6. RDD综合练习:更丰富的操作
三、学生课程分数
持久化 stu.cache()

总共有多少学生?map(), distinct(), count()

开设了多少门课程?

生成(姓名,课程分数)键值对RDD,观察keys(),values()

每个学生选修了多少门课?map(), countByKey()
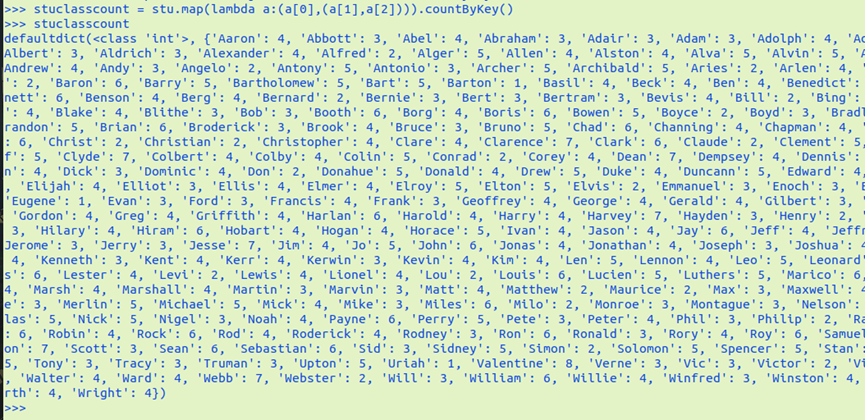
每门课程有多少个学生选?map(), countByValue()
![]()
有多少个100分?

Tom选修了几门课?每门课多少分?filter(), map() RDD
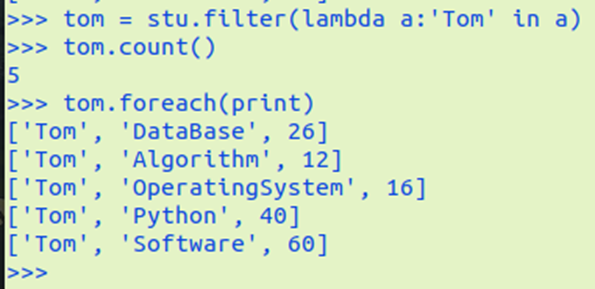
Tom选修了几门课?每门课多少分?map(),lookup() list
![]()
![]()
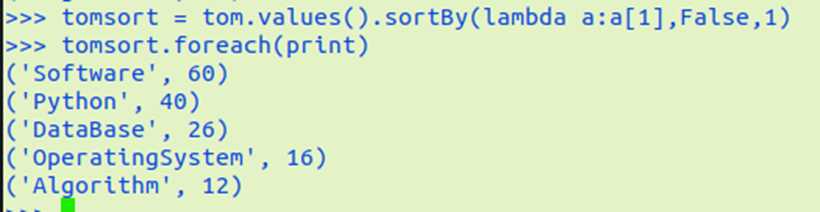
Tom的成绩按分数大小排序。filter(), map(), sortBy()
Tom的平均分。map(),lookup(),mean()

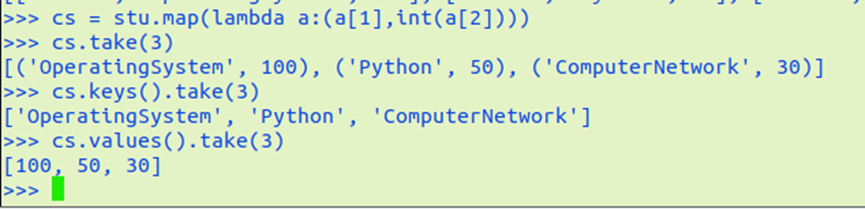
生成(课程,分数)RDD,观察keys(),values()
每个分数+20平时分。分别用mapValues(func)和 map(func)实现。并查看不及格人数的变化。

求每门课的选修人数及平均分
lookup(),np.mean()实现

reduceByKey()和collectAsMap()实现

combineByKey(),map(),round()实现,确到2位小数
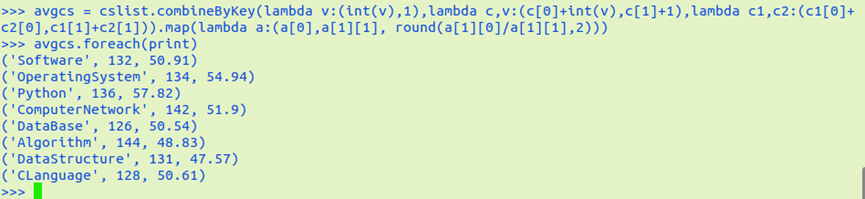
(课程,人数,平均分)
比较几种方法的异同:
reduceByKey 用于对每个 key 对应的多个 value 进行 merge 操作,最重要的是它能够在本地先进行 merge 操作,并且 merge 操作可以通过函数自定义;
CombineByKey是一个比较底层的算子:
combineByKey(createCombiner,mergeValue,mergeCombiners)
createCombiner:在第一次遇到Key时创建组合器函数,将RDD数据集中的V类型值转换C类型值(V => C);
mergeValue:合并值函数,再次遇到相同的Key时,将createCombiner的C类型值与这次传入的V类型值合并成一个C类型值(C,V)=>C
mergeCombiners:合并组合器函数,将C类型值两两合并成一个C类型值
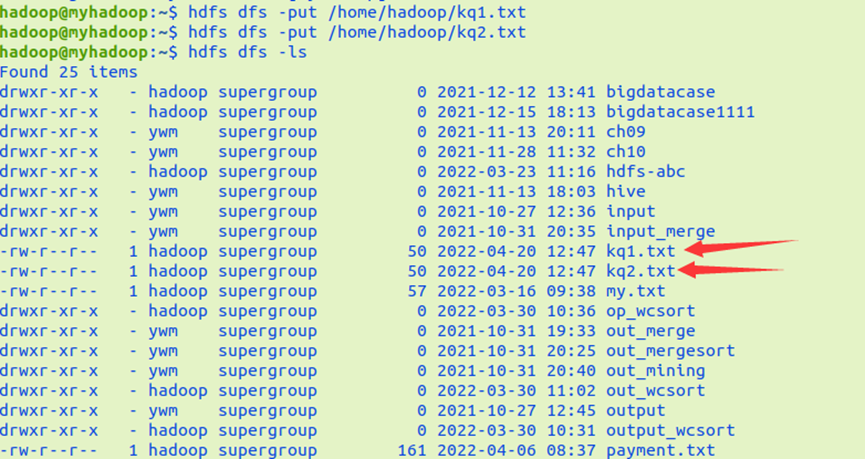
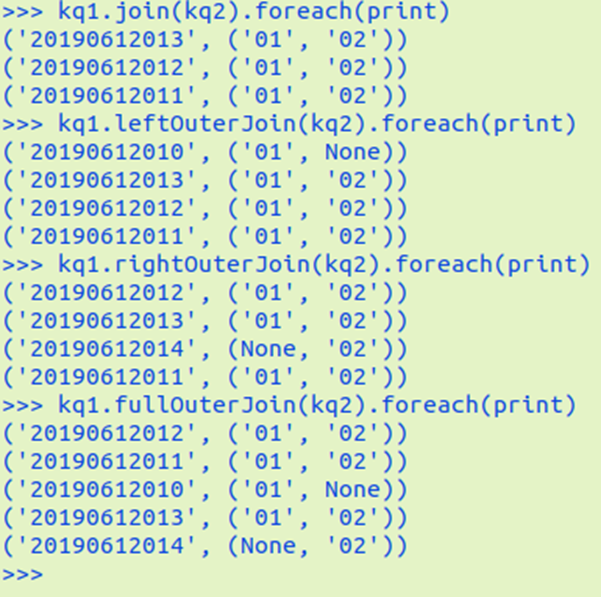
多个考勤文件,签到日期汇总,出勤次数统计键值对RDD的内连接与外连接
join(), leftOuterJoin(), rightOuterJoin(), fullOuterJoin()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号