideb) VALUES(1,1),(3,4),(6,8);
SELECT * FROM triangle;
结果:
| sidea | sideb | sidec |
|---|---|---|
| 1 | 1 | 1.4142 |
| 3 | 4 | 5 |
| 6 | 8 | 10 |
生成列定义语法:
col_name data_type [GENERATED ALWAYS] AS (expr)
[VIRTUAL | STORED] [NOT NULL | NULL]
[UNIQUE [KEY]] [[PRIMARY] KEY]
[COMMENT 'string']
AS (expr):定义该列是生成列,并指定计算表达式。VIRTUAL:列值不存储,只在读取行时计算(在BEFORE触发器之后),不需存储空间。STORED:在插入或更新行时评估并存储列值,需要存储空间,并可索引。- 默认存储方式为
VIRTUAL。
表达式规则:
生成列的表达式须符合以下规则:
- 允许使用字面值、确定性内建函数和操作符。
- 子查询、存储过程、函数参数、变量等不允许使用。
- 可以引用表定义中较早的其他生成列。
用例:
- 简化和统一查询:复杂条件定义为生成列,可通过多个查询使用。
- 存储生成列可用于条件的物化缓存,减少动态计算的成本。
- 生成列可模拟功能索引,优化器可使用生成列索引进行查询优化。
通过生成列可以实现直接查询组合信息如full_name,避免多次写出表达式:
CREATE TABLE t1 (
first_name VARCHAR(10),
last_name VARCHAR(10),
full_name VARCHAR(255) AS (CONCAT(first_name,' ',last_name))
);
SELECT full_name FROM t1;
虚拟列
虚拟列是 MySQL 中的一种生成列,本质上是通过表达式动态计算并在读取行时评估的列。虚拟列的一个显著特点是其不占用存储空间。其使用和定义如下:
- 存储方式: 虚拟列的值在读取行之后立即计算,因此对存储来说没有空间占用。与存储的列不同,虚拟列不在插入或更新时进行存储。
- 索引支持: 虚拟列可以在
InnoDB中被支持使用次级索引。详情请参考 https://dev.mysql.com/doc/refman/8.4/en/create-table-secondary-indexes.html 。 - 默认选择: 定义生成列时,如果不指定是
VIRTUAL或STORED,默认语法选择为VIRTUAL。
使用场景:
- 简化和统一查询:复杂条件可以定义为虚拟生成列,并在多次表查询中引用这些条件,以确保一致性。
与存储生成列的区别在于,虚拟列不在物理存储中存在,因此适合用于不涉及频繁条件计算负荷的查询优化。
虚拟列允许简化数据表结构,方便应用程序直接选择需要的结果而不用反复计算条件。
相关链接:https://dev.mysql.com/doc/refman/8.4/en/create-table-generated-columns.html
Q68
Examine this statement which executes successfully:
CREATE TABLE fshop ('product' JSON DEFAULT NULL) ENGINE=InnoDB;
Now, examine a JSON value contained in the table:
{
"name": "orange",
"varieties": [
{
"VarietyName": "clementine",
"Origin": ["PA", "SU"]
},
{
"VarietyName": "tangerine",
"Origin": ["CH", "JP"]
}
]
}
Which will cause documents to be indexed over the 'name' key?
A. ALTER TABLE fshop ADD COLUMN name VARCHAR(20), ADD KEY idx_name(name);
B. ALTER TABLE fshop ADD name VARCHAR(20) AS (JSON_UNQUOTE(product->"$.name")), ADD INDEX (name);
C. ALTER TABLE fshop ADD COLUMN name VARCHAR(20) AS (product->>"$.name") VIRTUAL, ADD KEY idx_name(name);
D. ALTER TABLE fshop ADD COLUMN name VARCHAR(20) AS (product->>"$.varieties.VarietyName") VIRTUAL, ADD KEY idx_name(name);
E. ALTER TABLE fshop ADD COLUMN name VARCHAR(100) AS (product->>"$.varieties") VIRTUAL, ADD KEY idx_name(name);
中文翻译题目和选项
审查以下成功执行的语句:
CREATE TABLE fshop ('product' JSON DEFAULT NULL) ENGINE=InnoDB;
现在,检查表中包含的JSON值:
{
"name": "orange",
"varieties": [
{
"VarietyName": "clementine",
"Origin": ["PA", "SU"]
},
{
"VarietyName": "tangerine",
"Origin": ["CH", "JP"]
}
]
}
哪一个语句将导致文档通过'name'键索引?
A. ALTER TABLE fshop ADD COLUMN name VARCHAR(20), ADD KEY idx_name(name);
B. ALTER TABLE fshop ADD name VARCHAR(20) AS (JSON_UNQUOTE(product->"$.name")), ADD INDEX (name);
C. ALTER TABLE fshop ADD COLUMN name VARCHAR(20) AS (product->>"$.name") VIRTUAL, ADD KEY idx_name(name);
D. ALTER TABLE fshop ADD COLUMN name VARCHAR(20) AS (product->>"$.varieties.VarietyName") VIRTUAL, ADD KEY idx_name(name);
E. ALTER TABLE fshop ADD COLUMN name VARCHAR(100) AS (product->>"$.varieties") VIRTUAL, ADD KEY idx_name(name);
答案:C
题干含义:
题目要求找出能使用'ALTER TABLE'语句使表中的JSON文档通过'name'键进行索引的语句。
选项分析:
- A: 简单添加字段和索引,但对JSON内容没有影响,语法不对。(错误)
- B: 缺少 COLUMN ,语法错误。(错误)
- C: 使用->>操作符解析'$.name'为虚拟字段以进行索引,正确。(正确答案)
- D: 操作符应用于错误的JSON路径,目标不是'name'键。(错误)
- E: 同样不对应JSON路径;过大的VARCHAR定义且错误引用。(错误)
相关知识点总结
-
JSON 数据类型: JSON数据类型允许更为复杂的结构存储在单个列内,在MySQL中使用时可支持多种函数进行操作。
-
索引JSON数据: 使用JSON类型字段时,JSON_UNQUOTE和->>是常用的方法用于提取字段值以供索引。
-
虚拟列: 可以创建虚拟列去保存JSON解析结果以供索引,节省存储空间。
-
ALTER TABLE 使用:
ALTER TABLE语句允许表布局的修改,包括增加列和键索引,是数据库管理维护的过程之一。
Secondary Indexes and Generated Columns(二级索引和生成列)
https://dev.mysql.com/doc/refman/5.7/en/create-table-secondary-indexes.html
概述
-
InnoDB支持虚拟生成列的二级索引:这些索引有时被称为“虚拟索引”,能够创建在一个或多个虚拟列上,或与常规和存储生成的列组合在一起。
-
虚拟生成列上的索引:生成列的值会在索引记录中物化。这种索引可以被定义为
UNIQUE。 -
覆盖索引:当索引本身就包括查询中所需的全部列时,直接从索引结构的物化值中获取数据,而不是实时计算。
-
写入成本:使用虚拟列上的二级索引时,在
INSERT和UPDATE操作中会有额外的计算和写入成本。然而,虚拟列的二级索引可能仍然比存储生成列更优,后者会导致表变大并占用更多的磁盘空间和内存。 -
回滚操作中的MVCC日志记录:用于虚拟列的索引值会被日志记录,以免在回滚或清理操作中重新计算。
- JSON列索引:由于JSON列无法直接索引,可通过定义生成列来提取可索引的信息,然后对生成列创建索引。
- 间接索引:此技巧可用于间接引用其他类型的列的索引,范如
GEOMETRY类型的列。
NDB集群中的间接索引
-
NDB与JSON:在MySQL NDB Cluster中,JSON列会被内部处理为BLOB,因此必须有一个主键以便能够记录在二进制日志中。
-
虚拟列在NDB中限制:NDB存储引擎不支持虚拟列的索引,所以必须显式指定相关生成列为
STORED。
示例
通过示例展示如何在JSON列实现间接索引:
CREATE TABLE jemp (
c JSON,
g INT GENERATED ALWAYS AS (c->"$.id"),
INDEX i (g)
);
-
查询优化:为了验证索引运作,使用EXPLAIN查看优化器如何利用生成列索引来改善查询性能。
-
插入样例:在表中插入JSON值:
INSERT INTO jemp (c) VALUES ('{"id": "1", "name": "Fred"}'), ('{"id": "2", "name": "Wilma"}');
Q69
You must write a statement that can insert the last name O'Hara into a column of the customers table.
Which two INSERT statements meet your requirement?
A. INSERT INTO customers (last_name) VALUES ('O'Hara');
B. INSERT INTO customers (last_name) VALUES ('O%27Hara');
C. INSERT INTO customers (last_name) VALUES ('O\\'Hara');
D. INSERT INTO customers (last_name) VALUES ("O""Hara");
E. INSERT INTO customers (last_name) VALUES ('O''Hara');
答案:C和E
中文翻译题目和选项
你需要编写一个语句,将姓氏 O'Hara 插入到 customers 表的某列中。
哪两个 INSERT 语句满足你的要求?
INSERT INTO customers (last_name) VALUES ('O'Hara');INSERT INTO customers (last_name) VALUES ('O%27Hara');INSERT INTO customers (last_name) VALUES ('O\\'Hara');INSERT INTO customers (last_name) VALUES ("O""Hara");INSERT INTO customers (last_name) VALUES ('O''Hara');
选项分析:
- 选项 A: 单引号未进行转义,语法错误。
- 选项 B: 使用URL编码替代引用对象,对于SQL无效。
- 选项 C: 使用反斜杠转义单引号,正确用法。(正确答案)
- 选项 D: 使用双引号进行另层转义,错误。
- 选项 E: 双引号方案,用两个单引号代替单引号是SQL拼接的正确方法。(正确答案)
相关知识点总结
- SQL 语句中的转义符: 在SQL中单引号用于字符串界定符,若包含在内容中需被正确转义,比如用两个单引号或反斜杠。
Q70
Examine these commands which execute successfully:
CREATE TABLE income (acct_num INT, amount DECIMAL(10,2));
CREATE TRIGGER subtotal BEFORE INSERT ON income FOR EACH ROW
SET @subtotal = @subtotal + NEW.amount;
Which is true for the income table?
A. Execution of an INSERT statement causes the trigger to activate.
B. The trigger activates after any row in the table has been updated.
C. The trigger activates after any row has been inserted into the table.
D. The trigger body SET causes trigger activation.
答案:A
中文翻译题目及选项
审查以下成功执行的命令:
CREATE TABLE income (acct_num INT, amount DECIMAL(10,2));
CREATE TRIGGER subtotal BEFORE INSERT ON income FOR EACH ROW
SET @subtotal = @subtotal + NEW.amount;
对于所得表以下哪项是正确的?
A. 执行插入语句激活触发器。
B. 当表中任意行更新后触发器激活。
C. 当行插入表后触发器激活。
D. 触发器主题设置导致触发器激活。
选项分析:
- 选项 A: 正确指出 INSERT 语句执行时激活触发器。(正确答案)
- 选项 B: 并未定义任何UPDATE相关行为。
- 选项 C: 错误,引发时间为插入前。
- 选项 D: 触发器体不引起激活,而是由语句事件。
相关知识点总结
- 触发器机制: SQL触发器用于在表上定义自动化操作,可以在指定事件前或后定义如INSERT、UPDATE、DELETE等,且每行影响。
Q71
Examine this table structure:
PRODUCT (P_ID INT, BAR_CODE INT, PNAME TEXT, PRIMARY KEY (P_ID, BAR_CODE));
When you insert duplicate entry for the composite key values, MySQL displays:
ERROR 1062 (23000): Duplicate entry '1-12346' for key 'product.PRIMARY'
When you insert a duplicate key, you want to only generate the output:
+--------------+
| ID_Error |
+--------------+
| ID: 1 and BarCode: 12346 ALREADY EXISTS. |
+--------------+
Now examine this statement:
CREATE PROCEDURE InsertProduct(IN P INT, IN C INT, IN N TEXT)
BEGIN
<place-holder 1>
INSERT INTO Product(P_ID, BAR_CODE, PNAME) VALUES(P, C, N);
SELECT COUNT(*) FROM product;
END
Which code fragment at <place-holder 1> meets your requirement?
A.
DECLARE CONTINUE HANDLER FOR 23000
BEGIN
SELECT concat("ID: ",P," and BarCode: ", C ," ALREADY EXISTS.") as ID_Error;
END;
B.
DECLARE CONTINUE HANDLER FOR 1062
BEGIN
SELECT concat("ID: ",P," and BarCode: ", C ," ALREADY EXISTS.") as ID_Error;
END;
C.
DECLARE EXIT HANDLER FOR 1062
BEGIN
SELECT concat("ID: ",P," and BarCode: ", C ," ALREADY EXISTS.") as ID_Error;
END;
D.
DECLARE dupKey INT DEFAULT 0;
DECLARE EXIT HANDLER FOR 23000 SET dupKey = 1;
BEGIN
IF dupKey=1 THEN
...
END IF;
END;
答案:B
中文翻译题目和选项
请检查下面的表结构:
PRODUCT (P_ID INT, BAR_CODE INT, PNAME TEXT, PRIMARY KEY (P_ID, BAR_CODE));
当你为复合键值插入重复项时,MySQL显示:
ERROR 1062 (23000): Duplicate entry '1-12346' for key 'product.PRIMARY'
插入重复键时,您希望只生成输出:
+--------------+
| ID_Error |
+--------------+
| ID: 1 and BarCode: 12346 ALREADY EXISTS. |
+--------------+
现在检查此语句:
CREATE PROCEDURE InsertProduct(IN P INT, IN C INT, IN N TEXT)
BEGIN
<place-holder 1>
INSERT INTO Product(P_ID, BAR_CODE, PNAME) VALUES(P, C, N);
SELECT COUNT(*) FROM product;
END
哪个代码片段可以在 <place-holder 1> 满足您的要求?
A.
DECLARE CONTINUE HANDLER FOR 23000
BEGIN
SELECT concat("ID: ",P," and BarCode: ", C ," ALREADY EXISTS.") as ID_Error;
END;
B.
DECLARE CONTINUE HANDLER FOR 1062
BEGIN
SELECT concat("ID: ",P," and BarCode: ", C ," ALREADY EXISTS.") as ID_Error;
END;
C.
DECLARE EXIT HANDLER FOR 1062
BEGIN
SELECT concat("ID: ",P," and BarCode: ", C ," ALREADY EXISTS.") as ID_Error;
END;
D.
DECLARE dupKey INT DEFAULT 0;
DECLARE EXIT HANDLER FOR 23000 SET dupKey = 1;
BEGIN
IF dupKey=1 THEN
...
END IF;
END;
选项分析:
关于1062和23000:
- 1062:
MySQL专用代码:这是 MySQL 自己的错误编号,用于具体识别违反唯一约束的错误(就是说你插入了数据库中重复的值)。 - 23000:
通用错误代码:这是一个标准化的代码,不止 MySQL 用,很多数据库都会用。它表示有东西不满足数据库的完整性规则(如某些值应该是唯一的)。 - 同时显示的原因
细节与兼容性:1062告诉你具体是因为什么(哪个值重复了),这样对 MySQL 用户可以更好地理解问题。而 23000 是一种通用语言,就像世界语,方便不同数据库系统都能理解和处理相似的问题。这对软件在不同数据库之间的移植和兼容性很重要。
两者一起提供了一个从具体到广义的错误信息链条。
- 选项 A: 错误代码匹配不准确,使用23000捕获通用约束失败。
- 选项 B: 1062精确匹配重复键错误代码并相应处理,继续执行流程展示错误信息。(正确答案)
- 选项 C: 虽然处理代码正确,但
EXIT HANDLER会退出处理器,中止执行。 - 选项 D: 复杂设置没必要,简化了直接输出逻辑的需求环境。
相关知识点总结
- 重复键的处理: 通过声明错误处理器可以在存储过程中解决重复键约束引发的错误。
- 错误代码: 不同的错误有不同的错误代码,如1062专门标识重复键插入,而23000指示通用约束失败。
- 存储过程中的异常处理:
CONTINUE HANDLER允许继续后续执行,而EXIT HANDLER会终止当前块。
Q72
You must suppress warning messages but display error messages.
Which command will do this?
A. SET SQL_WARNINGS=3;
B. SET @SQL_WARNINGS=1;
C. SET SQL_WARNINGS=1;
D. SET @SQL_WARNINGS=0;
E. SET @SQL_WARNINGS=3;
F. SET SQL_WARNINGS=0;
答案:F
中文翻译题目和选项
你需要压制警告消息但显示错误消息。
哪个命令可以做到这一点?
A. SET SQL_WARNINGS=3;
B. SET @SQL_WARNINGS=1;
C. SET SQL_WARNINGS=1;
D. SET @SQL_WARNINGS=0;
E. SET @SQL_WARNINGS=3;
F. SET SQL_WARNINGS=0;
选项分析:
-
选项 A, C: 错误,SQL_WARNINGS 的设置是布尔值。
-
选项 B, D, E:
@ 符号用于定义和使用用户会话变量。它使用户能够在会话中存储和传递值,于SQL语句和脚本中共享数据。
@SQL_WARNINGS 是用户可以定义并使用的会话级变量,不同于系统变量,它没有直接影响 SQL 警告的输出行为 -
选项 F: 通过
SET SQL_WARNINGS=0,可以关闭警告显示,只产生错误消息。(正确答案)
相关知识点总结
-
SQL_WARNINGS 变量: 此变量用于控制 SQL 警告消息输出。设置为
0时关闭警告,1时启用警告。 -
警告与错误: 警告常用于指出潜在问题,但不阻止语句继续执行。而错误是会中断执行的问题,须修正后续执行。
sql_warnings
https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_sql_warnings
- 系统变量:
sql_warnings - 范围: 全局, 会话
- 动态: 是
- 类型: 布尔型
- 默认值: OFF
描述
sql_warnings 变量决定单行 INSERT 语句在发生警告时是否会生成信息字符串。默认情况下,该变量设置为 OFF,意味着不会生成信息字符串。将变量设置为 ON 允许系统生成警告信息,这对于调试或了解数据插入问题可能很有用。
使用方式
- 默认行为:
OFF- 不生成信息字符串。
- 启用警告信息:
- 将变量设置为
ON可以在单行INSERT操作后接收到警告信息。
- 将变量设置为
Q73
Examine this statement and output:
mysql> DROP TABLE t1;
ERROR 1051 (42802): Unknown table 'db1.t1'
Which will provide the same level of detail when the error is encountered within a stored routine?
A.
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS CONDITION 1 @num = NUMBER, @errno = MYSQL_ERRNO, @text = MESSAGE_TEXT;
SET @full_error = CONCAT("ERROR ", @errno, " (", @num, "): ", @text);
SELECT @full_error;
END;
B.
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS CONDITION 1 @sqlstate = RETURNED_SQLSTATE, @errno = MYSQL_ERRNO, @text = MESSAGE_TEXT;
SET @full_error = CONCAT("ERROR ", @errno, " (", @sqlstate, "): ", @text);
SELECT @full_error;
END;
C.
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS CONDITION 1 @sqlstate = RETURNED_SQLSTATE, @num = NUMBER;
SELECT @sqlstate;
END;
D.
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS CONDITION 1 @sqlstate = RETURNED_SQLSTATE, @errno = MYSQL_ERRNO, @num = NUMBER;
SET @full_error = CONCAT("ERROR ", @errno, " (", @sqlstate, "): ", @num);
SELECT @full_error;
END;
答案:B
中文翻译题目和选项
请检查以下语句和输出:
mysql> DROP TABLE t1;
ERROR 1051 (42802): Unknown table 'db1.t1'
哪个选项将在存储过程中错误发生时提供同样详细的信息?
A.
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS CONDITION 1 @num = NUMBER, @errno = MYSQL_ERRNO, @text = MESSAGE_TEXT;
SET @full_error = CONCAT("ERROR ", @errno, " (", @num, "): ", @text);
SELECT @full_error;
END;
B.
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS CONDITION 1 @sqlstate = RETURNED_SQLSTATE, @errno = MYSQL_ERRNO, @text = MESSAGE_TEXT;
SET @full_error = CONCAT("ERROR ", @errno, " (", @sqlstate, "): ", @text);
SELECT @full_error;
END;
C.
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS CONDITION 1 @sqlstate = RETURNED_SQLSTATE, @num = NUMBER;
SELECT @sqlstate;
END;
D.
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS CONDITION 1 @sqlstate = RETURNED_SQLSTATE, @errno = MYSQL_ERRNO, @num = NUMBER;
SET @full_error = CONCAT("ERROR ", @errno, " (", @sqlstate, "): ", @num);
SELECT @full_error;
END;
选项分析:
- 选项 A: 提供错误号码和错误文本,但缺少
SQLSTATE信息。 - 选项 B: 包含
SQLSTATE、错误号码、错误代码及文本,与问题实际输出详细级别相符。(正确答案) - 选项 C: 仅返回
SQLSTATE和号码,不详细。 - 选项 D: 提供错误代码和号码,但未提供错误文本。
相关知识点总结
- GET DIAGNOSTICS: 用于获取关于最近执行错误的详细信息,常用于异常处理环境中提供丰富的上下文。
- SQLSTATE: 跨SQL标准的五字符代码,提供错误的详细技术原因,与具体错误代码、文本一起提供整个错误的全貌。
MySQL 8.0 Reference: GET DIAGNOSTICS Statement
https://dev.mysql.com/doc/refman/8.0/en/get-diagnostics.html
概述
GET DIAGNOSTICS 语句用于检查 SQL 语句产生的诊断信息,可以获取有关错误、警告和影响行数等详细信息。使用 SHOW WARNINGS 或 SHOW ERRORS 可以查看条件或错误。
用法语法
GET [CURRENT | STACKED] DIAGNOSTICS {
statement_information_item
[, statement_information_item] ...
| CONDITION condition_number
condition_information_item
[, condition_information_item] ...
}
- CURRENT: 从当前诊断区域获取信息。
- STACKED: 在条件处理器中从第二诊断区域获取信息,仅在条件处理器激活时可用。若无指定,则默认为当前诊断区域。
信息项
-
声明信息项(statement_information_item_name):
NUMBER: 条件数量ROW_COUNT: 影响行数
-
条件信息项(condition_information_item_name):
CLASS_ORIGIN: 类来源SUBCLASS_ORIGIN: 子类来源RETURNED_SQLSTATE: 返回的 SQL 状态码MESSAGE_TEXT: 错误信息文本MYSQL_ERRNO: MySQL错误号CONSTRAINT_CATALOG: 约束目录CONSTRAINT_SCHEMA: 约束模式CONSTRAINT_NAME: 约束名称CATALOG_NAME: 目录名称SCHEMA_NAME: 模式名称TABLE_NAME: 表名称COLUMN_NAME: 列名称CURSOR_NAME: 游标名称
参数解释
condition_number: 用于指明诊断区域中的条件编号,可以是存储过程或函数参数、用户定义变量、系统变量或文本字面。
示例
获取 SQLSTATE 和错误文本:
GET DIAGNOSTICS CONDITION 1
@p1 = RETURNED_SQLSTATE, @p2 = MESSAGE_TEXT;
SELECT @p1, @p2;
存储程序使用的实例:
CREATE PROCEDURE do_insert(value INT)
BEGIN
DECLARE code CHAR(5) DEFAULT '00000';
DECLARE msg TEXT;
DECLARE nrows INT;
DECLARE result TEXT;
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
BEGIN
GET DIAGNOSTICS CONDITION 1
code = RETURNED_SQLSTATE, msg = MESSAGE_TEXT;
END;
INSERT INTO t1 (int_col) VALUES(value);
IF code = '00000' THEN
GET DIAGNOSTICS nrows = ROW_COUNT;
SET result = CONCAT('insert succeeded, row count = ',nrows);
ELSE
SET result = CONCAT('insert failed, error = ',code, ', message = ',msg);
END IF;
SELECT result;
END;
关键点
- 使用
GET DIAGNOSTICS可以高效诊断 SQL 错误,帮助开发人员迅速调试和解决问题。 STACKED诊断区域提供了条件处理器激活信息,在存储过程中尤为重要。
通过使用 GET DIAGNOSTICS,开发者能够深入理解 SQL 执行过程中的错误信息,从而更有效地进行调试。
Q74
Examine this statement and output:
CREATE TABLE geom (g GEOMETRY NOT NULL, SPATIAL INDEX(g));
Query OK, 0 rows affected, 1 warning (0.01 sec)
An attempt is made to add an SRID attribute to the column using the statement:
ALTER TABLE geom MODIFY COLUMN g geometry NOT NULL SRID 0;
Which is true?
- A. Execution succeeds and allows the use of the index by the optimizer.
- B. An error is generated because the index prevents changes to the column.
- C. An error is generated because SRID 0 is an invalid identifier value.
- D. Execution succeeds with a warning.
中文翻译题目和选项
请检查如下语句及输出:
CREATE TABLE geom (g GEOMETRY NOT NULL, SPATIAL INDEX(g));
Query OK, 0 行受影响, 1 警告 (0.01 秒)
试图使用以下语句向列添加 SRID 属性:
ALTER TABLE geom MODIFY COLUMN g geometry NOT NULL SRID 0;
哪个说法正确?
- A. 执行成功,并允许优化器使用索引。
- B. 因为索引阻止对列进行更改而产生错误。
- C. 因为
SRID 0是无效标识符值而产生错误。 - D. 执行成功,但带有警告。
答案解析
题干含义:
题目首先创建了一个表 geom,包含一个 geometry 类型的列,该列没有SIRD属性,并指定了空间索引。
接着尝试通过 ALTER TABLE 语句为该列添加 SRID 属性。
测试结果:ERROR 3644 (HY000) at line 4: The SRID specification on the column 'g' cannot be changed because there is a spatial index on the column. Please remove the spatial index before altering the SRID specification.
选项分析
-
A. 执行成功,并允许优化器使用索引。
优化器会使用带有SIRD属性的空间索引,但空间索引通常阻止对列进行修改。 -
B. 因为索引阻止对列进行更改而产生错误。
空间索引通常阻止对列进行修改,此选项正确。 -
C. 因为
SRID 0是无效标识符值而产生错误。
指定的SRID 0是有效值,代表一个无限的平面直角坐标系。 -
D. 执行成功,但带有警告。
错误,不存在警告。
正确答案:
选择 B。
相关知识点总结
- GEOMETRY 和 SPATIAL INDEX 用于地理空间数据存储和优化。
- ALTER TABLE MODIFY COLUMN 用于在表中修改列定义。
- SRID 是定义地理数据参考系统的标识符,需要合理性和一致性。
空间数据类型
https://dev.mysql.com/doc/refman/8.0/en/spatial-type-overview.html
MySQL 提供了与 OpenGIS 类对应的空间数据类型,这些类型的基础在“OpenGIS 几何模型”中被描述。
一些空间数据类型用于存储单一几何值:
GEOMETRYPOINTLINESTRINGPOLYGON
GEOMETRY 可以存储任何类型的几何值,而其他类型 (POINT, LINESTRING, POLYGON) 限制存储特定类型的几何值。
其他空间数据类型用于存储值集合:
MULTIPOINTMULTILINESTRINGMULTIPOLYGONGEOMETRYCOLLECTION
GEOMETRYCOLLECTION 可以存储任何类型的对象集合,而其他集合类型 (MULTIPOINT, MULTILINESTRING, MULTIPOLYGON) 限制成员为特定几何类型。
示例:要创建一个名为 geom 的表,其列 g 可以存储任何几何类型的值,使用如下语句:
CREATE TABLE geom (g GEOMETRY);
SRID属性
空间数据类型的列可以声明 SRID 属性(后面有介绍SRID 属性),以明确表示该列中存储值的空间参考系统 (SRS)。例如:
CREATE TABLE geom (
p POINT SRID 0,
g GEOMETRY NOT NULL SRID 4326
);
空间索引 (SPATIAL index) 可以建立在空间列上,该列为NOT NULL并具有特定 SRID。因此,如果计划在列上建立索引,应使用 NOT NULL 和 SRID 属性进行声明:
CREATE TABLE geom (g GEOMETRY NOT NULL SRID 4326);
InnoDB 表允许针对笛卡尔和地理 SRS 使用 SRID 值。而 MyISAM 表仅允许笛卡尔 SRS 使用 SRID 值。
SRID限制及优化器使用
具有 SRID 属性的空间列是 SRID 限制的,这意味着:
- 该列只能包含具有声明
SRID的值,尝试插入不同SRID的值将导致错误。 - 优化器可以使用该列上的空间索引。详见“空间索引优化”。
在没有 SRID 属性的空间列中,虽然可以接受任何 SRID 的值,但优化器不能使用空间索引,直到通过修改列定义添加 SRID 属性,这可能需要首先修改列内容,以确保所有值具有相同 SRID。
欲了解如何在 MySQL 中使用空间数据类型的其它示例,请参阅“创建空间列”。关于空间参考系统的信息,请参阅“空间参考系统支持”。
MySQL 中的空间索引
https://dev.mysql.com/doc/refman/8.0/en/create-index.html
MySQL 的存储引擎 MyISAM、InnoDB、NDB 和 ARCHIVE 支持空间列,如 POINT 和 GEOMETRY。空间数据类型的详细描述见“空间数据类型”章节。然而,各个存储引擎对空间列索引的支持程度不同。空间索引对空间列的适用规则如下。
空间索引特性
-
存储引擎支持:
空间索引仅适用于 InnoDB 和 MyISAM 表。在其它存储引擎中指定SPATIAL INDEX会导致错误。 -
MySQL 8.0.12 及之后版本:
在空间列上的索引必须是空间索引,因此在创建空间索引时SPATIAL关键字是可选的,但隐含存在。 -
单列限制:
空间索引仅适用于单个空间列,不能在多个空间列上创建。 -
非空限制:
被索引的列必须是NOT NULL。 -
列前缀限制:
不允许使用列前缀长度进行索引,索引覆盖每列的完整宽度。 -
主键和唯一索引限制:
空间索引不能用于主键或唯一索引。
结论
- 空间索引在 MySQL 中的使用受到诸多限制,需要注意存储引擎、列属性和索引类型的不同要求。
- 使用空间数据和索引时,确保对数据类型和索引规则的正确理解,以优化数据存储和查询性能。
空间函数参数处理(包含SRID的解释)
https://dev.mysql.com/doc/refman/8.0/en/spatial-function-argument-handling.html
概述
空间值或几何体具备几何类中描述的属性。这一节概括了空间函数参数处理的普遍特性。某些特定空间函数或函数组可能有不同的参数处理特性,这些在具体函数的描述中有说明。
参数处理细节
-
几何有效性:
空间函数只能针对有效的几何值进行操作,详见几何的形态良好性和有效性。 -
空间参考系统 (SRS):
每个几何值关联一个空间参考系统,这是地理位置的坐标基准系统。 -
空间参考标识符 (SRID):
每个几何体的 SRID 标识了几何体所定义的 SRS。在 MySQL 中,SRID 是与几何值关联的整数。最大可用的 SRID 值为 (2^{32}-1),如果提供更大的值,仅使用低 32 位。 -
SRID 0 的使用:
SRID 0 代表一个无限的平面直角坐标系,其轴上没有单位分配。为了确保 SRID 0 的行为,建议使用 SRID 0 来创建几何值。在没有指定 SRID 的情况下,新建几何值默认使用 SRID 0。 -
多几何值计算:
多个几何值必须在同一 SRS 中进行计算,否则会出现错误。空间函数在接收多个几何参数时,需要它们位于同一 SRS 中。若空间函数返回ER_GIS_DIFFERENT_SRIDS错误,则表示几何参数不在同一 SRS 内,必须进行修改以拥有相同的 SRS。 -
几何值继承:
由空间函数返回的几何体将继承几何参数的 SRS。 -
输入多边形要求:
根据开放地理空间联盟的指引,输入的多边形必须是封闭的。未封闭的多边形会被视为无效,而非自动封闭。 -
空几何集合处理:
空几何集合在 WKT 中表示为'GEOMETRYCOLLECTION()',这是任何生成空几何集合的空间操作的输出格式。 -
嵌套几何集合解析:
在解析嵌套几何集合时,集合被展平成基本组成部分以供 GIS 操作。这允许用户无需担心几何数据的唯一性,GIS 函数调用可生成嵌套几何集合,不必显式展平。
相关要点
- 使用空间函数时,确保几何体的有效性及一致的 SRID 设置对于准确的函数运作至关重要。
- 对于复杂地理数据操作,遵循开放地理空间联盟的标准,可确保输入数据的适用性。
- SRID 规范影响空间数据如何在数据库中被分析和使用,保持一致性以避免异常处理。
Q75
Examine these statements issued from Session 1 which execute successfully:
Session 1> SET transaction_isolation = 'SERIALIZABLE';
Session 1> START TRANSACTION;
Session 1> SELECT * FROM world.city WHERE name='Roma' AND CountryCode='ITA';
Now, examine this statement issued from Session 2:
Session 2> UPDATE world.city SET population=2660000 WHERE name='Roma' AND CountryCode='ITA';
What is the outcome of the UPDATE statement in Session 2?
A. The statement will wait for the transaction in Session 1 to finish.
B. The transaction in Session 1 will be rolled back automatically.
C. The row will be updated immediately.
D. A deadlock will occur.
答案:A
中文翻译题目和选项
请检查在会话1中成功执行的这些语句:
Session 1> SET transaction_isolation = 'SERIALIZABLE';
Session 1> START TRANSACTION;
Session 1> SELECT * FROM world.city WHERE name='Roma' AND CountryCode='ITA';
现在,检查从会话2发出的此语句:
Session 2> UPDATE world.city SET population=2660000 WHERE name='Roma' AND CountryCode='ITA';
Session 2中的UPDATE语句的结果是什么?
A. 该语句将等待会话1中的事务结束。
B. 会话1中的事务将自动回滚。
C. 该行将被立即更新。
D. 将发生死锁。
题干含义:
题目中描述了两个SQL会话,其中会话1设置了严格的隔离级别(SERIALIZABLE)并开启了事务,随后执行了一次SELECT查询。会话2中的UPDATE语句试图对相同的数据进行修改,要求解释会话2 UPDATE语句的执行结果。
选项分析
- A: 在事务隔离级别为SERIALIZABLE时,一个事务中的读取会锁定被读取的数据,直到事务结束,因此更新会等待事务结束。(正确答案)
- B: 会话1中的事务不会自动回滚,因为语句不会在不明确请求的情况下回滚。
- C: 数据不会被立即更新,因为会话1的事务已锁定数据。
- D: 死锁不会发生,因为只有一个会话试图获取锁,而另一个会话已经持有该锁。
相关知识点总结
- Transaction Isolation Levels: SERIALIZABLE 是SQL中最严格的隔离级别,在Serializable隔离级别下,所有事务按照次序依次执行,因此,脏读、不可重复读、幻读都不会出现
- Concurrency Control: 在高隔离级别下,特别是SERIALIZABLE,可能会影响系统的并发性。
- 对数据的修改在读取锁释放之前受限于事务管理。
Q76
Examine these statements executed successfully in one session:
session 1> START TRANSACTION;
session 1> UPDATE world.city SET Population=3643581 WHERE Name='Roma' AND CountryCode='ITA';
Now, examine this statement and output from a second session:
session 2> SELECT INDEX_NAME, LOCK_TYPE, LOCK_MODE, COUNT(*)
FROM performance_schema.data_locks
WHERE OBJECT_SCHEMA='world'
AND OBJECT_NAME='city'
GROUP BY INDEX_NAME, LOCK_TYPE, LOCK_MODE;
| INDEX_NAME | LOCK_TYPE | LOCK_MODE | COUNT(*) |
|---|---|---|---|
| NULL | TABLE | IX | 1 |
| CountryCode | RECORD | X_REC_NOT_GAP | 1 |
| PRIMARY | RECORD | X_REC_NOT_GAP | 1 |
There is no index on column Name but there is one on column CountryCode.
What are the possible values for transaction_isolation given the output in Session 1?
A. READ-COMMITTED or READ-UNCOMMITTED
B. READ-COMMITTED or SERIALIZABLE
C. REPEATABLE-READ or READ-UNCOMMITTED
D. REPEATABLE-READ or SERIALIZABLE
中文翻译题目和选项
请检查在一个会话中成功执行的这些语句:
session 1> START TRANSACTION;
session 1> UPDATE world.city SET Population=3643581 WHERE Name='Roma' AND CountryCode='ITA';
现在,检查来自第二个会话的此语句和输出:
session 2> SELECT INDEX_NAME, LOCK_TYPE, LOCK_MODE, COUNT(*)
FROM performance_schema.data_locks
WHERE OBJECT_SCHEMA='world'
AND OBJECT_NAME='city'
GROUP BY INDEX_NAME, LOCK_TYPE, LOCK_MODE;
| INDEX_NAME | LOCK_TYPE | LOCK_MODE | COUNT(*) |
|---|---|---|---|
| NULL | TABLE | IX | 1 |
| CountryCode | RECORD | X_REC_NOT_GAP | 1 |
| PRIMARY | RECORD | X_REC_NOT_GAP | 1 |
在 Name 列上没有索引,但在 CountryCode 列上有一个。
在会话1中给定输出的情况下,transaction_isolation 的可能值是什么?
A. READ-COMMITTED 或 READ-UNCOMMITTED
B. READ-COMMITTED 或 SERIALIZABLE
C. REPEATABLE-READ 或 READ-UNCOMMITTED
D. REPEATABLE-READ 或 SERIALIZABLE
题干含义:
题目中描述了两个SQL会话。其中会话1进行了一个更新操作,会话2执行了一次通过 performance_schema.data_locks 插入的查询以检查锁状态。题目要求根据查询结果判断 transaction_isolation 的可能值。
排除法:在Update下,表里的锁都是非gap锁,首先排除隔离程度最高的SERIALIZABLE(这个模式不可能不加gap锁),B、D排除;
再分析是否可能为 REPEATABLE-READ,REPEATABLE-READ 在 唯一索引 和 唯一扫描条件 下 才不会加gap锁,题目并不满足唯一索引 和 唯一扫描条件 的条件,即一定会加gap锁,排除 C,D;
A正确
选项分析
- A. READ-COMMITTED 或 READ-UNCOMMITTED
- 选项含义:事务隔离级别为“读已提交”或者“读未提交”。
- 解释:这两种隔离级别下,InnoDB 用定向的行锁(不会加NEXT-KEY/GAP锁),只加精确的行锁(如X_REC_NOT_GAP)。
- B. READ-COMMITTED 或 SERIALIZABLE
- 选项含义:事务隔离级别为“读已提交”或“可串行化”。
- 解释:Serializable级别一般会引入更严格的锁(可能存在间隙锁或更大粒度锁),并不是最符合当前输出的情况。
- C. REPEATABLE-READ 或 READ-UNCOMMITTED
- 选项含义:隔离级别为“可重复读”或“读未提交”。
- 解释:Repeatable-Read 通常会加 Next-Key Lock(即X_REC_NOT_GAP和Gap混合锁),并非全是X_REC_NOT_GAP。
- D. REPEATABLE-READ 或 SERIALIZABLE
- 选项含义:隔离级别为“可重复读”或“可串行化”。
- 解释:同上,Serializable通常锁粒度更细致,Repeatable-Read会加gap锁,不符合两种都是X_REC_NOT_GAP。
答案:A
InnoDB 各隔离级别下锁行为
https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html
一、锁类型简述
- Record Lock(记录锁)
只锁定已存在的指定索引条目。属于行级锁,不影响索引区间。 - Gap Lock(间隙锁)
锁定索引中的两个条目之间的空隙,阻止其它事务在间隙插入新行,但不影响已存在的记录。 - Next-Key Lock
组合锁:= 记录锁 + 前面的间隙锁。既锁定索引记录本身,也锁定该记录前的空隙。 - 意向锁
标记交易即将获得何种行级锁(辅助表锁实现,DDL用)。由 InnoDB 自动管理。 - 表锁
整表加锁。DML几乎不用,DDL场景常见。
二、MySQL InnoDB 各事务隔离级别的详细锁行为
1. READ UNCOMMITTED(读未提交)
- 普通 SELECT:非锁定读,有脏读风险,能读到其他事务尚未提交的数据。
- 加锁读(SELECT ... FOR UPDATE/SHARE)、UPDATE/DELETE:仅锁定被检索到的记录(记录锁)。
- 不加 gap lock,其他事务任何插入不会被阻塞。
- 应用很少,几乎不用。
2. READ COMMITTED(读已提交)
- 普通 SELECT:非锁定一致性读,每次 SELECT 各自获取最新已提交快照,存在不可重复读、幻读。
- 锁定读(SELECT ... FOR UPDATE / SELECT ... FOR SHARE / UPDATE / DELETE):
- InnoDB 只锁定被检索到的索引记录(记录锁),不加 gap lock,也不加 next-key lock。
- 行未命中 WHERE 条件时,锁马上释放,减少死锁概率。
- 外键/唯一索引检查时可能暂用 gap lock。
- 插入/删除/更新无插入拦截保护(间隙锁不用),因为有幻读风险。
- 优点:更高的并发性能。适合高并发的插入场景(比如自增主键),锁冲突少。
3. REPEATABLE READ(可重复读,MySQL 默认)
- 普通 SELECT:读取事务开始时的一致性快照(快照读),不加任何行或间隙锁。
- 锁定读与 DML(UPDATE/DELETE/SELECT ... FOR UPDATE/SHARE):
- 若通过唯一索引 和 唯一扫描条件(如 WHERE id=... 且 id唯一),只加记录锁,不加 gap lock。
- 其他情况(范围查询,多条匹配,非唯一索引),加 next-key lock(记录锁+gap lock),不仅锁定命中记录,也锁定命中记录间所有“间隙”,阻止其他事务在范围内插入,来防止幻读。
- INSERT 受 next-key/gap lock 影响,遇到间隙锁会阻塞。
- 即使未命中 WHERE 的记录,扫描覆盖到的索引区间也会被加锁。
- 防止幻读。推荐业务场景:大多数通用OLTP。
4. SERIALIZABLE(可串行化)
- 所有普通 SELECT 被自动升级为 “SELECT ... FOR SHARE”,无论是否指定 FOR SHARE,都加共享锁。
- 所有写操作(UPDATE/DELETE/INSERT)加 next-key lock,阻止一切并发写与插入,确保串行一致性,不会有幻读。
- 并发度最低、冲突等待大量增加,但强一致性下唯一选择。
三、"InnoDB 仅锁定索引记录" 解析
InnoDB 的一切锁(记录锁、gap lock、next-key lock)本质上都只加在索引(主键/普通索引)上,而不是物理行或全表。
- 有索引:加锁直接落在 B+Tree 索引对应的节点上。命中哪些、锁哪些。
- 无索引、全表扫描:主键聚簇索引上每条也作为索引条目加锁。
- 未建索引条件下,UPDATE/DELETE/锁定读的性能极低,因所有行都要扫描、加锁。
举例说明:
假设有表 t(id int primary key, name varchar(100)),含数据 id = [1, 3, 5]。
- 执行:
SELECT * FROM t WHERE id=3 FOR UPDATE;- id 有唯一索引,命中记录3,只加记录锁在 id=3 上。
- 执行:
SELECT * FROM t WHERE id>1 AND id<5 FOR UPDATE;- 范围查询,命中 id=3,同时加 next-key lock(锁住 (1,3)、3、(3,5)的间隙及记录),阻止其它事务在2、4时插入。
四、同一事务中锁释放时机
- 行锁/间隙锁/next-key lock:在事务 COMMIT 或 ROLLBACK 时一次性释放。
- READ COMMITTED 特殊处理:未命中的行,WHERE 检查失败后立刻释放对应锁。
- 在加锁过程中(如 UPDATE、DELETE…)若实际未更新(WHERE校验失败),锁也会及时释放。
五、锁冲突与死锁说明
- InnoDB 支持自动死锁检测,有死锁自动回滚某一事务。
- READ COMMITTED 可减少死锁概率,REPEATABLE READ 上容易因长事务与多条件死锁。
六、插入唯一性/外键检测时的特殊锁
- INSERT 检查唯一索引/外键时,临时对候选值相应间隙加 gap lock,防止并发导致脏写冲突。
- 特殊时刻 gap lock 并不仅随隔离级别变化而变化。
七、常见锁行为一览表
| 隔离级别 | 普通SELECT | SELECT ... FOR UPDATE | UPDATE / DELETE | 能否加间隙锁 | 是否防幻读 |
|---|---|---|---|---|---|
| READ UNCOMMITTED | 非锁定脏读 | 记录锁 | 记录锁 | 否 | 否 |
| READ COMMITTED | 非锁定已提交快照 | 记录锁 | (条件记录锁, release快) | 通常否,仅特殊检查 | 否 |
| REPEATABLE READ | 快照读 | 记录锁/next-key lock | next-key lock/记录锁 | 是 | 是 |
| SERIALIZABLE | 自动FOR SHARE锁定 | 共享/排他锁、next-key锁 | next-key锁/排他锁 | 是 | 是 |
八、总结建议
- 理解“锁始终落在索引条目上”,合理利用主键/二级索引,是改善锁冲突与性能的关键。
- 查询条件越精确、索引越合理,锁冲突越少、并发度越高。
- 避免长事务,业务层注意纯 SELECT 和锁操作分离;写业务建议默认采用 REPEATABLE READ。
- 需分析死锁时,使用
SHOW ENGINE INNODB STATUS\G工具获取最新死锁日志。
Q77
Examine these statements which execute successfully:
SET SQL_MODE = '';
SELECT 2 * -3 a, 2 * '-3' b, CAST(2 * -3 as UNSIGNED) c;
What is the result?
Options:
A. a: -6 | b: -6 | c: 18446744073709551610
B. a: -6 | b: 0 | c: 6
C. a: -6 | b: -6 | c: 6
D. a: -6 | b: NULL | c: 6
E. a: -6 | b: -6 | c: -6
中文翻译题目和选项
请检查这些执行成功的语句:
SET SQL_MODE = '';
SELECT 2 * -3 a, 2 * '-3' b, CAST(2 * -3 as UNSIGNED) c;
结果是什么?
选项:
A. a: -6 | b: -6 | c: 18446744073709551610
B. a: -6 | b: 0 | c: 6
C. a: -6 | b: -6 | c: 6
D. a: -6 | b: NULL | c: 6
E. a: -6 | b: -6 | c: -6
题干含义:
题目要求核查给定的 SQL 语句在 SQL_MODE 为默认值且成功执行时,运行的结果。
选项分析
-
A:
a计算正常,结果为 -6。b将字符串 '-3' 转为数字,计算结果为 -6。c计算为 -6 后转换为 UNSIGNED,转换为大整数。(正确答案)
-
B:
b的计算错误,若字符串转数字,则计算应为 -6,而非 0。
-
C:
c应为大整数,不可能为 6。
-
D:
b应计算得 -6,不应为 NULL。
-
E:
c通过 UNSIGNED 应产生大整数,不应为 -6。
答案: 选项 A
相关知识点总结
- SQL 中当数字字符串作为数字计算时,会隐式转换,如
2 * '-3'。 - MySQL 的
UNSIGNED类型表示无符号整数,负数转此类型时会变为大整数。 - 在未设定
SQL_MODE的情况下,字符串与数值可被直接用于数字运算。
Q78
Examine the structure of the city table:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| ID | int(11) | NO | PRI | NULL | auto_increment |
| Name | char(35) | NO | NULL | ||
| CountryCode | char(3) | NO | NULL | ||
| District | char(20) | NO | NULL | ||
| Population | int(11) | NO | MUL | 0 |
Now examine this statement and output with a placeholder <keylength>:
EXPLAIN SELECT Name, Population FROM City WHERE Population=100231\G
- id: 1
- select_type: SIMPLE
- table: city
- partitions: NULL
- type: ref
- possible_keys: pop_idx
- key: pop_idx
- key_len:
<keylength> - ref: const
- rows: 1
- filtered: 100
- Extra: NULL
What is the value of keylength?
Options:
A. 1
B. 6
C. 2
D. 100231
E. 4
F. 5
答案: 选项 E
中文翻译题目和选项
请检查 city 表的结构:
| 字段 | 类型 | 是否为空 | 键 | 默认值 | 额外信息 |
|---|---|---|---|---|---|
| ID | int(11) | NO | PRI | NULL | auto_increment |
| Name | char(35) | NO | NULL | ||
| CountryCode | char(3) | NO | NULL | ||
| District | char(20) | NO | NULL | ||
| Population | int(11) | NO | MUL | 0 |
现在检查以下带占位符 <keylength> 的语句和输出:
EXPLAIN SELECT Name, Population FROM City WHERE Population=100231\G
- id: 1
- select_type: SIMPLE
- table: city
- partitions: NULL
- type: ref
- possible_keys: pop_idx
- key: pop_idx
- key_len:
<keylength> - ref: const
- rows: 1
- filtered: 100
- Extra: NULL
keylength 的值是什么?
选项:
A. 1
B. 6
C. 2
D. 100231
E. 4
F. 5
题干含义:
题目要求根据 EXPLAIN 查询 city 表中 Population 字段与给定常量匹配时使用的索引键长度。
选项分析
- A: 值太小。
- B: 值太大。
- C: 值太小。
- D: 这是条件值,与键长度无关。
- E: INT 类型的键长度,通常占用 4 个字节。(正确答案)
- F: 值略大,超出 int 类型标准。
相关知识点总结
SQL EXPLAIN 输出列解释
在 SQL 中使用 EXPLAIN 语句能够帮助我们理解 MySQL 如何执行查询以及哪些索引被使用。以下是 EXPLAIN 输出中每一列的解释:
| 列名 | JSON 名称 | 含义 |
|---|---|---|
| id | select_id | SELECT 标识符,对于每个 SELECT 查询在语句中都是唯一的。 |
| select_type | 无 | SELECT 类型,指示查询是简单的、主查询、依赖查询或者子查询等。 |
| table | table_name | 输出行对应的表。 |
| partitions | partitions | 查询中匹配的分区(如果有分区机制)。 |
| type | access_type | MySQL 使用的连接类型或访问方式。类型范围从 "ALL"(全表扫描)到 "const"(单行)。 |
| possible_keys | possible_keys | MySQL 可以选择的可能索引集合,用于更高效地检索数据。 |
| key | key | 实际上被 SQL 优化器选择的索引。 |
| key_len | key_length | 选中索引的键长度(以字节为单位) |
| ref | ref | 与索引进行比较以过滤行的列或常量。 |
| rows | rows | MySQL 预计需要检索行的数量。 |
| filtered | filtered | 应用表条件后过滤掉的行的百分比。 |
| Extra | 无 | 关于 MySQL 使用的执行策略的额外信息。这可能包括是否使用临时表或是否需要文件排序。 |
这些元素帮助分析和优化 SQL 查询,通过展示查询是如何被执行的、使用了哪些索引,以及执行计划的效率如何。
Q79
You successfully executed a PDO-based query in a PHP application. You must add a condition to accurately identify only NULLs. Which two conditions will do this?
Options:
A. if ( is_null($row[$key]) )
B. if ( $row[$key] === NULL )
C. if ( $row[$key] === "" )
D. if ( $row[$key] == "" )
E. if ( empty( $row[$key] ) )
中文翻译题目和选项
您已在一个 PHP 应用中成功执行了基于 PDO 的查询。您必须添加一个条件以准确识别 NULL。哪两个条件可以做到这一点?
选项:
A. if ( is_null($row[$key]) )
B. if ( $row[$key] === NULL )
C. if ( $row[$key] === "" )
D. if ( $row[$key] == "" )
E. if ( empty( $row[$key] ) )
题干含义:
题目要求在 PHP 中编写条件以准确识别数据中的 NULL 值。
选项分析
- A:
is_null()函数用于判断变量是否为 NULL,可以准确识别 NULL 值。(正确答案) - B: 全等运算符
===检查类型和值两个方面,$row[$key] === NULL检查变量是否为 NULL 类型和 NULL 值。这是检测 NULL 的标准方法。(正确答案) - C: 全等符号
===检查是否相等且同类型,但此处用于空字符串"",不适用于检测 NULL。 - D: 简单等号
==检查值相等,但不会检查类型,不适用于检测 NULL,因为它会将 "" 和 0 也视为等于 NULL。 - E:
empty()检查值是否为 0、""、false、array() 或 NULL 等,对 NULL 的识别不够精确,因结果可能会混淆。
答案: A B
相关知识点总结
- 在 PHP 中,
is_null()可用来精确检查变量是否为 NULL。 - === 运算符也能实现同样效果,因为它不仅检查值还检查数据类型。
- 使用
empty()时须谨慎,因为它将 0、false、空字符串或未设置视为“空”。
Q80
A server hosts MySQL Server and Apache Webserver supporting a PHP/PDO based application. The application must be migrated from PHP to their Java application server on another host. The MySQL instance remains on the original host.
Examine the PDO connection string used in the existing application:
mysql:host=localhost;dbname=sales;unix_socket=/var/run/mysql.sock
Which two prevent Java from using the Unix socket?
Options:
A. The socket is not implemented in Connector/J driver.
B. Java treats the socket file as insecure.
C. The socket can only be accessed from the local host.
D. The X Dev API protocol must be enabled to use sockets in Connector/J driver.
E. socket is a reserved word in Java.
中文翻译题目和选项
一台服务器托管 MySQL Server 和支持基于 PHP/PDO 应用程序的 Apache Webserver。应用程序必须从 PHP 迁移到另一台主机上的 Java 应用服务器上。MySQL 实例仍保留在原始主机上。
检查现有应用程序中使用的 PDO 连接字符串:
mysql:host=localhost;dbname=sales;unix_socket=/var/run/mysql.sock
哪两件事阻止了 Java 使用 Unix 套接字?
选项:
A. "Connector/J 驱动未原生支持套接字。
B. Java 将套接字文件视为不安全。
C. 套接字只能从本地主机访问。
D. 必须启用 X Dev API 协议才能在 Connector/J 驱动中使用套接字。
E. socket 是 Java 中的保留字。
题干含义:
题目要求识别阻止 Java 应用使用 Unix 套接字与 MySQL 通信的两项障碍。
选项分析
- A: MySQL Connector/J 驱动不支持通过 Unix 套接字进行通信。(正确答案)
- B: Java把套接字文件视为不安全的,但这不是Java不能使用Unix套接字的原因。Java本身并没有这个限制,而是由于驱动程序层面不支持,错误。
- C: Unix套接字本质上是本地主机间的通信方法,无法从远程主机直接访问。因此,当应用程序和MySQL数据库服务器不在同一主机上时,Unix套接字不能用于连接。(正确答案)
- D: 启用 X Dev API 协议 或者 配置系统变量
--socket,且使用第三方库 才能使用套接字,错误。 - E:
socket并不是 Java 的保留字,不会影响,错误。
答案: 选项 A 和 C
相关知识点总结
MySQL Connector/J 和 Unix Domain Sockets
https://dev.mysql.com/doc/connector-j/en/connector-j-unix-socket.html
MySQL Connector/J 不直接支持与 MySQL 服务器通过 Unix 域套接字连接。然而,可以通过使用第三方库并通过可插入的套接字工厂实现这种连接。定制工厂应该实现 com.mysql.cj.protocol.SocketFactory 接口或 Connector/J 的旧版 com.mysql.jdbc.SocketFactory 接口。使用自定义的 Unix 套接字工厂时,请遵循以下要求:
- MySQL 服务器必须配置系统变量
--socket(用于使用 JDBC API 的原生协议连接)或--mysqlx-socket(用于使用 X DevAPI 的 X 协议连接),这两个变量必须包含 Unix 套接字文件的路径。 - 需要将自定义工厂的完全限定类名通过连接属性
socketFactory传递给 Connector/J。例如,使用 junixsocket 库时,设置如下:socketFactory=org.newsclub.net.mysql.AFUNIXDatabaseSocketFactory - 也许需要将其他参数作为连接属性传递给自定义工厂。例如,对于 junixsocket 库,需通过属性
junixsocket.file提供套接字文件的路径:junixsocket.file=path_to_socket_file
Q81
Examine these lines of Python code:
hire_start = datetime.date(1999, 1, 1)
hire_end = datetime.date(1999, 12, 31)
query = ("SELECT * FROM employees WHERE hired BETWEEN %s AND %s")
You must add a line of code to complete the code to return data to the variable d. Which line will do this?
Options:
A. d = cursor.execute(query, (hire_start, hire_end))
B. d = cursor.fetchall(query)
C. d = cursor.fetch(query % (hire_start, hire_end))
D. d = cursor.fetch(query, (hire_start, hire_end))
E. d = cursor.fetchall(query, (hire_start, hire_end))
F. d = cursor.execute(query)
中文翻译题目和选项
请检查以下 Python 代码行:
hire_start = datetime.date(1999, 1, 1)
hire_end = datetime.date(1999, 12, 31)
query = ("SELECT * FROM employees WHERE hired BETWEEN %s AND %s")
您必须添加一行代码以完成代码并将数据返回到变量 d 中。哪一行能做到这一点?
选项:
A. d = cursor.execute(query, (hire_start, hire_end))
B. d = cursor.fetchall(query)
C. d = cursor.fetch(query % (hire_start, hire_end))
D. d = cursor.fetch(query, (hire_start, hire_end))
E. d = cursor.fetchall(query, (hire_start, hire_end))
F. d = cursor.execute(query)
题干含义:
题目要求在 Python 代码中通过添加语句执行 SQL 查询,并将结果返回给变量 d。
选项分析
- A: 正确使用
execute()方法将参数代入 SQL 查询,返回结果集游标以便后续 fetch 数据。(正确答案) - B:
fetchall()方法适用于取得所有查询结果,而不是执行查询。 - C:
fetch()方法及行中直接使用%替换操作不符合实际情况;fetch()不存在。 - D:
fetch()不存在且其参数使用方式不正确。 - E:
fetchall()并不能传递查询参数。 - F: 区缺少参数代入,直接执行查询不带参数会导致 SQL 错误。
答案: 选项 A
相关知识点总结
- 使用
cursor.execute(query, params)来执行带参数的 SQL 查询。 execute()方法返回的是影响行数,实际数据需要用fetchone()或fetchall()提取。- 参数化查询可有效预防 SQL 注入攻击,通过占位符
%s代替参数插入位置。
Q82
Which two are true about MySQL Document Store?
Options:
A. It depends heavily on strictly typed data.
B. There is no access to relational tables.
C. It can store documents greater than 4 GB.
D. It helps to store data items in a schema-less key-value store.
E. It allows one to bypass the SQL layer of the server.
中文翻译题目和选项
关于 MySQL 文档存储,哪两项是正确的?
选项:
A. 它在很大程度上依赖于严格类型的数据。
B. 无法访问关系表。
C. 它可以存储大于 4 GB 的文档。
D. 它有助于在无模式的键值存储中存储数据项。
E. 它允许绕过服务器的 SQL 层。
题干含义:
题目要求识别 MySQL Document Store 的两项正确特性。
选项分析
- A: 不依赖严格类型数据,文档存储相对灵活。
- B: MySQL Document Store 仍可访问关系数据库的功能。
- C: 支持存储大于 4 GB 的文档,超越传统的 BLOB 限制。(正确答案)
- D: 提供无模式的键值存储方式,灵活性更高,是文档存储的关键特性。(正确答案)
- E: 不绕过 SQL 层,而是可选择使用 X DevAPI 来直接操作文档格式。
答案: 选项 C 和 D
相关知识点总结
- MySQL Document Store 是 MySQL 的文档数据库功能,支持存储 JSON 格式的文档数据。
- 允许大规模文档存储,且无需定义模式(schema-less)。
- 支持通过 X DevAPI 使用无模式的灵活文档存储,而无需传统表结构。
- 确保良好的性能表现以及灵活的查询机制,兼具关系型和非关系型数据库操作。
Q83
Examine these MySQL Shell statements:
mysql-js> nc=db.createCollection('person')
mysql-js> nc.add({name: "Kate", city: "Paris"})
mysql-js> nc.add({name: "Bill", city: "London"})
mysql-js> nc.add({name: "John", place: "New York"})
mysql-js> nc.add({name: "Mary", place: "Boston", country: "USA"})
What is true about the attempts to add documents to the collection?
Options:
A. First three documents are added, then different number of fields cause an error.
B. All documents are added and cause a warning.
C. All documents are added without any error or warning.
D. First two documents are added, then mismatched field names cause an error.
中文翻译题目和选项
请检查以下 MySQL Shell 语句:
mysql-js> nc=db.createCollection('person')
mysql-js> nc.add({name: "Kate", city: "Paris"})
mysql-js> nc.add({name: "Bill", city: "London"})
mysql-js> nc.add({name: "John", place: "New York"})
mysql-js> nc.add({name: "Mary", place: "Boston", country: "USA"})
关于尝试向集合中添加文档有什么正确描述?
选项:
A. 前三个文档已添加,然后字段数量不同造成错误。
B. 所有文档已添加并引发警告。
C. 所有文档已添加,无任何错误或警告。
D. 前两个文档已添加,然后字段名称不匹配导致错误。
题干含义:
题目要求分析使用 MySQL Shell 插入文档至集合时的结果情况。
选项分析
- A MySQL Document Store 允许无模式存储,不会因字段数量不同而出错。
- B: 无模式文档存储不因字段差异造成警告。
- C: 所有文档字段适用于无模式灵活、混合数据写入,无引发错误或警告。(正确答案)
- D: 字段不匹配不引发错误,MySQL Document Store 支持不同字段格式。
答案: C
相关知识点总结
- MySQL Document Store 允许以灵活格式存储文档并支持 JSON 数据结构。
- 文档存储是无模式的,因此不会因为字段不一致导致错误。
- 每个文档可以有不同的字段结构和类型,为数据存储提供了更大的灵活性。
Q84
Examine the appointments table definition which contains one million rows:
CREATE TABLE `appointments` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`attendant_id` int(11) NOT NULL,
`attendant_session_id` int(11) NOT NULL,
`start` datetime NOT NULL,
`end` datetime NOT NULL,
`date` date NOT NULL,
`created_by` varchar(20) NOT NULL,
`created_at` datetime DEFAULT CURRENT_TIMESTAMP,
`payment` int(11) NOT NULL DEFAULT '0',
`credit` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
Now, examine this statement which executes successfully:
SELECT attendant_id,
payment,
credit
FROM appointments
WHERE attendant_session_id = 510
AND created_by = 'jsmith'
Which statement will improve query performance?
A. ALTER TABLE appointments add index IX_1(credit, payment)
B. ALTER TABLE appointments add index IX_4(attendant_id, payment, credit)
C. ALTER TABLE appointments add index IX_3(attendant_id, created_by)
D. ALTER TABLE appointments add index IX_2(attendant_session_id, created_by)
中文翻译与解析
题干翻译:
考察 appointments 表定义(含百万行数据)。
CREATE TABLE `appointments` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`attendant_id` int(11) NOT NULL,
`attendant_session_id` int(11) NOT NULL,
`start` datetime NOT NULL,
`end` datetime NOT NULL,
`date` date NOT NULL,
`created_by` varchar(20) NOT NULL,
`created_at` datetime DEFAULT CURRENT_TIMESTAMP,
`payment` int(11) NOT NULL DEFAULT '0',
`credit` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
根据如下查询语句,哪个 ALTER 语句能提升性能?
SELECT attendant_id, payment, credit
FROM appointments
WHERE attendant_session_id = 510
AND created_by = 'jsmith'
选项及其含义:
A: 为 (credit, payment) 添加索引 —— 与 WHERE 条件无关。
B: 为 (attendant_id, payment, credit) 添加索引 —— 与 WHERE 条件关联性不强(WHERE 无 attendant_id)。
C: 为 (attendant_id, created_by) 添加索引 —— 只包含 created_by,缺少 WHERE 中的另一个关键字段。
D: 为 (attendant_session_id, created_by) 添加索引 —— 完全覆盖 WHERE 子句中的两个过滤字段。
正确答案:
D. ALTER TABLE appointments add index IX_2(attendant_session_id, created_by)
该复合索引完全覆盖了 WHERE 子句中的两个筛选字段,最能提升本次查询性能。
相关知识点总结
索引覆盖原理: 查询的 WHERE 子句字段如果能被单个复合索引覆盖,则能显著提升查找与过滤的效率。
复合索引顺序: 建议按实际筛选的字段顺序来建索引,尤其是高基数字段优先。
无关字段索引不会提升性能。
索引覆盖的字段越多,与 WHERE 关联性越强,对查询加速效果越好。
Q85
A suite of applications has been migrated to a MySQL 8 production instance. These applications must use the default authentication plugin.
A legacy application yet to be migrated, does not support the default authentication plugin.
Examine this statement which executed successfully:
CREATE USER `app`@localhost IDENTIFIED BY 'password';
Which would allow the legacy application to connect while enabling other applications to adhere to the requirements?
A. CREATE USER 'legacyapp'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
B. ALTER USER app@localhost IDENTIFIED WITH mysql_native_password BY 'password';
C. SET GLOBAL default_authentication_plugin=mysql_native_password;
D. SET PERSIST default_authentication_plugin=mysql_native_password;
E. CREATE USER 'legacyapp'@'localhost' IDENTIFIED WITH caching_sha2_password BY 'password';
中文翻译与解析
一组应用已迁移到 MySQL 8 实例,要求使用默认认证插件。一个尚未迁移的遗留应用不支持该默认插件。
已知如下能执行成功的语句:
CREATE USER app@localhost IDENTIFIED BY 'password';
哪项做法能让遗留应用能连接,并保证其他应用也能遵循默认认证要求?
A. CREATE USER 'legacyapp'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
B. ALTER USER app@localhost IDENTIFIED WITH mysql_native_password BY 'password';
C. SET GLOBAL default_authentication_plugin=mysql_native_password;
D. SET PERSIST default_authentication_plugin=mysql_native_password;
E. CREATE USER 'legacyapp'@'localhost' IDENTIFIED WITH caching_sha2_password BY 'password';
选项解析
A:
创建一个单独的用户 legacyapp,并为其指定 mysql_native_password 插件,适配老应用需要,不会影响其他用户。
B:
修改已存在用户 app 的认证方式,会影响当前已迁移和合规的应用(不符合要求)。
C:
全局修改默认认证插件,将影响所有新用户(破坏整体合规性)。
D:
永久性修改默认认证插件,也将影响整体合规。
E:
虽然指定了认证插件,但还是默认的 caching_sha2_password,无法兼容老应用。
正确答案:
A. CREATE USER 'legacyapp'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
相关知识点总结
MySQL 8 默认认证插件是 caching_sha2_password,部分遗留应用程序只支持老的 mysql_native_password。
指定认证插件方法:可在 CREATE USER 或 ALTER USER 时选定 IDENTIFIED WITH 子句,仅影响该用户,不影响全局。
从安全和合规角度,推荐为特殊兼容需求单独建用户和授权,避免影响其他已迁移应用的安全策略。
Q86
Examine this statement which executes successfully:
mysql> SET GLOBAL sql_mode = ANSI_QUOTES;
Which sessions utilize the ANSI_QUOTES SQL mode?
A. all existing sessions at the next transaction
B. all existing sessions
C. new sessions only
D. existing sessions that execute FLUSH TABLES
E. new sessions and the current session
中文翻译与解析
题干翻译:
执行如下 SQL 成功后:
SET GLOBAL sql_mode = ANSI_QUOTES;
哪些 session 会使用 ANSI_QUOTES SQL 模式?
选项解析
A: 所有已存在的 session 从下一个事务起用此模式 —— 错误,已存在 session 的 sql_mode 不会受此影响。
B: 所有已存在的 session —— 错误,只有新建 session 取全局变量,老 session 不会变。
C: 新 session 才使用新模式 —— 正确。全局变量变化后,只有新建 session 受影响。
D: 执行 FLUSH TABLES 的现有 session —— 误导项,FLUSH TABLES 不会刷新 session 的 sql_mode。
E: 新 session 和当前 session —— 错误,当前(自己)session 如果没手动 set,还是旧的 session 变量。
正确答案:
C. new sessions only(新 session 才用新 sql_mode)
关联知识点Q18
MySQL SQL Mode 动态修改
https://dev.mysql.com/doc/refman/8.0/en/sql-mode.html#sql-mode-setting
- 运行时修改 SQL Mode 方法
- 可以通过
SET GLOBAL sql_mode = 'modes'修改全局 SQL模式。 - 也可以用
SET SESSION sql_mode = 'modes'修改当前会话的 SQL 模式。
- 可以通过
- 权限要求
- 设置全局 sql_mode 需要 SYSTEM_VARIABLES_ADMIN(或已废弃的 SUPER)权限。
- 作用范围
SET GLOBAL只影响此命令之后新建连接的 sql_mode(新 session),已存在会话的 sql_mode 不变。SET SESSION只影响当前连接(自己的 session)。- 每个客户端可以随时修改自己 session 级别的 sql_mode。
- 查看当前设置
- 查询全局值:
SELECT @@GLOBAL.sql_mode; - 查询当前 session 值:
SELECT @@SESSION.sql_mode;
- 查询全局值:
- 注意分区表影响
- 如果数据表用到了自定义分区,强烈不建议在建表插入数据后再修改 sql_mode,否则可能造成行为变化或数据损坏。
- 主从复制的情况下,source 和 replica 的 sql_mode 不一致,也会造成问题,建议保持一致。
- 其他提示
- 数据库新连接会继承当前 global sql_mode 作为初值。
- 新旧 session 和 global 设置间的关系,是 MySQL DBA 面试常考内容。
Q87
Which statement is true?
A. SHOW COUNT() WARNINGS and SELECT @@warning_count display the same result.
B. SHOW WARNINGS displays the same result as an EXPLAIN command.
C. SHOW WARNINGS displays warnings from DDL statements only.
D. SHOW COUNT() WARNINGS displays the number of warnings only.
E. SHOW WARNINGS displays errors, warnings, and notes.
中文翻译与解析
题干翻译:
下面哪个说法是正确的?
选项解析
- A:
SHOW COUNT(*) WARNINGS和SELECT @@warning_count显示相同的结果。—— 错误。- 这两者都用于展示返回总的错误、警告和备注数量,但SELECT语句会清空消息列表,如果先执行select再执行show结果会不一样。
- B:
SHOW WARNINGS和EXPLAIN命令显示相同结果。—— 错误,二者功能不同。 - C:
SHOW WARNINGS只显示 DDL 语句产生的警告。—— 错误,也显示 DML 等其他语句的警告。 - D:
SHOW COUNT(*) WARNINGS只显示警告数量。—— 错,显示错误、警告和备注数量。 - E:
SHOW WARNINGS显示错误、警告和备注。—— 正确,SHOW WARNINGS 用于诊断和显示当前会话中最新一条(非诊断类)SQL操作(如INSERT, UPDATE, DDL等)产生的错误、警告和备注
正确答案: E
SHOW WARNINGS 语句
https://dev.mysql.com/doc/refman/8.0/en/show-warnings.html
1. SHOW WARNINGS语句用途
- SHOW WARNINGS 用于诊断和显示当前会话中最新一条(非诊断类)SQL操作(如INSERT, UPDATE, DDL等)产生的错误、警告和备注。
- 也可用于 EXPLAIN 扩展模式后的详细信息查看。
2. 基本用法与语法
SHOW WARNINGS [LIMIT [offset,] row_count]:显示前N条警告(支持LIMIT和offset定制数量)SHOW COUNT(*) WARNINGS:只返回总的错误、警告和备注数量。- 也可通过
SELECT @@warning_count;获取当前警告数(但SELECT语句会清空消息列表,而SHOW则不会)。
3. 输出示例结构
- 每条警告信息包括:
- Level: 等级 (Warning、Error、Note)
- Code: 数字编码
- Message: 文字说明
4. 控制输出条数的变量
max_error_count:服务器变量,影响 SHOW WARNINGS 能显示的最多条目数(缺省1024,可调整)。- 超过该数目,只记录前N条,但
@@warning_count始终记录真实条数。
5. 其他相关SQL
SHOW ERRORS:只看Error类型,不含Warning/NoteSHOW COUNT(*) ERRORS:只统计Error条数GET DIAGNOSTICS:细粒度获取具体condition的信息
6. 注意事项
- 通过
sql_notes控制Note类型是否计入警告和存储。 - 在客户端命令行mysql工具中,可用
\\W和\\w控制是否自动显示警告。
7. 示例
CREATE TABLE t1 (a TINYINT NOT NULL, b CHAR(4));
INSERT INTO t1 VALUES(10,'mysql'), (NULL,'test'), (300,'xyz');
SHOW WARNINGS;
-- 会显示因b列数据截断、a列禁止为NULL、a列超出范围等三条警告
Q88
Which two commands display information to troubleshoot a SQL statement that does not execute as expected?
A. SELECT * FROM INFORMATION_SCHEMA.EVENTS;
B. GET DIAGNOSTICS CONDITION 1 @p1 = RETURNED_SQLSTATE, @p2 = MESSAGE_TEXT;
C. SHOW WARNINGS;
D. SELECT * FROM sys.user_summary;
E. SHOW MASTER STATUS;
中文题目与选项
下列哪两个命令可用于显示信息,以排查一个未按预期执行的 SQL 语句?
A. SELECT * FROM INFORMATION_SCHEMA.EVENTS;
B. GET DIAGNOSTICS CONDITION 1 @p1 = RETURNED_SQLSTATE, @p2 = MESSAGE_TEXT;
C. SHOW WARNINGS;
D. SELECT * FROM sys.user_summary;
E. SHOW MASTER STATUS;
选项逐项详解
- A. SELECT * FROM INFORMATION_SCHEMA.EVENTS;
- 查询事件调度器相关信息,不针对SQL执行错误或警告。
- B. GET DIAGNOSTICS CONDITION 1 @p1 = RETURNED_SQLSTATE, @p2 = MESSAGE_TEXT;
- 获取最近一条SQL语句的SQLSTATE代码和消息文本,可直接捕获错误/警告信息,是标准化的诊断语句。(正确答案)
- C. SHOW WARNINGS;
- 显示上一条SQL语句产生的所有警告、错误和注释,是MySQL特有常用的排查手段。(正确答案)
- D. SELECT * FROM sys.user_summary;
- 用于查询用户汇总信息,与SQL执行失败无关,不提供错误/警告信息。
- E. SHOW MASTER STATUS;
- 查询主服务器的binlog坐标,和SQL执行告警/错误无关,属于复制相关信息。
正确答案
B. GET DIAGNOSTICS CONDITION 1 @p1 = RETURNED_SQLSTATE, @p2 = MESSAGE_TEXT;
C. SHOW WARNINGS;
相关知识点总结
- SHOW WARNINGS; 能直接查看MySQL产生的各类警告和错误,非常适用于排查SQL执行不符预期的场景。
- GET DIAGNOSTICS ... 是标准SQL诊断命令,可以结构化获取错误码、消息文本等,复杂脚本和存储过程中更加灵活。
- 其它选项如查询事件、用户汇总、主从状态,均不提供针对"本次SQL是否正确执行"的实时诊断信息。
- 日常SQL开发与运维,应熟练掌握以上两种排查手段。
Q89
Examine these statements which execute successfully:
CREATE TABLE table1 (var1 TINYINT, var2 INT);
SET sql_mode=STRICT_ALL_TABLES;
Now, examine this statement:
INSERT INTO table1 (var1) VALUES(1000);
Which is true about the execution of the INSERT statement?
A. It inserts the value 127.
B. It fails with an error.
C. It inserts the value 1000.
D. It inserts the row with a warning.
E. It inserts a valid value nearest to 1000.
中文题目与选项
已成功执行如下语句:
CREATE TABLE table1 (var1 TINYINT, var2 INT);
SET sql_mode=STRICT_ALL_TABLES;
请判断下面这条语句会发生什么:
INSERT INTO table1 (var1) VALUES(1000);
以下说法哪个是正确的?
A. 插入值127。
B. 由于错误而失败。
C. 插入值1000。
D. 插入该行并给出警告。
E. 插入最接近1000的有效值。
选项逐项解析
A. 插入值127。
在非严格模式下,大于 TINYINT 上限的值会截断为127,带警告。但本题已开启STRICT_ALL_TABLES。
B. 由于错误而失败。
开启 STRICT_ALL_TABLES,超范围直接错误终止,不插入,(正确答案)。
C. 插入值1000。
1000远超 TINYINT 可表示范围,不可能插入成功。
D. 插入该行并给出警告。
非严格模式下如此,严格模式下失败。
E. 插入最接近1000的有效值。
非严格模式时才自动调整为127,严格模式报错。
正确答案
B. It fails with an error.
(由于SQL模式为STRICT_ALL_TABLES,超类型范围数值不可自动截断,执行失败)
相关知识点总结
TINYINT 类型 范围为 -128~127(有符号),超出时若为默认模式,MySQL会截断为127并给出警告;若为严格模式(如STRICT_ALL_TABLES),则会直接报错,插入失败。
STRICT_ALL_TABLES:强制类型/长度/格式违规时直接错误,不作自动调整,保证数据精确性。
切换到严格模式(strict mode)是防止“默默数据损坏”的推荐做法。
Q90
Which two statements are true about aggregate functions?
A. COUNT(DISTINCT) returns a count of the number of rows with different values including NULL.
B. SUM() returns 0 if there are no rows to aggregate.
C. MAX() returns NULL if there are no rows to aggregate.
D. AVG() does not allow use of the DISTINCT option.
E. MIN() cannot use DISTINCT when it executes as a Windows function.
中文题目与选项
关于聚合函数,下面哪两项说法是正确的?
A. COUNT(DISTINCT) 返回具有不同值(包括NULL)的行数。
B. SUM() 如果没有行可聚合,则返回0。
C. MAX() 如果没有行可聚合,则返回NULL。
D. AVG() 不允许使用 DISTINCT 选项。
E. MIN() 当作为窗口函数执行时,不能使用 DISTINCT。
选项逐项解析
- A. COUNT(DISTINCT)
- COUNT(DISTINCT col) 会统计不同非NULL值的数量,不包含NULL。选项描述错误。
- B. SUM() returns 0 if there are no rows to aggregate.
- SUM 对零行聚合时返回0,没有数据(全过滤掉)结果为 NULL。错误
- C. MAX() returns NULL if there are no rows to aggregate.
- MAX 若无数据可聚合(无任何行),则返回NULL。(正确答案)
- D. AVG() does not allow use of the DISTINCT option.
- AVG(DISTINCT ...) 是合法用法,此选项错误。
- E. MIN() cannot use DISTINCT when it executes as a Windows function.
- MIN(DISTINCT) 存在,但是当它作为窗口函数时不可以使用distinct,正确。
正确答案 CE
相关官方文档
https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html
Q91
Which two are true about PREPARE statements?
A. They are accessible in other active sessions.
B. They retain their resources even if the connection to the database is lost.
C. They can be nested.
D. They can be created and executed within a stored routine.
E. They can be created with the same name as an existing prepared statement in the same session.
中文翻译题目和选项
关于 PREPARE 语句,以下哪两项是正确的?
A. 它们可以在其他活动会话中访问。
B. 即使与数据库的连接丢失,它们仍保留资源。
C. 它们可以嵌套。
D. 它们可以在存储例程中创建和执行。
E. 它们可以在同一会话中以与已有的预备语句相同的名称创建。
题干含义
了解 PREPARE 语句的相关特性,选择正确选项。
选项分析
- A. PREPARE 语句与会话绑定,只能在创建它们的会话中使用。
- B. 连接丢失会导致资源释放,PREPARE 不保留。
- C. 不可以嵌套使用。
- D. PREPARE 语句可以在存储过程或函数中使用。(正确答案)
- E. 同一会话同名语句不会产生冲突,新语句会覆盖旧语句(正确答案)。
答案:DE
PREPARE 语句
https://dev.mysql.com/doc/refman/8.0/en/sql-prepared-statements.html#prepared-statements-in-scripts
定义与执行:
PREPARE用于准备一个 SQL 语句并给它分配名字(stmt_name),稍后可通过该名字引用。- 使用
EXECUTE执行预备语句,使用DEALLOCATE PREPARE释放。
语法细节:
- 名称不区分大小写。
preparable_stmt可以是字符串字面量或含有SQL语句的用户变量。- 语句文本必须表示单一语句而非多个语句。
- 使用 ? 字符作为参数标记来绑定数据值。? 不能用于 SQL 关键字或标识符。
重用与错误处理:
- 若给定名称的预备语句已存在,则会被自动释放。
- 如果新的语句存在错误且无法预备,会返回错误且删除原有语句。
作用域及会话管理:
-
会话限制:
- 预备语句是会话特定的,只在创建的该会话内有效。
- 会话结束后预备语句不再存在。若自动重连启用,客户端不被通知连接丢失(建议禁用自动重连)。
- 自动释放: 当会话终止时,任何未释放的预留语句都会被服务器自动释放。
- 全球有效性: 在会话结束前有效,允许在存储例程结束后继续使用。
-
存储程序上下文:
- 存储程序内创建的预备语句在程序结束后继续存在。
- 存储程序上下文中创建的语句不能引用存储过程或函数参数及局部变量。
- 可以使用用户定义变量以替代,因为其具有会话作用域,适用于程序外调用。
-
资源设置与限制:
- 最大预留语句计数: 通过
max_prepared_stmt_count变量限制同时创建的预留语句数量。设置为 0 可以阻止预留语句的使用。 - 安全性考虑: 限制最大数量是为了防止资源被过度消耗从而影响服务。
- 最大预留语句计数: 通过
-
诊断语句限制:
- 不支持作为预留语句的诊断语句包括:
SHOW WARNINGS、SHOW COUNT(*) WARNINGS及SHOW ERRORS、SHOW COUNT(*) ERRORS。 - 所有包含
warning_count或error_count系统变量引用的语句皆不允许使用。 - SQL标准要求诊断语句不可预备,MySQL遵循此规范。
- 不支持作为预留语句的诊断语句包括:
-
自动预备与异常:
- 大多数不支持在SQL预留语句中使用的语句也不允许在存储程序中使用,除非特别标明于“存储程序限制”中。
- 当表或视图的元数据被其引用预留语句修改,MySQL会在下次执行时自动重新预备该语句。
-
参数占位符使用:
- 占位符可用于SQL语法中的
LIMIT子句内的参数。 - MySQL 8.0起支持在
CALL语句中使用OUT和INOUT参数的占位符。
- 占位符可用于SQL语法中的
-
嵌套与动态语法限制:
- 预留语句语法不能嵌套,即语句中不能包含
PREPARE、EXECUTE或DEALLOCATE PREPARE。 - 预留语句不能用于游标动态语法,因为游标语句在创建时进行类型检查。
- 预留语句语法不能嵌套,即语句中不能包含
-
多重语句限制:
- 预留语句不支持多重语句(多个语句以
;分隔)。
- 预留语句不支持多重语句(多个语句以
-
C API与预留语法区分:
- 使用
mysql_stmt_prepare()C API函数无法为PREPARE、EXECUTE或DEALLOCATE PREPARE进行预备,这两者在逻辑上是不同的。
- 使用
-
存储程序中的使用场景:
- 预留语句可用于存储过程但不适用于存储函数或触发器。
- 当使用
CALL语句执行存储过程包含预留语句时,必须启用CLIENT_MULTI_RESULTS标记,确保结果集处理正确性。 CLIENT_MULTI_RESULTS可通过mysql_real_connect()启用,直接或间接通过CLIENT_MULTI_STATEMENTS。
Q92
Which is a use characteristic of NoSQL JSON document store databases?
- A: ACID transactions
- B: ad-hoc data format
- C: complex queries with JOINS
- D: well defined schemas
中文翻译题目和选项
NoSQL JSON 文档存储数据库的一个使用特征是什么?
- A: ACID事务
- B: 临时数据格式
- C: 使用JOIN的复杂查询
- D: 定义良好的模式
题干含义:
选题要求找出一种NoSQL JSON文档数据库的使用特点。
选项分析
-
A: ACID Transactions:
- ACID特性(原子性、一致性、隔离性和持久性)在关系型数据库中较常见,而NoSQL数据库通常不完全支持这些特性。
-
B: Ad-hoc Data Format:
- 由于NoSQL JSON文档数据库的灵活性,它允许使用临时数据格式来处理不规则或不断变化的结构。(正确答案)
-
C: Complex Queries with JOINS:
- NoSQL数据库通常不支持关系数据库常用的JOIN操作,因数据通常以嵌套结构存储。
-
D: Well Defined Schemas:
- NoSQL通常采用灵活的模式(schema-less)设计,因此不依赖于严谨的模式定义。
相关知识点总结
- NoSQL JSON文档数据库强调灵活性和扩展性,适合处理非结构化或半结构化数据。
- 它们通常不具备完整的ACID事务支持,而是设计成灵活的模式,以支持快速变化的应用需求。
- 与传统关系型数据库相比,NoSQL在进行复杂查询时一般有不同的实现策略,通常不支持复杂的JOIN操作。
Q93
Examine these statements which execute successfully:
CREATE TABLE `inventory_items` (
`inventory_item_id` INT NOT NULL AUTO_INCREMENT,
`inventory_item_name` VARCHAR(50) NOT NULL,
`inventory_item_count` INT UNSIGNED DEFAULT NULL,
PRIMARY KEY (`inventory_item_id`)
) ENGINE=InnoDB;
SET sql_mode = '';
INSERT INTO inventory_items (inventory_item_name, inventory_item_count)
VALUES ('calculators', -1);
What is the result?
A. It inserts a row with a warning.
B. It inserts a row with no error or warning.
C. It inserts a row with an error.
D. It fails with an error.
E. It fails with a warning.
中文翻译题目和选项
请检查以下成功执行的语句:
CREATE TABLE `inventory_items` (
`inventory_item_id` INT NOT NULL AUTO_INCREMENT,
`inventory_item_name` VARCHAR(50) NOT NULL,
`inventory_item_count` INT UNSIGNED DEFAULT NULL,
PRIMARY KEY (`inventory_item_id`)
) ENGINE=InnoDB;
SET sql_mode = '';
INSERT INTO inventory_items (inventory_item_name, inventory_item_count)
VALUES ('calculators', -1);
结果是什么?
A. 插入一行并发出警告。
B. 插入一行没有错误或警告。
C. 插入一行但有错误。
D. 插入失败,有错误。
E. 插入失败,有警告。
题干含义:
题目要求分析SQL插入语句的结果,特别是当向inventory_item_count插入负数值时在没有特定sql_mode设置情况下的行为。
选项分析
-
A: 插入一行并发出警告。
- 当 UNSIGNED 列尝试插入负值时,在没有严格模式的情况下一般会进行无符号转换并发出警告。(正确答案)
-
B: 插入一行没有错误或警告。
- 即使插入成功,因值不符合 UNSIGNED 要求也会有警告。
-
C: 插入一行但有错误。
- 如果有严格模式或其他限制,可能会导致出错;当前无此模式。
-
D: 插入失败,有错误。
- 错误模式不适用。
-
E: 插入失败,有警告。
- 实际上仍会插入,且数据可能经过处理。
答案 A
相关知识点总结
- SQL模式(sql_mode): sql_mode为空,是最宽松的模式, 即使有错误既不会报错也不会有警告
- 数据类型约束: UNSIGNED 表示不允许负值,但行为取决于系统模式设置。
- 熟悉数据库约束及系统变量设置的影响是写入数据库时的重要注意点。
Q94
+-----+---------+
| sid | score |
+-----+---------+
| 1 | 75.235 |
| 2 | 75.234 |
| 3 | 75.2533 |
| 4 | 75.2573 |
+-----+---------+
Examine these desired output values:
+------+--------+
| sid | score |
+------+--------+
| 1 | 75.2 |
| 2 | 75.2 |
| 3 | 75.3 |
| 4 | 75.3 |
+------+--------+
Which statement updates the table data as required?
- A:
UPDATE exam_result SET score=TRUNCATE(CEIL(score),1); - B:
UPDATE exam_result SET score=ROUND(CEIL(score),1); - C:
UPDATE exam_result SET score=ROUND(score,1); - D:
UPDATE exam_result SET score=TRUNCATE(score,1); - E:
UPDATE exam_result SET score=CEIL(TRUNCATE(score,1)); - F:
UPDATE exam_result SET score=CEIL(ROUND(score,1));
中文翻译题目和选项
+-----+---------+
| sid | score |
+-----+---------+
| 1 | 75.235 |
| 2 | 75.234 |
| 3 | 75.2533 |
| 4 | 75.2573 |
+-----+---------+
请检查以下所需的输出值:
+------+--------+
| sid | score |
+------+--------+
| 1 | 75.2 |
| 2 | 75.2 |
| 3 | 75.3 |
| 4 | 75.3 |
+------+--------+
哪个语句会按要求更新表数据?
- A:
UPDATE exam_result SET score=TRUNCATE(CEIL(score),1); - B:
UPDATE exam_result SET score=ROUND(CEIL(score),1); - C:
UPDATE exam_result SET score=ROUND(score,1); - D:
UPDATE exam_result SET score=TRUNCATE(score,1); - E:
UPDATE exam_result SET score=CEIL(TRUNCATE(score,1)); - F:
UPDATE exam_result SET score=CEIL(ROUND(score,1));
题干含义:
题目要求找出能够将表中的分数四舍五入到最接近的小数点后一位的 SQL 更新语句。
选项分析
-
A: TRUNCATE(CEIL(score),1):
- CEIL 将值提升到下一个整数,TRUNCATE 将其削减到小数点后一位,不会产生所需效果。
-
B: ROUND(CEIL(score),1):
- CEIL 会提升值,从而失去原始小数;结合 ROUND 可能会不产生正确舍入。
-
C: ROUND(score,1):
- ROUND 函数直接对 score 进行舍入到小数点后一位,是实现目标的正确方式。(正确答案)
-
D: TRUNCATE(score,1):
- TRUNCATE 只是简单的切掉小数点后的多余位,不进行舍入。
-
E: CEIL(TRUNCATE(score,1)):
- TRUNCATE 会切除多余小数,CEIL 对结果进行上升处理,不符合目标。
-
F: CEIL(ROUND(score,1)):
- ROUND 后再进行 CEIL 会将结果提升,不适用于四舍五入至小数点后一位目的。
相关知识点总结
- ROUND函数是用于数值舍入操作的常用工具,可根据所需精度进行设置。
- TRUNCATE和CEIL既不支持标准的舍入需要串联处理,限制多。
- 精确的数值操作对于数据输出格式需求很重要,记住每个函数的行为以匹配需求。
Q95
Examine these commands and output:
mysql> DESC hr.emp;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(25) | YES | | NULL | |
| salary| int(11) | YES | | NULL | |
| email | varchar(25) | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+
4 rows in set (0.00 sec)
mysql> CREATE VIEW hr.emp_vu1
-> AS
-> SELECT name, salary
-> FROM hr.emp;
Query OK, 0 rows affected (0.02 sec)
mysql> DROP TABLE hr.emp;
Query OK, 0 rows affected (0.02 sec)
mysql> CREATE TABLE hr.emp ( id INT PRIMARY KEY, name VARCHAR(25), salary int, email VARCHAR(25) NOT NULL);
Query OK, 0 rows affected (0.04 sec)
Now, examine this command:
mysql> CREATE VIEW hr.emp_vu1
-> AS
-> SELECT name, salary
-> FROM hr.emp;
Which is true?
- Existing emp_vu1 is dropped and a new emp_vu1 is created with the new definition.
- It returns an error because the CREATE TABLE statement automatically recreated the view.
- It returns an error because the DROP TABLE statement did not drop the view.
- A new view is created because the previous was dropped on execution of the DROP TABLE statement.
中文翻译题目和选项
请检查这些命令和输出:
mysql> DESC hr.emp;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(25) | YES | | NULL | |
| salary| int(11) | YES | | NULL | |
| email | varchar(25) | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+
4 行数据集(0.00 sec)
mysql> CREATE VIEW hr.emp_vu1
-> AS
-> SELECT name, salary
-> FROM hr.emp;
查询成功,影响0行(0.02 sec)
mysql> DROP TABLE hr.emp;
查询成功,影响0行(0.02 sec)
mysql> CREATE TABLE hr.emp ( id INT PRIMARY KEY, name VARCHAR(25), salary int, email VARCHAR(25) NOT NULL);
查询成功,影响0行(0.04 sec)
现在,请检查此命令:
mysql> CREATE VIEW hr.emp_vu1
-> AS
-> SELECT name, salary
-> FROM hr.emp;
哪个是正确的?
- 现有的 emp_vu1 被删除,新的 emp_vu1 按新设置创建。
- 它返回错误,因为 CREATE TABLE 语句自动重新创建视图。
- 它返回错误,因为 DROP TABLE 语句没有删除视图。
- 新的视图已创建,因为执行 DROP TABLE 语句时删除了先前的。
题干含义:
问题要求分析视图和表操作之间的关系在 SQL 实现中的影响。
选项分析
-
Existing emp_vu1 is dropped and a new emp_vu1 is created with the new definition.
- 视图定义不会自动删除或替换,需手工复原或重建,选项在语义上不完全可靠。
-
它返回错误,因为 CREATE TABLE 语句自动重新创建视图。
- 表创建不会影响已存在的视图,视图创建独立。
-
它返回错误,因为 DROP TABLE 语句没有删除视图。
- SQL 直接删除表时,关联的视图需要手动处理,未自动移除,可能导致不一致或错误。(正确答案)
-
新的视图已创建,因为执行 DROP TABLE 语句时删除了先前的。
- 自动删除视图需要在不同模式下探讨,不是结果保证状态。
答案:C
CREATE VIEW语句
功能描述
CREATE VIEW用于创建新视图。- 当包含
OR REPLACE子句时,如视图已存在,则替换该视图。 - 如果视图不存在,
CREATE OR REPLACE VIEW行为相当于CREATE VIEW。
Restrictions on Views 视图限制
https://dev.mysql.com/doc/refman/8.0/en/view-restrictions.html
MySQL 对视图的使用和管理有一定限制和注意事项:
表限制
- 最大表数限制:视图定义中最多可引用61个表。
视图处理优化
- 索引限制:不能为视图创建索引。但合并算法处理的视图可以使用其底层表的索引。经由暂存表算法处理的视图不能利用底层表的索引,但在生成暂存表时可以使用。
表和子查询原则
- 表修改与选择原则:不能在子查询中同时对同一个表进行修改和选择。这一原则同样适用于从视图选择,它在子查询中选择表,并且视图用合并算法评估。
暂存表算法应用
- 使用暂存表的好处:视图存储在暂存表中时,可以在子查询中选择表并修改该表。在定义视图时通过指定
ALGORITHM = TEMPTABLE可以强制使用此算法。
视图定义和表操作
- DROP和ALTER操作影响:可以使用 DROP TABLE 或 ALTER TABLE 删除或更改使用视图定义的表,操作无警告,视图无效化错误在使用时发生。可用 CHECK TABLE 检查受影响视图。
视图可更新性
- 目标原则:理论上可更新的视图应在实践中可更新。视图可更新性依旧存在限制,详情参见“可更新和可插入视图”部分。
SHOW VIEW权限
- 权限限制:创建视图时授予 CREATE VIEW 和 SELECT 权限的用户不能使用 SHOW CREATE VIEW,除非也授予 SHOW VIEW。
工作作为解决方案
数据库备份可能因权限不足失败。解决办法是为获得 CREATE VIEW 权限的用户手动授予 SHOW VIEW 。
索引提示限制
- 索引提示不可用:视图没有索引,因此选择视图时不允许索引提示。
SHOW CREATE VIEW别名问题
- 别名长度问题:展示视图定义时为每个列使用 AS alias_name 子句。如果表达式生成列,默认别名为表达式文本,可能过长。别名最长仅64字符,超长导致视图创建失败。
解决方案
视图定义应短别名保证复制到新副本和备份不出错。失败时需修改视图定义以较短别名重新创建。为解决备份文件中失败的问题,编辑转储文件的 CREATE VIEW 语句。过长别名问题不解决会在后续备份操作中产生问题。
Q96
Examine these commands and output:
mysql> DESC employees;
+----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| id | int(11) | Yes | PRI | NULL | |
| lastname | varchar(255) | Yes | | NULL | |
| salary | int(11) | No | | NULL | |
| email | varchar(255) | Yes | | NULL | |
+----------+--------------+------+-----+---------+-------+
4 rows in set (0.00 sec)
mysql> CREATE VIEW emp_vu
-> AS
-> SELECT id, salary
-> FROM employees;
Query OK, 0 rows affected (0.00 sec)
Now, examine this statement:
```sql
mysql> INSERT INTO emp_vu
-> VALUES (104, 17000);
Which is true about the execution of the INSERT statement?
- A: It returns an error.
- B: It inserts a row in the view and base table.
- C: It inserts a new row in the base table only.
- D: It inserts a new row in the view only.
中文翻译题目和选项
请检查以下命令和输出:
mysql> DESC employees;
+----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| id | int(11) | Yes | PRI | NULL | |
| lastname | varchar(255) | Yes | | NULL | |
| salary | int(11) | No | | NULL | |
| email | varchar(255) | Yes | | NULL | |
+----------+--------------+------+-----+---------+-------+
4 行结果集(0.00 sec)
mysql> CREATE VIEW emp_vu
-> AS
-> SELECT id, salary
-> FROM employees;
查询成功,影响0行(0.00 sec)
现在,请检查此语句:
```sql
mysql> INSERT INTO emp_vu
-> VALUES (104, 17000);
这段INSERT语句在执行时的结果是什么?
- A: 它返回一个错误。
- B: 在视图和基础表中插入了一行。
- C: 仅在基础表中插入了一行新数据。
- D: 仅在视图中插入了一行新数据。
题干含义:
问题要求分析在视图emp_vu上执行INSERT语句将产生的效果。
选项分析
-
A: 它返回一个错误。
- 该视图可以进行insert,满足包含基础表所有列,除非列有默认值条件,错误
-
B: 在视图和基础表中插入了一行。
- 视图本质上不存储数据,无法直接插入数据。
-
C: 仅在基础表中插入了一行新数据。
- 插入操作直接应用到基础表中。
-
D: 仅在视图中插入了一行新数据。
- 视图不能储存独立数据。、
答案
C
相关知识点总结
Updatable and Insertable Views in MySQL
定义与规则
- 可更新视图:可以在UPDATE、DELETE或INSERT语句中引用视图以更新基础表的内容。
- 一对一关系:视图和基础表行间需存在一对一关系。
- 非可更新条件:包含聚合函数、DISTINCT、GROUP BY、HAVING等时视图不可更新。
非可更新视图构造
某些构造导致视图不可更新,例如:
- 聚合函数或窗口函数(SUM(), MIN(), MAX(), COUNT()等)
- DISTINCT,GROUP BY,HAVING
- UNION或UNION ALL
- SELECT列表中子查询
- 使用ALGORITHM = TEMPTABLE
多表视图可更新性
多表视图可更新性需满足:
- 需使用内连接(不允许外连接或UNION)。
- 视图定义中只可更新单个表。
插入特性
视图具有可插入性需满足更多条件:
- 无重复视图列名。
- 视图需包含基础表所有列,除非列有默认值。
- 视图列需为简单列引用,不能为表达式。
View Updatability Flag
- MySQL在CREATE VIEW时设立视图可更新标志。
- 信息表VIEWS的IS_UPDATABLE列显示此标志状态。
示例视图和操作
假设以下表和视图存在:
CREATE VIEW v_today (today) AS SELECT CURRENT_DATE;
CREATE VIEW v_merge (vc1, vc2) AS SELECT c1, c2 FROM t WHERE c3 > 100;
INSERT、UPDATE、DELETE的使用
- 可更新视图允许 INSERT、UPDATE、DELETE,视图必须合并处理,不能物化。
- INSERT语法对合并视图有效,但对物化视图无效。
INSERT、UPDATE和DELETE操作示例
- INSERT示例:有效的插入应避免非可更新组件。
- UPDATE示例:需确保待更新表参考为基础表或可更新视图。
- DELETE示例:删除操作需确保视图已合并且可更新。
处理视图变化
一旦视图不可更新,UPDATE、DELETE、INSERT操作均不合法。视图的可更新性可能受系统变量updatable_views_with_limit的影响。
处理视图中的表达式列
可更新视图允许更新非表达式列。例如:
CREATE VIEW v AS SELECT col1, 1 AS col2 FROM t;
可以更新col1,但不能更新col2。
参考的讨论
建立视图时需考虑列的简单性和视图的结构,以支持预期的数据库操作。本文提供如何构建和使用 MySQL 可更新视图的重要指导。
Q97
Examine this partial Python code which executes successfully:
conn = mysql.connector.conn(**conn_params)
cursor = conn.cursor(raw=True)
What is true about this code?
- A: The result is returned asynchronously.
- B: It converts MySQL DATETIME to Python datetime values.
- C: The result is returned as a raw BLOB.
- D: It skips conversions from SQL to native formatted data types.
- E: The result is returned in a simple tabular form.
中文翻译题目和选项
请检查这段成功执行的Python代码:
conn = mysql.connector.conn(**conn_params)
cursor = conn.cursor(raw=True)
关于这段代码什么是正确的?
- A: 结果异步返回。
- B: 它将MySQL DATETIME转换为Python datetime值。
- C: 结果作为原始BLOB返回。
- D: 它跳过从SQL到原生格式化数据类型的转换。
- E: 结果以简单表格式返回。
题干含义:
问题要求分析关于Python MySQL Connector中cursor(raw=True)模式的行为。
选项分析
-
A: 结果异步返回。
- Python MySQL Connector通常同步处理,不适用于此选项。
-
B: 它将MySQL DATETIME转换为Python datetime值。
- raw模式下,数据不转换为Python本地数据类型,包括日期时间。(此选项错误)
-
C: 结果作为原始BLOB返回。
- raw返回并不指向BLOB数据类型,数据未变动。
-
D: 它跳过从SQL到原生格式化数据类型的转换。
- raw=True使游标返回未经处理的原始数据,不进行数据类型转换。(正确答案)
-
E: 结果以简单表格式返回。
- 游标返回原始数据,表格式无直接影响。
相关知识点总结
- Cursor Raw Mode: 当设置
raw=True时,游标会返回SQL查询结果的原始数据,跳过任何数据类型转换。 - 数据处理: 适用于需要保留数据真实性,并在Python中进行自定义数据解析的场景。
Q98
Examine this statement which executes successfully:
SELECT CONCAT('Hello ', NULL, 'World!');
What is the output?
- A: HelloWorld!
- B: Hello NULLWorld!
- C: NULL
- D: Hello World!
中文翻译题目和选项
请检查这条成功执行的语句:
SELECT CONCAT('Hello ', NULL, 'World!');
输出是什么?
- A: HelloWorld!
- B: Hello NULLWorld!
- C: NULL
- D: Hello World!
题干含义:
问题要求分析SQL中CONCAT函数在处理NULL值时的输出结果。
选项分析
-
A: HelloWorld!
- 在SQL中,任何字符串与
NULL值进行CONCAT结果都为NULL,此选项错误。
- 在SQL中,任何字符串与
-
B: Hello NULLWorld!
CONCAT不会输出NULL文本。
-
C: NULL
CONCAT遇到NULL进行处理时,整个结果为NULL,符合此选项。(正确答案)
-
D: Hello World!
CONCAT使用NULL不会部分拼接,选择为错误。
答案:C
相关知识点总结
- CONCAT函数行为: SQL
CONCAT,一旦参数包含NULL,结果为NULL。 - NULL处理: 需注意使用
IFNULL或其他处理函数替代NULL以获得默认值合并效果。
Q99
You must schedule an event to execute a stored routine, which will run every day at 6 AM starting from June 30, 2020.
Which will do this?
A.
CREATE EVENT event_purge_logs
ON SCHEDULE
EVERY 1 DAY
STARTS '2020-06-30 06:00:00'
DO
CALL purge_logs();
B.
CREATE EVENT event_purge_logs
ON SCHEDULE
AT ('2020-06-30 06:00:00' + INTERVAL 1 DAY)
DO
CALL purge_logs();
C.
CREATE EVENT event_purge_logs
ON SCHEDULE
EVERY 1 DAY
STARTS '2020-06-30 06:00:00' ON COMPLETION PRESERVE ENABLE
DO
CALL purge_logs();
D.
CREATE EVENT event_purge_logs
ON SCHEDULE
AT ('2020-06-30 06:00:00' + INTERVAL 1 DAY) ON COMPLETION PRESERVE ENABLE
DO
CALL purge_logs();
答案:C
中文翻译题目和选项
你需要安排一个事件以执行存储过程,该事件将于每天的早上6点从2020年6月30日开始运行。
哪一个可以实现这个功能?
A.
CREATE EVENT event_purge_logs
ON SCHEDULE
EVERY 1 DAY
STARTS '2020-06-30 06:00:00'
DO
CALL purge_logs();
B.
CREATE EVENT event_purge_logs
ON SCHEDULE
AT ('2020-06-30 06:00:00' + INTERVAL 1 DAY)
DO
CALL purge_logs();
C.
CREATE EVENT event_purge_logs
ON SCHEDULE
EVERY 1 DAY
STARTS '2020-06-30 06:00:00' ON COMPLETION PRESERVE ENABLE
DO
CALL purge_logs();
D.
CREATE EVENT event_purge_logs
ON SCHEDULE
AT ('2020-06-30 06:00:00' + INTERVAL 1 DAY) ON COMPLETION PRESERVE ENABLE
DO
CALL purge_logs();
题干含义:
题目要求设置一个事件,以便在每天的6点执行存储过程,从指定日期开始。
选项分析
- A: 每天执行,但没有任何附加选项来保存完成后的状态。起始时间正确。
- B: 使用 AT 替代 EVERY 意味着仅执行一次,且仅在第一个选项后加一天,并不是每天。
- C: 每天执行,从指定日期开始,并确保事件完成之后不会被移除。(正确答案)
- D: 同时使用 AT 和 INTERVAL,意味着不是每天重复,一旦运行就完成。
相关知识点总结
- CREATE EVENT 用来创建事件,在特定时间触发。
- EVERY 用于指定事件频率。
- STARTS 定义事件开始时间。
- ON COMPLETION PRESERVE 确保事件完成后仍保持在数据库中,不被自动移除。
- AT 用于单次执行而不是周期性执行。
Q100
The variables c and d are declared as integer types.
Examine these initialization statements with placeholder value <p1>, which execute successfully:
Now, examine this loop which executes successfully:
REPEAT
SET d = d + 1;
SET c = c + 1;
UNTIL c > 3
END REPEAT;
Which loop results in the same value of d for all valid values of <p1>?
A)
b: LOOP
SET d = d + 1;
SET c = c + 1;
IF c > 3 THEN LEAVE b; END IF;
END LOOP b;
B)
WHILE c <= 3 DO
SET d = d + 1;
SET c = c + 1;
END WHILE;
C)
b: LOOP
IF c > 3 THEN LEAVE b; END IF;
SET d = d + 1;
SET c = c + 1;
END LOOP b;
D)
WHILE c < 3 DO
SET d = d + 1;
SET c = c + 1;
END WHILE;
答案:A
中文翻译题目和选项
变量 c 和 d 被声明为整数类型。
请检查以下使用占位符 <p1> 初始化的语句,这些语句执行成功:
现在请检查成功执行的循环:
REPEAT
SET d = d + 1;
SET c = c + 1;
UNTIL c > 3
END REPEAT;
哪个循环会对于所有有效的 <p1> 值导致 d 的值相同?
A)
b: LOOP
SET d = d + 1;
SET c = c + 1;
IF c > 3 THEN LEAVE b; END IF;
END LOOP b;
B)
WHILE c <= 3 DO
SET d = d + 1;
SET c = c + 1;
END WHILE;
C)
b: LOOP
IF c > 3 THEN LEAVE b; END IF;
SET d = d + 1;
SET c = c + 1;
END LOOP b;
D)
WHILE c < 3 DO
SET d = d + 1;
SET c = c + 1;
END WHILE;
题干含义:
题目要求找到在所有有效的 <p1> 值下,产生与 REPEAT 循环等效结果的循环。
选项分析
- A: 使用
LOOP循环,只要c不大于 3,就继续执行,两者逻辑对齐,结果相同。(正确答案) - B:
WHILE c <= 3直到c大于 3,将导致多执行一次,与REPEAT不同。 - C: 先进行条件判断,此时
c=4不会执行循环内容,导致d结果少一次增量。 - D:
WHILE c < 3将导致比REPEAT少执行一次,与条件不符。
正确答案:A
相关知识点总结
REPEAT...UNTIL循环在最后一步进行条件检查,与其比较时需注意首次无条件执行。WHILE循环在条件不满足时不执行任何内容,且每次先检查再执行。- 在循环结构中,确保逻辑流转与退出条件与期望结果保持一致至关重要。
LEAVE用于退出LOOP,而不是控制执行条件。
Q101
Given the attempt to execute the following command:
CREATE TABLE tab (i int NOT NULL) ENGINE=CSV;
An error is returned:
ERROR 1 (HY000): Can't create/write to file './dbo/tab_402.sdi' (OS errno 13 - Permission denied)
What causes the error?
A. The engine is disabled.
B. The set local_infile option has not been enabled.
C. The database user does not have sufficient privilege.
D. The database server process does not have sufficient privilege.
E. The database client process does not have sufficient privilege.
F. The database server is running in read-only mode.
中文翻译题目和选项
尝试执行以下命令时:
CREATE TABLE tab (i int NOT NULL) ENGINE=CSV;
出现错误:
ERROR 1 (HY000): Can't create/write to file './dbo/tab_402.sdi' (OS errno 13 - Permission denied)
是什么导致了这个错误?
A. 引擎被禁用。
B. set local_infile 选项尚未启用。
C. 数据库用户没有足够的权限。
D. 数据库服务器进程没有足够的权限。
E. 数据库客户端进程没有足够的权限。
F. 数据库服务器正在以只读模式运行。
题干含义:
题目要求找出导致文件创建/写入失败的原因。
选项分析
- A: 如果引擎被禁用,应返回引擎相关的错误,而非权限错误。
- B: local_infile 选项与写入权限无关,此错误与文件读写权限相关。
- C: 数据库用户权限不足会导致其他类型权限错误,非文件系统权限。
- D: 数据库服务器进程权限不足,导致无法在指定目录写入文件。(正确答案)
- E: 客户端进程权限不会影响服务器端写入文件权限。
- F: 只读模式无法创建表,但与操作系统权限无关。
相关知识点总结
- OS errno 13 表示操作系统层面权限不足。
- 授予数据库服务器进程适当的文件系统权限是解决写入问题的一般方法。
- ENGINE=CSV 表示以 CSV 格式处理表存储,需相应的文件操作权限。
- 数据库目录或路径规范需确保有正确的权限设置,以防止权限错误。
Q102
Which statement is true about the SHOW ERRORS command?
A. It displays the total number of errors, warnings, and notes since the beginning of the current session.
B. It displays the total number of errors, warnings, and notes since the server last restarted.
C. It cannot display information for more than max_error_count server system variable setting.
D. It displays errors messages only, since the start time of the current session.
E. It displays errors messages only, since the server last restarted.
F. It displays similar diagnostics results as get diagnostics.
中文翻译题目和选项
关于 SHOW ERRORS 命令,下列哪个描述是正确的?
A. 它显示自当前会话开始以来的错误、警告和注意总数。
B. 它显示自服务器上次重启以来的错误、警告和注意总数。
C. 它不能显示超过 max_error_count 服务器系统变量设置的信息。
D. 它仅显示自当前会话开始以来的错误信息。
E. 它仅显示自服务器上次重启以来的错误信息。
F. 它显示与 get diagnostics 类似的诊断结果。
题干含义:
题目要求找出 SHOW ERRORS 命令特征的正确描述。
选项分析
- A:
SHOW ERRORS命令不显示警告和注意事项,仅显示错误。 - B: 错误信息是基于当前会话的,而不是自服务器重启后的累计。
- C: 由于受限于
max_error_count服务器系统变量,SHOW ERRORS命令最多显示该变量设置数量的信息。(正确答案) - D: 显示错误信息是正确的,但受限于系统变量设置。
- E: 同时受会话和系统变量限制,错误信息不是自重启后累计。
- F:
SHOW ERRORS与get diagnostics作用不同,不提供类似结果。
正确答案:C
关联知识点:Q87
SHOW ERRORS Statement
https://dev.mysql.com/doc/refman/8.0/en/show-errors.html
SHOW ERRORS 是一个诊断语句,类似于 SHOW WARNINGS,但它仅显示错误信息,而非错误、警告和注释。
语法
-
SHOW ERRORS [LIMIT [offset,] row_count] -
SHOW COUNT(*) ERRORS -
LIMIT 子句 与
SELECT语句的语法相同。
功能和特性
SHOW ERRORS仅应用于错误,非警告或注释。SHOW COUNT(*) ERRORS命令展示错误数量,你也可以通过error_count变量检索这个数字:SHOW COUNT(*) ERRORS; SELECT @@error_count;SHOW ERRORS和error_count仅涉及错误,与SHOW WARNINGS和warning_count在其他方面相似。- 特别是,
SHOW ERRORS不能显示超过max_error_count消息的信息,而error_count可以超过max_error_count的值,如果错误数量超过max_error_count。
Q103
Your session has sql_mode set to default. Examine this statement which executes successfully:
CREATE TABLE students (
std_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
firstname VARCHAR(255) NOT NULL,
lastname VARCHAR(255) NOT NULL,
birthdate DATE NOT NULL,
reg_date DATETIME NOT NULL
) ENGINE=InnoDB AUTO_INCREMENT=10300;
Now examine this statement:
INSERT INTO students (std_id, firstname, lastname, birthdate, reg_date)
VALUES ("NULL", "Mary", "O'Hagen", '1997-11-26', DATE());
requirement:
std_id = 10301
firstname = Mary
lastname = O'Hagen
birthdate = November 26, 1997
reg_date = the current date
Which three changes are required to the insert statement so that it inserts the correct data?
A. Change DATE() to DAY()
B. Change "O'Hagen" to o\'Hagen
C. Change date() to CURRENT_TIMESTAMP()
D. Change "NULL" to NULL
E. Change "NULL" to 'NULL'
F. Change "O'Hagen" to "O\Hagen"
中文翻译题目和选项
您的会话将 sql_mode 设置为默认值。请检查以下成功执行的语句:
CREATE TABLE students (
std_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
firstname VARCHAR(255) NOT NULL,
lastname VARCHAR(255) NOT NULL,
birthdate DATE NOT NULL,
reg_date DATETIME NOT NULL
) ENGINE=InnoDB AUTO_INCREMENT=10300;
现在检验以下语句:
INSERT INTO students (std_id, firstname, lastname, birthdate, reg_date)
VALUES ("NULL", "Mary", "O'Hagen", '1997-11-26', DATE());
要求数据:
std_id = 10301
firstname = Mary
lastname = O'Hagen
birthdate = November 26, 1997
reg_date = the current date
插入语句需要哪三个修改以插入正确的数据?
A. Change DATE() to DAY()
B. Change "O'Hagen" to o\'Hagen
C. Change date() to CURRENT_TIMESTAMP()
D. Change "NULL" to NULL
E. Change "NULL" to 'NULL'
F. Change "O'Hagen" to "O\Hagen"
题干含义:
题目要求识别出对插入语句的正确修改以确保表记录与数据库结构定义匹配。
insert语句错误点分析:
- "NULL" 被误用为字符串而非真正的 NULL 值:
1366 - Incorrect integer value: 'NULL' for column 'std_id' at row 1 - 单引号未转义导致语法错误:
1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'Hagen', '1997-11-26', CURDATE())' at line 2 - DATE() 函数需接收一个日期/时间表达式(如 DATE(NOW())),用于提取日期部分(返回 YYYY-MM-DD)。无参数调用是无效语法:
1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '))' at line 2
选项分析
- A: 将
DATE()改为DAY()并不合适,因为DATE()和DAY()都需要传入一个参数。 - B: 需要对撇号进行转义,使用
o\'Hagen,但是o是小写,不符合数据要求。 - C:
CURRENT_TIMESTAMP()能获取当前时间,正确。 - D: 将
"NULL"改为NULL可行,插入NULL会自动生成一个自增数值,正确。 - E:
'NULL'将作为字符串插入,与NULL作为空值用法不符。 - F: 需要对撇号进行转义,使用
O\'Hagen,正确。
正确答案:DCF
相关知识点总结
- AUTO_INCREMENT 列如果尝试插入 "NULL",应使用 DEFAULT 或无需显式设置以自动增值。
- 字段声明为 NOT NULL 需确保插入值格式正确,类型匹配。
- 使用
DATE()或NOW()需要传入参数。
Q104
What is an advantage of using mysqli in PHP programs rather than using PHP Data Objects (PDO)?
A. mysqli supports object oriented programming.
B. mysqli can access databases from other vendors.
C. mysqli supports non blocking, asynchronous queries.
D. mysqli includes X DevAPI functions.
中文翻译题目和选项
在 PHP 程序中使用 mysqli 而不是 PHP 数据对象 (PDO) 的优势是什么?
A. mysqli 支持面向对象编程。
B. mysqli 可以访问其他厂商的数据库。
C. mysqli 支持非阻塞异步查询。
D. mysqli 包含 X DevAPI 函数。
题干含义:
题目要求辨别在 PHP 中使用 mysqli 的一个优势,相较于 PDO,这涉及具体技术特性和支持。
选项分析
- A: mysqli 和 PDO 都支持面向对象编程。并不是 mysqli 特有的优势。
- B: 访问其他厂商数据库的能力通常由 PDO 提供。mysqli 主要针对 MySQL。
- C: mysqli 提供了异步查询功能,可以有效执行非阻塞操作。(正确答案)
- D: X DevAPI 与 mysqli 无关,通常属于 MySQL的另一模块。
答案:C
相关知识点总结
- mysqli 是专为 MySQL 数据库设计的 PHP 扩展。
- PDO 提供了一种通用的数据库访问接口,支持多种数据库类型。
- mysqli 的异步特性允许在查询时不阻塞程序继续执行。
- 理解各数据库接口的特性和适配性有助于更高效地选用解决方案。
Q105
Which two statements are true about AUTO_INCREMENT?
A. AUTO_INCREMENT values allocated to a transaction that is rolled back are not reused.
B. A table can have multiple AUTO_INCREMENT columns.
C. A server restart always resets the AUTO_INCREMENT value to largest value in the AUTO_INCREMENT column plus 1.
D. The decimal data type supports AUTO_INCREMENT.
E. An AUTO_INCREMENT column must be indexed.
中文翻译题目和选项
关于 AUTO_INCREMENT,下列哪两项陈述是正确的?
A. 分配给回滚事务的 AUTO_INCREMENT 值不会重新使用。
B. 一个表可以有多个 AUTO_INCREMENT 列。
C. 服务器重启后总是将 AUTO_INCREMENT 值重置为 AUTO_INCREMENT 列中的最大值加上1。
D. decimal 数据类型支持 AUTO_INCREMENT。
E. AUTO_INCREMENT 列必须被索引。
题干含义:
题目要求辨识关于 AUTO_INCREMENT 的两项正确陈述,这涉及数据分配和索引要求。
选项分析
- A: 当事务包含插入 AUTO_INCREMENT 值并被回滚后,这些值不再被分配。(正确答案)
- B: 一个表中不能含有多个 AUTO_INCREMENT 列。
- C: 服务器重启不会主动重置 AUTO_INCREMENT,除非表被校验或修复。
- D: AUTO_INCREMENT 主要用于整数数据,由 decimal 支持是不合理的。
- E: AUTO_INCREMENT 列必须是索引,通常设为主键以便快速访问。(正确答案)
答案:AE
相关知识点总结
- AUTO_INCREMENT 用于自动分配唯一标识符,通常为整数类型。
- AUTO_INCREMENT 列必须是索引,可以加速数据查找和管理。
- 正确理解事务管理与 AUTO_INCREMENT 行为有助于防止数据重复和索引过大。
- 通常,一个表有且只能有一个 AUTO_INCREMENT 列。
Q106
You must enforce data integrity for data Inserted in a JSON column.
Which statement successfully creates a constraint in a JSON column?
Options:
A. CREATE TABLE fshop (product JSON CHECK (JSON_VALID(product) ) );
B. CREATE TABLE fshop ( product JSON, f INT GENERATED ALWAYS AS (product->"$ - id") );
C. CREATE TABLE fshop (id INT NOT NULL AUTO_INCREMENT, product JSON, PRIMARY KEY (id)) ENGINE=InnoDB;
D. CREATE TABLE fshop (id INT NOT NULL AUTO_INCREMENT, product JSON, CHECK (id>0) ) ENGINE=InnoDB;
中文题目翻译与解析
你需要为插入到 JSON 列中的数据强制执行数据完整性。下列哪条语句能在 JSON 列上成功创建约束?
A.
CREATE TABLE fshop (product JSON CHECK (JSON_VALID(product) ) );
B.
CREATE TABLE fshop ( product JSON, f INT GENERATED ALWAYS AS (product->"$ - id") );
C.
CREATE TABLE fshop (id INT NOT NULL AUTO_INCREMENT, product JSON, PRIMARY KEY (id)) ENGINE=InnoDB;
D.
CREATE TABLE fshop (id INT NOT NULL AUTO_INCREMENT, product JSON, CHECK (id>0) ) ENGINE=InnoDB;
选项分析
-
A 选项解析
product JSON CHECK (JSON_VALID(product))- 该语句在创建表时对
product列施加约束,确保所有插入的值都是合法的 JSON 格式。CHECK (JSON_VALID(product))是标准且直接针对 JSON 列设置约束,可以强制数据完整性。 - 正确答案
-
B 选项解析
f INT GENERATED ALWAYS AS (product->"$ - id")- 这里定义了一个由 JSON 列生成的虚拟列,但没有约束约束 JSON 格式本身是否有效,对数据完整性无直接保证。
- 错误
-
C 选项解析
- 创建了主键和 JSON 列,但没有对 JSON 列的数据完整性(有效性)施加任何约束。
- 错误
-
D 选项解析
CHECK (id>0)约束的是 id 字段的值大于 0,对 JSON 列本身没有任何限制。- 错误
正确答案
A. CREATE TABLE fshop (product JSON CHECK (JSON_VALID(product) ) );
相关知识点总结
- JSON 列完整性约束:MySQL 等数据库允许在表定义时对 JSON 列加 CHECK 约束,例如
CHECK (JSON_VALID(json_col)),保证插入的数据是合法的 JSON 文本。 - CHECK 约束:可以对任意列设置检查条件,插入/更新数据时只有满足该条件才能通过,示例:
[CONSTRAINT [symbol]] CHECK (expr) [[NOT] ENFORCED]。 - JSON_VALID() 函数:数据库函数,判断输入数据是否是合法 JSON,返回1或0。
- 对于 JSON 类型字段,单纯声明数据类型为 JSON 并不能完全防止非合法 JSON 数据入库,必须配合 CHECK 约束提升数据完整性保障。
Q107
You are using buffered queries with PHP mysqli in a browser-based web application. Which three are true?
A. Additional queries on the same session are blocked until the result set is released.
B. Results are sent from the server to the browser for buffering.
C. Buffered queries are enabled by default.
D. Buffered queries should be used on large tables when the result size is unknown.
E. Results are sent to the calling PHP process for buffering.
F. Buffered queries must be explicitly enabled using mysqliuseresult.
G. Large results can have a negative impact on performance.
中文题意及解析
你在一个基于浏览器的 Web 应用中,使用 PHP 的 mysqli 执行缓冲查询(buffered queries)。下列哪三项说法是正确的?
A. 在释放结果集之前,同一个会话上的其他查询会被阻塞。
B. 查询结果由服务器发送到浏览器进行缓冲。
C. 默认启用缓冲查询。
D. 当结果大小未知时,应该在大表上使用缓冲查询。
E. 查询结果被发送到调用的 PHP 进程进行缓冲。
F. 必须通过 mysqliuseresult 显式启用缓冲查询。
G. 结果集很大时可能会对性能产生负面影响。
正确答案
- C.
- E.
- G.
选项解释
-
A. 在释放结果集之前,同一个会话上的其他查询会被阻塞。
- 错误。使用缓冲查询时,可以在同一连接上并行执行额外的查询。
-
B. 查询结果由服务器发送到浏览器进行缓冲。
- 错误。查询结果缓冲在 PHP 服务器端,而不是浏览器。
-
C. 默认启用缓冲查询。
- 正确。mysqli 默认使用缓冲查询(如
mysqli_query()默认缓冲,除非用MYSQLI_USE_RESULT)。
- 正确。mysqli 默认使用缓冲查询(如
-
D. 当结果大小未知时,应该在大表上使用缓冲查询。
- 错误。对于大表和未知结果集建议使用非缓冲查询,因缓冲查询会消耗大量内存。
-
E. 查询结果被发送到调用的 PHP 进程进行缓冲。
- 正确。结果集是从 MySQL 服务器拉到 PHP 进程中缓冲的。
-
F. 必须通过 mysqliuseresult 显式启用缓冲查询。
- 错误。缓冲查询是默认行为,不需调用
mysqli_use_result去启用。相反调用mysqli_use_result是用来关闭缓冲。
- 错误。缓冲查询是默认行为,不需调用
-
G. 结果集很大时可能会对性能产生负面影响。
- 正确。若缓冲大量结果集会占用 PHP 很多内存,影响性能。
Buffered and Unbuffered queries
https://www.php.net/manual/zh/mysqlinfo.concepts.buffering.php
1. 缓冲查询(Buffered Queries)
- 默认行为:MySQLi 查询默认是缓冲模式。
- 工作机制:查询结果会立即从 MySQL 服务器传输到 PHP,并缓存在 PHP 进程的内存中("store result")。
- 优点:
- 可以直接获取总行数、支持指针跳转(seek)。
- 可以在同一连接上并行执行额外的查询(即使还在处理结果集)。
- 缺点:
- 对于大结果集,内存消耗很大。
- 直到所有对结果集的引用被释放、或显式释放结果集,内存才会被回收(最晚为请求结束时)。
- 补充说明:
- 如果使用
libmysqlclient,PHP 的内存限制不包括结果集的内存,除非数据被 fetch 到 PHP 变量中。 - 如果使用
mysqlnd,则结果集所占的所有内存都会被计入 PHP 的内存限制。
- 如果使用
2. 非缓冲查询(Unbuffered Queries)
- 机制:查询后,数据只在需要时一行一行从 MySQL 服务器拉取,而不是一次性全部存入内存("use result")。
- 优点:
- PHP 端内存占用较小,适合处理大结果集。
- 缺点:
- 整个结果集未取完前,不能在同一连接上执行其他查询。
- 只有等所有行都取出后,结果集才释放,且不能重复遍历。
- 查询的总行数未知,直到所有行都被取出。
- 适用场景:仅在需要顺序处理大量数据时适合用非缓冲查询。
- 风险:操作更复杂、易出错,慎用。
3. 实际建议
- 缓冲查询更方便和灵活,是多数场景下的推荐做法(如随机访问数据、需要获取总行数)。
- 非缓冲查询适合数据量极大且仅需顺序处理的场合。
4. 相关术语
- Buffered(缓冲查询):“store result”
- Unbuffered(非缓冲查询):“use result”
Q108
Examine the Test.php script which is numbered for clarity, and its output:
$link = mysqli_connect("localhost", "username", "password", "schema");
$sql = "SELECT actor_id, first_name, last_name FROM actor";
$result = $link->query($sql);
echo $result->num_rows;
PHP Fatal error: Uncaught Error: call to undefined function mysqli_connect() in Test.php:2 Which action will fix this error?
A. Enable the mysqli extension in the php.ini file.
B. Replace line 2 with $link = mysql_connect("localhost: 3306", "username", "password", "schema");
C. Replace line 2 with: $link = mysql_xdevapi getSession("mysqlx://username:password@localhost:3306","schema");
D. Install the PHP executable in the path used by the MySQL installation.
答案:A
中文翻译题目和选项
请检查 Test.php 脚本及其输出如下:
$link = mysqli_connect("localhost", "username", "password", "schema");
$sql = "SELECT actor_id, first_name, last_name FROM actor";
$result = $link->query($sql);
echo $result->num_rows;
PHP Fatal error: 在 Test.php:2 行未捕获错误:调用未定义函数 mysqli_connect()。哪个操作可以解决此错误?
A. 在 php.ini 文件中启用 mysqli 扩展。
B. 将第 2 行替换为 $link = mysql_connect("localhost:3306", "username", "password", "schema");
C. 将第 2 行替换为:$link = mysql_xdevapi getSession("mysqlx://username:password@localhost:3306","schema");
D. 将 PHP 可执行文件安装到 MySQL 安装使用的路径中。
题干含义:
题目描述了一个 PHP 脚本的错误,为了解决未定义函数 mysqli_connect(),需要找出正确的操作。
选项分析
- A: 在 php.ini 文件中启用 mysqli 扩展。这是正确解决方法,因为错误表明
mysqli函数未定义,可能因为未启用相应的扩展。(正确答案) - B: 替换为使用
mysql_connect,但此函数在 PHP 5.5.0 中已被弃用,并且对于 MySQLi 函数无效。 - C: 使用
mysql_xdevapi,这适用于不同的 API,不直接解决mysqli未定义的问题。 - D: 安装 PHP 到 MySQL 路径无法解决函数未定义的问题,因为错误与路径无关。
相关知识点总结
- MySQLi 是 MySQL改进后的API,与 MySQL API 不兼容。
- 未定义函数
mysqli_connect()通常是因为 PHP 未启用 MySQLi 扩展,解决需确认 php.ini 文件中已加载该扩展。 mysql_connect已弃用,不再建议使用,选择 MySQLi 或 PDO 更为安全和现代。- PHP 和 MySQL 的路径设置不影响扩展功能,需通过适当的配置文件启用对应扩展。
Q109
Examine these commands which execute successfully in the sequence shown in Sessions S1 and S2:
S1> SET AUTOCOMMIT=ON;
S1> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
S1> SELECT * FROM emp;
S2> SET AUTOCOMMIT=ON;
S2> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
S2> START TRANSACTION;
S2> INSERT INTO emp values(103, 'King', 50000, 30);
Now, examine this statement that executes successfully in S1:
SELECT * FROM emp;
Which is true about the result of the select statement?
A. The inserted row is returned because the transaction is auto committed in S2.
B. The inserted row is not returned because the isolation level is READ COMMITTED in S2.
C. The inserted row is not returned because the transaction is still active in S2.
D. The inserted row is returned because the isolation level is REPEATABLE READ in S1.
正确答案 C. The inserted row is not returned because the transaction is still active in S2.
中文翻译题目和选项
请检查以下命令在会话 S1 和 S2 中按序成功执行:
S1> SET AUTOCOMMIT=ON;
S1> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
S1> SELECT * FROM emp;
S2> SET AUTOCOMMIT=ON;
S2> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
S2> START TRANSACTION;
S2> INSERT INTO emp values(103, 'King', 50000, 30);
现在,在 S1 中成功执行如下语句:
SELECT * FROM emp;
关于该查询语句结果,以下哪个是正确的?
A. 新插入的行会被返回,因为 S2 中的事务是自动提交的。
B. 新插入的行不会被返回,因为 S2 中的隔离级别是已提交读。
C. 新插入的行不会被返回,因为 S2 中的事务仍然活动。
D. 新插入的行会被返回,因为 S1 中的隔离级别是可重复读。
选项分析
- A: 自动提交并未在 S2 发生,因为事务在 START TRANSACTION 后未提交。
- B: 隔离级别影响的是读该事务的会话,而并非影响未提交事务是否可见。
- C: S2 中事务并未提交,因此在事务仍然运行时,其他会话无法读取未提交的数据。(正确答案)
- D: S1 的隔离级可重复读并不会显示其他会话未提交的更改。
相关知识点总结
- 事务的隔离级别定义了事务如何彼此隔离,常用的级别有:READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ、SERIALIZABLE。
- 在事务隔离级别设置为 READ COMMITTED 时,事务只能读到已提交的数据。
- 即使 AUTOCOMMIT 设置为 ON,显式 START TRANSACTION 将开启事务,直到 COMMIT 或 ROLLBACK 前,数据修改对其他事务不可见。
- 可重复读(REPEATABLE READ)确保数据库在一个事务内的多个读上下文保持一致性。
Q110
Examine the layout of the my_values table:
- Field:
- id: int(11), NULL: No, Key: Primary, Extra: auto_increment
- value_one: int(10) unsigned, NULL: Yes
- value_two: int(10) unsigned, NULL: Yes
Examine the data in the my_values table:
| id | value_one | value_two |
|---|---|---|
| 1 | 20 | 43 |
| 2 | 90 | 78 |
| 3 | 1 | NULL |
| 4 | 10205 | NULL |
| 5 | 7 | 634 |
Examine this statement:
SELECT value_one / value_two AS total
FROM my_values
WHERE id = 4;
Which one is the result of the above SQL statement?
- A) total = NULL
- B) total = 10205
- C) total = 0
- D) Error code 1365. Division by 0
中文翻译题目和选项
检查my_values表的结构:
- 字段:
- id: int(11), NULL: 否, 主键, 自动递增
- value_one: int(10) 无符号, NULL: 是
- value_two: int(10) 无符号, NULL: 是
检查my_values表中的数据:
| id | value_one | value_two |
|---|---|---|
| 1 | 20 | 43 |
| 2 | 90 | 78 |
| 3 | 1 | NULL |
| 4 | 10205 | NULL |
| 5 | 7 | 634 |
检查以下语句:
SELECT value_one / value_two AS total
FROM my_values
WHERE id = 4;
以下哪一项是上述SQL语句的结果?
- A) total = NULL
- B) total = 10205
- C) total = 0
- D) 错误代码 1365. 除数为0
题干含义:
此题目要求分析SQL查询,找出在从my_values表中选出id为4的记录,并计算value_one和value_two的商(value_one / value_two)时的结果。
选项分析
- A) total = NULL: 在SQL中,任何与 NULL 的操作结果通常为NULL。这里value_two为 NULL,因此总是会返回NULL。
- B) total = 10205: 这表示未进行任何除法操作,仅返回value_one的值,不正确。
- C) total = 0: 除数为 NULL 时应该返回 NULL,而不为 0。
- D) 错误代码 1365: 当分母为0时会出现,但这里是 NULL,不是0。
正确答案:A)
相关知识点总结
- NULL值与运算: 在SQL中,对NULL值进行任何数学运算(如加法、减法、乘法、除法),结果都是NULL。
DIVISION时需要确保分母不为 NULL。此外,通过选择合适的选项或加入防护措施来避免无效操作。- SQL标准和语言习惯中将NULL作为一种不确定或没有值的状态,操作者需注意针对 NULL 的运算结果。
- 数据库约束(如类型约束、非空约束等)能够防止存入不合理的数据,帮助保持数据的一致性和完整性。
Q111
英文原文
Which select statement returns true?
- A)
SELECT NULL <> NULL; - B)
SELECT NULL <=> NULL; - C)
SELECT NULL = NULL; - D)
SELECT NULL := NULL;
中文翻译题目和选项
哪个SELECT语句返回true?
- A)
SELECT NULL <> NULL; - B)
SELECT NULL <=> NULL; - C)
SELECT NULL = NULL; - D)
SELECT NULL := NULL;
题干含义:
本题要求确认哪个 SQL 查询语句能返回 TRUE,主要考查对 NULL 值在 SQL 中的比较操作的理解。
选项分析
- A)
SELECT NULL <> NULL;: 在SQL中,NULL表示未知值,两个未知值不应该被认为是不同的,因此结果为 false。 - B)
SELECT NULL <=> NULL;: 这个操作符是MySQL特有的,用来判断两个NULL是否是相等的。结果为 true。(正确答案) - C)
SELECT NULL = NULL;: 在SQL中,将两个NULL进行比较通常是不确定的,不返回 true。 - D)
SELECT NULL := NULL;: 这里使用了赋值操作符,而不是比较操作符,语法上即不正确。
正确答案:B)
相关知识点总结
- NULL值比较: 在标准SQL中,NULL与NULL的比较会返回 NULL,因为NULL代表未知的值。
<=>操作符: 专门用于比较NULL值,特别在MySQL中提供,用于处理NULL安全比较。- SQL标准: 除非特别处理,在标准SQL中的比较运算,NULL与其他值比较,包括NULL自己,通常返回NULL。
:=赋值操作符: 在SQL中常用于变量赋值,用于比较时不被接受。
Q112
Examine the statement which executes successfully:
SET sql_mode='NO_ENGINE_SUBSTITUTION';
You try to create a table with a storage engine that is not available. What will happen?
- A) An error occurs and the create table statement fails.
- B) The server will create the table but it will be unusable until the specified storage engine is available.
- C) The server will create the table but report an error when the first attempt to insert a row is performed.
- D) The server will create the table using the default storage engine.
中文翻译题目和选项
检查可以成功执行的语句:
SET sql_mode='NO_ENGINE_SUBSTITUTION';
您尝试使用不可用的存储引擎创建表。结果会怎样?
- A) 出现错误,创建表语句失败。
- B) 服务器将创建表,但在指定的存储引擎可用之前将无法使用该表。
- C) 服务器将创建表,但在第一次尝试插入行时报告错误。
- D) 服务器将使用默认存储引擎创建表。
题干含义:
此题目考察 MySQL 下 SQL_MODE 设置为 NO_ENGINE_SUBSTITUTION 时,使用不可用的存储引擎创建表会产生的结果。
选项分析
-
A) An error occurs and the create table statement fails.
- 正确。在 SQL_MODE 设为
NO_ENGINE_SUBSTITUTION时,若指定的存储引擎不可用,会直接抛出错误,而不进行其他引擎的替代。
- 正确。在 SQL_MODE 设为
-
B) The server will create the table but it will be unusable until the specified storage engine is available.
- 错误。在上述模式设置下,服务器不会在指定引擎不可用时创建该表。
-
C) The server will create the table but report an error when the first attempt to insert a row is performed.
- 错误。表不会因引擎不可用被创建,因此无行插入错误的可能。
-
D) The server will create the table using the default storage engine.
- 错误。若存储引擎不可用且
NO_ENGINE_SUBSTITUTION启用,表不会被创建,而非使用默认引擎替代。
- 错误。若存储引擎不可用且
正确答案:A)
相关知识点总结
关联知识点Q18
- NO_ENGINE_SUBSTITUTION:此模式阻止 MySQL 在目标引擎不可用时自动使用默认存储引擎。
- 存储引擎:在 MySQL 中定义用于数据存储、索引和各种功能特性支持的机械。
- SQL_MODE设置:提供多种用于更改MySQL处理SQL语法和数据校验的设置,以提升灵活性支持不同应用场景。
- 错误处理:理解并处理可能的数据库引擎不可用的错误是数据库管理重要组成部分。
Q113
英文原文
Which two differences exist between the timestamp and date time data types?
- A) timestamp has larger range of values.
- B) timestamp uses less storage space.
- C) timestamp stores more decimal points in seconds.
- D) timestamp converts the value based on the session time zone.
- E) timestamp stores the interval between two dates.
中文翻译题目和选项
时间戳和日期时间数据类型之间存在哪两个差异?
- A) 时间戳具有更大的值范围。
- B) 时间戳使用更少的存储空间。
- C) 时间戳在秒中存储更多的小数点。
- D) 时间戳根据会话时区转换值。
- E) 时间戳存储两个日期之间的间隔。
题干含义:
此题要求识别出两种数据类型 时间戳 (timestamp) 和 日期时间 (datetime) 数据类型之间的差异性。
选项分析
-
A) 时间戳具有更大的值范围:
- 错误。实际上,datetime通常支持比timestamp更大的日期范围。
-
B) 时间戳使用更少的存储空间:
- 正确。timestamp 使用较少的存储,因为它在处理时区转换方面相对紧凑。
-
C) 时间戳在秒中存储更多的小数点:
- 错误。timestamp 和 datetime 通常存储同样的精度(取决于数据库的具体实现,如MySQL通常不支持纳秒级)。
-
D) 时间戳根据会话时区转换值:
- 正确。timestamp数据类型会根据数据库的会话时区自动调整其表示。
-
E) 时间戳存储两个日期之间的间隔:
- 错误。interval是一种专门的数据类型,通常不与timestamp混淆。
正确答案:B 和 D
相关知识点总结
关联知识点Q17
- 时间戳 (timestamp): 通常用于表示某一特定时刻,随数据库会话时区的变化而变化。
- 日期时间 (datetime): 不处理时区,表示特定的日期和时间。
- 时区处理: Timestamp 处理时区方面的能力更强,对于全球应用很有用。
- 存储机制: Timestamp 的存储更紧凑,数据库内存分配上有所节约。
- 范围与精度: Timestamp在许多系统中限制在1970至2038年的范围内,而datetime通常支持更大日期范围。
Q114
Examine the content of the employee table:
| emp_id | empname | age |
|---|---|---|
| 1 | Kathy | 24 |
| 2 | Liril | 25 |
Now examine this PHP script:
$dsn = "mysql:host=localhost;dbname=dbname;charset=utf8mb4";
// -- insert here --
try {
$pdo = new PDO($dsn, 'username', 'password', $options);
} catch (PDOException $e) {
throw new PDOException($e->getMessage(), (int)$e->getCode());
}
$stmt = $pdo->query('SELECT * FROM employee');
while ($row = $stmt->fetch()) {
echo nl2br($row[1] . "'s age is : " . $row['age'] . "\n");
}
Finally examine this desired output:
Kathy's age is : 24
Liril's age is : 25
Which option should replace // -- insert here -- to produce the desired output?
- A)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_ASSOC]; - B)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_OBJ]; - C)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_BOTH]; - D)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_CLASS];
中文翻译题目和选项
检查employee表的内容:
| emp_id | empname | age |
|---|---|---|
| 1 | Kathy | 24 |
| 2 | Liril | 25 |
检查如下PHP脚本:
$dsn = "mysql:host=localhost;dbname=dbname;charset=utf8mb4";
// -- insert here --
try {
$pdo = new PDO($dsn, 'username', 'password', $options);
} catch (PDOException $e) {
throw new PDOException($e->getMessage(), (int)$e->getCode());
}
$stmt = $pdo->query('SELECT * FROM employee');
while ($row = $stmt->fetch()) {
echo nl2br($row[1] . "'s age is : " . $row['age'] . "\n");
}
期望输出:
Kathy's age is : 24
Liril's age is : 25
需替换 // -- insert here -- 的选项以实现期望输出:
- A)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_ASSOC]; - B)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_OBJ]; - C)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_BOTH]; - D)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_CLASS];
题干含义:
要求在PHP代码中替换适当的PDO选项以使得到的数据能够用index和关联键访问,以达到期望的输出效果。
选项分析
-
A)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_ASSOC];- 错误。此模式仅支持通过列名来访问数据,
$row[1]不可用。
- 错误。此模式仅支持通过列名来访问数据,
-
B)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_OBJ];- 错误。此模式返回对象,无法使用
$row[1]和$row['age']的方式访问。
- 错误。此模式返回对象,无法使用
-
C)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_BOTH];- 正确。此模式支持通过索引和列名两种方式访问数据:
$row[1]为名字,$row['age']为年龄。(正确答案)
- 正确。此模式支持通过索引和列名两种方式访问数据:
-
D)
$options = [PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_CLASS];- 错误。此模式无法直接支持数组形式访问,需要类且字段名与类属性匹配。
正确答案:C)
相关知识点总结
https://www.php.net/manual/zh/class.pdostatement.php
- PDO Fetch Mode: 此选项决定如何从PDO中提取数据。
- FETCH_ASSOC: 返回一个索引为结果集列名的数组。
- FETCH_BOTH: 默认模式,返回一个索引为结果集列名和以0开始的列号的数组。
- FETCH_OBJ: 返回数据作为对象。
- FETCH_CLASS: 将提取的数据映射到类实例上。
- 使用场景: 选择恰当的Fetch Mode优化代码数据处理和访问的便捷性。
- 性能与安全: 参数化PDO有效防止SQL注入,是数据库交互的重要手段。
Q115
Examine this table definition:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| doc | json | YES | |||
| _id | varbinary(32) | NO | PRI | STORED GENERATED | |
| _json_schema | json | YES | VIRTUAL GENERATED |
The table must always remain a valid document store collection. What restriction does this impose on any added column?
- A) The column must be a generated column referencing any attribute of doc.
- B) The column must have a default value.
- C) The column must be used in a unique constraint.
- D) The column must be a generated column referencing only an existing attribute of doc.
- E) The column must be indexed.
中文翻译题目和选项
检查此表定义:
| 字段 | 类型 | 允许为空 | 键 | 默认值 | 额外 |
|---|---|---|---|---|---|
| doc | json | 是 | NULL | ||
| _id | varbinary(32) | 否 | PRI | NULL | STORED GENERATED |
| _json_schema | json | 是 | NULL | VIRTUAL GENERATED |
表必须始终保持为有效的文档存储集合。这对任何添加的列有何限制?
- A) 列必须是引用doc中任何属性的生成列。
- B) 列必须具有默认值。
- C) 列必须用于唯一约束中。
- D) 列必须是仅引用doc中现有属性的生成列。
- E) 列必须被索引。
题干含义:
此问题考核的是在定义存储为有效的文档集合的表时,对STORED /VIRTUAL GENERATED 列施加的限制条件。
选项分析
-
A) The column must be a generated column referencing any attribute of doc.
- 不正确,因为STORED 生成列不能随意延伸到doc的未定义属性。
-
B) The column must have a default value.
- 不相关。STORED /VIRTUAL GENERATED 默认值不是必要。
-
C) The column must be used in a unique constraint.
- 不相关。与唯一约束无直接关系。
-
D) The column must be a generated column referencing only an existing attribute of doc.
- 正确。为了保持文档存储的完整性,生成列应仅引用doc的现有属性。(正确答案)
-
E) The column must be indexed.
- 不相关。索引是性能考虑,而不是有效性要求。
正确答案:D)
相关知识点总结
知识点 Q67
Q116
Examine these statements which execute successfully:
CREATE TABLE users (
user_id int(11) NOT NULL AUTO_INCREMENT,
loc_id int(11) DEFAULT NULL,
user_name varchar(50) NOT NULL,
loc_static int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (user_id)
) ENGINE=InnoDB AUTO_INCREMENT=4968107 DEFAULT CHARSET=latin1;
CREATE TABLE locations (
loc_id int(11) NOT NULL AUTO_INCREMENT,
site_id int(11) NOT NULL,
loc_name varchar(50) NOT NULL,
loc_static int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (loc_id)
) ENGINE=InnoDB AUTO_INCREMENT=6835 DEFAULT CHARSET=latin1;
SELECT
loc.site_id,
loc.loc_name,
loc.loc_static,
user_name
FROM users usr
INNER JOIN locations loc ON loc.loc_id=usr.loc_id
WHERE loc_mapping= 'daa9a225-8a4d-11ea-b3cf-00059a3c7a00';
Which two changes will improve this query performance?
- A) CREATE INDEX 1X7 ON users (user_name) USING HASH;
- B) CREATE INDEX 1X4 ON Locations (site_id, loc_shared);
- C) CREATE INDEX IX1 ON locations (loc_shareci);
- D) CREATE INDEX 1X6 ON users (user_name);
- E) CREATE INDEX 1X3 ON locations <loc_site_id>;
- F) CREATE INDEX 1X2 ON locations (loc_mapping) USING HASH;
- G) CREATE INDEX 1X5 ON users (loc_id);
中文翻译题目和选项
请分析以下可以成功执行的语句:
CREATE TABLE users (
user_id int(11) NOT NULL AUTO_INCREMENT,
loc_id int(11) DEFAULT NULL,
user_name varchar(50) NOT NULL,
loc_static int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (user_id)
) ENGINE=InnoDB AUTO_INCREMENT=4968107 DEFAULT CHARSET=latin1;
CREATE TABLE locations (
loc_id int(11) NOT NULL AUTO_INCREMENT,
site_id int(11) NOT NULL,
loc_name varchar(50) NOT NULL,
loc_static int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (loc_id)
) ENGINE=InnoDB AUTO_INCREMENT=6835 DEFAULT CHARSET=latin1;
SELECT
loc.site_id,
loc.loc_name,
loc.loc_static,
user_name
FROM users usr
INNER JOIN locations loc ON loc.loc_id=usr.loc_id
WHERE loc_mapping= 'daa9a225-8a4d-11ea-b3cf-00059a3c7a00';
哪两项更改将改善此查询的性能?
- A) CREATE INDEX 1X7 ON users (user_name) USING HASH;
- B) CREATE INDEX 1X4 ON Locations (site_id, loc_shared);
- C) CREATE INDEX IX1 ON locations (loc_shareci);
- D) CREATE INDEX 1X6 ON users (user_name);
- E) CREATE INDEX 1X3 ON locations <loc_site_id>;
- F) CREATE INDEX 1X2 ON locations (loc_mapping) USING HASH;
- G) CREATE INDEX 1X5 ON users (loc_id);
题干含义:
题目要求对给定的 SQL 查询,找出通过创建索引可以提升查询性能的两项改动。
选项分析
- A: Hash 索引用于 user_name,不针对连接中涉及字段。
- B: site_id 和 loc_shared 列在 JOIN 中未使用,不影响连接。
- C: loc_shareci 与查询无关,无提升效果。
- D: user_name 非连接键,且已在 SELECT 中,索引无特别提高。
- E: loc_site_id 非连接中使用字段,无性能提升。
- F: loc_mapping 是连接关键字段,为提高查询性能正确的索引。(选项 F)
- G: loc_id 是连接关键字段,为提高查询性能正确的索引。(选项 G)
正确答案: F,G
相关知识点总结
- 索引可以显著提升查询性能,特别是在连接或过滤中使用的字段。
- 使用HASH索引有助于提高均匀分布字段的查询效率。
- 在连接条件字段使用索引可优化
INNER JOIN性能。 - 优先索引常用过滤或连接键字段以提升检索速度和性能。
Q117
Examine these statements which execute successfully:
try {
$connect->beginTransaction();
$result = $connect->exec("INSERT INTO band(song) VALUES('Here comes the sun')");
$result = $connect->exec("SAVEPOINT addsong");
} catch (PDOException $ex) {
echo "Query error: " . $ex->getMessage() . "\n";
}
try {
$connect->rollBack();
$result = $connect->exec("DELETE FROM band;");
$result = $connect->exec("INSERT INTO band(song) VALUES('Here comes the sun')");
} catch (PDOException $ex) {
echo "Rollback error: " . $ex->getMessage() . "\n";
}
The statements executed without exception. Which two are true?
- A) No transaction commits.
- B) One row is inserted into band.
- C) Two transactions commit.
- D) No row is inserted into band.
- E) The transaction is rolled back to the savepoint.
中文翻译题目和选项
请查看以下成功执行的语句:
try {
$connect->beginTransaction();
$result = $connect->exec("INSERT INTO band(song) VALUES('Here comes the sun')");
$result = $connect->exec("SAVEPOINT addsong");
} catch (PDOException $ex) {
echo "Query error: " . $ex->getMessage() . "\n";
}
try {
$connect->rollBack();
$result = $connect->exec("DELETE FROM band;");
$result = $connect->exec("INSERT INTO band(song) VALUES('Here comes the sun')");
} catch (PDOException $ex) {
echo "Rollback error: " . $ex->getMessage() . "\n";
}
这些语句在没有异常的情况下执行。哪两项是正确的?
- A) 没有事务提交。
- B) 向表 band 插入了一行。
- C) 两个事务提交。
- D) 没有行被插入到 band 中。
- E) 事务回滚到保存点。
代码的分步分析:
try {
$connect->beginTransaction();
$result = $connect->exec("INSERT INTO band(song) VALUES('Here comes the sun')");
$result = $connect->exec("SAVEPOINT addsong");
} catch (PDOException $ex) {
echo "Query error: " . $ex->getMessage() . "\n";
}
- 第一部分解释
$connect->beginTransaction();
启动一个新的数据库事务。事务开始后,所有的数据库操作都将在事务内进行,直到事务被提交或回滚。
$connect->exec("INSERT INTO band(song) VALUES('Here comes the sun')");
执行插入语句,将字符串 'Here comes the sun' 插入到band表的song列中。
$connect->exec("SAVEPOINT addsong");
创建一个名为addsong的保存点。保存点允许之后的事务回滚到该点。
异常处理机制
使用try-catch结构。若在执行过程中发生数据库操作异常,如连接错误,那么会捕获PDOException并输出错误信息。
try {
$connect->rollBack();
$result = $connect->exec("DELETE FROM band;");
$result = $connect->exec("INSERT INTO band(song) VALUES('Here comes the sun')");
} catch (PDOException $ex) {
echo "Rollback error: " . $ex->getMessage() . "\n";
}
- 第二部分解释
$connect->rollBack();
进行事务的全局回滚,撤销自beginTransaction();以来的所有操作,包括前面的插入动作。
$connect->exec("DELETE FROM band;");
执行删除语句,删除band表中的所有记录。“自动提交”模式。
$connect->exec("INSERT INTO band(song) VALUES('Here comes the sun')");
再次尝试插入。该插入却未在事务内进行,实际会成功插入,因为事务已回滚过并且未再开始新的事务。“自动提交”模式
异常处理
try-catch结构再次用来捕获异常,输出错误信息以帮助调试。
选项分析
A: 第一个事务开始后进行了回滚,没有提交,但是事务回滚后的“自动提交”模式下提交两个事务。
B: 由于回滚操作和缺乏提交,第一个事务中的插入操作没有最终生效,但是事务回滚后的insert语句执行成功了。(正确答案)
C: “自动提交”模式下提交两个事务。(正确答案)
D: 事务回滚后的insert语句执行成功了。
E: COMMIT 或未经命名的 ROLLBACK: 当前事务的所有保存点被删除,代码块没有进行回滚到保存点的操作,只是进行了常规回滚。
正确答案: B, C
PDO 事务与自动提交
https://www.php.net/manual/zh/pdo.transactions.php
当第一次打开连接时,PDO 需要在所谓的“自动提交”模式下运行。自动提交模式意味着,如果数据库支持,运行的每个查询都有它自己的隐式事务,如果数据库不支持事务,则没有。
如果需要一个事务,则必须用 PDO::beginTransaction() 方法来启动。如果底层驱动不支持事务,则抛出一个 PDOException 异常(不管错误处理设置是怎样的,这都是一个严重的错误状态)。一旦开始了事务,可用 PDO::commit() 或 PDO::rollBack() 来完成,这取决于事务中的代码是否运行成功。
SAVEPOINT, ROLLBACK TO SAVEPOINT, and RELEASE SAVEPOINT Statements
https://dev.mysql.com/doc/refman/8.0/en/savepoint.html
InnoDB 支持如下 SQL 语句:
- SAVEPOINT
- ROLLBACK TO SAVEPOINT
- RELEASE SAVEPOINT
以及用于 ROLLBACK 的可选关键字 WORK。
语法
-
SAVEPOINT identifier:设置一个标记为identifier的事务保存点。如果当前事务已存在同名保存点,则删除旧保存点并设置新的保存点。 -
ROLLBACK [WORK] TO [SAVEPOINT] identifier:回滚事务至指定的保存点,而不终止事务。会撤销在保存点设置之后事务对行的修改,但不会释放内存中保存点后的行锁。(对于新插入的行,锁信息通过事务 ID 存储于行中,在撤销中释放锁)较晚的保存点将被删除。如果出现错误
ERROR 1305 (42000): SAVEPOINT identifier does not exist,这意味着指定名称的保存点不存在。 -
RELEASE SAVEPOINT identifier:从当前事务保存点集合中删除指定保存点,既不提交也不回滚。如果保存点不存在,将产生错误。
保存点行为
- COMMIT 或未经命名的 ROLLBACK: 当前事务的所有保存点被删除。
- 存储函数或触发器:调用或激活时创建一个新的保存点级别,之前级别的保存点变得不可用,以避免冲突。函数或触发器终止时,所创建的保存点会被释放,原保存点级别被恢复。
总结
- 保存点允许事务内部分回滚,增加控制细度。
- 在事务提交或整体回滚时,所有保存点将被删除。
- 使用存储函数和触发器时,会产生新的保存点层级,防止上下级保存点冲突。
Q118
Examine these statements:
SET collation_connection=utf8mb4_0900_as_cs;
SELECT STRCMP('Alice', UCASE('Alice*'));
What is displayed?
A. 0
B. ERROR: 1267 (HY000): Illegal mix of collations
C. -1
D. NULL
E. 1
答案:C
中文翻译题目和选项
请检查如下语句:
SET collation_connection=utf8mb4_0900_as_cs;
SELECT STRCMP('Alice', UCASE('Alice*'));
会显示什么?
A. 0
B. 错误:1267 (HY000):非法字符集混合
C. -1
D. NULL
E. 1
选项分析
- A: 会显示0,这在两个字符串相同或者字符集问题不影响时会出现,但此情况不正确。
- B: 显示-1。
- C: 显示-1,意味着后者大于前者。(正确答案)
- D: 显示NULL,通常在输入无效或者字符集问题情况下会出现,但不包括明显的字符集冲突。
- E: 显示-1
相关知识点总结
- 字符集和排序规则(collation)控制字符串比较的行为,尤其在不同字符集间进行运算时常导致错误。
- UCASE函数用于将字符串转为大写,可能影响字符排序的行为,尤其在特定字符集下。
- STRCMP函数用于比较两个字符串,但需要确保其使用相同的字符集来避免冲突。。
语法::STRCMP(string1, string2)
参数值
参数 描述
string1, string2 必需。要比较的两个字符串
返回值
如果string1 = string2,这个函数返回0
如果 string1 < string2,这个函数返回-1
如果 string1 > string2,这个函数返回1 - 错误代码1267指出字符集混合不合法,特别是当涉及不同排序规则和字符集时。
Q119
The Continent column in the country table contains no NULL values.
Examine this output:
| Continent | pop | num_country |
|--------------|---------------------|-------------|
| NULL | 6078749450 | 239 |
| Africa | 784475000 | 58 |
| Antarctica | 0 | 5 |
| Asia | 3705025700 | 51 |
| Europe | 730074600 | 46 |
| North America| 482993000 | 37 |
| Oceania | 30041150 | 28 |
| South America| 345780000 | 14 |
Which statement will produce the output with the default sql_mode?
A.
SELECT Continent,
Population as pop,
COUNT(DISTINCT code) as num_country
FROM country
GROUP BY Continent
ORDER BY Continent;
B.
SELECT Continent,
SUM(Population) as pop,
COUNT(DISTINCT code) as num_country
FROM country
GROUP BY Continent WITH ROLLUP
ORDER BY Continent;
C.
SELECT Continent,
SUM(Population) as pop,
COUNT(DISTINCT code) as num_country
FROM country
GROUP BY Continent
ORDER BY Continent;
D.
SELECT Continent,
Population as pop,
COUNT(DISTINCT code) as num_country
FROM country
GROUP BY Continent WITH ROLLUP
ORDER BY Continent;
答案:B
中文翻译题目和选项
country 表中 Continent 列没有 NULL 值。
请检查以下输出:
| Continent | pop | num_country |
|--------------|---------------------|-------------|
| NULL | 6078749450 | 239 |
| Africa | 784475000 | 58 |
| Antarctica | 0 | 5 |
| Asia | 3705025700 | 51 |
| Europe | 730074600 | 46 |
| North America| 482993000 | 37 |
| Oceania | 30041150 | 28 |
| South America| 345780000 | 14 |
哪个 SQL 语句在默认的 sql_mode 下能产生上述输出?
A.
SELECT Continent,
Population as pop,
COUNT(DISTINCT code) as num_country
FROM country
GROUP BY Continent
ORDER BY Continent;
B.
SELECT Continent,
SUM(Population) as pop,
COUNT(DISTINCT code) as num_country
FROM country
GROUP BY Continent WITH ROLLUP
ORDER BY Continent;
C.
SELECT Continent,
SUM(Population) as pop,
COUNT(DISTINCT code) as num_country
FROM country
GROUP BY Continent
ORDER BY Continent;
D.
SELECT Continent,
Population as pop,
COUNT(DISTINCT code) as num_country
FROM country
GROUP BY Continent WITH ROLLUP
ORDER BY Continent;
题干含义:
题目要求找出一种 SQL 查询语句,该语句在默认 sql_mode 下可以生成给定的输出表格。
选项分析
- A: 此句没有使用 SUM 函数聚合 Population,也没有处理 NULL 汇总行。(错误)
- B: 使用了
GROUP BY Continent WITH ROLLUP,将数据汇总,并在 NULL 行展示总汇结果,符合题目要求。(正确答案) - C: 使用 SUM 聚合但没有 ROLLUP,缺少 NULL 汇总行。(错误)
- D: Population 没有聚合,只是计数,且使用 ROLLUP,但不生成期望的总行。(错误)
GROUP BY 修饰符:关于 WITH ROLLUP
https://dev.mysql.com/doc/refman/8.0/en/group-by-modifiers.html
在 MySQL 中,GROUP BY 子句允许使用 WITH ROLLUP 修饰符,来包含额外的行用于更高级别(超聚合)的汇总操作。这对于在线分析处理(OLAP)操作特别有用,可以通过单个查询实现多级别的数据分析。
ROLLUP 在销售表中的示例
假定 sales 表有以下列:年份(year)、国家(country)、产品(product)、利润(profit)。ROLLUP 的实际应用如下:
-
不使用 ROLLUP:
SELECT year, SUM(profit) AS profit FROM sales GROUP BY year;结果:
| year | profit | |------|--------| | 2000 | 4525 | | 2001 | 3010 | -
使用 ROLLUP:
SELECT year, SUM(profit) AS profit FROM sales GROUP BY year WITH ROLLUP;结果:
| year | profit | |------|--------| | 2000 | 4525 | | 2001 | 3010 | | NULL | 7535 |注意:
year列中的NULL行代表所有年份的总利润。
ROLLUP 生成的超聚合行:
- 对于单一分组列,添加单行的超聚合。
- 对于多分组列,ROLLUP 提供子总计行及总计。
多列的高级示例
在多列中使用 ROLLUP,MySQL 提供多级别的聚合:
- 示例:
预期输出包括各级别的汇总:SELECT year, country, product, SUM(profit) AS profit FROM sales GROUP BY year, country, product WITH ROLLUP;- 每年、国家和产品组合的总和。
- 每年和国家组合的子总和。
- 所有年份的总总计。
管理 ROLLUP 中的 NULL 值
-
识别超聚合行:
GROUPING()函数帮助区分超聚合行中的 NULL 与常规数据中的 NULL:SELECT year, country, product, SUM(profit) AS profit, GROUPING(year) AS grp_year, GROUPING(country) AS grp_country, GROUPING(product) AS grp_product FROM sales GROUP BY year, country, product WITH ROLLUP; -
替换 NULL 值:
使用条件逻辑用描述性标签替换 NULL 值,以便更容易解读:SELECT IF(GROUPING(year), '所有年份', year) AS year, IF(GROUPING(country), '所有国家', country) AS country, IF(GROUPING(product), '所有产品', product) AS product, SUM(profit) AS profit FROM sales GROUP BY year, country, product WITH ROLLUP;这样,结果集中的 NULL 值将被易于理解的标签替代。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号