PairRDD中算子aggregateByKey图解
PairRDD 有几个比较麻烦的算子,常理解了后面又忘记了,自己按照自己的理解记录好,以备查阅
1、aggregateByKey
aggregate 是聚合意思,直观理解就是按照Key进行聚合。
转化: RDD[(K,V)] ==> RDD[(K,U)]
可以看出是返回值的类型不需要和原来的RDD的Value类型一致的。
在聚合过程中提供一个中立的初始值。
原型:
def aggregateByKey[U:ClassTag](zeroValue:U, partitioner:Partitioner)(seqOp:(U,V) =>U, comOp:(U,U) =>U):RDD[(K,U)]
def aggregateByKey[U:ClassTag](zeroValue:U, numPartitions:Int)(seqOp:(U,V) =>U, comOp:(U,U) =>U):RDD[(K,U)]
def aggregateByKey[U:ClassTag](zeroValue:U)(seqOp:(U,V) =>U, comOp:(U,U) =>U):RDD[(K,U)]
1、 第一个可以自己定义分区Partitioner; 2、第二个设置了分区数,最终定义了和HashPartitioner; 3、第三个会判断当前RDD是否定义分区函数,如果定义了则用当前的分区函数,没定义,则使用HashPartitioner
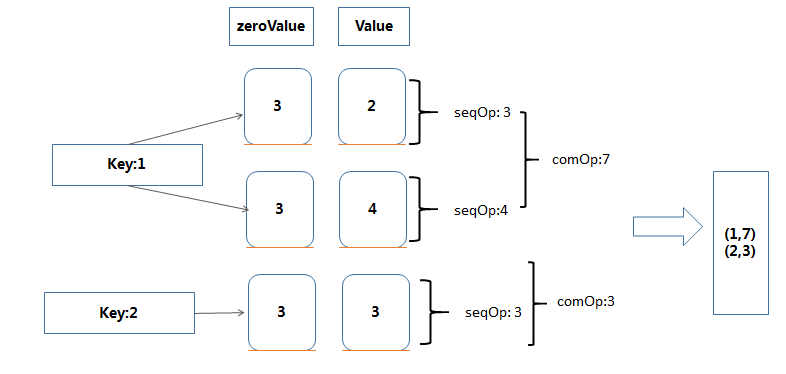
例子:
>val data = sc.parallelize(List((1,2),(1,4),(2,3)))
> data.aggregateByKey(3)((x,y)=>math.max(x,y) ,(z,m)=>z+m)
>Array((1,7)(2,3))
作者:明翼(XGogo)
-------------
公众号:TSparks
微信:shinelife
扫描关注我的微信公众号感谢

-------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号