Selenium29-数据驱动测试
常见的驱动模式
- 数据驱动测试:把测试数据从测试代码里分离出来,也称为"表驱动测试"或"参数化测试"
- 关键字驱动测试:把业务逻辑代码块封装为"关键字",本质就是函数或方法
- 混合驱动测试=数据驱动测试+关键字驱动测试
- 行为驱动测试:用自然语言来实现测试用例内容
为什么要做数据驱动测试
- 测试数据有多组,代码只有一份,实现不同数据运行同一份代码
- 数据驱动测试
- 避免编写重复代码
- 数据与测试脚本分离
- 通过使用数据驱动测试,来验证多组数据测试场景
![]()
数据驱动测试
-
Data-Driven Test
-
是一种软件测试方法,将测试数据提取到表或外部表格形式的文件里
-
对一个测试代码里的业务操作,使用表或文件中的所有测试数据来反复执行测试
-
也称为表驱动测试或参数化测试
-
Python的unittest框架借助于ddt来实现数据驱动测试
- ddt是一个第三方python库,用于实现数据驱动测试
- 安装ddt: pip install ddt
ddt基础装饰器
- ddt本质其实就是用装饰器来模拟多组测试数据,一组数据一个测试场景
- 装饰器的作用是增强类、函数、方法的功能
- @data 用来装饰测试方法,通过装饰器的参数来准备多组测试数据
- @ddt 用来装饰测试用例实现类,自动读取数据内容,按照数据组数来自动生成多个测试方法
ddt基础使用步骤
-
导入装饰器
from ddt import ddt,data -
使用@ddt装饰类
@ddt class mytestclass: -
使用@data准备多组测试数据
@data(值1,值2,值3...) def test_**(变量): # 增加形参变量来接收数据 print(变量) # 在测试方法中可使用变量 -
注意
- 运行代码时,必须整个类来运行,不能单独运行某一个测试方法
-
import unittest from ddt import ddt,data,unpack @ddt class MyTestCase(unittest.TestCase): @data(1,2,3,4,5) def test_something(self,value): print(value) if __name__ == '__main__': unittest.main()
unpack装饰器
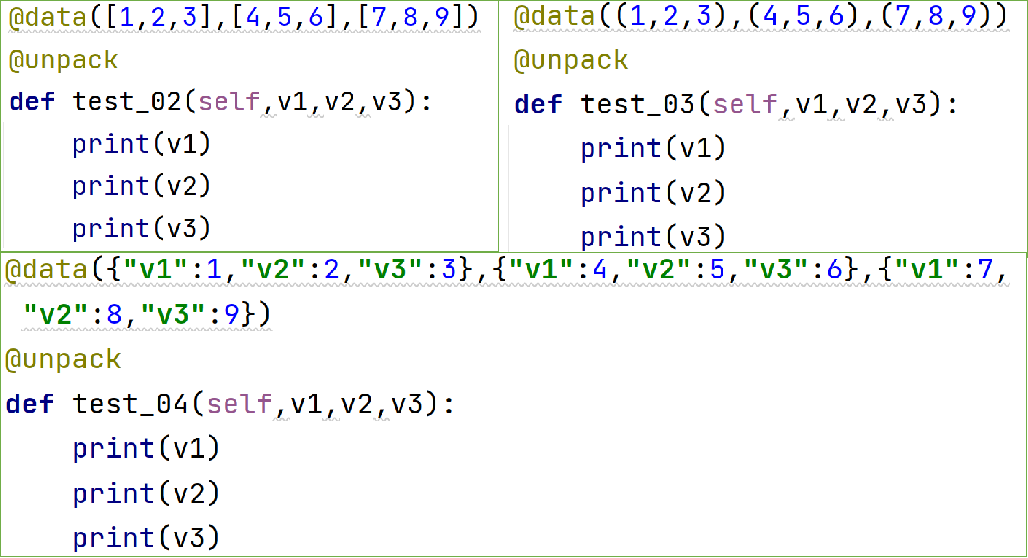
- 解决的问题:每组测试数据有多个值,用列表、元组或字典传入,需要解包后才能使用
- @unpack装饰器对列表、元组或字典进行解包,获取其中的值
@ddt
class ....
@data([值11,值12,值13],[值21,值22,值23])
@unpack
def test_....(变量1,变量2,变量3):
.....
注意:
- 每组数据里数据个数必须一致
- 每组数据里有几个值,就需要准备几个变量
![]()
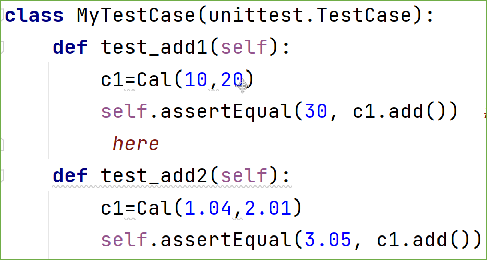
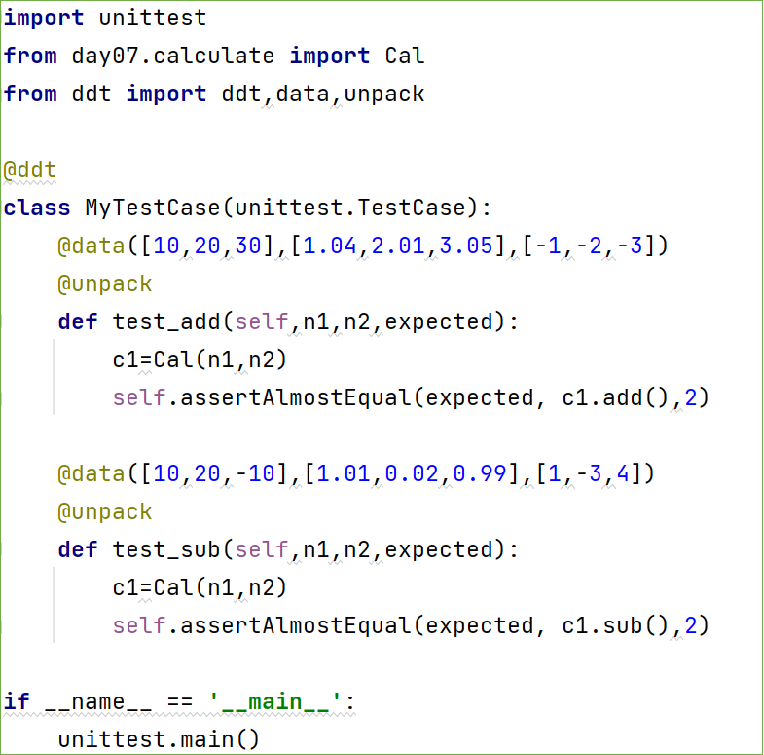
针对calculate.py单元测试的用例,使用ddt来简化代码
- 把加法计算的三个测试方法test_add1、test_add2、test_add3合并为一个测试方法test_add,用它来测试三组加法的数据。
- 把减法计算的三个测试方法test_sub1、test_sub2、test_sub3合并为一个测试方法test_sub,用它来测试三组减法的数据。
![]()
外部文件数据
问题:ddt测试数据量大时,与业务逻辑一起写在测试代码里会较为混乱,如何管理大量的测试数据才能最大限度减少耦合度
解决方案:
- 数据量大时,建议提取到外部文件里存储管理
- 数据存储在外部文件里,方便后期更新和维护,也可以进行数据复用
![]()

外部文件格式: CSV、JSON、YAML、TXT、EXCEL

file_data装饰器
- @file_data 装饰测试方法,参数是文件名(包含路径)
- @file_data 支持的文件格式:json 或 yaml类型
- 如果文件是以.yml或者.yaml结尾,ddt会作为yaml类型处理
- 其它文件都会作为json文件处理
- 如果使用yaml格式,需要安装yaml模块:pip install pyyaml
- JSON是一种轻量级的数据交换格式,采用完全独立于编程语言的文本格式来存储和表示数据
- YAML是一种直观的数据序列化格式,可读性强,可被支持YAML库的不同的编程语言程序导入
![]()

json

yaml

CSV模式
-
Python自带了csv模块,导入import csv后使用它读取csv文件
![]()
![]()
-
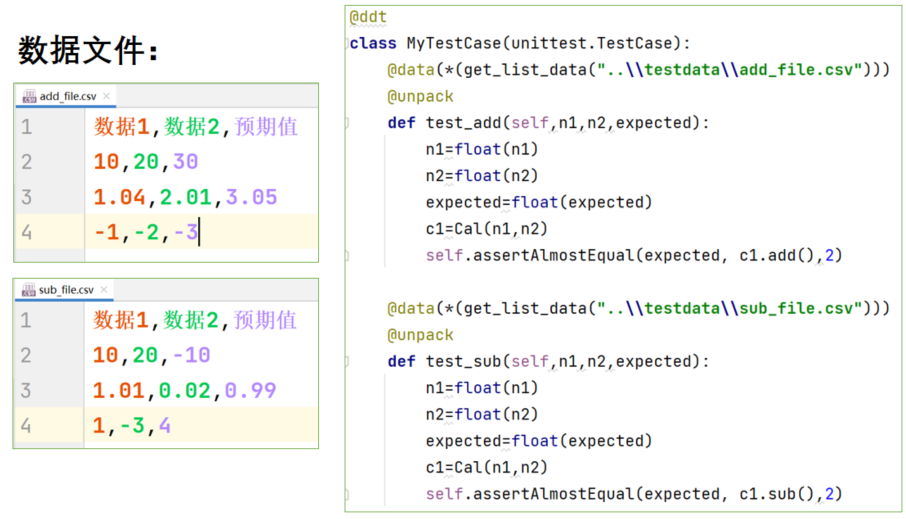
针对calculate.py单元测试的用例,使用csv格式的数据文件来提供测试数据
- 在testcase8002.py代码基础上改造,使用csv格式的两个数据文件。
- add_file.csv存储加法数据,sub_file.csv存储减法数据。
- 提示:注意数据类型需要强制转换。
![]()


模块化程序设计
- 应用场景:把通用的功能代码,封装设计为函数(或类里的方法),把它存储在一个单独的模块里,需要使用这段功能的代码块时,调用这个通用的函数。
- 读取csv文件的功能的代码块,希望设计一个独立的工具模块
- utils(工具包)---New---Python file---read_csv.py
- 导入csv模块,定义一个读取csv文件内容的工具类,假设叫做CSVUtil定义一个构造方法,传入csv文件的路径作为参数,初始化成员变量file_path的值
- 定义一个方法(假设get_list_data),读取成员变量file_path表示的文件所有内容,返回该内容
- 注意:参数、返回值的数据类型(例如:大列表里有小列表)
- 使用工具模块
from utils.read_csv import CSVUtil
d=CSVUtil("..\\testdata\\test4.csv").get_list_data()
本文来自博客园,作者:暄总-tester,转载请注明原文链接:https://www.cnblogs.com/sean-test/p/17007911.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号