
社区新贡献:X2SeaTunnel 助你无缝迁移到 SeaTunnel!
为了帮助用户更顺利地迁移到 Apache SeaTunnel 平台,社区成员提出了一个实用建议:开发一个通用的配置转换工具,支持将多种数据集成工具的配置文件转换为 SeaTunnel 支持的 HOCON 或 JSON 格式。这样,用户在迁移过程中将更加省心高效。
目前,该工具的设计方案已在 GitHub 上发布,并正式进入 SeaTunnel Roadmap。开发工作也已启动。
这个想法是否正好戳中你的需求?如果你也感兴趣,欢迎加入共建,一起打磨这个实用功能!
GitHub 链接:https://github.com/apache/seatunnel/issues/9507
背景概述
X2SeaTunnel 是一个通用配置转换工具,用于将多种数据集成工具(如 DataX、Sqoop 等)的配置文件转换为 SeaTunnel 的 HOCON 或 JSON 配置文件,帮助用户平滑迁移到 SeaTunnel 平台。
设计思路
核心理念
- 简单轻量:保持工具轻量高效,专注于配置文件格式转换
- 统一框架:构建一个通用框架,支持多种数据集成工具的配置转换
- 可扩展性:采用插件式设计,便于后续扩展支持更多工具
- 易用性:提供多种使用方式,提供SDK,提供命令行方式,支持单脚本和批量,满足不同场景需求
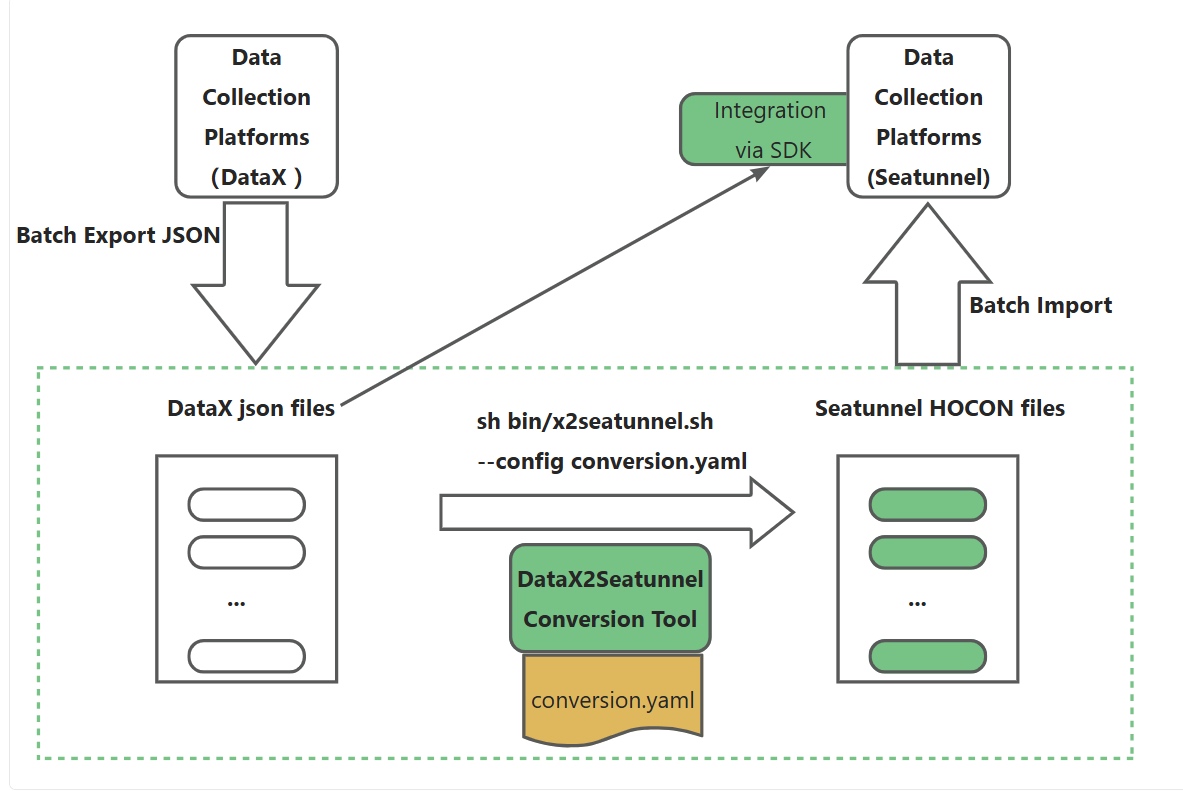
转换流程
源工具配置(DataX json) → 解析 → 统一模型 → 映射转换 → 生成 SeaTunnel 配置
使用方式
简单命令行方式
# 基本用法
sh bin/x2seatunnel.sh -t datax -i /path/to/config.json -o /path/to/output.conf
# 指定工具类型、输入输出和格式
sh bin/x2seatunnel.sh -t datax -i input.json -o output.conf -f hocon
# 批量转换
sh bin/x2seatunnel.sh -t datax -d /input/dir/ -o /output/dir/
Yaml命令行方式
# 使用YAML配置文件
sh bin/x2seatunnel.sh --config conversion.yaml
YAML配置文件示例
# X2SeaTunnel配置文件
metadata:
# 配置文件格式版本
configVersion: "1.0"
# 描述(可选)
description: "DataX到SeaTunnel转换配置"
# 工具配置
tool:
# 源工具类型:datax, sqoop等
sourceType: "datax"
sourceVersion: "2.1.2"
# 目标SeaTunnel版本
targetVersion: "2.3.11"
# 输入配置
input:
# 源配置路径(文件或目录)
path: "/path/to/configs"
# 是否递归处理子目录
recursive: true
# 文件匹配模式
pattern: "*.json"
# 输出配置
output:
# 输出路径
path: "/path/to/output"
# 输出格式:hocon或json
format: "hocon"
# 文件名转换规则
namePattern: "${filename}_seatunnel.conf"
# 映射配置
mapping:
# 自定义映射规则路径(可选)
rulesPath: "/path/to/custom/rules.json"
# 验证配置
validation:
# 是否启用验证
enabled: true
# 验证失败行为:warn, error, ignore
# 日志配置
logging:
# 日志级别:debug, info, warn, error
level: "info"
# 日志输出路径
path: "./logs"
# 日志文件名模式
filePattern: "x2seatunnel-%d{yyyy-MM-dd}.log"
# 是否同时输出到控制台
console: true
SDK方式集成
// 创建特定工具转换器
X2SeaTunnelConverter converter = X2SeaTunnelFactory.createConverter("datax");
// 配置转换选项
ConversionOptions options = new ConversionOptions.Builder()
.outputFormat("hocon")
.targetVersion("2.3.11")
.build();
// 执行转换
String seatunnelConfig = converter.convert(sourceConfigContent, options);
实施路线图
- 第一阶段:基础框架及DataX支持,Mysql数据源可使用
核心接口设计
- DataX常用连接器支持(MySQL, Hive)
- 基本命令行工具
- 批量处理功能
- 实现单元测试与e2e测试
- 总结基于AI实现不同连接器的prompt。
- 第二阶段:完善DataX更多数据源支持
- 扩展DataX连接器支持(PostgreSQL,ES, Kafka等)
- 版本适配功能
- 第三阶段:扩展其他工具支持与持续优化
- Sqoop支持实现
- 更多高级功能
实现思路
采用“配置驱动、取用逻辑的设计”,可以减少代码量,降低扩展难度,适合迁移转换场景。因为:
- 目标系统Seatunnel的配置规范是确定的
- 需要确保迁移后配置的完整性和正确性
- 需要识别哪些原有配置无法迁移,不追求完美,需要人工处理
具体选型依据见后文。
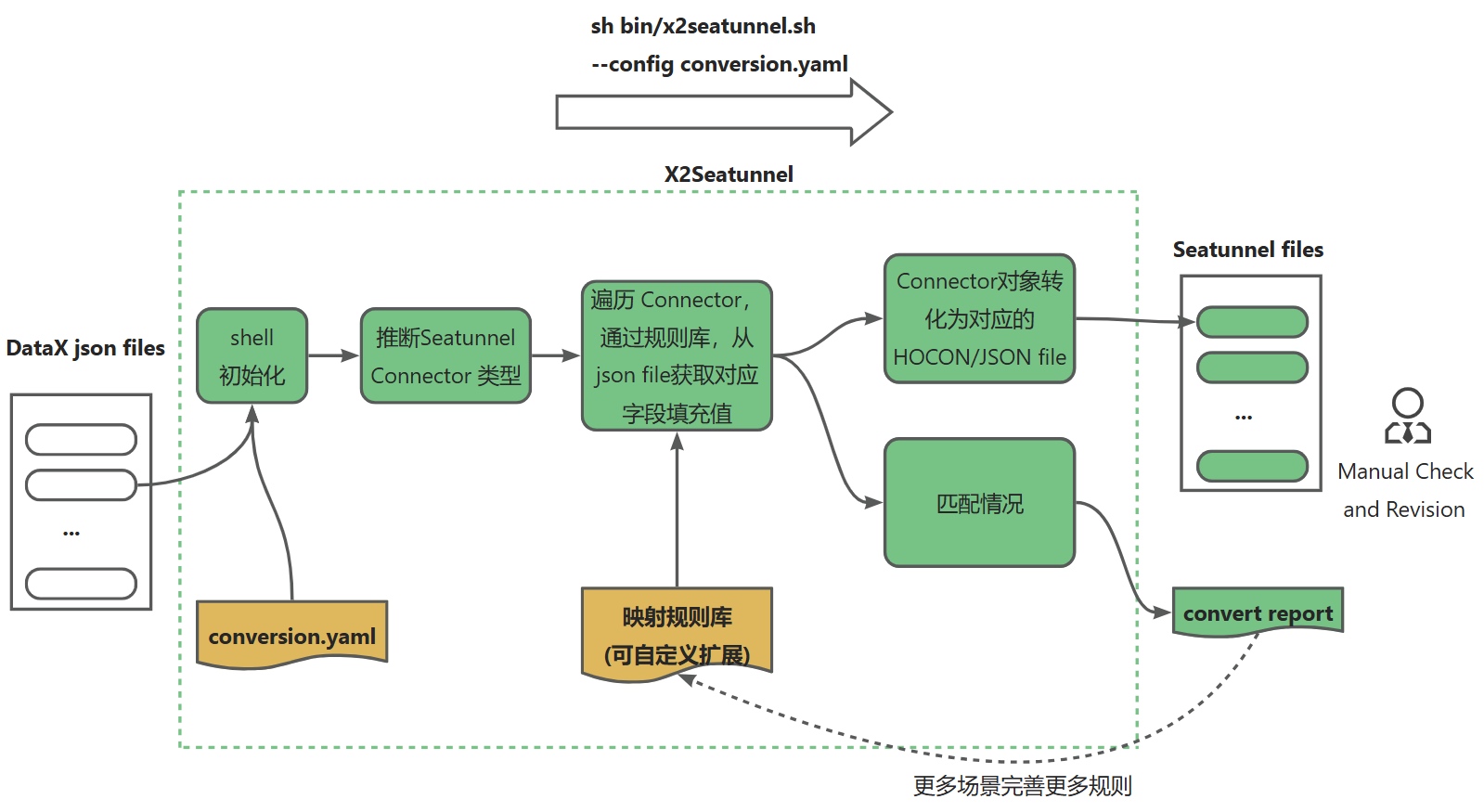
如上图,整体逻辑包含如下几步:
- 脚本调用与工具触发
执行 sh bin/x2seatunnel.sh --config conversion.yaml ,调用 X2Seatunnel jar包工具,依托 conversion.yaml 配置(可选)或命令行参数,启动数据转换工具流程 。 - Jar 包核心初始化
Jar 包运行时,根据 DataX(或sqoop等)的配置文件,以及相关参数,推断待转换的 SeaTunnel Connector 类型,明确转换适配的组件方向,为后续字段匹配、文件转换奠定基础。 - 规则匹配与字段填充阶段
遍历 Connector,借助映射规则库,从 DataX 的 json 文件中提取并填充对应字段值,同时输出字段、Connector 的匹配情况,明确转换过程中各元素的适配状态。 - 转换输出阶段
4.1 配置文件转换
将 Connector 对象转化为 SeaTunnel 适用的 HOCON/JSON 文件,输出到指定目录;
4.2 输出转换报告
生成转换报告(convert report),记录转换详情与匹配结果;供人工检查和确认,保障转换质量。 - 规则迭代阶段
基于实际转换场景,可持续完善映射规则库,覆盖更多数据转换需求,优化 X2Seatunnel 工具的适配能力,让流程在多样场景下更精准、高效。
待规则引擎逐步迭代稳定后,后续新增转换规则,只需要修改映射规则库,即可快速添加新类型数据源的转换。
通过总结的prompt,可以利用AI大模型,快速生成映射规则。
整个流程通过规则驱动、人工校验,助力数据同步任务向 SeaTunnel 迁移,支撑工具功能落地与迭代 。
三种实现思路探讨
X2Seatunnel的实现方式有很多种,主要有以下三种实现方式:
- 对象映射路线:强类型,通过对象模型转换,编码为主
- 声明映射逻辑(推送式):遍历源配置,映射到目标,配置为主
- 取用逻辑(拉取式):遍历目标需求,从源获取,模板为主
下面用一个表格来说明不同实现思路的特点:
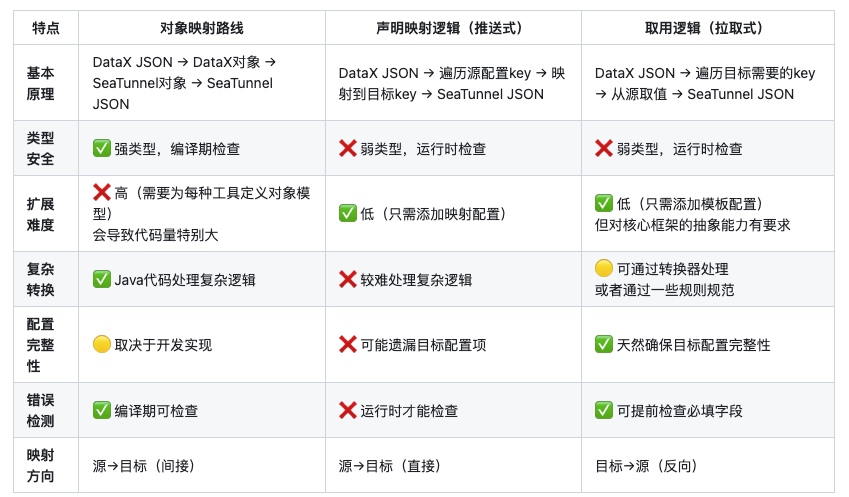
各实现思路本质区别
- 对象映射路线:强类型,通过对象模型转换,编码为主
DataXConfig dataX = JsonUtils.parse(jsonStr, DataXConfig.class);
SeaTunnelConfig st = converter.convert(dataX);
String stJson = JsonUtils.toString(st);
- 声明映射逻辑(推送式):遍历源配置,映射到目标,配置为主
// 遍历源配置中的每个字段
for (String srcPath : mappingRules.keySet()) {
String targetPath = mappingRules.get(srcPath);
Object value = JsonPath.read(sourceJson, srcPath);
JsonPath.set(targetJson, targetPath, value);
}
- 取用逻辑(拉取式):遍历目标需求,从源获取,模板为主
// 遍历目标模板中需要的每个字段
for (TemplateField field : targetTemplate.getFields()) {
String sourcePath = field.getSourcePath();
Object value = sourcePath != null ?
JsonPath.read(sourceJson, sourcePath) : field.getDefault();
targetJson.put(field.getName(), value);
}
推送式与拉取式的本质区别
这两种方式看似相似(都用映射引擎),但方向完全相反:
- 推送式:从源出发,"我有什么给你什么",可能遗漏目标字段
- 拉取式:从目标出发,"我需要什么从你那拿什么",确保目标完整
最佳实践建议
根据分析,混合方案最为合适,结合三种思路的优点:
- 以拉取式映射为核心:确保目标配置的完整性
# 模板驱动的映射配置
seatunnel_mysql_source:
required_fields:
url:
source_path: "job.content[0].reader.parameter.connection[0].jdbcUrl[0]"
-
复杂转换用对象处理:处理需要编程逻辑的转换
这个到时候具体看,我觉得基于简单的字符串拼接规则应该就ok了。 -
配置驱动扩展:新增工具支持主要通过配置文件
实现思路结论
推荐采用以 "拉取式映射"为核心,辅以少量对象映射处理复杂逻辑的混合方案。这种方式既确保了目标配置的完整性,又保持了良好的扩展性和维护性,同时能够应对复杂的转换场景。
总结
X2SeaTunnel工具采用统一框架设计,支持多种数据集成工具配置向SeaTunnel的转换。通过插件式架构,既保证了工具的轻量高效,又提供了良好的扩展性。该工具通过降低迁移成本,帮助用户平滑迁移到SeaTunnel平台,提高数据集成效率。
工具同时提供命令行和SDK两种使用方式,满足不同场景需求。核心设计着重于配置映射的准确性和通用性,确保生成的SeaTunnel配置可直接使用。整体架构支持未来扩展更多数据集成工具的转换能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号