
SQL 语句 笔记
Structured Query Language 结构化查询语言
SQL 标准之外,大部分 SQL 数据库程序都拥有它们自己的专有扩展!
RDBMS (Relational Database Management System) 指关系型数据库管理系统。
database 库
create database 建库
create database 数据库名;
alter database 改库
alter database 数据库名;
选中数据库
use 数据库名
table 表
create table 建表
create table 表名(
属性名1 varchar(20) not null,
属性名2 varchar(15) not null,
属性名3 oumeric(12, 2),
primary key (属性名1,属性名2),
foreign key (属性名3) references 另一个表名(属性名)
);
| 约束字 | |
|---|---|
| not null | 指示某列不能存储 NULL 值。 |
| unique | 保证某列的每行必须有唯一的值。 |
| primary key | not null 和 unique 的结合。确保某列(或两个列多个列的结合)有唯一标识。 |
| foreign key | 保证一个表中的数据匹配另一个表中的值的参照完整性。 |
| check | 保证列中的值符合指定的条件。 |
| default | 规定没有给列赋值时的默认值。 |
check 独立一行(, 分隔)定义
// 命名约束
constraint chk_Person check (condition)
追加 check
alter table Persons
add check (condition)
AUTO INCREMENT 自动递增
drop table 删表
drop table 表名;
alter table 改表
// 增加 属性
alter table 表名 add 新的属性名 数据类型;
// 删去 属性
alter table 表名 drop 已有属性名;
索引
CREATE INDEX - 创建索引(搜索键)
create index index_name
on table_name (col1,col2,···)
CREATE UNIQUE INDEX 创建唯一索引
DROP INDEX - 删除索引
drop view view_name
insert into 增
insert into 表名(属性1,属性2,···)
values (属性值1, 属性值2,···);
insert into 表名
values (属性值1, 属性值2,···); // 需要列出插入行的每一列数据
复制表插入
select into
select col(s)
into 插入表名 [in 另一个数据库名]
from 复制表名
where condition;
insert into select
insert into table2
(col1, col2,···, coln)
select col1, col2,···, coln
from 复制表名
where condition;
delete 删
delete from 表名 // 无where则删除表内全部数据,此操作可回滚;truncate 不可回滚
[where 谓词];
update 改
update 表名
set 赋值操作
[from 另一个表中获取属性,供赋值操作]
where 条件筛选
赋值格式:
col1=123, col2='xxx'
case条件分支
case
when pred1 then result1
when pred2 then result2
when pred3 then result3
···
when predn then resultn
else result0
end
select 查
//单表查询(单关系)
select [distinct/all] 属性名1,属性名2,..[可对属性进行加减乘除运算]
from 表名
[where 谓词]; //通过谓词对表的数据项进行筛选, 支持 and or not 比较运算符
[order by 属性名1 desc降序, 属性名2 asc升序]
//联表查询(多关系)
from 表1,表2,..
where 表1.属性A = 表2.属性B; //给定匹配关系
关键字说明:
distinct去除重复行;all全部显示(重复行)
where 子句
用于提取那些满足指定条件的记录
select column1, column2, ...
from table_name
where condition;
condition 写法:
列名='xxx'
列名=123
比较字符与关键字
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| between xx and yy | 在 xx~yy 范围内 |
| like | 搜索某种模式,可使用通配符 col1 like '_xxx%' |
| in | 指定针对某个列的多个可能值 col1 in (1,3,5) |
| is null | col1 is null |
where 子句并不一定带比较运算符,当不带运算符时,会执行一个隐式转换。
当 0 时转化为 false,1 转化为 true。
通配符:
%匹配任意字符串
_匹配任意单个字符
[charlist]字符列中的任何单一字符
[^charlist]或者[!charlist]不在字符列中的任何单一字符
逻辑运算关键字:
() > not > and > or
order by 排序
order by column1 [asc|desc], column2, ...
多列时,依次按照列排序,前列同名时,才会考虑后列排序。
asc:按升序排序。默认
desc:按降序排序。
mysql
select top n选取前n项
col1 regexp '^[A-H]'
join 连接 连表
inner join:如果表中有至少一个匹配,则返回行 必须能找到on匹配才返回left join:即使右表中没有匹配,也从左表返回所有的行 未匹配的最终列以null填充right join:即使左表中没有匹配,也从右表返回所有的行 未匹配的最终列以null填充full join:只要其中一个表中存在匹配,则返回行
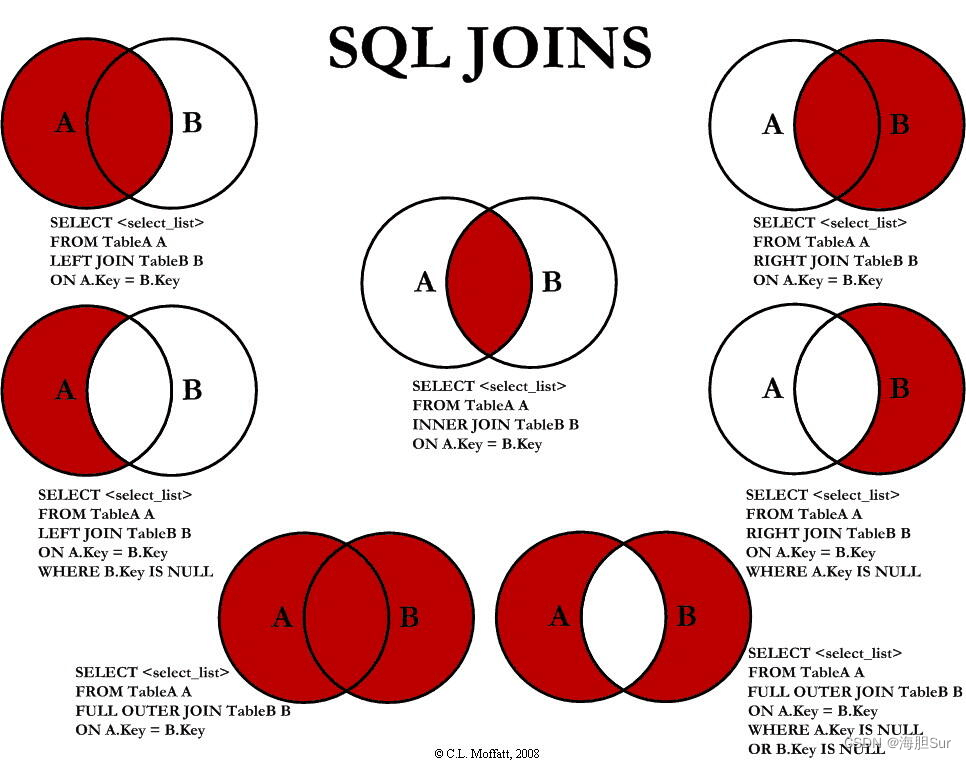
where 条件是在临时表生成好后,再对临时表进行过滤的条件。
笛卡尔积
自然连接
链接两个关系中都出现的相同属性取值相等的元组
from 表1 natural join 表2
更名 as 子句
旧名字 as 新名字 //很多语言都有这种操作
concat(url, ', ', alexa, ', ', country) as site_info // 把三个列(url、alexa 和 country)结合在一起,并创建一个名为 "site_info" 的别名
upper(s)/lower(s)转换字符串大小写\转义字符union并 运算 默认自动去除重复,加上all全部实现intersect交 运算
set names utf8; 命令用于设置使用的字符集。
union / union all 操作符 取并集
函数
Aggregate 聚合函数
特点就是它们的结果都是一个单一的值,多个行一起应用一个这样的函数后,就变成一行了。
AVG()- 返回平均值COUNT()- 返回行数FIRST()- 返回第一个记录的值LAST()- 返回最后一个记录的值MAX()- 返回最大值MIN()- 返回最小值SUM()- 返回总和
Scalar 函数
基于输入值,返回一个单一的值
UCASE()- 将某个字段转换为大写LCASE()- 将某个字段转换为小写MID()- 从某个文本字段提取字符,MySql 中使用SubString(字段,1,end)- 从某个文本字段提取字符LEN()- 返回某个文本字段的长度ROUND()- 对某个数值字段进行指定小数位数的四舍五入NOW()- 返回当前的系统日期和时间FORMAT()- 格式化某个字段的显示方式
group by
指定聚合函数 按照哪些列进行分组计算
分组依据是值相同分为一组
having 子句
- having 在 group by 之后
- 聚合函数(avg、sum、max、min、count)不能直接作为条件放在where之后,但可以放在having之后
where count > (select AVG(count) from access_log);
having SUM(access_log.count) > 200;
视图 Views
create or replace view view_name as
select column_name(s)
from table_name
where condition;
使用 视图
SELECT * FROM view_name

 浙公网安备 33010602011771号
浙公网安备 33010602011771号