4.K均值算法--应用
1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
第一题:
import imageio
from sklearn.cluster import KMeans
import sys
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as img
seele = imageio.imread('D:/seele.jpg')
image = seele[::3, ::3]
# seele.shape
# image.shape
# 二维变线性
x = image.reshape(-1, 3)
model = KMeans(64)
labels = model.fit_predict(x)
colors = model.cluster_centers_
#以聚类中心替代原像素颜色,还原为二维
new_image = colors[labels].reshape(image.shape)
#前后占内存大小
sys.getsizeof(seele)
sys.getsizeof(new_image)
#画
plt.rcParams['font.sans-serif'] = 'SimHei'# 设置中文显示
p = plt.figure(figsize=(10, 10))
a1 = p.add_subplot(2, 1, 1)
plt.imshow(seele)
plt.title("压缩前")
a2 = p.add_subplot(2, 1, 2)
plt.imshow(new_image.astype(np.uint8))
plt.title("压缩后")
#存
img.imsave('D://new_seele.jpg',new_image.astype(np.uint8))
压缩前后占内存大小对比:

压缩前后文件大小对比:

压缩前后图片对比:

第二题:
import pandas as pd
import os
import docx
import re
import operator
path='D:/data/'
def readD(path):
df = pd.DataFrame(columns = ['word'])
rowname=[]#改行名
folder = os.listdir(path)
for i in folder:
if i[-4:-1] == 'doc' or i[-5:-1] == 'docx':
file = docx.Document(path+i)
str = ''
for para in file.paragraphs:
rowname = re.findall('\d+',i)
row=rowname[0]+'年'+rowname[1]+'月第'+rowname[2]+'套'
str = str + ' ' + para.text
data = re.findall("[a-z]+", ''.join(str).lower())#匹配字母转小写
dic = {}
for word in data:
if word not in dic.keys():
dic[word] = 1
else:
dic[word] = dic[word] + 1
tempdf=pd.DataFrame(sorted(dic.items(), key=operator.itemgetter(1), reverse=True))
tempdf.columns = ['word',row]
df = df.drop_duplicates(['word']).merge(tempdf, on=['word'], how='outer').fillna(0)#连接,补0
return df
dff=readD(path)
for i in range(len(dff)):
if len(dff["word"][i])<=4:#去掉简单词
dff=dff.drop([i])
dff=dff.reset_index(drop=True)#行重新编号
dff.set_index(["word"], inplace=True)#单词列设为index
#先计算再赋值
temp1=dff.apply(lambda x: x.sum(), axis=1)
temp2=(dff != 0).astype(int).sum(axis=1)/(dff.shape[1])#在多少份卷子出现过/卷数
dff['出现次数'] = temp1
dff['出现频率'] =temp2
import numpy as np
from sklearn.cluster import KMeans
s=np.array(dff.iloc[:,:dff.shape[1]])
model=KMeans(3)
labels = model.fit_predict(s)
group1 = []
group2 = []
group3 = []
for i in range(len(s)):
if labels[i] == 0:
group1.append(s[i, :])
groupA = np.array(group1)
elif labels[i] == 1:
group1.append(s[i, :])
groupB = np.array(group1)
elif labels[i] == 2:
group3.append(s[i, :])
groupC = np.array(group3)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
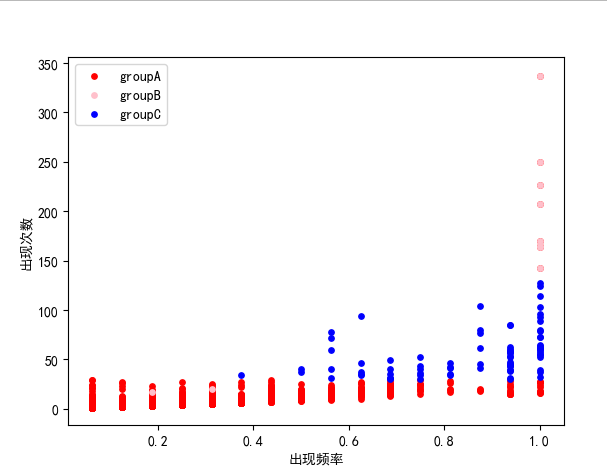
p1=plt.scatter(groupA[:,-1],groupA[:,-2],s=15,c='red')
p2=plt.scatter(groupB[:,-1],groupB[:,-2],s=15,c="pink")
p3=plt.scatter(groupC[:,-1],groupC[:,-2],s=15, c="blue")
plt.xlabel("出现频率")
plt.ylabel("出现次数")
plt.legend((p1, p2, p3), ('groupA', 'groupB', 'groupC'))
w=[]
for i in range(len(dff)):
for j in range(len(groupC)):
if np.all(groupC[j] == np.array(dff[i-1:i])):
if dff.index.values[i-1] not in w:
w.append(dff.index.values[i-1])
print(w)
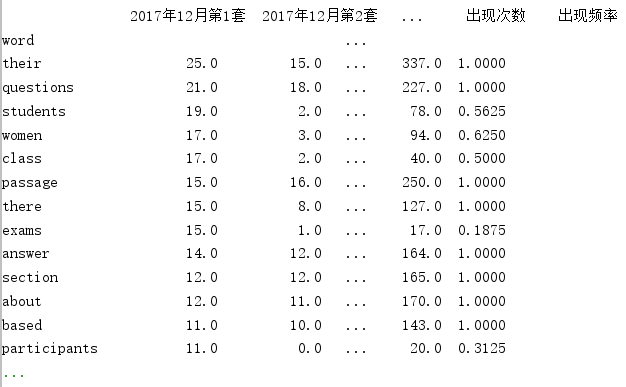
数据为若干个英语四级历年真题word文档,将其中单词划分为高、中、低频3类。使用sklearn库的kmeans函数进行预测。
原数据:
整理完后的数据:
把单词划分为groupA,B,C三类
groupC组词这种“不温不火”的单词更应该值得我们注意。
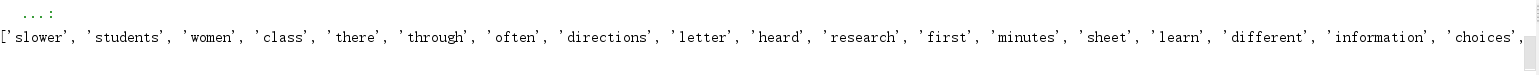

 浙公网安备 33010602011771号
浙公网安备 33010602011771号